outline p1eda’s simple features currently implemented –and their ablation test features we have...
TRANSCRIPT

Outline• P1EDA’s simple features currently implemented
– And their ablation test • Features we have reviewed from Literature
– (Let’s briefly visit them) – Iftene’s. – MacCarteny et al. (Stanford system) – BIUTEE gap mode features.
• Discussion: what we want to (re-)implement, and bring back into EOP. – As aligners, – or as features.

Current features for mk.1
• Basic Idea: Simple features first. • Word coverage ratio
– How much of the H components (here, Tokens) are covered by those of T components?
– “base alignment score” • Content word coverage ratio
– Content words are more important than, non-content words (prepositions, articles, etc)
– “Penalize if missed content words”

Current features for mk.1 • Proper Noun coverage ratio
– Proper nouns (or name entities) are quite specific. Missing (no alignment) PNs should be penalized severely.
– Iftene’s rules on NERs. Named entity drops are always non entailment. The only exception is dropping of first name.
• Verb coverage ratio – Two most effective features of an alignment-based
system (Stanford) was – Is the main predicate of Hypothesis covered? – Are the arguments of that predicate covered?

Current results (with optimal settings on mk1 features and aligners )
• English: 67.0 % (accuracy) – Aligners: identical.lemma, wordNet, VerbOcean,
Meteor paraphrase– Features: word, content word, PN coverage.
• Italian: 65.875 % (accuracy) – Aligners: identical.lemma, Italian WordNet – Features: word, content word, verb coverage
• German: 64.5 % (accuracy)– Aligners: identical.lemma, GermaNet – Features: word, content word, PN coverage.
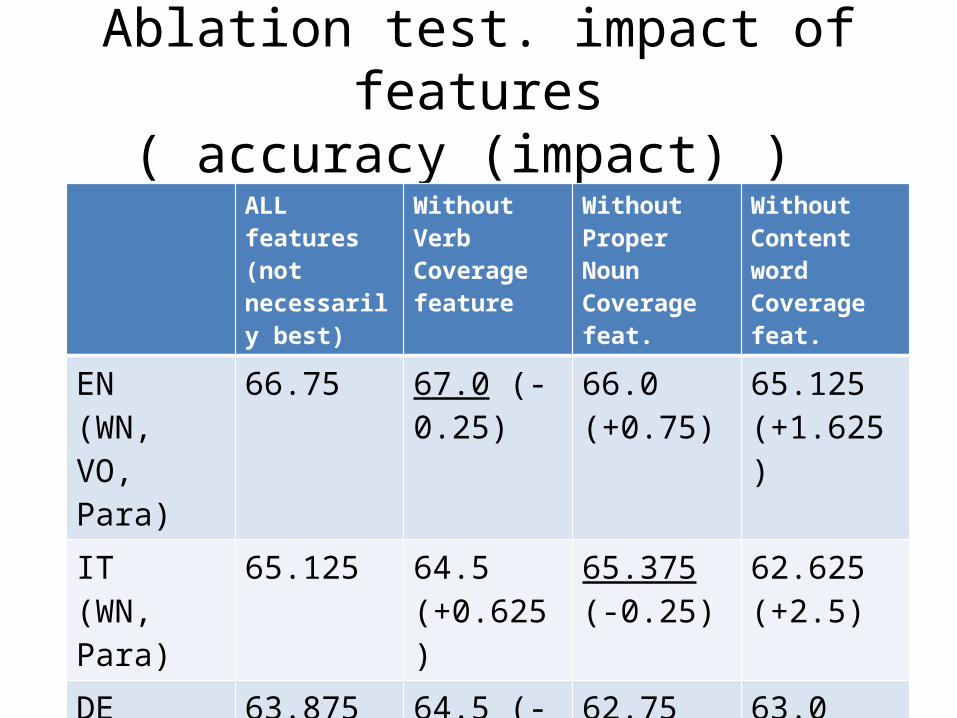
Ablation test. impact of features( accuracy (impact) )
ALL features(not necessarily best)
Without Verb Coverage feature
Without Proper NounCoverage feat.
WithoutContent word Coverage feat.
EN(WN, VO, Para)
66.75 67.0 (-0.25)
66.0 (+0.75)
65.125 (+1.625)
IT(WN, Para)
65.125 64.5 (+0.625)
65.375 (-0.25)
62.625 (+2.5)
DE(GN)
63.875 64.5 (-0.625)
62.75 (+1.125)
63.0 (+1.875)

Ablation test, impact of aligners(with best features of previous slide)
• EN (67.0 with all of the following + base) – without WordNet: 65.125 (+1.875)– without VerbOcean: 66.75 (+0.25) – without Paraphrase (meteror): 64.875 (+2.125)
• IT (65.375 with the following + base)– without WordNet(IT): 65.25 (+0.125) – without Paraphrase (Vivi’s): 65.875 (-0.5)
• DE (62.25 with the following + base) – without GermaNet: 62.125 (+0.125)– without Paraphrase (meteor): 64.5 (-2.25)

