multilayer perceptron perceptron.pdf · multilayer perceptron ... input x belongs to c 1....
TRANSCRIPT

Outline
Multilayer Perceptron
Hong Chang
Institute of Computing Technology,Chinese Academy of Sciences
Machine Learning Methods (Fall 2012)
Hong Chang (ICT, CAS) Multilayer Perceptron

Outline
Outline I
1 Introduction
2 Single Perceptron
3 Boolean Function Learning
4 Multilayer Perceptron
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Artificial Neural Network
Cognitive scientists and neuroscientists: the aim is to understand thefunctioning of the brain by building models of the natural neuralnetworks.Machine learning researchers: the aim (more pragmatic) is to buildbetter computer systems based on inspirations from studying thebrain.A human brain has:
Large number (1011) of neurons as processing unitsLarge number (104) of synapses per neuron as memory unitsParallel processing capabilitiesDistributed computation/memoryHigh robustness to noise and failure
Artificial neural networks (ANN) mimic some characteristics of thehuman brain, especially with regard to the computational aspects.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Perceptron
The output f is weighted sum of the inputs x = (x0, x1, . . . , xd )T :
f =d∑
j=1
wjxj + w0 = wT x
where x0 is a special bias unit with x0 = 1 and w = (w0,w1, . . . ,wd )T
are called the connection weights.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
What a Perceptron Does
Regression vs. classification:
To implement a linear discriminant function, we need the thresholdfunction
s(a) ={
1 if a > 00 otherwise
to define the following decision rule:
Choose{
C1 if s(wT x) = 1C2 otherwise
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Sigmoid Function
Instead of using the threshold function to give a discrete output in{0,1}, we may use the sigmoid function
sigmoid(a) =1
1 + exp(−a)
to give a continuous output in (0,1):
f = sigmoid(wT x)
The output may be interpreted as the posterior probability that theinput x belongs to C1.Perceptron is cosmetically similar to logistic regression and leastsquares linear regression.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
K > 2 Outputs
K perceptrons, each with a weight vector wk :
fk =d∑
j=1
wkjxj + w0 = wTk x or f = Wx
where wkj is the weight from input xj to output yk , and each row of theK × (d + 1) matrix W is the weight vector of one perceptron.W performs a linear transformation from a d-dimensional space to aK -dimensional space.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Classification
Classification:Choose Ck if fk = maxl fl
If we need the posterior probabilities as well, we can use softmax todefine fk as:
fk =exp(wT
k x)∑Kl=1 exp(wT
l x)
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Perceptron Learning
Learning mode:Online learning: instances seen one by one.Batch learning: whole sample seen all at once.
Advantages of online learning:No need to store the whole sample.Can adapt to changes in sample distribution over time.Can adapt to physical changes in system components.
The error function is not defined over the whole sample but onindividual instances.Starting from randomly initialized weights, the parameters areadjusted a little bit at each iteration to reduce the error withoutforgetting what was learned previously.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Stochastic Gradient Descent
If the error function is differentiable, gradient descent may be appliedat each iteration to reduce the error.Gradient descent for online learning is also known as stochasticgradient descent.For regression, the error on a single instance (x(i), y (i)):
E(w|x(i), y (i)) =12(y (i) − f (i))2 =
12(y (i) − (wT x(i)))2
which gives the following online update rule:
4w (i)j = η(y (i) − f (i))x (i)
j
where η is a step size parameter which is decreased gradually in timefor convergence.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Binary Classification
Logistic discrimination for a single instance (x(i), y (i)), where y (i) = 1 ifx(i) ∈ C1 and y (i) = 0 if x(i) ∈ C2, gives the output:
f (i) = sigmoid(wT x(i))
Likelihood:L = (f (i))y (i)
(1− f (i))1−y (i)
Cross-entropy error function:
E(w|x(i), y (i)) = − log L = −y (i) log f (i) − (1− y (i)) log(1− f (i))
Online update rule:
4w (i)j = η(y (i) − f (i))x (i)
j
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
K > 2 Classes
Softmax for a single instance (x(i), y (i)), where y (i)k = 1 if x(i) ∈ Ck and
0 otherwise, gives the outputs:
f (i)k =exp(wT
k x(i))∑l exp(wT
l x(i))
Likelihood:L =
∏k
(f (i)k )y (i)k
Cross-entropy error function:
E({wk}|x(i), y (i)) = − log L = −∑
k
y (i)k log f (i)k
Online update rule:
4w (i)kj = η(y (i)
k − f (i)k )x (i)j
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Perceptron Learning Algorithm
For k = 1, . . . ,KFor j = 0, . . . ,d
wkj ← rand(−0.01,0.01)Repeat
For all (xt , y t) ∈ X in random orderFor k = 1, . . . ,K
ok ← 0For j = 0, . . . ,d
ok ← ok + wkjx tj
For k = 1, . . . ,Kfk ← exp(ok )/
∑l exp(ol)
For k = 1, . . . ,KFor j = 0, . . . ,d
wjk ← wjk + η(y tk − fk )x t
jUntil convergence
Update=Learning Factor × (Desired Output - Actual Output) × Input
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Online Learning Error of Perceptron
Theorem (Block, 1962, and Novikoff, 1962)
Let a sequence of examples (x(1), y (1)), . . . , (x(N), y (N)) be given. Supposethat ‖x(i)‖ ≤ M for all i , and further that there exists a unit-length vector u(‖u‖2 = 1) such that y (i) · (uT x(i)) ≥ γ for all examples in the sequence(i.e., uT x(i) ≥ γ if y (i) = 1 and uT x(i) ≤ −γ if y (i) = −1, so that u separatesthe data with a margin of at least γ). Then the total number of mistakesthat the perceptron algorithm makes on this sequence is at most (M/γ)2.
Given a training example (x, y) (y ∈ {−1,1}), the perceptron learningrule updates the parameters as follows: If fθ(x) = y , then it makes nochange to the parameters. Otherwise, θ ← θ + yx.Note that bound on the number of errors does not have an explicitdependence on the number of examples N in the sequence, or on thedimension d of the inputs.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Convergence of Perceptron
Perceptron convergence theorem:If there exists an exact solution (i.e., if the training data set is linearlyseparable), then the perceptron learning algorithm is guaranteed tofind an exact solution in finite number of steps.The number of steps required to achieve convergence could still besubstantial.For linearly separable data set, there may be many solutions.For linearly nonseparable data set, the perceptron algorithm will neverconverge.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Illustration of Convergence of Perceptron
−1 −0.5 0 0.5 1−1
−0.5
0
0.5
1
−1 −0.5 0 0.5 1−1
−0.5
0
0.5
1
−1 −0.5 0 0.5 1−1
−0.5
0
0.5
1
−1 −0.5 0 0.5 1−1
−0.5
0
0.5
1
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Learning Boolean AND
Learning a Boolean function is a two-class classification problem.AND function with 2 inputs and 1 output:
x1 x2 y0 0 00 1 01 0 01 1 1
Perceptron for AND and its geometric interpretation:
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Learning Boolean XOR
A simple perceptron can only learn linearly separable Booleanfunctions such as AND and OR but not linearly nonseparablefunctions such as XOR.XOR function with 2 inputs and 1 output:
x1 x2 y0 0 00 1 11 0 11 1 0
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Learning Boolean XOR (2)
There do not exist w0,w1,w2 that satisfy the following inequalities:
w0 ≤ 0w2 + w0 > 0w1 + w0 > 0
w1 + w2 + w0 ≤ 0
The VC dimension of a line in 2-D is 3. With 2 binary inputs there are4 cases, so there exist problems with 2 inputs that are not solvableusing a line.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Multilayer Perceptrons
A multilayer perceptron (MLP) has a hidden layer between the inputand output layers.MLP can implement nonlinear discriminants (for classification) andnonlinear regression functions (for regression).We call this a two-layer network because the input layer performs nocomputation.
Hong Chang (ICT, CAS) Multilayer Perceptron
Introduction Single Perceptron Boolean Function Learning MLPs
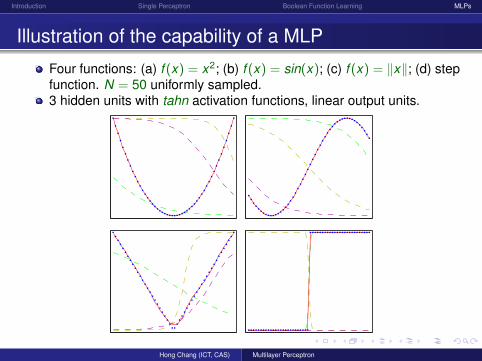
Illustration of the capability of a MLP
Four functions: (a) f (x) = x2; (b) f (x) = sin(x); (c) f (x) = ‖x‖; (d) stepfunction. N = 50 uniformly sampled.3 hidden units with tahn activation functions, linear output units.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Forward Propagation
Input-to-hidden:
zh = sigmoid(wTh x) =
1
1 + exp[−(∑d
j=1 whjxj + wh0)]
The hidden units must implement a nonlinear function (e.g., sigmoid orhyperbolic tangent) or else it is equivalent to a simple perceptron.Sigmoid can be seen as a continuous, differentiable version ofthresholding.
Hidden-to-output:
fk = vTk z =
H∑h=1
vkhzh + vk0
Regression: linear output units.Classification: a sigmoid unit (for K = 2) or K output units with softmax(for K > 2).
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Forward Propagation (2)
The hidden units make a nonlinear transformation from thed-dimensional input space to the H-dimensional space spanned bythe hidden units.In the new H-dimensional space, the output layer implements a linearfunction.Multiple hidden layers may be used for implementing more complexfunctions of the inputs, but learning the network weights in such deepnetworks will be more complicated.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
MLP for XOR
Any Boolean function can be represented as a disjunction ofconjunctions, e.g.,
x1 XOR x2 = (x1 AND ∼ x2) OR (∼ x1 AND x2)
which can be implemented by an MLP with one hidden layer.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
MLP as a Universal Approximator
The result for arbitrary Boolean functions can be extended to thecontinuous case.Universal approximation:An MLP with one hidden layer can approximate any nonlinear functionof the input given sufficiently many hidden units.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Backpropagation Learning Algorithm
Extension of the perceptron learning algorithm to multiple layers byerror backpropagation from the outputs back to the inputs:
Learning of hidden-to-output weights: like perceptron learning by treatingthe hidden units as inputs.Learning of the input-to-hidden weights: applying the chain rule tocalculate the gradient:
∂E∂whj
=∂E∂fk
∂fk∂zh
∂zh
∂whj
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
MLP Learning for Nonlinear Regression
Assuming a single output:
f (i) = f (x(i)) =H∑
h=1
vhz(i)h + v0
where z(i)h = sigmoid(wT
h x(i)).Error function over entire sample:
E(W,v|X ) = 12
∑i
(y (i) − f (i))2
Update rule for second-layer weights:
4vh = η∑
i
(y (i) − f (i))z(i)h
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
MLP Learning for Nonlinear Regression (2)
Update rule for first-layer weights:
4whj = −η ∂E∂whj
= −η∑
i
∂E∂f (i)
∂f (i)
∂z(i)h
∂z(i)h
∂whj
= η∑
i
(y (i) − f (i))vhz(i)h (1− z(i)
h )x (i)j
(y (i) − f (i))vh acts like the error term for hidden unit h, which isbackpropagated from the output to the hidden unit with the weight vhreflecting the responsibility of the hidden unit.Either batch learning or online learning may be carried out.
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Example
Evolution of regression function and error over time
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
MLP Learning for Nonlinear Multiple-OutputRegression
Outputs:
f (i)k =H∑
h=1
vkhz(i)h + vk0
Error function:
E(W,V|X ) = 12
∑i
∑k
(y (i)k − f (i)k )2
Update rule for second-layer weights:
4vkh = η∑
i
(y (i)k − f (i)k )z(i)
h
Update rule for first-layer weights:
4whj = η∑
i
[∑k
(y (i)k − f (i)k )vkh
]z(i)
h (1− z(i)h )x (i)
j
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
Algorithm
Initialize all vkh and whj to rand(−0.01,0.01)Repeat
For all (xt , y t) ∈ X in random orderFor h = 1, . . . ,H
zh ← sigmoid(wTh xt)
For k = 1, . . . ,Kfk = vT
k zFor k = 1, . . . ,K
4vk = η(y tk − f t
k )zFor h = 1, . . . ,H
4wh = η(∑
k (ytk − f t
k )vkh)zh(1− zh)xt
For k = 1, . . . ,Kvk ← vk +4vk
For h = 1, . . . ,Hwh ← wh +4wh
Until convergence
Hong Chang (ICT, CAS) Multilayer Perceptron

Introduction Single Perceptron Boolean Function Learning MLPs
MLP Learning for Nonlinear Multi-Class Discrimination
Outputs:
f (i)k = fk (x(i)) =exp(o(i)
k )∑l exp(o(i)
l )
which approximate the posterior probabilities P(Ck |x(i)), whereo(i)
k =∑H
h=1 vkhz(i)h + vk0.
Error function:
E(W,V|X ) = −∑
i
∑k
y (i)k log f (i)k
Update rules:
4vkh = η∑
i
(y (i)k − f (i)k )z(i)
h
4whj = η∑
i
[∑k
(y (i)k − f (i)k )vkh
]z(i)
h (1− z(i)h )x (i)
j
Hong Chang (ICT, CAS) Multilayer Perceptron