nosql - log.in.th · • all nosql offerings relax one or more of the acid properties. database...
TRANSCRIPT

N O S Q L
K A N AT P O O L S A W A S D D E PA R T M E N T O F C O M P U T E R E N G I N E E R I N G
M A H I D O L U N I V E R S I T Y
E G C O 3 2 1 D ATA B A S E S Y S T E M S

W H AT I S N O S Q L ?
• Stands for No-SQL or Not Only SQL. • Class of non-relational data storage systems
• E.g. MongoDB, Neo4j, … • Usually do not require a fixed table schema nor do
they use the concept of joins • Distributed data storage systems
• All NoSQL offerings relax one or more of the ACID properties.
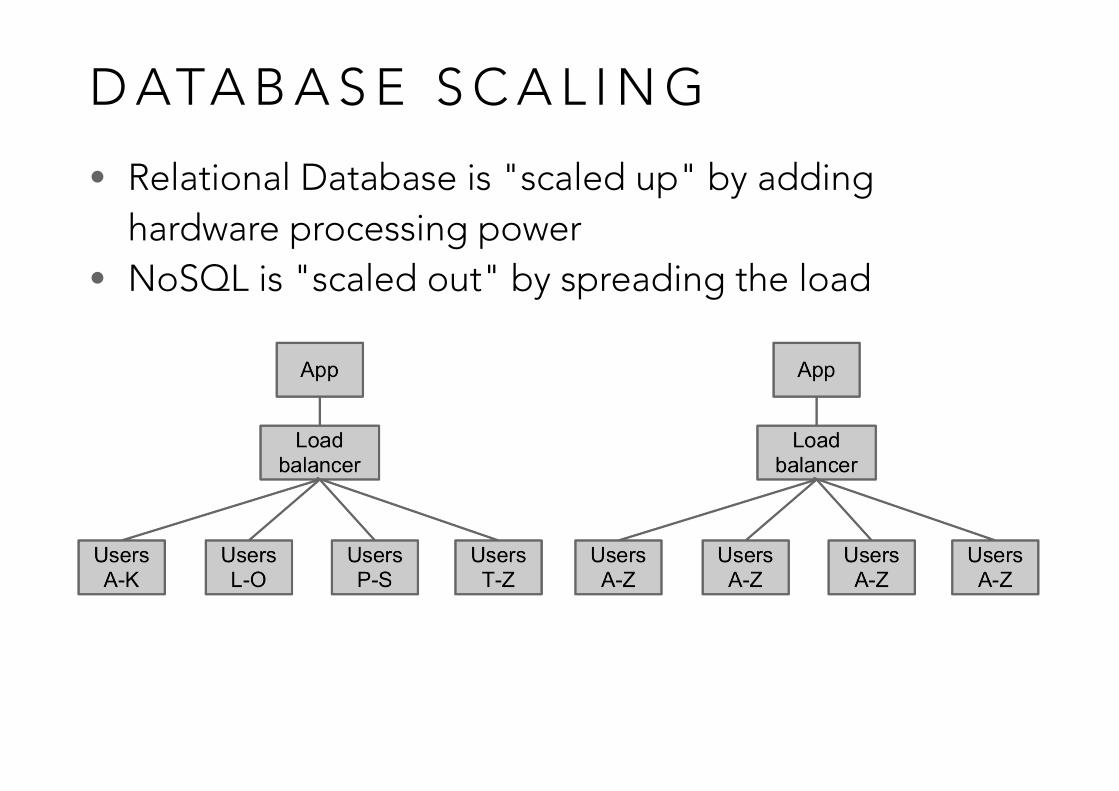
D ATA B A S E S C A L I N G
• Relational Database is "scaled up" by adding hardware processing power
• NoSQL is "scaled out" by spreading the load
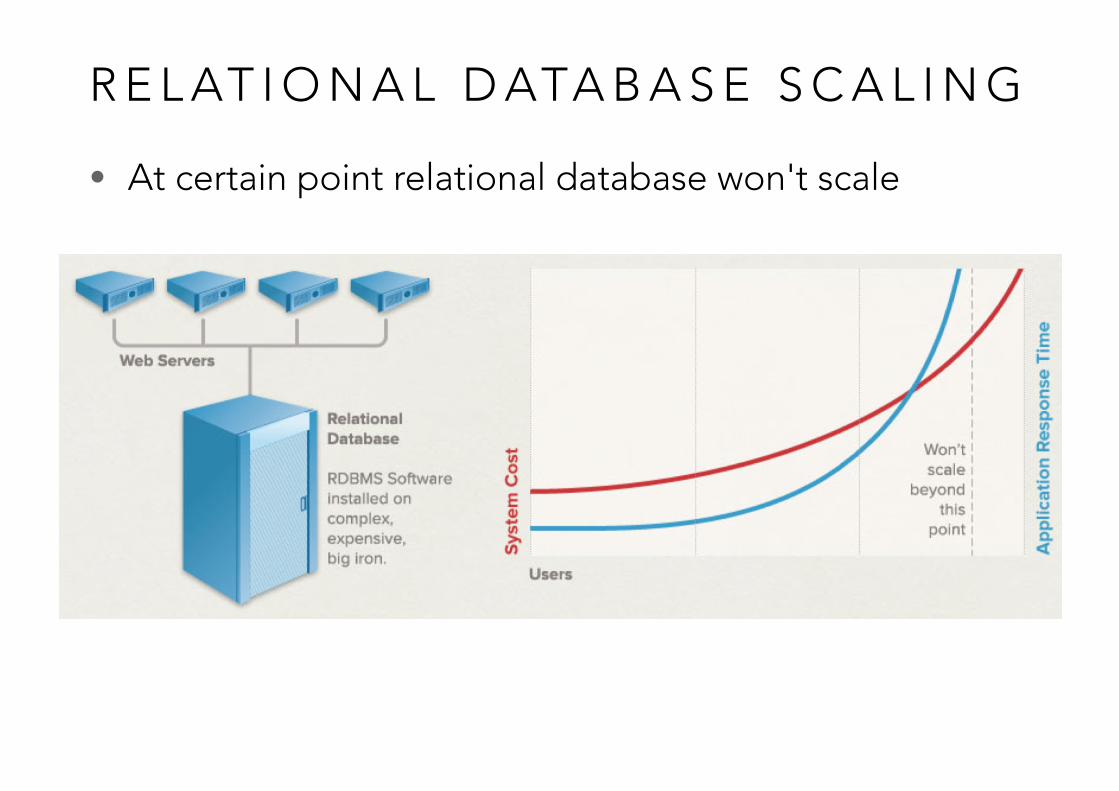
R E L AT I O N A L D ATA B A S E S C A L I N G
• At certain point relational database won't scale

