oow2016: exploring advanced sql techniques using analytic functions
TRANSCRIPT

Zohar Elkayam www.realdbamagic.com
Twitter: @realmgic
Exploring Advanced SQL Techniques Using Analytic Functions

Who am I?• Zohar Elkayam, CTO at Brillix
• DBA, team leader, database trainer, public speaker, and a senior consultant for over 18 years
• Oracle ACE Associate
• Blogger – www.realdbamagic.com and www.ilDBA.co.il
2

About Brillix• We plan, develop and deploy various data platforms and data
security solutions• We offer complete, integrated end-to-end solutions based on
best-of-breed innovations in database, security and big data technologies
• We are committed to provide the highest quality of products and services delivered by our world renowned team of industry’s top data experts
3

Some of Our Customers
4

• I’m also a proud member of ilOUG which is part of EOUC
Are you a member yet? Join now!
https://community.oracle.com/community/usergroups
Visit the User Groups booth in the Moscone South Exhibition hall
Database Showcase, Booth SDB-062
EOUC – EMEA Oracle User Group Community
5

• Brand new quarterly free e-magazine for Oracle users around the world!
• Exciting stories, funny comic strips, interesting surveys, interviews, and infographics
• Submit your own articles, ideas or events• Subscribe now for free!
Please visit www.oraworld.org
For more information.
ORAWORLD Magazine
6

Agenda: Advanced SQL• “Basic” aggregation extensions: Rollup, Cube, and Grouping Sets• Analytic functions
• Reporting Functions• Ranking Functions• Inter-row Functions
• Oracle 12c new features overview• Top-N queries• Pattern matching (Match Recognize Syntax)
7

Advanced AggregationMore than just group by…
8

Basics• Group functions will return a single row for each group of rows• We can run group functions only when we group the rest of the
columns together using GROUP BY clause• Common group functions: SUM, MIN, MAX, AVG, etc.• We can filter out rows after aggregation, if we use the HAVING
clause
9

• Use ROLLUP or CUBE with GROUP BY to produce super aggregate rows by cross-referencing columns
• ROLLUP grouping produces a result set containing the regular grouped rows and the subtotal and grand total values
• CUBE grouping produces a result set containing the rows from ROLLUP and cross-tabulation rows
10
GROUP BYWith the ROLLUP and CUBE Operators

The ROLLUP Operator• ROLLUP is an extension of the GROUP BY clause• Use the ROLLUP operation to produce cumulative aggregates,
such as subtotals
SELECT [column,] group_function(column). . .
FROM table
[WHERE condition]
[GROUP BY [ROLLUP] group_by_expression]
[HAVING having_expression];
[ORDER BY column];
`
11

