mpi for scalable computing -...
TRANSCRIPT

MPI for Scalable Computing
Pavan Balaji,1 BillGropp,2 RajeevThakur11ArgonneNationalLaboratory
2UniversityofIllinois

The MPI Part of ATPESC
§ WeassumeeveryonealreadyhassomeMPIexperience
§ WewillfocusmoreonunderstandingMPIconceptsthanoncodingdetails
§ Emphasiswillbeonissuesaffectingscalabilityandperformance
§ Therewillbecodewalkthroughsandhands-onexercises
2

Outline
§ Morning– IntroductiontoMPI
– PerformanceissuesinMPIprograms
– Sourcesofscalabilityproblems
– Avoidingcommunicationdelays• understandingsynchronization
– Minimizingdatamotion• usingMPIdatatypes
– Topicsincollectivecommunication
– Hands-onexercises
§ Afternoon– Usingremotememoryaccessto
avoidextrasynchronizationanddatamotion
– Hands-onexercises
– Hybridprogramming
– Processtopologies
§ Afterdinner
– Hands-onexercises
3

What is MPI?
§ MPIisamessage-passinglibraryinterfacestandard.– Specification,notimplementation– Library,notalanguage– Classicalmessage-passingprogrammingmodel
§ MPI-1wasdefined(1994)byabroadly-basedgroupofparallelcomputervendors,computerscientists,andapplicationsdevelopers.– 2-yearintensiveprocess
§ ImplementationsappearedquicklyandnowMPIistakenforgrantedasvendor-supportedsoftwareonanyparallelmachine.
§ Free,portableimplementationsexistforclustersandotherenvironments(MPICH,OpenMPI)
4

5
Timeline of the MPI Standard§ MPI-1(1994),presentedatSC’93
– Basicpoint-to-pointcommunication,collectives,datatypes,etc
§ MPI-2(1997)– AddedparallelI/O, RemoteMemoryAccess(one-sidedoperations),dynamicprocesses,
threadsupport,C++bindings,…
§ ---- Unchangedfor10years----
§ MPI-2.1(2008)– MinorclarificationsandbugfixestoMPI-2
§ MPI-2.2(2009)– SmallupdatesandadditionstoMPI2.1
§ MPI-3.0(2012)– Majornewfeaturesandadditionsto MPI
§ MPI-3.1(2015)– SmallupdatestoMPI3.0

Important considerations while using MPI
§ Allparallelismisexplicit:theprogrammerisresponsibleforcorrectlyidentifyingparallelismandimplementingparallelalgorithmsusingMPIconstructs
6

Basic MPI Communication
OR
MPI_Recv
MPI_Isend
MPI_Send
MPI_Irecv
MPI_Wait MPI_Wait
7

Web Pointers
§ MPIStandard:http://www.mpi-forum.org/docs/docs.html
§ MPIForum:http://www.mpi-forum.org/
§ MPIimplementations:– MPICH:http://www.mpich.org
– MVAPICH:http://mvapich.cse.ohio-state.edu/
– IntelMPI:http://software.intel.com/en-us/intel-mpi-library/
– MicrosoftMPI:https://msdn.microsoft.com/en-us/library/bb524831%28v=vs.85%29.aspx
– OpenMPI:http://www.open-mpi.org/
– IBMMPI,CrayMPI,HPMPI,THMPI,…
§ SeveralMPItutorialscanbefoundontheweb
8

Tutorial Books on MPI (Released November 2014)
BasicMPI AdvancedMPI,includingMPI-2andMPI-3
9

Understanding MPI Performance on Modern Processors§ MPIwasdevelopedwhenasingleprocessorrequiredmultiplechipsand
mostprocessorsandnodeshadasinglecore.
§ Buildingeffective,scalableapplicationsrequireshavingamodelofhowthesystemexecutes,howitperforms,andwhatoperationsitcanperform– Thisis(roughly)theexecutionmodel forthesystem,alongwithaperformance
model
§ Fordecades,asimplemodelworkedfordesigningandunderstandingMPIprograms– Programscommunicateeitherwithpoint-to-pointcommunication
(send/recv),withaperformancemodelofT=s+rn,wheresislatency(startup)andrisinversebandwidth(rate),orcollectivecommunication
§ Buttoday,processorsaremulti-coreandmanynodesaremulti-chip.– HowdoesthatchangehowwethinkaboutperformanceandMPI?
10

SMP Nodes: One Model
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
NIC
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
NIC
11

Classic Performance Model
§ s +rn– Sometimescalledthe“postalmodel”
§ Modelcombinesoverheadandnetworklatency(s)andasinglecommunicationrate1/rfornbytesofdata
§ Goodfittomachineswhenitwasintroduced
§ ButdoesitmatchmodernSMP-basedmachines?– Let’slookatthethecommunicationrateperprocesswithprocessescommunicatingbetweentwonodes
12

Rates Per MPI Process
§ Ping-pong between2nodesusing1-16coresoneachnode
§ TopisBG/Q,bottomCrayXE6
§ “Classic”modelpredictsasinglecurve– ratesindependentofthenumberofcommunicatingprocesses
Band
width
Band
width
13

Why this Behavior?
§ TheT=s+rnmodelpredictsthesame performanceindependentofthenumberofcommunicatingprocesses– Whatisgoingon?
– Howshouldwemodelthetimeforcommunication?
14

SMP Nodes: One Model
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
NIC
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
MPI Process
NIC
15

Modeling the Communication
§ EachlinkcansupportaraterL ofdata
§ Dataispipelined(LogP model)– Storeandforwardanalysisisdifferent
§ Overheadiscompletelyparallel– kprocessessendingoneshortmessageeachtakesthesametimeasoneprocesssendingoneshortmessage
16

A Slightly Better Model
§ Assumethatthesustainedcommunicationrateislimitedby– Themaximumratealonganysharedlink• ThelinkbetweenNICs
– Theaggregateratealongparallellinks• Eachofthe“links”fromanMPIprocessto/fromtheNIC
0.00E+00
1.00E+09
2.00E+09
3.00E+09
4.00E+09
5.00E+09
6.00E+09
7.00E+09
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
n=256k
n=512k
n=1M
n=2M
Reachedmaximumdatarate
Not doublesingleprocessrate
AggregateBandwidth
17

A Slightly Better Model
§ Forkprocessessendingmessages,thesustainedrateis– min(RNIC-NIC,kRCORE-NIC)
§ Thus– T=s+kn/min(RNIC-NIC,kRCORE-NIC)
§ NoteifRNIC-NIC isverylarge(veryfastnetwork),thisreducesto– T=s+kn/(kRCORE-NIC)=s+n/RCORE-NIC
18

Two Examples
§ Two simplifiedexamples:
Node Node NodeNIC
BlueGene/Q CrayXE6
• Notedifferences:• BG/Q:Multiplepathsintothenetwork• CrayXE6:SinglepathtoNIC(sharedby2nodes)• Multipleprocessesonanodesendingcanexceedtheavailable
bandwidthofthesinglepath
19

The Test
§ Nodecomm discoverstheunderlyingphysicaltopology
§ Performspoint-to-pointcommunication(ping-pong)using1to#corespernodetoanothernode(oranotherchipifanodehasmultiplechips)
§ Outputscommunicationtimefor1 to#coresalongasinglechannel– Notethathardware mayroutesomecommunicationalongalonger
pathtoavoidcontention.
§ Thefollowingresultsusethecodeavailablesoonat– https://bitbucket.org/williamgropp/baseenv
20

How Well Does this Model Work?
§ Testedonawiderangeofsystems:– CrayXE6withGemininetwork– IBMBG/Q– ClusterwithInfiniBand– Clusterwithanothernetwork
§ Resultsin– ModelingMPICommunicationPerformanceonSMPNodes:Isit
TimetoRetirethePingPongTest• WGropp,LOlson,PSamfass• ProceedingsofEuroMPI 16• https://doi.org/10.1145/2966884.2966919
§ CrayXE6resultsfollow
21

Cray: Measured Data
22

Cray: 3 parameter (new) model
23
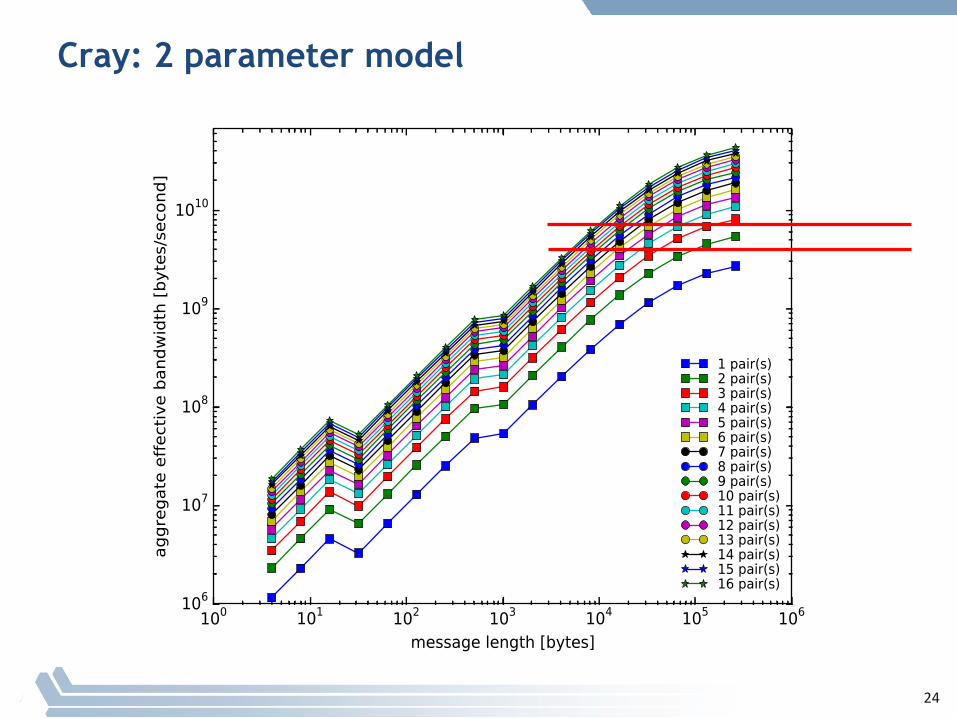
Cray: 2 parameter model
24

Notes
§ BothCrayXE6 andIBMBG/Qhaveinadequatebandwidthtosupporteachcoresendingdataalongthesamelink– ButBG/Q hasmoreindependentlinks,soitisabletosustaina higher
effective“haloexchange”
§ Whataboutothersystems?– Weseethesamebehavioronawidevarietyofsystemsandnetworks
– Many-coresystemsarestronglyaffected…• Testonnextslidefromasimplerversionofthetestcodeavailablefromhttp://wgropp.cs.illinois.edu/mpimesh-0.3.tgz inthecodempingpong
25
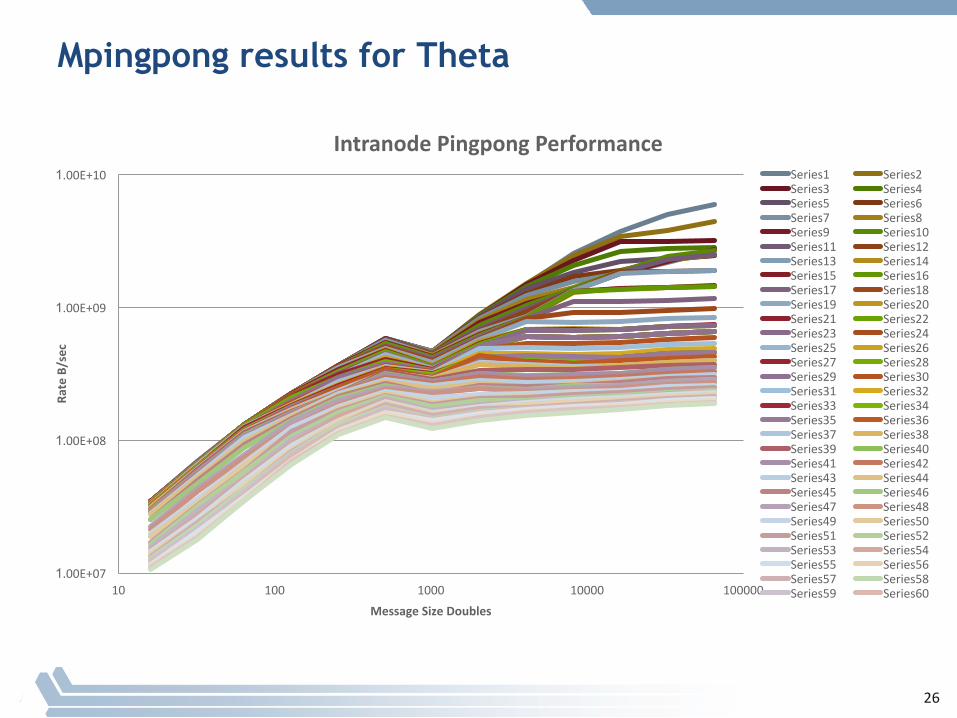
Mpingpong results for Theta
1.00E+07
1.00E+08
1.00E+09
1.00E+10
10 100 1000 10000 100000
RateB/sec
MessageSizeDoubles
IntranodePingpongPerformanceSeries1 Series2Series3 Series4Series5 Series6Series7 Series8Series9 Series10Series11 Series12Series13 Series14Series15 Series16Series17 Series18Series19 Series20Series21 Series22Series23 Series24Series25 Series26Series27 Series28Series29 Series30Series31 Series32Series33 Series34Series35 Series36Series37 Series38Series39 Series40Series41 Series42Series43 Series44Series45 Series46Series47 Series48Series49 Series50Series51 Series52Series53 Series54Series55 Series56Series57 Series58Series59 Series60
26

