openfest 2012 : leveraging the public internet
TRANSCRIPT

Leveraging the public internet
Tonimir Kisasondi, mag.inf., EUCIP

$whois tkisason
• Junior resarcher @ www.foi.hr • Head of Open Systems and Security lab
• Likes to build and break things • [email protected] • skype:tkisason

What happens when you digitize the whole world?
• Google, Facebook, Twitter • Is it a bubble or a valid business model?
• The new buzzword is big data • Storage per capita doubles every three
years • Kryder's law says that storage density
doubles every 18 months • Can you really store the whole world?

What happens when you digitize the whole world?

What happens when you digitize the whole world?
• Storing 20 Tbps traffic • Map/Reduce like infrastructure to mine and
combine data • Why is this interesting to us now?
o Storage is cheap o Big data is useful everywhere o Use tricks that intel agencies use to enable cool stuff o It’s not rocket science... o Yes, the most interesting applications are in cross
disciplinary fields

First: OSINT
• OSINT: Open Source Intelligence o Finding, selecting and acquiring information over
open, publicly available sources like newspapers, internet, books, internet, social networks (twitter)...
o Various registries (firm, open postings, public listing) o Metadata o Mine those, and you might find a lot of interesting
stuff
o White zone – Legal and ethical o Black zone – Illegal and Unethical o Gray zone – Legal but unethical

First: OSINT
• Not everything is OSINT, but you can actually glean interesting data from almost anything
• It worked for the guys that wrote Splunk, so
they decided to write Splunk. • It works for data mining folks.

Data analysis 101
• Data is just data, you have to correlate it or put it in context for it to be useful o Find outliers o Spot differences o Find common attributes o Find connections, not answers o First identify, then try to interpret o Put data into perspective, seek help J o "Data driven design”
• A nice showcase of data driven design: o A/B Testing

Do i need advanced statistics?
• Most of the time: No • Are statistics awesome? Yup • Well, don’t play with things where you can
get hurt. J • Seek professional help
• Grep, Google refine/Mojo facets, and your favorite scripting languages are just fine...

How can we approach the problem
• There are many (finished) tools, if they help, great
• Roll your own script • Duct tape some finished libraries • Most of the times it takes less time then finding a
tool. • Cheating and stealing is encouraged. ;)

Finished tools
• Wget, python, ruby, perl... • Just kidding
• Tapir • Maltego • Metagofil, FOCA, ExifTool • Wayback machine (Extremely interesting)

Bad design 101
• If you hack it together, watch out for some gotchas
• Line per line analysis o Minimal complexity O(n)
• You can easily kill the speed of your script/parser/*
• Best separator is \t • .split() is godsent

ignorecase?
#!/usr/bin/python import re a = open("access.log") b = open("test.log","w") for line in a: if re.search("DENIED",line,re.IGNORECASE): b.write(line) b.close() $ time ./re-search.py real 0m4.516s user 0m4.444s sys 0m0.056s

simple RE
#!/usr/bin/python import re a = open("access.log") b = open("test.log","w") for line in a: if re.search("DENIED",line): b.write(line) b.close() $ time time ./re-search.py real 0m2.520s user 0m2.456s sys 0m0.056s

find
#!/usr/bin/python a = open("access.log") b = open("test.log","w") for line in a: c = line.find("DENIED") if c >= 0 : b.write(line) b.close() $ time ./testparse.py real 0m0.781s user 0m0.728s sys 0m0.044s

grep
$ time grep DENIED access.log > test real 0m0.074s user 0m0.040s sys 0m0.032s

To sum it up...
Python RE ignorecase : 4.516s Python RE : 2.520s Python find : 0.781s grep : 0.074s

Primer on useful and interesting tools
• ipython o http://ipython.org/
• python-nltk o http://nltk.org/ (nltk.clean_html(messy_html))
• python-requests o www.python-requests.org
• python-graphviz o http://code.google.com/p/pydot/
• python-google by Mario Vilas o https://github.com/MarioVilas

pydot and graphviz #!/usr/bin/python import pydot graph = pydot.Dot(graph_type='graph') graph.add_edge(pydot.Edge('link 1','person 2',label='link 3')) graph.add_edge(pydot.Edge('person 2','person 3',label='link 4',color="red",penwidth=6)) ......... graph.write_png('output.png',prog='dot')

