newsfinder: automating an ai news service · although newsfinder and google news differ in this...
TRANSCRIPT

Selecting a small number of interesting news stories eachweek about AI, or any other topic, requires more thansearching for individual terms. Since it is time-consuming
to find and post interesting stories manually, we have designedand written an AI program called NewsFinder1 that automati-cally collects English-language news stories from the web, cate-gorizes them with trained models, filters out uninteresting andunrelated stories based on a set of heuristics, and publishesthem in summarized form as the AI in the News service. AI inthe News is part of the AAAI AITopics2 site described previously(Buchanan, Smith, and Glick 2008).
The goal for NewsFinder is to publish a small, select set ofnews stories that are of general interest to the AI communityand to provide categorization metadata to help readers scan forstories that match their specific interests. A news story may beassigned to a single category or to multiple categories (for exam-ple, Robots and Vision). The task is similar to asking GoogleNews3 to find stories about AI, but differs in one importantrespect. Google News is driven by readers’ queries to find storiescontaining a set of keywords from thousands of news sources.By contrast, NewsFinder uses multiple predetermined queriesand Really Simple Syndication (RSS) feeds to find stories from apreferred set of hand-selected sources, as well as from GoogleNews query searches. Google News can be described as a “pull”service because readers must perform queries in order to findnews stories that match their interests. NewsFinder, on the oth-er hand, is a “push” service that selects news stories based on
Articles
SUMMER 2012 43Copyright © 2012, Association for the Advancement of Artificial Intelligence. All rights reserved. ISSN 0738-4602
NewsFinder: Automating an AI News Service
Joshua Eckroth, Liang Dong, Reid G. Smith, Bruce G. Buchanan
n NewsFinder automates the steps involved infinding, selecting, categorizing, and publishingnews stories that meet relevance criteria for theartificial intelligence community. The softwarecombines a broad search of online news sourceswith topic-specific trained models and heuris-tics. Since August 2010, the program has beenused to operate the AI in the News service thatis part of the AAAI AITopics website.

predicted reader interest and “pushes” those storiesto readers by email. We believe that readers of AI inthe News expect higher-quality stories than thosedelivered by Google News, precisely because News-Finder “pushes” (emails) its weekly alerts.Although NewsFinder and Google News differ inthis way, we nevertheless provide an empiricalcomparison of the two systems.
NewsFinder crawls the web each week lookingfor recent AI-related news. For each news story,NewsFinder determines which aspects of AI are themain focus of the story (for example, robots,machine learning, vision, and so on), whether thestory is a duplicate of another that NewsFinderknows about, and finally whether the story meetscertain publication criteria. The best stories areautomatically summarized and sorted. After anadministrator approves their distribution, the sto-ries are published on a website, inserted into RSSfeeds, and sent to email list subscribers.
DesignNewsFinder has two principle components: aweekly crawling, filtering, and publishing compo-nent and an offline training component.
Document RepresentationAs is common in information retrieval applica-tions, we use Salton and Buckley’s weighted term-frequency vector space model (Salton and Buckley1988), commonly known as tf-idf, to representeach news story. Let W = {f1, f2, …. fm} be the com-plete vocabulary set of the crawled news afterstemming and stopword filtering. On average,each story contains about 180 different terms afterremoving stopwords (for example, common Eng-lish words like and, or, not).4 The term frequencyvector Xi of news story is defined as
Xi = [x1i, x2i, …, xmi]T
xji = log(tfji + 1) * log(n/dfj +1)),
where tfji denotes the frequency of the term fj ŒWin the news story di; dfj denotes the number of sto-ries containing word fj; and n denotes the totalnumber of news stories in the database. The firstcomponent, log(tfji + 1), is the contribution of theterm frequency (tf). The second component,log(n/dfj +1)), is the contribution of the inversedocument frequency (idf). The vector Xi is nor-malized to unit Euclidean length.
When we discuss training in later sections, notethat the inverse document frequency of each termand the number of news stories in the database (n)do not change during weekly web crawling. Rather,we calculate a story’s tf-idf value based on a docu-ment database that is not changed until retrainingis initiated.
Weekly Crawling, Filtering, and Publishing
Each Sunday morning, NewsFinder crawls the webfor news stories and publishes a select few. Theprocess consists of three stages: discover, filter, andpublish. These stages are shown graphically in fig-ure 1.
DiscoverNewsFinder searches 37 preferred online newssources for interesting news. Examples includeBBC using search terms “artificial intelligence” and“robots,” CNN’s “Tech” feed, Discovery’s “Robot-ics” feed, the New York Times’s “Artificial Intelli-gence” and “Robots” feeds, MIT News “AI/Robot-ics” feed, IEEE Spectrum’s “Robotics” feed, andothers.5 Web page and RSS parsers extract storytitles, content, and publication dates from thesources. If the news source has an RSS feed, thetitles, content, and publication dates of stories areusually already tagged and can be retrieved direct-ly from the RSS format. NewsFinder also queriesGoogle News to find news stories not found in oth-er sources. Queries include “artificial intelligence,”“intelligent agent,” “machine learning,” and 14other AI-specific phrases.
If the news story does not come from an RSSfeed, an open-source heuristic-driven text extrac-tor6 automatically extracts the main content of anews story, ignoring advertisements, links to otherstories, and other unwanted content often foundin web pages. For story categorization, summariza-tion, and other filtering and ranking procedures,we are only interested in obtaining an article’s title,publisher (for example, BBC, CNN), publicationdate, and main text (without links).
