overview of the intel sandy bridge micro- architecture · intel sandy bridge memory subsystem 6...
TRANSCRIPT

OVERVIEW OF THE INTEL
SANDY BRIDGE MICRO-
ARCHITECTURESlides by: Pedro Tomás
ADVANCED COMPUTER ARCHITECTURES
ARQUITECTURAS AVANÇADAS DE COMPUTADORES (AAC)

Advanced Computer Architectures, 2014
Outline
2
Intel Sandy Bridge
Memory Hierarchy System
Data Prefetching
Performance issues
Advanced Computer Architectures, 2014
Intel Sandy Bridge
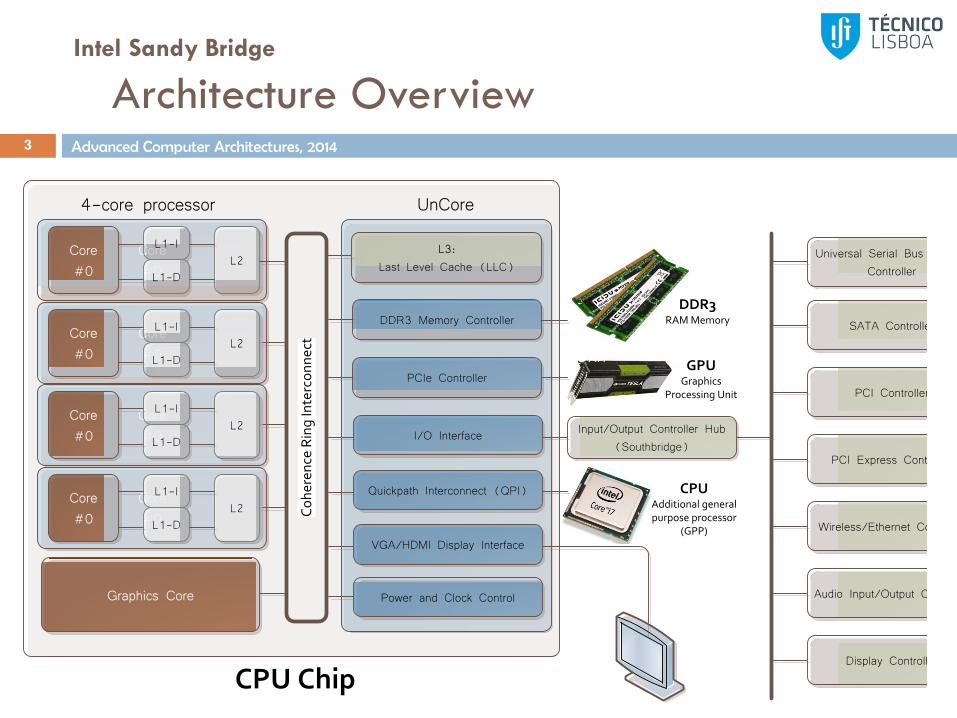
Architecture Overview3
Core#0
Core#0
L1-I
L1-DL2
L3:Last Level Cache (LLC)
PCIe Controller
Input/Output Controller Hub(Southbridge)
Graphics Core
Co
her
ence
Rin
g In
terc
on
nec
tCore#0
Core#0
L1-I
L1-DL2
Core#0
Core#0
L1-I
L1-DL2
Core#0
Core#0
L1-I
L1-DL2
4-core processor
Power and Clock Control
UnCore
Universal Serial Bus (USB) Controller
SATA Controller
PCI Controller
Audio Input/Output Controller
PCI Express Controller
Display Controller
Wireless/Ethernet Controller
Solid State Drive (SSD)or
Hard Disk Drive (HDD)
Additional GPUor
FPGA
GPUGraphics
Processing Unit
DDR3RAM Memory
CPUAdditional general purpose processor
(GPP)
CPU Chip
VGA/HDMI Display Interface
Quickpath Interconnect (QPI)
I/O Interface
DDR3 Memory Controller