Visualization: pydot and graphviz

So, how about a short showcase of some things i did
• Yeah, they are lame, and simple • Works for me
• Available on github • Hope they can motivate you to do some fun
and simple “one afternoon” stuff • Most of the “hard” stuff is easy once you try
to hack it together

mkwordlist - https://github.com/tkisason/gcrack
• Idea: Create wordlists with google results for a set of keywords
• For a keyword return top 5 links (or N) • Scrape and clean with NLTK • Optional lowercasing for future mutations
o You can use JtR/HashCat with a ruleset to mutate the lists
• Result: Nice targeted wordlist generator

mkwordlist - https://github.com/tkisason/gcrack
• Some other cool things o Keywords can be google dorks
§ site:.bg § filetype:txt § “”
• Interesting results for targeted attacks • Broad keywords are also ok
o If you are pentesting a company or similar
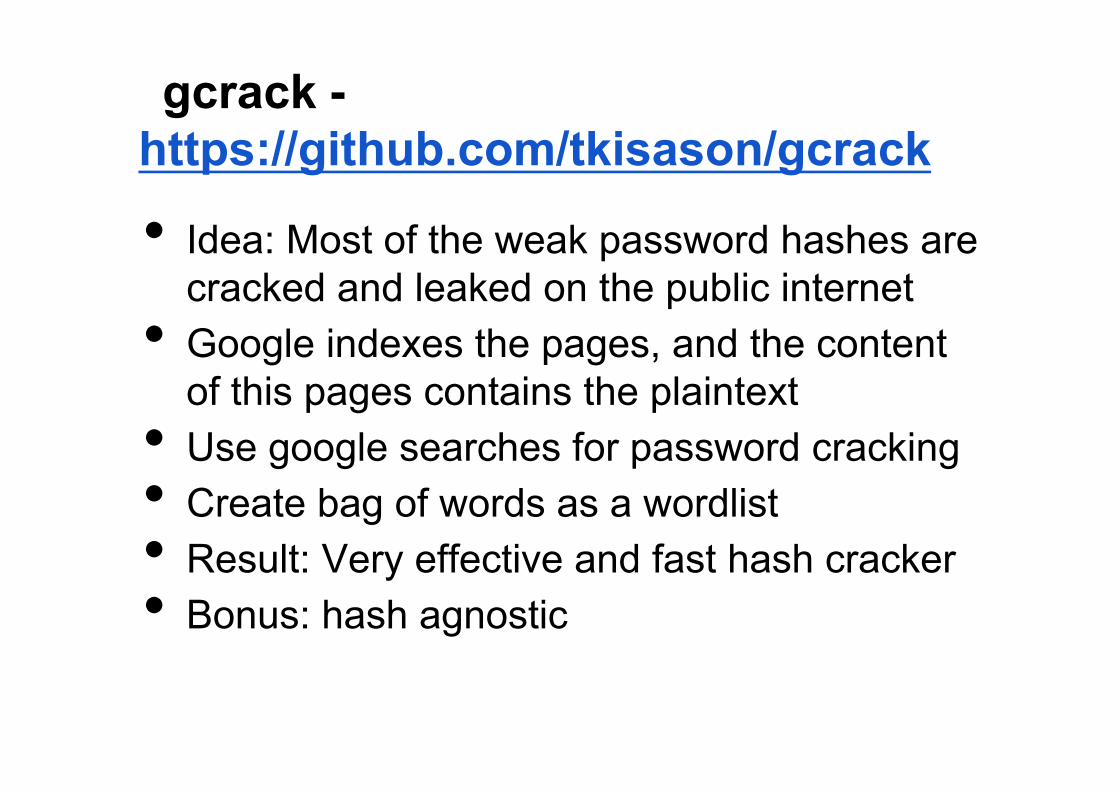
gcrack - https://github.com/tkisason/gcrack
• Idea: Most of the weak password hashes are cracked and leaked on the public internet
• Google indexes the pages, and the content of this pages contains the plaintext
• Use google searches for password cracking • Create bag of words as a wordlist • Result: Very effective and fast hash cracker • Bonus: hash agnostic

logtool https://github.com/tkisason/logtool
• log files are interesting..ish • Especially if you have a compromised
machine and the attackers were noobish enough to leave the log files
• What can you learn: o IP addresses (known proxyes and tor exit points) o Usernames (are they generic or are they specific) o IP-GeoIP data o Toolmarks (user agents, wordlists for attacks)

linkcrawl and nltk https://github.com/tkisason/linkcrawl
• Building a simple crawler is easy (or use wget and cURL, man up and write some shell scripts)
• NLTK is awesome! o import nltk, nltk.clean_html(data)
• http://orange.biolab.si is also a nice platform

conclusion
• Well, have just have fun • Problems are all around you, try to solve
some J

questions?

Thank you!