In addition to crawling news sources, News-Finder gathers user-submitted news7 — user sub-missions come in the form [web address, publica-tion date] — and extracts the web-page content aswith any other news source.
FilterThe discover stage produces on average about 170stories a week. Most of these stories have nothingto do with AI, although they may use AI-relatedwords. The task in the filter stage is to select onlythe most relevant stories from this collection.
In a prior version of NewsFinder (Dong, Smith,and Buchanan 2011), we asked readers to rate pub-lished stories on a 0–5 scale where zero indicates astory is irrelevant and five means a story is highlyrelevant. This feedback was used to train a multi-class support vector machine (SVM) that predicteda story’s rating. The predicted rating would be con-sidered when filtering stories (stories with ratingsin the range of 0–2 would be filtered out). Howev-er, we subsequently judged that the predictions
Articles
44 AI MAGAZINE

were not sufficiently accurate and abandoned thismethod of filtering stories. Although we continueto collect and display ratings from readers, we usethe ratings for information only and not for train-ing purposes. The filtering process described nextseems to be accurate enough for our needs, and hasthe benefit of greater simplicity.
A news story is first filtered out of the candidateset if it contains any occurrences of profanity orother offensive words on a list known as a black-list8 or if its URL matches the URL blacklist (forexample, websites that advertise engineering jobs).Next, a news story is filtered out if it does not con-tain at least one occurrence of each of two differ-ent whitelist terms. Subject-matter experts helpedus produce the list of 107 terms (the full whitelistis available online9), which includes artificial intel-ligence, Bayes, computer vision, ethical issues,intelligent agents, machine translation, pattern
recognition, qualitative reasoning, smart car, andTuring.
Terms without initial capitalization are stemmedbefore comparing with the news story’s content(which is likewise stemmed). We use the Porterstemmer from the Natural Language Toolkit (Lop-er and Bird 2002).
Next, all occurrences of stopwords are removedfrom the story’s content and the tf-idf vector isconstructed. This vector is passed off to the 19SVMs that individually predict category member-ship. Stories without any predicted categories arefiltered out.
Duplicates are then detected based on a trainedsimilarity threshold. One benefit of representingdocuments as tf-idf vectors is that we have accessto a simple similarity measure, known as thecosine similarity. The dot-product of two docu-ment vectors indicates the cosine similarity of the
Articles
SUMMER 2012 45
Drop blacklisted or old stories
Sort by relevance
1 2 3
Categorize with19 SVM models
Ready for publication
Summarize content
Drop stories with no categories
Crawl web to obtain stories
Drop less relevant duplicates
Discover
Filter
Publish
Figure 1 NewsFinder’s Three Processing Stages.
Documents are shown as crossed out to indicate that they have been filtered out of the candidate set of news stories.Only candidate stories may be published.

two documents; this similarity measure is between0.0 and 1.0. A similarity threshold (currently 0.17)is used as a cutoff point: if the cosine similarity oftwo news stories is greater than or equal to thisthreshold, the stories are labeled as duplicates.
Among a set of duplicate stories, one must bechosen (which may or may not ultimately be pub-lished by NewsFinder depending on the numberand quality of other candidate stories). We use thefollowing heuristics to choose the top story amongduplicates: (1) if one of the duplicates has alreadybeen published by NewsFinder in the past 14 days,then do not publish any others; (2) if one of theduplicates has been submitted by a user, thenchoose the user-submitted story; (3) otherwise,choose the story that comes from the most pre-ferred source (online news sources have been man-
ually ranked for preference10), or if two storiescome from the same source or both come fromGoogle News searches (whose true sources may nothave been seen before, and thus not ranked forpreference), then choose the story that has themost predicted categories. We assume that a storywith more predicted categories than a duplicatestory will take a wider and therefore more interest-ing view of the news. Finally, if two duplicate sto-ries come from the same source (or Google News)and have the same number of predicted categories,then choose arbitrarily.
What remains at this point is a collection of can-didate stories that are considered relevant andnonduplicates. The final task is to further cull thisset to produce a small yet diverse selection of sto-ries that represent the week’s AI-related news.
Articles
46 AI MAGAZINE
“Monkeys Control Virtual Limbs With Their Minds”Date: Oct 5, 2011Publisher: WiredCategories: Cognitive Science, Robots
Summary: “Now, by implanting electrodes into both the motor and the sensory areas of the brain, researchers have created a virtual prosthetic hand that monkeys control using only their minds, and that enables them to feel virtual textures. Using the !rst set, the monkey could control a virtual monkey arm on a computer screen and sweep the hand over virtual disks with different textures. By giving the monkey rewards when it identi!ed the right texture, the researchers discovered that it took as few as four training sessions for the animal to consistently distinguish the textures from one another, even when the researchers switched the order of the visually identical disks on the screen. Although the monkeys are all adults, the motor and sensory regions of their brains are amazingly plastic, Nicolelis says: the combination of seeing an appendage that they control and feeling a physical touch tricks them into thinking that the virtual appendage is their own within minutes.”
http://www.wired.com/wiredscience/2011/10/monkeys-control-virtual-limbs/
This story was selected for publication due to the following reasons. Two whitelisted (stemmed) phrases, “brain control” and “virtual prosthet,” were found in the text; two categories were selected; and though the story was considered a duplicate of four other stories, this version came from a preferred source (Wired)
Figure 2. Example of NewsFinder Output.