Modeling Communication
§ Forkprocessessendingmessagesconcurrentlyfromthesamenode,thecorrect(moreprecisely,amuchbetter)timemodelis– T=s+kn/min(RNIC-NIC,kRCORE-NIC)
§ Furthertermsimprovethismodel,butthisoneissufficientformanyuses
27

Costs of Unintended Synchronization
28

Unexpected Hot Spots
§ Evensimpleoperationscangivesurprisingperformancebehavior.
§ Examplesariseevenincommongridexchangepatterns
§ Messagepassingillustratesproblemspresenteveninsharedmemory– Blockingoperationsmaycauseunavoidablestalls
29

Mesh Exchange
§ Exchangedataonamesh
30

Sample Code
§ Doi=1,n_neighborsCallMPI_Send(edge(1,i),len,MPI_REAL,&
nbr(i),tag,comm,ierr)EnddoDoi=1,n_neighborsCallMPI_Recv(edge(1,i),len,MPI_REAL,&
nbr(i),tag,comm,status,ierr)Enddo
31

Deadlocks!
§ Allofthesendsmayblock,waitingforamatchingreceive(willforlargeenoughmessages)
§ Thevariationofif(hasdownnbr)thenCallMPI_Send(…down…)
endifif(hasupnbr)thenCallMPI_Recv(…up…)
endif…sequentializes (allexceptthebottomprocessblocks)
32

Sequentialization
StartSend
StartSend
StartSend
StartSend
StartSend
StartSend
Send Recv
Send Recv
Send Recv
Send Recv
Send Recv
Send Recv
Send Recv
33

Fix 1: Use Irecv
§ Doi=1,n_neighborsCallMPI_Irecv(inedge(1,i),len,MPI_REAL,nbr(i),tag,&
comm,requests(i),ierr)EnddoDoi=1,n_neighborsCallMPI_Send(edge(1,i),len,MPI_REAL,nbr(i),tag,&
comm,ierr)EnddoCallMPI_Waitall(n_neighbors,requests,statuses,ierr)
§ Doesnotperformwellinpractice.Why?
34

Understanding the Behavior: Timing Model
§ Sendsinterleave
§ Sendsblock(datalargerthanbufferingwillallow)
§ Sendscontroltiming
§ ReceivesdonotinterferewithSends
§ Exchangecanbedonein4steps(down,right,up,left)
35

Mesh Exchange - Step 1
§ Exchangedataonamesh
36

Mesh Exchange - Step 2
§ Exchangedataonamesh
37

Mesh Exchange - Step 3
§ Exchangedataonamesh
38
Mesh Exchange - Step 4
§ Exchangedataonamesh
39
Mesh Exchange - Step 5
§ Exchangedataonamesh
40
Mesh Exchange - Step 6
§ Exchangedataonamesh
41

Timeline from IBM SP
• Notethatprocess1finisheslast,aspredicted
42

Distribution of Sends
43

Why Six Steps?
§ OrderingofSendsintroducesdelayswhenthereiscontentionatthereceiver
§ Takesroughlytwiceaslongasitshould
§ Bandwidthisbeingwasted
§ Samethingwouldhappenifusingmemcpyandsharedmemory
44

Fix 2: Use Isend and Irecv
§ Doi=1,n_neighborsCallMPI_Irecv(inedge(1,i),len,MPI_REAL,nbr(i),tag,&
comm,requests(i),ierr)EnddoDoi=1,n_neighborsCallMPI_Isend(edge(1,i),len,MPI_REAL,nbr(i),tag,&
comm,requests(n_neighbors+i),ierr)EnddoCallMPI_Waitall(2*n_neighbors,requests,statuses,ierr)
45

Mesh Exchange - Steps 1-4
§ Fourinterleavedsteps
46

Timeline from IBM SP
Noteprocesses5and6aretheonlyinteriorprocessors;theseperformmorecommunicationthantheotherprocessors
47

Lesson: Defer Synchronization
§ Send-receiveaccomplishestwothings:– Datatransfer
– Synchronization
§ Inmanycases,thereismoresynchronizationthanrequired
§ Considertheuseofnonblocking operationsandMPI_Waitalltodefersynchronization– EffectivenessdependsonhowdataismovedmytheMPI
implementation
– E.g.,IflargemessagesaremovedbyblockingRMAoperations“underthecovers,”theimplementationcan’tadapttocontentionatthetargetprocesses,andyoumayseenobenefit.
– Thisismorelikelywithlargermessages
48

Hotspot results for Theta
1.00E-05
1.00E-04
1.00E-03
1.00E-0210 100 1000 10000 100000
Time/ite
ratio
ninSecs
Edgesizeinwords
2-dMeshExchangeComparison
W-Isend/IrecvW-Send/IrecvNC-Isend/IrecvNC-Send/Irecv
49

Datatypes
50

Introduction to Datatypes in MPI
§ Datatypes allowuserstoserializearbitrary datalayoutsintoamessagestream– Networksprovideserialchannels
– SameforblockdevicesandI/O
§ Severalconstructorsallowarbitrarylayouts– Recursivespecificationpossible
– Declarative specificationofdata-layout• “what”andnot“how”,leavesoptimizationtoimplementation(manyunexplored possibilities!)
– Choosingtherightconstructorsisnotalwayssimple
51

Derived Datatype Example
52

MPI’s Intrinsic Datatypes
§ Whyintrinsictypes?– Heterogeneity,nicetosendaBooleanfromCtoFortran
– Conversionrulesarecomplex,notdiscussedhere
– Lengthmatchestolanguagetypes• Nosizeof(int)mess
§ Usersshouldgenerallyuseintrinsictypesasbasictypesforcommunicationandtypeconstruction!– MPI_BYTEshouldbeavoidedatallcost
§ MPI-2.2addedsomemissingCtypes– E.g.,unsignedlonglong
53

MPI_Type_contiguous
§ Contiguousarrayofoldtype
§ Shouldnotbeusedaslasttype(canbereplacedbycount)
MPI_Type_contiguous(int count, MPI_Datatypeoldtype, MPI_Datatype *newtype)
54

MPI_Type_vector
§ Specifystrided blocksofdataofoldtype
§ VeryusefulforCartesianarrays
MPI_Type_vector(int count, int blocklength, int stride, MPI_Datatype oldtype, MPI_Datatype *newtype)
55

MPI_Type_create_hvector
§ Createnon-unitstrided vectors
§ Usefulforcomposition,e.g.,vectorofstructs
MPI_Type_create_hvector(int count, int blocklength, MPI_Aintstride, MPI_Datatype oldtype, MPI_Datatype *newtype)
56

MPI_Type_indexed
§ Pullingirregularsubsetsofdatafromasinglearray(cf.vectorcollectives)– Dynamiccodeswithindexlists,expensivethough!
– blen={1,1,2,1,2,1}
– displs={0,3,5,9,13,17}
MPI_Type_indexed(int count, int *array_of_blocklengths,int *array_of_displacements, MPI_Datatype oldtype,MPI_Datatype *newtype)
57

MPI_Type_create_indexed_block
§ LikeCreate_indexed butblocklength isthesame
– blen=2
– displs={0,5,9,13,18}
MPI_Type_create_indexed_block(int count, int blocklength,int *array_of_displacements, MPI_Datatype oldtype,MPI_Datatype *newtype)
58

MPI_Type_create_hindexed
§ Indexedwithnon-unitdisplacements,e.g.,pullingtypesoutofdifferentarrays
MPI_Type_create_hindexed(int count, int *arr_of_blocklengths, MPI_Aint *arr_of_displacements, MPI_Datatype oldtype, MPI_Datatype *newtype)
59
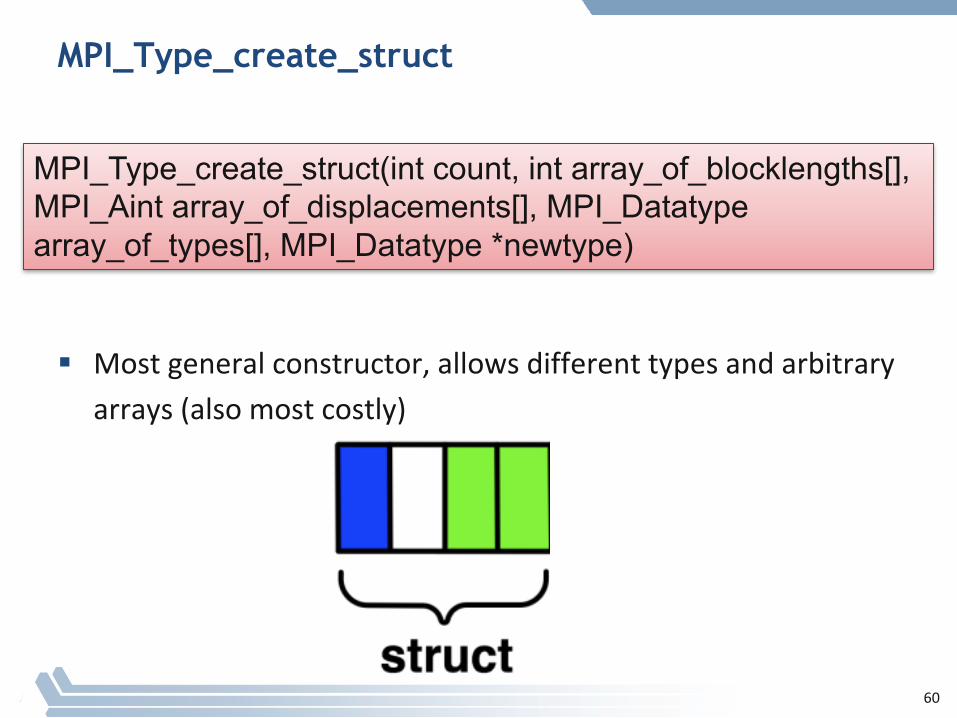
MPI_Type_create_struct
§ Mostgeneralconstructor,allowsdifferenttypesandarbitraryarrays(alsomostcostly)
MPI_Type_create_struct(int count, int array_of_blocklengths[],MPI_Aint array_of_displacements[], MPI_Datatypearray_of_types[], MPI_Datatype *newtype)
60

MPI_Type_create_subarray
§ Specifysubarray ofn-dimensionalarray(sizes)bystart(starts)andsize(subsize)
MPI_Type_create_subarray(int ndims, int array_of_sizes[],int array_of_subsizes[], int array_of_starts[], int order,MPI_Datatype oldtype, MPI_Datatype *newtype)
61

MPI_Type_create_darray
§ Createdistributedarray,supportsblock,cyclicandnodistributionforeachdimension– VeryusefulforI/O
MPI_Type_create_darray(int size, int rank, int ndims,int array_of_gsizes[], int array_of_distribs[], intarray_of_dargs[], int array_of_psizes[], int order,MPI_Datatype oldtype, MPI_Datatype *newtype)
62

MPI_BOTTOM and MPI_Get_address
§ MPI_BOTTOMistheabsolutezeroaddress– Portability(e.g.,maybenon-zeroingloballysharedmemory)
§ MPI_Get_address– ReturnsaddressrelativetoMPI_BOTTOM
– Portability(donotuse“&”operatorinC!)
§ Veryimportantwhen– Buildingstruct datatypes
– Dataspansmultiplearrays
63

Commit, Free, and Dup
§ Typesmustbecommittedbeforeuse– Onlytheonesthatareused!
– MPI_Type_commit mayperformheavyoptimizations(andwillhopefully)
§ MPI_Type_free– FreeMPIresourcesofdatatypes
– Doesnotaffecttypesbuiltfromit
§ MPI_Type_dup– Duplicatesatype
– Libraryabstraction(composability)
64

Other Datatype Functions
§ Pack/Unpack– Mainlyforcompatibilitytolegacylibraries
– Avoidusingityourself
§ Get_envelope/contents– Onlyforexpertlibrarydevelopers
– LibrarieslikeMPITypes1 makethiseasier
§ MPI_Type_create_resized– Changeextentandsize(dangerousbutuseful)
http://www.mcs.anl.gov/mpitypes/
65

Datatype Selection Order
§ Simpleandeffectiveperformancemodel:– Moreparameters==slower
§ contig <vector<index_block <index<struct
§ Some(most)MPIsareinconsistent– Butthisruleisportable
W.Gropp etal.:PerformanceExpectationsandGuidelinesforMPIDerivedDatatypes
66

Datatype Performance in Practice
§ Datatypes can provideperformancebenefits,particularlyforcertainregularpatterns– However,manyimplementationsdonotoptimizedatatype operations
– Ifperformanceiscritical,youwillneedtotest• Evenmanualpacking/unpackingcanbeslowifnotproperlyoptimizedbythecompiler– makesuretocheckoptimizationreportsorifthecompilerdoesn’tprovidegoodreports,inspecttheassemblycode
§ ForparallelI/O,datatypes do providelargeperformancebenefitsinmanycases
67

Collectives and Nonblocking Collectives
68

Introduction to Collective Operations in MPI
§ Collectiveoperationsarecalledbyallprocessesinacommunicator.
§ MPI_BCAST distributesdatafromoneprocess(theroot)toallothersinacommunicator.
§ MPI_REDUCE combinesdatafromallprocessesinthecommunicatorandreturnsittooneprocess.
§ Inmanynumericalalgorithms,SEND/RECV canbereplacedbyBCAST/REDUCE,improvingbothsimplicityandefficiency.
69

MPI Collective Communication
§ Communicationandcomputationiscoordinatedamongagroupofprocessesinacommunicator
§ Tagsarenotused;differentcommunicatorsdeliversimilarfunctionality
§ Non-blockingcollectiveoperationsinMPI-3
§ Threeclassesofoperations:synchronization,datamovement,collectivecomputation
70

