open problems in statistical machine translation roland kuhn january 2008
TRANSCRIPT

Open Problems in Statistical Machine Translation
Roland Kuhn
January 2008

Plan
A. Overview of Statistical Machine Translation (SMT)
B. Open Problems
NOTE: best overall reference for SMT hasn’t been published yet – Philipp Koehn’s « Statistical Machine Translation » (to be published by Cambridge University Press). Some of the material presented here is from a draft of that book.

The MT Task & Approaches to it
• Core MT task: translate a sentence from a source language S to target language T
• Conventional expert system approach: hire experts to write rules for translating S to T
• Statistical approach: using a bilingual text corpus (lots of S sentences & their translations into T), train a statistical translation model that will map each new S sentence into a T sentence.
IMPORTANT: SMT models are trained on huge corpora – e.g., our Chinese-English system is trained on 10 million sentence pairs.

• We seem to be in a period of transition, during which SMT is replacing the expert system approach. This happened in automatic speech recognition in the 1980s …
• Systran, biggest MT company, uses expert systems; so do most MT companies. However, Systran has recently begun exploring possibility of adding a statistical component to their system. We (NRC) created a very good « serial combination » Systran-NRC hybrid.
• LanguageWeaver is new company based on SMT (closely linked to researchers at ISI, U. Southern California)
• Google has superb SMT research team – but online, Google mainly used Systran until a few months ago (probably because of computational cost of online SMT). Recently, they swapped in SMT systems for most language pairs.
The MT Task & Approaches to it

Bilingual parallel corpus
S T
Phrase TranslationModel
Target LanguageModel
Preprocessor
Decoder
S: Mais où sont les neiges d’antan?
mais où sont les neiges d’ antan ?
Extra Target Corpora
(optional extra LM training corpora)
Other KnowledgeSources
offline training
T1: however where are the snows #d’ antan# P = 0.22T2: but where are the snows #d’ antan# P = 0.21T3: but where did the #d’ antan# snow go P = 0.13
…
T1: But where are the snows of yesteryear? P=0.41T2: However, where are yesterday’s snows? P = 0.33
…Postprocessor
Initial N-best hypotheses
Reordering
Final N-best hypotheses
Structure of Typical SMT System
The MT Task & Approaches to it

Example of SMT output
A silly English → German example from Google (Jan. 25, 2007):
the hotel has a squash court das Hotel hat ein Kürbisgericht (think “zucchini tribunal”)
* but this kind of error – perfect syntax, never-seen word combination – isn’t typical of a statistical system: this was a rule-based system
Tried again Dec. 13, 2007: now translation is
das Hotel verfügt über ein Squashplatz

Culture:• SMT research is very engineering-oriented; driven by performance in NIST &
other evaluations • Advantages of SMT culture: open-minded to new ideas that can be tested
quickly; researchers who count have working systems with reasonably well-written software (so they can participate in evaluations)
• Disadvantages of SMT culture: closed-minded to ideas not tested in a working system if you have a brilliant theory that doesn’t show a BLEU score improvement in a reasonable baseline system, don’t expect SMT researchers to read your paper! (*** this is slight exaggeration – besides BLEU, other automatic & manual metrics sometimes used)
SMT Research: Culture,Evaluations, & Metrics

• Since 2001, US National Institute of Standards & Technology (NIST) has been evaluating MT systems
• Participants include MIT , IBM , CMU , RWTH , Hong Kong UST , ATR , IRST , others …
and NRC:
• NRC’s system is called PORTAGE• Main NIST language pairs: ChineseEnglish, ArabicEnglish• In 2005 & 2006 statistical systems beat expert systems according to
BLEU metric in NIST• in most recent (2006) NIST MT evaluation, PORTAGE ranked 4th/24
& 6th/24 for the two large track Chinese→English tasks. • Other evaluations: WMT, TC-STAR, IWSLT
MT Evaluations
SMT Research: Culture,Evaluations, & Metrics

What is BLEU? • Human evaluation of automatic translation quality hard & expensive. BLEU metric compares MT output
with human-generated reference translations via N-gram matches. • BLEU correlates roughly with human judgment (the more reference translations, the better it correlates)
SMT Research: Metrics

Why BLEU Is Controversial• If system produces a brilliant translation that uses many N-grams not found in the references, it will receive a low score. • Proponents of the expert system approach argue that BLEU is biased against this approach, & that it favours SMT• Partial confirmation:
1. in NIST 2006 Arabic-to-English evaluation, AppTek hybrid system (rule-based + SMT system) did best according to human evaluators, but not according to BLEU. 2. in 2006 WMT evaluation Systran was scored comparably to other systems for some European language pairs (e.g., French-English) by human evaluators, but had much lower in-domain BLEU scores (see graphs in http://www.statmt.org/wmt06/proceedings/pdf/WMT14.pdf).
SMT Research: Metrics