PublishFor aesthetic reasons, we have decided that only 12or fewer stories will be published per week, and ide-ally no single category (such as robots or machinelearning) will have more than eight representativesamong the 12 stories. The candidate stories are firstsorted by duplicate count (stories with more dupli-cates are presumed to be more interesting), thensorted by news source credibility, and further sort-ed by category count (having more categories indi-cates greater interestingness). Stories are selected inthis order until 12 stories have been selected. A sto-ry may be skipped if all of its categories are “maxedout,” meaning the category already has eight rep-resentatives. We only require that one of the story’scategories not be “maxed out,” so a category mayhave more than eight representatives in the finalpublished set of stories.
Once 12 stories have been selected, they aresummarized using the Open Text Summarizer(Yatsko and Vishnyakov 2007).11 The summaries(see example in figure 2) are published to an elec-tronic mailing list,12 on the web,13 and in 19 cate-gory-specific RSS feeds plus one aggregate RSSfeed.14
TrainingTwo components of NewsFinder are retrained peri-odically. The first is the Categorizer; the other isthe Duplicate Story Detector.
Categorizer TrainingNewsFinder categorizes a story in one or more ofthe 19 categories shown on the AITopics website:AI overview, agents, applications, cognitive sci-ence, education, ethics, games, history, interfaces,machine learning, natural language, philosophy,reasoning, representation, robots, science fiction,speech, systems, and vision.
In an earlier version of NewsFinder (Dong,Smith, and Buchanan 2011), we trained 19 sepa-rate centroids (a centroid is a normalized sum of tf-idf document vectors of the members of some cat-egory), and predicted that a news story was amember of a category if the cosine similarity (dot-product) of that category centroid and the story’sdocument vector Xi surpassed a threshold. Thiscentroid classification is similar to that describedby Han and Karypis (2000) and commonly foundin the information retrieval literature. However, itperformed poorly on our corpus. We found thatour 19 centroids were not well separated, likely dueto the fact that news stories naturally fall into morethan one category and the categories themselvesare not widely separated.
Thus, we changed our approach and trained aseparate SVM for each of the 19 categories.15 Sup-port vector machines, widely used for supervised
learning for classification, regression, or othertasks, construct a hyperplane or set of hyperplanesin a high-dimensional space (Burges 1998). Theyhave been applied with success in information-retrieval problems particular to text classification.Recent studies (Dumais et al. 1998; Joachims 1998;Zhang, Tang, and Yoshida 2007; Zaghloul, Lee, andTrimi 2009) have shown that SVMs lead to bettertext classification than BPNN, Bayes, Rocchio,C4.5, and kNN techniques.
Each SVM is trained on positive and negativeexamples from the corpus of saved stories andmakes a binary prediction for a single category. Wedo not limit the number of predicted categories fora story, though generally a story matches 1–4 cate-gories. Validation of our categorization procedureis presented later.
Duplicate Story Detector TrainingSome events in the world of AI are reported by sev-eral news sources. For example, recently IBM show-cased its SyNAPSE chips, which are designed tomimic some aspects of a brain. NewsFinder foundsix news articles, published over a four-day period,which contained essentially the same informa-tion.16 Clearly, it is important to publish, at most,only one story among the duplicates.
NewsFinder’s duplicate detection is based on thecosine similarity measure of document vectors.The training procedure involves finding a globalthreshold that minimizes false positives and max-imizes true positives. If two stories have a cosinesimilarity greater than or equal to this threshold,and the stories were published within two weeks ofeach other, then they are considered duplicates.
Alternative techniques for detecting duplicatesinclude the shingling algorithm (Broder et al. 1997)and locality sensitive hashing (Charikar 2002). (SeeKumar and Govindarajulu [2009] for recentprogress in this field.) We chose to use a tf-idf doc-ument vector model for its simplicity and speed.Validation of this technique is presented later.
AdministrationWe recognized early in the development of News-Finder that it is wise to maintain editorial oversightso that the software does not publish offensive orirrelevant stories. Given that the software obtainsits inputs from the web, whose content is unpre-dictable, there is a possibility that a web pagemeets NewsFinder’s filtering and publishing crite-ria but is nonetheless outside the scope of AI in theNews. Thus, we built the AINewsAdmin interface(figure 3), which allows administrators to remove anews story or modify a story’s title, publicationdate, categorization, and summary in case thesefields were erroneously extracted from the story.These modifications can be performed before the
Articles
SUMMER 2012 47

story is posted in AI in the News or distributed inthe email alert.
The interface also enables administrators to addpositive and negative examples to the categoriza-tion training corpus. The training corpus containsstories deemed relevant to AI in the News readers.For each category, positive examples are those sto-ries that have been tagged with that category by
an administrator; negative examples are storiesthat do not have that category’s tag. We believethat any person who is knowledgeable about asubset of our 19 categories can determine if a sto-ry is related to categories in that subset. Addingtraining examples to the corpus need not requireany understanding of automated text classifica-tion.
Articles
48 AI MAGAZINE
Figure 3. AINewsAdmin Interface.

In addition to adding examples to the trainingcorpus, an administrator can choose to mark a sto-ry as irrelevant and thereby ensure it is kept out ofthe training corpus.
Not all administrative tasks have been capturedby the AINewsAdmin interface. The word blacklistand the URL blacklist may need to be updated. Asadditional credible news sources are identified,they need to be added to the set of crawled sources.And publication criteria, such as how many storiesto publish per category, may need to be modified iftoo many stories are seen to appear in one catego-ry. Each of these modifications can only be per-formed by editing configuration files or programcode, and the modifications are not yet possiblethrough an efficient online interface (see the side-bar “There’s More Than AI”).