Synchronization
§ MPI_BARRIER(comm)
– Blocksuntilallprocessesinthegroupof communicatorcomm callit– Aprocesscannotgetoutofthebarrieruntilallotherprocesseshave
reachedbarrier
§ Notethatabarrierisrarely,ifever,necessaryinanMPIprogram§ Addingbarriers“justtobesure”isabadpracticeandcausesunnecessary
synchronization.Removeunnecessarybarriersfromyourcode.
§ OnelegitimateuseofabarrierisbeforethefirstcalltoMPI_Wtime tostartatimingmeasurement.Thiscauseseachprocesstostartatapproximately thesametime.
§ Avoidusingbarriersotherthanforthis.
71
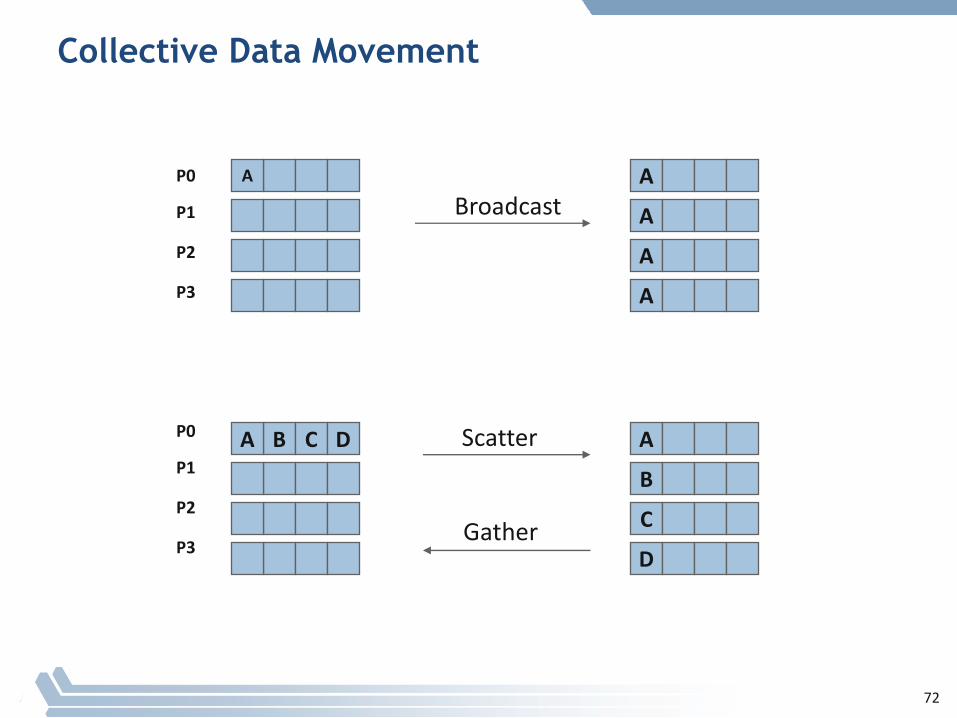
Collective Data Movement
A
B
D
C
B C D
A
A
A
A
Broadcast
Scatter
Gather
A
A
P0
P1
P2
P3
P0
P1
P2
P3
72
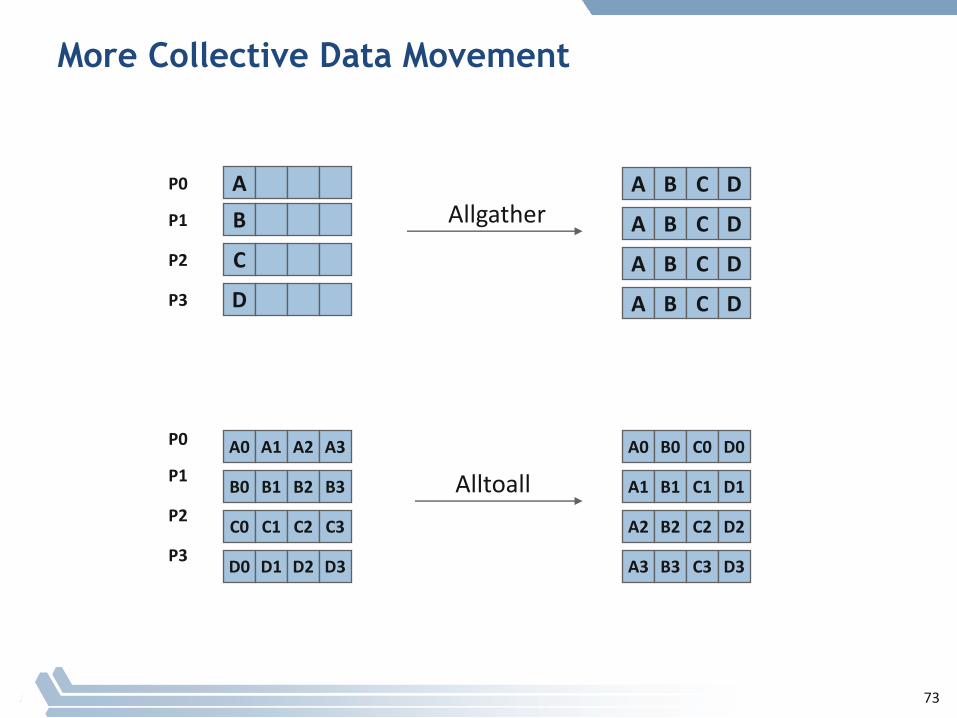
More Collective Data Movement
AB
D
C
A0 B0 C0 D0
A1 B1 C1 D1
A3 B3 C3 D3
A2 B2 C2 D2
A0 A1 A2 A3
B0 B1 B2 B3
D0 D1 D2 D3
C0 C1 C2 C3
A B C D
A B C D
A B C D
A B C D
Allgather
Alltoall
P0
P1
P2
P3
P0
P1
P2
P3
73

Collective Computation
P0P1
P2
P3
P0
P1
P2
P3
A
B
D
C
A
B
D
C
ABCD
AAB
ABC
ABCD
Reduce
Scan
74

MPI Collective Routines
§ ManyRoutines,including:MPI_ALLGATHER, MPI_ALLGATHERV, MPI_ALLREDUCE, MPI_ALLTOALL, MPI_ALLTOALLV, MPI_BCAST, MPI_EXSCAN, MPI_GATHER, MPI_GATHERV, MPI_REDUCE, MPI_REDUCE_SCATTER, MPI_SCAN, MPI_SCATTER, MPI_SCATTERV
§ “All” versionsdeliverresultstoallparticipatingprocesses
§ “V” versions(standsforvector)allowthe chunkstohavedifferentsizes
§ “W” versionsforALLTOALLallowthechunkstohavedifferentsizesinbytes,ratherthanunitsofdatatypes
§ MPI_ALLREDUCE,MPI_REDUCE,MPI_REDUCE_SCATTER,
MPI_REDUCE_SCATTER_BLOCK,MPI_EXSCAN,andMPI_SCANtakebothbuilt-inanduser-definedcombinerfunctions
75

MPI Built-in Collective Computation Operations
§ MPI_MAX§ MPI_MIN§ MPI_PROD§ MPI_SUM§ MPI_LAND§ MPI_LOR§ MPI_LXOR§ MPI_BAND§ MPI_BOR§ MPI_BXOR§ MPI_MAXLOC§ MPI_MINLOC§ MPI_REPLACE,
MPI_NO_OP
MaximumMinimumProductSumLogicalandLogicalorLogicalexclusiveorBitwiseandBitwiseorBitwiseexclusiveorMaximumandlocationMinimumandlocationReplaceandnooperation(RMA)
76

Defining your own Collective Operations
§ Createyourowncollectivecomputationswith:MPI_OP_CREATE(user_fn, commutes, &op);MPI_OP_FREE(&op);
user_fn(invec, inoutvec, len, datatype);
§ Theuserfunctionshouldperform:inoutvec[i] = invec[i] op inoutvec[i];fori from0tolen-1
§ Theuserfunctioncanbenon-commutative,butmustbeassociative
77

Nonblocking Collectives
78

Nonblocking Collective Communication
§ Nonblocking communication– Deadlockavoidance
– Overlappingcommunication/computation
§ Collectivecommunication– Collectionofpre-definedoptimizedroutines
§ Nonblocking collectivecommunication– Combinesbothadvantages
– Systemnoise/imbalanceresiliency
– Semanticadvantages
79

Nonblocking Communication
§ Semanticsaresimple:– Functionreturnsnomatterwhat
– Noprogressguarantee!
§ E.g.,MPI_Isend(<send-args>,MPI_Request *req);
§ Nonblocking tests:– Test,Testany,Testall,Testsome
§ Blockingwait:– Wait,Waitany,Waitall,Waitsome
80

Nonblocking Collective Communication
§ Nonblocking variantsofallcollectives– MPI_Ibcast(<bcast args>,MPI_Request *req);
§ Semantics:– Functionreturnsnomatterwhat– Noguaranteedprogress(qualityofimplementation)– Usualcompletioncalls(wait,test)+mixing– Out-ofordercompletion
§ Restrictions:– Notags,in-ordermatching– Sendandvectorbuffersmaynotbetouchedduringoperation– MPI_Cancel notsupported– Nomatchingwithblockingcollectives
Hoefleretal.:ImplementationandPerformanceAnalysisofNon-BlockingCollectiveOperationsforMPI81

Nonblocking Collective Communication
§ Semanticadvantages:– Enableasynchronousprogression(andmanual)
• Softwarepipelining
– Decoupledatatransferandsynchronization• Noiseresiliency!
– Allowoverlappingcommunicators• Seealsoneighborhoodcollectives
– Multipleoutstandingoperationsatanytime• Enablespipeliningwindow
Hoefleretal.:ImplementationandPerformanceAnalysisofNon-BlockingCollectiveOperationsforMPI82

A Non-Blocking Barrier?
§ Whatcanthatbegoodfor?Well,quiteabit!
§ Semantics:– MPI_Ibarrier()– callingprocessenteredthebarrier,no
synchronizationhappens
– Synchronizationmay happenasynchronously
– MPI_Test/Wait()– synchronizationhappens ifnecessary
§ Uses:– Overlapbarrierlatency(smallbenefit)
– Usethesplitsemantics!Processesnotify non-collectivelybutsynchronize collectively!
83

Nonblocking And Collective Summary
§ Nonblocking comm doestwothings:– Overlapandrelaxsynchronization
§ Collectivecomm doesonething– Specializedpre-optimizedroutines
– Performanceportability
– Hopefullytransparentperformance
§ Theycanbecomposed– E.g.,softwarepipelining
84

Advanced Topics: One-sided Communication

One-sided Communication
§ Thebasicideaofone-sidedcommunicationmodelsistodecoupledatamovementwithprocesssynchronization– Shouldbeabletomovedatawithoutrequiringthattheremote
processsynchronize
– Eachprocessexposesapartofitsmemorytootherprocesses
– Otherprocessescandirectlyreadfromorwritetothismemory
Process 1 Process 2 Process 3
PrivateMemory
PrivateMemory
PrivateMemory
Process 0
PrivateMemory
RemotelyAccessible
Memory
RemotelyAccessible
Memory
RemotelyAccessible
Memory
RemotelyAccessible
Memory
GlobalAddressSpace
PrivateMemory
PrivateMemory
PrivateMemory
PrivateMemory
86

Two-sided Communication Example
MPI implementation
Memory Memory
MPI implementation
Send Recv
MemorySegment
Processor Processor
Send Recv
MemorySegment
MemorySegment
MemorySegment
MemorySegment
87

One-sided Communication Example
MPI implementation
Memory Memory
MPI implementation
Send Recv
MemorySegment
Processor Processor
Send Recv
MemorySegment
MemorySegment
MemorySegment
88
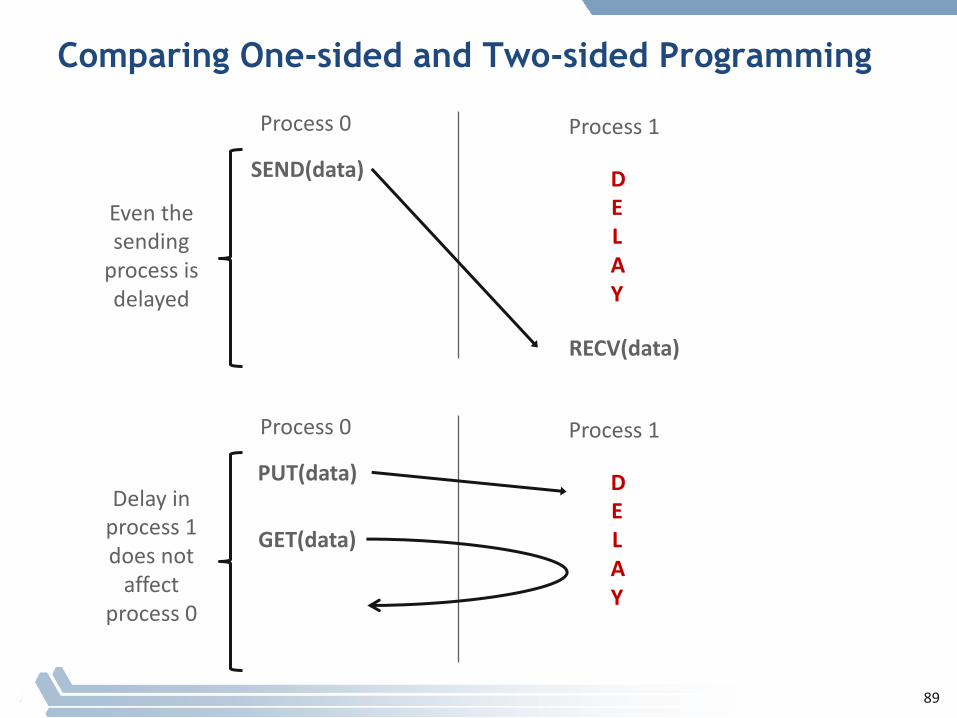
Comparing One-sided and Two-sided Programming
Process0 Process1
SEND(data)
RECV(data)
DELAY
Eventhesendingprocessisdelayed
Process0 Process1
PUT(data) DELAY
Delayinprocess1doesnotaffect
process0
GET(data)
89