Advanced Computer Architectures, 2014
Intel x86 and x86_64 processors
IA32 Virtual Memory System4
Physical Address Space
36 address bits
Allows addressing up to 64GB of memory
Virtual Address Space
32 address bits
Allows up to 4GB of virtual memory (OS can restrict the total amount to a smaller value)
4KB / 4MB virtual and physical pages
Page tables (and directory) with 1024 entries, each occupying 4B
Page sizeVirtual Address (32 bits)
32 22 21 12 11 0
4KB Directory Page Table Page offset 2 levels
4MB Directory Page offset 1 level

Advanced Computer Architectures, 2014
Intel x86_64 processors
IA32e Virtual Memory System5
Physical Address Space
52 address bits
Allows addressing up to 4PB of memory
Virtual Address Space
48 address bits
Allows up to 256TB of virtual memory (OS can restrict the total amount to a smaller value)
4KB / 4MB / 1GB virtual and physical pages
Page tables (and directory) with 512 entries, each occupying 8B
Page sizeVirtual Address (64 bits) (16 most significant bits are unused)
63 48 47 39 38 30 29 21 20 12 11 0
4KB - Directory PT (Level 3) PT (Level 2) PT (Level 1) Page offset 4 levels
2MB - Directory PT (Level 3) PT (Level 2) Page offset 3 levels
1GB - Directory PT (Level 3) Page offset 2 levels
Note: page size on on higher level tables is always 4KB

Advanced Computer Architectures, 2014
Intel Sandy Bridge
Memory subsystem6
Translation look-aside buffer
Requires supporting multiple page sizes
Instruction TLB is simpler, since instruction pages are always of 4KB
Data TLB requires supporting multiple page sizes
Access to data is a bottleneck in many applications
Complex TLBs delay access to data
Many processors use a fully associative TLB
E.g., MIPS, Alpha, ARM Cortex A8, Intel Itanium 2
Intel Ivy Bridge uses an 4-way associative TLB
L1 Instruction TLB uses 64 entries (4KB only pages)
L1 Data TLB uses
64 entries for 4KB pages
32 entries for 2MB pages
32 entries for 1GB pages

Advanced Computer Architectures, 2014
Memória Cache
TAG V
Get the data and return the value to the processor
=
DATA
TAG V DATA
Retrieve one entry per way
Retrieve the page physical address
Check TAG in all for ways for
Also get the value of the remaining index bits
Generate a cache miss if the data is not on cache
PAGE VIRTUAL ADDRESS PAGE OFFSET
INDEX OFFSET
VIRTUAL ADDRESSOFFSET
Select only the bytes corresponding to the
line offset
Use only the index bits
falling within the page
offset
Select 2K words, where K is the number of index bits overlapping the page virtual address
Extract TAGfor comparison
Extract remaining index bits
TLB structure
TAG PTECONTROL
Check all TLB entries and verify if any of the entries is a match
Page Virtual Address V Page physical addressPID
Intel Nehalem memory subsystem
L1 Instruction cache (3 cycles)7
512
lines
4 ways
6 bits
9 bits
8KB/way
32KB in total
Retrieves 4+4 entries
On miss check
Unified L2 cache
4 ways
32 entries for 4KB pages
64B
Fetches 16B
each time

Advanced Computer Architectures, 2014
Memória Cache
TAG V
Get the data and return the value to the processor
=
DATA
TAG V DATA
Retrieve one entry per way
Retrieve the page physical address
Check TAG in all for ways for
Also get the value of the remaining index bits
Generate a cache miss if the data is not on cache
PAGE VIRTUAL ADDRESS PAGE OFFSET
INDEX OFFSET
VIRTUAL ADDRESSOFFSET
Select only the bytes corresponding to the
line offset
Use only the index bits
falling within the page
offset
Extract TAGfor comparison
Extract remaining index bits
TLB structure
TAG PTECONTROL
Check all TLB entries and verify if any of the entries is a match
Page Virtual Address V Page physical addressPID
Intel Sandy Bridge memory subsystem
L1 Instruction cache (3 cycles)8
64B
512 lines
8 ways
6 bits
9 bits
4KB/way
32KB in total
Retrieves 8 entries
On miss check
Unified L2 cache
4 ways
32 entries for 4KB pages
On miss check the Unified
L2 TLB, with 512 entries
Fetches 16B
each time