Validation, Use, and PayoffAs described previously, NewsFinder utilizes 19trained support vector machines that model the 19AITopics categories, a trained numeric thresholdused by the duplication detector, and heuristicpublication criteria. We validate each subsystem inturn, then show how widely AI in the News is readand discuss the payoff of developing the News-Finder software.
Support Vector Machines for CategorizationThe task of choosing one or more categories for anews story is known as multilabel classification. Asimple approach to this problem is to build a sep-arate model for each label. This is our approach aswell: we train one support vector machine for eachlabel (category). Additionally, we utilize the featureselection algorithm of Chen and Lin (2006) inorder to reduce the feature space for the SVM mod-els. Our feature space consists of (stemmed) wordsfound in news stories. Each SVM is trained fromabout 3000 examples (mostly negative examples),which results in about 37,000 distinct words or fea-tures. We determined that most of these wordscontribute virtually no information about the cat-egory membership of a news story, so one may findlittle benefit in using all 37,000 words during SVMtraining (and removing a majority of the wordsfrom the training data may reduce overfitting).Additionally, training an SVM requires significantcomputational resources (one of the major draw-backs of an SVM model), and limiting the featurespace reduces this cost.
NewsFinder’s feature selection algorithm com-putes the F-score17 of each feature (stemmed word)and then sorts the features according to this F-score. With experimentation we found that train-ing with only the top 9000 features (about one-quarter of the unique stemmed words found in the
corpus) performed best across all categories, and isconsiderably faster.
All 19 SVMs are trained in this way, independ-ently of each other. For validation, we trained eachSVM on 10 percent, 50 percent, and 90 percent of2940 news stories from the past 10 years (whichwere categorized by a human). We tested on anonoverlapping 10 percent of these stories. Addi-tionally, the results (shown in table 1) are averagedover three random training/testing subsets.
The results show that the SVM method of bina-ry category membership is highly accurate in mostcategories. Less accurate is the applications catego-ry, likely because a large number of articles in thecorpus are labeled with that category (among oth-
Articles
SUMMER 2012 49
There’s More Than AIThe raison d’être of the Innovative Applications of Artifi-cial Intelligence (IAAI) conference is to highlightdeployed applications whose value depends on the use ofAI technology. NewsFinder fits this bill: the service hasbeen active for several months and depends on several AIcomponents in order to do its job.
However, what is especially interesting about deployedAI applications is that significant effort, if not the major-ity of effort, is often spent developing and maintainingthe non-AI parts of the system. NewsFinder is no differ-ent; much human intelligence is required on a regularbasis in order to maintain the system and keep the AIcomponents functioning.
NewsFinder requires a variety of parsers and filters inorder to extract useful content (such as a news story’stext) and to keep out spam or otherwise unwanted con-tent (such as links to other stories, comments, copyrightnotices, and so on). As of yet, there is no completely auto-mated system that can consistently extract useful contentfrom the web. Websites change formats, and heuristictext extractors sometimes fail to distinguish a story’smain text from unmoderated reader comments.
Thus, each week the NewsFinder administrators studythe performance of the software and consider modifyingthe word blacklist, the URL blacklist, the whitelist, andthe news sources and search terms. They also determineif parsers must be updated in response to source websiteredesigns. Before the AI components of NewsFinder areretrained, administrators also have the option to “cleanup” the news stories by modifying their content, titles, orcategories.
Even though NewsFinder is clearly an application of AItechniques, human intelligence remains a critical com-ponent of the overall system.

er categories), in part due to reporters’ tendency towrite about present or future applications.
Duplicate Story DetectorAs described previously, the duplicate story detec-tor considers one story to be a duplicate of anoth-er if the cosine similarity of the stories exceeds athreshold. Recall that stories are represented as tf-idf vectors; because the tf-idf measure is alwaysnonnegative, the cosine similarity, which is simplythe dot product of the document vectors, is alwaysbetween 0.0 and 1.0. Thus, the threshold thatdetermines whether two stories are duplicates isalso between 0.0 and 1.0.
One hundred thresholds between 0.01 and 1.0(inclusive) were evaluated on a corpus of 1173news stories, 489 of which have been manuallylabeled by an administrator as duplicates of one ormore others (resulting in 1392 duplicate pairs). Theprecision, recall, and F1 score resulting from test-ing with each threshold were measured, and thethreshold that maximizes the F1 score was ulti-mately chosen. In our experiments, this thresholdis 0.17. Table 2 shows the performance for thisthreshold.
Publishing CriteriaTo ensure that only interesting and relevant newsstories are published by NewsFinder, the heuris-tics described previously are employed to find thebest stories among the large set obtained eachweek by the automated crawlers. Here we evaluatethe performance of these heuristics. We define“true positive” stories as those that NewsFinderpublished and that a human administrator indi-cated as interesting and relevant. “False positive”stories were published by NewsFinder but anadministrator indicated they should not havebeen published. “True negative” stories were notpublished and an administrator agreed and “falsenegative” stories were not published but anadministrator indicated that they should havebeen. (Note that “false negative” stories are onlythose that NewsFinder crawled but failed to pub-lish.) Table 3 shows the performance of the publi-cation criteria. NewsFinder achieves high preci-sion but relatively low recall. However, becausemany readers receive the news in their emailinbox, we feel that high precision (fewer irrele-vant stories) is more important than high recall(more stories each week).