What we need to know in MPI RMA
§ Howtocreateremoteaccessiblememory?
§ Reading,WritingandUpdatingremotememory
§ DataSynchronization
§ MemoryModel
90

Creating Public Memory
§ Anymemoryusedbyaprocessis,bydefault,onlylocallyaccessible– X=malloc(100);
§ Oncethememoryisallocated,theuserhastomakeanexplicitMPIcalltodeclareamemoryregionasremotelyaccessible– MPIterminologyforremotelyaccessiblememoryisa“window”
– Agroupofprocessescollectivelycreatea“window”
§ Onceamemoryregionisdeclaredasremotelyaccessible,allprocessesinthewindowcanread/writedatatothismemorywithoutexplicitlysynchronizingwiththetargetprocess
91
Process 1 Process 2 Process 3
PrivateMemory
PrivateMemory
PrivateMemory
Process 0
PrivateMemoryPrivateMemory
PrivateMemory
PrivateMemory
PrivateMemory
window window window window

Window creation models
§ Fourmodelsexist– MPI_WIN_ALLOCATE
• Youwanttocreateabufferanddirectlymakeitremotelyaccessible
– MPI_WIN_CREATE• Youalreadyhaveanallocatedbufferthatyouwouldliketomakeremotelyaccessible
– MPI_WIN_CREATE_DYNAMIC• Youdon’thaveabufferyet,butwillhaveoneinthefuture
• Youmaywanttodynamicallyadd/removebuffersto/fromthewindow
– MPI_WIN_ALLOCATE_SHARED• Youwantmultipleprocessesonthesamenodeshareabuffer
92

MPI_WIN_ALLOCATE
§ CreatearemotelyaccessiblememoryregioninanRMAwindow– OnlydataexposedinawindowcanbeaccessedwithRMAops.
§ Arguments:– size - sizeoflocaldatainbytes(nonnegativeinteger)
– disp_unit - localunitsizefordisplacements,inbytes(positiveinteger)
– info - infoargument(handle)
– comm - communicator(handle)
– baseptr - pointertoexposedlocaldata
– win- window(handle)
93
MPI_Win_allocate(MPI_Aint size, int disp_unit,MPI_Info info, MPI_Comm comm, void *baseptr,MPI_Win *win)

Example with MPI_WIN_ALLOCATE
int main(int argc, char ** argv){
int *a; MPI_Win win;
MPI_Init(&argc, &argv);
/* collectively create remote accessible memory in a window */MPI_Win_allocate(1000*sizeof(int), sizeof(int), MPI_INFO_NULL,
MPI_COMM_WORLD, &a, &win);
/* Array ‘a’ is now accessible from all processes in* MPI_COMM_WORLD */
MPI_Win_free(&win);
MPI_Finalize(); return 0;}
94

MPI_WIN_CREATE
§ ExposearegionofmemoryinanRMAwindow– OnlydataexposedinawindowcanbeaccessedwithRMAops.
§ Arguments:– base - pointertolocaldatatoexpose– size - sizeoflocaldatainbytes(nonnegativeinteger)– disp_unit - localunitsizefordisplacements,inbytes(positiveinteger)– info - infoargument(handle)– comm - communicator(handle)– win- window(handle)
95
MPI_Win_create(void *base, MPI_Aint size, int disp_unit, MPI_Info info,MPI_Comm comm, MPI_Win *win)

Example with MPI_WIN_CREATEint main(int argc, char ** argv){
int *a; MPI_Win win;
MPI_Init(&argc, &argv);
/* create private memory */MPI_Alloc_mem(1000*sizeof(int), MPI_INFO_NULL, &a);/* use private memory like you normally would */a[0] = 1; a[1] = 2;
/* collectively declare memory as remotely accessible */MPI_Win_create(a, 1000*sizeof(int), sizeof(int),
MPI_INFO_NULL, MPI_COMM_WORLD, &win);
/* Array ‘a’ is now accessibly by all processes in* MPI_COMM_WORLD */
MPI_Win_free(&win);MPI_Free_mem(a);MPI_Finalize(); return 0;
}
96

MPI_WIN_CREATE_DYNAMIC
§ CreateanRMAwindow,towhichdatacanlaterbeattached– OnlydataexposedinawindowcanbeaccessedwithRMAops
§ Initially“empty”– Applicationcandynamicallyattach/detachmemorytothiswindowby
callingMPI_Win_attach/detach– Applicationcanaccessdataonthiswindowonlyafteramemory
regionhasbeenattached
§ WindoworiginisMPI_BOTTOM– DisplacementsaresegmentaddressesrelativetoMPI_BOTTOM– Musttellothersthedisplacementaftercallingattach
97
MPI_Win_create_dynamic(MPI_Info info, MPI_Comm comm,MPI_Win *win)

Example with MPI_WIN_CREATE_DYNAMICint main(int argc, char ** argv){
int *a; MPI_Win win;
MPI_Init(&argc, &argv);MPI_Win_create_dynamic(MPI_INFO_NULL, MPI_COMM_WORLD, &win);
/* create private memory */a = (int *) malloc(1000 * sizeof(int));/* use private memory like you normally would */a[0] = 1; a[1] = 2;
/* locally declare memory as remotely accessible */MPI_Win_attach(win, a, 1000*sizeof(int));
/* Array ‘a’ is now accessible from all processes */
/* undeclare remotely accessible memory */MPI_Win_detach(win, a); free(a);MPI_Win_free(&win);
MPI_Finalize(); return 0;}
98

Data movement
§ MPIprovidesabilitytoread,writeandatomicallymodifydatainremotelyaccessiblememoryregions– MPI_PUT
– MPI_GET
– MPI_ACCUMULATE(atomic)
– MPI_GET_ACCUMULATE(atomic)
– MPI_COMPARE_AND_SWAP(atomic)
– MPI_FETCH_AND_OP (atomic)
99

Data movement: Put
§ Movedatafrom origin,to target
§ Separatedatadescriptiontriplesfororigin andtarget
100
Origin
MPI_Put(const void *origin_addr, int origin_count,MPI_Datatype origin_dtype, int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_dtype, MPI_Win win)
Target
RemotelyAccessibleMemory
PrivateMemory

Data movement: Get
§ Movedatato origin,from target
§ Separatedatadescriptiontriplesfororigin andtarget
101
Origin
MPI_Get(void *origin_addr, int origin_count,MPI_Datatype origin_dtype, int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_dtype, MPI_Win win)
Target
RemotelyAccessibleMemory
PrivateMemory

Atomic Data Aggregation: Accumulate
§ Atomicupdateoperation,similartoaput– Reducesoriginandtargetdataintotargetbufferusingopargumentascombiner
– Op=MPI_SUM,MPI_PROD,MPI_OR,MPI_REPLACE,MPI_NO_OP,…
– Predefinedopsonly,nouser-definedoperations
§ Differentdatalayoutsbetweentarget/originOK– Basictypeelementsmustmatch
§ Op=MPI_REPLACE– Implementsf(a,b)=b
– AtomicPUT
102
MPI_Accumulate(const void *origin_addr, int origin_count,MPI_Datatype origin_dtype, int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_dtype, MPI_Op op, MPI_Win win)
Origin Target
RemotelyAccessibleMemory
PrivateMemory
+=

Atomic Data Aggregation: Get Accumulate
§ Atomicread-modify-write– Op=MPI_SUM,MPI_PROD,MPI_OR,MPI_REPLACE,MPI_NO_OP,…– Predefinedopsonly
§ Resultstoredintargetbuffer§ Originaldatastoredinresultbuf§ Differentdatalayoutsbetween
target/originOK– Basictypeelementsmustmatch
§ AtomicgetwithMPI_NO_OP§ AtomicswapwithMPI_REPLACE
103
MPI_Get_accumulate(const void *origin_addr,int origin_count, MPI_Datatype origin_dtype, void *result_addr,int result_count,MPI_Datatype result_dtype, int target_rank, MPI_Aint target_disp,int target_count, MPI_Datatype target_dype, MPI_Op op, MPI_Win win)
+=
Origin Target
RemotelyAccessibleMemory
PrivateMemory

Atomic Data Aggregation: CAS and FOP
§ FOP:SimplerversionofMPI_Get_accumulate– Allbuffersshareasinglepredefineddatatype
– Nocountargument(it’salways1)
– Simplerinterfaceallowshardwareoptimization
§ CAS:Atomicswapiftargetvalueisequaltocomparevalue
104
MPI_Compare_and_swap(const void *origin_addr,const void *compare_addr, void *result_addr,MPI_Datatype dtype, int target_rank,MPI_Aint target_disp, MPI_Win win)
MPI_Fetch_and_op(const void *origin_addr, void *result_addr,MPI_Datatype dtype, int target_rank,MPI_Aint target_disp, MPI_Op op, MPI_Win win)

Ordering of Operations in MPI RMA
§ NoguaranteedorderingforPut/Getoperations§ ResultofconcurrentPutstothesamelocation undefined§ ResultofGetconcurrentPut/Accumulateundefined
– Canbegarbageinbothcases
§ Resultofconcurrentaccumulateoperationstothesamelocationaredefinedaccordingtotheorderinwhichtheoccurred– Atomicput:Accumulatewithop=MPI_REPLACE– Atomicget:Get_accumulate withop=MPI_NO_OP
§ Accumulateoperationsfromagivenprocessareorderedbydefault– UsercantelltheMPIimplementationthat(s)hedoesnotrequireordering
asoptimizationhint– Youcanaskforonlytheneededorderings:RAW(read-after-write),WAR,
RAR,orWAW
105

Examples with operation ordering
106
Process0 Process1
GET_ACC(y,x+=2,P1)
ACC(x+=1,P1) x +=2
x+=1y=2
x=2
PUT(x=2,P1)
GET(y,x,P1)
x=2y=1
x=1
PUT(x=1,P1)
PUT(x=2,P1)
x=1
x=0
x=21.ConcurrentPuts:undefined
2.ConcurrentGetandPut/Accumulates:undefined
3.ConcurrentAccumulateoperationstothesamelocation: orderingisguaranteed

RMA Synchronization Models
§ RMAdataaccessmodel– Whenisaprocessallowedtoread/writeremotelyaccessiblememory?– WhenisdatawrittenbyprocessXisavailableforprocessYtoread?– RMAsynchronizationmodelsdefinethese semantics
§ ThreesynchronizationmodelsprovidedbyMPI:– Fence(activetarget)– Post-start-complete-wait(generalizedactivetarget)– Lock/Unlock(passivetarget)
§ Dataaccessesoccurwithin“epochs”– Accessepochs:containasetofoperationsissuedbyanoriginprocess– Exposureepochs:enableremoteprocessestoupdateatarget’swindow– Epochsdefineorderingandcompletionsemantics– Synchronizationmodelsprovidemechanismsforestablishingepochs
• E.g.,starting,ending,andsynchronizingepochs
107

Fence: Active Target Synchronization
§ Collectivesynchronizationmodel
§ Startsand endsaccessandexposureepochsonallprocessesinthewindow
§ Allprocessesingroupof“win”doanMPI_WIN_FENCEtoopenanepoch
§ EveryonecanissuePUT/GEToperationstoread/writedata
§ EveryonedoesanMPI_WIN_FENCEtoclosetheepoch
§ Alloperationscompleteatthesecondfencesynchronization
108
Fence
Fence
MPI_Win_fence(int assert, MPI_Win win)
P0 P1 P2

Implementing Stencil Computation with RMA Fence
109
Originbuffers
Targetbuffers
RMAwindow
PUT
PUT
PUT
PUT

110
Code Example
§ Codeexamplefromtheexamplesset

PSCW: Generalized Active Target Synchronization
§ LikeFENCE,butoriginandtargetspecifywhotheycommunicatewith
§ Target:Exposureepoch– OpenedwithMPI_Win_post
– ClosedbyMPI_Win_wait
§ Origin:Accessepoch– OpenedbyMPI_Win_start
– ClosedbyMPI_Win_complete
§ Allsynchronizationoperationsmayblock,toenforceP-S/C-Wordering– Processescanbebothoriginsandtargets
111
Start
Complete
Post
Wait
Target Origin
MPI_Win_post/start(MPI_Group grp, int assert, MPI_Win win)MPI_Win_complete/wait(MPI_Win win)

Lock/Unlock: Passive Target Synchronization
§ Passivemode:One-sided,asynchronous communication
– Targetdoesnotparticipateincommunicationoperation
§ Sharedmemory-likemodel
112
ActiveTargetMode PassiveTargetMode
Lock
Unlock
Start
Complete
Post
Wait

Passive Target Synchronization
§ Lock/Unlock:Begin/endpassivemodeepoch– TargetprocessdoesnotmakeacorrespondingMPIcall– Caninitiatemultiplepassivetargetepochstodifferentprocesses– Concurrentepochstosameprocessnotallowed(affectsthreads)
§ Locktype– SHARED:Otherprocessesusingsharedcanaccessconcurrently– EXCLUSIVE:Nootherprocessescanaccessconcurrently
§ Flush:RemotelycompleteRMAoperationstothetargetprocess– Aftercompletion,datacanbereadbytargetprocessoradifferentprocess
§ Flush_local:LocallycompleteRMAoperationstothetargetprocess
MPI_Win_lock(int locktype, int rank, int assert, MPI_Win win)
113
MPI_Win_unlock(int rank, MPI_Win win)
MPI_Win_flush/flush_local(int rank, MPI_Win win)