Advanced Computer Architectures, 2014
Memória Cache
TAG V
Get the data and return the value to the processor
=
DATA
TAG V DATA
Retrieve one entry per way
Retrieve the page physical address
Check TAG in all for ways for
Also get the value of the remaining index bits
Generate a cache miss if the data is not on cache
PAGE VIRTUAL ADDRESS PAGE OFFSET
INDEX OFFSET
VIRTUAL ADDRESSOFFSET
Select only the bytes corresponding to the
line offset
Use only the index bits
falling within the page
offset
Extract TAGfor comparison
Extract remaining index bits
TLB structure
TAG PTECONTROL
Check all TLB entries and verify if any of the entries is a match
Page Virtual Address V Page physical addressPID
Intel Ivy Bridge memory subsystem
L1 Data cache9
64B
512 lines
8 ways
6 bits
9 bits
4KB/way
32KB in total
Retrieves 8 entries
On miss check
Unified L2 cache
4 ways
64 entries for 4KB pages
32 entries for 2MB pages
32 entries for 1GB pages On miss check the Unified
L2 TLB, with 512 entries

Advanced Computer Architectures, 2014
Intel Sandy Bridge
L1 Data cache10
Sandy Bridge includes 2 load ports and 1 store port, allowing to sustain 2x
128-bit loads and 1x 128-bit store each cycle
Integer load to use latency is 4 cycles
FP and SIMD load to use latency is increased by 1-2 cycles
Memory accesses that are split between two cache lines, or between two pages take
longer:
Requires checking two different tags, or making two virtual to physical address translations
Load units support out-of-order access to data
If the first load misses L1, the following can still fetch from L1
A maximum of 10 outstanding misses are allowed
1x outstanding miss 1x miss to a cache line
Uses a write-back write allocate policy
SIMD stream_store instructions allow writing directly to low level caches

Advanced Computer Architectures, 2014
Memória Cache
TAG V DATA
TAG OFFSET
PHYSICAL ADDRESS
INDEX
Intel Ivy Bridge memory subsystem
L2 Unified instruction + data cache11
Lines of 64B
4096
lines
8 ways
6 bits
9 bits
32KB/way
256KB in total
Load to use latency of 12 cycles (10 in
Nehalem)
L1 to L2 bandwidth is 32B/cycle
Fetching a line takes 2 clock cycles
Cache controller allows bypassing the L1
cache, by sending the data to the
processor while it is being written to the L1
cache
L1-L2 relationship is non-inclusive and
non-exclusive
A line on L1 cache may, or may not be on
the L2 cache
L2 allows up to 16 outstanding misses
Write back, write allocate policy

Advanced Computer Architectures, 2014
Memória Cache
TAG V DATA
TAG OFFSET
PHYSICAL ADDRESS
INDEX
Intel Ivy Bridge memory subsystem
L3 shared cache12
Lines of 64B
8192
lines
16 ways
6 bits
9 bits
512KB/way
8MB in total
The L3 Cache is shared between all
cores and the integrated GPU
Load to use latency of 26-31 cycles
(35-40 in Nehalem)
Latency varies because of the time to
transfer the data from the L3, through the
ring, to the core
It is expected that a core closer to the L3
has a smaller latency, whereas a core
farther way has a longer latency
L3 to L1/L2 bandwidth is 32B/cycle
L1 can bypass the L2 cache and load data
directly from the L3
The L3 cache is inclusive
A line on L1 or L2 cache is always on the
L3 cache