UseNewsFinder publishes its weekly news on theAITopics website, in 1 aggregate and 19 topic-spe-cific RSS feeds, and through the AI-Alert electronicmailing list. Usage statistics for these channelsshow that we are reaching many readers. The
Articles
50 AI MAGAZINE
Category (SVM) Average Accuracy for Percentage of Corpus
10% 10% 90 % AI Overview 88.3% 89.3% 90.0%
Agents 91.3 91.3 92.7
Applications 76.7 76.0 78.0
Cognitive Science 93.7 94.3 94.0
Education 96.0 96.3 98.0
Ethics 88.3 88.0 90.0
Games 89.3 94.7 96.3
History 90.0 91.3 90.7
Interfaces 90.7 90.7 91.0
Machine Learning 85.7 87.3 88.3
Natural Language 91.0 92.0 91.3
Philosophy 97.3 97.7 97.3
Reasoning 96.7 95.7 95.0
Representation 97.3 97.7 97.7
Robots 86.3 89.3 90.0
Science Fiction 93.3 92.3 94.0
Speech 93.7 95.7 95.3
Systems 95.7 95.7 95.0
Vision 90.0 92.7 93.7
True Positive False Positive Precision Recall F118
992 207 0.827 0.712 0.766
True Positive
True Negative
False Positive
False Negative
Precision Recall F1
191 523 15 118 0.93 0.62 0.74
Table 1. SVM Accuracy Scores Per Category.
The feature size was fixed at 9000 (details are in the accompanying text).Results are shown for training on 10 percent, 50 percent, 90 percent of the cor-pus. Each cell reports an average of training accuracies (percent) across threerandom subsets of the corpus.
Table 2. Performance of Duplicate Detection.
As judged by one administrator, with threshold equal to 0.17.
Table 3. Performance of NewsFinder’s Publication Criteria.
“Interesting and relevant” stories (that is, stories that should be published)are considered positive examples. Stories under consideration range fromAugust 21, 2011, to March 06, 2012 (N = 847).
AITopics website had a total of 20,945 unique visi-tors in the 30 days ending on March 6, 2012; theAINews page in particular (which is where News-Finder publishes its news) had 879 unique visitorsin the same time period. The aggregate RSS feedhad 185 subscribers as of March 6, 2012. Finally,the AI-Alert weekly email was received by 916inboxes.
At this time, we are soliciting more feedbackfrom readers in the form of ratings, to be used infuture training. We ask in the email and on thewebsite that users rate each news story on a scale of0–5, where 0 means the story is irrelevant to AI,and 5 means the story is highly relevant. We havealso installed Facebook “Recommend” and Twitter“Tweet” buttons on news items to further engageour audience.
PayoffThe cost of developing the program was studentstipends for two and a half summers, plus volun-
teered time by two senior AI scientists. All softwarelibraries used in the development of NewsFinderand the associated AITopics website are free andopen source. Maintenance is overseen by volun-teers. However, programmers must be hired to con-sult on major problems when they arise. Before theAI in the News service was automated by News-Finder, about 10 hours a week was required for awebmaster to find, categorize, summarize, and pub-lish AI-related news. The savings introduced byautomating this service offsets the 2.5 studentstipends in a year or less. Additional benefits accruefrom the consistency and reliability of an automat-ed service plus the unquantifiable benefits of pro-viding useful information to the AI community.
Comparison with Google NewsProbably the most widely used news retrieval serv-ice is Google News,19 which finds stories published
Articles
SUMMER 2012 51
Query Top story on Google News Source
Arti!cial Intelligence *iOS 5 Voice Assistant to Be “World Changing” InformationWeek
Autonomous Vehicle Are Autonomous Vehicles Bad News for Fleets?
Hitachi Capital Vehicle Solutions
Cognitive Science Key to Greatness Is Working Memory, Not Practice PsychCentral.com
Computer Vision Commentary: Steve Jobs’s Remarkable Vision and Legacy Kansas City Star
Image Understanding
European Space Agency Selects First Two “Cosmic Vision” Missions Gizmag
Intelligent Agent *Apple’s Siri Is the Ful!llment of a Dream from 1987 Telegraph.co.uk
Machine Learning Kuzman Ganchev: John Atanasoff Award Is Great Honor to Me Focus News
Machine Translation
*Bing Powers New Facebook Page Post Translation Tool Inside Facebook
Neural Network *Elliot Wave: Extracting Extremes and Predicting Next One by Neural Network Technorati
Pattern Recognition
Pattern Recognition: How to Find and Photograph Interesting Patterns Tecca
