naïve bayes advanced statistical methods in nlp ling572 january 19, 2012 1
TRANSCRIPT

1
Naïve Bayes
Advanced Statistical Methods in NLPLing572
January 19, 2012

2
RoadmapNaïve Bayes
Multi-variate Bernoulli event model (recap)Multinomial event modelAnalysis
HW#3

3
Naïve Bayes Models in Detail
(McCallum & Nigam, 1998)
Alternate models for Naïve Bayes Text Classification
Multivariate Bernoulli event modelBinary independence model
Features treated as binary – counts ignored
Multinomial event modelUnigram language model

4
Multivariate Bernoulli Event Text Model
Each document:Result of |V| independent Bernoulli trials I.e. for each word in vocabulary,
does the word appear in the document?
From general Naïve Bayes perspectiveEach word corresponds to two variables, wt and
In each doc, either wt or appearsAlways have |V| elements in a document

5
Training & Testing
Laplace smoothed training:
MAP decision rule classification:
P(c)

6
Multinomial Event Model

7
Multinomial DistributionTrial: select a word according to its probability
Possible outcomes: {w1,w2,…,w|V|}

8
Multinomial DistributionTrial: select a word according to its probability
Possible outcomes: {w1,w2,…,w|V|}
Document is viewed as result of:One trial for each position
P(word = wi) = pi
Σipi= 1

9
Multinomial DistributionTrial: select a word according to its probability
Possible outcomes: {w1,w2,…,w|V|}
Document is viewed as result of:One trial for each position
P(word = wi) = pi
Σipi= 1
P(X1=x1,X2=x2,….,X|V|=x|V|)

10
Multinomial DistributionTrial: select a word according to its probability
Possible outcomes: {w1,w2,…,w|V|}
Document is viewed as result of:One trial for each position
P(word = wi) = pi
Σipi= 1
P(X1=x1,X2=x2,….,X|V|=x|V|)

11
Multinomial DistributionTrial: select a word according to its probability
Possible outcomes: {w1,w2,…,w|V|}
Document is viewed as result of:One trial for each position
P(word = wi) = pi
Σipi= 1
P(X1=x1,X2=x2,….,X|V|=x|V|)

12
ExampleConsider a vocabulary V with only three words:
a, b, c
Due to F. Xia

13
ExampleConsider a vocabulary V with only three words:
a, b, c
Document di contains only 2 word instances
Due to F. Xia

14
ExampleConsider a vocabulary V with only three words:
a, b, c
Document di contains only 2 word instances
For each position:(P(w=a)=p1, P(w=b)=p2, P(w=c) = p3
Due to F. Xia

15
ExampleConsider a vocabulary V with only three words:
a, b, c
Document di contains only 2 word instances
For each position:(P(w=a)=p1, P(w=b)=p2, P(w=c) = p3
What is the probability that we see ‘a’ once and ‘b’ once in di?
Due to F. Xia

16
Example (cont’d)
How many possible sequences?
Due to F. Xia

17
Example (cont’d)
How many possible sequences? 3^2 = 9Sequences: aa, ab, ac, bb, ba, bc, ca, cb, cc
Due to F. Xia

18
Example (cont’d)
How many possible sequences? 3^2 = 9Sequences: aa, ab, ac, bb, ba, bc, ca, cb, cc
How many sequences with one ‘a’ and one ‘b’?
Due to F. Xia

19
Example (cont’d)
How many possible sequences? 3^2 = 9Sequences: aa, ab, ac, bb, ba, bc, ca, cb, cc
How many sequences with one ‘a’ and one ‘b’?n!/(x1!..x|v|!) = 2
Probability of the sequence ‘ab’ is:
Due to F. Xia

20
Example (cont’d)
How many possible sequences? 3^2 = 9Sequences: aa, ab, ac, bb, ba, bc, ca, cb, cc
How many sequences with one ‘a’ and one ‘b’?n!/(x1!..x|v|!) = 2
Probability of the sequence ‘ab’ is: p1*p2
Probability of the sequence ‘ba’
Due to F. Xia

21
Example (cont’d)
How many possible sequences? 3^2 = 9Sequences: aa, ab, ac, bb, ba, bc, ca, cb, cc
How many sequences with one ‘a’ and one ‘b’?n!/(x1!..x|v|!) = 2
Probability of the sequence ‘ab’ is: p1*p2
Probability of the sequence ‘ba’ : p1 * p2
So probability of seeing ‘a’ once and ‘b’ once is:
Due to F. Xia