Advanced Computer Architectures, 2014
Intel Smart Memory Access
Advanced pre-fetching mechanism13
Advanced pre-fetching mechanisms try to anticipate loads
Pre-fetched data is placed on a buffer
When loading a value, the processor verifies if the data is:
On the Data Cache
On the Write Buffer
On the Pre-fetch Buffer
(the store and pre-fetch buffer may be merged to increase hardware utilization)
Each core contains:
1 L1 Instruction pre-fetcher
2 L1 Data pre-fetchers
Each pair of cores share:
2 L2 pre-fetchers
Advanced Computer Architectures, 2014
Intel Smart Memory Access
Advanced pre-fetching mechanism14
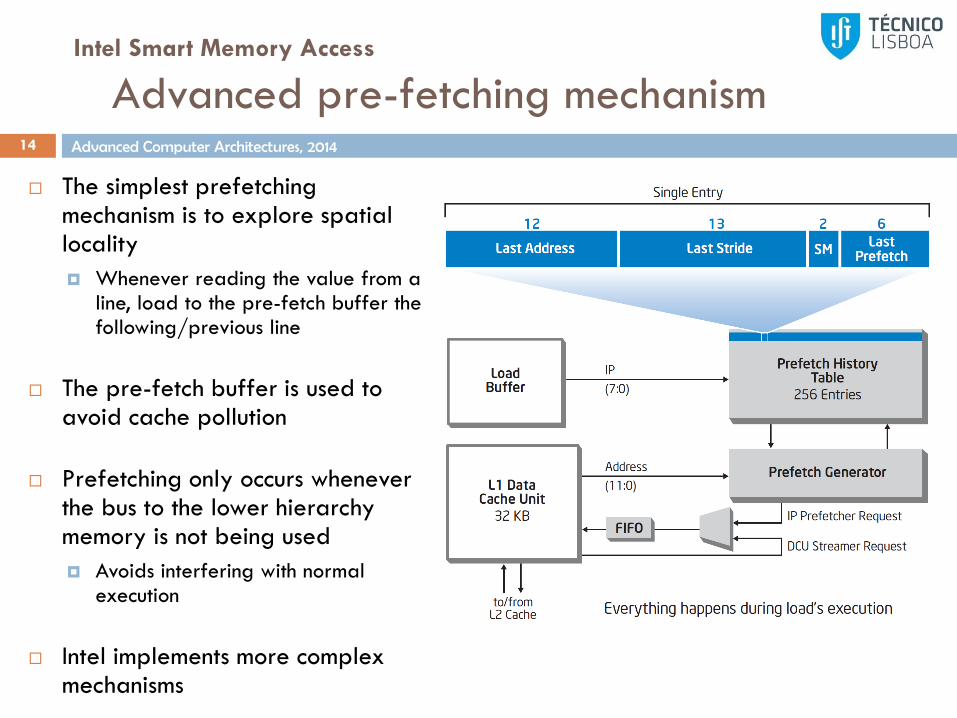
The simplest prefetching mechanism is to explore spatial locality
Whenever reading the value from a line, load to the pre-fetch buffer the following/previous line
The pre-fetch buffer is used to avoid cache pollution
Prefetching only occurs whenever the bus to the lower hierarchy memory is not being used
Avoids interfering with normal execution
Intel implements more complex mechanisms

Advanced Computer Architectures, 2014
Intel Smart Memory Access
Advanced pre-fetching mechanism15
Loads are tracked by the
instruction pointer (IP)
E.g., the program counter
A Prefetch History Table (PHT) is used
to hold load history
The instruction pointer is used to check
the PHT for previous memory accesses
by that instruction
On HIT it verifies the next loads are
already on the cache
If the next loads are not on the cache, try to
load the correct data
Exceptions generated by the pre-fetchers
(e.g., accessing to invalid pages) are
ignored.

Advanced Computer Architectures, 2014
Intel Smart Memory Access
Advanced pre-fetching mechanism16
Hardware pre-fetchers are very
good at guessing requests with a
constant stride
The difference (in address) between
consecutive loads (for the same
instruction) is always constant, e.g.
LD R1,A
LD R1,A+32
LD R1,A+64
LD R1,A+96
…
Complex patterns require
software prefetching
Typically using the prefetch
instruction

Performance issues…
Next on Intel Architectures…17