parallel io - research school of computer science · parallel io these slides are possible thanks...
TRANSCRIPT

5/11/2017
1
nci.org.au
nci.org.au
@NCInews
Parallel IOThese slides are possible thanks to these sources –Jonathan Drusi - SCInet Toronto – Parallel I/O Tutorial, Argonne National Labs: HPC I/O for Computational Scientists,TACC/Cornell MPI/IO Tutorial, Course in Data Intensive Computing – SICS; NeRSC Lustre Notes; Quincey Koziol – HDF Group
nci.org.au
References
• eBook: High Performance Parallel I/O
– Chapter 8: Lustre
– Chapter 13: MPI/IO
– Chapter 15: HDF5
• HPC I/O For Computational Scientists
(YouTube); Slides
• Parallel IO Basics - Paper
• eBook: Memory Systems - Cache, DRAM,
Disk – Bruce Jacob

5/11/2017
2
nci.org.au
The Advent of Big Data
• Big Data refers to datasets and flows large enough that have outpaced our capability to store, process, analyze and understand
– Increase in computing power makes simulations
larger and more frequent
– Increase in sensor technology resolution creates
larger observation data points
• Data sizes that once used to be measured in MBs or GBs now measured in TBs or PBs
• Easier to generate the data than to store it
nci.org.au
The Four V’s
http://www.ibmbigdatahub.com/infographic/four-vs-big-data

5/11/2017
3
nci.org.au
BIG DATA PROJECTS AT THE NCI
nci.org.au© National ComputationalInfrastructure 2014
Numerical Weather Prediction Roadmap
Model Topography of Sydney, NSW
2 x daily 10-day & 3-day forecast40km Global Model
4 x daily 3-day forecast12km Regional Model
Sydney, NSW (research 1.5km topography)
4 x daily 36-hour forecast4km City/State Model
TCTC
Increasing model resolutionfor improved local information
Future model ensembles for likelihood of significant weather
2 x daily 10-day & 3-day forecast12km Global Model
8 x daily 3-day forecast5km Regional Model
24 x daily 18h or 36h forecast1.0km City/State Model
20132020
IN53E-01:“NCI Computational Environments and HPC/HPD” #AGU14, 19 December, 2014 @BenJKEvans
C/- Tim Pugh, BoM
2/34

5/11/2017
4
nci.org.au© National ComputationalInfrastructure 2014
Capture, analysis & application of Earth Obs
c/- Adam Lewis, GA
IN53E-01:“NCI Computational Environments and HPC/HPD” #AGU14, 19 December, 2014 @BenJKEvans
nci.org.au
ESA’s Sentinel Constellation
We care for a safer world
• Sentinel-1 systematic observation scenario in one/two main high rate modes of operation will result in significanlty large acquisition segments (data takes of few minutes)
• 25min in high rate modes leads to about 2.4 TBytes of compressed raw data per day for the 2 satellites
• Wave Mode operated continuously over ocean where high rate modes are not used
6 m
in IW
15 m
in IW
2 m
in IW
Sentinel-1 observation scenario and impact on data volumes
16 GB for SLC4 GB for GRD-HR
46 GB for SLC12 GB for GRD-HR

5/11/2017
5
nci.org.au
ESA’s Sentinel Constellation
We care for a safer world
• Sentinel-1 systematic observation scenario in one/two main high rate modes of operation will result in significanlty large acquisition segments (data takes of few minutes)
• 25min in high rate modes leads to about 2.4 TBytes of compressed raw data per day for the 2 satellites
• Wave Mode operated continuously over ocean where high rate modes are not used
6 m
in IW
15 m
in IW
2 m
in IW
Sentinel-1 observation scenario and impact on data volumes
16 GB for SLC4 GB for GRD-HR
46 GB for SLC12 GB for GRD-HR
Sentinel-1s 2.4TB/daySentinel-2s 1.6TB/day (High-Res Optical Land Monitoring)Sentinel-3s providing 0.6 TB/day (Land+Marine Observation)
nci.org.au
Nepal Earthquake Inteferogram using
Sentinel SAR Data

5/11/2017
6
nci.org.au© National ComputationalInfrastructure 2014
How to bring as much observational scrutiny as possible
to the CMIP/IPCC process?
How to best utilize the wealth of satellite observations for the
CMIP/IPCC process?
c/- Robert Ferraro, NASA/JPL, ESGF F2F, 2014
IN53E-01:“NCI Computational Environments and HPC/HPD” #AGU14, 19 December, 2014 @BenJKEvans
Combining Satellite and Climate4/34
nci.org.au
HARDWARE TRENDS

5/11/2017
7
nci.org.au
Disk and CPU Performance
HPCS2012
(and getting slower)
Dis
k (
MB
/s),
CPU
(M
IPS)
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
Disk and CPU Performance
HPCS2012
(and getting slower)
Dis
k (
MB
/s),
CPU
(M
IPS)
1000x
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
8
nci.org.au
Memory and Storage Latency
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
Assessing Storage Performance
• Data Rate – MB/sec
–Peak or sustained
–Writes are faster than reads
• IOPS – IO Operations Per Second
–open(), close(), seek(), read(),
write()