• In the late 1980s, members of IBM’s speech recognition group applied statistical learning techniques to bilingual corpora. These American researchers worked mainly with the Canadian Hansard – bilingual transcription of parliamentary proceedings.
• These researchers quit IBM around 1991 for a hedge fund, Renaissance Technologies – they are now very rich!
• Renewed interest in their work sparked the revival of research into statistical learning for MT that occurred from late 1990s onward. Newer « phrase-based » approach still partially relies on IBM models.
• The IBM approach used Bayes’s Theorem to define the « Fundamental Equation » of MT (Brown et al. 1993)
SMT History: IBM Models

The best-fit translation of a source-language (French) sentence S into a target-language (English) sentence T is:
T = argmaxT [P(T)*P(S|T)]^
search task language model word translation model
Fundamental Equation of MT
Job of language model: ensure well-formed target-language TJob of translation model: ensure T could have generated S Search task: find T maximizing product P(T)*P(S|T)
SMT History: IBM Models

• The IBM researchers defined five statistical translation models (numbered in order of complexity)
• Each defines a mechanism for generation of text in one language
(e.g., French or foreign = F) from another (e.g., English = E): P(F|E)• Most general many-to-many case is not covered by IBM models; in this
forbidden case, a group of E words generates a group of F words, e.g. :
The poor don’t have any money
Les pauvres sont démunis
SMT History: IBM Models

• The IBM models only allow zero or one connections for each source word; a target word has arbitrary # of connections, e.g. (F=source, E=target):
And the program has been implemented
Le programme a été mis en application
• IBM Model 1 is « bag of words » - word order in F & E doesn’t matter• In model 2, chance that an E word generates given F word(s) depends on position • IBM models 3, 4, & 5 are fertility-based; some E words (e.g., « implemented ») may be specially fertile
SMT History: IBM Models

IBM model 1: « bag of words »
IBM model 2: « position-dependent bag of words »
e1
e2
….
eL
f1
f2
….
fM
P(2 →1)
P(2 →M)
P(L→1)
P(1 →1)
P(L→M)
….
e1
e2
….
eL
f1
f2
….
fM
(draw with uniform probability)
(draw with position-dep. prob)
….P(L→M)
P(1→M)
SMT History: IBM Models

Parameters: φ(ei) = fertility of ei = prob. will produce
0, 1, 2 … words in F; t(f|ei) = probability that ei can generate f;
Π(j | i, k) = distortion prob. = prob. that kth word generated by ei ends up in pos. j of F
IBM model 3
e1
e2
….
eL
φ(e1)2
φ(e2)0
φ(eL)Ø
1
f1
f2
….
fM
f2
fM
….
f1
Distortion model Π P(1→1), P(1→2),
…, P(M→M)
IBM model 5: cleaned-up version of model 4 (e.g., two F words can’t be given same position)
e1
e2
….
eL
3
0Ø
1
Distortion model
Π IBM model 4
φ(e1)
φ(e2)
φ(eL)
f1
f2
f3
….
fM
f1
f2
f3
fM
NOTE: phrases can be broken up,but with lower prob. than in model 3
(phrase)
t
t
t
t
t
SMT History: IBM Models

Phrase-based SMT
Five key ideas• phrase-based models (Och04, Koehn03, Marcu02)• N-gram language model (Jelinek90) • dynamic programming search algorithms (Koehn04)• loglinear model combination (Och02)• error-driven learning (Och03)

Phrase-based approach introduced around 1998 by Franz Josef Och & others (Ney, Wong, Marcu): many words to many words (improvement on IBM one-to-many)
Example: « cul de sac » word-based translation = « ass of bag » (N. Am), « arse of bag » (British)phrase-based translation = « dead end » (N. Am.), « blind alley » (British)
This knowledge is stored in a phrase table : collection of conditional probabilities of form P(S|T) = backward phrase table or P(T|S) = forward phrase table. Recall Bayes: T = argmaxT [P(T)*P(S|T)] backward table essential,
forward table used for heuristics. Tables for French->English:
^
backward: P(S|T)p(sac|bag) = 0.9p(sacoche|bag) = 0.1…p(cul de sac|dead end) = 0.7p(impasse|dead end) = 0.3…
forward: P(T|S)p(bag|sac) = 0.5p(hand bag|sac) = 0.2…p(ass|cul) = 0.5p(dead end|cul de sac) = 0.85…
Phrase-based SMT