N O S Q L D ATA B A S E S C A L I N G
• Scaling horizontally is possible with NoSQL
• Scaling up / down is easy • Supports rapid
production-ready prototyping
• Better handling of traffic spikes

W H E R E N O S Q L I S U S E D ? • Google (BigTable, LevelDB) • LinkedIn (Voldemort) • Facebook (Cassandra) • Twitter (Hadoop/Hbase, FlockDB, Cassandra) • Netflix (SimpleDB, Hadoop/HBase, Cassandra) • CERN (CouchDB)

C A P T H E O R E M ( 1 )
• It is impossible for a distributed computer system to simultaneously provide all three of the following guarantees: • Consistency (all nodes see the same data at the
same time) • Availability (a guarantee that every request receives
a response about whether it was successful or failed) • Partition tolerance (the system continues to operate
despite arbitrary message loss or failure of part of the system)

C A P T H E O R E M ( 2 )
• In other words, CAP can be expressed as "If the network is broken, your database won’t work”
• In Relational DBMS we do not have P (network partitions) • Consistency and Availability are achieved
• In NoSQL we want to have P • Need to select either C or A • Drop A -> Accept waiting until data is consistent • Drop C -> Accept getting inconsistent data
sometimes
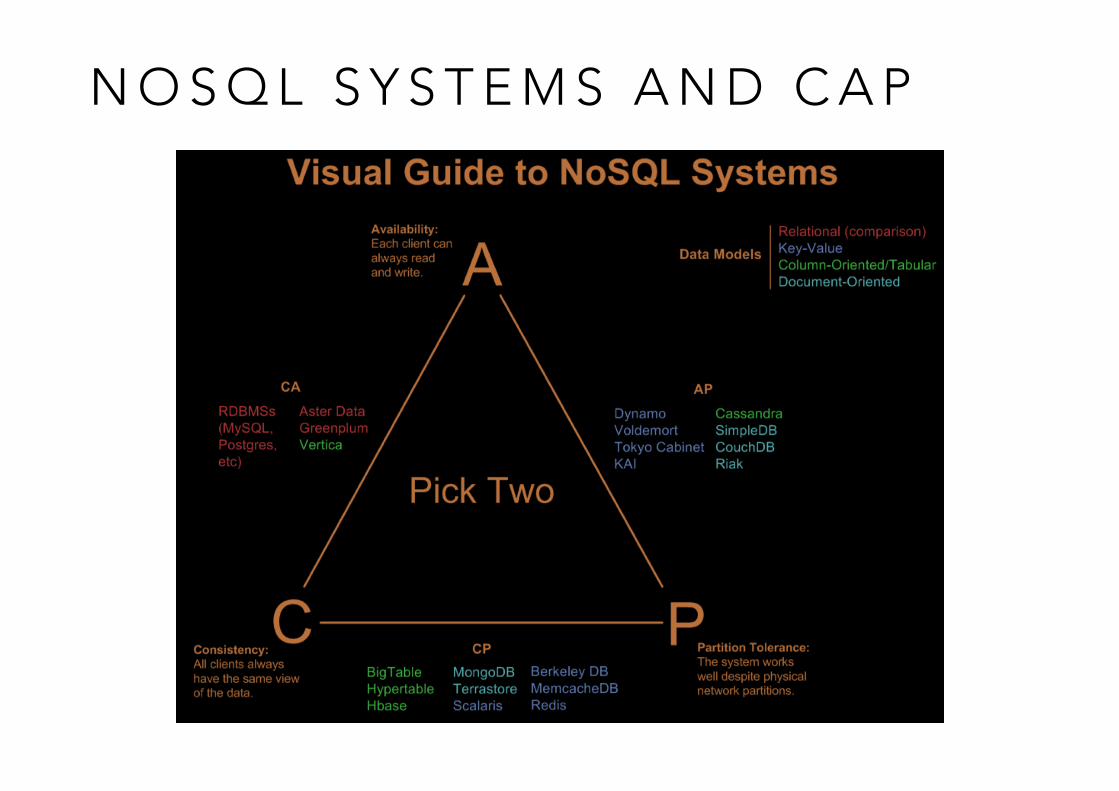
N O S Q L S Y S T E M S A N D C A P
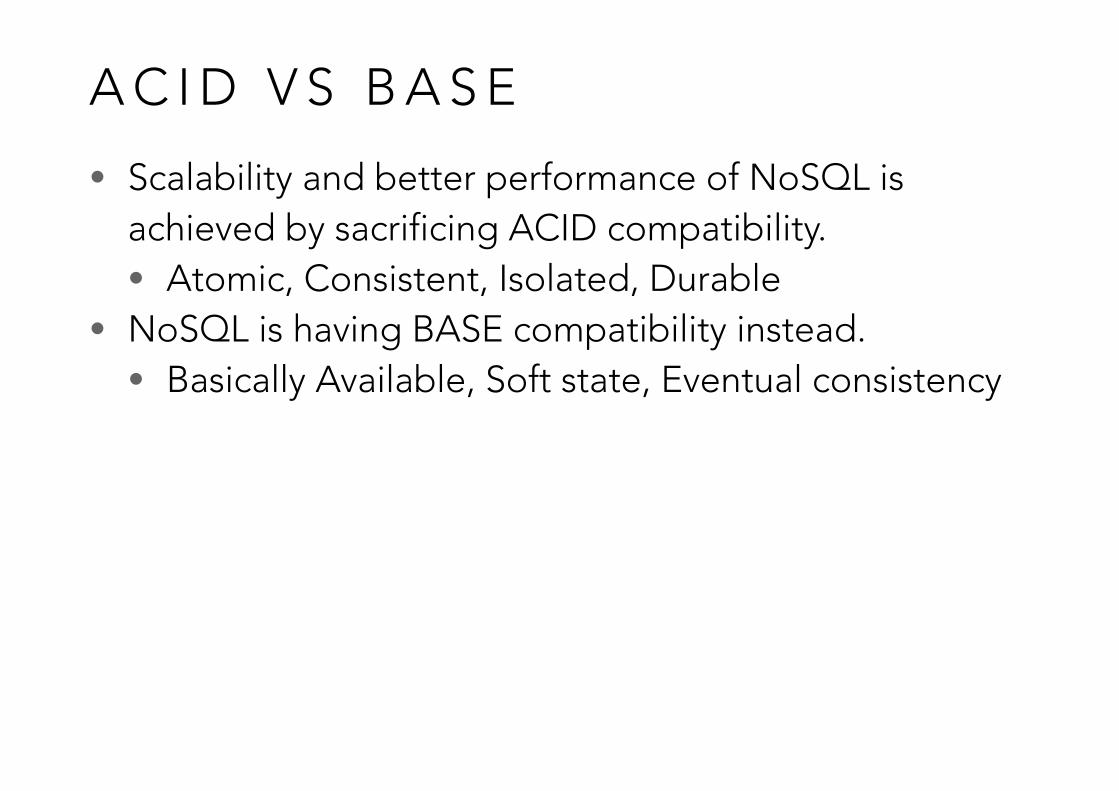
A C I D V S B A S E
• Scalability and better performance of NoSQL is achieved by sacrificing ACID compatibility. • Atomic, Consistent, Isolated, Durable
• NoSQL is having BASE compatibility instead. • Basically Available, Soft state, Eventual consistency

B A S E — B A S I C A L LY AVA I L A B L E
• Use replication and sharding to reduce the likelihood of data unavailability and use sharding, or partitioning the data among many different storage servers, to make any remaining failures partial.
• The result is a system that is always available, even if subsets of the data become unavailable for short periods of time.

B A S E A N D AVA I L A B I L I T Y
• The availability of BASE is achieved through supporting partial failures without total system failure.
• Example. If users are partitioned across five database servers, BASE design encourages crafting operations in such a way that a user database failure impacts only the 20 percent of the users on that particular host. • This leads to higher perceived availability of the
system. Even though a single node is failing, the interface is still operational.

B A S E — E V E N T U A L LY C O N S I S T E N T
• Although applications must deal with instantaneous consistency, NoSQL systems ensure that at some future point in time the data assumes a consistent state.
• In contrast to ACID systems that enforce consistency at transaction commit, NoSQL guarantees consistency only at some undefined future time. • Where ACID is pessimistic and forces consistency at
the end of every operation, BASE is optimistic and accepts that the database consistency will be in a state of flux.

