monday, september 18, 2000 william h. hsu department of computing and information sciences, ksu
DESCRIPTION
CIS 540 Robotics Laboratory. Robotic Soccer: A Machine Learning Testbed. Monday, September 18, 2000 William H. Hsu Department of Computing and Information Sciences, KSU http://www.cis.ksu.edu/~bhsu Readings: Chapter 13.1-13.4, Mitchell Sections 20.1-20.2, Russell and Norvig. - PowerPoint PPT PresentationTRANSCRIPT

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Monday, September 18, 2000
William H. Hsu
Department of Computing and Information Sciences, KSUhttp://www.cis.ksu.edu/~bhsu
Readings:
Chapter 13.1-13.4, Mitchell
Sections 20.1-20.2, Russell and Norvig
Robotic Soccer:A Machine Learning Testbed
CIS 540 Robotics LaboratoryCIS 540 Robotics Laboratory

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Lecture OutlineLecture Outline
• References: Chapter 13, Mitchell; Sections 20.1-20.2, Russell and Norvig
– Today: Sections 13.1-13.4, Mitchell
– Review: “Learning to Predict by the Method of Temporal Differences”, Sutton
• Introduction to Reinforcement Learning
• Control Learning
– Control policies that choose optimal actions
– MDP framework, continued
– Issues
• Delayed reward
• Active learning opportunities
• Partial observability
• Reuse requirement
• Q Learning
– Dynamic programming algorithm
– Deterministic and nondeterministic cases; convergence properties

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Control LearningControl Learning
• Learning to Choose Actions
– Performance element
• Applying policy in uncertain environment (last time)
• Control, optimization objectives: belong to intelligent agent
– Applications: automation (including mobile robotics), information retrieval
• Examples
– Robot learning to dock on battery charger
– Learning to choose actions to optimize factory output
– Learning to play Backgammon
• Problem Characteristics
– Delayed reward: loss signal may be episodic (e.g., win-loss at end of game)
– Opportunity for active exploration: situated learning
– Possible partially observability of states
– Possible need to learn multiple tasks with same sensors, effectors
(e.g., actuators)

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Example:Example:TD-GammonTD-Gammon
• Learns to Play Backgammon [Tesauro, 1995]
– Predecessor: NeuroGammon [Tesauro and Sejnowski, 1989]
• Learned from examples of labelled moves (very tedious for human expert)
• Result: strong computer player, but not grandmaster-level
– TD-Gammon: first version, 1992 - used reinforcement learning
• Immediate Reward
– +100 if win
– -100 if loss
– 0 for all other states
• Learning in TD-Gammon
– Algorithm: temporal differences [Sutton, 1988] - next time
– Training: playing 200000 - 1.5 million games against itself (several weeks)
– Learning curve: improves until ~1.5 million games
– Result: now approximately equal to best human player (won World Cup of
Backgammon in 1992; among top 3 since 1995)
Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
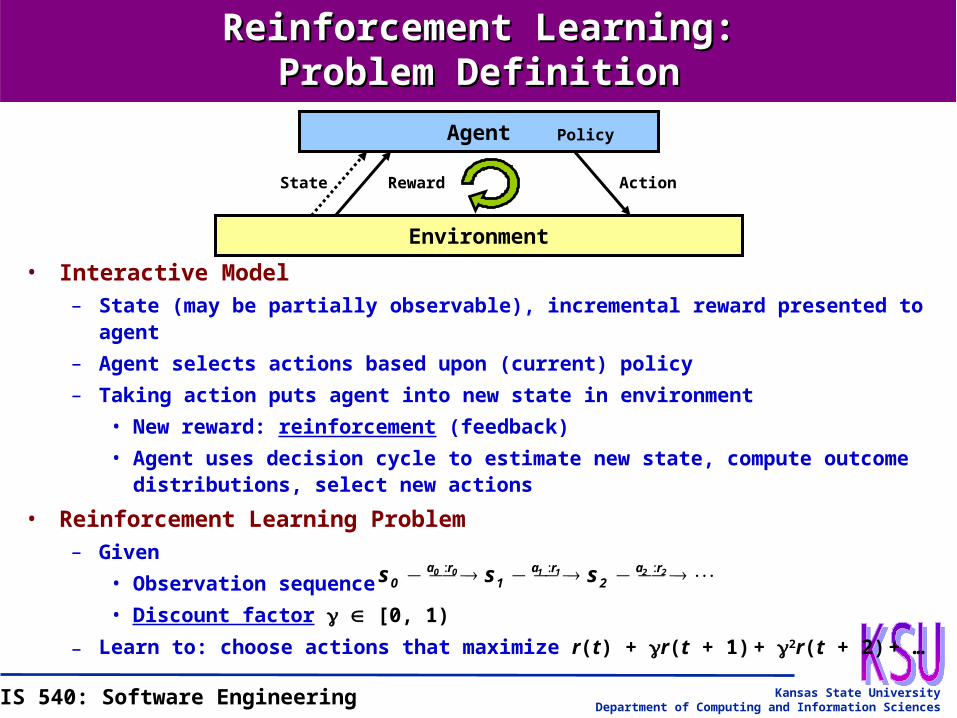
Reinforcement Learning:Reinforcement Learning:Problem DefinitionProblem Definition
Agent
Environment
State Reward Action
Policy
• Interactive Model– State (may be partially observable), incremental reward presented to agent
– Agent selects actions based upon (current) policy
– Taking action puts agent into new state in environment
• New reward: reinforcement (feedback)
• Agent uses decision cycle to estimate new state, compute outcome distributions, select new actions
• Reinforcement Learning Problem– Given
• Observation sequence
• Discount factor [0, 1)
– Learn to: choose actions that maximize r(t) + r(t + 1) + 2r(t + 2) + …
sss 221100 r a2
r a1
r a0 :::