Advanced Passive Target Synchronization
§ Lock_all:Sharedlock,passivetargetepochtoallotherprocesses– Expectedusageislong-lived:lock_all,put/get,flush,…,unlock_all
§ Flush_all – remotelycompleteRMAoperationstoallprocesses
§ Flush_local_all – locallycompleteRMAoperationstoallprocesses
114
MPI_Win_lock_all(int assert, MPI_Win win)
MPI_Win_unlock_all(MPI_Win win)
MPI_Win_flush_all/flush_local_all(MPI_Win win)

NWChem [1]
§ Highperformancecomputationalchemistryapplicationsuite
§ Quantumlevelsimulationofmolecularsystems– Veryexpensiveincomputationanddata
movement,soisusedforsmallsystems– Largersystemsusemolecularlevelsimulations
§ Composedofmanysimulationcapabilities– MolecularElectronicStructure– QuantumMechanics/MolecularMechanics– PseudopotentialPlane-WaveElectronicStructure– MolecularDynamics
§ Verylargecodebase– 4MLOC;Totalinvestmentof~200M$todate
[1]M.Valiev,E.J.Bylaska,N.Govind,K.Kowalski,T.P.Straatsma,H.J.J.vanDam,D.Wang,J.Nieplocha,E.Apra,T.L.Windus,W.A.deJong,"NWChem:acomprehensiveandscalableopen-sourcesolutionforlargescalemolecularsimulations"Comput.Phys.Commun.181,1477(2010)
Water(H2O)21
CarbonC20
115

NWChem Communication Runtime
ARMCI:CommunicationinterfaceforRMA[3]
GlobalArrays[2]
[2]http://hpc.pnl.gov/globalarrays[3]http://hpc.pnl.gov/armci
ARMCInativeports
IB DMMAP …
MPI RMA
ARMCI-MPI
AbstractionsfordistributedarraysGlobalAddressSpace
Physicallydistributedtodifferentprocesses
Hiddenfromuser
Applications
Irregularlyaccesslargeamountofremotememoryregions
116

Get-Compute-Update
§ TypicalGet-Compute-UpdatemodeinGAprogramming
PerformDGEMMinlocalbuffer
for i in I blocks:for j in J blocks:
for k in K blocks:GET block a from AGET block b from Bc += a * b /*computing*/
end do ACC block c to CNXTASK
end doend do
Pseudocode
ACCUMULATEblockc
GETblockb
GETblocka
Alloftheblocksarenon-contiguousdata
Mockfigureshowing2DDGEMMwithblock-sparsecomputations.Inreality,NWChem uses6Dtensors.
117

Which synchronization mode should I use, when?
§ RMAcommunicationhaslowoverheadsversussend/recv– Two-sided:Matching,queuing,buffering,unexpectedreceives,etc…– One-sided:Nomatching,nobuffering,alwaysreadytoreceive– UtilizeRDMAprovidedbyhigh-speedinterconnects(e.g.InfiniBand)
§ Activemode:bulksynchronization– E.g.ghostcellexchange
§ Passivemode:asynchronousdatamovement– Usefulwhendatasetislarge,requiringmemoryofmultiplenodes– Also,whendataaccessandsynchronizationpatternisdynamic– Commonusecase:distributed,sharedarrays
§ Passivetargetlockingmode– Lock/unlock– Usefulwhenexclusiveepochsareneeded– Lock_all/unlock_all – Usefulwhenonlysharedepochsareneeded
118

MPI RMA Memory Model
§ MPI-3providestwomemorymodels:separateandunified
§ MPI-2:SeparateModel– Logicalpublicandprivatecopies– MPIprovidessoftwarecoherencebetween
windowcopies– Extremelyportable,tosystemsthatdon’t
providehardwarecoherence
§ MPI-3:NewUnifiedModel– Singlecopyofthewindow– Systemmustprovidecoherence– Supersetofseparatesemantics
• E.g.allowsconcurrentlocal/remoteaccess– Providesaccesstofullperformance
potentialofhardware
119
PublicCopy
PrivateCopy
UnifiedCopy
Separate Unified

MPI RMA Memory Model (separate windows)
§ Veryportable,compatiblewithnon-coherentmemorysystems§ Limitsconcurrentaccessestoenablesoftwarecoherence
PublicCopy
PrivateCopy
SamesourceSameepoch Diff.Sources
load store store
X
120
X

MPI RMA Memory Model (unified windows)
§ Allowsconcurrentlocal/remoteaccesses§ Concurrent,conflictingoperationsareallowed(notinvalid)
– OutcomeisnotdefinedbyMPI(definedbythehardware)
§ Canenablebetterperformancebyreducingsynchronization
121
UnifiedCopy
SamesourceSameepoch Diff.Sources
load store store
X

MPI RMA Operation Compatibility (Separate)
Load Store Get Put Acc
Load OVL+NOVL OVL+NOVL OVL+NOVL NOVL NOVL
Store OVL+NOVL OVL+NOVL NOVL X X
Get OVL+NOVL NOVL OVL+NOVL NOVL NOVL
Put NOVL X NOVL NOVL NOVL
Acc NOVL X NOVL NOVL OVL+NOVL
ThismatrixshowsthecompatibilityofMPI-RMAoperationswhentwoormoreprocessesaccessawindowatthesametargetconcurrently.
OVL – OverlappingoperationspermittedNOVL – Nonoverlapping operationspermittedX – CombiningtheseoperationsisOK,butdatamightbegarbage
122

MPI RMA Operation Compatibility (Unified)
Load Store Get Put Acc
Load OVL+NOVL OVL+NOVL OVL+NOVL NOVL NOVL
Store OVL+NOVL OVL+NOVL NOVL NOVL NOVL
Get OVL+NOVL NOVL OVL+NOVL NOVL NOVL
Put NOVL NOVL NOVL NOVL NOVL
Acc NOVL NOVL NOVL NOVL OVL+NOVL
ThismatrixshowsthecompatibilityofMPI-RMAoperationswhentwoormoreprocessesaccessawindowatthesametargetconcurrently.
OVL – OverlappingoperationspermittedNOVL – Nonoverlapping operationspermitted
123

Advanced Topics: Hybrid Programming with Threads, Shared Memory, and Accelerators

Hybrid MPI + X : Most Popular Forms
125AdvancedMPI,Argonne(06/26/2017)
GPU
Memory
CPU
Memory
NetworkCard
MPI+X
CPU
Memory
NetworkCard
CPU
Memory
NetworkCard
CPU
Memory
NetworkCard
CoreCore
MPI+0 MPI+Threads MPI+Shared Memory
MPI+ACC
CoreCore CoreCore
P0 P1P0 P1
MPIProcess
T0 T1

MPI + Threads
126
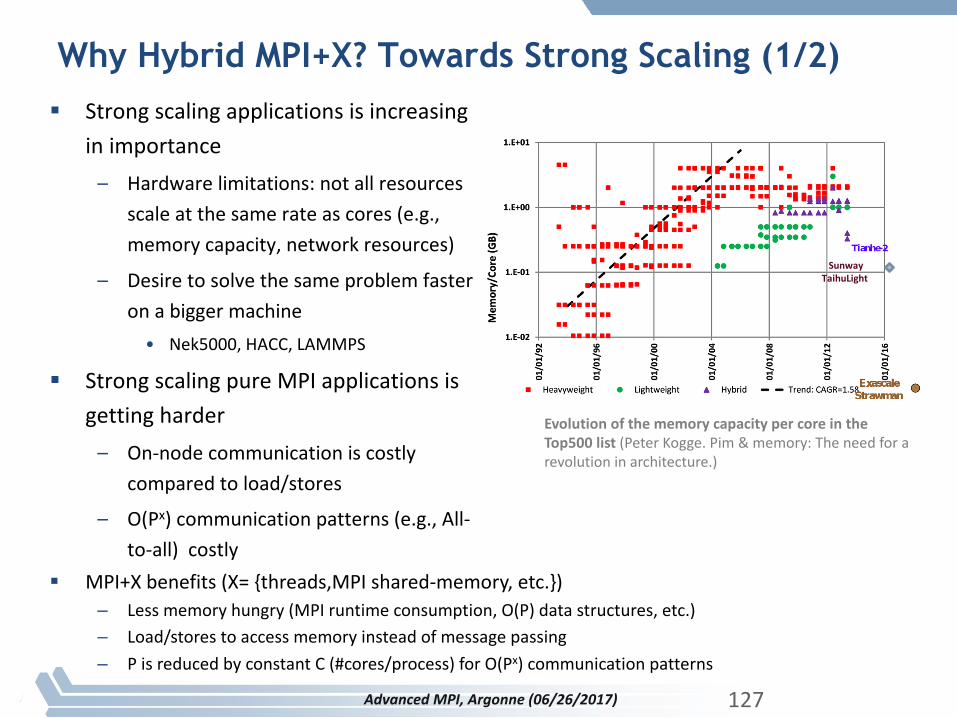
Why Hybrid MPI+X? Towards Strong Scaling (1/2)§ Strongscalingapplicationsisincreasing
inimportance– Hardwarelimitations:notallresources
scaleatthesamerateascores(e.g.,memorycapacity,networkresources)
– Desiretosolvethesameproblemfasteronabiggermachine• Nek5000,HACC,LAMMPS
§ StrongscalingpureMPIapplicationsisgettingharder– On-nodecommunicationiscostly
comparedtoload/stores
– O(Px)communicationpatterns(e.g.,All-to-all)costly
EvolutionofthememorycapacitypercoreintheTop500list(PeterKogge.Pim &memory:Theneedforarevolutioninarchitecture.)
SunwayTaihuLight
§ MPI+Xbenefits(X={threads,MPI shared-memory,etc.})– Lessmemoryhungry(MPIruntimeconsumption,O(P)datastructures,etc.)– Load/storestoaccessmemoryinsteadofmessagepassing– PisreducedbyconstantC(#cores/process)forO(Px)communicationpatterns
127AdvancedMPI,Argonne(06/26/2017)

Why Hybrid MPI+X? Towards Strong Scaling (2/2)
§ Example1:QuantumMonteCarloSimulation(QCMPACK)– Sizeofthephysicalsystemtosimulateisbound
bymemorycapacity[1]– Memoryspacedominatedbylargeinterpolation
tables(typicallyseveralGigaBytesofstorage)– Threadsareusedtosharethosetables– Memoryforcommunicationbuffersmustbe
keptlowtobeallowsimulationoflargerandhighlydetailedsimulations.
§ Example2:theNek5000teamisworkingatthestrongscalinglimit
Nek5000
SharedlargeB-splinetable
W W W W W W
Thread0 Thread1 Thread2
MPIProcess
Core Core Core
CommunicateWalker
information
WWalkerdata
[1] Kim,Jeongnim,etal."HybridalgorithmsinquantumMonteCarlo." JournalofPhysics,2012.
128AdvancedMPI,Argonne(06/26/2017)
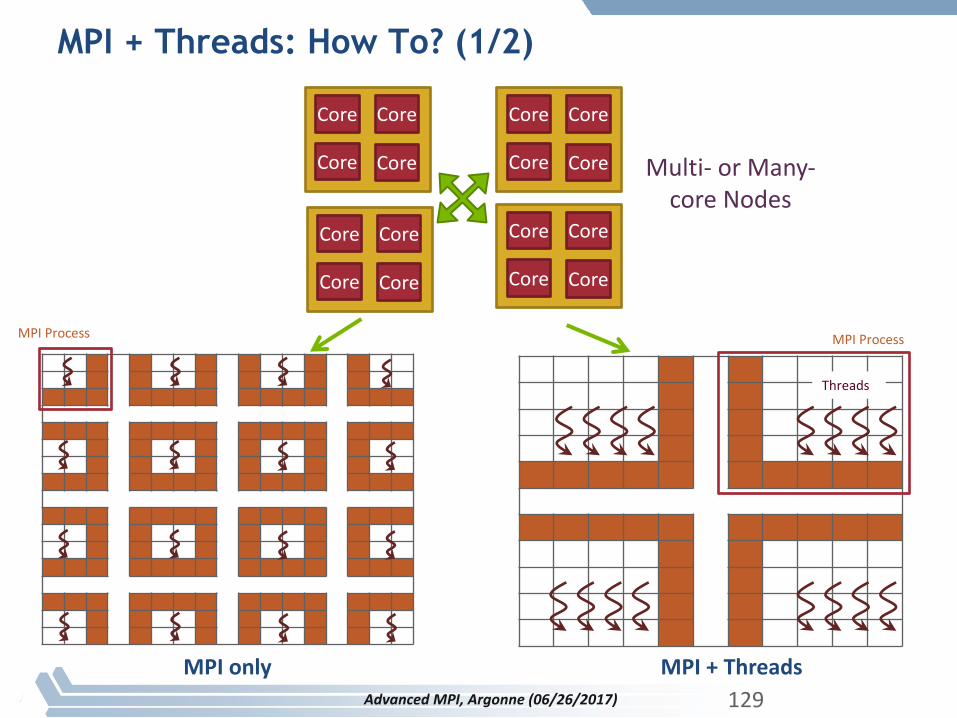
Core
Core Core
Core Core
Core Core
Core
Core
Core Core
Core Core
Core Core
Core
MPIProcess MPIProcess
MPI+ThreadsMPIonly
Threads
Multi- orMany-coreNodes
129
MPI + Threads: How To? (1/2)
AdvancedMPI,Argonne(06/26/2017)

