olap battle - solrcloud vs. hbase: presented by dragan milosevic, zanox ag
TRANSCRIPT

O C T O B E R 1 3 - 1 6 , 2 0 1 6 • A U S T I N , T X

OLAP Battle: SolrCloud vs. HBase Dragan Milosevic
Chief Search Architect, zanox

3
01Table of Content
Introduce zanox and me What is OLAP? Solrcloud with Doc-Values HBase with End-Point Coprocessors Response Time Comparison Summary Questions
Tip 7 Tip 8
Tip 1 Tip 2 Tip 3
Tip 4 Tip 5 Tip 6

4
02Who am I? Chief Search Architect at Zanox
9+ years experience in building distributed search systems based on Lucene Lucid Certified Apache Solr/Lucene Developer 6+ years of using Hadoop and 4+ years of using HBase for data mining Cloudera Certified Developer for Apache Hadoop and HBase
I have applied different machine-learning techniques mainly to optimise resource usage while performing distributed search during my PhD study at Technical University Berlin
See my book: “Beyond Centralised Search Engines An Agent-Based Filtering Framework”
How can you reach me? [email protected] http://www.linkedin.com/in/draganmilosevic

5
03Zanox Network

6
02What is OLAP?
OLAP = Online Analytical Processing

7
02What is Solrcloud?

8
01Lucene Stored Fields Lucene Stored Fields are optimized for retrieving the values of fields for relatively small number of documents (top hits to be presented to user) Tip 1

Lucene Stored Fields Lucene Stored Fields are optimized for retrieving the values of fields for relatively small number of documents (top hits to be presented to user)
It is difficult to use them efficiently for reporting because many documents (thousands, even millions) are selected and their fields will be needed
Machine learning has to be used to analyze queries and determine the optimal order of documents and optimize the loading of hits if stored fields are used for reporting
Lucene Revolution San Diego 2013 Analytics in OLAP with Lucene and Hadoop
Tip 2
Tip 1
10
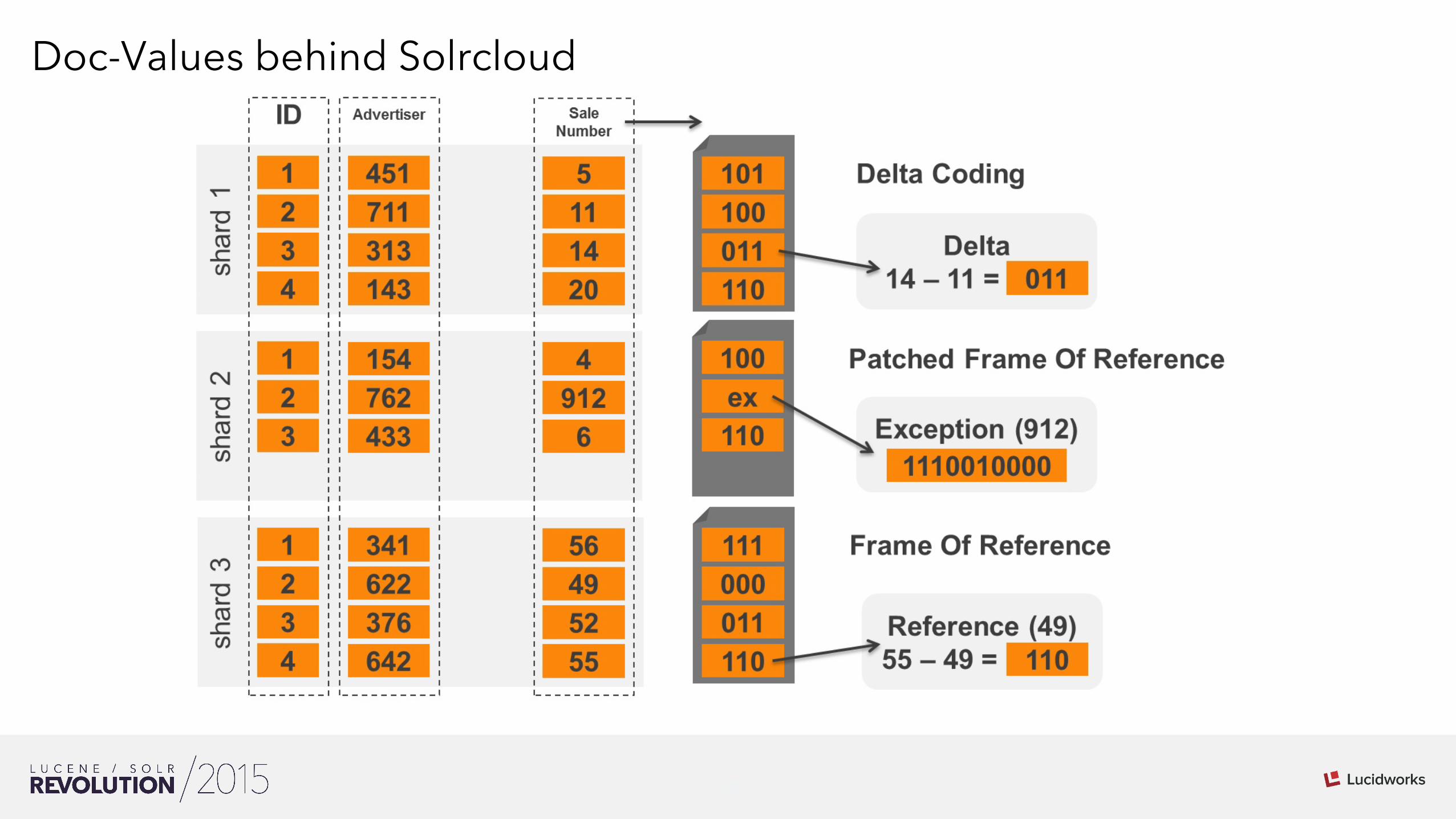
01Doc-Values behind Solrcloud