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Quick Review:Quick Review:Markov Decision ProcessesMarkov Decision Processes
• Markov Decision Processes (MDPs)
– Components
• Finite set of states S
• Set of actions A
– At each time, agent
• observes state s(t) S and chooses action a(t) A;
• then receives reward r(t),
• and state changes to s(t + 1)
– Markov property, aka Markov assumption: s(t + 1) = (t + 1) and r(t) = r(s(t), a(t))
• i.e., r(t) and s(t + 1) depend only on current state and action
• Previous history s(0), s(1), …, s(t - 1): irrelevant
• i.e., s(t + 1) conditionally independent of s(0), s(1), …, s(t - 1) given s(t)
, r: may be nondeterministic; not necessarily known to agent
– Variants: totally observable (accessible), partially observable (inaccessible)
• Criterion for a(t): Total Reward – Maximum Expected Utility (MEU)

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Agent’s Learning TaskAgent’s Learning Task
• Performance Element
– Execute actions in environment, observe results
– Learn action policy : state action that maximizes expected discounted reward
E[r(t) + r(t + 1) + 2r(t + 2) + …] from any starting state in S
[0, 1)
• Discount factor on future rewards
• Expresses preference for rewards sooner rather than later
• Note: Something New!
– Target function is : state action
– However…
• We have no training examples of form <state, action>
• Training examples are of form <<state, action>, reward>

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Value FunctionValue Function
• First Learning Scenario: Deterministic Worlds
– Agent considers adopting policy from policy space
– For each possible policy , can define an evaluation function over states:
where r(t), r(t + 1), r(t + 2), … are generated by following policy starting at state s
– Restated, task is to learn optimal policy *
• Finding Optimal Policy
0
2 11
i
i
π
itrγ
trγtγrtrsV
s,sVmaxargπ* π
π
r(state, action)immediate reward values
Q(state, action) values One optimal policyV*(state) values
100
0
0
100
G 0
0
0
0
0 0
0 0
0
90
81
100
G 0
81
72
90
81 81
72
90
81
100
G 90 100 0
81 90 100
G