22
Example (cont’d)
How many possible sequences? 3^2 = 9Sequences: aa, ab, ac, bb, ba, bc, ca, cb, cc
How many sequences with one ‘a’ and one ‘b’?n!/(x1!..x|v|!) = 2
Probability of the sequence ‘ab’ is: p1*p2
Probability of the sequence ‘ba’ : p1 * p2
So probability of seeing ‘a’ once and ‘b’ once is:
= 2 p1*p2
Due to F. Xia

23
Multinomial Event ModelDocument is sequence of word events drawn
from vocabulary V.Assume document length independent of classAssume (Naïve Bayes) words independent of
context

24
Multinomial Event ModelDocument is sequence of word events drawn
from vocabulary V.Assume document length independent of classAssume (Naïve Bayes) words independent of
context
Define Nit = # of occurrences of wt in document di

25
Multinomial Event ModelDocument is sequence of word events drawn
from vocabulary V.Assume document length independent of classAssume (Naïve Bayes) words independent of
context
Define Nit = # of occurrences of wt in document di
Then under multinomial event model:

26
Multinomial Event ModelDocument is sequence of word events drawn
from vocabulary V.Assume document length independent of classAssume (Naïve Bayes) words independent of
context
Define Nit = # of occurrences of wt in document di
Then under multinomial event model:

27
Multinomial Event ModelDocument is sequence of word events drawn
from vocabulary V.Assume document length independent of classAssume (Naïve Bayes) words independent of
context
Define Nit = # of occurrences of wt in document di
Then under multinomial event model:

28
Multinomial Event ModelDocument is sequence of word events drawn
from vocabulary V.Assume document length independent of classAssume (Naïve Bayes) words independent of
context
Define Nit = # of occurrences of wt in document di
Then under multinomial event model:

29
TrainingP(cj|di)=1 if document di is of class cj, and 0 o.w.
So,

30
TrainingP(cj|di)=1 if document di is of class cj, and 0 o.w.
So,

31
TrainingP(cj|di)=1 if document di is of class cj, and 0 o.w.
So,

32
TrainingP(cj|di)=1 if document di is of class cj, and 0 o.w.
So,

33
TrainingP(cj|di)=1 if document di is of class cj, and 0 o.w.
So,
Contrast this with multivariate Bernoulli

34
TestingTo classify a document di compute:
argmaxc P(c)P(di|c)

35
TestingTo classify a document di compute:
argmaxc P(c)P(di|c)
argmaxc P(c)

36
Two Naïve Bayes ModelsMulti-variate Bernoulli event model:
Models binary presence/absence of word feature

37
Two Naïve Bayes ModelsMulti-variate Bernoulli event model:
Models binary presence/absence of word feature
Multinomial event model:Models counts of word features, unigram models

38
Two Naïve Bayes ModelsMulti-variate Bernoulli event model:
Models binary presence/absence of word feature
Multinomial event model:Models counts of word features, unigram models
In experiments on a range of different text classification corpora, multinomial model usually outperforms multivariate Bernoulli (McCallum & Nigam, 1998)

39
Thinking about Performance
Naïve Bayes: conditional independence assumptionClearly unrealistic, but performance is often goodWhy?

40
Thinking about Performance
Naïve Bayes: conditional independence assumptionClearly unrealistic, but performance is often goodWhy?
Classification based on sign, not magnitude Direction of classification usually right
Multivariate Bernoulli vs MultinomialWhy does multinomial perform better?

41
Thinking about Performance
Naïve Bayes: conditional independence assumptionClearly unrealistic, but performance is often goodWhy?
Classification based on sign, not magnitude Direction of classification usually right
Multivariate Bernoulli vs MultinomialWhy does multinomial perform better?
Captures additional information: presence/absence+freq
What if we wanted to include other types of features?