5/11/2017
9
nci.org.au
Assessing Storage Performance
• Data Rate – MB/sec
–Peak or sustained
–Writes are faster than reads
• IOPS – IO Operations Per Second
–open(), close(), seek(), read(),
write()
Lab – measuring
MB/s and IOPS
nci.org.au
Storage Performance
• Data Rate – MB/sec
– Peak or sustained
– Writes are faster than reads
• IOPS – IO Operations Per Second
– open(), close(), seek(), read(), write()
Device Bandwidth (MB/s) IOPS
SATA HDD 100 100
SSD 250 10000
HD: !
Open, Write, Close 1000x1kB files: 30.01s (eff: 0.033 MB/s)!
Open, Write, Close 1x1MB file: 40ms (eff: 25 MB/s) Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
10
nci.org.au
Storage Performance
• Data Rate – MB/sec
– Peak or sustained
– Writes are faster than reads
• IOPS – IO Operations Per Second
– open(), close(), seek(), read(), write()
Device Bandwidth (MB/s) IOPS
SATA HDD 100 100
SSD 250 10000
SSD: !
Open, Write, Close 1000x1kB files: 300ms (eff: 3.3 MB/s)!
Open, Write, Close 1x1MB file: 4ms (eff: 232 MB/s)
SSDs better at IOPS – no moving parts
Latency at controller, system calls etc.
SSDs are still very expensive. Disk to stay!
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
Storage Performance
• Data Rate – MB/sec
– Peak or sustained
– Writes are faster than reads
• IOPS – IO Operations Per Second
– open(), close(), seek(), read(), write()
Device Bandwidth (MB/s) IOPS
SATA HDD 100 100
SSD 250 10000
SSD: !
Open, Write, Close 1000x1kB files: 300ms (eff: 3.3 MB/s)!
Open, Write, Close 1x1MB file: 4ms (eff: 232 MB/s)
SSDs better at IOPS – no moving parts
Latency at controller, system calls etc.
SSDs are still very expensive. Disk to stay!
Raijin/short – aggregate – 150GB/sec (writes), 120GB/sec (reads)
5 DDN SFA12K arrays for /short, each is capable of 1.3M read IOPS; 700,000 write IOPS yielding a totalof 6.5M read IOPS and 3.5M write IOPS
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
11
nci.org.au
Applications (processes)
VFS
Request-baseddevice mapper targets
dm-multipath
Physical devices
HDD SSD DVDdrive
MicronPCIe card
LSIRAID
AdaptecRAID
QlogicHBA
EmulexHBA
malloc
BIOs (block I /Os)
sysfs(transport attributes) SCSI upper level drivers
/dev/sda
scsi-mq
.../dev/sd*
SCSI low level driversmegaraid_sas
aacraid
qla2xxx ...libata
ahci ata_piix ... lpfc
Transport classesscsi_t ransport_fc
scsi_t ransport_sas
scsi_t ransport_...
/dev/vd*
virtio_blk mtip32xx
/dev/rssd*
ext2 ext3
btrfs
ext4 xfs
ifs iso9660...
NFS codaNetwork FS
gfs ocfs
smbfs ...
Pseudo FS Specialpurpose FSproc sysfs
futexfs
usbfs ...
tmpfs ramfs
devtmpfspipefs
network
nvmedevice
The Linux Storage Stack Diagram
version 4.10, 2017-03-10out lines the Linux storage stack as of Kernel version 4.10
mmap(anonymous pages)
iscsi_tcp
network
/dev/rbd*
Block-based FS
read
(2)
wri
te(2
)
open
(2)
sta
t(2
)
chm
od(2
)
...
Pagecache
mdraid...
stackable
Devices on top of “normal”block devices drbd
(opt ional)
LVMBIOs (block I /Os)
BIOs BIOs
Block Layer
multi queue
blkmq
Softwarequeues
Hardwaredispatchqueues
...
...
hooked in device drivers(they hook in like stackeddevices do)
BIOs
Maps BIOs to requests
deadline
cfqnoop
I /O scheduler
Hardwaredispatchqueue
Requestbased drivers
BIObased drivers
Requestbased drivers
ceph
struct bio- sector on disk
- bio_vec cnt- bio_vec index- bio_vec list
- sector cntFi
bre
Ch
an
nel
ove
r Et
her
net
LIO
target_core_mod
tcm
_fc
Fire
Wir
e
ISC
SI
Direct I/O(O_DIRECT)
device mapper
network
iscs
i_ta
rget
_mod
sbp_
targ
et
target_core_��le
target_core_iblock
target_core_pscsi
vfs_writev, vfs_readv, ...
dm-crypt dm-mirror
dm-thindm-cache
tcm
_qla
2xxx
tcm
_usb
_gad
get
USB
Fib
re C
ha
nn
el
tcm
_vh
ost
Vir
tua
l Ho
st
/dev/nvme*n*
SCSI mid layer
virtio_pci
LSI 12GbsSAS HBA
mpt3sas
bcache
/dev/nullb*
vmw_pvscsi
/dev/skd*
skd
stecdevice
virtio_scsi
para-virtualizedSCSI
VMware'spara-virtualized
SCSI
target_core_user
unionfs FUSE
/dev/mmcblk*p*
dm-raid
/dev/sr* /dev/st *
pm8001
PMC-SierraHBA
SD-/MMC-Card
/dev/rsxx*
rsxx
IBM ��ashadapter
/dev/zram*
memory
null_blk
ufs
userspace
ecryptfs
Stackable FS
mobile device��ash memory
nvme
overlayfs
userspace (e.g. sshfs)
mmcrbdzram
dm-delay
/dev/nbd*
nbd
/dev/ubiblock*
ubi
/dev/loop*
loop
nci.org.au
Applicat ions (processes)
VFS
malloc
BIOs (block I/Os)
ext2 ext3
btrfs
ext4 xfs
ifs iso9660...
NFS codaNetwork FS
gfs ocfs
smbfs ...
Pseudo FS Specialpurpose FSproc sysfs
futexfs
usbfs ...
tmpfs ramfs
devtmpfspipefs
network
The Linux Storage Stack Diagram
version 4.10, 2017-03-10outlines the Linux storage stack as of Kernel version 4.10
mmap(anonymous pages)
Block-based FS
read
(2)
wri
te(2
)
ope
n(2
)
stat
(2)
chm
od(2
)
...
Pagecache
mdraid...
stackable
Devices on top of “normal”block devices drbd
(optional)
LVMBIOs (block I/Os)
ceph
struct bio- sector on disk
- bio_vec cnt- bio_vec index- bio_vec list
- sector cnt
Fibr
e Ch
anne
lov
er E
ther
net
LIO
target_core_mod
tcm
_fc
Fire
Wire
ISCS
I
Direct I /O(O_DIRECT)
device mapper
iscs
i_ta
rget
_mod
sbp_
targ
et
target_core_��le
target_core_iblock
target_core_pscsi
vfs_writev, vfs_readv, ...
dm-crypt dm-mirror
dm-thindm-cache
tcm
_qla
2xx
x
tcm
_usb
_ga
dget
USB
Fibr
e Ch
anne
l
tcm
_vh
ost
Vir
tua
l Hos
t
bcache
target_core_user
unionfs FUSE
dm-raiduserspace
ecrypt fs
Stackable FS
overlayfs
userspace (e.g. sshfs)
dm-delay