Overall Phrase Pair Extraction Algorithm
1. Run a sentence aligner on a parallel bilingual corpus (won’t go over this)
2. Run word aligner (e.g., one based on IBM models) on each aligned sentence pair – see next slide.
3. From each aligned sentence pair, extract all phrase pairs with no external links - see two slides ahead.
Phrase-based SMT

Symmetrized Word Alignment using IBM Models
Alignments produced by IBM models are asymmetrical: source words have at most one connection, but target words may have many connections.
To improve quality, use symmetrization heuristic (Och00):
1. Perform two separate alignments, one in each different translation direction.
2. Take intersection of links as starting point.
3. Add neighbouring links from union until all words are covered.
S: I want to go home
T: Je veux aller chez moi
S: Je veux aller chez moi
T: I want to go home
I want to go home
Je veux aller chez moi
Phrase-based SMT

Je l’ ai vu à la télévision
I saw him on television
Extract all phrase pairs with no external links, for example:
Good pairs:
(Je, I) (Je l’ ai vu, I saw him) (ai vu, saw) (l’ ai vu à la, saw him on)Bad pairs:
(Je l’ ai vu, I saw) (l’ ai vu à, saw him on) (la télévision, television)
Input: aligned sentence pair
Output: set of consistent phrases
Phrase-based SMT
« diag-and » phrase extraction

Target Language Model P(T)
• Language model helps generate fluent output by 1. assigning higher probability to correct word order – e.g.,
PLM(the house is small) >> PLM(small the is house) 2. assigning higher probability to correct word choices – e.g.,
PLM(i am going home) >> PLM(I am going house) • Almost everyone in both SMT and ASR (automatic speech
recognition) communities uses N-gram language models. Start with P(W) = P(w1)*P(w2|w1)*P(w3|w1,w2)*…*P(wi|w1,…,wi-1)*…*P(wm|w1,…,wm-1),
then limit window to N words. E.g., for N=3, trigram LM: P(W) = P(w1)*P(w2|w1)*P(w3|w1,w2)*…*P(wi|wi-2,wi-1)*…*P(wm|wm-2,wm-1).
• Language model estimated on large unilingual T-language corpus, often using freeware (SRILM or CMU toolkit)
• « A Bit of Progress in Language Modeling » (Goodman01) is good summary of state of the art in N-gram language modeling.

Source: s1 s2 s3 s4 s5 s6 s7 s8 s9 Segmentation
P(S|T)p(s2 s3 | t8)p(s2 s3 | t5 t3)…p(s3 s4 | t4 t9)…
phrase table: 1. suggests possible segments2. supplies phrase translation scores
Backward Table
Order: Target hypotheses grow left->right, from source segments consumed in any order
(pick s2 s3 first)
Source: s1 s2 s3 s4 s5 s6 s7 s8 s9
Tgt hyp: t8| … Tgt hyp: t5 t3| …
(pick s3 s4 first)
Source: s1 s2 s3 s4 s5 s6 s7 s8 s9
Tgt hyp: t4 t9| …(pick s5 s6 s7)
Source: s1 s2 s3 s4 s5 s6 s7 s8 s9
Tgt hyp: t8| t6 t2| … LanguageModel P(T)…
…
…
language model: scores growing target hypotheses left -> right
(phrase transl)
(phrase transl)
(phrase transl)
Phrase-Based Search: finding argmaxT [P(T)*P(S|T)]

Loglinear Model Combination
Previous slides show basic system that ranks hypotheses by P(S|T)*P(T). Now let’s introduce an alignment/reordering variable A (aligns T & S phrases). We want
T = argmaxT P(T|S) ≈ argmaxT ,AP(T, A|S) =
argmaxT, A f1(T,A,S)λ1* f2(T,A,S)λ2 * … * fM(T,A,S)λM =argmaxT,A exp (∑i λi log fi(T,A,S)).
The fi now typically include not only functions related to P(S|T) and language model P(T), but also to A « distortion », P(T|S), length(T), etc. The λi serve as reliability weights. This change in score computation doesn’t fundamentally change the search algorithm.
^

AdvantagesVery flexible! Anyone can devise dozens of features.
• E.g., if lots of mismatched brackets in output, include feature function that outputs +1 if no mismatched brackets, -1 if have mismatched brackets.
• So lots of new features being tried in somewhat haphazard way.
• But systems steadily improving – outputs from NIST 2006 look much better than those from NIST 2002. SMT not good enough to replace human translators, but good enough for, e.g., most Web browsing. Using 1000 machines and massive quantities of data, Google got 45.4 BLEU for Arabic to English, 35.0 for Chinese to English – very high scores!
Loglinear Model Combination