§ MPIdescribesparallelismbetweenprocesses(withseparateaddressspaces)
§ Thread parallelismprovidesashared-memorymodelwithinaprocess
§ OpenMP andPthreads arecommonmodels– OpenMP providesconvenientfeaturesforloop-
levelparallelism.Threadsarecreatedandmanagedbythecompiler,basedonuserdirectives.
– Pthreads providemorecomplexanddynamicapproaches.Threadsarecreatedandmanagedexplicitlybytheuser.
130
MPIProcess
COMP.
COMP.
MPICOMM.
MPIProcess
COMP.
COMP.
MPICOMM.
MPI + Threads: How To? (2/2)

§ MPI_THREAD_SINGLE
– Noadditionalthreads
§ MPI_THREAD_FUNNELED
– Masterthreadcommunicationonly
§ MPI_THREAD_SERIALIZED
– Threadedcommunicationserialized
§ MPI_THREAD_MULTIPLE
– Norestrictions
•Restriction
•LowThread-
SafetyCosts
•Flexibility
•HighThread-
SafetyCosts
131
MPI+ Threads
Interoperability
Interoperationorthreadlevels:
MPI + Threads: How To? (2/2)

MPI’s Four Levels of Thread Safety
§ MPIdefinesfourlevelsofthreadsafety-- thesearecommitmentstheapplicationmakestotheMPI
§ Threadlevelsareinincreasingorder– IfanapplicationworksinFUNNELEDmode,itcanworkinSERIALIZED
§ MPIdefinesanalternativetoMPI_Init– MPI_Init_thread(requested,provided):Applicationspecifieslevelit
needs;MPIimplementationreturnslevelitsupports
132

MPI_THREAD_SINGLE
§ Therearenoadditionaluserthreadsinthesystem– E.g.,therearenoOpenMP parallelregions
int buf[100];int main(int argc, char ** argv){
MPI_Init(&argc, &argv);MPI_Comm_rank(MPI_COMM_WORLD, &rank);
for (i = 0; i < 100; i++)compute(buf[i]);
/* Do MPI stuff */
MPI_Finalize();
return 0;}
133
MPIProcess
COMP.
COMP.
MPICOMM.

MPI_THREAD_FUNNELED
§ AllMPIcallsaremadebythemaster thread– OutsidetheOpenMP parallelregions– InOpenMP masterregions
int buf[100];int main(int argc, char ** argv){
int provided;
MPI_Init_thread(&argc, &argv, MPI_THREAD_FUNNELED, &provided);if (provided < MPI_THREAD_FUNNELED) MPI_Abort(MPI_COMM_WORLD,1);
for (i = 0; i < 100; i++)pthread_create(…,func,(void*)i);
for (i = 0; i < 100; i++)pthread_join();
/* Do MPI stuff */
MPI_Finalize();return 0;
} 134
MPIProcess
COMP.
COMP.
MPICOMM.
void* func(void* arg) {int i = (int)arg;compute(buf[i]);
}

int buf[100];int main(int argc, char ** argv){
int provided;pthread_mutex_t mutex;
MPI_Init_thread(&argc, &argv, MPI_THREAD_SERIALIZED, &provided);if (provided < MPI_THREAD_SERIALIZED) MPI_Abort(MPI_COMM_WORLD,1);
for (i = 0; i < 100; i++)pthread_create(…,func,(void*)i);
for (i = 0; i < 100; i++)pthread_join();
MPI_Finalize();return 0;
}
MPI_THREAD_SERIALIZED
§ Onlyone threadcanmakeMPIcallsatatime– ProtectedbyOpenMP criticalregions
135
MPIProcess
COMP.
COMP.
MPICOMM.
void* func(void* arg) {int i = (int)arg;compute(buf[i]);pthread_mutex_lock(&mutex);/* Do MPI stuff */pthread_mutex_unlock(&mutex);
}

int buf[100];int main(int argc, char ** argv){
int provided;
MPI_Init_thread(&argc, &argv, MPI_THREAD_MULTIPLE, &provided);if (provided < MPI_THREAD_SERIALIZED) MPI_Abort(MPI_COMM_WORLD,1);
for (i = 0; i < 100; i++)pthread_create(…,func,(void*)i);
MPI_Finalize();return 0;
}
void* func(void* arg) {int i = (int)arg;compute(buf[i]);
/* Do MPI stuff */}
MPI_THREAD_MULTIPLE
§ Any threadcanmakeMPIcallsanytime(restrictionsapply)
136
MPIProcess
COMP.
COMP.
MPICOMM.

Threads and MPI
§ AnimplementationisnotrequiredtosupportlevelshigherthanMPI_THREAD_SINGLE;thatis,animplementationisnotrequiredtobethreadsafe
§ Afullythread-safeimplementationwillsupportMPI_THREAD_MULTIPLE
§ AprogramthatcallsMPI_Init (insteadofMPI_Init_thread)shouldassumethatonlyMPI_THREAD_SINGLEissupported– MPIStandardmandatesMPI_THREAD_SINGLEforMPI_Init
§ AthreadedMPIprogramthatdoesnotcallMPI_Init_thread isanincorrectprogram(commonusererrorwesee)
137

MPI Semantics and MPI_THREAD_MULTIPLE
§ Ordering:WhenmultiplethreadsmakeMPIcallsconcurrently,theoutcomewillbeasifthecallsexecutedsequentiallyinsome(any)order– Orderingismaintainedwithineachthread– Usermustensurethatcollectiveoperationsonthesamecommunicator,
window,orfilehandlearecorrectlyorderedamongthreads• E.g.,cannotcallabroadcastononethreadandareduceonanotherthreadonthesamecommunicator
– Itistheuser'sresponsibilitytopreventraceswhenthreadsinthesameapplicationpostconflictingMPIcalls
• E.g.,accessinganinfoobjectfromonethreadandfreeingitfromanotherthread
§ Progress: BlockingMPIcallswillblockonlythecallingthreadandwillnotpreventotherthreadsfromrunningorexecutingMPIfunctions
138

Ordering in MPI_THREAD_MULTIPLE: Incorrect Example with Collectives
Process 0
MPI_Bcast(comm)
MPI_Barrier(comm)
Process 1
MPI_Bcast(comm)
MPI_Barrier(comm)
139
Thread0
Thread1

Ordering in MPI_THREAD_MULTIPLE: Incorrect Example with Collectives
§ P0andP1canhavedifferentorderingsofBcast andBarrier§ Heretheusermustusesomekindofsynchronizationto
ensurethateitherthread1orthread2getsscheduledfirstonbothprocesses
§ Otherwiseabroadcastmaygetmatchedwithabarrieronthesamecommunicator,whichisnotallowedinMPI
Process 0Thread 1 Thread 2
MPI_Bcast(comm)
MPI_Barrier(comm)
140
Process 1Thread 1 Thread 2
MPI_Barrier(comm)
MPI_Bcast(comm)

Ordering in MPI_THREAD_MULTIPLE: Incorrect Example with Object Management
§ Theuserhastomakesurethatonethreadisnotusinganobjectwhileanotherthreadisfreeingit– Thisisessentiallyanorderingissue;theobjectmightgetfreedbefore
itisused
141
Process 0Thread 1 Thread 2
MPI_Comm_free(comm)
MPI_Bcast(comm)

Blocking Calls in MPI_THREAD_MULTIPLE: Correct Example
§ Animplementationmustensurethattheaboveexampleneverdeadlocksforanyorderingofthreadexecution
§ ThatmeanstheimplementationcannotsimplyacquireathreadlockandblockwithinanMPIfunction.Itmustreleasethelocktoallowotherthreadstomakeprogress.
Process 0
MPI_Recv(src=1)
MPI_Send(dst=1)
Process 1
MPI_Recv(src=0)
MPI_Send(dst=0)
Thread 1
Thread 2
142

The Current Situation
§ AllMPIimplementationssupportMPI_THREAD_SINGLE
§ TheyprobablysupportMPI_THREAD_FUNNELEDeveniftheydon’tadmitit.– Doesrequirethread-safetyforsomesystemroutines(e.g.malloc)
– Onmostsystems-pthread willguaranteeit(OpenMP implies
-pthread )
§ Many(butnotall)implementationssupportTHREAD_MULTIPLE– Hardtoimplementefficientlythough(threadsynchronizationissues)
§ Bulk-synchronousOpenMP programs(loopsparallelizedwithOpenMP,communicationbetweenloops)onlyneedFUNNELED– Sodon’tneed“thread-safe”MPIformanyhybridprograms
– ButwatchoutforAmdahl’sLaw!
143

Hybrid Programming: Correctness Requirements
§ HybridprogrammingwithMPI+threads doesnotdomuchtoreducethecomplexityofthreadprogramming– Yourapplicationstillhastobeacorrectmulti-threadedapplication
– Ontopofthat,youalsoneedtomakesureyouarecorrectlyfollowingMPIsemantics
§ ManycommercialdebuggersoffersupportfordebugginghybridMPI+threads applications(mostlyforMPI+PthreadsandMPI+OpenMP)
144

An Example we encountered
§ WereceivedabugreportaboutaverysimplemultithreadedMPIprogramthathangs
§ Runwith2processes
§ Eachprocesshas2threads
§ Boththreadscommunicatewiththreadsontheotherprocessasshowninthenextslide
§ WespentseveralhourstryingtodebugMPICHbeforediscoveringthatthebugisactuallyintheuser’sprogramL
145

2 Proceses, 2 Threads, Each Thread Executes this Code
for(j=0;j<2;j++){
if(rank==1){
for(i=0;i<2;i++)
MPI_Send(NULL,0,MPI_CHAR,0,0,MPI_COMM_WORLD);
for(i=0;i<2;i++)
MPI_Recv(NULL,0,MPI_CHAR,0,0,MPI_COMM_WORLD,&stat);
}
else{/*rank==0*/
for(i=0;i<2;i++)
MPI_Recv(NULL,0,MPI_CHAR,1,0,MPI_COMM_WORLD,&stat);
for(i=0;i<2;i++)
MPI_Send(NULL,0,MPI_CHAR,1,0,MPI_COMM_WORLD);
}
}146

Intended Ordering of Operations
§ Everysendmatchesareceiveontheotherrank
2recvs (T2)2 sends(T2)2 recvs (T2)2 sends(T2)
2recvs (T1)2 sends(T1)2 recvs (T1)2 sends(T1)
Rank0
2sends(T2)2recvs (T2)2sends(T2)2recvs (T2)
2sends(T1)2recvs (T1)2sends(T1)2recvs (T1)
Rank1
147

Possible Ordering of Operations in Practice
§ BecausetheMPIoperationscanbeissuedinanarbitraryorderacrossthreads,allthreadscouldblockinaRECVcall
1 recv (T2)
1recv (T2)
2sends(T2)2 recvs (T2)2 sends(T2)
2recvs (T1)2 sends(T1)1 recv (T1)
1recv (T1)
2sends(T1)
Rank0
2sends(T2)1 recv (T2)
1recv (T2)
2sends(T2)2recvs (T2)
2sends(T1)1 recv (T1)
1recv (T1)
2sends(T1)2recvs (T1)
Rank1
148
MPI+OpenMP correctness semantics
§ ForOpenMP threads,theMPI+OpenMP correctnesssemanticsaresimilartothatofMPI+threads– Caution:OpenMP iterationsneedtobe
carefullymappedtowhichthreadexecutesthem(someschedulesinOpenMP makethisharder)
§ ForOpenMP tasks,thegeneralmodeltouseisthatanOpenMP threadcanexecuteoneormoreOpenMP tasks– AnMPIblockingcallshouldbeassumedto
blocktheentireOpenMP thread,soothertasksmightnotgetexecuted
149
Applications
OpenMP,Cilk,TBB MPI
Pthreadsor otherthreadingpackages

OpenMP threads: MPI blocking Calls (1/2)
150
int main(int argc, char ** argv){
MPI_Init_thread(NULL, NULL, MPI_THREAD_MULTIPLE, &provided);
#pragma omp parallel forfor (i = 0; i < 100; i++) {
if (i % 2 == 0)MPI_Send(.., to_myself, ..);
elseMPI_Recv(.., from_myself, ..);
}
MPI_Finalize();
return 0;}
IterationtoOpenMP threadmappingneedstoexplicitlybehandledbytheuser;otherwise,OpenMP threadsmightallissuethesameoperationanddeadlock

OpenMP threads: MPI blocking Calls (2/2)
151
int main(int argc, char ** argv){
MPI_Init_thread(NULL, NULL, MPI_THREAD_MULTIPLE, &provided);
#pragma omp parallel{
assert(omp_get_num_threads() > 1)#pragma omp for schedule(static, 1)for (i = 0; i < 100; i++) {
if (i % 2 == 0)MPI_Send(.., to_myself, ..);
elseMPI_Recv(.., from_myself, ..);
}}
MPI_Finalize();
return 0;}
Eitherexplicit/carefulmappingofiterationstothreads,orusingnonblockingversionsofsend/recv wouldsolvethisproblem

OpenMP tasks: MPI blocking Calls (1/5)
152
int main(int argc, char ** argv){
MPI_Init_thread(NULL, NULL, MPI_THREAD_MULTIPLE, &provided);
#pragma omp parallel{
#pragma omp forfor (i = 0; i < 100; i++) {
#pragma omp task{if (i % 2 == 0)MPI_Send(.., to_myself, ..);
elseMPI_Recv(.., from_myself, ..);
}}
}MPI_Finalize();return 0;
}
Thiscanleadtodeadlocks.NoorderingorprogressguaranteesinOpenMP taskschedulingshouldbeassumed;ablockedtaskblocksit’sthreadandtaskscanbeexecutedinanyorder.