B A S E A N D C O N S I S T E N C Y
• As DB nodes are added while scaling up, need for synchronisation arises
• If absolute consistency is required, nodes need to communicate when read/write operations are performed on a node • Consistency over availability -> bottleneck
• As a trade-off, "eventual consistency" is used • Consistency is maintained later
• Numerous approaches for keeping up "distributed consistency" are available • Amazon Dynamo - consistent hashing • CouchDB - asynchronous master-master replication • MongoDB - auto-sharding+replication cluster with a
master server

B A S E — S O F T S TAT E
• While ACID systems assume that data consistency is a hard requirement, NoSQL systems allow data to be inconsistent and relegate designing around such inconsistencies to application developers.
• In other words, soft state indicates that the state of the system may change over time, even without input. • This is because of the eventual consistency model
(the acronym is a bit contrived).

S O M E B R E E D S O F N O S Q L S O L U T I O N S
• Key-Value Stores • Column Family Stores • Document Databases • Graph Databases • In addition: Object and RDF databases as well as
Tuple stores

K E Y- VA L U E S T O R E S
• Key-Value is based on a hash table where there is a unique key and a pointer to a particular item of data.
• Mappings are usually accompanied by cache mechanisms to maximise performance.
• API is typically simple — implementation is often complex.
• Example: Dynamo, Voldemort, Rhino DHT, etc.

C O L U M N FA M I LY S T O R E S
• Store and process very large amounts of data distributed over many machines. • "Petabytes of data across thousands of servers"
• Keys point to multiple columns • Example: BigTable, Cassandra, HBase, Hadoop

D O C U M E N T D ATA B A S E S ( S T O R E S )
• Documents are addressed in the database via a unique key that represents that document.
• Semi-structured documents can be XML or JSON formatted, for instance.
• In addition to the key, documents can be retrieved with queries.
• Redis is sometimes referred to as data structure server since keys can contain strings, hashes, lists, sets and sorted sets.
• Example: CouchDB, MongoDB, Lotus Notes, Redis, etc.

G R A P H D ATA B A S E S
• Graph Databases are built with nodes, relationships between nodes (edges) and the properties of nodes. • Nodes represent entities (e.g. "Bob" or "Alice").
• Similar in nature to the objects as in object-oriented programming.
• Properties are pertinent information related to nodes (eg. age: 18).
• Edges connect nodes to nodes or nodes to properties. • Represent the relationship between the two.
• Scaling graph DBs is problematic • Neo4J: cache sharding, sharding strategy heuristics
• Example: Neo4J, FlockDB, GraphBase, InfoGrip, etc.

S O M E N O S Q L C H A L L E N G E S
• Lack of maturity — numerous solutions still in their beta stages
• Lack of commercial support for enterprise users • Lack of support for data analysis • Maintenance efforts and skills are required — experts
are hard to find

W H AT I S M O N G O D B ? • Developed by 10gen, founded in 2007 • A document oriented, NoSQL database
• Hash - based, schema - less database • No Data Definition Language • In practice, this means you can store hashes with any keys and
values that you choose • Keys are a basic data type but in reality stored as strings • Document Identifiers (_id) will be created for each document,
field name reserved by system • Application tracks the schema and mapping • Uses BSON format
• Based on JSON – B stands for Binary • Supports APIs (drivers) in many computer languages
• JavaScript, Python, Ruby, Perl, Java, Java Scala, C#, C++, Haskell, Erlang

F U N C T I O N A L I T Y O F M O N G O D B
• Dynamic Schema (No DDL) • Document - based database • Secondary indexes • Query language via an API • Atomic writes and fully - consistent reads
• If system configured that way • Master - slave replication with automated failover
(replica sets) • Built-in horizontal scaling via automated range - based
partitioning of data (sharding) • No joins nor transactions

W H Y U S E M O N G O D B ?• Simple queries • Functionality provided applicable to most web
applications • Easy and fast integration of data (No ERD diagram) • Not well suited for heavy and complex transactions
systems
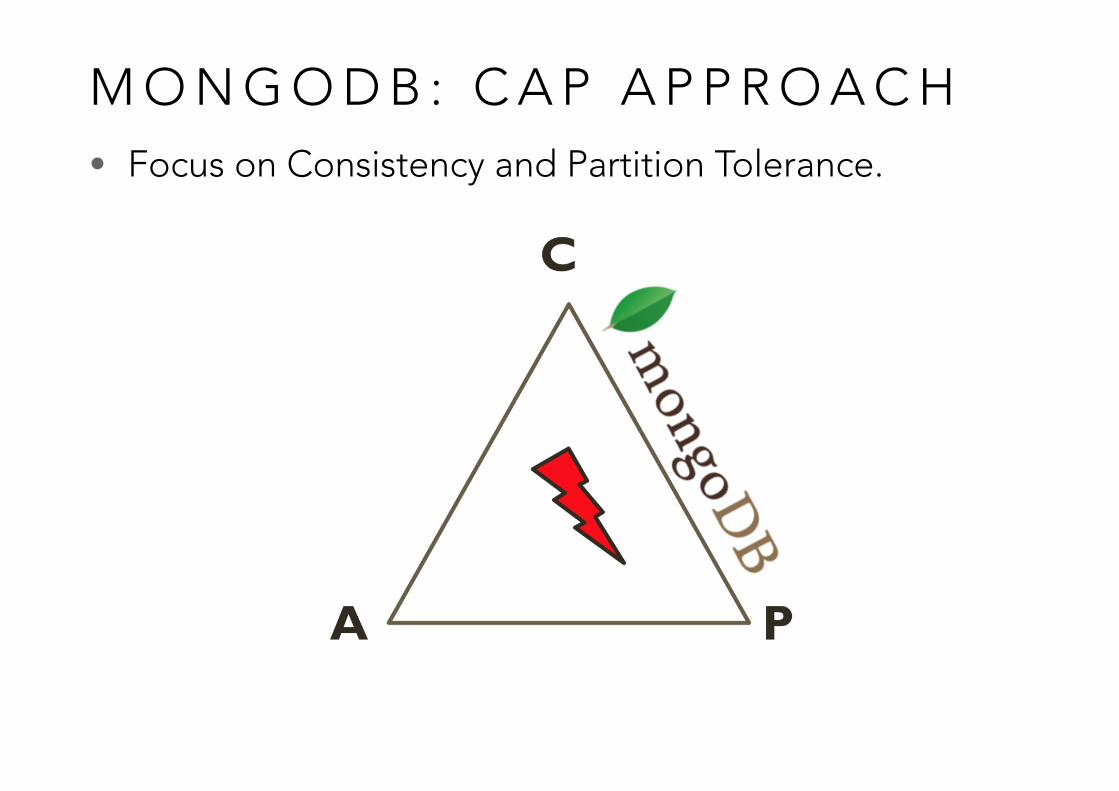
M O N G O D B : C A P A P P R O A C H• Focus on Consistency and Partition Tolerance.
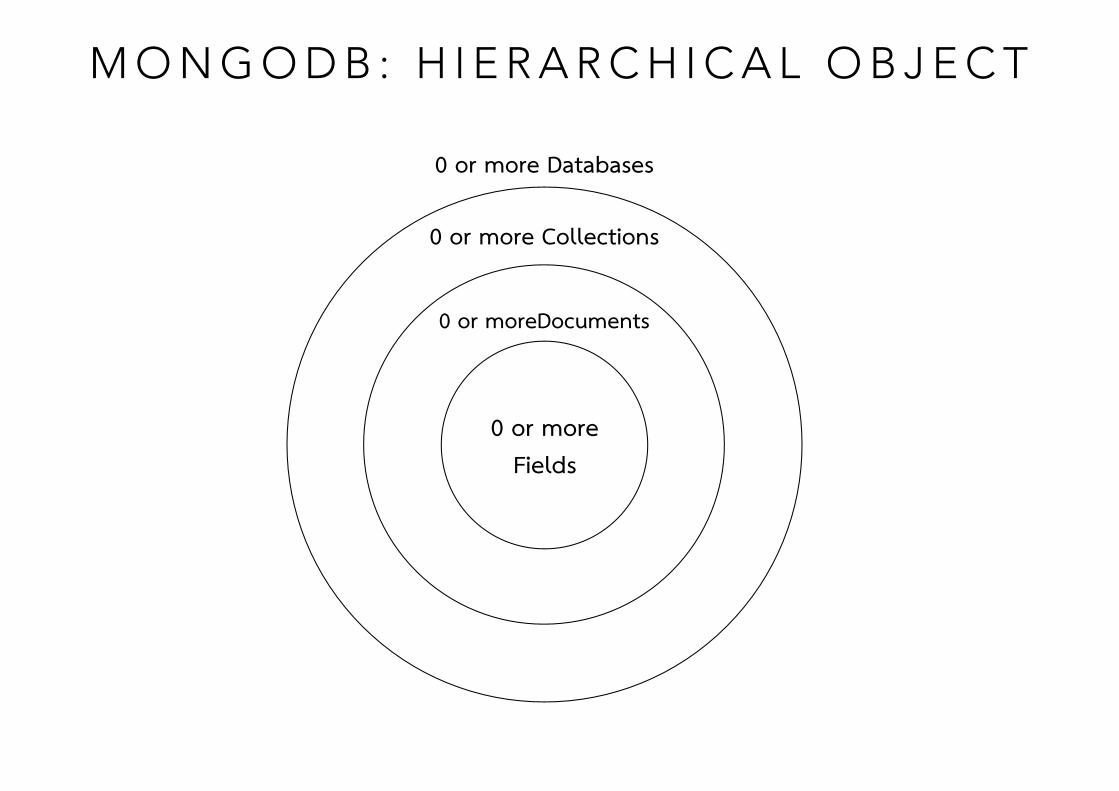