Using the ROLLUP Operator: ExampleSELECT department_id, job_id, SUM(salary)
FROM hr.employees
WHERE department_id < 60
GROUP BY ROLLUP(department_id, job_id);
1
2
3
Total by DEPARTMENT_ID
and JOB_ID
Total by DEPARTMENT_ID
Grand total
12
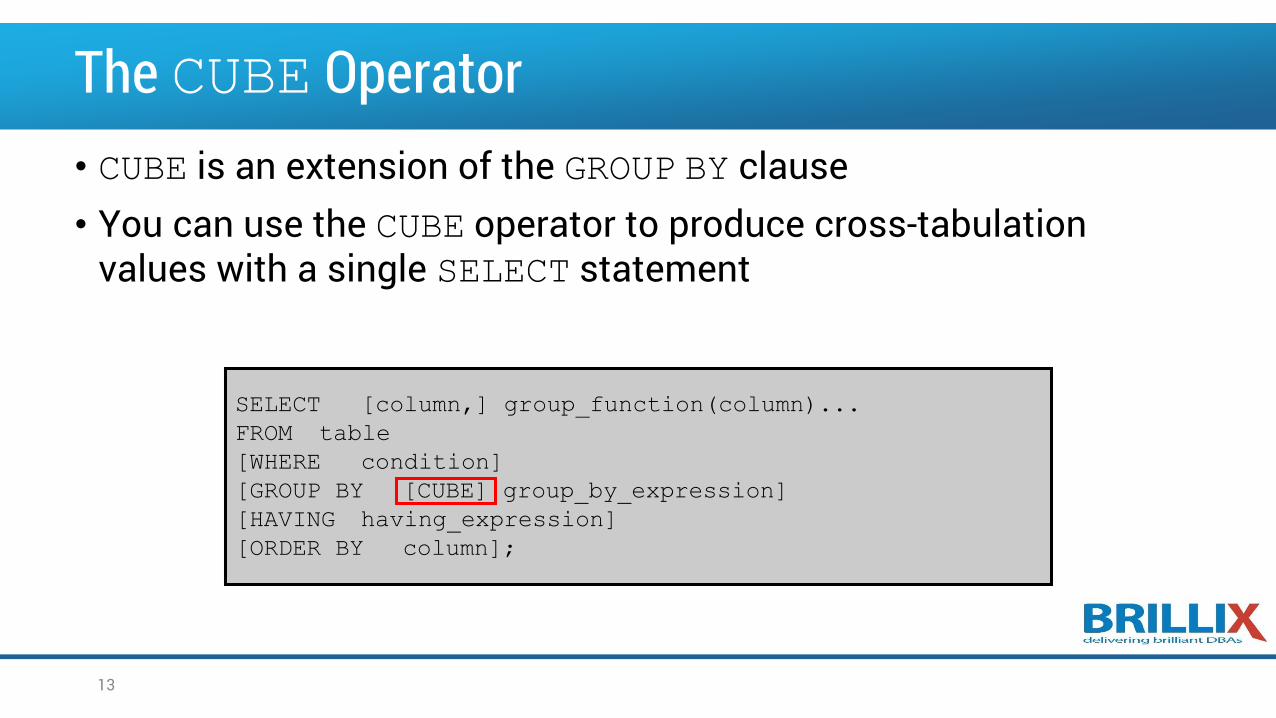
The CUBE Operator• CUBE is an extension of the GROUP BY clause• You can use the CUBE operator to produce cross-tabulation
values with a single SELECT statement
SELECT [column,] group_function(column)...
FROM table
[WHERE condition]
[GROUP BY [CUBE] group_by_expression]
[HAVING having_expression]
[ORDER BY column];
13

SELECT department_id, job_id, SUM(salary)
FROM hr.employees
WHERE department_id < 60
GROUP BY CUBE (department_id, job_id);
. . .
Using the CUBE Operator: Example
14
1
2
3
4
Grand total
Total by JOB_ID
Total by DEPARTMENT_ID
and JOB_ID
Total by DEPARTMENT_ID

The GROUPING SETS Operator• The GROUPING SETS syntax is used to define multiple
groupings in the same query• All groupings specified in the GROUPING SETS clause are
computed and the results of individual groupings are combined with a UNION ALL operation
• Grouping set efficiency:• Only one pass over the base table is required• There is no need to write complex UNION statements• The more elements GROUPING SETS has, the greater the potential of a
performance benefit
15

SELECT department_id, job_id,
manager_id, AVG(salary)
FROM hr.employees
GROUP BY GROUPING SETS
((department_id,job_id), (job_id,manager_id));
Using GROUPING SETS: Example
. . .
1
2
16

Composite Columns• A composite column is a collection of columns that are treated
as a unit.ROLLUP (a,(b,c), d)
• Use parentheses within the GROUP BY clause to group columns, so that they are treated as a unit while computing ROLLUP or CUBE operators.
• When used with ROLLUP or CUBE, composite columns require skipping aggregation across certain levels.
17

SELECT department_id, job_id, manager_id,
SUM(salary)
FROM hr.employees
WHERE department_id < 50
GROUP BY CUBE ( department_id,(job_id, manager_id));
Composite Columns: Example
18
1
2
3
4

Analytic FunctionsLet’s analyze our data!
19

Overview of SQL for Analysis and Reporting• Oracle has enhanced SQL's analytical processing capabilities by
introducing a family of analytic SQL functions• These analytic functions enable you to calculate and perform:
• Reporting operations (MIN, MAX, COUNT)• Rankings and percentiles (RANK, ROW_NUMBER)• Moving window calculations• Inter-row calculations (LAG/LEAD, FIRST/LAST etc.)• Pivoting operations (11g)• Pattern matching (12c)• Linear regression and predictions
20

Why Use Analytic Functions?• Ability to see one row from another row in the results• Avoid self-join queries and simplify the queries• Summary data in detail rows• Slice and dice within the results• Different function can use different grouping sets• Performance improvement, in some cases
21

