network flow pattern extraction by clustering eugine kang
TRANSCRIPT

Network Flow Pattern Extraction by Clustering
Eugine Kang, Seojoon Jin
Korea University
Abstract
Network is a system which allows users to connect with the
internet. Although the internet seems to be ever increasing and
boundless, the infrastructure to provide the internet has physical
limitations. Network flow analysis tools are developed for efficient
network management. This paper discusses a statistical learning method
for efficient network management. Network flow data is first transformed
by time block and then followed by calculating Within Sum of Squares
(WSS) and Calinski-Harabasz index (CH) for optimal number of clusters.
The clustering algorithms used for this paper is k-means clustering.
Principal Component Analysis (PCA) allows dimension reduction of the
data set to visually confer the clusters by relative position of
observations. The stability of the clusters is measured by the mean of
Jaccard coefficient from 10,000 bootstrap resampled data sets.
Keywords: Calinski-Harabasz index, principal component analysis, Jaccard
coefficient, bootstrap, k-means clustering
Introduction
Data is collected from all fields and the amount of data collected
is exponentially growing. Richer datasets allow researchers and entities
to extract meaningful knowledge with the use of machine learning
algorithms. In many business and engineering applications, raw data
collected from systems needs to be processed into various forms of
structured and semantically rich records before data analysis tasks can
produce accurate, useful, and understandable results. However, the
difficulty comes when the raw data is difficult to understand and
manipulate. This paper walks through the network flow data collected at

Korea University Sejong Campus, and transform the data to extract
meaningful knowledge. This project first started under the goal to
increase network flow efficiency within the campus. The flow of data is
labeled with the type of application and trying to minimize or detect the
use of non-academic purpose flow was essential. Torrent is a p2p file
sharing service commonly used among users for downloading audio and
video files. The campus labels torrent as a non-academic purpose flow
and deeper analysis of the torrent flow within the campus is the main
purpose of this paper.
Recent works of network flow analysis has been conducted on a
time basis but fail to produce any meaningful pattern from the users.
Reference to previous studies and similar studies with explanation will be
added to this section on a later date.
The rest of the paper is organized as follows. We first give an
overview of the data collected from the network. We then discuss the
data transformation steps, which include time base patterns, and parsing
each such pattern to construct statistical features. We report the
experiments of using clustering techniques on the network flow data. We
then describe how to utilize the knowledge extracted from experiments.
Collected Data from Campus Network
Figure 1: Diagram of network flow data collection

Korea University Sejong Campus data center collects each IP’s
network flow information on a minute-to-minute basis. There is about
5,000 IPs designated for desktop connections and a separate data center
for collecting mobile devices connection through WI-FI. The type of
information collected can be seen on table 1. Service and protocol level
features tells us the type of service being used by the users on the local
IP address. The type of service varies from web browsing, video
streaming, e-mail, and torrent, which is the type of service we are
interested in for this paper. Other features in table 1 collect information
on the connection to the local IP. The network flow information is stored in
a table like structure, e.g. relational database. However, the size of the
entire network flow exceeds 3TB and required a different type of
database to store and extract data. Hadoop Distributed File System
(HDFS) was used to store the enormous amount of data and applications
were used accordingly to extract data.
Table 1: Network connection features
Feature Name
Feature MeaningFeature Name
Feature Meaning
flow_I flow index o_octet outbound byte count
con_I continue index(flow's parent index)
i_pkt inbound pkt count
sip local ip i_octet inbound byte count
sport local port flag flag information flag
prot transmission protocol sr_lvl1 service level 1dip remote ip sr_lvl2 service level 2dport remote port sr_lvl3 service level 3time time of flow start pt_lvl1 protocol level 1o_pkt outbound pkt count pt_lvl2 protocol level 2
Data Transformation
The bandwidth limitation of the campus network has a limit at a given time. We are more interested in torrent usage according to time blocks. Detecting torrent usage patterns by time will allow the network administrator to prepare for heavy loads of network use at peak times.