M O N G O D B : H I E R A R C H I C A L O B J E C T
0 or more Fields
0 or moreDocuments
0 or more Collections
0 or more Databases
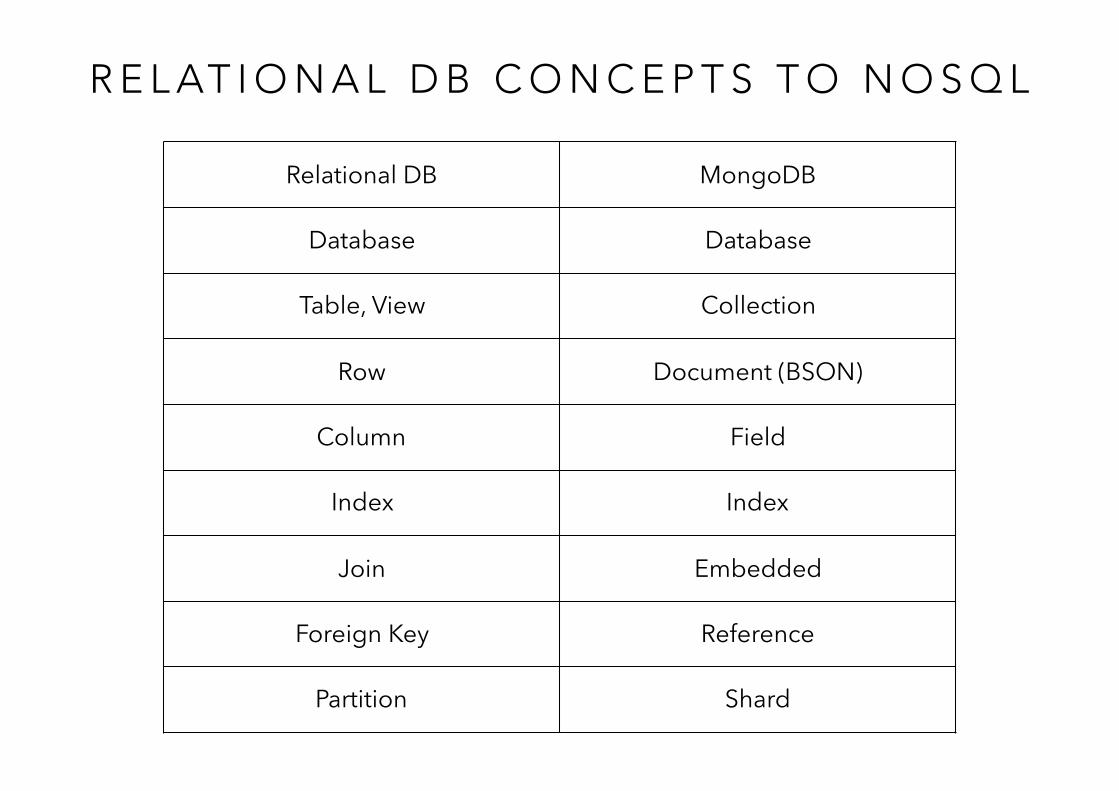
R E L AT I O N A L D B C O N C E P T S T O N O S Q L
Relational DB MongoDB
Database Database
Table, View Collection
Row Document (BSON)
Column Field
Index Index
Join Embedded
Foreign Key Reference
Partition Shard