5/11/2017
12
nci.org.au
BIOs (block I /Os)
...gfs ocfs usbfs ... devtmpfs
network
mdraid...
stackable
Devices on top of “normal”block devices drbd
(opt ional)
LVMBIOs (block I /Os)
BIOs BIOs
Block Layer
multi queue
blkmq
Softwarequeues
Hardwaredispatchqueues
...
...
hooked in device drivers(they hook in like stackeddevices do)
BIOs
Maps BIOs to requests
deadline
cfqnoop
I /O scheduler
Hardwaredispatchqueue
Requestbased drivers
BIObased drivers
Requestbased drivers
ceph
struct bio- sector on disk
- bio_vec cnt- bio_vec index- bio_vec list
- sector cnt
device mapper
target_core_��le
target_core_iblock
target_core_pscsi
dm-crypt dm-mirrordm-thindm-cache bcache
target_core_user
unionfs FUSE
dm-raiduserspace
ecrypt fs
Stackable FS
overlayfs
userspace (e.g. sshfs)
dm-delay
nci.org.au
Request-baseddevice mapper targets
dm-multipath
Physical devices
HDD SSD DVDdrive
MicronPCIe card
LSIRAID
AdaptecRAID
QlogicHBA
EmulexHBA
sysfs(transport at tributes) SCSI upper level drivers
/dev/sda
scsi-mq
.../dev/sd*
SCSI low level driversmegaraid_sas
aacraid
qla2xxx ...libata
ahci ata_piix ... lpfc
Transport classesscsi_transport_fc
scsi_t ransport_sas
scsi_transport_...
/dev/vd*
virt io_blk mt ip32xx
/dev/rssd*
nvmedevice
iscsi_tcp
network
/dev/rbd*
dispatchqueues
...dispatchqueue
Requestbased drivers
BIObased drivers
Requestbased drivers
network
/dev/nvme*n*
SCSI mid layer
virtio_pci
LSI 12GbsSAS HBA
mpt3sas
/dev/nullb*
vmw_pvscsi
/dev/skd*
skd
stecdevice
virtio_scsi
para-virtualizedSCSI
VMware'spara-virtualized
SCSI
/dev/mmcblk*p*
/dev/sr* /dev/st*
pm8001
PMC-SierraHBA
SD-/MMC-Card
/dev/rsxx*
rsxx
IBM ��ashadapter
/dev/zram*
memory
null_blk
ufs
mobile device��ash memory
nvmemmcrbdzram
/dev/nbd*
nbd
/dev/ubiblock*
ubi
/dev/loop*
loop

5/11/2017
13
nci.org.au
nci.org.au
HPC IO

5/11/2017
14
nci.org.au
Scientific I/O
• I/O is commonly used by scientific applications to achieve goals like
– Storing numerical output from simulations for later analysis
– Implementing 'out-of-core' techniques for algorithms that process more data
than can fit in system memory and must page data in from disk
– Checkpointing to files that save the state of an application in case of system
failure
• In most cases, scientific applications write large amounts of data in a structured or
sequential 'append-only' way that does not overwrite previously written data or
require random seeks throughout the file
– Having said that, there are seeky workloads like graph traversal and bioinformatics
problems
• Most HPC systems are equipped with a parallel file system such as Lustre or GPFS that
abstracts away spinning disks, RAID arrays, and I/O subservers to present the user
with a simplified view of a single address space for reading and writing to files
https://www.nersc.gov/users/training/online-tutorials/introduction-to-scientific-i-o/?show_all=1
nci.org.au
Data Access in Current Large-Scale Systems
Current systems have greater support on the logical side, more
complexity on the physical side.
I/O Hardware
Application
Files (POSIX)
I/O Transform Layer(s)
Data Model Library
SAN and RAID Enclosures
Compute Node Memory
Internal System Network(s)
Data Movement
Logical (data model) view of data access.
Physical (hardware) view of data access.
I/O Gateways
External Sys. Network(s)
I/O Servers
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf

5/11/2017
15
nci.org.au
Common Methods for Access Data In
Parallel
https://www.nersc.gov/users/training/online-tutorials/introduction-to-scientific-i-o/?show_all=1
nci.org.au
Common Methods for Access Data In
Parallel
• Simplest to implement – each processor has its own
file-handle and works independently of other nodes
• PFS perform well on this type of IO, but this creates
a metadata bottleneck
– ls breaks for example
• Another downside is that program restarts are now
dependent on the getting the same processor layout
https://www.nersc.gov/users/training/online-tutorials/introduction-to-scientific-i-o/?show_all=1

5/11/2017
16
nci.org.au
Common Methods for Access Data In
Parallel
• Many processors share the same file-handle, but write to their own distinct sections of a shared file
• If there are shared regions of files, then a locking manager is used to serialize access
– For large O(N), the locking is an impediment to performance
– Even in ideal cases where the file system is guaranteed that processors are writing to exclusive regions, shared file performance can be lower compared to file-per-processor
• The advantage of shared file access lies in data management and portability, especially when a higher-level I/O format such as HDF5 or netCDF is used to encapsulate the data in the file
https://www.nersc.gov/users/training/online-tutorials/introduction-to-scientific-i-o/?show_all=1
nci.org.au
Common Methods for Access Data In
Parallel
• Collective buffering is a technique used to improve the performance of shared-file access by offloading some of the coordination work from the file system to the application
– A subset of the processors is chosen to be the 'aggregators'
– These collect data from other processors and pack it into contiguous buffers in memory that are then written to the file system
• Reducing the number of processors that interact with the I/O subservers reduces PFS contention
• Originally, developed to reduce the number of small, noncontiguous writes
– Another benefit that is important for file systems such as Lustre is that the buffer size can be set to a multiple of the ideal transfer size preferred by the file system
https://www.nersc.gov/users/training/online-tutorials/introduction-to-scientific-i-o/?show_all=1

5/11/2017
17
nci.org.au
HPC IO – How it works
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf
nci.org.au
Storing and Organizing Data: Storage Model
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf

5/11/2017
18
nci.org.au
Reading and Writing Data to a PFS
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf
nci.org.au
Data Distribution in Parallel File Systems
Distribution across multiple servers allows concurrent access.
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf

5/11/2017
19
nci.org.au
Request Size and IO Rate
Interconnect latency has a significant impact on effective rate
of I/O. Typically I/Os should be in the O(Mbytes) range.
Tests run on 2K processes of IBM Blue Gene/P at ANL.
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf
nci.org.au
Request Size and IO Rate
Interconnect latency has a significant impact on effective rate
of I/O. Typically I/Os should be in the O(Mbytes) range.
Tests run on 2K processes of IBM Blue Gene/P at ANL.
Why are writes faster than reads?
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf

5/11/2017
20
nci.org.au
Where, how you do I/O matters.
•Binary - smaller files, much faster to read/write.
•You’re not going to read GB/TB of data yourself; don’t
bother trying.
•Write in 1 chunk, rather than a few #s at a time.
Large Parallel File System
ASCII binary
173s 6s
Ramdisk
ASCII binary
174s 1s
Typical work station disk
ASCII binary
260s 20s
Timing data: writing 128Mdouble-precision numbers
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
Where, how you do I/O matters.
• All disk systems do best when
reading/writing large,
contiguous chunks
• I/O operations (IOPS) are
themselves expensive
•moving around within a file
•opening/closing
• Seeks - 3-15ms - enough time
to read 0.75 MB!
Typical work station disk
binary - one large read
14s
binary - 8k at a time
20s
binary - 8k chunks, lots of seeks
150s
binary - seeky + open and closes
205s
Timing data: reading 128M
double-precision numbers
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
21
nci.org.au
Where, how you do I/O matters.
•RAM is much better for
random accesses
•Use right storage medium for
the job!
•Where possible, read in
contiguous large chunks, do
random access in memory
•Much better if you use most
of data read in
Large Parallel File System
ASCII binary
173s 6s
Ramdisk
ASCII binary
174s 1s
Typical work station disk
ASCII binary
260s 20s
Ramdisk
binary - one large read
1s
binary - 8k at a time
1s
binary - 8k chunks, lots of seeks
1s
binary - seeky + open and closes
1.5s
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
Where, how you do I/O
matters.• Well built parallel file systems can
greatly increase bandwidth
• Many pipes to network (servers), many spinning disks (bandwidth off of disks)
• But typically even worse penalties for seeky/IOPSy operations (coordinating all those disks.)
• Parallel FS can help with big data in two ways
Large Parallel File System
ASCII binary
173s 6s
Ramdisk
ASCII binary
174s 1s
Typical work station disk
ASCII binary
260s 20s
Large Parallel File System
binary - one large read
7.5s
binary - 8k at a time
62 s
binary - 8k chunks, lots of seeks
428 s
binary - seeky + open and closes
2137 sJonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
22
nci.org.au
Where, how you do I/O
matters.• Well built parallel file systems can
greatly increase bandwidth
• Many pipes to network (servers), many spinning disks (bandwidth off of disks)
• But typically even worse penalties for seeky/IOPSy operations (coordinating all those disks.)
• Parallel FS can help with big data in two ways
Large Parallel File System
ASCII binary
173s 6s
Ramdisk
ASCII binary
174s 1s
Typical work station disk
ASCII binary
260s 20s
Large Parallel File System
binary - one large read
7.5s
binary - 8k at a time
62 s
binary - 8k chunks, lots of seeks
428 s
binary - seeky + open and closes
2137 s
StripingMultiple readers + writers
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
Storing and Organizing Data:
Application Models
Application data models are supported via libraries that map
down to files (and sometimes directories).
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf

5/11/2017
23
nci.org.au
HPC IO Software Stack
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf
nci.org.au
Lustre Components
• All of Raijin’s filesystems are Lustre, which is
is a distributed filesystem
• Primary components are the MDSes and
OSSes. The OSSes contain data, whereas the
MDSes map these objects into files

5/11/2017
24
nci.org.au
nci.org.au
Parts of the Lustre System
http://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf

5/11/2017
25
nci.org.au
Lustre File System and Striping
http://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf
nci.org.au
How does striping help?
• Due to striping, the Lustre file system scales with the number of OSS’s available
• The capacity of a Lustre file system equals the sum of the capacities of the storage targets– Benefit #1: max file size is not limited by the size of a
single target.
– Benefit #2: I/O rate to a file is the of the aggregate I/O rate to the objects.
• Raijin provides 6 MDSes and 50 OSSes, capabile of 150GB/sec, but this speed is split by all users of the system
• Metadata access can be a bottleneck, so the MDS needs to have especially good performance (e.g., solid state disks on some systems)

5/11/2017
26
nci.org.au
Striping data across disks
Parallel FS
• Single client can make use of multiple disk systems simultaneously
• “Stripe” file across many drives
•One drive can be finding next block while another is sending current blockhttp://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf
nci.org.au
Lustre on Raijin 1/2
• Lustre is a scalable, POSIX-compliant parallel
file system designed for large, distributed-
memory systems, such as Raijin at NCI
• It uses a server-client model with separate
servers for file metadata and file content
https://www.nersc.gov/users/training/online-tutorials/introduction-to-scientific-i-o/?show_all=1

5/11/2017
27
nci.org.au
Lustre on Raijin 2/2
• For example, on Raijin, the /short and /gdata{1,2} file systems each have a single metadata server (which can be a bottleneck when working with thousands of files) and 720, 520, 240 'Object Storage Targets' for /short and /gdata{1,2} respectively that store the contents of files
• Although Lustre is designed to correctly handle any POSIX-compliant I/O pattern, in practice it performs much better when the I/O accesses are aligned to Lustre's fundamental unit of storage, which is called a stripe and has a default size (on NCI systems) of 1MB
• Striping is a method of dividing up a shared file across many OSTs, as shown below. Each stripe is stored on a different OST, and the assignment of stripes to OSTs is round-robin
• Striping increases available b/w by using several OSTs in parallel
https://www.nersc.gov/users/training/online-tutorials/introduction-to-scientific-i-o/?show_all=1
nci.org.au
Invoking Striping
http://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf

5/11/2017
28
nci.org.au
Invoking Striping
Lab – perform
striping on
Raijin:/short
and measure
IOPS, B/W
nci.org.au
End-to-End View
Parallel FS(GPFS, PVFS..)
I/O
Middleware
(MPIIO)
Application High-level
Library(HDF5,NetCDF,
ADIOS)
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
29
nci.org.au
Abstraction Layers• High Level libraries can simplify programmers tasks
• Express IO in terms of the data structures of the code, not bytes and blocks
• I/O middleware can coordinate, improve performance
• Data Sieving
• 2-phase I/O
Parallel FS(GPFS, PVFS..)
I/O
Middleware(MPIIO)
Application High-level
Library(HDF5,NetCDF,
ADIOS)
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
Data Sieving
• Combine many non-contiguous IO requests into fewer, bigger IO requests
• “Sieve” unwanted data out
• Reduces IOPS, makes use of high bandwidth for sequential IO
Jonathan Dursi