Flaws of Phrase-based, Loglinear Systems
• Loglinear feature function combination is too flexible! Makes it easy not to think about theoretical properties of models.• The IBM models were true models: given arbitrary source
sentence S and target sentence T, could estimate non-zero P(T|S). Phrase-based “models” are not models: in general, for T which is a good translation of S, they give P(T|S) = 0. They don’t guarantee existence of an alignment between T and S. Thus, the only translations T’ to which a phrase-based system is guaranteed to assign P(T’|S) > 0 are T’ output by same system.
• This has practical consequences: in general, a phrase-based MT system can’t be used for analyzing pre-existing translations. This rules out many useful forms of assistance to human translators - e.g., spotting potential errors in translations based on regions of low P(T|S).

Plan
B. Open Problems in SMT• Adaptation: how make SMT system work well in new
domain? • Feature selection: can we devise more principled ways of
selecting phrases for the phrase tables P(S|T) and P(T|S)? • Generalizing beyond phrases: how enable system to
learn gappy & hierarchical patterns? E.g., “ne VERB pas” ↔ “not VERB”, “don’t VERB”
• Can SMT systems be trained discriminatively?• Can kernel regression techniques be applied to SMT?

Adaptation
Foster07:• For SMT to work well, there shouldn’t be mismatch between
training and test material.• Adaptive approaches strive to reduce mismatch by modifying
model parameters in response to information about test domain.• In mixture-based approaches, model is combination of component
models; adaptation adjusts weights on components based on their fit with the test domain → “dynamic adaptation”.
• We tried linear adaptation within each of two main components of SMT: “translation model” P(S|T) and “language model” P(T)
P(T|S) ≈ P(S|T) * P(T)β * (other features)
P(S|T)= a1*TM1 + a2*TM2 + … + anTMn P(T)=b1*LM1 + b2*LM2 + … + bkLMk
ai’s shift dynamically bj’s shift dynamically

Adaptation
• In our experiments, we trained 7 different TM’s and 7 different LM’s on Chinese-English corpora, and allowed linear weights on these to vary.
• Want “distance” (really closeness) measure that gives best linear weights. Will use naively: if C i is one of 7 training corpora, q is test text, then if metric m gives “distance” m(q,C i) between q and Ci, the weight w(q,Ci) decoder uses on model trained on Ci when decoding q with metric m is w(q,Ci) = m(q,Ci) /i’m(q,Ci’) [also tried sigmoid function – no good!]
• We tried 4 metrics for m(q,Ci) – see Foster07 for details:1. tf/idf: cos(vC,vq) 2. LSA: cos(uC,uq)3. Ngram LM perplexity: pC(q)-1/|q|
4. Interpolation coeff est. via EM: i(q,Ci), where 1 … 7 = argmax[1 … 7]Πj [Σi i*pCi (qj)] , pCi is Language Model est. on Ci, and
1 + … + 7 =1.0

Adaptation
Results:• EM interpolation works best• LM adaptation yields + 0.5 – 1.1 BLEU • TM adaptation helps on its own, but doesn’t add anything to LM adaptationOpen questions: How fine should granularity be? (7 corpora too coarse!) Can we adapt TMs as well as LMs? How can we incorporate LMs trained on unilingual target-language corpora? Can we do better than linear interpolation? (E.g., Box-Cox generalizes linear &
loglinear combination – could explore intermediate settings)

Feature Selection
Johnson07:• “Diag-and” phrase pair extraction is voodoo – a collection of
heuristics. Can we do better?• To begin with, let’s see if we can prune out some of the phrase pairs
suggested by “diag-and”. Will test null hypothesis that a phrase pair is due to chance; will reject phrase pairs that could be accidental.
• Phrase tables are huge – pruning them makes life easier• Consider two by two contingency table for phrase pair (“chat”, “cat”)
from WMT06 French-English corpus (next slide)

Feature Selection
# pairs with cat # pairs without cat Total
# pairs with chat 14 31 45
# pairs without chat 12 687,974 687,986
Total 26 688,005 688,031
H0: co-occurrences of (chat, cat) are result of random hypergeometric process constrained by marginal counts (45 occ. of chat, 26 occ. of cat) [Fisher’s exact test]. Then Pr(#(chat, cat) ≥14 | H0) = 2.636*10-53 = e-121.07 →neg-log-Pr(#(chat, cat)) = 121.07 NOTE: neg-log-Pr()=2.9957 is 5% sig. level,
neg-log-Pr()=4.6052 is 1% sig. level.

Feature Selection
• Results for English-French (WMT06): setting threshold neg-log-Pr()=25 yields +1 BLEU and eliminates 90% of the phrase table
• Results for Chinese-English (NIST06): setting threshold neg-log-Pr()=16 yields +0.3 BLEU and eliminates 65% of the phrase table
• But some weird phrases are still left in – e.g., neg-log-Pr(#(chat, spade)) = 81.48: “appeler un chat un chat” = “call a spade a spade”; neg-log-Pr(#(chat, pig)) = 45.38: “chat dans un sac” = “pig in a poke”.
Open questions: How handle these compositional cases? Instead of just using sig. testing to prune phrase tables generated by “diag-and”,
can we be more ambitious and use sig. testing to find phrase pairs?

Generalizing beyond phrases
How enable system to learn gappy & hierarchical patterns? E.g., “ne VERB pas” ↔ “not VERB”, “don’t VERB”.
NOTE: there have been many unsuccessful attempts to get syntax into SMT – e.g., OchJHU04 describes summer workshop on syntax for SMT. End result: no improvement from syntax!
Chiang05:• SMT system that learns hierarchical phrases from data• Formally, is synchronous context-free grammar• But - grammar is learned, not imposed by linguistic theory!• BLEU: 26.76→28.77 = 7.5% relative improvement on
Chinese-English task

Generalizing beyond phrases
Mandarin: Aozhou shi yu Bei Han you bangjiao de shaoshu guojia zhiyiEnglish: Australia is with North Korea have diplomatic relations that few
countries one of
Three synchronous CFG rules learned from data:1. X → [X1 zhiyi, one of X1]2. X → [X1 de X2, the X2 that X1]3. X → [yu X1 you X2, have X2 with X1]
Aozhou shi yu Bei Han you bangjiao de shaoshu guojia zhiyi → (1)Aozhou shi one of yu Bei Han you bangjiao de shaoshu guojia → (2)Aozhou shi one of the shaoshu guojia that yu Bei Han you bangjiao → (3)Aozhou shi one of the shaoshu guojia that have bangjiao with Bei Han →
(other rules) Australia is one of the few countries that have diplomatic relations with North
Korea

Generalizing beyond phrases
Learning rules from data:
• First, Chiang generates phrase table via “diag-and”
• Then, generalizes patterns seen by introducing variables. E.g.,
if saw (s1, t1), (s2, t2), (s1 zhiyi, one of t1), (s2 zhiyi, one of t2) then system generates rule X → [X1 zhiyi, one of X1].
• This overgenerates rules – in practice, Chiang imposes several heuristics to prune rule set.
Open question: Can one generate all and only useful rules in principled way –
e.g., by using significance testing?

Discriminative training
SMT uses a model Pθ(t|s) to pick best translation t for source s: t = argmaxt Pθ(t|s).
In discriminative training, want to find parameters θ that yield best t.
Problem: calculating t as a function of θ (SMT decoding) is expensive.
Two solutions:
1. Optimize over N-best lists (but no guarantee θ learned on N-best lists is optimal)
2. Constrain decoding so calculation of t(θ) is cheaper (but no guarantee θ learned with constraints is optimal for normal decoding).
^^
^
^
^
^

Discriminative training
Och03 maxBLEU method for finding loglinear weights:
Recall that SMT model is T = argmaxT,A exp (∑i λi log fi(T,A,S)).
For each sentence in small « dev » corpus S, generate N-best list. Using Powell’s algorithm, find λi that maximize BLEU (or another automatic metric). Then rerun decoder to get new set of N-best lists, which is merged with old set. Iterate. Stop when set of lists stops growing.
* This is self-correcting: bad value of θ adds bad hypotheses to set!
^
START Decoder(θ)cumulative
N-best
optimizer(Powell’s)
References
S T
S
θ̂
Discriminative training
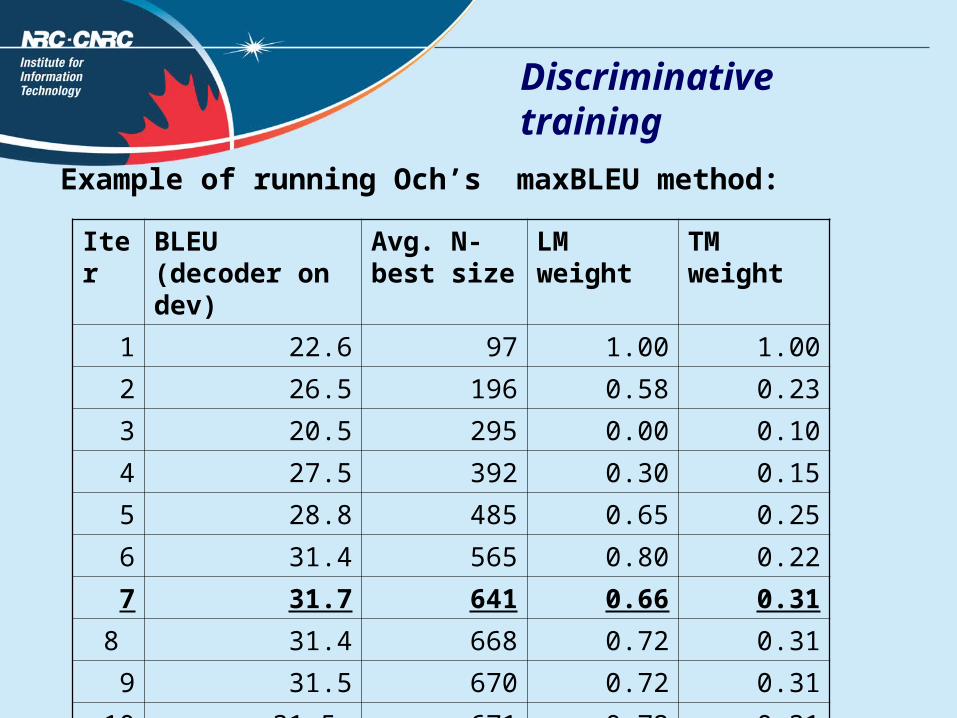
Example of running Och’s maxBLEU method:
Iter BLEU (decoder on dev)
Avg. N-best size
LM weight TM weight
1 22.6 97 1.00 1.00
2 26.5 196 0.58 0.23
3 20.5 295 0.00 0.10
4 27.5 392 0.30 0.15
5 28.8 485 0.65 0.25
6 31.4 565 0.80 0.22
7 31.7 641 0.66 0.31
8 31.4 668 0.72 0.31
9 31.5 670 0.72 0.31
10 31.5 671 0.72 0.31

Discriminative training
But what about large-scale discriminative training?Want to train loglinear model with large feature set on big training corpus,
not small “dev” (Och’s method only applied to about 10 weights). • Liang06: perceptron inputs about 1.5M features (global phrase table
& LM, individual phrase pairs & Ngrams, etc.) Decoder generates N-best list, perceptron does Viterbi-style update based on N-best oracle. Processed 67K source sentences.
• Tillmann06: similar – initialize by using forced alignments to generate maxBLEU translation for each source sentence, then merge with N-best lists. Margin-inspired loss function: punish hypotheses that score higher than N-best oracle. 35M features (individual phrase-pairs, word-pairs, N-grams, and distortion-related features). Processed 230K source sentences.
→ Both Liang06 & Tillman06 had to severely limit reordering and use narrow beam – their results no better than for conventionally trained systems.

Discriminative training
Open question: Can large-scale discriminative training be carried out for an SMT
system with free phrase reordering and a wide beam?