M O N G O D B P R O C E S S E S A N D C O N F I G U R AT I O N • Mongod – Database instance • Mongos - Sharding processes
• Analogous to a database router. • Processes all requests • Decides how many and which mongod s should receive the
query • Mongos collates the results, and sends it back to the client.
• Mongo – an interactive shell ( a client) • Fully functional JavaScript environment for use with a MongoDB
• You can have one mongos for the whole system no matter how many mongods you have OR you can have one local mongos for every client if you wanted to minimise network latency.

C H O I C E S M A D E F O R D E S I G N O F M O N G O D B • Scale horizontally over commodity hardware
• Lots of relatively inexpensive servers • Keep the functionality that works well in RDBMSs
• Ad hoc queries • Fully featured indexes • Secondary indexes
• What doesn’t distribute well in RDB? • Long running multi - row transactions • Joins • Both artifacts of the relational data model (row x
column)

B S O N F O R M AT
• Binary-encoded serialisation of JSON - like documents • Zero or more key/value pairs are stored as a single
entity • Each entry consists of a field name, a data type, and a
value • Large elements in a BSON document are prefixed with
a length field to facilitate scanning
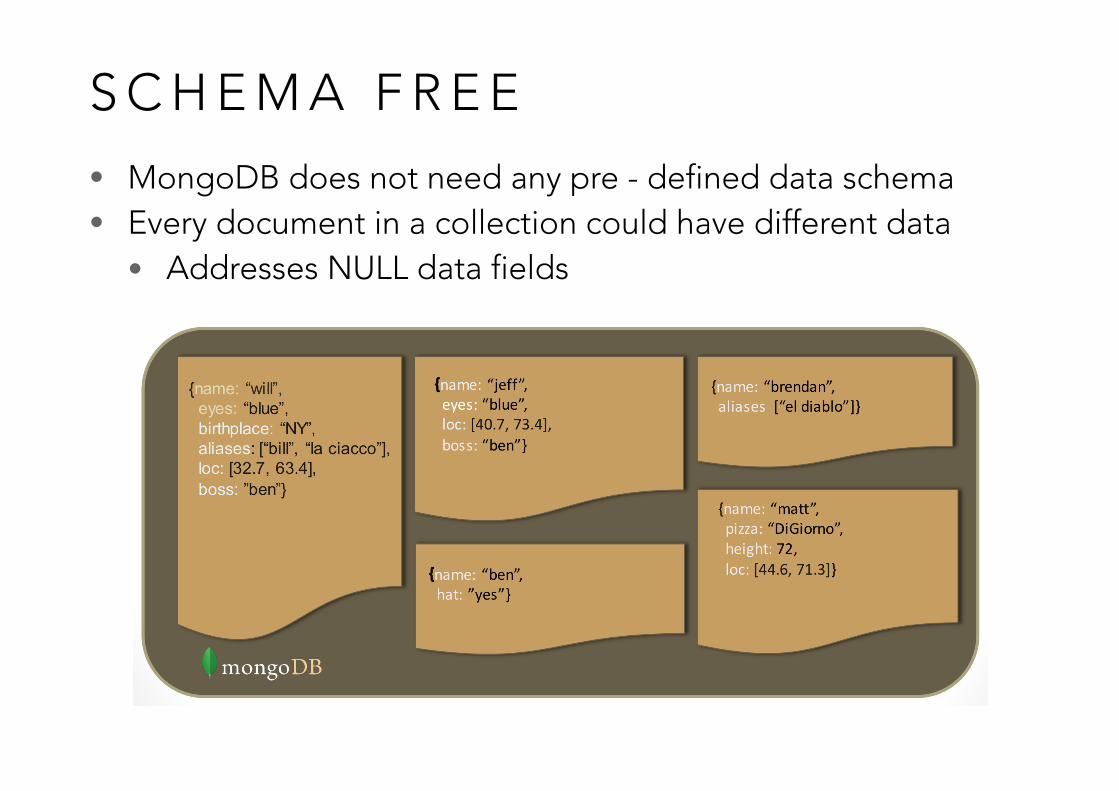
S C H E M A F R E E
• MongoDB does not need any pre - defined data schema • Every document in a collection could have different data
• Addresses NULL data fields

J S O N F O R M AT
• Data is in name/value pairs • Data is separated by commas • Curly braces hold objects • Square brackets hold arrays • Example:
{"employees":[ { "firstName":"John", "lastName":"Doe" }, { "firstName":"Anna", "lastName":"Smith" }, { "firstName":"Peter", "lastName":"Jones" } ]}

J S O N V S . X M L
• JSON Example: {"employees":[ { "firstName":"John", "lastName":"Doe" }, { "firstName":"Anna", "lastName":"Smith" }, { "firstName":"Peter", "lastName":"Jones" } ]}
• XML Example <employees> <employee> <firstName>John</firstName> <lastName>Doe</lastName> </employee> <employee> <firstName>Anna</firstName> <lastName>Smith</lastName> </employee> <employee> <firstName>Peter</firstName> <lastName>Jones</lastName> </employee> </employees>

C R U D O P E R AT I O N S
• Create • db.collection.insert(<document>) • db.collection.update(<query>,<update>,{update:true})
• Read • db.collection.find(<query>,<projection>)
• Update • db.collection.update(<query>,<update>,<options>)
• Delete • db.collection.remove(<query>,<justOne>)