5/11/2017
30
nci.org.au
Two-Phase
IO• Collect requests into larger chunks
• Have individual nodes read big blocks
• Then use network communications to exchange pieces
• Fewer IOPS, faster IO
• Network communication usually faster
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
BEHIND THE SCENES

5/11/2017
31
nci.org.au
How it works – Concurrent Access
Files are treated like global shared memory regions. Locks are
used to manage concurrent access:
Files are broken up into lock units
Clients obtain locks on units that they will access before
I/O occurs
Enables caching on clients as well (as long as client has a lock,
it knows its cached data is valid)
Locks are reclaimed from clients when others desire access
If an access touches any
data in a lock unit, the
lock for that region must
be obtained before access
occurs.
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf
nci.org.au
Implications of Locking in Concurrent Access
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf

5/11/2017
32
nci.org.au
Reducing the Number of Operations –
Data Sieving
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf
nci.org.au
Avoiding Lock Contention
http://press3.mcs.anl.gov/computingschool/files/2014/01/hpc-io-all-final.pdf

5/11/2017
33
nci.org.au
nci.org.au
@NCInews
Data Storage at NCI
nci.org.au
Data Storage Subsystems at the NCI
• The NCI compute and data environments
allow researchers the ability to seamlessly
work with HPC and Cloud based compute
cycles, while have unified data storage.
• How is this done?

5/11/2017
34
nci.org.au
NCI’s integrated high-performance
environment
10 GigE
/g/data 56Gb FDR IB Fabric
/g/data1~6.3PB
/g/data2~3.1PB
/short7.6PB
/home, /system, /images, /apps
Cache 1.0PB, Tape 12.3PB
Massdata (tape)Persistent global parallel
filesystem
Raijin high-speed
filesystem
Raijin HPC Compute
Raijin Login + Data
moversVMware Cloud
NCI data
movers
To
Hu
xley
DC
Raijin 56Gb FDR IB Fabric
Internet
nci.org.au
10 GigE
/g/data 56Gb FDR IB Fabric
Raijin&HPC&Compute&
Raijin&Login&+&Data&
movers&VMware& Cloud&
NCI&data&
movers&
To H
uxl
ey D
C
Raijin 56Gb FDR IB Fabric
Internet&
The NCI Compute Environment

5/11/2017
35
nci.org.au
10 GigE
/g/data 56Gb FDR IB Fabric
Raijin&HPC&Compute&
Raijin&Login&+&Data&
movers&VMware& Cloud&
NCI&data&
movers&
To H
uxl
ey D
C
Raijin 56Gb FDR IB Fabric
Internet&
The NCI Compute Environment - Raijin
• The NCI compute environment consists of Raijin, the ‘Cloud’ and data movers
• Raijin itself is composed of
– Login nodes, Data mover nodes
– Compute node
• Users see the login and data-mover nodes
nci.org.au
10 GigE
/g/data 56Gb FDR IB Fabric
Raijin&HPC&Compute&
Raijin&Login&+&Data&
movers&VMware& Cloud&
NCI&data&
movers&
To H
uxl
ey D
C
Raijin 56Gb FDR IB Fabric
Internet&
The NCI Compute Environment – The Cloud

5/11/2017
36
nci.org.au
10 GigE
/g/data 56Gb FDR IB Fabric
Raijin&HPC&Compute&
Raijin&Login&+&Data&
movers&VMware& Cloud&
NCI&data&
movers&
To H
uxl
ey D
C
Raijin 56Gb FDR IB Fabric
Internet&
The NCI Compute Environment – The Cloud
• The NCI hosts two OpenStack clouds – the NCI NeCTAR node and the NCI partner cloud called Tenjin
– The Tenjin cloud node is managed by the NCI VL team and has a mature eco-system for hosting virtual laboratories and on-demand science desktops
– If you need access to the 10PB+ of Lustre storage, it is only available via Tenjin
• Our VMWare instance is reserved for internal NCI use like hosting our accounting infrastructure, wikis, LDAP
nci.org.au
10 GigE
/g/data 56Gb FDR IB Fabric
Raijin&HPC&Compute&
Raijin&Login&+&Data&
movers&VMware& Cloud&
NCI&data&
movers&
To H
uxl
ey D
C
Raijin 56Gb FDR IB Fabric
Internet&
The NCI Compute Environment – Data
movers
• Three types of data-mover nodes exist
– Shell access
– Aspera (in-production)
– GridFTP (Q3, 2017)

5/11/2017
37
nci.org.au
/g/data1 ~6.3PB
/g/data2 ~3.1PB
/short 7.6PB
/home, /system, /images, /apps
Cache 1.0PB, Tape 12.3PB
Massdata&(tape)&Persistent&global¶llel&
filesystem&
Raijin&high9speed&
filesystem&
NCI’s Data Infrastructure
nci.org.au
/g/data1 ~6.3PB
/g/data2 ~3.1PB
/short 7.6PB
/home, /system, /images, /apps
Cache 1.0PB, Tape 12.3PB
Massdata&(tape)&Persistent&global¶llel&
filesystem&
Raijin&high9speed&
filesystem&
NCI’s Data Infrastructure – Raijin /short
• /short provides Raijin’s fast Lustre-based scratch storage
• It is intended for short-term, fast disk for compute jobs
• Striping data across multiple OSTs gets good performance.
Be mindful whether your IO workload is IOPS or streaming
bandwidth based to make choices about stripe-widths and
stripe-size

5/11/2017
38
nci.org.au
/g/data1 ~6.3PB
/g/data2 ~3.1PB
/short 7.6PB
/home, /system, /images, /apps
Cache 1.0PB, Tape 12.3PB
Massdata&(tape)&Persistent&global¶llel&
filesystem&
Raijin&high9speed&
filesystem&
NCI’s Data Infrastructure - Massdata
• Massdata is a SGI DMF based tape archive or HSM
• The HSM is dual-site and keeps two copies on tape and we don’t keep backups
• There is a 1PB disk cache in-front of massdata to help stage data to tape or retrieve from tape
• Data is aged in the cache and when certain policies are met, then migrated to two copues
• Middle of 2017 NCI’s Lustre systems will be interfaced to the HSM i.e you don’t have to manually copy data into the massdata area
nci.org.au
/g/data1 ~6.3PB
/g/data2 ~3.1PB
/short 7.6PB
/home, /system, /images, /apps
Cache 1.0PB, Tape 12.3PB
Massdata&(tape)&Persistent&global¶llel&
filesystem&
Raijin&high9speed&
filesystem&
NCI’s Data Infrastructure - gdata
• gdata provides persistent disk storage for jobs
running on Raijin and for VMs running on the cloud
• gdata is designed for bulk storage and streaming,
large writes. Think of it as fast tape!
• Users should stage data from gdata into Raijin’s
/short filesystem for compute jobs