OpenMP tasks: MPI blocking Calls (2/5)
153
int main(int argc, char ** argv){
MPI_Init_thread(NULL, NULL, MPI_THREAD_MULTIPLE, &provided);
#pragma omp parallel{
#pragma omp taskloopfor (i = 0; i < 100; i++) {
if (i % 2 == 0)MPI_Send(.., to_myself, ..);
elseMPI_Recv(.., from_myself, ..)
}}
MPI_Finalize();return 0;
}
Sameproblemasbefore.

OpenMP tasks: MPI blocking Calls (3/5)
154
int main(int argc, char ** argv){
MPI_Init_thread(NULL, NULL, MPI_THREAD_MULTIPLE, &provided);
#pragma omp parallel{
#pragma omp taskloopfor (i = 0; i < 100; i++) {
MPI_Request req;if (i % 2 == 0)
MPI_Isend(.., to_myself, .., &req);else
MPI_Irecv(.., from_myself, .., &req);MPI_Wait(&req, ..);
}}
MPI_Finalize();return 0;
}
Usingnonblocking operationsbutwithMPI_Wait insidethetaskregiondoesnotsolvetheproblem

OpenMP tasks: MPI blocking Calls (4/5)
155
int main(int argc, char ** argv){
MPI_Init_thread(NULL, NULL, MPI_THREAD_MULTIPLE, &provided);
#pragma omp parallel{
#pragma omp taskloopfor (i = 0; i < 100; i++) {
MPI_Request req; int done = 0;if (i % 2 == 0)
MPI_Isend(.., to_myself, .., &req);else
MPI_Irecv(.., from_myself, .., &req);While (!done) {
#pragma omp taskyieldMPI_Test(&req, &done, ..);
}}
}}
MPI_Finalize();return 0;
}
Stillincorrect;taskyield doesnotguaranteeataskswitch

OpenMP tasks: MPI blocking Calls (5/5)
156
int main(int argc, char ** argv){
MPI_Init_thread(NULL, NULL, MPI_THREAD_MULTIPLE, &provided);MPI_Request req[100];
#pragma omp parallel{
#pragma omp taskloopfor (i = 0; i < 100; i++) {
if (i % 2 == 0)MPI_Isend(.., to_myself, .., &req[i]);
elseMPI_Irecv(.., from_myself, .., &req[i]);
}}
MPI_Waitall(100, req, ..);MPI_Finalize();return 0;
}
Correctexample.Eachtaskisnonblocking.

Ordering in MPI_THREAD_MULTIPLE: Incorrect Example with RMA
157
int main(int argc, char ** argv){
/* Initialize MPI and RMA window */
#pragma omp parallel forfor (i = 0; i < 100; i++) {
target = rand();MPI_Win_lock(MPI_LOCK_EXCLUSIVE, target, 0, win);MPI_Put(..., win);MPI_Win_unlock(target, win);
}
/* Free MPI and RMA window */
return 0;}
Differentthreadscanlockthesameprocesscausingmultiplelockstothesametargetbeforethefirstlockisunlocked

Implementing Stencil Computation using MPI_THREAD_FUNNELED
158

Implementing Stencil Computation using MPI_THREAD_MULTIPLE
159

MPI + Shared-Memory
160

Hybrid Programming with Shared Memory
§ MPI-3allowsdifferentprocessestoallocatesharedmemorythroughMPI– MPI_Win_allocate_shared
§ Usesmanyoftheconceptsofone-sidedcommunication
§ ApplicationscandohybridprogrammingusingMPIorload/storeaccessesonthesharedmemorywindow
§ OtherMPIfunctionscanbeusedtosynchronizeaccesstosharedmemoryregions
§ Canbesimplertoprogramthanthreads
161
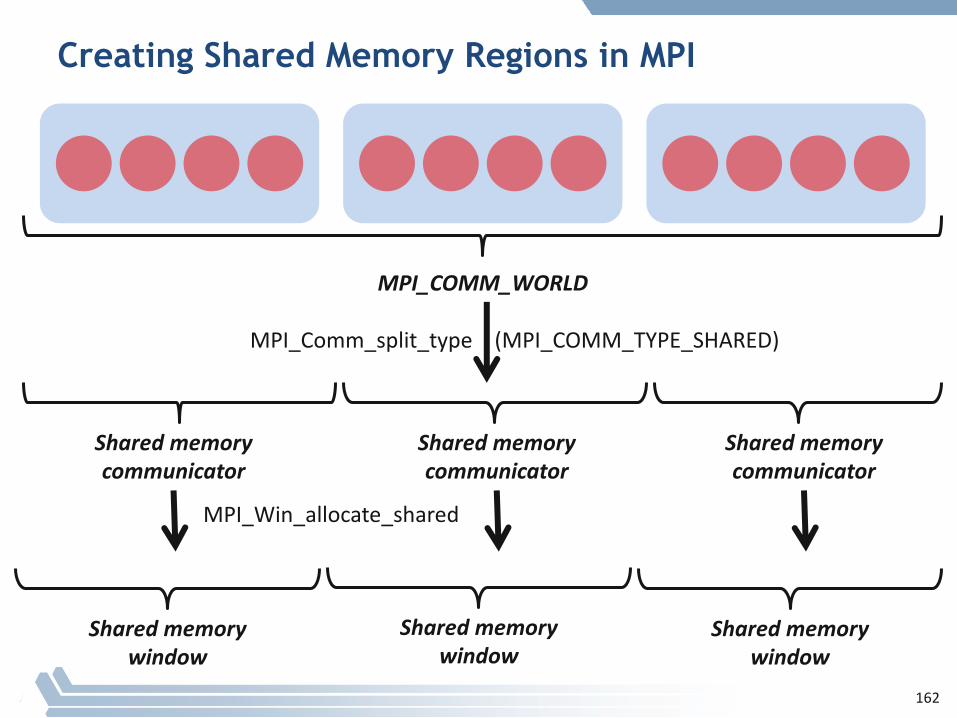
Creating Shared Memory Regions in MPI
MPI_COMM_WORLD
MPI_Comm_split_type (MPI_COMM_TYPE_SHARED)
Sharedmemorycommunicator
MPI_Win_allocate_shared
Sharedmemorywindow
Sharedmemorywindow
Sharedmemorywindow
Sharedmemorycommunicator
Sharedmemorycommunicator
162
Load/store
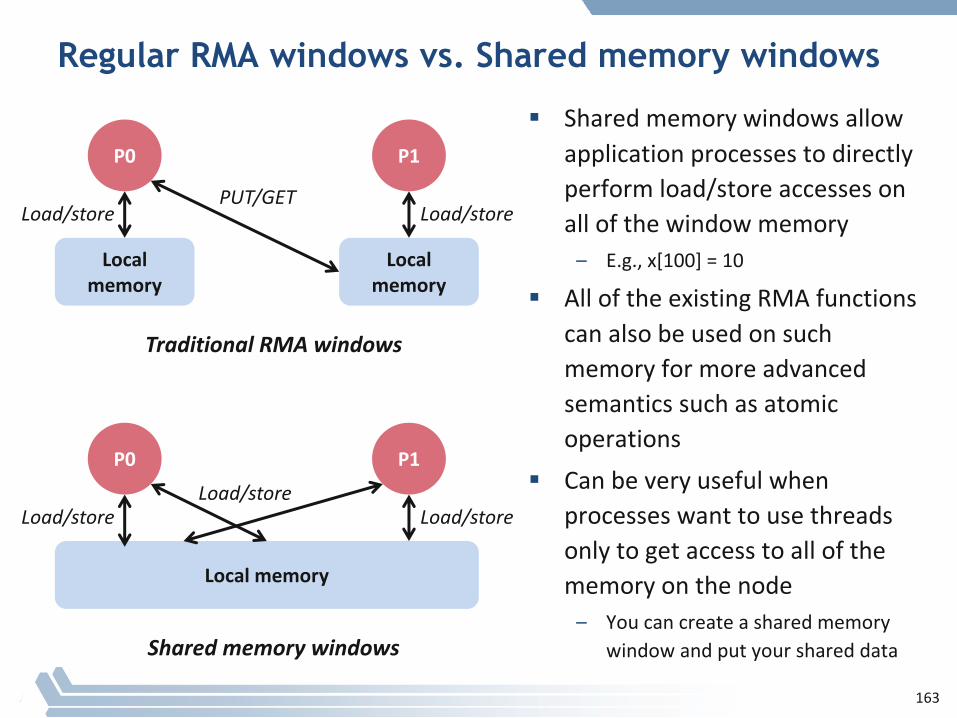
Regular RMA windows vs. Shared memory windows
§ Sharedmemorywindowsallowapplicationprocessestodirectlyperformload/storeaccessesonallofthewindowmemory– E.g.,x[100]=10
§ AlloftheexistingRMAfunctionscanalsobeusedonsuchmemoryformoreadvancedsemanticssuchasatomicoperations
§ Canbeveryusefulwhenprocesseswanttousethreadsonlytogetaccesstoallofthememoryonthenode– Youcancreateasharedmemory
windowandputyourshareddata
Localmemory
P0
Localmemory
P1
Load/storePUT/GET
TraditionalRMAwindows
Load/store
Localmemory
P0 P1
Load/store
Sharedmemorywindows
Load/store
163

MPI_COMM_SPLIT_TYPE
§ Createacommunicatorwhereprocesses“shareaproperty”– Propertiesaredefinedbythe“split_type”
§ Arguments:– comm - inputcommunicator(handle)
– Split_type - propertyofthepartitioning(integer)
– Key - Rankassignmentordering(nonnegativeinteger)
– info - infoargument(handle)
– newcomm- outputcommunicator(handle)
164
MPI_Comm_split_type(MPI_Comm comm, int split_type,int key, MPI_Info info, MPI_Comm *newcomm)

MPI_WIN_ALLOCATE_SHARED
§ CreatearemotelyaccessiblememoryregioninanRMAwindow– DataexposedinawindowcanbeaccessedwithRMAopsorload/store
§ Arguments:– size - sizeoflocaldatainbytes(nonnegativeinteger)
– disp_unit - localunitsizefordisplacements,inbytes(positiveinteger)
– info - infoargument(handle)
– comm - communicator(handle)
– baseptr - pointertoexposedlocaldata
– win- window(handle)
165
MPI_Win_allocate_shared(MPI_Aint size, int disp_unit,MPI_Info info, MPI_Comm comm, void *baseptr,MPI_Win *win)

Shared Arrays with Shared memory windowsint main(int argc, char ** argv){
int buf[100];
MPI_Init(&argc, &argv);MPI_Comm_split_type(..., MPI_COMM_TYPE_SHARED, .., &comm);MPI_Win_allocate_shared(comm, ..., &win);
MPI_Win_lockall(win);
/* copy data to local part of shared memory */MPI_Win_sync(win);
/* use shared memory */
MPI_Win_unlock_all(win);
MPI_Win_free(&win);MPI_Finalize();return 0;
}
166

Memory allocation and placement
§ Sharedmemoryallocationdoesnotneedtobeuniformacrossprocesses– Processescanallocateadifferentamountofmemory(evenzero)
§ TheMPIstandarddoesnotspecifywherethememorywouldbeplaced(e.g.,whichphysicalmemoryitwillbepinnedto)– Implementationscanchoosetheirownstrategies,thoughitis
expectedthatanimplementationwilltrytoplacesharedmemoryallocatedbyaprocess“closetoit”
§ Thetotalallocatedsharedmemoryonacommunicatoriscontiguousbydefault– Userscanpassaninfohintcalled“noncontig”thatwillallowtheMPI
implementationtoalignmemoryallocationsfromeachprocesstoappropriateboundariestoassistwithplacement
167

Example Computation: Stencil
Messagepassingmodelrequiresghost-cellstobeexplicitlycommunicatedtoneighborprocesses
Intheshared-memorymodel,thereisnocommunication.
Neighborsdirectlyaccessyourdata.
168

Which Hybrid Programming Method to Adopt?
§ Itdependsontheapplication,targetmachine,andMPIimplementation
§ WhenshouldIuseprocesssharedmemory?– Theonlyresourcethatneedssharingismemory
– Fewallocatedobjectsneedsharing(easytoplacetheminapublicsharedregion)
§ WhenshouldIusethreads?– Morethanmemoryresourcesneedsharing(e.g.,TLB)
– Manyapplicationobjectsrequiresharing
– Applicationcomputationstructurecanbeeasilyparallelizedwithhigh-levelOpenMP loops
169

Example: Quantum Monte Carlo
WWalkerdata
§ MemorycapacityboundwithMPI-only§ Hybridapproaches
– MPI+threads(e.g.X=OpenMP,Pthreads)– MPI+shared-memory(X=MPI)
§ Canusedirectload/storeoperationsinsteadofmessagepassing
LargeB-splinetable
W W W W
Thread0 Thread1
MPITask1
Core Core
MPI+Threads• Shareeverythingbydefault• Privatizedatawhennecessary
MPI+Shared-Memory(MPI3.0)• Everythingprivatebydefault• Exposeshareddataexplicitly
MPITask1MPITask0
LargeB-splinetableinaShare-MemoryWindow
W
Core
W
Core
WW
170

MPI + Accelerators
171

Accelerators in Parallel Computing
§ Generalpurpose,highlyparallelprocessors– HighFLOPs/WattandFLOPs/$– UnitofexecutionKernel– Separatememorysubsystem– ProgrammingModels:OpenAcc,CUDA,OpenCL,…
§ Clusterswithacceleratorsarebecomingcommon
§ Newprogrammabilityandperformancechallengesforprogrammingmodelsandruntimesystems
172
GPU
Memory
CPU
Memory
NetworkCard

MPI + Accelerator Programming Examples (1/2)
173
GPU
Memory
CPU
Memory
NetworkCard
GPU
Memory
CPU
Memory
NetworkCard
FAQ:HowtomovedatabetweenGPUswithMPI?