Concepts Used in Analytic Functions • Result set partitions: These are created and available to any
aggregate results such as sums and averages. The term “partitions” is unrelated to the table partitions feature.
• Window: For each row in a partition, you can define a sliding window of data, which determines the range of rows used to perform the calculations for the current row.
• Current row: Each calculation performed with an analytic function is based on a current row within a partition. It serves as the reference point determining the start and end of the window.
22

Reporting Functions• We can use aggregative/group functions as analytic functions
(i.e. SUM, AVG, MIN, MAX, COUNT etc.)• Each row will get the aggregative value for a given partition
without the need for group by clause so we can have multiple group by’s on the same row
• Getting the raw data along with the aggregated value• Use Order By to get cumulative aggregations
23

Reporting Functions Examples
24
SELECT last_name, salary, department_id,
ROUND(AVG(salary) OVER (PARTITION BY department_id),2) AVG,
COUNT(*) OVER (PARTITION BY manager_id) CNT,
SUM(salary) OVER (PARTITION BY department_id ORDER BY salary) SUM,
MAX(salary) OVER () MAX
FROM hr.employees;

Ranking Functions
25

Using the Ranking Functions• A ranking function computes the rank of a record compared to
other records in the data set based on the values of a set of measures. The types of ranking function are:• RANK and DENSE_RANK functions• ROW_NUMBER function• PERCENT_RANK function• NTILE function
26

Working with the RANK Function
• The RANK function calculates the rank of a value in a group of values, which is useful for top-N and bottom-N reporting.
• When using the RANK function, ascending is the default sort order, which you can change to descending.
• Rows with equal values for the ranking criteria receive the same rank. • Oracle Database then adds the number of tied rows to the tied rank to
calculate the next rank.
RANK ( ) OVER ( [query_partition_clause] order_by_clause )
27

Using RANK: Example
SELECT department_id, last_name, salary,
RANK() OVER (PARTITION BY department_id
ORDER BY salary DESC) "Rank"
FROM employees
WHERE department_id = 60
ORDER BY department_id, "Rank", salary;
28

RANK and DENSE_RANK: Example
SELECT department_id, last_name, salary,
RANK() OVER (PARTITION BY department_id
ORDER BY salary DESC) "Rank",
DENSE_RANK() over (partition by department_id
ORDER BY salary DESC) "Drank"
FROM employees
WHERE department_id = 60
ORDER BY department_id, salary DESC, "Rank" DESC;
DENSE_RANK ( ) OVER ([query_partition_clause] order_by_clause)
29

Working with the ROW_NUMBER Function
• The ROW_NUMBER function calculates a sequential number of a value in a group of values.
• When using the ROW_NUMBER function, ascending is the default sort order, which you can change to descending.
• Rows with equal values in the ranking criteria might receive different values across executions.
ROW_NUMBER ( ) OVER ( [query_partition_clause] order_by_clause )
30

ROW_NUMBER VS. ROWNUM• ROWNUM is a pseudo column, ROW_NUMBER is an actual
function• ROWNUM is calculated when the result returns to the client so it
requires sorting of the entire dataset in order to return an ordered list
• ROW_NUMBER will only sort the required rows thus giving better performance
• ROW_NUMBER can use grouping
31

Using the PERCENT_RANK Function• Uses rank values in its numerator and returns the percent rank of a
value relative to a group of values• PERCENT_RANK of a row is calculated as follows:
• The range of values returned by PERCENT_RANK is 0 to 1, inclusive. The first row in any set has a PERCENT_RANK of 0. The return value is NUMBER. Its syntax is:
(rank of row in its partition - 1) /
(number of rows in the partition - 1)
PERCENT_RANK () OVER ([query_partition_clause]
order_by_clause)
32

Using PERCENT_RANK: ExampleSELECT department_id, last_name, salary, PERCENT_RANK()
OVER (PARTITION BY department_id ORDER BY salary DESC)
AS pr
FROM hr.employees
ORDER BY department_id, pr, salary;
33

Working with the NTILE Function
• Not really a ranking function• Divides an ordered data set into a number of buckets indicated
by expr, and assigns the appropriate bucket number to each row• The buckets are numbered 1 through expr
NTILE ( expr ) OVER ([query_partition_clause] order_by_clause)
34

Summary of Ranking Functions• Different ranking functions may return different results if the
data has tiesSELECT last_name, salary, department_id,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) A,
RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) B,
DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) C,
PERCENT_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) D,
NTILE(4) OVER (PARTITION BY department_id ORDER BY salary DESC) E
FROM hr.employees;
35

Inter-row Analytic Functions
36

Using the LAG and LEAD Analytic Functions
• LAG provides access to more than one row of a table at the same time without a self-join.
• Given a series of rows returned from a query and a position of the cursor, LAG provides access to a row at a given physical offset before that position.
• If you do not specify the offset, its default is 1. • If the offset goes beyond the scope of the window, the optional
default value is returned. If you do not specify the default, its value is NULL.
{LAG | LEAD}(value_expr [, offset ] [, default ])
OVER ([ query_partition_clause ] order_by_clause)
37

Using LAG and LEAD: Example
SELECT time_id, TO_CHAR(SUM(amount_sold),'9,999,999') AS SALES,
TO_CHAR(LAG(SUM(amount_sold),1) OVER (ORDER BY
time_id),'9,999,999') AS LAG1,
TO_CHAR(LEAD(SUM(amount_sold),1) OVER (ORDER BY
time_id),'9,999,999') AS LEAD1
FROM sales
WHERE time_id >= TO_DATE('10-OCT-2000') AND
time_id <= TO_DATE('14-OCT-2000')
GROUP BY time_id;
38

Using FIRST_VALUE/LAST_VALUE• Returns the first/last value in an ordered set of values• If the first value in the set is null, then the function returns NULL
unless you specify IGNORE NULLS. This setting is useful for data densification.
39
FIRST_VALUE (expr [ IGNORE NULLS ]) OVER (analytic_clause)
LAST_VALUE (expr [ IGNORE NULLS ]) OVER (analytic_clause)
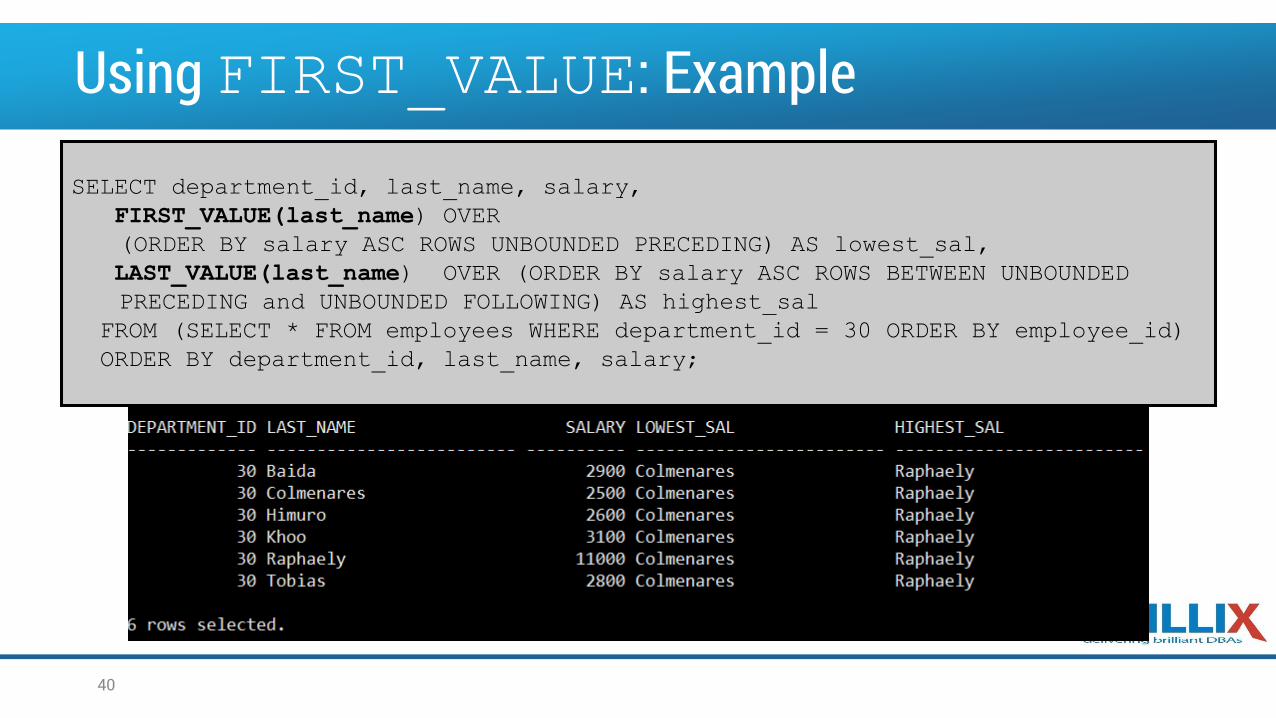
Using FIRST_VALUE: Example
SELECT department_id, last_name, salary,
FIRST_VALUE(last_name) OVER
(ORDER BY salary ASC ROWS UNBOUNDED PRECEDING) AS lowest_sal,
LAST_VALUE(last_name) OVER (ORDER BY salary ASC ROWS BETWEEN UNBOUNDED
PRECEDING and UNBOUNDED FOLLOWING) AS highest_sal
FROM (SELECT * FROM employees WHERE department_id = 30 ORDER BY employee_id)
ORDER BY department_id, last_name, salary;
40

Using NTH_VALUE Analytic Function• Returns the N-th values in an ordered set of values• Different default window: RANGE BETWEEN UNBOUNDED
PRECEDING AND CURRENT ROW
41
NTH_VALUE (measure_expr, n)
[ FROM { FIRST | LAST } ][ { RESPECT | IGNORE } NULLS ]
OVER (analytic_clause)
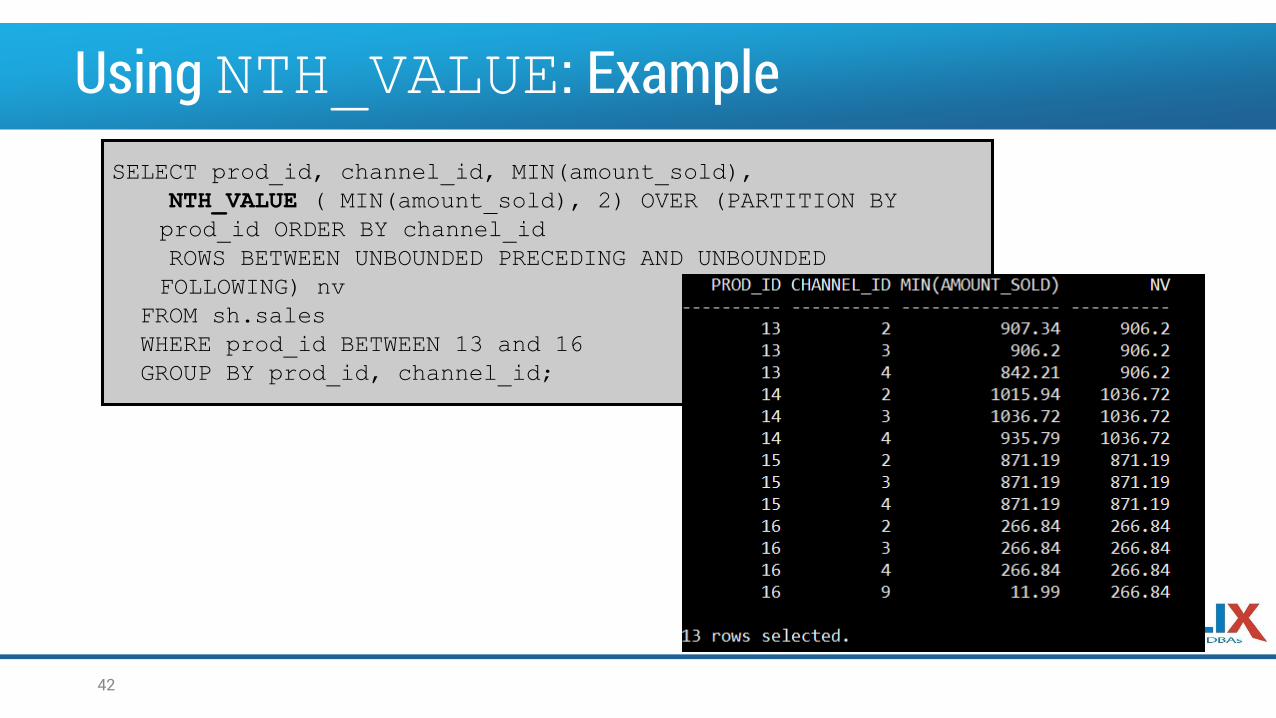
Using NTH_VALUE: ExampleSELECT prod_id, channel_id, MIN(amount_sold),
NTH_VALUE ( MIN(amount_sold), 2) OVER (PARTITION BY
prod_id ORDER BY channel_id
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED
FOLLOWING) nv
FROM sh.sales
WHERE prod_id BETWEEN 13 and 16
GROUP BY prod_id, channel_id;
42