Robots Movie Review: “Real Steel Los Angeles Times
Science Fiction It Has Robots, but Is Real Steel Real Science Fiction? Wired News
Speech Recognition
*Apple Gets Edge with Use of Voice-Recognition Technology USA Today
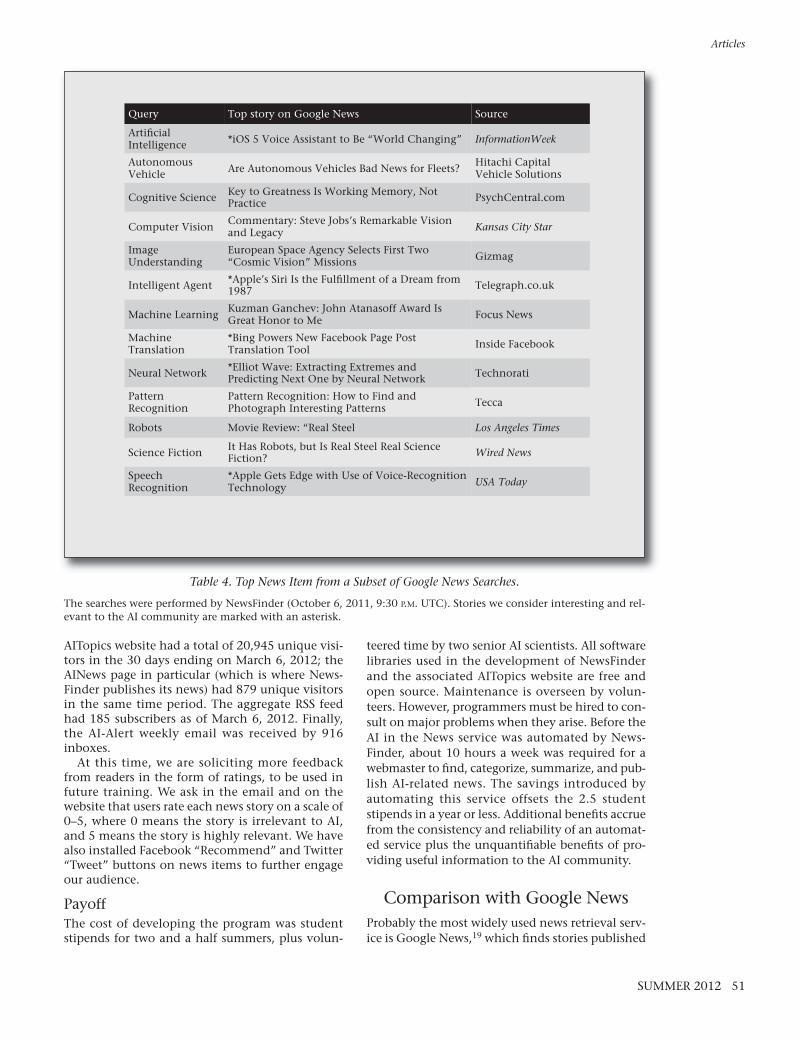
Table 4. Top News Item from a Subset of Google News Searches.
The searches were performed by NewsFinder (October 6, 2011, 9:30 P.M. UTC). Stories we consider interesting and rel-evant to the AI community are marked with an asterisk.

within the last 30 days. These are selected byquery-driven search and ranked with a proprietaryalgorithm. Because of its widespread use, we com-pare NewsFinder with this service.
Although the actual list of Google News sourcesis not published, the stated information fromGoogle is that it crawls more than 4500 English-language sources20 and altogether more than25,000 sources in 19 languages around the world.21
Though the news sources are manually selected byhuman editors, Google News employs a news rank-ing algorithm that considers user clicks (populari-ty), the estimated authority of a publication in aparticular topic (credibility), freshness, and geog-raphy to determine which stories to show.22
Because Google News obtains news stories frommany sources, NewsFinder actually performs sev-eral searches on Google News in order to find newsstories beyond those found in our 37 human-selected sources. Including Google News as aresource enhances the breadth of AI in the News.
NewsFinder does not simply republish GoogleNews stories. As with all stories NewsFinderobtains, Google News stories are filtered accordingto topic-specific heuristics, then categorized andchecked for duplication, and finally summarizedand ranked. Google News performs duplicatedetection (though we cannot use their algorithmson our own crawled stories). The two systems donot use comparable ranking heuristics or compa-rable categories for stories beyond high-level cate-gories (technology, entertainment, science, andothers.).
To illustrate differences between Google News
and NewsFinder, we conducted a sample of theGoogle News searches that NewsFinder consults,and picked out the top result for each search.(Blogs and press releases, as indicated by GoogleNews, were skipped, as were news stories olderthan seven days, since blogs, press releases, and oldstories are also skipped by NewsFinder.) This exper-iment is an attempt to simulate a user who iswatching several news feeds related to AI. BecauseGoogle News searches are user-initiated, one mayimagine that readers of Google News are more for-giving if search results are irrelevant or uninterest-ing. NewsFinder, on the other hand, delivers thenews in readers’ inboxes (among other outlets),and thus must maintain relatively high precision.The AINewsAdmin interface allows human over-sight of NewsFinder’s output, while Google News iscompletely automated.
Results from searches on Google News areshown in table 4. NewsFinder was executed at thesame time the Google News searches were per-formed; its output is shown in table 5. The timeand date of the experiment are arbitrary.
We see that Google News returns some irrele-vant stories such as “Commentary: Steve Jobs’sRemarkable Vision and Legacy”23 for the “comput-er vision” query. On the other hand, NewsFindermissed some stories that we consider interestingand relevant to AI that Google News did find. Onecase is the story “Bing Powers New Facebook PagePost Translation Tool,”24 which describes howmachine translation will be further integrated intoFacebook, allowing users to communicate witheach other across disparate languages. NewsFinder
Articles
52 AI MAGAZINE
Categories (Chosen by NewsFinder) Title Source
Natural Language, Speech Siri for iPhone 4S iProgrammer through Google News
Cognitive Seience, Interfaces, Robots
Monkeys Use Brain Interface to Move and Feel Virtual Objects
IEEE Spectrum
Robots Spin-Based Magnetologic Gate to Replace Silicon Chips
KurzweilAI
Machine Learning Software to Prevent Abuse at the Click of a Mouse
PhysOrg.com through Google News
Interfaces, Robots Ready for the Robot Revolution? BBC News through Google News
Speech Has the Last Fence Fallen? Outperforming Human Emotional Sensitivity
Innovation Investment Journal through Google News
Table 5. NewsFinder’s Complete Published News, Ordered by NewsFinder’s Ranking.