FEATURES IN LITERATURE (PREVIOUS RTE SYSTEMS)

Iftene’s RTE system
• Approach: alignment score and threshold– Alignment has two parts: Positive contribution
parts, Negative contribution parts – Use a (manually designed) score function to
combine various scores into one final, global alignment score.
– Learns a threshold to determine “entailment” (better then threshold) and “non-entailment” (all else)

Iftene’s RTE system
• Base unit of alignment: node-edge of tree – (Hypothesis) node – edge – node. – Text nodes dependency node-edge-nodes are
compared with extended match. (partial match)– Alignment score forms the base-line for score.
• WordNet, and other resources are used on those matches
• Additional scores are designed to reflect various good / bad match

Iftene’s RTE system, features
• Numerical compatibility rule (positive rule)– Numbers and quantities are normally not mapped
by lexical resource + local alignment • “at least 80 percent” -> “more than 70 percent” • “killed 109 people on board and four workers” -> “killed
113 people” – Special calculator was used to calculate the
compatibility of the numeric expressions – Reported some impact (1% +) on accuracy. – Our choice: possible aligner candidate?

Iftene’s RTE system, features• Negation rules
– Truth of the verbs are are denoted on all verbs. – Traversing dependency tree and check existence of
“not”, “never”, “may”, “might”, “cannot”, “could”, etc. • Particle rules
– Particle “to” gets special checking: strongly influenced by active verb, adverb, or noun before particle to
– Search for positive (believe, glad, claim) and negative (failed, attempted) ques.
• “Non matching parts” → add negative score

Iftene’s RTE system, features
• Named Entity Rule– If an NE on Hypothesis not mapped – Outright rejection as non entailment
• Exception: if it is a human name, dropping (no alignment) of First name is Okay.
– Our choice? NER aligner would be nice. • (poor man’s ner coverage checking == current Proper
Noun coverage feature)

Stanford TE system
• Stanford TE system (MacCarteny et al) – 1) do monolingual alignment
• Trained on gold (manually prepared) alignment – 2) get alignment score
• no negative elements in this alignment step. – 3) apply feature extraction
• Design features that would reflect various linguistic phenomena

Stanford TE system, Polarity features
• Polarity features– Polarity of T-H is checked by existence of negative
linguistic markers. • Negation (not), downward-monotone marker (no, few),
restricting prepositions (without, except) – Features on polarity: polarity of T, polarity of H, does
two polarity T-H same? • Our choice?
– TruthTeller would be better.– But on the other hand, “word” based simple
approaches might be useful for other languages.

Stanford TE system, Modality / Factivity features
• Modality preservation feature – Record modal changes from T to H, and generates
a nominal feature. • “could be XX” (T) -> “XX” (H) → “WEAK_NO” • “cannot YY” (T) -> “not YY” (H) → “WEAK YES”
• Factivity preservation feature – Focus on verbs that affects “Truth” or “Factivity”
• “tried to escape” (T) -> “escape” (H) (Feature: false) • “managed to escape” (T) -> “escape” (H) (Feature: true)

Stanford TE system, Adjunction feature
• If T-H are both in positive context– “A dog barked” -> “A dog barked loudly” (not safe adding)– “A dog barked carefully” -> “A dog barked” (safe dropping)
• If T-H are both in negative context – “The dog did not bark” -> “The dog did not bark loudly”
(safe adding) – “The dog did not bark loudly” -> “The dog did not bark”
(not safe dropping) • Features: “not safe adjunct drop detected”, “not safe
adjunct addition detected”, …

Stanford TE systemSome other features …
• Antonym feature– Antonyms found in aligned region (with WordNet).
• Date/Numbers feature – Binary features that indicates “dates described in T
– H aligned region are not matched”. • Quantifier feature
– Quantifies modifying two aligned parts are “not matched”.

BIUTEE gap mode
• Main approach of Gap mode – Transform Text as close to Hypothesis with reliable
rules → T’ – Evaluate T’ – H pair, by extracting features to
evaluate the pair. • Two set of features
– Lexical Gap features – Predicate Argument Gap features

BIUTEE gap mode, lexical gap feature
• Two numerical feature values – Score for non-predicate words – Score for predicate words – Not all words are equal: missing rare terms are
more heavily penalized (weight: log prob)• Sum of all missing terms’ weight, forms one
feature value.

BIUTEE gap mode, predicate-argument gap feature
• Requires predicate-argument structure– How well the structures are covered from that of
Text? • Degree of matching from Full match to Partial
match – Full match: same head words, same governing
predicate, set of content words. – Category I, II, III partial matches are defined.
• 5 numeric features represents degree of match– No. of matched NE arguments, no. of matched non-NE
arguments, no. of argument in Cat I, II, III.

Priorities?
• Features that we might hope to try soon … – Main verb of H matched? Its arguments matched? – Weighted coverage (such as IDF), on word
coverage– Date matcher (an aligner) – Features that use TruthTeller alignments (number
of matching/non-matching predicate truth)– Polarity/Modality/Factivity features (cheaper than
TruthTeller … )