Using the LISTAGG Function• For a specified measure, LISTAGG orders data within each group
specified in the ORDER BY clause and then concatenates the values of the measure column
• WARNING: Limited to output of 4000 chars (else, error message in runtime)
43
LISTAGG(measure_expr [, 'delimiter'])
WITHIN GROUP (order_by_clause) [OVER
query_partition_clause]
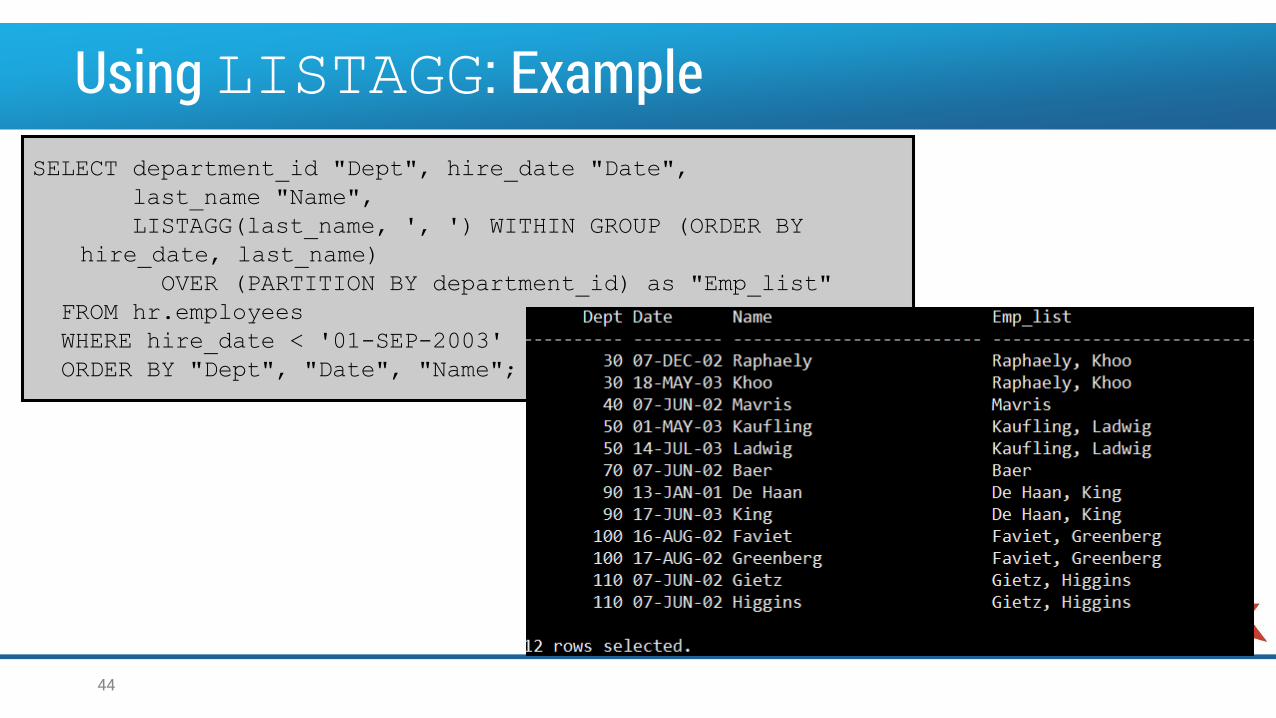
Using LISTAGG: ExampleSELECT department_id "Dept", hire_date "Date",
last_name "Name",
LISTAGG(last_name, ', ') WITHIN GROUP (ORDER BY
hire_date, last_name)
OVER (PARTITION BY department_id) as "Emp_list"
FROM hr.employees
WHERE hire_date < '01-SEP-2003'
ORDER BY "Dept", "Date", "Name";
44

Window Functions
45

Window Functions• The windowing_clause gives some analytic functions a further
degree of control over this window within the current partition• The windowing_clause can only be used if an order_by_clause is present
• The windows are always limited to the current partition• Generally, the default window is the entire work set unless stated
otherwise
46

Windowing Clause Useful Usages• Cumulative aggregation• Sliding average over proceeding and/or following rows• Using the RANGE parameter to filter aggregation records
47