(October 6, 2011, 9:30 P.M. UTC). Note that every story in this table was categorized as “applications” in addition to the indicated categories;we hide the “applications” category label in published news because most published stories each week match that category.

did crawl this story but only found the whitelistedterm “machine translation,” and no otherwhitelisted terms. NewsFinder’s publication crite-ria require that at least two distinct whitelistedterms be found in a story. An administrator maychoose to alter the whitelist so that stories such asthis one are published in the future; however,modifying the whitelist or other heuristics affectsNewsFinder’s overall accuracy, and this impact isoften unpredictable.
We believe that the comparison of Google Newssearch results with (unmodified) NewsFinder out-put shows that NewsFinder, and the AI in the Newsservice, has a higher signal-to-noise ratio than acollection of query-driven news feeds. GoogleNews’s lower signal-to-noise ratio may be accept-able to a reader who wants the flexibility of search-ing for news through specific queries. NewsFinder,on the other hand, is not flexible in this way. How-ever, because it is designed specifically to find AI-related news, the quality of news published byNewsFinder generally exceeds that of a collectionof Google News searches.
Conclusions and Future WorkReplacing a time-consuming, yet intelligent, man-ual operation with an AI-enhanced system is a nat-ural project for AAAI. The AI in the News servicewas the subject of this exact line of thought, andthe success of the NewsFinder system demon-strates that automating such a task is both feasibleand advantageous.
Several design decisions have made NewsFinderan effective yet relatively inexpensive AI project.We used open source and free software for impor-tant features like support vector machine training,natural language processing, data storage, webcrawling, and website content management. Sev-eral heuristics and human oversight are built intothe system to ensure high-quality output. Addi-tionally, because NewsFinder attempts to cast abroad net, we implemented strict filters so that itcan provide information that is both relevant andextensive.
Finally, although NewsFinder presently seeksout AI-related news, there is no aspect of its designthat intentionally restricts its domain to AI. Primafacie, the requirements to apply the system toanother domain are: subject matter experts toserve as administrators; a set of topics that charac-terize the domain; a corpus of news stories to trainthe topic-specific support vector machines; and awhitelist, blacklists, and source-specific parsers.However, one might expect to encounter hiddeninterdependencies of the heuristics and other com-ponents of NewsFinder that would initially com-plicate adaptation to a new domain.
The system should continue to improve over
time as additional training examples are added toits corpus, but work remains to be done to makemore of NewsFinder accessible to automated learn-ing. Other improvements we would like to pursueinclude more useful analytical tools such as theability to determine how strongly whitelist wordsare correlated to category membership, how cate-gory membership relates to news sources (forexample, do some news sources always deliverrobot stories?), and whether certain categories are“trending” over time (for example, is cognitive sci-ence becoming a hot news topic and, if so, why).
NewsFinder was constructed for the Associationfor the Advancement of Artificial Intelligence fromopen-source modules at low cost and supplies aneffective service for the AI community.
AcknowledgmentsWe are grateful to Tom Charytoniuk for imple-menting the initial prototype of this system and toJim Bennett for many useful comments, especiallyon the Netflix rating system after which the News-Finder user feedback mechanism is modeled.
Notes1. NewsFinder’s code is available at github.com/AAAI.
2. See aaai.org/AITopics/AINews.
3. See news.google.com.
4. We use a modified version of the MIT list of 583 terms,available at jmlr.csail.mit.edu/papers/volume5/lewis04a.
5. The full list of sources can be found at aaai.org/AITopics/NewsSources.
6. See Justext, code.google.com/p/justext.
7. News may be submitted at www.aaai.org/AITopics/Sub-mitNewContent.
8. We use a modification of this blacklist. See urbanoal-varez.es/blog/2008/04/04/bad-words-list/.
9. See github.com/AAAI/AINewsSupplementary/blob/master/resource/whitelist.txt.
10. See www.aaai.org/AITopics/NewsSources for the fulllist of sources and their preference ratings.
11. Available at libots.sourceforge.net.
12. See www.aaai.org/AITopics/mailinglist. To preventspam, the AAAI distribution-list server does not allowautomatic sending of email. Thus a member of the AAAIstaff must manually send a prepared message to sub-scribers each week.
13. See www.aaai.org/AITopics/AINews.
14. See www.aaai.org/AITopics/AINews#feeds.
15. We use the LibSVM open source library (Chang andLin 2011) for its extensive programming language sup-port and speed.
16. Visit www.aaai.org/AITopics/AIArticles/2011-2669 tosee the list of duplicate SyNAPSE stories found by News-Finder.
17. A feature with a larger F-score is more discriminative,with respect to a certain binary SVM. Details can befound in Chen and Lin (2006).
18. Precision = TruePos/(TruePos+FalsePos). Recall = True-Pos/(TruePos+FalseNeg). F1 = 2*(Precision*Recall)/(Preci-
Articles
SUMMER 2012 53

sion+Recall); note that this F1 score is not related to theF-score used to select features for the SVMs.