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
What to LearnWhat to Learn
• Idea
– Might have agent try to learn evaluation function V* (abbreviated V*)
– Could then perform lookahead search to choose best action from any state s,
because:
• Problem with Idea
– Works well if agent knows
: state action state
• r : state action R
– When agent doesn’t know and r, cannot choose actions this way
a s,δ*Va s,rmaxargsπ*a

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
QQ Function Function
• Solution Approach
– Define new function very similar to V*
– If agent learns Q, it can choose optimal action even without knowing !
• Using Learned Q
– Q: evaluation function to be learned by agent
– Apply Q to select action
• Idealized, computed policy (this is your brain without Q-learning):
• Approximated policy (this is your brain with Q-learning):
a s,δ*γVa s,ra s,Q
a s,δ*Va s,rmaxargsπ*a
a s,Q maxargsπ*a

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Training Rule to Learn Training Rule to Learn QQ
• Developing Recurrence Equation for Q
– Note: Q and V* closely related
– Allows us to write Q recursively as
– Nice! Let denote learner’s current approximation to Q
• Training Rule
– s’: state resulting from applying action a in state s
– (Deterministic) transition function made implicit
– Dynamic programming: iterate over table of possible a’ values
Q̂
a' s,Q maxargs*Va'
a' ,tsQmax γta ,tsr
ta ,tsδγVta ,tsr ta ,tsQ
a'1
a' ,s'Q max γa s,r a s,Q a'
ˆˆ

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
QQ Learning for Learning forDeterministic WorldsDeterministic Worlds
• (Nonterminating) Procedure for Situated Agent
• Procedure Q-Learning-Deterministic (Reinforcement-Stream)
– Reinforcement-Stream: consists of <<state, action>, reward> tuples
– FOR each <s, a> DO
• Initialize table entry
– Observe current state s
– WHILE (true) DO
• Select action a and execute it
• Receive immediate reward r
• Observe new state s’
• Update table entry for as follows
• Move: record transition from s to s’
0 a s,Q̂
a s,Q̂
a' ,s'Q max γa s,r a s,Q a'
ˆˆ

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
• Example: Propagating Credit (Q) for Candidate Action
– glyph: denotes mobile robot
– Initial state: s1 (upper left)
– Let discount factor be 0.9
– Q estimate
• Property
– If rewards nonnegative, then increases monotonically between 0 and true Q
–
90
100} 81, {63,0.90
max
a' ,sQ max γa s,r a ,sQ 2a'
right1ˆˆ
a ,sQ a s,Q . n a, s, a ,sQ a s,Q . n a, s, a s,r nnn ˆˆˆ 0 0 1
Q̂
Updating the Updating the QQ Estimate Estimate
Initial state: s1
72
63
100
G 81
Next state: s2
arights1 s2 s1 s2
90
63
100
G 81

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
ConvergenceConvergence
• Claim
– converges to Q
– Scenario: deterministic world where <s, a> are observed (visited) infinitely often
• Proof
– Define full interval: interval during which each <s, a> is visited
– During each full interval, largest error in table is reduced by factor of
– Let be table after n updates and n be the maximum error in ; that is,
– For any table entry , updated error in revised estimate is
– Note: used general fact,
γΔa s,Qa s,Q
a' ,'s'Qa' ,'s'Q maxγa' ,s'Qa' ,s'Q maxγ
a' ,s'Q maxa' ,s'Q max γ
a' ,s'Q max γra' ,s'Q max γr a s,Qa s,Q
nn
na' ,'s'
na'
a'n
a'
na'
na'
n
1
1
ˆ
ˆˆ
ˆ
ˆˆ
Q̂
Q̂
nQ̂ nQ̂
a s,Qa s,Q max Δ na s,
n ˆ
a s,Qnˆ a s,Qn 1
ˆ
afafmax af maxaf max aaa
2121

