parafs: a log-structured file system to exploit the ... · usenix association 2016 usenix annual...
TRANSCRIPT

This paper is included in the Proceedings of the 2016 USENIX Annual Technical Conference (USENIC ATC ’16).
June 22–24, 2016 • Denver, CO, USA
978-1-931971-30-0
Open access to the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16) is sponsored by USENIX.
ParaFS: A Log-Structured File System to Exploit the Internal Parallelism of Flash Devices
Jiacheng Zhang, Jiwu Shu, and Youyou Lu, Tsinghua University
https://www.usenix.org/conference/atc16/technical-sessions/presentation/zhang

USENIX Association 2016 USENIX Annual Technical Conference 87
ParaFS: A Log-Structured File Systemto Exploit the Internal Parallelism of Flash Devices
Jiacheng Zhang Jiwu Shu∗ Youyou LuDepartment of Computer Science and Technology, Tsinghua UniversityTsinghua National Laboratory for Information Science and Technology
[email protected] {shujw, luyouyou}@tsinghua.edu.cn
Abstract
File system designs are undergoing rapid evolution toexploit the potentials of flash memory. However, theinternal parallelism, a key feature of flash devices, ishard to be leveraged in the file system level, due tothe semantic gap caused by the flash translation layer(FTL). We observe that even flash-optimized file systemshave serious garbage collection problems, which lead tosignificant performance degradation, for write-intensiveworkloads on multi-channel flash devices.
In this paper, we propose ParaFS to exploit the internalparallelism while ensuring efficient garbage collection.ParaFS is a log-structured file system over a simpli-fied block-level FTL that exposes the physical layout.With the knowledge of device information, ParaFS firstproposes 2-D data allocation, to maintain the hot/colddata grouping in flash memory while exploiting channel-level parallelism. ParaFS then coordinates the garbagecollection in both FS and FTL levels, to make garbagecollection more efficient. In addition, ParaFS sched-ules read/write/erase requests over multiple channelsto achieve consistent performance. Evaluations showthat ParaFS effectively improves system performance forwrite-intensive workloads by 1.6× to 3.1×, compared tothe flash-optimized F2FS file system.
1 Introduction
Flash memory has been widely adopted across embeddedsystems to data centers in the past few years. In thedevice level, flash devices outperform hard disk drives(HDDs) by orders of magnitude in terms of both latencyand bandwidth. In the system level, the latency benefithas been made visible to the software by redesigningthe I/O stack [8, 43, 22, 11]. But unfortunately, thebandwidth benefit, which is mostly contributed by the
∗Corresponding author: Jiwu Shu ([email protected]).
internal parallelism of flash devices [13, 18, 10, 15], isunderutilized in system softwares.
Researchers have made great efforts in designing a filesystem for flash storage. New file system architectureshave been proposed, to either improve data allocationperformance, by removing redundant functions betweenFS and FTL [20, 45], or improve flash memory en-durance, by using an object-based FTL to facilitate hard-ware/software co-designs [33]. Features of flash memoryhave also been leveraged to redesign efficient metadatamechanisms. For instance, the imbalanced read/writefeature has been studied to design a persistence-efficientfile system directory tree [32]. F2FS, a less aggressivedesign than the above-mentioned designs, is a flash-optimized file system and has been merged into the Linuxkernel [28]. However, the internal parallelism has notbeen well studied in these file systems.
Unfortunately, internal parallelism is a key design is-sue to improve file system performance for flash storage.Even though it has been well studied in the FTL level,file systems cannot always gain the benefits. We observethat, even though the flash-optimized F2FS file systemoutperforms the legacy file system Ext4 when writetraffic is light, its performance does not scale well withthe internal parallelism when write traffic is heavy (48%of Ext4 in the worst case, more details in Section 4.3 andFigure 6).
After investigating into file systems, we have the fol-lowing three observations. First, optimizations in bothFS and FTL are made but may collide. For example, datapages1 are grouped into hot/cold groups in some file sys-tems, so as to reduce garbage collection (GC) overhead.FTL stripes data pages over different parallel units (e.g.,channels) to achieve parallel performance, but breaks upthe hot/cold groups. Second, duplicated log-structureddata management in both FS and FTL leads to inefficientgarbage collection. FS-level garbage collection is unable
1In this paper, we use data pages instead of data blocks, in ordernot to be confused with flash blocks.

88 2016 USENIX Annual Technical Conference USENIX Association
to erase physical flash blocks, while FTL-level garbagecollection is unable to select the right victim blocks dueto the lack of semantics. Third, isolated I/O schedulingin either FS or FTL results in unpredictable I/O latencies,which is a new challenge in storage systems on low-latency flash devices.
To exploit the internal parallelism while keeping lowgarbage collection overhead, we propose ParaFS, a log-structured file system over simplified block-level FTL.The simplified FTL exposes the device information tothe file system. With the knowledge of the physicallayout, ParaFS takes the following three approaches toexploit the internal parallelism. First, it fully exploits thechannel-level parallelism of flash memory by page-unitstriping, while ensuring data grouping physically. Sec-ond, it coordinates the garbage collection processes inthe FS and FTL levels, to make GC more efficient. Third,it optimizes the request scheduling on read, write anderase requests, and gains more consistent performance.Our major contributions are summarized as follows:• We observe the internal parallelism of flash devices
is underutilized when write traffic is heavy, and pro-pose ParaFS, a parallelism-aware file system over asimplified FTL.
• We propose parallelism-aware mechanisms in theParaFS file system, to mitigate the parallelism’sconflicts with hot/cold grouping, garbage collec-tion, and I/O performance consistency.
• We implement ParaFS in the Linux kernel. Eval-uations using various workloads show that ParaFShas higher and more consistent performance withsignificant lower garbage collection overhead, com-pared to legacy file systems including the flash-optimized F2FS.
The rest of this paper is organized as follows. Sec-tion 2 analyses the parallelism challenges and mo-tivates the ParaFS design. Section 3 describes theParaFS design, including the 2-D allocation, coordi-nated garbage collection and parallelism-aware schedul-ing mechanisms. Evaluations of ParaFS are shown inSection 4. Related work is given in Section 5 and theconclusion is made in Section 6.
2 Motivation
2.1 Flash File System ArchitecturesFlash devices are seamlessly integrated into legacy stor-age systems by introducing a flash translation layer(FTL). Though NAND flash has low access latencyand high I/O bandwidth, it has several limitations, e.g.,erase-before-write and write endurance (i.e., limited pro-gram/erase cycles). Log-structured design is supposed tobe a friendly way for flash memory. It is adopted in both
the file system level (e.g., F2FS [28], and NILFS [27])and the FTL level [10, 36]. The FTL hides the flashlimitations by updating data in a log-structured wayusing an address mapping table. It exports the same I/Ointerface as HDDs. With the use of the FTL, legacy filesystems can directly run on these flash devices, withoutany changes. This architecture is shown in Figure 1(a).
FTL
READ / WRITE / TRIM
Log-structured File System
Namespace
Alloc. GC
Alloc.
Mapping
GC WL ECC
Channel N
Flash
…Channel 0
Flash
Channel 1
Flash
Flash Memory
(a) Block Interface
Object-based FTL
GET / PUT
Object-based File System
Namespace
Alloc.
Mapping
GC WL ECC
Channel N
Flash
…Channel 0
Flash
Channel 1
Flash
Flash Memory
(b) Object Interface
Figure 1: FS Architectures on Flash Storage
While FTL is good at abstracting the flash memoryas a block device, it widens the semantic gap betweenfile systems and flash memory. As shown in Figure 1(a),the FS and FTL run independently without knowingeach other’s behaviours, resulting in inefficient storagemanagement. Even worse, the two levels have redundantfunctions, e.g., space allocation, address mapping, andgarbage collection, which further induce performanceand endurance overhead.