19. See news.google.com.
20. See en.wikipedia.org/wiki/Google_News.
21. See googlenewsblog.blogspot.com/2009/12/same-protocol-more-options-for-news.html.
22. See searchengineland.com/google-news-ranking-sto-ries-30424.
23. See www.kansascity.com/2011/10/06/3190839/com-mentary-steve-jobs-remarkable.html.
24. See www.insidefacebook.com/2011/10/05/bing-trans-late-pages.
ReferencesBroder, A. Z.; Glassman, S. C.; Manasse, M. S.; and Zweig,G. 1997. Syntactic Clustering of the Web. Computer Net-works and ISDN Systems 29(8–13): 1157–1166.
Buchanan, B. G.; Smith, R. G.; and Glick, J. 2008. TheAAAI Video Archive. AI Magazine 29(1): 91–94.
Burges, C. J. C. 1998. A Tutorial on Support VectorMachines for Pattern Recognition. Data Mining andKnowledge Discovery 2(2): 121–167.
Chang, C.-C., and Lin, C.-J. 2011. LIBSVM: A Library forSupport Vector Machines. ACM Transactions on IntelligentSystems and Technology (TIST) 2(3): 27–53.
Charikar, M. S. 2002. Similarity Estimation Techniquesfrom Rounding Algorithms. In Proceedings of the Thirty-fourth Annual ACM Symposium on Theory of Computing,380–388. New York: Association for Computing Machin-ery.
Chen, Y.-W., and Lin, C.-J. 2006. Combining SVMs withVarious Feature Selection Strategies. Feature Extraction:Studies in Fuzziness and Soft Computing 207: 315–324.
Dong, L.; Smith, R. G.; and Buchanan, B. G. 2011. News-Finder: Automating an Artificial Intelligence News Serv-ice. In Proceedings of the Twenty-Third IAAI Conference onInnovative Applications of Artificial Intelligence (IAAI 11).Palo Alto, CA: AAAI Press.
Dumais, S.; Platt, J.; Heckerman, D.; and Sahami, M.1998. Inductive Learning Algorithms and Representa-tions for Text Categorization. In Proceedings of the SeventhInternational Conference on Information and KnowledgeManagement (CIKM 98), 148–155. New York: Associationfor Computing Machinery.
Han, E.-H. S., and Karypis, G. 2000. Centroid-Based Doc-ument Classification: Analysis and Experimental Results.In Principles of Data Mining and Knowledge Discovery, 116–123. Berlin: Springer.
Joachims, T. 1998. Text Categorization with Support Vec-tor Machines: Learning with Many Relevant Features. InProceedings of the 10th European Conference on MachineLearning, 137–142. Berlin: Springer.
Kumar, J. P., and Govindarajulu, P. 2009. Duplicate andNear Duplicate Documents Detection: A Review. EuropeanJournal of Scientific Research 32(4): 514–527.
Loper, E., and Bird, S. 2002. NLTK: The Natural LanguageToolkit. In Proceedings of the ACL Workshop on EffectiveTools and Methodologies for Teaching Natural Language Pro-cessing and Computational Linguistics, 63–70. Philadelphia,PA: Association for Computational Linguistics.
Salton, G., and Buckley, C. 1988. Term-Weighting
Approaches in Automatic Text Retrieval. Information Pro-cessing and Management 24(5): 513–523.
Yatsko, V. A., and Vishnyakov T. N. 2007. A Method forEvaluating Modern Systems of Automatic Text Summa-rization. Automatic Documentation and Mathematical Lin-guistics 41(3): 93–103.
Zaghloul, W.; Lee, S. M.; and Trimi, S. 2009. Text Classifi-cation: Neural Networks Versus Support VectorMachines. Industrial Management and Data Systems 109(5):708–717.
Zhang, W.; Tang, X.; and Yoshida, T. 2007. Text Classifi-cation with Support Vector Machine and Back Propaga-tion Neural Network. In Proceedings of the Seventh Interna-tional Conference on Computational Science (ICCS 07),150–157. Berlin: Springer.
Joshua Eckroth is a Ph.D. student at the Ohio State Uni-versity. He is studying artificial intelligence, cognitive sci-ence, and logic. His research focuses on how an abductivereasoning agent may employ novel metareasoning strate-gies to improve its understanding of a changing world.
Liang Dong is a Ph.D. candidate in computer science atthe School of Computing of Clemson University, SouthCarolina. His research interests lie in search engines andthree-dimensional animation. He is expecting to gradu-ate in May 2012. He obtained his M.S. and B.S. in Shang-hai Jiao Tong University in 2007 and 2004, respectively.
Reid G. Smith is the enterprise content managementdirector and IT upstream services manager of MarathonOil Corporation. Prior to joining Marathon, he wasresponsible for information solutions at Medstory. Earli-er, he led the knowledge management program atSchlumberger and managed a number of the company’sresearch laboratories in the United States and the UnitedKingdom. Smith holds a Ph.D. in electrical engineeringfrom Stanford University and is a fellow of the Associa-tion for the Advancement of Artificial Intelligence.
Bruce G. Buchanan is the University Professor of Com-puter Science Emeritus at the University of Pittsburgh.Before joining the Pitt faculty as a professor of computerscience, medicine, and philosophy, he was a professor ofcomputer science (research) at Stanford where he workedon the Dendral, Meta-Dendral, Mycin, and Protean sys-tems. He has supervised more than two dozen Ph.D. dis-sertations in AI and related fields. Buchanan holds aPh.D. in philosophy from Michigan State University; heis a fellow of AAAI and the American College of MedicalInformatics, an elected member of the National Academyof Science Institute of Medicine, and has served as thesecretary-treasurer and president of AAAI.
Articles
54 AI MAGAZINE