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Nondeterministic CaseNondeterministic Case
• Second Learning Scenario: Nondeterministic World (Nondeterministic MDP)
– What if reward and next state are nondeterministically selected?
– i.e., reward function and transition function are nondeterministic
– Nondeterminism may express many kinds of uncertainty
• Inherent uncertainty in dynamics of world
• Effector exceptions (qualifications), side effects (ramifications)
• Solution Approach
– Redefine V, Q in terms of expected values
– Introduce decay factor; retain some of previous Q value
– Compare: momentum term in ANN learning
0
2 11
i
i
π
itrγE
trγtγrtrEsV
a s,δ*γVa s,rEa s,Q

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Nondeterministic Case:Nondeterministic Case:Generalizing Generalizing QQ Learning Learning
• Q Learning Generalizes to Nondeterministic Worlds
– Alter training rule to
– Decaying weighted average
– visitsn(s, a): total number of times <s, a> has been visited by iteration n, inclusive
– r: observed reward (may also be stochastically determined)
• Can Still Prove Convergence of to Q [Watkins and Dayan, 1992]
• Intuitive Idea [0, 1]: discounts estimate by number of visits, prevents oscillation
– Tradeoff
• More gradual revisions to
• Able to deal with stochastic environment: P(s’ | s, a), P(r | s, s’, a)
a' ,s'Q maxγrαa s,Q α a s,Q na'
nnnn 1-1-1- ˆˆˆ
Q̂
a s,visitsα
nn
1
1
Q̂

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
TerminologyTerminology
• Reinforcement Learning (RL)
– RL: learning to choose optimal actions from <state, reward, action> observations
– Scenarios
• Delayed reward: reinforcement is deferred until end of episode
• Active learning: agent can control collection of experience
• Partial observability: may only be able to observe rewards (must infer state)
• Reuse requirement: sensors, effectors may be required for multiple tasks
• Markov Decision Processes (MDPs)
– Markovity (aka Markov property, Markov assumption): CI assumption on states
over time
– Maximum expected utility (MEU): maximum expected total reward (under additive
decomposition assumption)
• Q Learning
– Action-value function Q : state action value
– Q learning: training rule and dynamic programming algorithm for RL

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Monday, September 18, 2000
William H. Hsu
Department of Computing and Information Sciences, KSUhttp://www.cis.ksu.edu/~bhsu
Readings:
Sections 13.5-13.8, Mitchell
Sections 20.2-20.7, Russell and Norvig
More Reinforcement Learning:Temporal Differences
CIS 540 Robotics LaboratoryCIS 540 Robotics Laboratory