5/11/2017
39
nci.org.au
PARALLEL I/O WITH MPI-IO
nci.org.auhttp://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf

5/11/2017
40
nci.org.auhttp://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf
nci.org.auhttp://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf

5/11/2017
41
nci.org.au
FILE
P0
P1
P2
P(n-1)
P# is a single processor with rank #.
…
memory
memory
memory
Simple MPI-IO
Each MPI task reads/writes a single block:
memory
http://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf
nci.org.auhttp://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf

5/11/2017
42
nci.org.auhttp://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf
nci.org.auhttp://www.cac.cornell.edu/education/training/ParallelMay2012/ParallelIOMay2012.pdf

5/11/2017
43
nci.org.au
MPI-IO Hello World#include <stdio.h>#include <string.h>#include <mpi.h>
int main(int argc, char **argv) { int ierr, rank, size; MPI_Offset offset; MPI_File file; MPI_Status status; const int msgsize=6; char message[msgsize+1];
ierr = MPI_Init(&argc, &argv); ierr|= MPI_Comm_size(MPI_COMM_WORLD, &size); ierr|= MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if ((rank % 2) == 0) strcpy (message, "Hello "); else strcpy (message, "World!");
offset = (msgsize*rank);
MPI_File_open(MPI_COMM_WORLD, "helloworld.txt", MPI_MODE_CREATE|MPI_MODE_WRONLY, MPI_INFO_NULL, &file); MPI_File_seek(file, offset, MPI_SEEK_SET); MPI_File_write(file, message, msgsize, MPI_CHAR, &status); MPI_File_close(&file);
MPI_Finalize(); return 0;}
helloworldc.c
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
#include <stdio.h>#include <string.h>#include <mpi.h>
int main(int argc, char **argv) { int ierr, rank, size; MPI_Offset offset; MPI_File file; MPI_Status status; const int msgsize=6; char message[msgsize+1];
ierr = MPI_Init(&argc, &argv); ierr|= MPI_Comm_size(MPI_COMM_WORLD, &size); ierr|= MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if ((rank % 2) == 0) strcpy (message, "Hello "); else strcpy (message, "World!");
offset = (msgsize*rank);
MPI_File_open(MPI_COMM_WORLD, "helloworld.txt", MPI_MODE_CREATE|MPI_MODE_WRONLY, MPI_INFO_NULL, &file); MPI_File_seek(file, offset, MPI_SEEK_SET); MPI_File_write(file, message, msgsize, MPI_CHAR, &status); MPI_File_close(&file);
MPI_Finalize(); return 0;}
MPI-IO
Hello
World
Usual MPI
startup/
teardown
boilerplate
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
44
nci.org.au
MPI-IO
Hello
World
0 1 2 3
mpiexec -n 4 ./helloworldc
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
MPI-IO
Hello
World
Hello_ World! Hello_ World!
if ((rank % 2) == 0) strcpy (message, "Hello ");
else strcpy (message, "World!");
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
45
nci.org.au
MPI-IO
Hello
World
Hello_ World! Hello_ World!
helloworld.tx t :
MPI_File_open(MPI_COMM_WORLD, "helloworld.txt", MPI_MODE_CREATE|MPI_MODE_WRONLY, MPI_INFO_NULL, &file);
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
MPI-IO
Hello
World
Hello_ World! Hello_ World!
helloworld.tx t :
MPI_File_open(MPI_COMM_WORLD, "helloworld.txt", MPI_MODE_CREATE|MPI_MODE_WRONLY, MPI_INFO_NULL, &file);
int MPI_File_Open( MPI_Comm communicator, char *filename, int mode, MPI_Info info, MPI_File *handle);
Communicator;
collective
operation.
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
46
nci.org.au
MPI-IO
Hello
World
Hello_ World! Hello_ World!
helloworld.tx t :
MPI_File_open(MPI_COMM_WORLD, "helloworld.txt", MPI_MODE_CREATE|MPI_MODE_WRONLY, MPI_INFO_NULL, &file);
int MPI_File_Open( MPI_Comm communicator, char *filename, int mode, MPI_Info info, MPI_File *handle);
Info allows us to send
extra hints to MPI-IO
layer about
file(performance
tuning, special case
handling)
MPI_INFO_NULL: no
extra info.
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
MPI-IO
Hello
World
Hello_ World! Hello_ World!
helloworld.tx t:
offset = (msgsize*rank); MPI_File_seek(file, offset, MPI_SEEK_SET);
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
47
nci.org.au
MPI-IO
Hello
World
Hello_ World! Hello_ World!
helloworld.tx t:
offset = (msgsize*rank); MPI_File_seek(file, offset, MPI_SEEK_SET);
int MPI_File_seek( MPI_File mpi_fh, MPI_Offset offset, int mode);
MPI_SEEK_SET Set file pointer to position offset
MPI_SEEK_CUR pointer ← current position + offset
MPI_SEEK_END pointer ← end of file - offset
Not collective; each adjusts its own local file pointerJonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf
nci.org.au
MPI-IO
Hello
World
Hello_ World! Hello_ World!
helloworld.tx t:
MPI_File_write(file, message, msgsize, MPI_CHAR, &status);
Hello_ Hello_World! World!
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
48
nci.org.au
MPI-IO
Hello
World
Hello_ World! Hello_ World!
helloworld.tx t:
MPI_File_write(file, message, msgsize, MPI_CHAR, &status);
Hello_ Hello_World! World!
int MPI_File_write(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status)
• MPI File write is very much
like a MPI_Send.
• “Sending” count of datatype
from buf “to” the file.
• Here, writing 6 MPI_CHARs.
• Contiguous in memory
starting in buffer.Jonathan Dursi
nci.org.au
MPI-IO
Hello
World
Hello_ World! Hello_ World!
helloworld.tx t:
MPI_File_close(&file);
Hello_ Hello_World! World!
Jonathan Dursi https://support.scinet.utoronto.ca/wiki/images/3/3f/ParIO-HPCS2012.pdf