The data transformation step parses data into weekdays, hours, and by flow, incoming, outgoing data amount.
Figure 2: Heatmap visualization of data transformation
Figure 2 shows one local IP’s torrent flow usage over time. The horizontal axis represents weekday and vertical axis represents the hour of day. The red region indicates relative heavy usage compared to the green regions. Through this data transformation process we are able to detect patterns from local IP torrent usage by time blocks. This information will be helpful for the network administrator to prevent heavy bandwidth loading caused by torrent usage.
Experiment Technique
-means clustering
-means clustering is a method of vector quantization, that is popular for cluster analysis in data mining. The goal of this algorithm is to
partition observations into clusters in which each observation belongs to the cluster with the nearest mean. In this paper we set each observation as a local IP, and observe how they partition.
The algorithm uses an iterative refinement technique. Given an
randomly initialized set of means , the algorithm proceeds by iterating two steps, assignment step and update step. The assignment step assigns each observation to the cluster with the nearest

centroid. Equation 1 assign each observation to exactly one . Once each observations are assigned to a cluster, the update step calculates the centroids of the cluster with newly updated observations. Equation 2 sums up the features of each observation and generate a new centroid.
(1)
(2)
Given the number of clusters to be partitioned, the objective of the algorithm is to find equation 3. The cluster orientation which minimizes the within sum of squares (WSS). WSS is also used to determine the appropriate number of clusters, but inappropriate due to nature of decreasing WSS value as number of clusters increases.
(3)
Calinski-Harabasz Index
-means clustering is a fast and efficient clustering technique.
However, one drawback is the pre-determination of before the algorithms proceed. To optimize the clustering results, WSS is a common
scoring method to determine . As mentioned above, the nature of
decreasing WSS value as increases makes it difficult for optimization. Calinski-Harabasz index is best suited in finding the optimal number of cluster for k-means clustering solutions.
The Calinski-Harabasz index is also called the variance ratio criterion. Equation 4 calculates the variance between clusters and equation 5 the variance between observations within a cluster. Well-defined clusters have a large between-cluster variance and a small within-cluster variance. The larger the Calinski-Harabasz index, the better the data partition. To determine the optimal number of clusters, the best
practice is to maximize equation 6 respect to .
(4)

(5)
(6)
In theory, determining which maximizes the Calinski-Harabasz index results in the best partitioned cluster. However, in practice the number of clusters tend to be lower than the amount of clusters needed for distinct pattern analysis.
Principal Component Analysis
Determining for clustering data may not always lead to desired results. WSS and CH scores are a method to determine the optimal
number of clusters for -means clustering. In practice, a visual determination of optimal number of clusters helps with the decision process. Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. The number of principal components allowed are determined by the number of features given in the data set. By selecting the first two principal components, the data goes through data reduction to be represented on a lower dimensional space.

Figure 3: Data reduction on data set by PCA
Figure 3 represents 4,111 local IP’s with 168 features on a two dimensional space. Due to the orthogonal transformation gone through PCA, the values on the first and second principal components do not provide statistically significant meaning. However, the dimension reduction visualization provides relative nearness from observation to observation. We induce observations closer to one another share similar feature values and hence belong in the same partition for cluster analysis. PCA is used as a visual tool to determine the fitness of our cluster analysis.
Cluster Stability Assessment
Even the most sophisticated clustering algorithms tend to generate partitions even for fairly homogeneous data sets. Cluster validation is very important in cluster analysis. An important aspect of cluster validity is stability. Stability means that a meaningful valid cluster should not disappear if the data set is altered in a non-typical way. There could be serval conceptions what a “non-typical alternation” of the data set is. In terms of this paper, data set extracted from the underlying database should give rise to more or less the same clustering.
The stability of the clusters formed is tested through the methods provided by Hennig (2007). Equation 7 calculates the Jaccard coefficient between two clusters as a measure of similarity. Jaccard coefficient does not depend on two clusters having identical amount of observations for the measurement to be valid. This is an advantage for cluster analysis because clusters with varying observation counts may form.