42
Thinking about Performance
Naïve Bayes: conditional independence assumptionClearly unrealistic, but performance is often goodWhy?
Classification based on sign, not magnitude Direction of classification usually right
Multivariate Bernoulli vs MultinomialWhy does multinomial perform better?
Captures additional information: presence/absence+freq
What if we wanted to include other types of features?Multivariate: just another Bernoulli trial
Multinomial can’t mix distributions

43
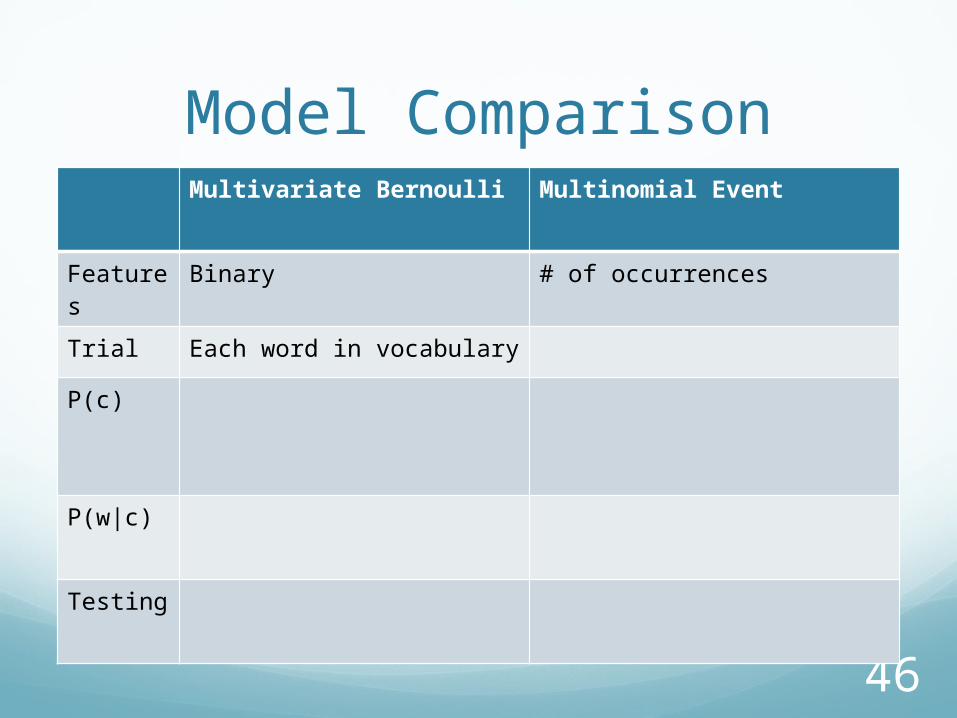
Model ComparisonMultivariate Bernoulli Multinomial Event
Features
Trial
P(c)
P(w|c)
Testing

44
Model ComparisonMultivariate Bernoulli Multinomial Event
Features Binary
Trial
P(c)
P(w|c)
Testing

45
Model ComparisonMultivariate Bernoulli Multinomial Event
Features Binary # of occurrences
Trial
P(c)
P(w|c)
Testing
46
Model ComparisonMultivariate Bernoulli Multinomial Event
Features Binary # of occurrences
Trial Each word in vocabulary
P(c)
P(w|c)
Testing

47
Model ComparisonMultivariate Bernoulli Multinomial Event
Features Binary # of occurrences
Trial Each word in vocabulary Each position in document
P(c)
P(w|c)
Testing

48
Model ComparisonMultivariate Bernoulli Multinomial Event
Features Binary # of occurrences
Trial Each word in vocabulary Each position in document
P(c)
P(w|c)
Testing

49
Model ComparisonMultivariate Bernoulli Multinomial Event
Features Binary # of occurrences
Trial Each word in vocabulary Each position in document
P(c)
P(w|c)
Testing

50
Model ComparisonMultivariate Bernoulli Multinomial Event
Features Binary # of occurrences
Trial Each word in vocabulary Each position in document
P(c)
P(w|c)
TestingP(c) P(c)

51
Naïve Bayes: StrengthsAdvantages:

52
Naïve Bayes: StrengthsAdvantages:
Simplicity (conceptual)Training efficiencyTesting efficiencyScales fairly well to large dataPerforms multiclass classificationCan provide n-best outputs

53
Naïve Bayes: WeaknessesDisadvantages:
Theoretical foundation weak:Ragingly inaccurate independence assumption
Decent accuracy, but outperformed by more sophisticated

54
Naïve Bayes: WeaknessesDisadvantages:

55
HW#3Naïve Bayes Classification:
Experiment with the Mallet Naïve Bayes Learner
Implement Multivariate Bernoulli event model
Implement Multinomial event modelCompare with binary variables
Analyze results

56
NotesUse add-delta smoothing (vs add-one)
Beware numerical underflow log probs are your friend
Also converts exponents to multipliers
Look out for repeated computationPrecompute normalization denominators
E.g. for multinomial P(w|c), compute once for each c

57
EfficiencyMVB:

58
EfficiencyMVB:

59
EfficiencyMVB: