open shift and docker - october,2014
TRANSCRIPT

OpenShift v3
Docker, Kubernetes, Containers
Peter Larsen, Sr. Solutions [email protected]
October 2014

Agenda
● Recent Highlights
● OpenShift Online
● OpenShift v3 – Overview
● OpenShift – detailed archiecture
● Q&A
● Demo

Recent Highlights
● OpenShift wins InfoWorld Bossie 2014 Award
● Gartner gives OpenShift edge over Cloud Foundry in report on Open Source PaaS Frameworks
● Hortonworks announces Yarn integration with v3 / Kubernetes
● Paychex added to public reference customers (CA, Boeing, FICO, Cisco, UNC)
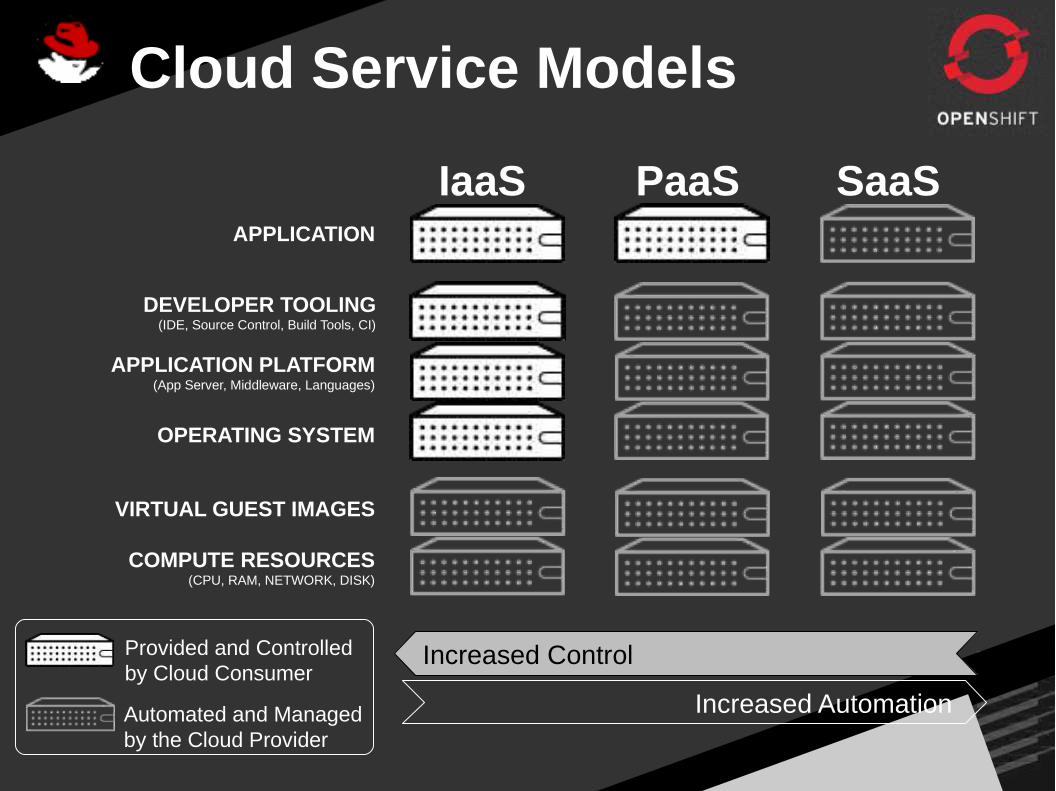
COMPUTE RESOURCES(CPU, RAM, NETWORK, DISK)
VIRTUAL GUEST IMAGES
OPERATING SYSTEM
APPLICATION PLATFORM(App Server, Middleware, Languages)
APPLICATION
Automated and Managed by the Cloud Provider
Provided and Controlled by Cloud Consumer
IaaS PaaS SaaS
Increased Control
Increased Automation
DEVELOPER TOOLING(IDE, Source Control, Build Tools, CI)
Cloud Service Models

COMPUTE RESOURCES(CPU, RAM, NETWORK, DISK)
VIRTUAL GUEST IMAGES
OPERATING SYSTEM
APPLICATION PLATFORM(App Server, Middleware, Languages)
APPLICATION
Automated and Managed by the Cloud Provider
Provided and Controlled by Cloud Consumer
IaaS+ IaaS++
Increased Control
Increased Automation
DEVELOPER TOOLING(IDE, Source Control, Build Tools, CI)
What is PaaS?
PaaS

COMPUTE RESOURCES(CPU, RAM, NETWORK, DISK)
VIRTUAL GUEST IMAGES
OPERATING SYSTEM
APPLICATION PLATFORM(App Server, Middleware, Languages)
APPLICATION
Automated and Managed by the Cloud Provider
Provided and Controlled by Cloud Consumer
OpenStack CloudForms
Increased Control
Increased Automation
DEVELOPER TOOLING(IDE, Source Control, Build Tools, CI)
Red Hat Offerings
OpenShift

Red Hat’s Cloud Portfolio
PaaS = Platform as a Service
A Cloud Application Platform
Code Deploy Run
Save Time and MoneyCode your app
Push-button
Deploy, and your App is running in the Cloud!