5/11/2017
49
nci.org.au
HDF5 – Beyond MPI-IO
www.hdfgroup.org
The HDF Group
Parallel HDF5
March 4, 2015 HPC Oil & Gas Workshop
Quincey KoziolDirector of Core Software & HPC
The HDF [email protected]
http://bit.ly/QuinceyKoziol98

5/11/2017
50
www.hdfgroup.org
QUICK INTRO TO HDF5
March 4, 2015 HPC Oil & Gas Workshop 99
www.hdfgroup.org
What is HDF5?
March 4, 2015 HPC Oil & Gas Workshop 100
• HDF5 == Hierarchical Data Format, v5
http://bit.ly/ParallelHDF5-HPCOGW-2015
• A flexible data model• Structures for data organization and specification
• Open source software• Works with data in the format
• Open file format
• Designed for high volume or complex data

5/11/2017
51
www.hdfgroup.org
What is HDF5, in detail?
• A versatile data model that can represent very complex data objects and a wide variety of metadata.
• An open source software library that runs on a wide range of computational platforms, from cell phones to massively parallel systems, and implements a high-level API with C, C++, Fortran, and Java interfaces.
• A rich set of integrated performance features that allow for access time and storage space optimizations.
• Tools and applications for managing, manipulating, viewing, and analyzing the data in the collection.
• A completely portable file format with no limit on the number or size of data objects stored.
March 4, 2015 101HPC Oil & Gas Workshop
http://bit.ly/ParallelHDF5-HPCOGW-2015
www.hdfgroup.org
HDF5 is like …
March 4, 2015 HPC Oil & Gas Workshop 102

5/11/2017
52
www.hdfgroup.org
Why use HDF5?
• Challenging data:• Application data that pushes the limits of what can be
addressed by traditional database systems, XML documents, or in-house data formats.
• Software solutions:• For very large datasets, very fast access requirements,
or very complex datasets.• To easily share data across a wide variety of
computational platforms using applications written in different programming languages.
• That take advantage of the many open-source and commercial tools that understand HDF5.
• Enabling long-term preservation of data.
March 4, 2015 103HPC Oil & Gas Workshop
www.hdfgroup.org
Who uses HDF5?
• Examples of HDF5 user communities• Astrophysics• Astronomers• NASA Earth Science Enterprise• Dept. of Energy Labs• Supercomputing Centers in US, Europe and Asia• Synchrotrons and Light Sources in US and Europe• Financial Institutions• NOAA• Engineering & Manufacturing Industries• Many others
• For a more detailed list, visit• http://www.hdfgroup.org/HDF5/users5.html
March 4, 2015 104HPC Oil & Gas Workshop

5/11/2017
53
www.hdfgroup.orgMarch 4, 2015 105
HDF5 Data Model
• File – Container for objects• Groups – provide structure among objects• Datasets – where the primary data goes
• Data arrays• Rich set of datatype options• Flexible, efficient storage and I/O
• Attributes, for metadata
Everything else is built essentially from these parts.
HPC Oil & Gas Workshop
www.hdfgroup.orgMarch 4, 2015 106
Structures to organize objects
palette
Raster image
3-D array
2-D arrayRaster image
lat | lon | temp
----|-----|-----
12 | 23 | 3.1
15 | 24 | 4.2
17 | 21 | 3.6
Table
““““/”””” (root)
““““/TestData””””
““““Groups””””
““““Datasets””””
HPC Oil & Gas Workshop

5/11/2017
54
www.hdfgroup.org
HDF5 Dataset
March 4, 2015 107
• HDF5 datasets organize and contain data elements.• HDF5 datatype describes individual data elements.
• HDF5 dataspace describes the logical layout of the data elements.
Integer: 32-bit, LE
HDF5 Datatype
Multi-dimensional array of identically typed data elements
Specifications for single dataelement and array dimensions
3
Rank
Dim[2] = 7
Dimensions
Dim[0] = 4
Dim[1] = 5
HDF5 Dataspace
HPC Oil & Gas Workshop
www.hdfgroup.org
HDF5 Attributes
• Typically contain user metadata
• Have a name and a value
• Attributes “decorate” HDF5 objects
• Value is described by a datatype and a dataspace
• Analogous to a dataset, but do not support partial I/O operations; nor can they be compressed or extended
March 4, 2015 108HPC Oil & Gas Workshop

5/11/2017
55
www.hdfgroup.org
HDF5 Software Distribution
HDF5 home page: http://hdfgroup.org/HDF5/• Latest release: HDF5 1.8.14 (1.8.15 coming in May
2015)
HDF5 source code:• Written in C, and includes optional C++, Fortran 90 APIs,
and High Level APIs• Contains command-line utilities (h5dump, h5repack,
h5diff, ..) and compile scripts
HDF5 pre-built binaries:• When possible, includes C, C++, F90, and High Level
libraries. Check ./lib/libhdf5.settings file.• Built with and require the SZIP and ZLIB external
librariesMarch 4, 2015 HPC Oil & Gas Workshop 109
www.hdfgroup.org
The General HDF5 API
• C, Fortran, Java, C++, and .NET bindings • IDL, MATLAB, Python (h5py, PyTables)• C routines begin with prefix H5?
? is a character corresponding to the type of object the function acts on
March 4, 2015 HPC Oil & Gas Workshop 110
Example Interfaces:
H5D : Dataset interface e.g., H5Dread H5F : File interface e.g., H5FopenH5S : dataSpace interface e.g., H5Sclose

5/11/2017
56
www.hdfgroup.org
The HDF5 API
• For flexibility, the API is extensive � 300+ functions
• This can be daunting… but there is hope�A few functions can do a lot�Start simple �Build up knowledge as more features are needed
March 4, 2015 HPC Oil & Gas Workshop 111
Victorinox
Swiss Army
Cybertool 34
www.hdfgroup.org
General Programming Paradigm
• Object is opened or created• Object is accessed, possibly many times• Object is closed
• Properties of object are optionally defined �Creation properties (e.g., use chunking storage)�Access properties
March 4, 2015 HPC Oil & Gas Workshop 112