Windows Can Be By RANGE or ROWS
48
Possible values for start_point and end_pointUNBOUNDED PRECEDING The window starts at the first row of the partition. Only
available for start points.UNBOUNDED FOLLOWING The window ends at the last row of the partition. Only
available for end points.CURRENT ROW The window starts or ends at the current rowvalue_expr PRECEDING A physical or logical offset before the current row.
When used with RANGE, can also be an interval literalvalue_expr FOLLOWING As above, but an offset after the current row
RANGE BETWEEN start_point AND end_point
ROWS BETWEEN start_point AND end_point

Shortcuts• Useful shortcuts for the windowing clause:
49
ROWS UNBOUNDED PRECEDING ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
ROWS 10 PRECEDING ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
ROWS CURRENT ROW ROWS BETWEEN CURRENT ROW AND CURRENT ROW (1 row)
Oracle 12c New Feature OverviewJust a couple, we can talk for hours about all the new features..
50

What’s New in Oracle 12c• Top-N Queries and pagination: returning the top-n queries
• Compatible with ANSI SQL• synthetic honey – just a syntax enhancement, not performance
enhancement
• Pattern matching: New MATCH_RECOGNIZE syntax for finding row between patterns
51

Top-N Examples
52
SELECT last_name, salary
FROM hr.employees
ORDER BY salary
FETCH FIRST 4 ROWS ONLY;
SELECT last_name, salary
FROM hr.employees
ORDER BY salary
FETCH FIRST 4 ROWS WITH TIES;
SELECT last_name, salary
FROM hr.employees
ORDER BY salary DESC
FETCH FIRST 10 PERCENT ROWS ONLY;

What is Pattern Matching?• A new syntax that allows us to identify and group rows with
consecutive values• Consecutive in this regards – row after row (must be ordered)• Uses regular expression like syntax to find patterns• Finds complex behavior we couldn’t find before, or needed
PL/SQL to do it (for example: V-shape, U-shape, and others)!
53

Example: Sequential Employee IDs• Our goal: find groups of users with sequences IDs• This can be useful for detecting missing employees in a table, or
to locate “gaps” in a group
54
FIRSTEMP LASTEMP
---------- ----------
7371 7498
7500 7520
7522 7565
7567 7653
7655 7697
7699 7781
7783 7787
7789 7838

SELECT *
FROM Emps
MATCH_RECOGNIZE (
ORDER BY emp_id
PATTERN (STRT B*)
DEFINE B AS emp_id = PREV(emp_id)+1
ONE ROW PER MATCH
MEASURES
STRT.page firstemp,
LAST(page) lastemp
AFTER MATCH SKIP PAST LAST ROW
);
1. Define input2. Pattern Matching3. Order input4. Process pattern5. Using defined conditions6. Output: rows per match7. Output: columns per row8. Where to go after match?
Pattern Matching Example
55

1. Define input2. Pattern Matching3. Order input4. Process pattern5. Using defined conditions6. Output: rows per match7. Output: columns per row8. Where to go after match?
Pattern Matching Example (actual syntax)
SELECT *
FROM Emps
MATCH_RECOGNIZE (
ORDER BY emp_id
MEASURES
STRT.emp_id firstemp,
LAST(emp_id) lastemp
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (STRT B*)
DEFINE B AS emp_id = PREV(emp_id)+1
);
56

Oracle 11g Analytic Function Solution
57
select firstemp, lastemp
From (select nvl (lag (r) over (order by r), minr) firstemp, q lastemp
from (select emp_id r,
lag (emp_id) over (order by emp_id) q,
min (emp_id) over () minr,
max (emp_id) over () maxr
from emps e1)
where r != q + 1 -- groups including lower end
union
select q,
nvl (lead (r) over (order by r), maxr)
from ( select emp_id r,
lead (emp_id) over (order by emp_id) q,
min (emp_id) over () minr,
max (emp_id) over () maxr
from emps e1)
where r + 1 != q -- groups including higher end
);

Q&A
58

Summary• We talked about advanced aggregation clauses, multi- dimensional
aggregation, and how utilizing it can save us time and effort• Analytic functions are really important both for performance and
for code clarity• We saw how reporting and rank function work and how to use them• We explored some Oracle 12c enhancements – more information
about that can be found in my blog: www.realdbamagic.com
59