(7)
Resampling methods is quite natural to assess cluster stability. Bootstrap is performed to resample new data sets from the original data set. The desired clustering algorithm is applied and the similarity values are recorded for every original cluster to the most similar cluster in the proceeding iteration. The stability of every single cluster is taken by the mean similarity taken over the resampled data sets. Equation 8 calculates the mean similarity of clusters over bootstrapped data sets.
is the number of bootstrap replications.
(8)
Experiment Results
The experiment to extract torrent usage pattern by local IP begins with transforming the data to represent weekday to time usage. The reason for this transformation is due to the natural limitation of bandwidth within the campus network system. Identifying heavy loads of non-academic network usage by time is necessary for efficient management of the network system.
One drawback of -means clustering is the pre-determination of
. This paper first find candidates for suitable using WSS and CH.
Figure shows the WSS and CH score respect to increasing . WSS naturally decreases as the number of clusters increases, but the pattern
we are looking for is a significant drop of WSS from a value to the next.
Just looking at WSS, a significant drop can be observed when . Although the drop from 6 clusters to 7 is not as steep compared to others we are searching for appropriate candidates at this point. CH measures the ratio of variance between clusters and variance between observations within clusters. In literature, the maximum value of CH
respect to leads to the best partition. stands out as the best candidate, but restricting to 3 clusters may lead to lack to distinct torrent usage patterns. Minimizing the torrent usage to 3 types may not as be helpful to network administrators and lead to unnecessary restriction on network usage to local IPs. The next candidate we look for is a bump in
CH value compares to the overall trend. shows a small bump compared to the trend given by previous and after CH values. This

narrows our candidates to 3, and 7.
PCA is used as a dimension reduction technique to visualize the
relative positions of observations. When the number of candidates forcan not be reduced to one, PCA can help settle the tie through
visualization. Figure 5 shows the clusters when . The relative positioning of observations how each clusters are closely formed, and cluster 2 show observations spread out the entire reduced dimensional space. This finding is difficult to conclude distinct patterns within the cluster. Compared to cluster 2, the other clusters are relatively closely located to other observations. This leads to a distinct pattern within the cluster while the other does not.
Figure 4: WSS vs CH to determine optimal k

Figure 5: PCA visualization for 3 clusters
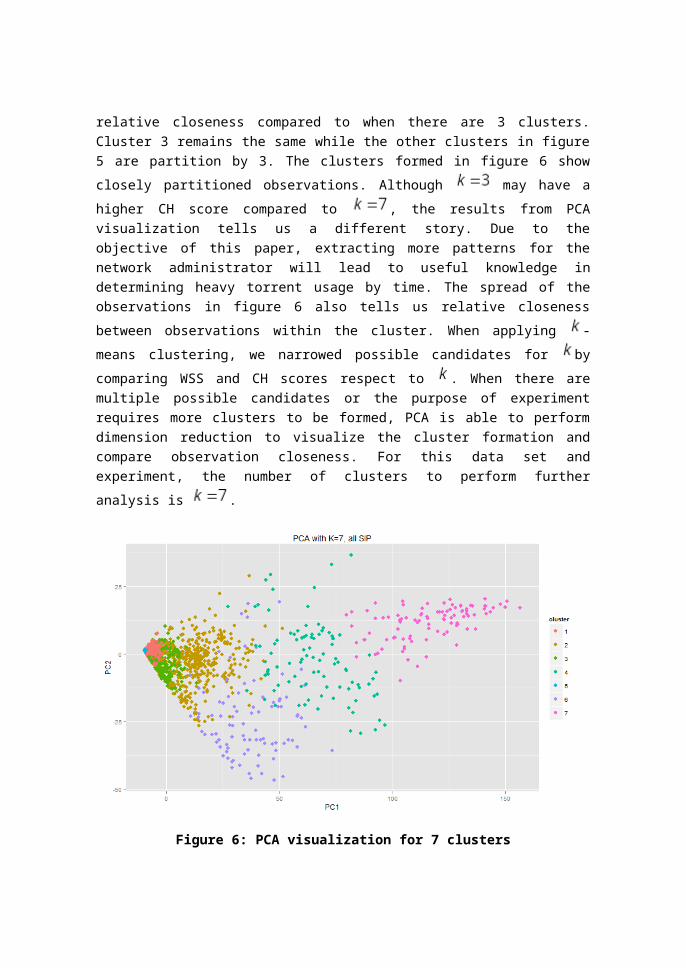
Figure 6 shows a different formation of clusters compared to figure 5. The 7 clusters formed in figure 6 show relative closeness compared to when there are 3 clusters. Cluster 3 remains the same while the other clusters in figure 5 are partition by 3. The clusters formed in
figure 6 show closely partitioned observations. Although may have
a higher CH score compared to , the results from PCA visualization tells us a different story. Due to the objective of this paper, extracting more patterns for the network administrator will lead to useful knowledge in determining heavy torrent usage by time. The spread of the observations in figure 6 also tells us relative closeness between
observations within the cluster. When applying -means clustering, we
narrowed possible candidates for by comparing WSS and CH scores
respect to . When there are multiple possible candidates or the purpose of experiment requires more clusters to be formed, PCA is able to perform dimension reduction to visualize the cluster formation and compare observation closeness. For this data set and experiment, the number of
clusters to perform further analysis is .