Kernel regression techniques
• Kernel methods for machine learning project data into a high-dimensional Euclidean space. Learning takes place in that space, provided that the learning algorithm only acts on inner products of data points in that space.
• Wang07:
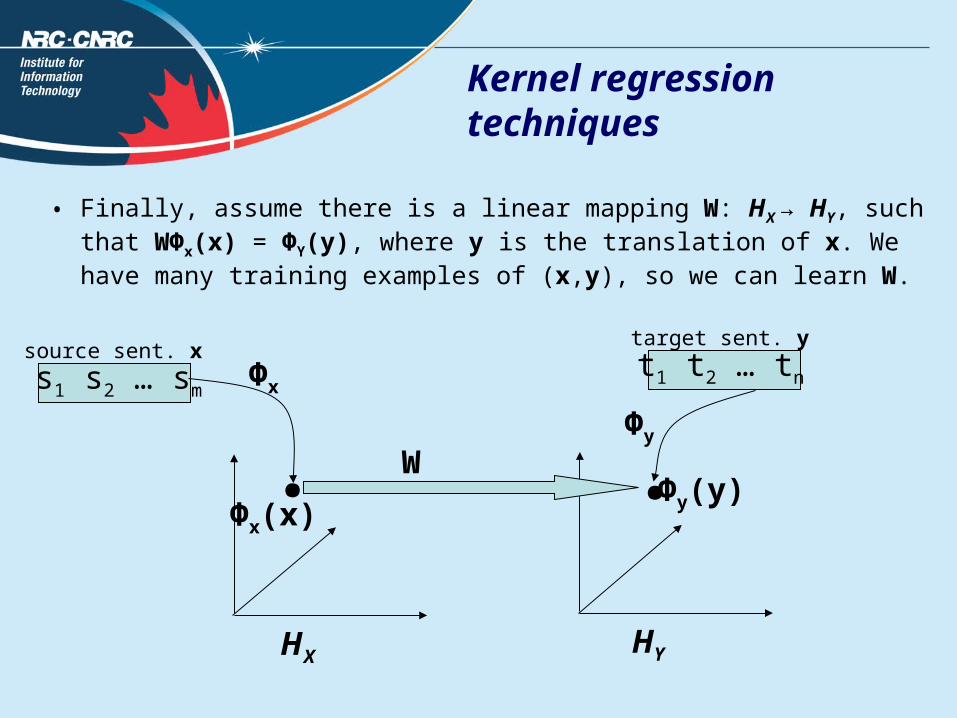
for source language Χ define its feature space HΧ as all its possible blended word N-grams*, and define Фx: Χ → HΧ , such that a sentence x ε Χ can be expressed by its feature vector Фx(x) ε HΧ . Given two source-language sentences x1 and x2, a high value of inner product < Фx(x1) , Фx(x2)> indicates that x1 and x2 are similar; a low value indicates they are dissimilar. Similarly, define feature space HY as all possible blended word N-grams for target language Y, and define ФY: Y→ HY .
*For blended word N-grams see Lodhi02
Kernel regression techniques
• Finally, assume there is a linear mapping W: HΧ → HY, such that WФx(x) = ФY(y), where y is the translation of x. We have many training examples of (x,y), so we can learn W.
.
HΧ
s1 s2 … sm
source sent. x
Фx(x)
Фx
WФy(y) .
HY
t1 t2 … tn
target sent. y
Фy

Kernel regression techniques
• For a given source sentence x, we want y minimizing the loss from WФx(x). Wang et al. tried two loss functions: least squares regression (LSR) and maximum margin regression (MMR).
• In theory, they can’t evaluate the loss until they have a complete target language hypothesis y. In practice, they piggyback on standard phrase-based decoding by pretending that the loss between a partial y and the part of x it translates is representative of final result. This loss estimate is used to score partial hypotheses.
• Thus, their system is a hybrid: phrase-based search (with constrained decoding), string kernel hypothesis scoring. They don’t use a language model.
• With training on 12K French-English sentences, their LSR model obtains performance comparable to baseline decoder. Surprisingly good (no LM, no “future score”, constrained decoding)!
^

Kernel regression techniques
• Achilles heel of their method: where m = size of training corpus, they need to do an O(m3)-time matrix inversion. Decoding is O(m)-time. That’s why they only used 12K training sentence pairs.
• Current research: instead of using 12K randomly chosen sentences, search big parallel corpus for sentence pairs whose source half resembles sentences to be translated (our suggestion).
Open questions: Can string kernel approach to MT be scaled up? Can a pure string kernel MT system be built?

The Last Word: PORTAGEshared
• NRC licenses PORTAGEshared source code to Canadian universities for research & education purposes, for a nominal fee. The goal is to develop a PORTAGE research community. The source code may be modified, provided that modifications are granted back to NRC (so we can incorporate them in future releases).
• Canadian companies can license PORTAGEshared for 1 year, for evaluation purposes only (no modifications), for a given province or territory
→ For details, contact Michel Mellinger: [email protected]

References (1)
Best overall referencePhilipp Koehn, « Statistical Machine Translation », University of Edinburgh (textbook to appear 2008, Cambridge University Press).
Papers (NOTE: short summary of key papers available from Kuhn/Foster)
Brown93 Peter F. Brown, Stephen A. Della Pietra, Vincent Della J. Pietra, and Robert L. Mercer. The mathematics of Machine Translation: Parameter estimation. Computational Linguistics, 19(2):263-312, June 1993.Chiang05 David Chiang. A Hierarchical Phrase-Based Model for Statistical Machine Translation. Proceedings of the ACL, Ann Arbor, 2005. Foster07 George Foster and Roland Kuhn. Mixture-Model Adaptation for SMT. SMT Workshop, Prague, Czech Republic, June 23, 2007.Foster06 George Foster, Roland Kuhn, and Howard Johnson. Phrasetable Smoothing for Statistical Machine Translation. EMNLP 2006, Sydney, Australia, July 22-23, 2006. Germann01 Ulrich Germann, Michael Jahr, Kevin Knight, Daniel Marcu, and Kenji Yamada. Fast decoding and optimal decoding for machine translation. Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics (ACL), Toulouse, July 2001.