11
01Doc-Values Step-by-Step – schema.xml & Search Component class
Enable Doc-Values in shema.xml for fields that should be aggregated (with stored=“false”) <field name="adrank" type="tfloat" indexed=“false" stored=“false" docValues="true"/> Implement Search Component that uses Doc-Values and aggregates public class SummingComponent extends SearchComponent { public void prepare(ResponseBuilder rb) throws IOException { rb.setNeedDocSet(true); } public void process(ResponseBuilder rb) throws IOException {
DocIterator itr = rb.getResults().docSet.iterator(); LeafReader reader = rb.req.getSearcher().getLeafReader(); NumericDocValues docValues = reader.getNumericDocValues("adrank");
double sum = 0; while (itr.hasNext()) { sum += Float.intBitsToFloat((int) docValues.get(itr.nextDoc())); } rb.rsp.add("sum", sum);
}
Tip 3

Doc-Values Step-by-Step – solrconfig.xml
Build jar with search component, put it somewhere in contrib and add it in solrconfig.xml <lib dir="${solr.install.dir:../../../..}/contrib/zanox/lib" regex=".*\.jar" /> Register newly created search component for summing in solrconfig.xml <searchComponent name="summer" class="com.zanox.search.SummingComponent"> <str name=“…">…</str> </searchComponent> Use search component in request handler <requestHandler name="/summing" class="solr.SearchHandler"> <lst name="defaults"> … </lst> … <arr name="components"> <str>query</str> <str>summer</str> </arr> </requestHandler>

What is HBase?
“HBase is an open source, non-relational, distributed database modeled after Google's BigTable and written in Java. It is developed as part of Apache Software Foundation's Apache Hadoop project and runs on top of HDFS (Hadoop Distributed Filesystem), providing BigTable-like capabilities for Hadoop. That is, it provides a fault-tolerant way of storing large quantities of sparse data …” https://en.wikipedia.org/wiki/Apache_HBase “we could simply state that HBase is a faithful, open source implementation of Google’s BigTable. But that would be a bit too simplistic …” HBase: The Definitive Guide, Lars George “HBase is a database: the Hadoop database. It’s often described as a sparse, distributed, persistent, multidimensional sorted map, which is indexed by row-key, column key, and timestamp. You’ll hear people refer to it as a key value store, a column family-oriented database … “ HBase in Action, Nick Dimiduk, Amandeep Khurana

HBase Table and Regions

Row-Key Design for Reporting

Many Different Columns

Column Family Challenge There are hundreds of columns that should be assigned to few column families The goal is to minimize the number of column families to be accessed for requested query
Fewer column families needed means fewer files to be checked
Because of the way how splitting of regions is implemented in HBase region servers, the difference in size between column families should be minimized
Small column families will be spread across many regions, many files will be needed to be checked while processing queries and response time will increase The irrelevant columns that are not needed for query should be minimized It is allowed to duplicate data and put column in multiple column families to optimize access
Important columns that are needed for many queries will be duplicated But the amount of duplication should be minimized not to waste space
NP-hard optimization problem


End Point Coprocessors
End-Point Coprocessors provide a way to run custom code on region-servers and aggregation can be this code They are therefore analogous to both stored-procedures and map-reduce jobs as they execute logic where data resides Without them, client will have to retrieve all values locally before applying logic and probably network bandwidth will be bottleneck They behave as network friendly as possible, as only the summarized results from region servers are sent to client HBase provides high level interface for calling End-Point Coprocessors and selects regions to be queried automatically
Tip 4

HBase Reporting Guidelines
Queries have to be known and analyzed profoundly because Row-keys should be designed so that needed records are saved next to each other
and therefore can be accessed quickly Tip 5

HBase Reporting Guidelines
Queries have to be known and analyzed profoundly because Row-keys should be designed so that needed records are saved next to each other
and therefore can be accessed quickly It is necessary to decide which column should be saved in which column-family so that
the number of accessed column-families is minimized
Tip 5
Tip 6

HBase Reporting Guidelines
Queries have to be known and analyzed profoundly because Row-keys should be designed so that needed records are saved next to each other
and therefore can be accessed quickly It is necessary to decide which column should be saved in which column-family so that the
number of accessed column-families is minimized Queries that are unexpected can be very expensive because
The structure of row-keys solely decides the order in which records are saved and consequently needed records will not be saved next to each other and therefore cannot be accessed quickly
Even though this sounds as a huge disadvantage, typically there are standard reports (queries) that are the only ones made available to end-users and unexpected queries are not possible
Tip 5
Tip 6

Response Time Comparison – Single Column
Tip 7If aggregation should be performed on single attribute (column) there is no clear winner Therefore use the technology that you are more familiar with

Response Time Comparison – Multiple Columns
Tip 8If aggregation should be performed on many big attributes (columns) there is clear winner Use HBase with row-keys and column-families that are optimized for expected queries

Summary
Tip 3
Tip 1
Tip 2
Tip 6
Tip 4
Tip 5
Tip 8
Tip 7
Do not use Lucene Stored Fields for reporting
If not convinced watch Analytics in OLAP with Lucene and Hadoop
Activate Doc-Values and enjoy great aggregation performance
Plug aggregation code as End-Point Coprocessor in HBase
Design row-keys based on queries so that needed records are next to each other
Optimize the structure of column-families for queries requesting many aggregations
Pick any technology if aggregation is performed over single (few) attributes
Use optimized HBase for aggregating many big attributes

Questions?