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Lecture OutlineLecture Outline
• Readings: 13.1-13.4, Mitchell; 20.2-20.7, Russell and Norvig
• This Week’s Paper Review: “Connectionist Learning Procedures”, Hinton
• Suggested Exercises: 13.4, Mitchell; 20.11, Russell and Norvig
• Reinforcement Learning (RL) Concluded
– Control policies that choose optimal actions
– MDP framework, continued
– Continuing research topics
• Active learning: experimentation (exploration) strategies
• Generalization in RL
• Next: ANNs and GAs for RL
• Temporal Diffference (TD) Learning
– Family of dynamic programming algorithms for RL
• Generalization of Q learning
• More than one step of lookahead
– More on TD learning in action
Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
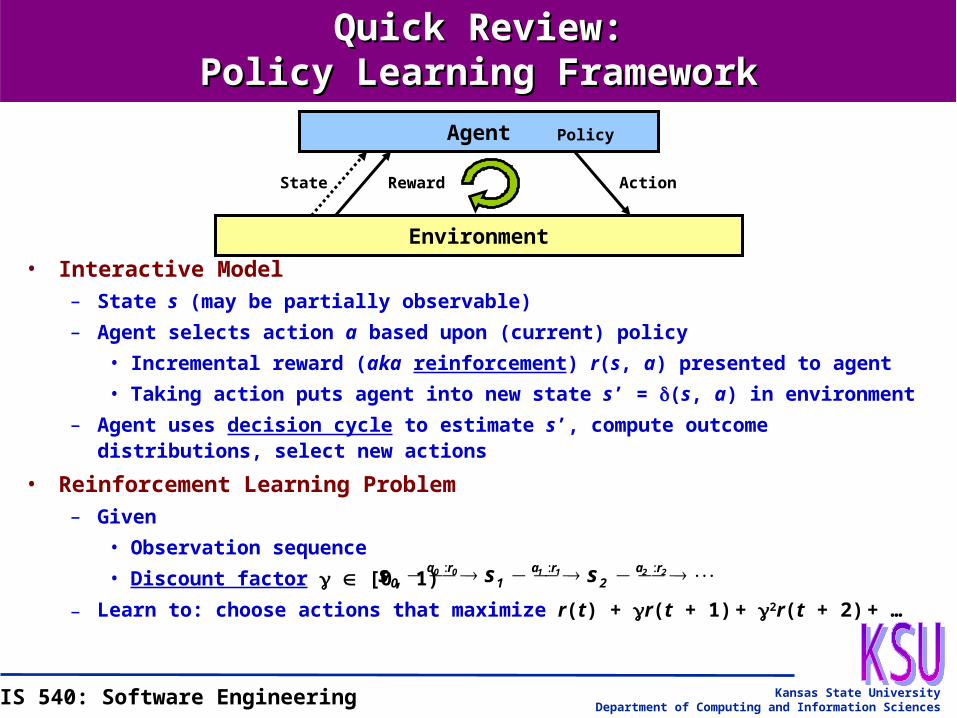
Quick Review:Quick Review:Policy Learning FrameworkPolicy Learning Framework
• Interactive Model– State s (may be partially observable)
– Agent selects action a based upon (current) policy
• Incremental reward (aka reinforcement) r(s, a) presented to agent
• Taking action puts agent into new state s’ = (s, a) in environment
– Agent uses decision cycle to estimate s’, compute outcome distributions, select new actions
• Reinforcement Learning Problem– Given
• Observation sequence
• Discount factor [0, 1)
– Learn to: choose actions that maximize r(t) + r(t + 1) + 2r(t + 2) + …
sss 221100 r a2
r a1
r a0 :::
Agent
Environment
State Reward Action
Policy

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Quick Review:Quick Review:QQ Learning Learning
r(state, action)immediate reward values
Q(state, action) values One optimal policyV*(state) values
100
0
0
100
G 0
0
0
0
0 0
0 0
0
90
81
100
G 0
81
72
90
81 81
72
90
81
100
G 90 100 0
81 90 100
G
• Deterministic World Scenario
– “Knowledge-free” (here, model-free) search for policy from policy space
– For each possible policy , can define an evaluation function over states:
where r(t), r(t + 1), r(t + 2), … are generated by following policy starting at state s
– Restated, task is to learn optimal policy *
• Finding Optimal Policy
• Q-Learning Training Rule
0
2 11
i
i
π
itrγ
trγtγrtrsV
s,sVmaxargπ* π
π
a' ,s'Q max γa s,r a s,Q a'
ˆˆ

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Learning ScenariosLearning Scenarios
• First Learning Scenario
– Passive learning in known environment (Section 20.2, Russell and Norvig)
– Intuition (passive learning in known and unknown environments)
• Training sequences (s1, s2, …, sn, r = U(sn))
• Learner has fixed policy ; determine benefits (expected total reward)
– Important note: known accessible deterministic (even if transition model
known, state may not be directly observable and may be stochastic)
– Solutions: naïve updating (LMS), dynamic programming, temporal differences
• Second Learning Scenario
– Passive learning in unknown environment (Section 20.3, Russell and Norvig)
– Solutions: LMS, temporal differences; adaptation of dynamic programming
• Third Learning Scenario
– Active learning in unknown environment (Sections 20.4-20.6, Russell and Norvig)
– Policy must be learned (e.g., through application and exploration)
– Solutions: dynamic programming (Q-learning), temporal differences

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Reinforcement Learning MethodsReinforcement Learning Methods
• Solution Approaches
– Naïve updating: least-mean-square (LMS) utility update
– Dynamic programming (DP): solving constraint equations
• Adaptive DP (ADP): includes value iteration, policy iteration, exact Q-learning
• Passive case: teacher selects sequences (trajectories through environment)
• Active case: exact Q-learning (recursive exploration)
– Method of temporal differences (TD): approximating constraint equations
• Intuitive idea: use observed transitions to adjust U(s) or Q(s, a)
• Active case: approximate Q-learning (TD Q-learning)
• Passive: Examples
– Temporal differences: U(s) U(s) + (R(s) + U(s’) - U(s))
– No exploration function
• Active: Examples
– ADP (value iteration): U(s) R(s) + maxa (s’ (Ms,s’(a) · U(s’)))
– Exploration (exact Q-learning): a' ,s'Q max γa s,r a s,Q a'
ˆˆ

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Active Learning and ExplorationActive Learning and Exploration
• Active Learning Framework
– So far: optimal behavior is to choose action with maximum expected utility (MEU),
given current estimates
– Proposed revision: action has two outcomes
• Gains rewards on current sequence (agent preference: greed)
• Affects percepts ability of agent to learn ability of agent to receive future
rewards (agent preference: “investment in education”, aka novelty, curiosity)
– Tradeoff: comfort (lower risk) reduced payoff versus higher risk, high potential
– Problem: how to quantify tradeoff, reward latter case?
• Exploration
– Define: exploration function - e.g., f(u, n) = (n < N) ? R+ : u
• u: expected utility under optimistic estimate; f increasing in u (greed)
• n N(s, a): number of trials of action-value pair; f decreasing in n (curiosity)
– Optimistic utility estimator: U+(s) R(s) + maxa f (s’ (Ms,s’(a) · U+(s’)), N(s, a))
• Key Issues: Generalization (Today); Allocation (CIS 830)

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Temporal Difference Learning:Temporal Difference Learning:Rationale and FormulaRationale and Formula
• Q-Learning
– Reduce discrepancy between successive estimates
– Q estimates
• One step time difference
•
• Method of Temporal Differences (TD()), aka Temporal Differencing
– Why not two steps?
– Or n steps?
– TD() formula
• Blends all of these
•
– Intuitive idea: use constant 0 1 to combine estimates from various
lookahead distances (note normalization factor 1 - )
a ,tsQ max γ tr ta ,tsQ a
11 ˆ
a ,tsQ maxγ tγr tr ta ,tsQ a
21 22 ˆ
a ,ntsQ maxγntrγ tγr tr ta ,tsQ a
nnn ˆ11 1
ta ,tsQλta ,tsλQta ,tsQ λ ta ,tsQ λ 32211

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Temporal Difference Learning:Temporal Difference Learning: TD( TD() Training Rule and Algorithm) Training Rule and Algorithm
• Training Rule: Derivation from Formula
– Formula:
– Recurrence equation for Q()(s(t), a(t)) (recursive definition) defines update rule
• Select a(t + i) based on current policy
•
• Algorithm
– Use above training rule
– Properties
• Sometimes converges faster than Q learning
• Converges for learning V* for any 0 1 [Dayan, 1992]
• Other results [Sutton, 1988; Peng and Williams, 1994]
– Application: Tesauro’s TD-Gammon uses this algorithm [Tesauro, 1995]
– Recommended book
• Reinforcement Learning [Sutton and Barto, 1998]
• http://www.cs.umass.edu/~rich/book/the-book.html
ta ,tsQλta ,tsλQta ,tsQ λ ta ,tsQ λ 32211
ta ,tsQ λa ,tsQ λγtr ta ,tsQ λ
a
λ 111 max1 ˆ

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Applying Results of RL:Applying Results of RL:Models versus Action-Value FunctionsModels versus Action-Value Functions
• Distinction: Learning Policies with and without Models– Model-theoretic approach
• Learning: transition function , utility function U
• ADP component: value/policy iteration to reconstruct U from R
• Putting learning and ADP components together: decision cycle (Lecture 17)
• Function Active-ADP-Agent: Figure 20.9, Russell and Norvig
– Contrast: Q-learning
• Produces estimated action-value function
• No environment model (i.e., no explicit representation of state transitions)
• NB: this includes both exact and approximate (e.g., TD) Q-learning
• Function Q-Learning-Agent: Figure 20.12, Russell and Norvig
• Ramifications: A Debate– Knowledge in model-theoretic approach corresponds to “pseudo-experience” in
TD (see: 20.3, Russell and Norvig; distal supervised learning; phantom induction)
– Dissenting conjecture: model-free methods “reduce need for knowledge”
– At issue: when is it worth while to combine analytical, inductive learning?

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Applying Results of RL:Applying Results of RL:MDP Decision Cycle RevisitedMDP Decision Cycle Revisited
• Function Decision-Theoretic-Agent (Percept)
– Percept: agent’s input; collected evidence about world (from sensors)
– COMPUTE updated probabilities for current state based on available evidence,
including current percept and previous action (prediction, estimation)
– COMPUTE outcome probabilities for actions, given
action descriptions and probabilities of current state (decision model)
– SELECT action with highest expected utility, given
probabilities of outcomes and utility functions
– RETURN action
• Situated Decision Cycle
– Update percepts, collect rewards
– Update active model (prediction and estimation; decision model)
– Update utility function: value iteration
– Selecting action to maximize expected utility: performance element
• Role of Learning: Acquire State Transition Model, Utility Function

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Generalization in RLGeneralization in RL
• Explicit Representation– One output value for each input tuple
– Assumption: functions represented in tabular form for DP
• Utility U: state value, Uh: state vector value
• Transition M: state state action probability
• Reward R: state value, r: state action value
• Action-value Q: state action value
– Reasonable for small state spaces, breaks down rapidly with more states
• ADP convergence, time per iteration becomes unmanageable
• “Real-world” problems and games: still intractable even for approximate ADP
• Solution Approach: Implicit Representation– Compact representation: allows calculation of U, M, R, Q
– e.g., checkers:
• Input Generalization– Key benefit of compact representation: inductive generalization over states
– Implicit representation : RL :: representation bias : supervised learning
brtwbbtwbrkwbbkwbrpwbbpww bV 6543210 ˆ

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Relationship to Dynamic ProgrammingRelationship to Dynamic Programming
• Q-Learning
– Exact version closely related to DP-based MDP solvers
– Typical assumption: perfect knowledge of (s, a) and r(s, a)
– NB: remember, does not mean
• Accessibility (total observability of s)
• Determinism of , r
• Situated Learning
– aka in vivo, online, lifelong learning
– Achieved by moving about, interacting with real environment
– Opposite: simulated, in vitro learning
• Bellman’s Equation [Bellman, 1957]
– Note very close relationship to definition of optimal policy:
– Result: satisfies above equation iff =*
ss,πδγVsπ s,rEsV . Ss **
s,sVmaxargπ* π
π

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Subtle Issues and Subtle Issues and Continuing ResearchContinuing Research
• Current Research Topics– Replace table of Q estimates with ANN or other generalizer
• Neural reinforcement learning (next time)
• Genetic reinforcement learning (next week)
– Handle case where state only partially observable
• Estimation problem clear for ADPs (many approaches, e.g., Kalman filtering)
• How to learn Q in MDPs?
– Optimal exploration strategies
– Extend to continuous action, state
– Knowledge: incorporate or attempt to discover?
• Role of Knowledge in Control Learning– Method of incorporating domain knowledge: simulated experiences
• Distal supervised learning [Jordan and Rumelhart, 1992]
• Pseudo-experience [Russell and Norvig, 1995]
• Phantom induction [Brodie and Dejong, 1998])
– TD Q-learning: knowledge discovery or brute force (or both)?

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
RL Applications:RL Applications:Game PlayingGame Playing
• Board Games
– Checkers
• Samuel’s player [Samuel, 1959]: precursor to temporal difference methods
• Early case of multi-agent learning and co-evolution
– Backgammon
• Predecessor: Neurogammon (backprop-based) [Tesauro and Sejnowski, 1989]
• TD-Gammon: based on TD() [Tesauro, 1992]
• Robot Games
– Soccer
• RoboCup web site: http://www.robocup.org
• Soccer server manual: http://www.dsv.su.se/~johank/RoboCup/manual/
– Air hockey: http://cyclops.csl.uiuc.edu
• Discussions Online (Other Games and Applications)– Sutton and Barto book: http://www.cs.umass.edu/~rich/book/11/node1.html– Sheppard’s thesis: http://www.cs.jhu.edu/~sheppard/thesis/node32.html

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
RL Applications:RL Applications:Control and OptimizationControl and Optimization
• Mobile Robot Control: Autonomous Exploration and Navigation
– USC Information Sciences Institute (Shen et al): http://www.isi.edu/~shen
– Fribourg (Perez): http://lslwww.epfl.ch/~aperez/robotreinfo.html
– Edinburgh (Adams et al): http://www.dai.ed.ac.uk/groups/mrg/MRG.html
– CMU (Mitchell et al): http://www.cs.cmu.edu/~rll
• General Robotics: Smart Sensors and Actuators
– CMU robotics FAQ: http://www.frc.ri.cmu.edu/robotics-faq/TOC.html
– Colorado State (Anderson et al): http://www.cs.colostate.edu/~anderson/res/rl/
• Optimization: General Automation
– Planning
• UM Amherst: http://eksl-www.cs.umass.edu/planning-resources.html
• USC ISI (Knoblock et al) http://www.isi.edu/~knoblock
– Scheduling: http://www.cs.umass.edu/~rich/book/11/node7.html

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
TerminologyTerminology
• Reinforcement Learning (RL)
– Definition: learning policies : state action from <<state, action>, reward>
• Markov decision problems (MDPs): finding control policies to choose optimal
actions
• Q-learning: produces action-value function Q : state action value
(expected utility)
– Active learning: experimentation (exploration) strategies
• Exploration function: f(u, n)
• Tradeoff: greed (u) preference versus novelty (1 / n) preference, aka curiosity
• Temporal Diffference (TD) Learning : constant for blending alternative training estimates from multi-step lookahead
– TD(): algorithm that uses recursive training rule with -estimates
• Generalization in RL
– Explicit representation: tabular representation of U, M, R, Q
– Implicit representation: compact (aka compressed) representation

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Summary PointsSummary Points
• Reinforcement Learning (RL) Concluded– Review: RL framework (learning from <<state, action>, reward>
– Continuing research topics
• Active learning: experimentation (exploration) strategies
• Generalization in RL: made possible by implicit representations
• Temporal Diffference (TD) Learning– Family of algorithms for RL: generalizes Q-learning
– More than one step of lookahead
– Many more TD learning results, applications: [Sutton and Barto, 1998]
• More Discussions Online– Harmon’s tutorial: http://www-anw.cs.umass.edu/~mharmon/rltutorial/
– CMU RL Group: http://www.cs.cmu.edu/Groups/reinforcement/www/
– Michigan State RL Repository: http://www.cse.msu.edu/rlr/
• For More Info– Post to http://www.kddresearch.org web board
– Send e-mail to [email protected], [email protected]

Kansas State University
Department of Computing and Information SciencesCIS 540: Software Engineering
Summary PointsSummary Points
• Control Learning– Learning policies from <state, reward, action> observations
– Objective: choose optimal actions given new percepts and incremental rewards
– Issues
• Delayed reward
• Active learning opportunities
• Partial observability
• Reuse of sensors, effectors
• Q Learning– Action-value function Q : state action value (expected utility)
– Training rule
– Dynamic programming algorithm
– Q learning for deterministic worlds
– Convergence to true Q
– Generalizing Q learning to nondeterministic worlds
• Next Week: More Reinforcement Learning (Temporal Differences)