Today’s IT Challenge
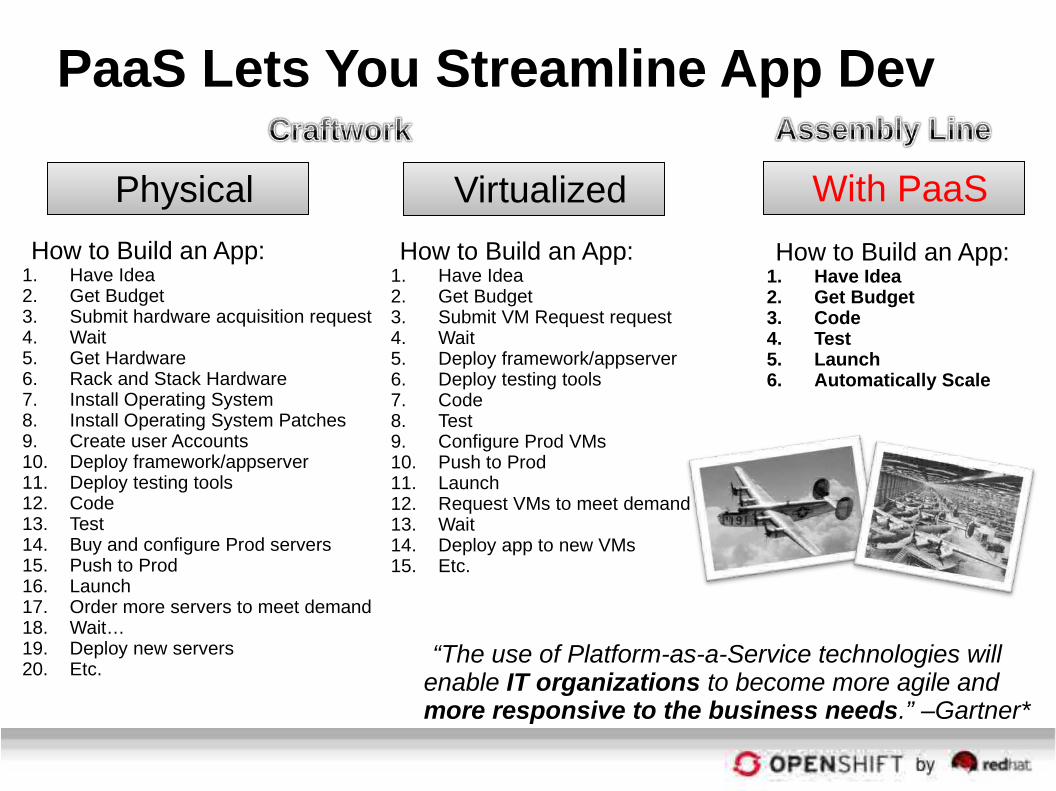
PaaS Lets You Streamline App Dev
With PaaS
How to Build an App:1. Have Idea2. Get Budget3. Code4. Test5. Launch6. Automatically Scale
How to Build an App:1. Have Idea2. Get Budget3. Submit VM Request request4. Wait5. Deploy framework/appserver6. Deploy testing tools7. Code8. Test9. Configure Prod VMs10. Push to Prod11. Launch12. Request VMs to meet demand13. Wait14. Deploy app to new VMs15. Etc.
Virtualized
How to Build an App:1. Have Idea2. Get Budget3. Submit hardware acquisition request4. Wait5. Get Hardware6. Rack and Stack Hardware7. Install Operating System8. Install Operating System Patches9. Create user Accounts10. Deploy framework/appserver11. Deploy testing tools12. Code13. Test14. Buy and configure Prod servers15. Push to Prod16. Launch17. Order more servers to meet demand18. Wait…19. Deploy new servers20. Etc.
Physical
“The use of Platform-as-a-Service technologies will enable IT organizations to become more agile and more responsive to the business needs.” –Gartner*
Velocity and Efficiency enable Scalability
●Scalable Applications●Scalable Infrastructure●Scalable Workflows/Processes
Scale IT Like a Factory with PaaS

DevOps? Continuous Delivery?
What is DevOps? - The application of software development principles to the tasks of IT Operations, often automating Operations tasks such as application code deployment and promotion.
What is Continuous Delivery? – The automation of code promotion through the application lifecycle so that code changes can be pushed into production environments very often.
But how do we do these things?

Code Deploy Run
PaaS leverages automation technologies and a cloud architecture…
to drive Velocity, Efficiency and Scalability in IT.
Accelerate IT

OpenShift is
PaaS by Red HatMulti-languageAuto-scalingSelf-serviceOpen Source
Enterprise-gradeSecure
Built on Red Hat
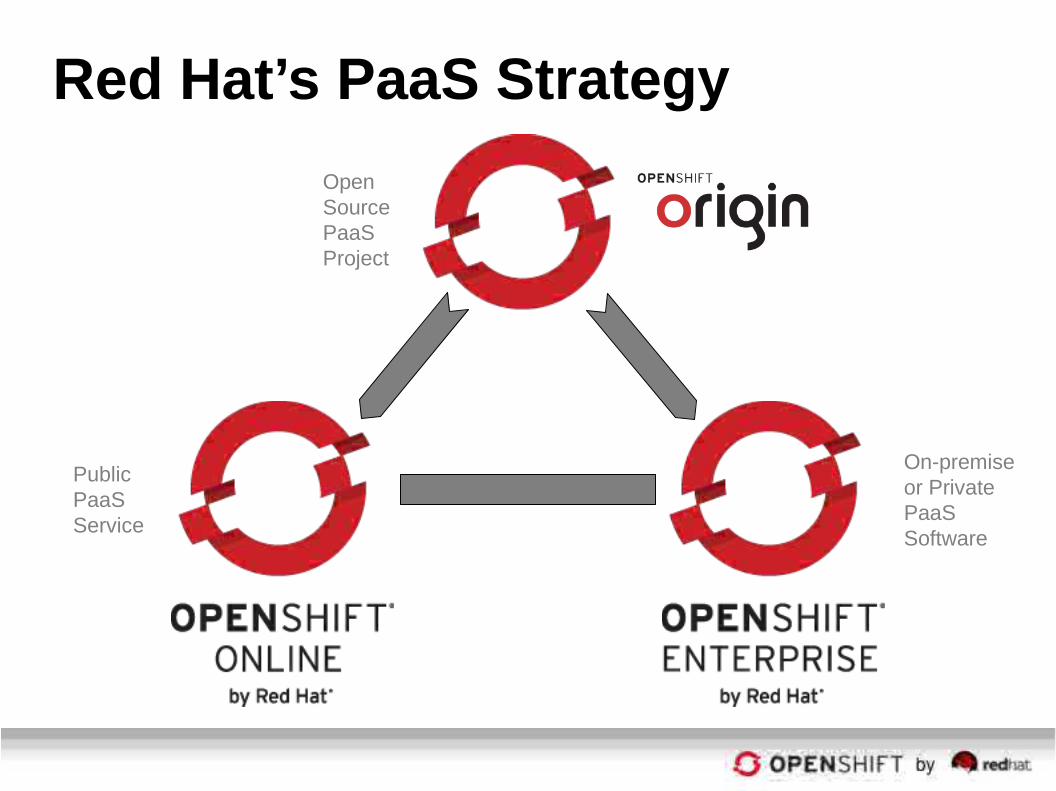
Red Hat’s PaaS Strategy
Public PaaSService
On-premise or Private PaaSSoftware
Open Source PaaSProject

OpenShift Online

OpenShift Online Adoption

Docker Intro
● Great intro here: https://goldmann.pl/presentations/2013-red-hat-docker-introduction
● https://www.docker.com/whatisdocker/

OpenShift v3 – Big Picture
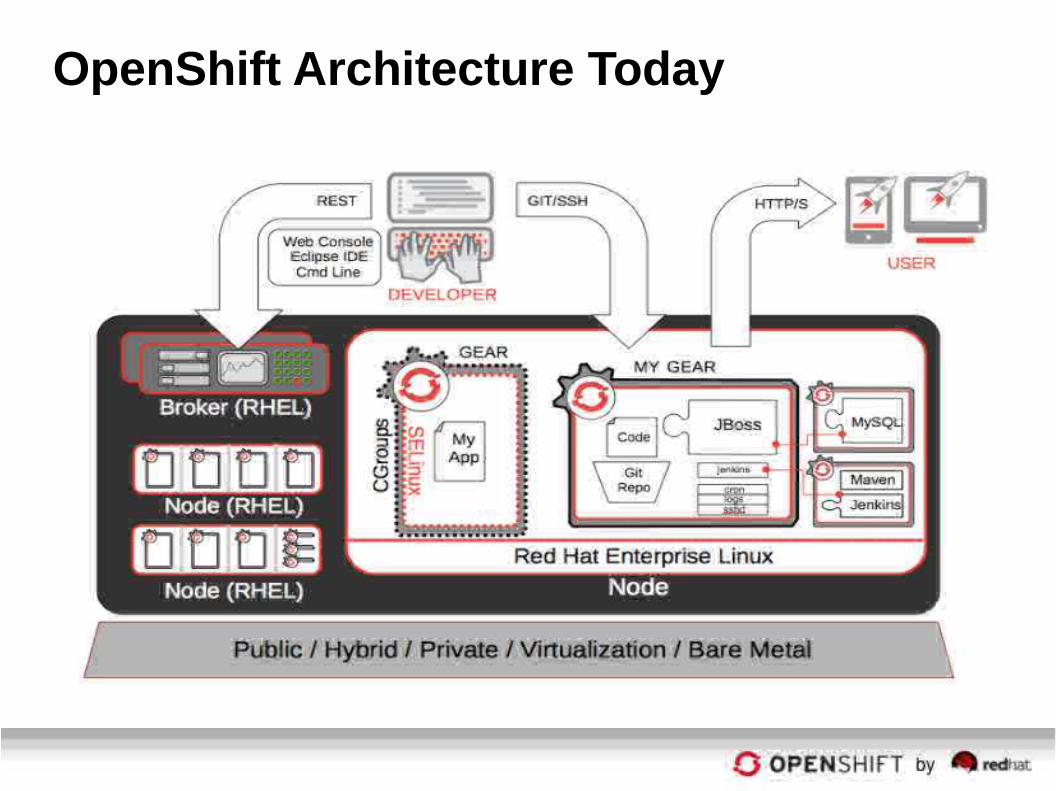
OpenShift Architecture Today

Node
Developer
Node (RHEL)
ReplicationController
Python
Pod
JBoss
PodPostgres
Pod
pgadmin
Tomcat
Pod
JBoss
Pod
Node
(RHEL 7 / Atomic)
Node
(RHEL 7 / Atomic)
Ruby
Pod
Node.js
Pod
Master
(RHEL 7 / Atomic)
etcd
Scheduler
OAuth
REST
Web ConsoleCLIIDE
Service Layer
Pod
Pod
Pod
Pod
Routing Layer
Application Users
GIT / SSH
OpenShift v3 Architecture

What's Different?● New base OS
● RHEL 7 + Atomic vs. RHEL 6● New container model
● Docker vs. v2 “Gears”● New orchestration engine
● Kubernetes vs. v2 “Broker” ● New packaging model
● Docker images vs. v2 “Cartridges”● New routing tier
● Platform routing layer vs. v2 Node-based routing● More services and a better developer experience

Why Is This Better?
● Standard containers API
● Container-optimized OS
● Web-scale orchestration
● Expanded choice of services
● Enhanced developer and operator experience
● Industry standard PaaS stack!

OpenShift v3 – Key Principles

Redefine the “Application”
● Networked components wired together● Not just a “web frontend” anymore● Service-oriented-Architectures / microservices are real● HTTP frontends are just one type of component
● Critical: relationships between components● If you can’t abstract the connection between
components you can’t evolve them independently

Immutable Images as Building Blocks
● Image based deployment (Docker)● Create once, test everywhere● Build a single artifact containing the dependency chain● Needs tools to manage the build process, manage
security updates● Declarative application descriptions
● Record “intent” - this links to this, this should be deployed like this, and let system converge to that intent

Decouple Dev and Ops
● Reduce complexity of application topology● Less need for complicated post-deploy setup
● Allow teams to share common stacks● Better migration from dev stacks to production stacks● Reduce vendor lock-in
● Ops and Devs can use same tools● OpenShift is an app, so are most organizational tools● Ensure patterns work cleanly for both

Decouple Dev and Ops (cont.)
● Templatize / blueprint everything● Ensure that organizations have clear configuration
chains● Define common patterns for rolling out changes
● Easily provision new resources● Allow infrastructure teams to provision at scale● Subdivide resources for organizational teams with hard
and soft limits

Abstract Operational Complexity
● Networking● App deployers should see flat networks● Define private vs public, internal vs external, fast vs
slow● Storage
● Most components need *simple* persistent storage● Ensure storage is not coupled to the host
● Health● Every component should expose health information

Multi-Level Security
● Ensure containers “contain”● SELinux, user namespaces, audit● Decompose the Docker daemon over time● Fine grained security controls on SSH access
● Allow easy integration with existing security tools● Kerberos, system wide security, improved scoping of
access● More customization possible
● Allow application network isolation

Architectural Overview

Major components
● Docker image: Defines a filesystem for running an isolated Linux process (typically an application)
● Docker container: Running instance of a Docker image with its own isolated filesystem, network, and process spaces.
● Pod: Kubernetes object that groups related Docker containers that need to share network, filesystem or memory together for placement on a node. Multiple instances of a Pod can run to provide scaling and redundancy
● Replication Controller: Kubernetes object that ensures N (as specified by the user) instances of a given Pod are running at all times.
● Service: Kubernetes object that provides load balanced access to all instances of a Pod from another container in another Pod.
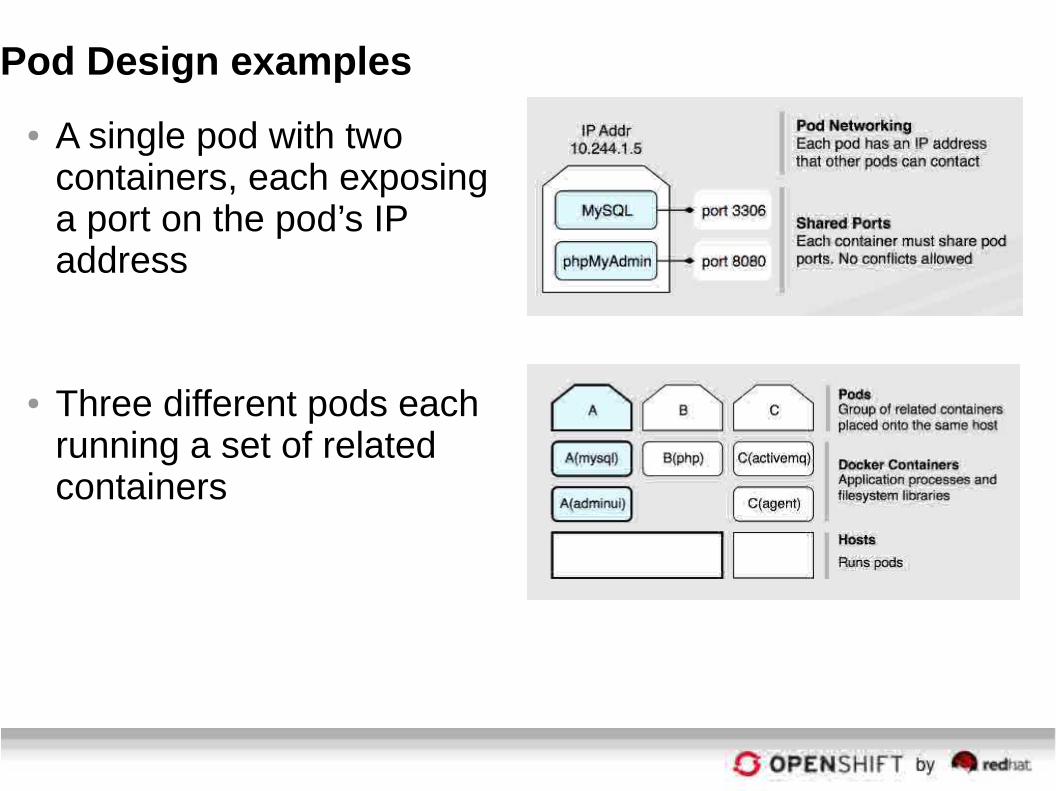
Pod Design examples
● A single pod with two containers, each exposing a port on the pod’s IP address
● Three different pods each running a set of related containers
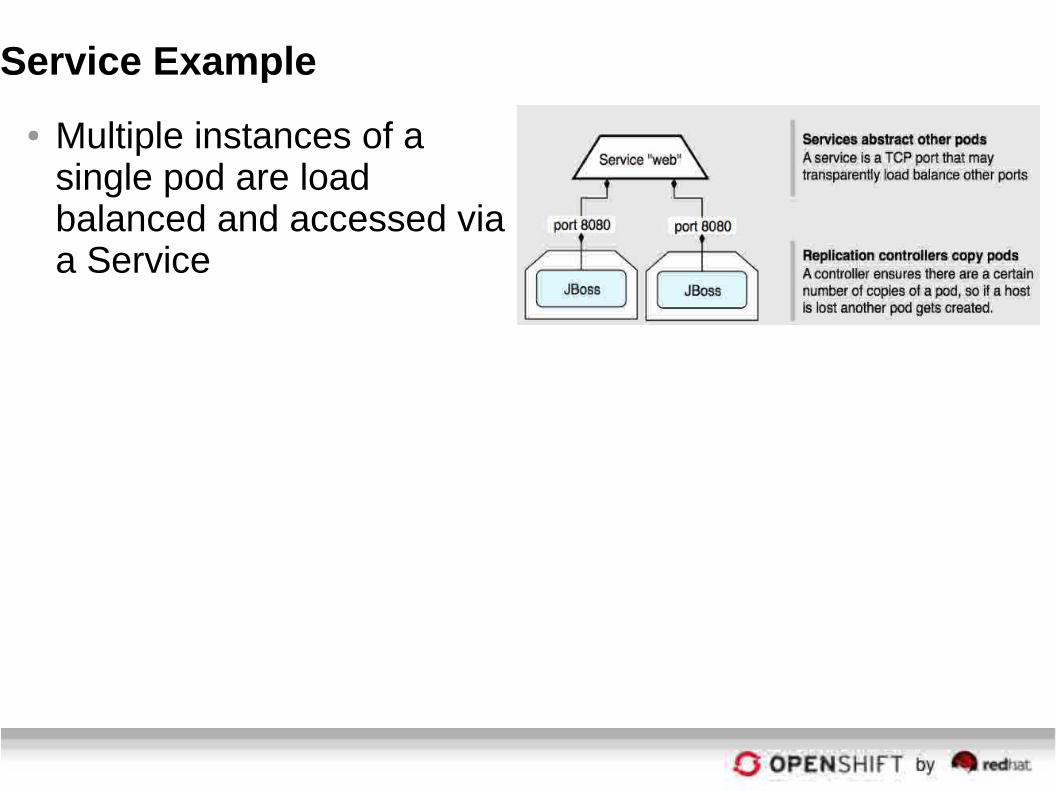
Service Example
● Multiple instances of a single pod are load balanced and accessed via a Service
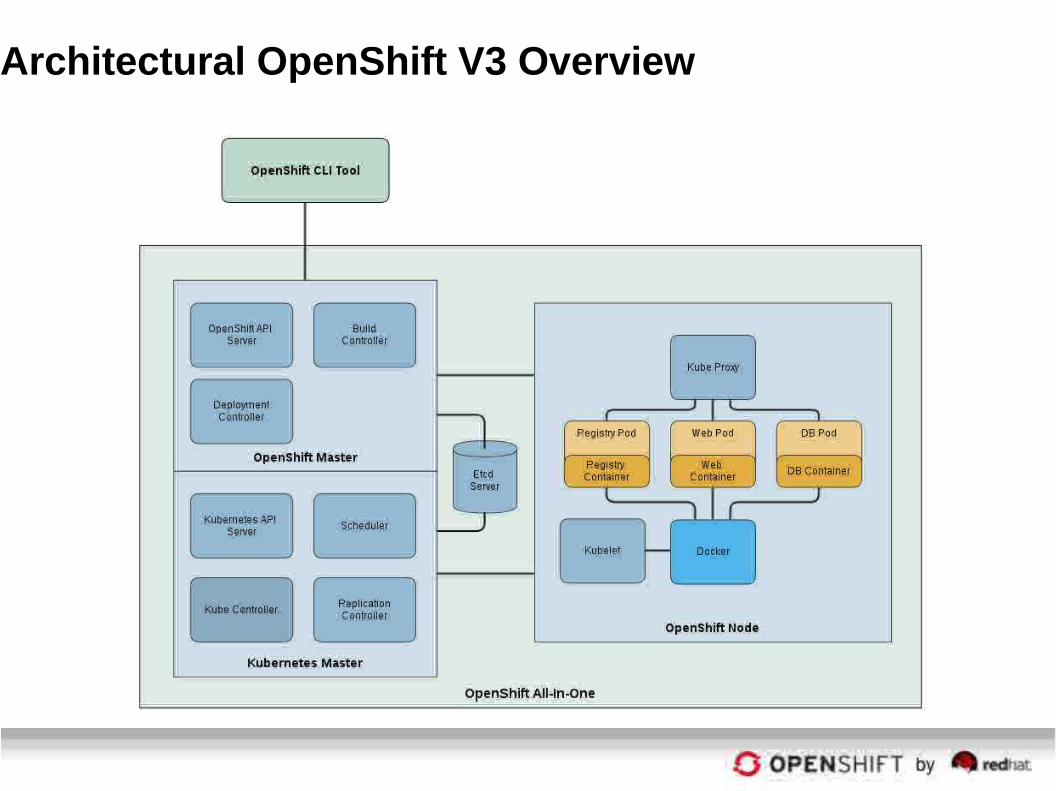
Architectural OpenShift V3 Overview

Getting Started

Architecture Details
Shamefully borrowed from: https://github.com/openshift/openshift-pep/blob/master/openshift-pep-013-openshift-3.md
● This is work in progress. Absolutely subject to change!

Building and Managing images

Docker Image● An executable image that represents a runnable
component (web app, mysql, etc), a set of exposed ports, and an set of directories that represent persistent storage across container restarts– an image may have extended metadata beyond that specified in the
Dockerfile/registry
– how many instances of the image are required for normal function (1, 1..N)
– the environment variables it exposes that must be generated or specified (beyond the defaults in the Dockerfile itself)
– additional port metadata describing what type of network services are exposed
– named commands that may be run inside of an image for performing specific actions

Docker images● each image (contents and metadata) are immutable and changing
them requires creating a new image (the reference to older image data or older metadata may be preserved)
● image metadata may change over successive versions of an image - multiple images may share the same metadata
● any image can be executed (which runs its default command/entrypoint), but different images may have different roles and thus not be suitable for execution as a network service
● An example is an image that contains scripts for backing up a database - the image might be used by a service like cron to periodically execute tasks against a remote DB, but the image itself is not useful for hosting the DB
● images are protected by reference - if you have access to a resource that refers to an image, you can view that image

Build● A build creates a docker image as output and places that image into a single image
repository.
● there are two defined types of build:– Docker build takes as input as input a source repository or an archive containing a resource
– Source build takes as input a builder image and a source repository
● A source build is typically based on either an image, OR an image repository
● a build is owned by a project
● a build result is recorded whenever a build happens– a build provides a webhook resource for remote servers to notify a build that an underlying image or repo or
archive has changed (allows consumers to trigger builds)
– build results history may be removed when it reaches certain limits
● a build has configuration to control whether an automatic build occurs when an input changes
● a build exposes an endpoint that allows a consumer to POST an archive that results in a build– Example: post a WAR file to a source-to-images build that results in that WAR being deployed
– Example: post a zip of the source contents of a Git repo to the build endpoint to result in a Docker image build using those contents as the Docker build context

Image repository
A set of images with a given name corresponding to a Docker repository in a registry (a set of images where a single tag represents the latest image that people pull by default). A repository has 1..N tags - the implicit "latest" tag refers to the image that would be retrieved / used if the user did not specify a tag
● An image repository has a set of default metadata which is applied to every image created under that stream, which allows an operator to define an image repository and then push images to the stream and have that metadata set
● Use case: allows operators to provide security updates to end users - allows end users to rely on a continuously maintained piece of software
● Use case: allow developers and operators to share a set of images across multiple applications and environments
● An image repository would expose a webhook that allows a consumer to register a new image, as well as integrating into a Docker registry so that a docker push to a certain repository (probably uniquely identified by name and a short id) would add that image * Image streams are owned by a project or are public, and an administrator of that project can grant view access to that stream to other projects. Anyone who can view an image repository can use it. If access is revoked, any builds or services that reference that stream can still use it.
● Retention of images is controlled by reference - deployed services, service deployment history, and recent builds all take strong references on individual images in a stream and control when images pass out of scope.
● Image repositories may be global in scope to a deployment as well as per project

Source Code Repository● OpenShift 2.x embeds a git repository in the first gear of every application
● OpenShift 3.x, source code repositories are referenced or owned by a service, but are not physically located inside the gears of that service.
● The APIs for repositories should be flexible to other types of source code repositories, but OpenShift will focus on Git integration
● When creating a service a user may
– specify that a source code repository be allocated for that service
● the repository will be secured with the keys and tokens of the owning project
● a build will be defined using the "source to images flow" if the image(s) used by the service support STI
● a git postreceive hook will be configured that triggers the build hook, if a build exists
– reference an external source code repository and optionally provide authentication credentials for the repository (private key, username or password)
● a build will be defined using the "source to images flow" if the image(s) used by the service support STI
● the user will be able to download a commit hook that they can put into their git repository
– specify no repository
● When a source code repository is connected to a build, there is a set of config on that reference that what source code specific options apply (similar to 2.x):
– Trigger build only a specific branch (optional, defaults to false)
● Whether to automatically build (is the link present or not)
– Any service with a referenced source code repository has a source code webhook exposed via the API which can be used to trigger the default flow

Scenarios
● A user should be able to easily push a Docker image to OpenShift and have applications be redeployed
● An integrator should be able to easily notify OpenShift when the inputs to a build have changed (source code or base image) as well as notify OpenShift of the existence of a new image generated by an external build
● Workflows on top of images should be able to refer to an image repository instead of having to directly specify an image
● A system administrator can manage the total images in use across the system by setting retention policies on accounts

Integration
● Images may be referenced externally (via their full name <registry>/<user>/<repository>) or pulled into the integrated OpenShift registry
● An image repository should support a direct docker push with access control from a Docker client to the integrated OpenShift registry docker push my.openshift.server.com/<some_generated_user_name>/mysql-58343
● An image repository should have a webhook endpoint which allows a new image to be created when a 3rd party builds an external image (like the DockerHub)
● In the future it would be nice to be able to automatically pull that image into the integrated registry
● A build can be triggered by a DockerHub build webhook (for a base image) or a GitHub commit webhook (for an external source repo)

Multi-tenancy and Isolation● In OpenShift 2.x, the primary unit of access control was
the domain, which has a membership list and each member is granted a specific role.
● In 3.x this pattern will continue, but we will rename the domain to a project to more closely associate the concept with its common use.

Everything scales● Stateful – copy state between systems
● Stateless
● 2/3 tier architecture

What is: Container / Gear?
● A running execution environment based on an image and runtime parameters– a container encapsulates a set of processes and manages their lifecycle
and allows a unit of software to be deployed repeatably to a host
– gear is the historical OpenShift term for a container and will continue to be exposed via the user interface

What is: Pod ?● A set of related containers that should be run together on
a host as a group. The primary motivation of a pod is to support co-located, co-managed helper programs.– a pod enables users to group containers together on a host and share
disk storage, memory, and potentially access each other's processes.
– images beyond the first in a pod can be thought of as plugins - providing additional functionality through composition
– a pod template is a definition of a pod that can be created multiple times

What is: Service ?
● A pod definition that can be replicated 0..N times onto hosts. A service is responsible for defining how a set of images should be run and how they can be replicated and reused by other services, as well as defining a full software lifecycle (code, build, deploy, manage).– All services have environment variables, aliases, an optional internal or
external source code repository, a build flow (if they have a source code repository), and a set of deployments
– a service is a template for a sequence of deployments which create actual containers. The service has 0..N current deployments, but typically transitions from one deployment to another.
– a user may customize the ports exposed by an image in a service

What is: Stateful Service ?● Some images may depend on persistent disk data (such
as a database) - these images have special rules that restrict how a pod containing them may be replicated, moved, or configured– in a stateful service, a "move" operation is exposed for each pod that will
relocate the pod onto another host while preserving the data of that pod
– stateful services may incur downtime when a host is rebooted or fails, but the system will be designed to minimize that downtime
– by design, stateless services may be aggressively moved and the system will prefer to create extra pods in new locations and delete existing pods in the old locations

What is: Service Environment ?
● Each service has 0..N environment variables (key value string pairs) which may be set by the user, automatically generated at creation, or automatically provided by a link, that are available at runtime in each container in the service– Automatically generated environment variables may represent passwords or
shared secrets, and can be overriden by the user post-creation
– Link environment variables may be overridden by a user environment variable (to the empty string or a different value) but if the user unsets the user environment variable the link variable will return
– The pod template for a service may also define container level variables, which override service environment variables.
– If an image requires a variable be generated, but does not publish it (via a link), the variable is only defined on the pod template. A published variable is added to the service environment.
– Changing an environment variable may require a deployment (if only to update environment settings). It may be desirable to offer a faster change process.

What is: Deployment ?
● A historical or in-progress rolling update to a service that replaces one service configuration with another (primarily updating the image, but also changing ports, environment, or adding new images). A deployment is a snapshot of the state of a service at a point in time, and as such records the history of the service.– Recording deployments allows a user to see the history of the deployments of a service, rollback to a previous
configuration, and to react to ongoing deployments
– A deployment may be automatically triggered by a build, by manual intervention with a known image, or via an API call such as a DockerHub webhook.
– Some deployments may fail because the ports the old image exposes differ from the ports the new image exposes
– A deployment in the model records the intent of what a deployment should be - a deployment job carries out the deployment and may be cancelled or stopped. There may be pods representing multiple deployments active in a service at any one time.
– A deployment retains a reference to an image - the retention policy of deployments controls which references are valid, and as long as an image is referenced it will not be deleted.
– A deployment does not control the the horizontal scale of a service, and during a deployment the number of pods created may exceed the current horizontal scale depending on the type of deployment requested.
– There are different deployment types:
– External - user defines the new deployment, and creates or manipulates the underlying replication controllers corresponding to the service to add or remove pods for old and new versions
– Simple rolling deploy - pods corresponding to the new template are created, added to the load balancer(s), and then the old pods are removed from the load balancer and then deleted

What is: Link ?
● A relationship between two services that defines an explicit connection, how that connection is exposed environment, a proxy or load balancer), and potentially whether start order is significant.– Use Case: A link allows one service to export environment variables to
another service
– Use Case: A link may be used by the infrastructure to create or configure proxies to service a load balanced access point for the instances of a service
– A link represents an intent to connect two components of a system - the existing "add cartridge" action is roughly translated to "create a new service and link to the existing service with a set of defaults".
– A link as described is different than a Docker link, which links individual containers. Service links define how sets of Docker links may be created.

What is: Template ?
● A template defines how one or more services can be created, linked, and deployed– Use case: A template allows users to capture existing service
configurations and create new instances of those services
– A template also may have a deployment script (an embedded text blob, URL, or command in a known image), which is invoked as a job after the service definitions, links, and environment variables have been created
– A template merges the existing quickstart and cartridge concepts to allow precanned applications or units of software to be deployed.
– A template may be the target of the "create and link" action, which allows complex components to be templatized and reused. The template must identify the components that should be linked in this fashion.
– Templates may be global in scope to a deployment as well as per project

Relationships
● Resources are nested:– 0..N public image repositories
● 1 account
– 0..N projects
● 0..N image repositories● 0..X owned image repositories● 0..Y shared image repositories
● 0..M references to images (images are one-to-many repositories)● 0..N services
● 1 active pod definition (1..M images)● references 1..M image repositories or explicit images
● additional per image config that becomes the template for containers● 0..N instances of a pod● 0..N deployments● 0..1 source code repositories● 0..1 builds● 0..N aliases● 0..N environment variables● 0..N links
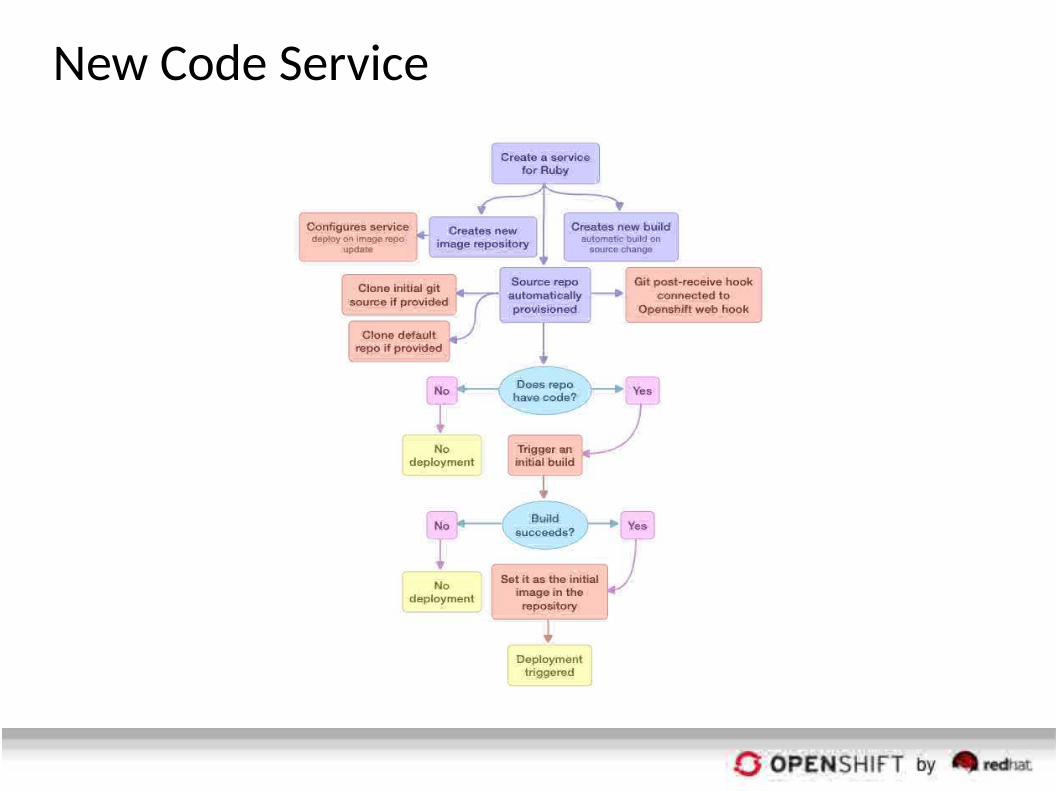
New Code Service
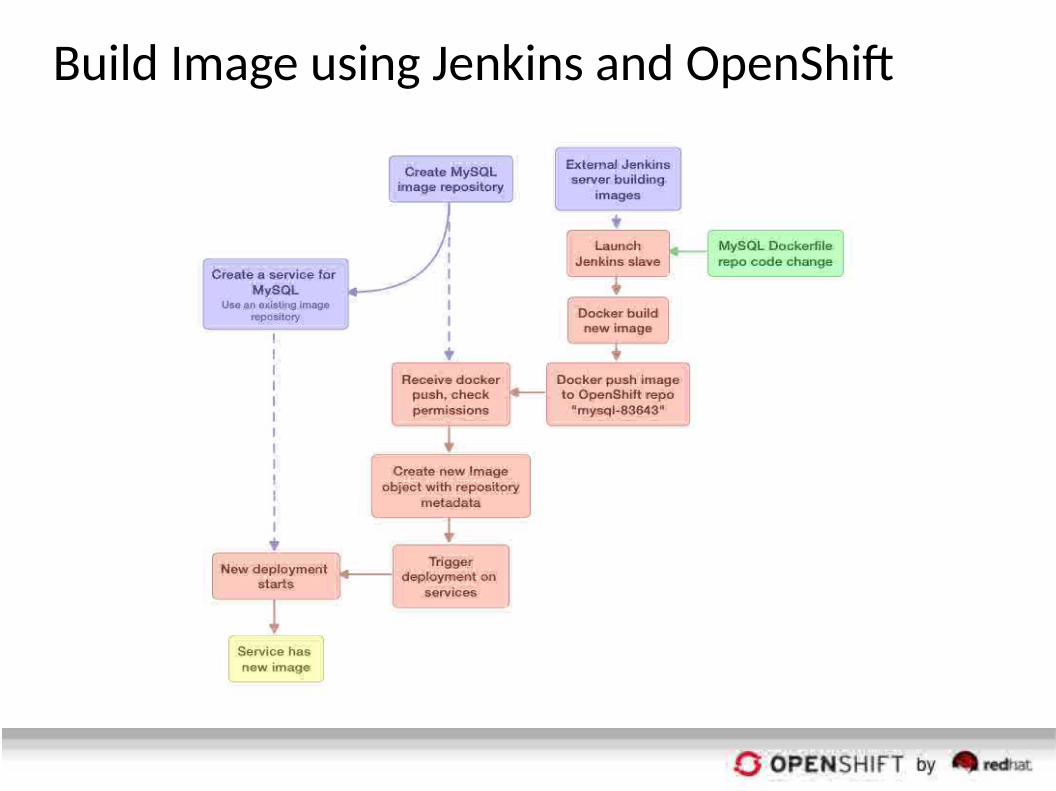
Build Image using Jenkins and OpenShif

● System Components

System Components – the big picture

Subsystem: API and Images (Purple)
● Implements a high level API that allows end users and clients to offer an application centric view of the world, vs a container centric view. Performs project validation on incoming requests and invokes/triggers the orchestrator and scheduler as necessary.
● The API allocates source repositories via an API and configures them to bind to build hooks. The build hooks can trigger builds via the orchestrator onto hosts as containers, and then after completion push the new images into the registry and trigger other orchestrations like deployments.

Subsystem: Orchestrator (green)
● A job API that schedules sequential execution of tasks on the cluster (which may run for seconds, minutes, or hours). Examples include triggering a build, running a long deployment across multiple services, or scheduled operations that run at intervals.
● A job creates a "run-once" pod and has an API for callback, blocking, or status.
● The orchestrator encapsulates all operations that run to completion that a client may wish to block on.

Subsystem: Scheduler (red)
● The scheduler (and cluster manager) would be Google's Kubernetes and exposes an API for setting the desired state of a cluster (via a replication controller) and managing the cluster.
● The scheduler is related to ensuring containers are running with a certain config, for autohealing the cluster as issues develop, and for ensuring individual hosts are in sync with the master.
● Over time, integration at a lower level with Mesos for fine grained resource allocation is desirable.

Events (Pink)
● The event subsystem aggregates and exposes events from many sources to enable administrators, users, and third party observers to make decisions about the health of a system or container.
● The policy engine represents a component that may make decisions automatically based on events from the cluster. Examples of events include container exit, host unreachable, router detecting failed backend, node removed, or an alert generated by a hardware monitoring agent.
● The policy engine is able to decide on the appropriate action in a customizable fashion. Some events are core to other subsystems and may flow through alternate means (as an example, Kubernetes may aggregate exit status of containers via its own API), but the general goal is to expose as much of the activity of the system to external observation and review as possible.
● System integrators may choose to expose the event bus to containers.

Subsystem: Routing and Load Balancing (blue)● Routers provide external DNS mapping and load balancing to
services over protocols that pass distinguishing information directly to the router (HTTP, HTTPS, TLS with SNI, and potentially SSH).
● Routers subscribe to configuration changes and automatically update themselves with new configuration, and routers may be containerized or virtual (converting those changes to API calls to a system like an F5).
● Other automatic capabilities exist to load balance individual services within the cluster - these would be exposed via configuration on link relations between services and would ensure a set of services would be available. Implementations may choose to implement these as local proxies per host, or to reuse the shared routing infrastructure.

Subsystem: Containers (yellow)
● The execution of containers is handled by systemd unit files generated by geard.
● Key access for SSH or additional linking information would be propagated to hosts similar to the container configuration.
● The host may also be configured to run one or more additional containers that provide monitoring, management, or pluggable capabilities.
● The container subsystem is responsible for ensuring logs are aggregated and available to be centralized in the cluster.

Subsystem: Cluster Health (orange)
● The status of containers and hosts is monitored by active and passive checks over TCP or through process level calls.
● The state reconciler has the responsibility of acting on failing heath checks on containers, while the host health monitor reports failing hosts to the event subsystem for the policy engine to act on.

Git Repository Hosting
● Rather than forcing Git to be directly integrated into the hosting infrastructure, OpenShift 3.x will allow external integration to Git hosting.
● The requirements on a host are to be able to dynamically create a repository on demand, set git postreceive hooks, and assign security to those repositories that matches the ownership model in OpenShift.

Docker Registry
● OpenShift should utilize any server implementing the Docker registry API as a source of images, including the canonical DockerHub, private registries run by 3rd parties, and self hosted registries that implement the registry API– In order to connect to private registries, it is expected that authorization
information may need to be associated with the registry source
– It would be desirable to develop plugins that allow smooth integration of an external access control model with individual repositories in the registry
– In many systems, imposing quota limits on repositories (size of image, number of images, total image size) may be necessary
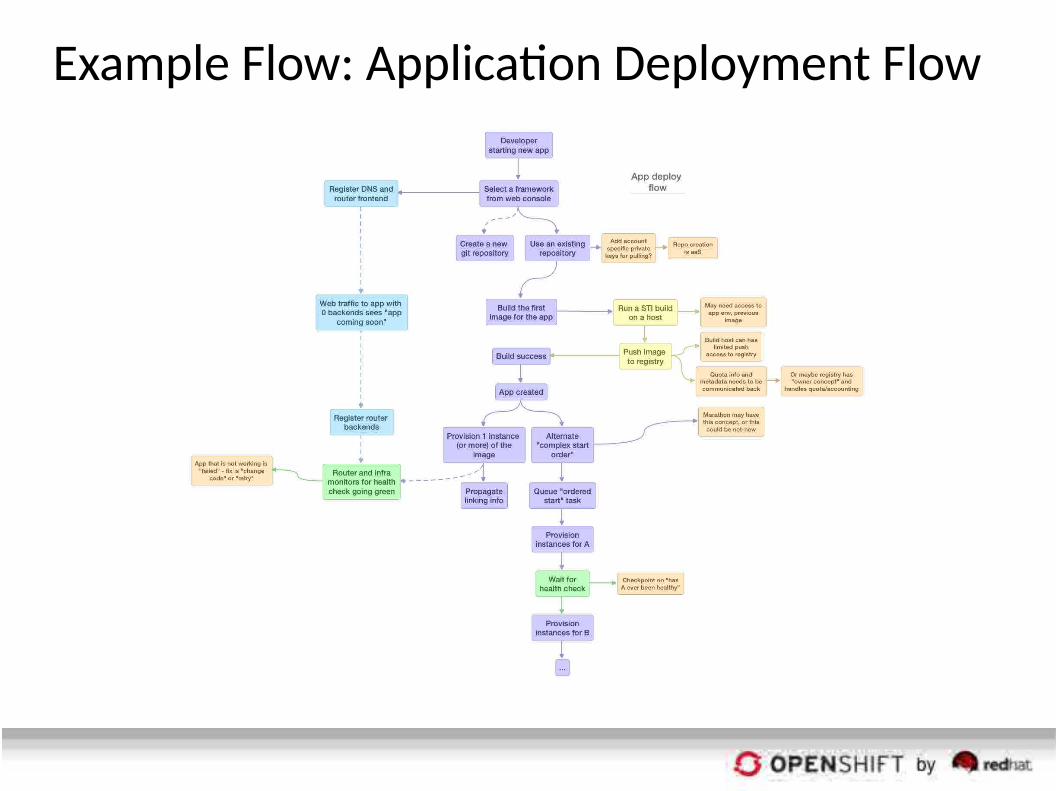
Example Flow: Application Deployment Flow

Example Flow: Git Push Path

Thank YouAnd now let's DEMO things