Object-based FTL (OFTL) [33] is a recently proposedarchitecture to bridge the semantic gap between filesystems and FTLs, as shown in Figure 1(b). However,it requires dramatic changes of current I/O stack, andis difficult to be adopted currently, either in the devicedue to complexity or in the operating system due to richinterfaces required in the drivers.
2.2 Challenges of Internal ParallelismIn a flash device, a number of flash chips are connectedto the NAND flash controller through multiple chan-nels. I/O requests are distributed to different channelsto achieve high parallel performance, and this is knownas the internal parallelism. Unfortunately, this featurehas not been well leveraged in the file systems for thefollowing three challenges.
Hot/Cold Grouping vs. Internal Parallelism. Withthe use of the FTL, file systems allocate data pages in aone-dimension linear space. The linear space works finefor HDDs, because a hard disk accesses sectors seriallydue to the mechanical structure, but not for flash devices.
2

USENIX Association 2016 USENIX Annual Technical Conference 89
In flash-based storage systems, a fine hot/cold groupingreduces the number of valid pages in victim flash blocksduring garbage collection. Some file systems separatedata into groups with different hotness for GC efficiency.Meanwhile, the FTL trys to allocate flash pages fromdifferent parallel units, aiming at high bandwidth. Datapages that belong to the same group in the file systemmay be written to different parallel units. Parallel spaceallocation in FTL breaks hot/cold data groups. As such,the hot/cold data grouping in the file system collides withthe internal parallelism in the FTL.
Garbage Collection vs. Internal Parallelism. Log-structured file systems are considered to be flash friendly.However, we observe that F2FS, a flash-optimized log-structured file system, performs worse than Ext4 onmulti-channel flash devices when write traffic is heavy.To further analyse this inefficiency, we implement apage-level FTL and collect the GC statistics in the FTL,including the number of erased flash blocks and thepercentage of invalid pages in each erased block (i.e.,GC efficiency). Details of the page-level FTL and eval-uation settings are introduced in Section 4. As shown inFigure 2, for the random update workload in YCSB[14],F2FS has increasing number of erased flash blocks anddecreasing GC efficiency when the number of channelsincreases.
The reason lies in the incoordinate garbage collectionsin FS and FTL. When the log-structured file systemcleans a segment in the FS level, the invalid flash pagesare actually scattered over multiple flash parallel units.The more channels the device has, the more diverse theinvalid pages are. This degrades the GC efficiency in theFTL. At the same time, the FTL gets pages’ invalidationonly after receiving the trim commands from the log-structured file system, due to the no in-place update.As we observed in the experiments, a large number ofpages which are already invalidated in the file system aremigrated to the clean flash blocks during the FTL’s eraseprocess. Therefore, garbage collections in FS and FTLlevels collide and damage performance.
(a) # of Recycled Blocks (b) GC Efficiency
Figure 2: GC Statistics under Heavy Traffic
Consistent Performance vs. Internal Parallelism.Read or write requests may be blocked by erase opera-tions in the FTL. Since erase latency is much higher thanread/write latency, this causes latency spikes, making I/O
latency unpredictable. It is known as the inconsistentperformance, which is a serious issue for low-latencystorage devices. Parallel units offer an opportunity toremove latency spikes by carefully scheduling I/O re-quests. Once a file system controls read, write and eraseoperations, it can dynamically schedule requests to makeperformance more consistent.
To address the above-mentioned challenges, we pro-pose a new architecture (as shown in Figure 3) to ex-ploit the internal parallelism in the file system. In thisarchitecture, we use a simplified FTL to expose thephysical layout to the file system. Our designed ParaFSmaximizes the parallel performance in the file systemlevel while achieving physical hot/cold data grouping,lower garbage collection overhead and more consistentperformance.
3 Design
ParaFS is designed to exploit the internal parallelismwithout compromising other mechanisms. To achievethis goal, ParaFS uses three key techniques:
• 2-Dimension Data Allocation to stripe data pagesover multiple flash channels at page granularitywhile maintaining hot/cold data separation physi-cally.
• Coordinated Garbage Collection to coordinategarbage collections in FS and FTL levels and lowerthe garbage collection overhead.
• Parallelism-Aware Scheduling to schedule theread/write/erase requests to multiple flash channelsfor more consistent system performance.
In this section, we introduce the ParaFS architecture first,followed by the description of the above-mentioned threetechniques.
3.1 The ParaFS ArchitectureParaFS reorganizes the functionalities between the filesystem and the FTL, as shown in Figure 3. In the ParaFSarchitecture, ParaFS relies on a simplified FTL (anno-tated as S-FTL). S-FTL is different from traditional FTLsin three aspects. First, S-FTL uses a static block-levelmapping table. Second, it performs garbage collectionby simply erasing the victim flash blocks without movingany pages, while the valid pages in the victim blocksare migrated by ParaFS in the FS level. Third, S-FTLexposes the physical layout to the file system using threevalues, i.e., the number of flash channels2, the flash pagesize and the flash block size. These three values arepassed to the ParaFS file system through ioctl interface,
2Currently, ParaFS exploits only the channel-level parallelism,while finer level (e.g., die-level, plane-level) parallelism can be ex-ploited in the FTL by emulating large pages or blocks.
3

90 2016 USENIX Annual Technical Conference USENIX Association
READ / WRITE / ERASE
ParaFS
Namespace
S-FTL
Block Mapping WL ECC
Channel N
Flash
Channel 0
Flash
Channel 1
Flash
Flash Memory
2-D Allocation
Region 0 Region N
…
Parallelism-Aware Scheduler
ReadWriteEraseRead
Req. Que. 0
…
…
Coordinated GC
Thread 0 Thread N
Req. Que. 1
ReadWriteEraseRead
Req. Que. N
ReadWriteEraseRead
…
…
…
Figure 3: The ParaFS Architecture
when the device is formatted. With the physical layoutinformation, ParaFS manages data allocation, garbagecollection, and read/write/erase scheduling in the filesystem level. The ParaFS file system uses an I/O inter-face that consists of read/write/erase commands, whichremains the same as the legacy block I/O interface. InParaFS, the erase command reuses the trim command inthe legacy protocol.
In S-FTL, the block mapping is different from thosein legacy block-based FTLs. S-FTL uses static block-level mapping. For normal writes, the ParaFS file systemupdates data pages in a log-structured way. There is noin-place update in the FS level. For these writes, S-FTL doesn’t need to remap the block. S-FTL updatesits mapping entries only for wear leveling or bad blockremapping. In addition, ParaFS tracks the valid/invalidstatuses of pages in each segment, whose address isaligned to the flash block in flash memory. The file sys-tem migrates valid pages in the victim segments duringgarbage collection, and the S-FTL only needs to erasethe corresponding flash blocks afterwards. As such, thesimplified block mapping, simplified garbage collectionand reduced functionalities make S-FTL a lightweightimplementation, which has nearly zero overhead.
The ParaFS file system is a log-structured file system.To avoid the “wandering tree” problem [38], file systemmetadata is updated in place, by introducing a smallpage-level FTL. Since we focus on the data management,we omit discussions of this page-level FTL for the restof the paper. In contrast, file system data is updated
in a log-structured way and sent to the S-FTL. TheParaFS file system is able to perform more effectivedata management with the knowledge of the internalphysical layout of flash devices. Since the file systemis aware of the channel layout, it allocates space indifferent channels to exploit the internal parallelism andmeanwhile keeps the hot/cold data separation physically(details in Section 3.2). ParaFS aligns the segment oflog-structured file system to the flash block of the device.Since it knows exactly the valid/invalid statuses of datapages, it performs garbage collection in the file systemwith the coordination of the FTL erase operations (detailsin Section 3.3). With the channel information, ParaFS isalso able to optimize the scheduling on read/write/eraserequests in the file system and make system performancemore consistent (details in Section 3.4).