C R U D E X A M P L E
• Create • db.employee.insert(“firstName":"John","lastName":"Doe
") • db.employee.insert(“firstName”:”John”,”lastName”:”Doe
”:”Age":40)
• Read • db.employee.find() • db.employee.find({firstName:”John”})
• Update • db.employee.update({firstName:”John”},{$set:
{firstName:”Jane”},{multi:true})
• Delete • db.employee.remove({firstName:”John”},{justOne:true})
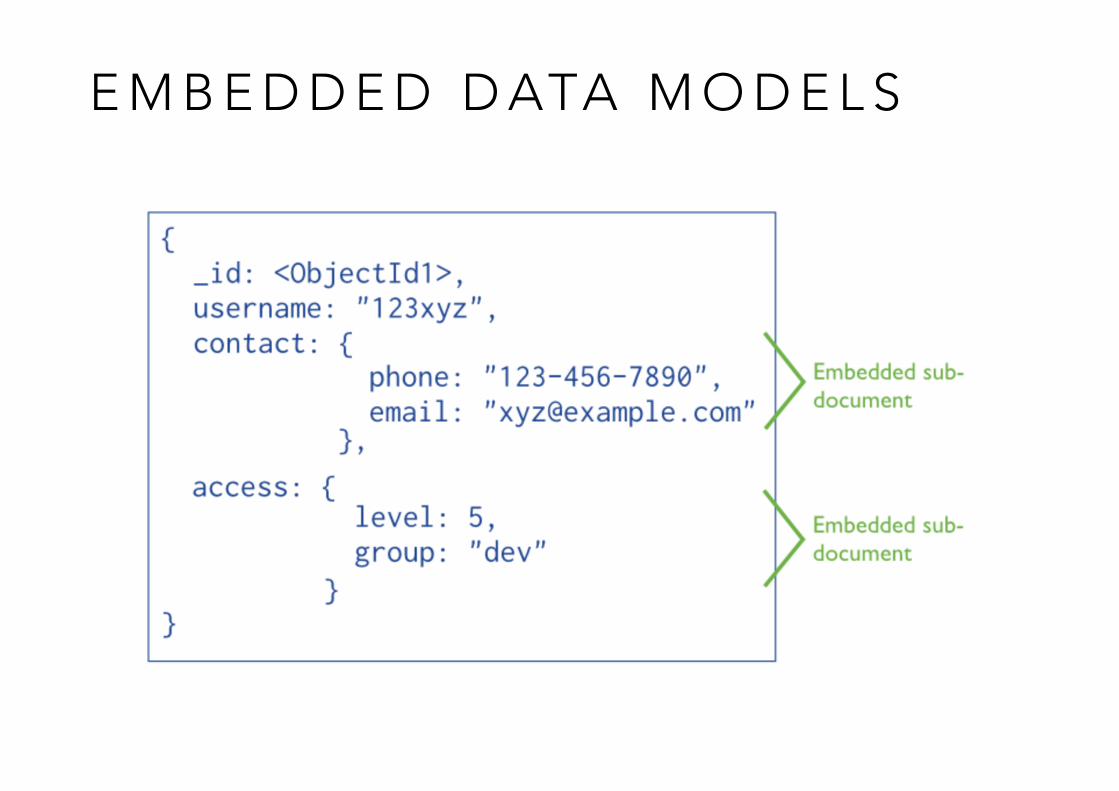
E M B E D D E D D ATA M O D E L S
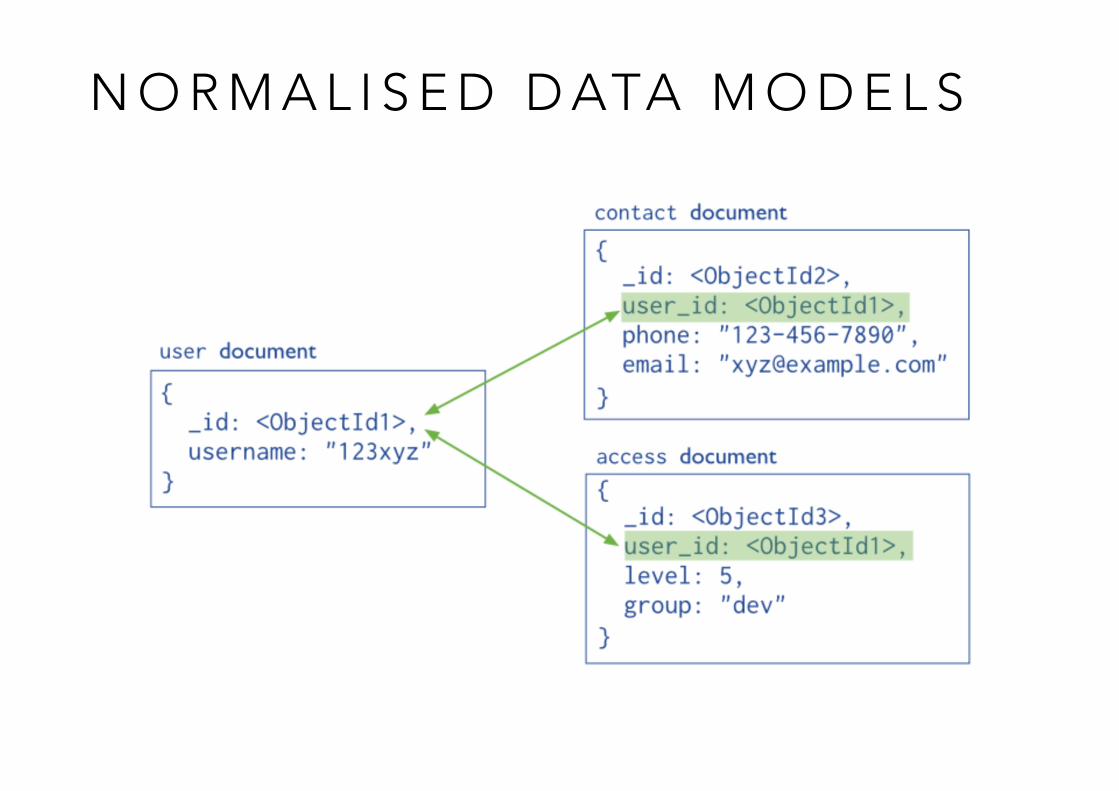
N O R M A L I S E D D ATA M O D E L S