References (2)
Goodman01 Joshua Goodman. A Bit of Progress in Language Modeling (extended version). Microsoft Research Technical Report, Aug. 2001. Downloadable from research.microsoft.com/~joshuago/publications.htmHuang07 Liang Huang and David Chiang. Forest Rescoring: Faster Decoding with Integrated Language Models. Proceedings of the ACL, Prague, Czech Republic, June 2007. Jelinek90 Frederick Jelinek. Self-organized language modeling for speech recognition. In: A. Waibel and K.-F. Lee, Editors, Readings in Speech Recognition, Morgan Kaufmann, San Mateo, CA (1990), pp. 450-506. Johnson07 Howard Johnson, Joel Martin, George Foster, and Roland Kuhn. Improving Translation Quality by Discarding Most of the Phrasetable. Proceedings of EMNLP, Prague, Czech Republic, June 2007. Jones05 Douglas Jones, Edward Gibson, et al. Measuring Human Readability of Machine Generated Text: Studies in Speech Recognition and Machine Translation. Proceedings of the IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP), Philadelphia, PA, USA, March 2005 (Special Session on Human Language Technology: Applications and Challenge of Speech Processing). Knight99 Kevin Knight. Decoding complexity in word-replacement translation models. Computational Linguistics, Squibs and Discussion, 25(4), 1999.

References (3)
Koehn04 Philipp Koehn. Pharaoh: a beam search decoder for phrase-based statistical machine translation models. Proceedings of the 6th Conference of the Association for Machine Translation in the Americas, Georgetown University, Washington D.C., October 2004. Springer-Verlag.KoehnDec03 Philipp Koehn. PHARAOH - a Beam Search Decoder for Phrase-Based Statistical Machine Translation Models (User Manual and Description). USC Information Sciences Institute, Dec. 2003.KoehnMay03 Philipp Koehn, Franz Josef Och, and Daniel Marcu. Statistical phrase-based translation. In Eduard Hovy, editor, Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics (HLT/NAACL), pp. 127-133, Edmonton, Alberta, Canada, May 2003. Liang06 Percy Liang, Alexandre Bouchard-Côté, Dan Klein, and Ben Taskar. An end-to-end discriminative approach to machine translation. Proceedings of the ACL, Sydney, July 2006. Lodhi02 Huma Lodhi, Craig Saunders, John Shawe-Taylor, Nello Cristianini, and Chris Watkins. Text Classification Using String Kernels. Journal of Machine Learning Research, V. 2, pp. 419-422, 2002.

References (4)
Marcu02 Daniel Marcu and William Wong. A phrase-based, joint probability model for statistical machine translation. Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP), Philadelphia, PA, 2002. OchJHU04 Franz Josef Och, Daniel Gildea, et al. Final Report of the Johns Hopkins 2003 Summer Workshop on Syntax for Statistical Machine Translation (revised version). http://www.clsp.jhu.edu/ws03/groups/translate (JHU-syntax-for-SMT.pdf), Feb. 2004. Och04 Franz Och and Hermann Ney. The alignment template approach to statistical machine translation. Computational Linguistics, V. 30, pp. 417-449, 2004. Och03 Franz Josef Och. Minimum Error Rate Training for Statistical Machine Translation. Proceedings of 41st Annual Meeting of the Association for Computational Linguistics (ACL), Sapporo, Japan, July 2003. Och02 Franz Josef Och and Hermann Ney. Discriminative training and maximum entropy models for statistical machine translation. Proceedings of 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, July 2002. Och01 Franz Josef Och, Nicola Ueffing, and Hermann Ney. An Efficient A* Search Algorithm for Statistical Machine Translation. Proc. Data-Driven Machine Translation Workshop, July 2001.

References (5)
Och00 Franz Josef Och and Hermann Ney. A Comparison of Alignment Models for Statistical Machine Translation. Int. Conf. on Computational Linguistics (COLING), Saarbrucken, Germany, August 2000.Papineni01 Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: A method for automatic evaluation of Machine Translation. Technical Report RC22176, IBM, September 2001. Tillmann06 Christoph Tillmann and Tong Zhang. A discriminative global training algorithm for statistical MT. Proceedings of the ACL, Sydney, July 2006. Ueffing02 Nicola Ueffing, Franz Josef Och, and Hermann Ney. Generation of Word Graphs in Statistical Machine Translation. Empirical Methods in Natural Language Processing, July 2002.Wang07 Zhuoran Wang, John Shawe-Taylor, and Sandor Szedmak. Kernel Regression Based Machine Translation. Proceedings of NAACL-HLT, Rochester, 2007.