3.2 2-D Data Allocation
The first challenge as described in Section 2.2 is the con-flict between data grouping in the file system and internalparallelism in the flash device. Intuitively, the easiestway for file system data groups to be aligned to flashblocks, is using block granularity striping in the FTL.The block striping maintains data grouping while paral-lelizing data groups to different channels in block units.However, the block-unit striping fails to fully exploitthe internal parallelism, since the data within one groupneeds to be accessed sequentially in the same flash block.We observe in our systems that block-unit striping hassignificantly lower performance than page-unit striping(i.e., striping in page granularity), especially in the smallsynchronous write situations, like mail server. Some co-designs employ a super block unit which contains flashblocks from different flash channels [42, 12, 29]. Thewrites can be striped in a page granularity within thesuper block and different data groups are maintained indifferent super blocks. However, the large recycle size ofthe super block incurs higher overhead in the garbagecollection. Therefore, we propose 2-D allocation inParaFS that uses small allocation units to fully exploitchannel-level parallelism while keeping effective datagrouping. Tabel 1 summaries the characteristics of thesedata allocation schemes and compares them with 2-Dallocation used in ParaFS.
Figure 4 shows the 2-D allocation in ParaFS. With thedevice information from S-FTL, ParaFS is able to allo-cate and recycle space that aligned to the flash memorybelow. The data space is divided into multiple regions. Aregion is an abstraction of a flash channel in the device.The number and the size of regions equal to those offlash channels. Each region contains multiple segmentsand each segments contains multiple data pages. Thesegment is the unit of allocation and garbage collection
4

USENIX Association 2016 USENIX Annual Technical Conference 91
Table 1: Data Allocation SchemesParallelism Garbage Collecion
Stripe Granularity Parallelism Level GC Granulariy Grouping Effect GC OverheadPage Stripe Page High Block No HighBlock Stripe Block Low Block Yes LowSuper Block Page High Multiple Blocks Yes Medium
2-D Allocation Page High Block Yes Low
Alloc.
Space
Free
Space
Alloc. Head 0
Alloc. Head 1
…
Alloc. Head m
…
Region 0
…Free Seg. List
Log-structured Segment Written Data Page
…
Region 1
…
…
Region N
…
…
Figure 4: 2-D Allocation in ParaFS
in ParaFS. Its size and address are aligned to the physicalflash block. The data page in the segments representsthe I/O unit to the flash and is aligned to the flash page.There are multiple allocator heads and a free segmentlist in each region. The allocator heads point to datagroups with different hotness within the region. Theyare assigned a number of free segments and they allocatefree pages to the written data with different hotness, in alog-structured way. The free segments of the region aremaintained in the free segment list.
The 2-D allocation consists of channel-level dimen-sion and hotness-level dimension. ParaFS delays spaceallocation until data persistence. Updated data pagesare first buffered in memory. When a write request isgoing to be dispatched to the device, ParaFS starts the2-D scheme to allocate free space for the request.
First, in the channel-level dimension, ParaFS dividesthe write request into pages, and then stripes these pagesover different regions. Since the regions match the flashchannels one-to-one, the data in the write request is sentto different flash channels in a page-size granularity, soas to exploit the channel-level parallelism in the FS level.After dividing and striping the data of the write requestover regions, the allocation process goes to the seconddimension.
Second, in the hotness-level dimension, ParaFSgroups data pages into groups with different hotness ina region, and sends the divided write requests to theirproper groups. There are multiple allocator heads withdifferent hotness in the region. The allocator head,which has similar hotness to the written data, is selected.Finally, the selected allocator head allocates a free pageto the written data. The data is sent to the device withthe address of the allocated page. Since the segments
of allocator heads are aligned to the flash blocks, thedata pages with different hotness are assigned to differentallocator heads, thereby placed in separated flash blocks.The hotness-level dimension ensures the effective datagrouping physically.
In implementation, ParaFS uses six allocators in eachregion. The data is divided into six kinds of hotness,i.e., hot, warm, and cold, respectively for metadata andregular data. The hotness classification uses the samehints as in F2FS [28]. Each allocator is assigned tensegments each time. The address of the segments andthe offset of the allocator heads are recorded in the FScheckpoint in case of system crash.
Crash Recovery. After the crash, legacy log-structured file systems will recover itself to the lastcheckpoint, which maintains the latest consistent stateof the file system. Some file systems[33][28] will dothe roll-forward recovery to restore changes after lastcheckpoint. ParaFS differs slightly during the recovery.Since ParaFS directly accesses and erases flash memorythrough statically mapped S-FTL, it has to detect thewritten pages after last checkpoint. These written pagesneed to be detected so that the file system does notoverwrite these pages, which otherwise causes overwriteerrors in flash memory.
To solve this problem, ParaFS employs an updatewindow similar to that in OFSS [33]. An update windowconsists of segments from each region that are assignedto allocator heads after last checkpoint. Before a set ofsegments are assigned to allocator heads, their addressesare recorded first. During recovery, ParaFS first recoversitself to the last checkpoint. Then, ParaFS does theroll-forward recovery with the segments in the updatewindow in each region, since all written pages after lastcheckpoint fall in this window. After recovering the validpages in the window, other pages will be considered asinvalid, and they will be erased by the GC threads in thefuture.
3.3 Coordinated Garbage CollectionThe second challenge as described in Section 2.2 isthe mismatch of the garbage collection processes in FSand FTL levels. Efforts in either side are ineffectivein reclaiming free space. ParaFS coordinates garbagecollection in the two levels and employs multiple GCthreads to leverage the internal parallelism. This tech-
5

92 2016 USENIX Annual Technical Conference USENIX Association
nique improves both the GC efficiency (i.e., the percentof invalid pages in victim blocks) and the space reclaimefficiency (i.e., time used for GC).
The coordinated garbage collection contains the GCprocess from FS level and FTL level. We use theterms “paraGC” and “flashGC” to distinguish them. Inthe FS level, the paraGC is triggered when free spacedrops below a threshold (i.e., foreground paraGC) or filesystem is idle (i.e., background paraGC). The unit ofgarbage collection is the segment, as we described inSection 3.2. The foreground paraGC employs greedyalgorithm to recycle the segments quickly and minimizethe latency of I/O threads. The background paraGC usescost-benefit algorithm [38] that selects victim segmentsnot only based on the number of invalid data pages, butalso their “age”. When the paraGC thread is triggered, itfirst selects victim segments using the algorithms above.Then, the paraGC thread migrates the valid pages inthe victim segments to the free space. If the migrationis conducted by foreground paraGC, these valid pagesare striped to the allocator heads with similar hotnessin different regions. If the migration is conducted bybackground paraGC, these valid pages are consideredto be cold, and striped to the allocator heads with lowhotness. After the valid pages are written to the device,the victim segments are marked erasable and they will beerased after checkpoint. The background paraGC exitsafter the migration while the foreground paraGC doesthe checkpoint and sends the erase requests to S-FTL bytrim.
In the FTL level, the block recycling is simplified,since the space management and garbage collection aremoved from FTL level to FS level. The segments inthe FS level match the flash blocks one to one. AfterparaGC migrates valid pages in the victim segments,the corresponding flash blocks can be erased withoutadditional copies. When S-FTL receives trim commandsfrom the ParaFS, flashGC locates the flash blocks thatvictim segments mapped to, and directly erases them.After the flash blocks are erased, S-FTL informs theParaFS by the callback function of the requests. Thecoordinated GC migrates the valid pages in FS level,and invalidates the whole flash block to the S-FTL. Nomigration overhead is involved during the erase processin the S-FTL.