Figure 6: PCA visualization for 7 clusters
Table 2: Cluster stability
Cluster Stability Observations
1 0.842 762 0.957 863 0.808 914 0.773 2735 0.652 1016 0.985 33147 0.692 170
Non-typical alteration with the data may lead to different clusters forming. Testing the stability is very important in cluster analysis. When we are detecting network patterns with the cluster formation, the stability and validity of these patterns occurring with a different data set must be tested. We use the Jaccard coefficient as a measurement of similarity and generate multiple data sets by the bootstrap resampling method. We
generated 7 clusters with the -means clustering algorithm and generated a stability value by the mean of Jaccard coefficients over 10,000 bootstrap resampled data sets. The stability value varies between 0-1. Values over 0.75 are considered stable and the same cluster forming with non-typical alteration.
5 out of 7 clusters form stable clusters to derive meaningful partitioning. The highest stability comes from cluster 6 with a value close
to 1. The number of local IPs belonging in cluster 6 is also the highest containing about 80% of the total local IPs. Cluster 5 and 7 fails to reach a stability of 0.75 or higher. The patterns of stable clusters will be visually examined.
Figure 7: Torrent usage pattern for cluster 1
Cluster 1 shows a regular usage of torrent during working hours. The campus network is used by students, researchers, and professors, but they are also used by office staffs as well. The torrent usage seems to follow the user’s computer usage time, and indicate the start of the week the most concentrated. This could be explained by users downloading shows over the weekend.

Figure 8: Torrent usage pattern for cluster 2
Cluster 2 takes up most of the torrent usage over all observations. The 86 local IPs belonging to cluster 2 are responsible for loading the network system with heavy torrent usage. Figure 8 makes it quite obvious to see the reason why. Unlike cluster 1 with specific time usage, cluster 2 does not know when to stop torrent usage. Managing and curving down the non-academic network usage of these 86 local IPs is the key for making more room for network bandwidth.
Cluster 3 tells us a similar pattern to cluster 1 but with heavier intensity. The difference between cluster 1 and 3 is the moment of peak usage. Cluster 1 show a gradual decrease in usage as the weekday goes on, but cluster 3 show peak on Mon, Thurs, and Friday. The maximum flow visible through the legend is 2-3 folds the maximum of cluster 1. The usage pattern for cluster 1 and cluster 3 share common relationship between working hours and torrent usage, but differ in moment of intensity and maximum amount.

