nagios in the agile / devops / continuous deployment world kishore jalleda director of operations...
TRANSCRIPT

Nagios in the Agile / DevOps / Continuous Deployment World
Kishore Jalleda
Director of Operations
IMVU, Inc

22012
About IMVU

3
About IMVU
Avatar based Social Entertainment destination
$50+ Million Annual Revenue
100+ Million Registered Users
10+ Million Items in Virtual Catalog
2012

42012
IMVU Engineering and Continuous Deployment
►Doing the Impossible 50 times a day
►Continuous deployment (CD) is real
►IMVU has been one of the pioneers of CD
►DevOps culture is big
►No approval needed to ship to 1% of customers
Check out our engineering blog http://engineering.imvu.com/

52012
What does this mean ?
►Things change quickly
►New features add up instantly
►Can break frequently
►Failures can cascade rapidly
►Things can fall through the cracks
►Many things change at the same time
►Etc

Insights into Nagios @IMVU

72012
Overview
►Nagios Core 3.2.0
►800+ Hosts
►18000+ Service Checks
►Single Nagios Instance
►8 cores, 8GB RAM

2012 8
Server Lifecycle Management
Purchase & Asset
Management
DHCP,
DNSPreseed,
CFEngine Opspush Nagios,
Cacti, Istatd CFEngine Production Decommissi
on

[ Operations ] Continuous Integration and Deployment
2012 9

102012
IMVU Asset Database ( AssetDB )
►Built internally by IMVU
►Simple but powerful concept
►Source of truth for everything asset related
►Has information on
►Class ( mysql, standard-http-server, redis )
►Role ( customer shard, clientdynweb )
►Tag (available, no-update )
►Attributes (cpu-cores, memory-size, mysql-role )
►Much more …

112012
Auto generation of Nagios configuration files
#generate_nagios_conf.pl
( most configurations auto generated from AssetDB )

122012
Ops Buildbot ( builds, builders/buildslaves )
# svn commit hosts.cfg hostgroups.cfg

132012
Opspush ( Operations Push System )
# opspush --comment “xxxxxx” –role nagios
opspush
check status of “last build”
run “cfagent -v” on the box
--oncall-override ?
green
red
exit
yes
No
--use-last-green-rev
2012 14
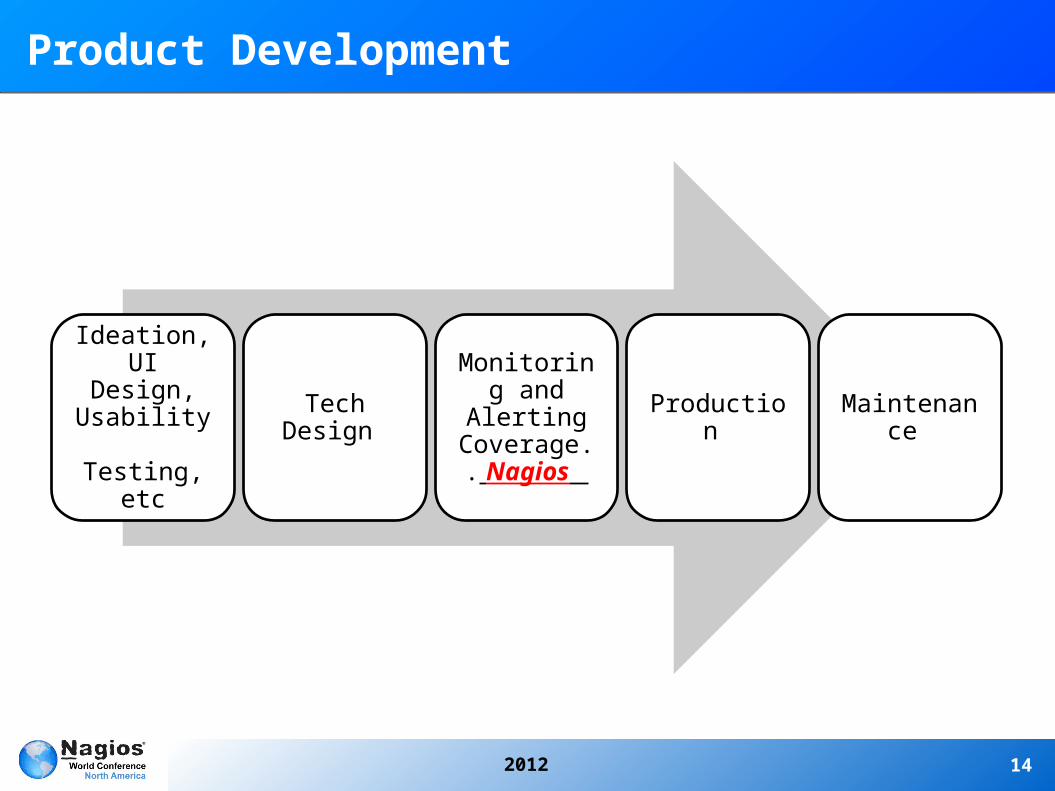
Product Development
Ideation, UI Design,
Usability Testing, etc
Tech Design
Monitoring and Alerting
Coverage.. Nagios
Production Maintenance

15
Tech Designs & New Nagios Alert Requests
2012

16
Nagios Alert Request Template
2012

172012
Big Data / De-Sharding
► Data freshness is critical to help make the right business decisions
► Nagios used for ETL/DW status and error checking
► Nagios and Ops embeds can help empower your Data Infrastructure team

Things will FAIL
2012 18

2012 19
How we try to prevent and catch failures
Local Acceptance
Tests Hypo Builds Buildbot
Automated Cluster
Immunity (CI)
Manual QA using roll-out Nagios
3rd party like webmetrics, customers,
etc

Push to X% of
servers
Monitor Critical Metrics
Push to rest
Auto Rollback
Good
Bad
w00t!, my change is
Live
Monitor Critical Metrics
Bad
Good
Cluster Immune System
Automated push monitoring and rollback !

Don’t just rely on Standard Metrics
2012

222012
Demystifying P1s ( Priority 1 )
P1: Priority 1 issue impacting live operations
Phases
► Identification (Nagios )
► Communication and Declaration
► Resolution
► Postmortem / 5 Whys / Root Cause Analysis
► P1 follow up

232012
5 Why / Postmortem (PM) / Root Cause Analysis
► 5 Why process
► Amazing culture of running blameless postmortems
► New Nagios checks are the most common action Items .
► A lot of monitoring and alerting on business and application level metrics was originally the outcome of PMs

242012
Example “5 Whys” Process

252012
Monitor Business & Application Level Metrics

262012
Monitor Response Times
Load Average is a meaningless number

272012
Continuous Monitoring ( Istatd )
► Developed by IMVU
► Sub 10 sec resolution of data
► API to get average, SD, min, max sample count for each data point in a graph
► Ability to stack multiple graphs on the fly
► Long retention times
► Releasing as open source this week !!!
https://github.com/imvu-open/istatd/wiki

282012
Istatd: 10 Second Resolution of Data

292012
Istatd: Stacking graphs on the fly

Have a “Strategy” for Monitoring and Alerting

312012
Our (Nagios) Strategy
► Human element of Monitoring and Alerting ( Nagios )
► Nagios & Test Driven Development ( TDD )
► Decouple ( Nagios )
► Aggregated Checks

322012
Human Element of Monitoring and Alerting
► Have zero tolerance towards False Positives. You do not want your ops staff to walk into the office next AM looking like zombies ;)
► Do not let people develop immunity to pages as very soon real issues will be ignored
► All pages are Actionable policy: If there is no action, it should not be paging
► Automatic enabling of alerting/notifications for improperly silenced ones.
► Ownership and accountability of issues/alerts

332012
Daily Triage of Nagios Alerts and Interrupts

342012
Nagios & Test Driven Development (TDD)
► Write tests for your Nagios Infrastructure
► Adopted heavily by Ops ( imp to keep pace with eng, DevOps culture is awesome )
► High degree of confidence in pushing changes
► Things will eventually change ( OS, libraries, logic, people, Nagios version, etc ). Tests will make the change much smoother.
► Functional testing can still be a challenge

352012
Sample Nagios Test Output

362012
Decouple Nagios
We do it using “Fact, Worker, Reporter & Aggregator” Model
Worker
Redis
Reporter
Aggregator
fact
fact
fact status
fact status

372012
Why Decouple ?
For scalability and efficiency
Our model was higher performing compared to NRPE
Lets you make changes ( like thresholds ) in one place instead of on like a 1000 machines ( if using NRPE )
Lets you do aggregated checks, which is again a very simple but powerful concept to reduce paging levels by a ton

Closing Remarks

392012
Closing Remarks
► Monitoring and Alerting (M&A) is mission critical for any business, invest properly and smartly in it
► Don’t limit the usage of Nagios to just Ops. The secret to wide spread adoption is to make things frictionless
► Bathroom breaks can take 5-10 minutes, so don’t fret too much about Nagios performance
► Build some form of predictive monitoring and alerting to catch and alert on change in trends
► Invest in configuration automation, validation and compliance
► Finally, Nagios has been like a Honda, very reliable !!!

Questions ?

412012
Thank You !!!
We are Hiring: imvu.com/jobs
Engineering Blog: http://engineering.imvu.com/