Coordinated GC also reduces the over-provisioningspace of the device and brings more user available capac-ity. Traditional FTLs need to move the valid pages fromthe victim blocks before erasing. They keeps large over-provisioning space to reduce the overhead of garbagecollection. The spared space in FTL decreases theuser visible capacity. Since the valid pages are alreadymoved by ParaFS, the flashGC in S-FTL can directlyerase the victim blocks without any migration. S-FTL
needn’t spare space for garbage collection. The over-provisioning space of S-FTL is much smaller than thetraditional ones. The spared blocks are only used for badblock remapping and block mapping table storage. S-FTL also needn’t track and maintain the flash page statusand flash block utilization, which also reduces the size ofspared space.
ParaFS optimizes the foreground GC by employingmultiple GC threads. Legacy log-structured file systemsperform foreground GC in one thread [28], or none [27].Since all operations are blocked during checkpointing.Multiple threads cause frequent checkpoint and decreasethe performance severely. However, one or less fore-ground GC thread is not enough under write intensiveworkloads which consume the free segments quickly.ParaFS assigns one GC thread to each region and em-ploys an additional manager thread. The manager checksthe utilization of each region, and wakes up the GCthread of the region when it’s necessary. After GCthreads migrate the valid data pages, the manager willdo the checkpoint, and send the erase requests asyn-chronously. This optimization avoids multiple check-points, and accelerates the segment recycling underheavy writes.
3.4 Parallelism-Aware Scheduling
The third challenge as described in Section 2.2 is theperformance spikes. To address this challenge, ParaFSproposes to schedule the read/write/erase requests in thefile system level while exploiting the internal parallelism.In ParaFS, the 2-D allocation selects the target flashchannels for the write requests, and the coordinated GCmanages garbage collection in the FS level. These twotechniques offer an opportunity for ParaFS to optimizethe scheduling on read, write and erase requests. ParaFSemploys parallelism-aware scheduling to provide moreconsistent performance under heavy write traffic.
Parallelism-aware scheduling consists of request dis-patching phase and request scheduling phase. In thedispatching phase, it optimizes the write requests. Thescheduler maintains a request queue for each flash chan-nel of the device, shown in Figure 3. The target flashchannels of read and erase requests are fixed, whilethe target channel of writes can be adjusted due to thelate allocation. In the channel-level dimension of 2-D allocation, ParaFS splits the write requests into datapages, and selects a target region for each page. Theregion of ParaFS and the flash channel below are one-to-one correspondence. Instead of a Round-Robin se-lection, ParaFS selects the region to write, whose corre-sponding flash channel is the least busy in the scheduler.Due to the asymmetric read and write performance ofthe flash drive, the scheduler assigns different weights
6

USENIX Association 2016 USENIX Annual Technical Conference 93
(Wread , Wwrite) to read and write requests in the requestqueues. The weights are obtained by measuring thecorresponding latency of the read and write requests.Since the write latency is 8× of the read latency inour device, the Wread and Wwrite are set to 1 and 8 inthe evaluation. The channel with the smallest weightcalculated by the Formula 1 will be selected. Sizereadand Sizewrite represent the size of read and write requestsin the request queue. The erase requests in the requestqueue are not considered in the formula, because thetime, when they are sent to the device, is uncertain.
Wchannel = ∑(Wread ×Sizeread ,Wwrite ×Sizewrite) (1)
In the scheduling phase, the scheduler optimizes theerase requests scheduling. Considering the fairness, theparallelism-aware scheduler assigns a time slice for readrequests and a same-size slice for write/erase requests.The scheduler works on each request queue individually.In the read slice, the scheduler schedules read requeststo the channel. When the slice ends or no read requestis left in the queue, the scheduler determines to schedulewrite or erase request in next slice by Formula 2. Thef is the percent of free blocks in the flash channel. Neis the percent of flash channels that are processing theerase requests at this moment. The a and b represents theweight of these parameters.
e = a× f +b×Ne (2)
If e is higher than 1, the scheduler sends write requestsin the time slice. Otherwise, the scheduler sends eraserequests in that time slice. After the write/erase slice,the scheduler turns to read slice again. In current im-plementation, a and b are respectively set to 2 and 1,which implies that erase requests are scheduled onlyafter the free space drops below 50%. This schemegives higher priority to erase requests when the freespace is not enough. Meanwhile, it prevents too manychannels erasing at the same time, which helps to easethe performance wave under heavy write traffic.
With the employment of these two optimizations, theparallelism-aware scheduler helps to provide both highand consistent performance.
4 Evaluation
In this section, we evaluate ParaFS to answer the follow-ing three questions:
1. How does ParaFS perform compared to other filesystems under light write traffic?
2. How does ParaFS perform under heavy write traf-fic? And, what are the causes behind?
3. What are the benefits respectively from the pro-posed optimizations in ParaFS?
4.1 Experimental SetupIn the evaluation, we compare ParaFS with Ext4 [2],BtrFS [1] and F2FS [28], which respectively representthe in-place-update, copy-on-write, and flash-optimizedlog-structured file systems. ParaFS is also compared toa revised F2FS (annotated as F2FS SB) in addition toconventional F2FS (annotated as F2FS). F2FS organizesdata into segment, which is the GC unit in FS and is thesame size as flash block. F2FS SB organizes data intosuper blocks. A super block consists of multiple adjacentsegments. The number of the segments equals to thenumber of channels in the flash device. In F2FS SB, asuper block is the unit of allocation and garbage collec-tion, and can be accessed in parallel.
We customize a raw flash device to support pro-grammable FTLs. Parameters of the flash device arelisted in Table 2. To support the file systems above,we implement a page-level FTL, named PFTL, based onDFTL [17] with lazy indexing technique [33]. PFTLstripes updates over different channels in a page sizeunit, to fully exploit the internal parallelism. S-FTL isimplemented based on PFTL. It removes the allocationfunction, replaces the page-level mapping with staticblock-level mapping, and simplifies the GC process, asdescribed in Section 3.1. In both FTLs, the numberof flash channels and the capacity of the device areconfigurable. With the help of these FTLs, we collectthe information about flash memory operations, like thenumber of erase operations and the number of pagesmigrated during garbage collection. The low-level in-formation is helpful for comprehensive analysis of filesystem implications.
Table 2: Parameters of the Customized Flash DeviceHost Interface PCIe 2.0 x8
Number of Flash Channel 34Capacity per Channel 32G
NAND Type 25nm MLCPage Size 8KBBlock Size 2MB
Read Bandwidth per Channel 49.84 MB/sWrite Bandwidth per Channel 6.55 MB/s
The experiments are conducted on an X86 serverwith Intel Xeon E5-2620 processor, clocked at 2.10GHz,and 8G memory of 1333MHz. The server runs withLinux kernel 2.6.32, which is required by the customizedflash device. For the target system, we back-port F2FSfrom the 3.15-rc1 main-line kernel to the 2.6.32 kernel.ParaFS is implemented as a kernel module based onF2FS, but differs in data allocation, garbage collection,and I/O scheduling.Workloads. Table 3 summarizes the four workloadsused in the experiments. Two of them run directly on file
7

94 2016 USENIX Annual Technical Conference USENIX Association
Table 3: Workload CharacteristicsName Description # of Files I/O size Threads R/W fsync
Fileserver File server workload: random read and write files 60,000 1MB 50 33/66 NPostmark Mail server workload: create, delete, read and append files 10,000 512B 1 20/80 Y
MobiBench SQLite workload: random update database records N/A 4KB 10 1/99 YYCSB MySQL workload: read and update database records N/A 1KB 50 50/50 Y
(a) channel = 8 (b) channel = 32
Figure 5: Performance Evaluation (Light Write Traffic)
systems and the other two run on databases. Fileserveris a typical pre-defined workload in Filebench [3] toemulate the I/O behaviors in file servers. It creates,deletes and randomly accesses files in multiple threads.Postmark [26] emulates the behavior of mail servers.Transactions, including create, delete, read and appendoperations, are performed to the file systems. Mo-bibench [19] is a benchmark tool for measuring the per-formance of file IO and DB operations. In the evaluation,it issues random update operations to the SQLite[9],which runs with FULL synchronous and WAL journalmode. YCSB [14] is a framework to stress many populardata serving systems. We use the workload-A of YCSBon MySql [7], which consists of 50% random reads and50% random updates.
4.2 Evaluation with Light Write TrafficIn this section, we compare ParaFS with other file sys-tems under light write traffic. We choose 8 and 32channels for this evaluation, which respectively representSATA SSDs [6, 4, 5] and PCIe SSDs [5, 41]. The devicecapacity is set to 128GB.
Figure 5 shows the throughput of evaluated file sys-tems, and results are normalized against F2FS’s perfor-mance in 8-channel case. From the figure, we have twoobservations.
(1) ParaFS outperforms other file systems in all cases,and achieves 13% higher over F2FS for postmark work-load in the 32-channel case. In the evaluated file systems,BtrFS performs poorly, especially for database bench-marks that involve frequent syncs. The update prop-agation (i.e., “wandering tree” problem [38]) of copy-on-write brings intensive data writes in BtrFS during
the sync calls (7.2× for mobibench, 3.0× for YCSB).F2FS mitigates this problem by updating the metadatain place [28]. Except BtrFS, other file systems performroughly similar under light write traffic. F2FS onlyoutperforms Ext4 by 3.5% in fileserver with 32 channels,which is consistent to the F2FS evaluations on PCIeSSD[28]. The performance bottleneck appears to bemoved, due to the fast command processing and highrandom access ability of the PCIe drive. F2FS SBshows nearly the same performance to F2FS. Since PFTLstripes the requests over all flash channels with a page-size unit, larger allocation unit in F2FS SB doesn’t gainmore benefit in parallelism. The GC impact of largerblock recycling is also minimized due to the light writepressure. The impact will be seen under heavy write traf-fic evaluations in Section 4.3. ParaFS uses cooperativedesigns in both FS and FTL levels, eliminates the dupli-cate functions, and achieves the highest performance.
(2) Performance gains in ParaFS grow when the num-ber of channels is increased. Comparing the two figuresin Figure 5, all file systems have their performanceimproved when the number of channels is increased.Among them, ParaFS achieves more. It outperformsF2FS averagely by 1.53% in 8-channel cases and 6.29%in 32-channel cases. This also evidences that ParaFSspends more efforts in exploiting the internal parallelism.
In all, ParaFS has comparable or better performancethan the other evaluated file systems when the writetraffic is light.
4.3 Evaluation with Heavy Write TrafficSince ParaFS is designed to address the problems ofdata grouping and garbage collection while exploiting
8

USENIX Association 2016 USENIX Annual Technical Conference 95
(a) Fileserver (b) Postmark
(c) MobiBench (d) YCSB
Figure 6: Performance Evaluation (Heavy Write Traffic)
the internal parallelism, evaluations using heavy writetraffic are much more important. In this evaluation, welimit the capacity of flash device to 16GB and increasethe benchmark sizes. The write traffic sizes in the fourevaluated benchmarks are set to 2× ∼ 3× of the flashdevice capacity, to trigger the garbage collection actions.
4.3.1 Performance
Figure 6 shows the throughput of evaluated file systemsfor the heavy write traffic cases, with the number ofchannels varied from 1 to 32. Results are normalizedagainst F2FS’s throughput in 1-channel case. From thefigure, we have three observations.
(1) Ext4 outperforms F2FS for three out of the fourevaluated workloads, which is different from that inthe light write traffic evaluation. The performance gapbetween Ext4 and F2FS tends to be wider with moreflash channels. The reason why the flash-optimized F2FSfile system has worse performance than Ext4 is the sideeffects of internal parallelism. In F2FS, the hot/cold datagrouping and the aligned segments are broken when datapages are distributed to multiple channels in the FTL.Also, the invalidation of a page is known in the FTLonly after it is recycled in the F2FS, due to the no in-place update. Unfortunately, a lot of invalid pages havebeen migrated during garbage collection before theirstatuses are passed to the FTL. Both reasons lead tohigh GC overhead in FTL, and the problem gets moreserious with increased parallelism. In Ext4, the in-
place update pattern is more accurate in telling FTLs thepage invalidation than F2FS. The exceptional case is thepostmark workload, which contains a lot of create anddelete operations. Ext4 spreads the inode allocation inall of the block groups for load balance. This causes theinvalid pages distributed evenly in the flash blocks andresults in higher garbage collection overhead than F2FS(18.5% higher on average). In general, the observationthat flash-optimized file system is not good at exploitinginternal parallelism under heavy write traffic motivatesour ParaFS design.
(2) F2FS SB shows improved performance than F2FSfor the four evaluated workloads, and the improvementgrows with more channels. This is also different fromresults in the light write traffic evaluation. The perfor-mance of F2FS improves quickly when the number ofchannels is increased from 1 to 8, but the improvementis slowed down afterward. For fileserver, postmark andYCSB workloads, F2FS gains little improvement in the32-channel case over the 16-channel case. The maincause is the increasing GC overhead, which will be seenin next section. In contrast, allocation and recyclingin super block units of F2FS SB ease the GC overheadcaused by unaligned segments. The trim commands sentby F2FS SB contain larger address space, and are moreeffective in telling the invalid pages to the FTL. However,selecting victims in larger units also decreases the GCefficiency. As such, the internal parallelism using superblock methods [12, 42] is still not effective.
(3) ParaFS outperforms other file systems in all cases.
9

96 2016 USENIX Annual Technical Conference USENIX Association
(a) Recycled Block Count (b) GC Efficiency
(c) Write Traffic from FS (d) Write Traffic from FTL
Figure 7: Garbage Collection and Write Traffic Evaluation (Fileserver)
ParaFS outperforms Ext4 from 1.0× to 1.7× in the 8-channel case, and to 2.5× in the 32-channel case. ParaFSoutperforms F2FS from 1.6× to 1.9× in the 8-channelcase, and from 1.7× to 3.1× in the 32-channel case.ParaFS outperforms F2FS SB from 1.2× to 1.5× inboth cases. ParaFS keeps the aligned flash block eraseunits while using page-unit striping in 2-D allocation.The coordinated multi-threaded GC is also helpful inreducing the GC overhead. And thus, ParaFS is effectivein exploiting the internal parallelism under heavy writetraffic.
4.3.2 Write Traffic and Garbage Collection
To further understand the performance gains in ParaFS,we collect the statistics of garbage collection and writetraffic from both FS and FTL levels. We select thefileserver workload as an example due to space limita-tion. The other workloads have similar patterns and areomitted. For fairness, we revise the fileserver benchmarkto write fixed-size data. In the evaluation, the write trafficsize in fileserver is set to 48GB, and the device capacityis 16GB.
Figure 7(a) and Figure 7(b) respectively give the re-cycled block count and the garbage collection efficiencyof evaluated file systems with varied number of flashchannels. The recycled block count is the number offlash blocks that are erased in flash memory. The GCefficiency is measured using the average percentage ofinvalid pages in a victim flash block.
ParaFS has the lowest garbage collection overhead andhighest GC efficiency among all evaluated file systemsunder four benchmarks. For the fileserver evaluation, itachieves the lowest recycled block count (62.5% of F2FSon average) and the highest GC efficiency (91.3% on av-erage). As the number of channels increases, the numberof recycled blocks in F2FS increases quickly. This isdue to the unaligned segments and uncoordinated GCprocesses of both sides (as analyzed in Section 4.3.1).It is also explained with the GC efficiency degradationin Figure 7(b). The GC efficiency of Ext4, BtrFS,ParaFS trends to drop a little with more flash channels.Because the adjacent pages are more scattered when thedevice internal parallelism increases, and they tend to beinvalidated together. F2FS SB acts different from otherfile systems. In F2FS SB, when the number of channelsis increased from 8 to 32, the number of recycled blocksdecreases and the GC efficiency increases. The reasonis that the super block has better data grouping andalignments, and this advantage becomes increasinglyevident with higher degree of parallelism. F2FS SB alsotriggers FS-level GC threads more frequently with largerallocation and GC unit. More trim commands with largeraddress space help to decrease the number of invalidpages migrated by GC process in the FTL level. ParaFSfurther utilizes fine-grained data grouping and GC unit,and has the lowest garbage collection overhead.
Figure 7(c) shows the write traffic that file systemswrite to FTLs. Figure 7(d) shows the write traffic
10
USENIX Association 2016 USENIX Annual Technical Conference 97
Figure 8: Performance Consistency Evaluation
that FTLs write to the flash memory. Write traffic ineither level comes from not only the file system dataand metadata but also the page migrated during garbagecollection in FS or FTL level. The write traffic fromFS in Ext4, BtrFS and F2FS are stable for differentparallelism levels, because the increase of the flash chan-nels in the device is transparent to them. ParaFS writesmore in the file system than Ext4, F2FS and F2FS SB,but less than them in the FTL. Because all the pagemigration during the garbage collection is done in theFS level. Similarly, F2FS SB has higher write trafficfrom FS and lower from FTL than F2FS, as the numberof channels is increased from 8 to 32. This resultsfrom the improved GC efficiency as mentioned above.The FTL write traffic in F2FS is higher than F2FS SB,which explains why F2FS SB has better performancethan F2FS in Figure 6. ParaFS coordinates garbagecollections in the two levels, and is more effective inspace recycling. Compared to F2FS, ParaFS decreasesthe write traffic to the flash memory by 31.7% ∼ 54.7%in 8-channel case, and 37.1% ∼ 58.1% in 32-channelcase. Compared to F2FS SB, ParaFS decreases it by14.9% ∼ 48.4% in 8-channel case, and 15.7% ∼ 32.5%in 32-channel case.
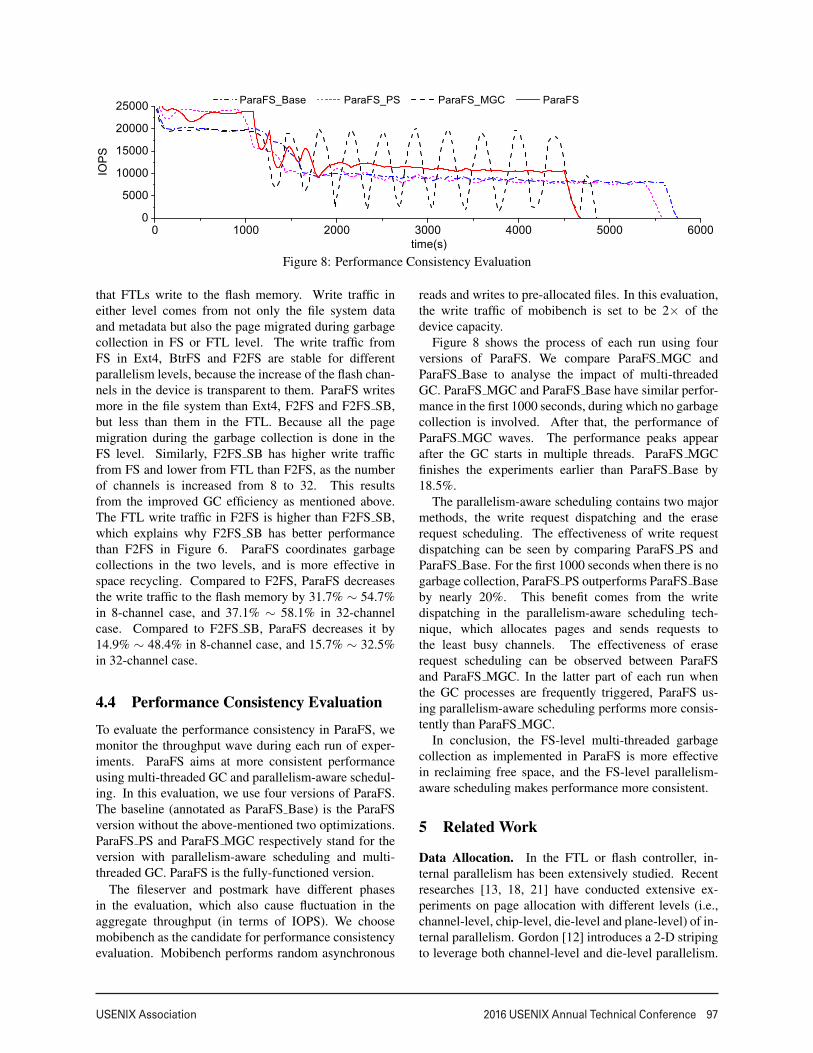
4.4 Performance Consistency Evaluation
To evaluate the performance consistency in ParaFS, wemonitor the throughput wave during each run of exper-iments. ParaFS aims at more consistent performanceusing multi-threaded GC and parallelism-aware schedul-ing. In this evaluation, we use four versions of ParaFS.The baseline (annotated as ParaFS Base) is the ParaFSversion without the above-mentioned two optimizations.ParaFS PS and ParaFS MGC respectively stand for theversion with parallelism-aware scheduling and multi-threaded GC. ParaFS is the fully-functioned version.
The fileserver and postmark have different phasesin the evaluation, which also cause fluctuation in theaggregate throughput (in terms of IOPS). We choosemobibench as the candidate for performance consistencyevaluation. Mobibench performs random asynchronous
reads and writes to pre-allocated files. In this evaluation,the write traffic of mobibench is set to be 2× of thedevice capacity.
Figure 8 shows the process of each run using fourversions of ParaFS. We compare ParaFS MGC andParaFS Base to analyse the impact of multi-threadedGC. ParaFS MGC and ParaFS Base have similar perfor-mance in the first 1000 seconds, during which no garbagecollection is involved. After that, the performance ofParaFS MGC waves. The performance peaks appearafter the GC starts in multiple threads. ParaFS MGCfinishes the experiments earlier than ParaFS Base by18.5%.
The parallelism-aware scheduling contains two majormethods, the write request dispatching and the eraserequest scheduling. The effectiveness of write requestdispatching can be seen by comparing ParaFS PS andParaFS Base. For the first 1000 seconds when there is nogarbage collection, ParaFS PS outperforms ParaFS Baseby nearly 20%. This benefit comes from the writedispatching in the parallelism-aware scheduling tech-nique, which allocates pages and sends requests tothe least busy channels. The effectiveness of eraserequest scheduling can be observed between ParaFSand ParaFS MGC. In the latter part of each run whenthe GC processes are frequently triggered, ParaFS us-ing parallelism-aware scheduling performs more consis-tently than ParaFS MGC.
In conclusion, the FS-level multi-threaded garbagecollection as implemented in ParaFS is more effectivein reclaiming free space, and the FS-level parallelism-aware scheduling makes performance more consistent.
5 Related Work
Data Allocation. In the FTL or flash controller, in-ternal parallelism has been extensively studied. Recentresearches [13, 18, 21] have conducted extensive ex-periments on page allocation with different levels (i.e.,channel-level, chip-level, die-level and plane-level) of in-ternal parallelism. Gordon [12] introduces a 2-D stripingto leverage both channel-level and die-level parallelism.
11

98 2016 USENIX Annual Technical Conference USENIX Association
But note that, 2-D striping in Gordon is different from2-D data allocation in ParaFS. 2-D striping is designedin the flash controller, which places data to leveragemultiple levels of parallelism. 2-D data allocation isdesigned in file system, which organizes data into dif-ferent groups using metrics of parallelism and hotness.In addition, aggressive parallelism in the device levelscatters data addresses, breaking up the data organizationin the system level. P-OFTL [42] has pointed out thisproblem and found that increased parallelism leads tohigher garbage overhead, which in turn can decrease theoverall performance.
In the file system level, DirectFS [20] and NamelessWrite [45] propose to remove data allocation functionsfrom file systems and leverage the data allocations inthe FTL or storage device, which can have better de-cisions with detailed knowledge of hardware internals.OFSS [33] proposes an object-based FTL, which enableshardware/software codesign with both knowledge of filesemantics and hardware internals. However, these filesystems pay little attention to internal parallelism, whichis the focus of ParaFS in this paper.Garbage Collection. Garbage collection has a strongimpact on system performance for log-structured de-signs. Researchers are trying to pass more file semanticsto FTLs to improve GC efficiency. For instance, trim is auseful interface to inform FTLs the data invalidation, inorder to reduce GC overhead in migrating invalid pages.Also, Kang et al. [25] found that FTLs can have moreefficient hot/cold data grouping, which further reducesGC overhead, if the expected lifetime of written data ispassed from file systems to FTLs. In addition, Yang etal. [44] found log-structured designs in both levels ofsystem software and FTLs have semantic gaps, whichmake garbage collection in both levels inefficient. Incontrast, ParaFS proposes to bridge the semantic gap andcoordinate garbage collection in the two levels.
In the file system level, SFS [34] uses a sophisticatedhot/cold data grouping algorithm using both access countand age of the block. F2FS [28] uses a static data group-ing method according to the file and data types. How-ever, these grouping algorithms suffer when groupeddata are spread out in the FTL. Our proposed ParaFSaims to solve this problem and keep physical hot/coldgrouping while exploiting the internal parallelism.
A series of research works use large write block size toalign the flash block and decrease the GC overhead[40,31, 30, 35]. RIPQ[40] and Pannier[31] aggregate smallrandom writes in memory, divide them into groups ac-cording to the hotness, and evict the groups in flash blocksize. Nitro[30] deduplicates and compresses the writes inRAM and evicts them in flash block size. Nitro proposesto modify the FTL to support block-unit striping thatensures the effective of the block-size write optimization.
SDF[35] employs block-unit striping which is tightlycoupled with key-value workloads. ParaFS uses page-size I/O unit and aims at file system workloads.I/O Scheduling. In flash storage, new I/O schedulingpolicies have been proposed to improve utilization ofinternal parallelism [24, 23, 16] or fairness [37, 39].These scheduling policies are designed in the controller,the FTL or the block layer. In these levels, addressesof requests are determined. In comparison, system-level scheduling can schedule write requests before dataallocation, which is flexible.
LOCS [41] is a key-value store that schedules I/Orequests in the system level upon open-channel SSDs.With the use of log-structured merge tree (LSM-tree),data is organized into data blocks aligned to flash blocks.LOCS schedules the read, write and erase operations tominimize the response time.
Our proposed ParaFS is a file system that schedulesI/O requests in the system level. Different from key-value stores, file systems have irregular reads and writes.ParaFS exploits the channel-level parallelism with page-unit striping. Moreover, its goal is in making perfor-mance more consistent.
6 Conclusion
ParaFS is effective in exploiting the internal parallelismof flash storage, while keeping physical hot/cold datagrouping and low garbage collection overhead. It alsotakes the parallelism opportunity to schedule read, writeand erase requests to make system performance moreconsistent. ParaFS’s design relies on flash devices withcustomized FTL that exposes physical layout, which canbe represented by three values. The proposed designbridges the semantic gap between file systems and FTLs,by simplifying FTL and coordinating functions of thetwo levels. We implement ParaFS on a customizedflash device. Evaluations show that ParaFS outperformsthe flash-optimized F2FS by up to 3.1×, and has moreconsistent performance.
Acknowledgments
We thank our shepherd Haryadi Gunawi and anonymousreviewers for their feedbacks and suggestions. This workis supported by the National Natural Science Foundationof China (Grant No. 61232003, 61433008, 61502266),the Beijing Municipal Science and Technology Com-mission of China (Grant No. D151100000815003), theNational High Technology Research and DevelopmentProgram of China (Grant No. 2013AA013201), andthe China Postdoctoral Science Foundation (Grant No.2015M580098).
12

USENIX Association 2016 USENIX Annual Technical Conference 99
References[1] Btrfs. http://btrfs.wiki.kernel.org.
[2] Ext4. https://ext4.wiki.kernel.org/.
[3] Filebench benchmark. http://sourceforge.net/apps/mediawiki/filebench.
[4] Intel dc s3500 480gb enterprise ssd review.http://www.tweaktown.com/reviews/5534/intel-dc-s3500-480gb-enterprise-ssd-review/index.html.
[5] Intel ssd 750 pcie ssd review.http://www.anandtech.com/show/9090/intel-ssd-750-pcie-ssd-review-nvme-for-the-client.
[6] Intel x25-m and x18-m mainstream sata solid-state drives.ftp://download.intel.com/newsroom/kits/ssd/pdfs/X25-M 34nm ProductBrief.pdf.
[7] Mysql. https://www.mysql.com/.
[8] FusionIO Virtual Storage Layer.http://www.fusionio.com/products/vsl, 2013.
[9] SQLite. http://www.sqlite.org/, 2014.
[10] N. Agrawal, V. Prabhakaran, T. Wobber, J. D. Davis, M. Man-asse, and R. Panigrahy. Design tradeoffs for SSD performance.In Proceedings of 2008 USENIX Annual Technical Conference(USENIX ATC), Berkeley, CA, 2008. USENIX.
[11] M. Bjørling, J. Axboe, D. Nellans, and P. Bonnet. Linux blockio: introducing multi-queue ssd access on multi-core systems.In Proceedings of the 6th International Systems and StorageConference (SYSTOR), page 22. ACM, 2013.
[12] A. M. Caulfield, L. M. Grupp, and S. Swanson. Gordon:Using flash memory to build fast, power-efficient clusters fordata-intensive applications. In Proceedings of the 14th Inter-national Conference on Architectural Support for ProgrammingLanguages and Operating Systems (ASPLOS), pages 217–228,New York, NY, USA, 2009. ACM.
[13] F. Chen, R. Lee, and X. Zhang. Essential roles of exploitinginternal parallelism of flash memory based solid state drives inhigh-speed data processing. In Proceedings of the 17th IEEEInternational Symposium on High Performance Computer Archi-tecture (HPCA), pages 266–277. IEEE, 2011.
[14] B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, andR. Sears. Benchmarking cloud serving systems with ycsb. InProceedings of the 1st ACM symposium on Cloud computing,pages 143–154. ACM, 2010.
[15] C. Dirik and B. Jacob. The performance of pc solid-statedisks (ssds) as a function of bandwidth, concurrency, devicearchitecture, and system organization. In Proceedings of the36th annual International Symposium on Computer Architecture(ISCA). ACM, 2009.
[16] C. Gao, L. Shi, M. Zhao, C. J. Xue, K. Wu, and E. H. Sha.Exploiting parallelism in i/o scheduling for access conflict min-imization in flash-based solid state drives. In Mass StorageSystems and Technologies (MSST), 2014 30th Symposium on,pages 1–11. IEEE, 2014.
[17] A. Gupta, Y. Kim, and B. Urgaonkar. DFTL: A flash translationlayer employing demand-based selective caching of page-leveladdress mappings. In Proceedings of the 14th International Con-ference on Architectural Support for Programming Languagesand Operating Systems (ASPLOS), pages 229–240, New York,NY, USA, 2009. ACM.
[18] Y. Hu, H. Jiang, D. Feng, L. Tian, H. Luo, and S. Zhang.Performance impact and interplay of ssd parallelism throughadvanced commands, allocation strategy and data granularity. InProceedings of the International Conference on Supercomputing(ICS), pages 96–107. ACM, 2011.
[19] S. Jeong, K. Lee, J. Hwang, S. Lee, and Y. Won. Frameworkfor analyzing android i/o stack behavior: from generating theworkload to analyzing the trace. Future Internet, 5(4):591–610,2013.
[20] W. K. Josephson, L. A. Bongo, D. Flynn, and K. Li. DFS: A filesystem for virtualized flash storage. In Proceedings of the 8thUSENIX Conference on File and Storage Technologies (FAST),Berkeley, CA, 2010. USENIX.
[21] M. Jung and M. Kandemir. An evaluation of different pageallocation strategies on high-speed ssds. In Proceedings of the 4thUSENIX conference on Hot Topics in Storage and File Systems,pages 9–9. USENIX Association, 2012.
[22] M. Jung and M. Kandemir. Revisiting widely held ssd expecta-tions and rethinking system-level implications. In Proceedings ofthe fifteenth international joint conference on Measurement andmodeling of computer systems (SIGMETRICS), pages 203–216.ACM, 2013.
[23] M. Jung and M. T. Kandemir. Sprinkler: Maximizing resourceutilization in many-chip solid state disks. In High PerformanceComputer Architecture (HPCA), 2014 IEEE 20th InternationalSymposium on, pages 524–535. IEEE, 2014.
[24] M. Jung, E. H. Wilson III, and M. Kandemir. Physicallyaddressed queueing (paq): improving parallelism in solid statedisks. In Proceedings of the 39th ACM/IEEE InternationalSymposium on Computer Architecture (ISCA), pages 404–415,2012.
[25] J.-U. Kang, J. Hyun, H. Maeng, and S. Cho. The multi-streamed solid-state drive. In Proceedings of the 6th USENIXconference on Hot Topics in Storage and File Systems, pages 13–13. USENIX Association, 2014.
[26] J. Katcher. Postmark: A new file system benchmark. Technicalreport, Technical Report TR3022, Network Appliance, 1997.
[27] R. Konishi, Y. Amagai, K. Sato, H. Hifumi, S. Kihara, andS. Moriai. The linux implementation of a log-structured filesystem. ACM SIGOPS Operating Systems Review, 40(3):102–107, 2006.
[28] C. Lee, D. Sim, J. Hwang, and S. Cho. F2FS: A new file systemfor flash storage. In Proceedings of the 13th USENIX Conferenceon File and Storage Technologies (FAST), Santa Clara, CA, Feb.2015. USENIX.
[29] S. Lee, M. Liu, S. Jun, S. Xu, J. Kim, and Arvind. Application-managed flash. In Proceedings of the 14th Usenix Conferenceon File and Storage Technologies (FAST), pages 339–353, SantaClara, CA, 2016. USENIX Association.
[30] C. Li, P. Shilane, F. Douglis, H. Shim, S. Smaldone, and G. Wal-lace. Nitro: A capacity-optimized ssd cache for primary storage.In Proceedings of 2014 USENIX Annual Technical Conference(USENIX ATC), pages 501–512, Philadelphia, PA, June 2014.USENIX Association.
[31] C. Li, P. Shilane, F. Douglis, and G. Wallace. Pannier: Acontainer-based flash cache for compound objects. In Proceed-ings of the 16th Annual Middleware Conference, pages 50–62,Vancouver, Canada, 2015. ACM.
[32] Y. Lu, J. Shu, and W. Wang. ReconFS: A reconstructable filesystem on flash storage. In Proceedings of the 12th USENIXConference on File and Storage Technologies (FAST), pages 75–88, Berkeley, CA, 2014. USENIX.
[33] Y. Lu, J. Shu, and W. Zheng. Extending the lifetime of flash-basedstorage through reducing write amplification from file systems. InProceedings of the 11th USENIX Conference on File and StorageTechnologies (FAST), Berkeley, CA, 2013. USENIX.
13

100 2016 USENIX Annual Technical Conference USENIX Association
[34] C. Min, K. Kim, H. Cho, S.-W. Lee, and Y. I. Eom. SFS: randomwrite considered harmful in solid state drives. In Proceedings ofthe 10th USENIX Conference on File and Storage Technologies(FAST), Berkeley, CA, 2012. USENIX.
[35] J. Ouyang, S. Lin, S. Jiang, Z. Hou, Y. Wang, and Y. Wang. SDF:Software-defined flash for web-scale internet storage systems.In Proceedings of the 19th International Conference on Archi-tectural Support for Programming Languages and OperatingSystems (ASPLOS), pages 471–484, New York, NY, USA, 2014.ACM.
[36] X. Ouyang, D. Nellans, R. Wipfel, D. Flynn, and D. K. Panda.Beyond block I/O: Rethinking traditional storage primitives. InProceedings of the 17th IEEE International Symposium on HighPerformance Computer Architecture (HPCA), pages 301–311.IEEE, 2011.
[37] S. Park and K. Shen. Fios: a fair, efficient flash i/o scheduler. InProceedings of the 10th USENIX Conference on File and StorageTechnologies (FAST), Berkeley, CA, 2012. USENIX.
[38] M. Rosenblum and J. K. Ousterhout. The design and imple-mentation of a log-structured file system. ACM Transactions onComputer Systems (TOCS), 10(1):26–52, 1992.
[39] K. Shen and S. Park. Flashfq: A fair queueing i/o schedulerfor flash-based ssds. In Proceedings of 2013 USENIX AnnualTechnical Conference (USENIX ATC), pages 67–78, Berkeley,CA, 2013. USENIX.
[40] L. Tang, Q. Huang, W. Lloyd, S. Kumar, and K. Li. Ripq:Advanced photo caching on flash for facebook. In Proceedings ofthe 13th USENIX Conference on File and Storage Technologies(FAST), pages 373–386, Santa Clara, CA, Feb. 2015. USENIXAssociation.
[41] P. Wang, G. Sun, S. Jiang, J. Ouyang, S. Lin, C. Zhang, andJ. Cong. An efficient design and implementation of LSM-treebased key-value store on open-channel SSD. In Proceedings ofthe Ninth European Conference on Computer Systems (EuroSys),pages 16:1–16:14, New York, NY, USA, 2014. ACM.
[42] W. Wang, Y. Lu, and J. Shu. p-OFTL: an object-based semantic-aware parallel flash translation layer. In Proceedings of theConference on Design, Automation and Test in Europe (DATE),page 157. European Design and Automation Association, 2014.
[43] J. Yang, D. B. Minturn, and F. Hady. When poll is better thaninterrupt. In Proceedings of the 10th USENIX Conference on Fileand Storage Technologies (FAST), Berkeley, CA, 2012. USENIX.
[44] J. Yang, N. Plasson, G. Gillis, N. Talagala, and S. Sundararaman.Dont stack your log on my log. In USENIX Workshop on In-teractions of NVM/Flash with Operating Systems and Workloads(INFLOW), 2014.
[45] Y. Zhang, L. P. Arulraj, A. C. Arpaci-Dusseau, and R. H. Arpaci-Dusseau. De-indirection for flash-based SSDs with namelesswrites. In Proceedings of the 10th USENIX Conference on Fileand Storage Technologies (FAST), Berkeley, CA, 2012. USENIX.
14