Figure 9: Torrent usage pattern for cluster 3
Cluster 4 and 6 share common patterns which show the lack of torrent activity. This is odd discovery to be revealed from this experiment. The current network system is overloaded with the usage of torrent activity, but the clusters pattern show the contrary when looking at the number of local IPs actively using the service. Cluster 4 and 6 take more than 80% of local IPs, but the torrent usage seems to be nearly none. This discovery gives heavier emphasis to the pattern shown in cluster 2. Small amount of users are responsible for the majority of network load within this campus. Cluster 4 shows a peak on Saturday morning, but this is not an important feature to worry as a network administrator because the overall network usage during that time is low anyway. The peak is within cluster 4 but compared to other clusters the intensity is significant lower than others. The pattern from cluster 4 and 6 allows us to conclude that most of the local IPs do not require special administration to curve down the usage of non-academic network usage such as torrent.

Figure 10: Torrent usage pattern for cluster 4
Figure 11: Torrent usage pattern for cluster 6
Cluster 5 and 7 fail to achieve stability from the mean of Jaccard coefficient by bootstrap resample data sets. The patterns detected are hard to assume stability and hence can change with non-typical alteration to extracted data set.

Conclusion
The network system within an entity requires management for efficiency. This paper experimented with a method to detect patterns from a massive data set collected from network flow. The steps we took was first to transform the data by time blocks and extract network flow data which are labeled as torrent. Torrent is a non-academic network service which takes a big burden to the network system. WSS and CH were calculated within the transformed data set to narrow down the possible number of clusters, and the clusters were visually reexamined through PCA. The dimension reduction technique allows us to observe relative positioning from one observation to another. The stability of clusters formed by k-means clustering was validated through bootstrap resampling and taking the mean of the Jaccard coefficient of the most similar clusters formed over 10,000 iterations.
The patterns detected from each clusters are visualized by heatmap to easily detect peaks in usage over time. The main discovery of this cluster analysis reveals a small amount of users are responsible for the majority of network load to the entire system. 80% or more of the users barely load the network with non-academic network usage. As a network administrator, the patterns detected can be used for special administration for users with a history of heavy usage. Because the users who belong to this field are low, the job of the network administrator can be lessened. Further analysis of the clusters show relative peak, and this information can also prepare a network administrator for the specific time slot where network usage will increase. The proposed method can also be applied other network services as well.
Reference
Hartigan, John A., and Manchek A. Wong. "Algorithm AS 136: A k-means clustering algorithm." Applied statistics (1979): 100-108.
Likas, Aristidis, Nikos Vlassis, and Jakob J. Verbeek. "The global k-means clustering algorithm." Pattern recognition 36.2 (2003): 451-461.
Ding, Chris, and Xiaofeng He. "K-means clustering via principal component analysis." Proceedings of the twenty-first international conference on Machine learning. ACM, 2004.
Caliński, Tadeusz, and Jerzy Harabasz. "A dendrite method for cluster analysis." Communications in Statistics-theory and Methods 3.1 (1974): 1-27.
Wold, Svante, Kim Esbensen, and Paul Geladi. "Principal component analysis." Chemometrics and intelligent laboratory systems 2.1 (1987): 37-52.
Abdi, Hervé, and Lynne J. Williams. "Principal component analysis." Wiley Interdisciplinary Reviews: Computational Statistics 2.4 (2010): 433-459.

Becker, R. A., J. M. Chambers, and A. R. Wilks. "The New S Language Pacific Grove CA: Wadsworth & Brooks/Cole." BeckerThe New S Language1988(1988).
Mardia, Kantilal Varichand, John T. Kent, and John M. Bibby. Multivariate analysis. Academic press, 1979.
Venables, William N., and Brian D. Ripley. Modern applied statistics with S. Springer Science & Business Media, 2002.
Hennig, C. (2007) Cluster-wise assessment of cluster stability. Computational Statistics and Data Analysis, 52, 258-271.
Hennig, C. (2008) Dissolution point and isolation robustness: robustness criteria for general cluster analysis methods. Journal of Multivariate Analysis 99, 1154-1176.