MPI + Accelerator Programming Examples (2/2)
174
double *dev_buf, *host_buf;cudaMalloc(&dev_buf, size);cudaMallocHost(&host_buf, size);
if(my_rank == sender) {computation_on_GPU(dev_buf);cudaMemcpy(host_buf, dev_buf, size, …);MPI_Isend(host_buf, size, …);
} else {MPI_Irecv(host_buf, size, …);cudaMemcpy(dev_buf, host_buf, size, …);computation_on_GPU(dev_buf);
}
CUDA
double *buf;buf = (double*)malloc(size * sizeof(double));#pragma acc enter data create(buf[0:size])
if(my_rank == sender) {computation_on_GPU(buf);#pragma acc update host (buf[0:size])MPI_Isend(buf, size, …);
} else {MPI_Irecv(buf, size, …);#pragma acc update device (buf[0:size])computation_on_GPU(buf);
}
Ope
nACC

MPI with Old GPU Technologies
175
GPU
Memory
CPU
Memory
NetworkCard
GPU
Memory
CPU
Memory
NetworkCard
computation_on_GPU(dev_buf);cudaMemcpy(host_buf, dev_buf, size, …);MPI_Isend(host_buf, size, …);
MPI_Irecv(host_buf, size, …);cudaMemcpy(dev_buf, host_buf, size, …);computation_on_GPU(dev_buf);
CUDA
computation_on_GPU(buf);#pragma acc update host (buf[0:size])MPI_Isend(buf, size, …);
MPI_Irecv(buf, size, …);#pragma acc update device (buf[0:size])computation_on_GPU(buf);
Ope
nACC
§ MPIonlyseeshostmemory§ Userhastoensuredatacopiesonhostand
deviceareupdatedconsistently§ Severalmemorycopyoperationsarerequired§ Nooverlappingbetweendevice-hostmemory
transfersandnetworkcommunication§ NoMPIoptimizationopportunities
1 32MPI
Networkpinned/registeredbuffer
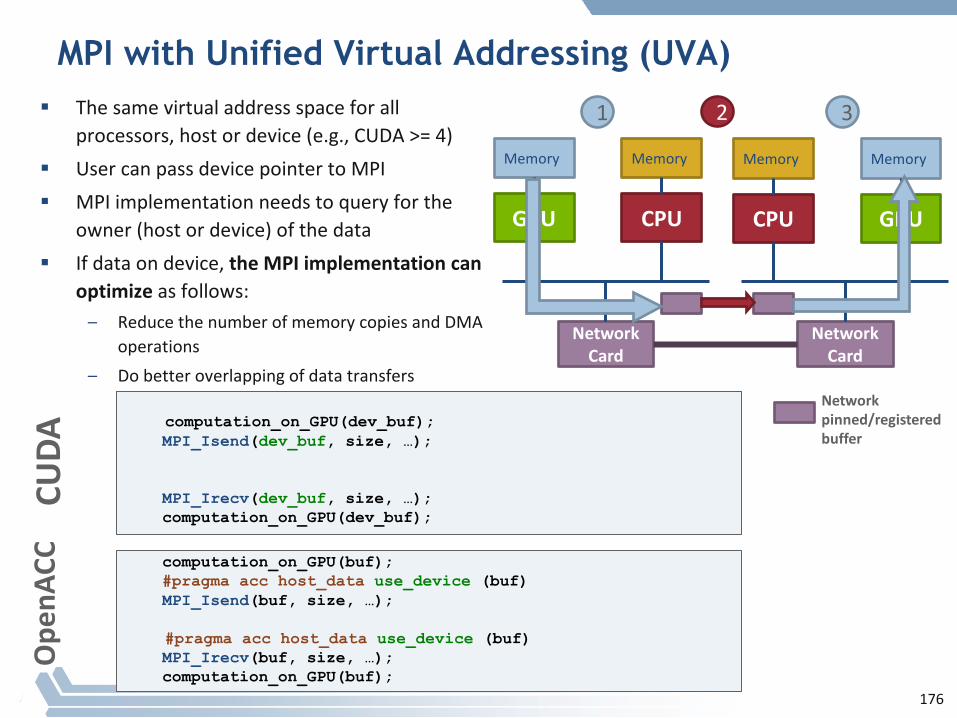
MPI with Unified Virtual Addressing (UVA)
176
GPU
Memory
CPU
Memory
NetworkCard
GPU
Memory
CPU
Memory
NetworkCard
CUDA
computation_on_GPU(buf);#pragma acc host_data use_device (buf)MPI_Isend(buf, size, …);
#pragma acc host_data use_device (buf)MPI_Irecv(buf, size, …);computation_on_GPU(buf);
Ope
nACC
§ Thesamevirtualaddressspaceforallprocessors,hostordevice(e.g.,CUDA>=4)
§ UsercanpassdevicepointertoMPI§ MPIimplementationneedstoqueryforthe
owner(hostordevice)ofthedata§ Ifdataondevice,theMPIimplementationcan
optimize asfollows:– Reducethenumberofmemorycopiesand DMA
operations– Dobetteroverlappingofdatatransfers
1 32
Networkpinned/registeredbuffer
computation_on_GPU(dev_buf);MPI_Isend(dev_buf, size, …);
MPI_Irecv(dev_buf, size, …);computation_on_GPU(dev_buf);

MPI with UVA + GPUDirect
177
GPU
Memory
CPU
Memory
NetworkCard
GPU
Memory
CPU
Memory
NetworkCard
CUDA
Ope
nACC
§ ThehardwaresupportsdirectGPU-to-GPUdatatransferswithinoracrossnodes
§ MPIimplementationsmayusethefollowingoptimizationstotransferdatabetweenGPUs– CanusedirectlyGPUmemoryforRDMA
communication– Peer-to-peerdatatransferswhenGPUsareonthe
samenode
computation_on_GPU(buf);#pragma acc host_data use_device (buf)MPI_Isend(buf, size, …);
#pragma acc host_data use_device (buf)MPI_Irecv(buf, size, …);computation_on_GPU(buf);
computation_on_GPU(dev_buf);MPI_Isend(dev_buf, size, …);
MPI_Irecv(dev_buf, size, …);computation_on_GPU(dev_buf);

Topology Mapping
178

Topology Mapping Basics
§ Firsttype:Allocationmapping(whenjobissubmitted)– Up-frontspecificationofcommunicationpattern
– Batchsystempicksgoodsetofnodesforgiventopology
§ Properties:– Notwidelysupportedbycurrentbatchsystems
– Eitherpredefinedallocation(BG/P),randomallocation,or“globalbandwidthmaximization”
– Alsoproblematictospecifycommunicationpatternupfront,notalwayspossible(orstatic)
179

Topology Mapping Basics contd.
§ Rankreordering– Changenumberinginagivenallocationtoreducecongestionor
dilation
– Sometimesautomatic(earlyIBMSPmachines)
§ Properties– Alwayspossible,buteffectmaybelimited(e.g.,inabadallocation)
– Portableway:MPIprocesstopologies• Networktopologyisnotexposed
– Manualdatashufflingafterremappingstep
180

On-Node Reordering
NaïveMapping OptimizedMapping
Topomap
Gottschling andHoefler:ProductiveParallelLinearAlgebraProgrammingwithUnstructuredTopologyAdaption 181

Off-Node (Network) Reordering
ApplicationTopology NetworkTopology
NaïveMapping OptimalMapping
Topomap
182

MPI Topology Intro
§ Conveniencefunctions(inMPI-1)– Createagraphandqueryit,nothingelse
– UsefulespeciallyforCartesiantopologies• Queryneighborsinn-dimensionalspace
– Graphtopology:eachrankspecifiesfullgraphL
§ ScalableGraphtopology(MPI-2.2)– Graphtopology:eachrankspecifiesitsneighborsor anarbitrary
subsetofthegraph
§ Neighborhoodcollectives(MPI-3.0)– Addingcommunicationfunctionsdefinedongraphtopologies
(neighborhoodofdistanceone)
183

MPI Topology Realities
§ CartesianTopologies– MPI_Dims_create isrequiredtoprovidea“square”decomposition
• Maynotmatchunderlyingphysicalnetwork
• Evenifitdid,hardtodefineunlessphysicalnetworkismeshortorus
– MPI_Cart_create issupposedtoprovidea“good”remapping(ifrequested)• Butimplementationsarepoorandmayjustreturntheoriginalmapping
§ GraphTopologies– Thegeneralprocessmappingproblemisveryhard
– Most(all?)MPIimplementationsarepoor
– Someresearchworkhasdevelopedtoolstocreatebettermappings• YoucanusethemwithMPI_Comm_dup tocreatea“wellordered”communicator
§ Neighborcollectives– MPI3introducedthese;permitcollectivecommunicationwithjustthe
neighborsasdefinedbytheMPIprocesstopology
– OffersopportunitiesfortheMPIimplementationtooptimize;notrealizedyet184

Hotspot results for Theta
1.00E-05
1.00E-04
1.00E-03
1.00E-0210 100 1000 10000 100000
Time/ite
ratio
ninSecs
Edgesizeinwords
2-dMeshExchangeComparison
W-Isend/IrecvW-Send/IrecvNC-Isend/IrecvNC-Send/Irecv
• CommunicatorfromMPI_Cart_create hassameorderasMPI_COMM_WORLD• For2-dmeshexchangewith512processesand64processes/node,MPI_Cart_create
hasanaverageof28targetoff-nodeprocesses.• The“node-cart”communicatorhasanaverageof20targetoff-nodeprocesses
• Communicationtimeis26%fasterwiththehand-optimizedcommunicator
185

MPI_Dims_create
§ CreatedimsarrayforCart_create withnnodes andndims– Dimensionsareascloseaspossible(well,intheory)
§ Non-zeroentriesindimswillnotbechanged– nnodes mustbemultipleofallnon-zeroesindims
MPI_Dims_create(int nnodes, int ndims, int *dims)
186

MPI_Dims_create Example
§ Makeslifealittlebiteasier– Someproblemsmaybebetterwithanon-squarelayoutthough
int p;int dims[3] = {0,0,0};MPI_Comm_size(MPI_COMM_WORLD, &p);MPI_Dims_create(p, 3, dims);
int periods[3] = {1,1,1};MPI_Comm topocomm;MPI_Cart_create(comm, 3, dims, periods, 0, &topocomm);
187

MPI_Cart_create
§ Specifyndims-dimensionaltopology– Optionallyperiodicineachdimension(Torus)
§ SomeprocessesmayreturnMPI_COMM_NULL– Productofdimsmustbe≤P
§ Reorderargumentallowsfortopologymapping– Eachcallingprocessmayhaveanewrankinthecreatedcommunicator
– Datahastoberemappedmanually
MPI_Cart_create(MPI_Comm comm_old, int ndims, const int *dims, const int *periods, int reorder, MPI_Comm *comm_cart)
188

MPI_Cart_create Example
§ Createslogical3-dTorusofsize5x5x5
§ Butwe’restartingMPIprocesseswithaone-dimensionalargument(-pX)– Userhastodeterminesizeofeachdimension
– Oftenas“square”aspossible,MPIcanhelp!
int dims[3] = {5,5,5};int periods[3] = {1,1,1};MPI_Comm topocomm;MPI_Cart_create(comm, 3, dims, periods, 0, &topocomm);
189

Cartesian Query Functions
§ Librarysupportandconvenience!
§ MPI_Cartdim_get()– GetsdimensionsofaCartesiancommunicator
§ MPI_Cart_get()– Getssizeofdimensions
§ MPI_Cart_rank()– Translatecoordinatestorank
§ MPI_Cart_coords()– Translateranktocoordinates
190

Cartesian Communication Helpers
§ Shiftinonedimension– Dimensionsarenumberedfrom0tondims-1
– Displacementindicatesneighbordistance(-1,1,…)
– MayreturnMPI_PROC_NULL
§ Veryconvenient,allyouneedfornearestneighborcommunication
MPI_Cart_shift(MPI_Comm comm, int direction, int disp,int *rank_source, int *rank_dest)
191

Algorithms and Topology
§ Complexhierarchy:– Multiplechipspernode;
differentaccesstolocalmemoryandtointerconnect;multiplecoresperchip
– Meshhasdifferentbandwidthsindifferentdirections
– Allocationofnodesmaynotberegular(youareunlikelytogetacompactbrickofnodes)
– SomenodeshaveGPUs
§ Mostalgorithmsdesignedforsimplehierarchiesandignorenetworkissues
192
14
15
16
17
18
1818.51919.52020.52121.52222.5230
5
10
15
20
25
Recentworkongeneraltopologymappinge.g.,
GenericTopologyMappingStrategiesforLarge-scaleParallelArchitectures,Hoefler andSnir

Dynamic Workloads Require New, More Integrated Approaches
§ Performanceirregularitiesmeanthatclassicapproachestodecompositionareincreasinglyineffective– IrregularitiescomefromOS,runtime,process/threadplacement,
memory,heterogeneousnodes,power/clockfrequencymanagement
§ Staticpartitioningtoolscanleadtopersistentloadimbalances– Meshpartitionershaveincorrectcostmodels,nofeedback
mechanism
– “Regridwhenthingsgetbad”won’tworkifthecostmodelisincorrect;alsocostly
§ Basicbuildingblocksmustbemoredynamicwithoutintroducingtoomuchoverhead
193