5/11/2017
57
www.hdfgroup.org
Basic Functions
H5Fcreate (H5Fopen) create (open) File
H5Screate_simple/H5Screate create Dataspace
H5Dcreate (H5Dopen) create (open) Dataset
H5Dread, H5Dwrite access Dataset
H5Dclose close Dataset
H5Sclose close Dataspace
H5Fclose close File
March 4, 2015 HPC Oil & Gas Workshop 113
www.hdfgroup.org
Useful Tools For New Users
March 4, 2015 HPC Oil & Gas Workshop 114
h5dump:Tool to “dump” or display contents of HDF5 files
h5cc, h5c++, h5fc:Scripts to compile applications
HDFView:Java browser to view HDF5 fileshttp://www.hdfgroup.org/hdf-java-html/hdfview/
HDF5 Examples (C, Fortran, Java, Python, Matlab)http://www.hdfgroup.org/ftp/HDF5/examples/

5/11/2017
58
www.hdfgroup.org
OVERVIEW OF PARALLEL HDF5 DESIGN
March 4, 2015 HPC Oil & Gas Workshop 115
www.hdfgroup.org
• Parallel HDF5 should allow multiple processes to perform I/O to an HDF5 file at the same time• Single file image for all processes• Compare with one file per process design:
• Expensive post processing• Not usable by different number of processes• Too many files produced for file system
• Parallel HDF5 should use a standard parallel I/O interface
• Must be portable to different platforms
Parallel HDF5 Requirements
March 4, 2015 HPC Oil & Gas Workshop 116

5/11/2017
59
www.hdfgroup.org
Design requirements, cont
• Support Message Passing Interface (MPI) programming
• Parallel HDF5 files compatible with serial HDF5 files• Shareable between different serial or
parallel platforms
March 4, 2015 HPC Oil & Gas Workshop 117
www.hdfgroup.org
Design Dependencies
• MPI with MPI-IO• MPICH, OpenMPI• Vendor’s MPI-IO
• Parallel file system• IBM GPFS• Lustre• PVFS
March 4, 2015 HPC Oil & Gas Workshop 118
5/11/2017
60
www.hdfgroup.org
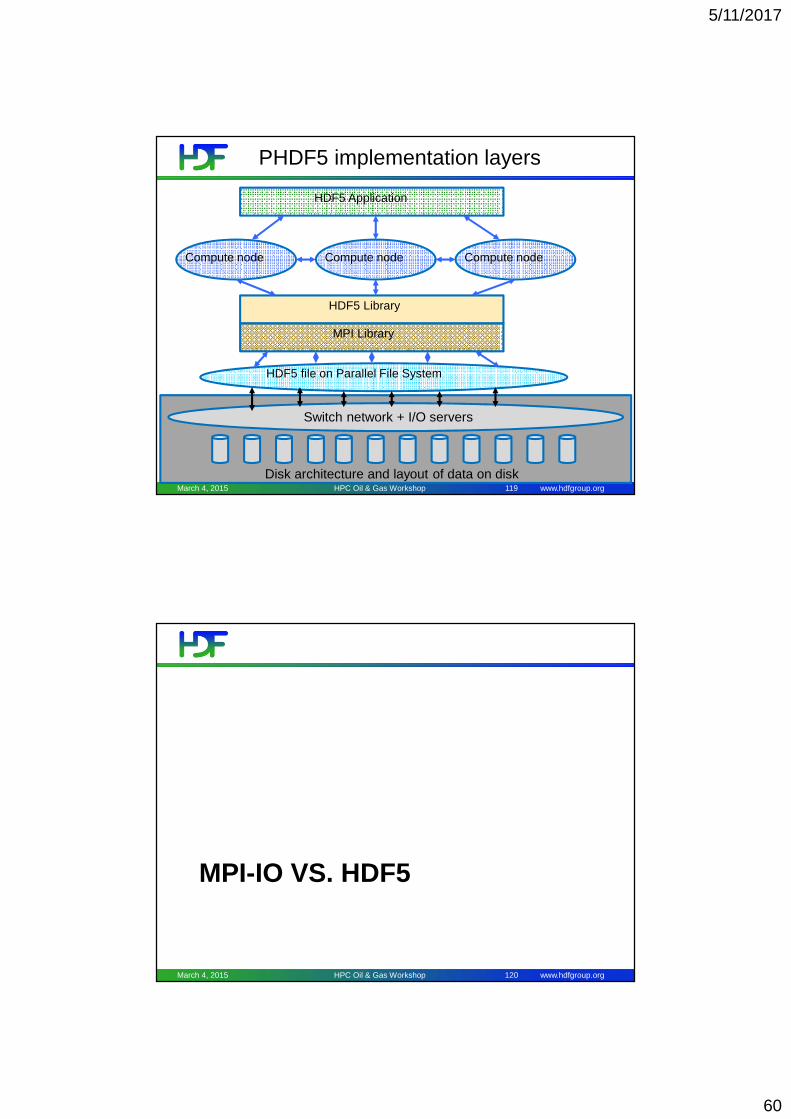
PHDF5 implementation layers
HDF5 Application
Compute node Compute node Compute node
HDF5 Library
MPI Library
HDF5 file on Parallel File System
Switch network + I/O servers
Disk architecture and layout of data on diskMarch 4, 2015 HPC Oil & Gas Workshop 119
www.hdfgroup.org
MPI-IO VS. HDF5
March 4, 2015 HPC Oil & Gas Workshop 120

5/11/2017
61
www.hdfgroup.org
MPI-IO
• MPI-IO is an Input/Output API• It treats the data file as a “linear byte
stream” and each MPI application needs to provide its own file and data representations to interpret those bytes
March 4, 2015 HPC Oil & Gas Workshop 121
www.hdfgroup.org
MPI-IO
• All data stored are machine dependent except the “external32” representation
• External32 is defined in Big Endianness• Little-endian machines have to do the data
conversion in both read or write operations• 64-bit sized data types may lose
information
March 4, 2015 HPC Oil & Gas Workshop 122

5/11/2017
62
www.hdfgroup.org
MPI-IO vs. HDF5
• HDF5 is data management software• It stores data and metadata according
to the HDF5 data format definition• HDF5 file is self-describing
• Each machine can store the data in its own native representation for efficient I/O without loss of data precision
• Any necessary data representation conversion is done by the HDF5 library automatically
March 4, 2015 HPC Oil & Gas Workshop 123
nci.org.au
LABS

5/11/2017
63
nci.org.au
Lab 1 - Measuring IO Performance
• Specifically: Measure IO performance (IOPS,
streaming b/w and latency);
• Objective 1: Learning to use the FIO tool to measure
IOPS and streaming bandwidth;
• Objective 2: Learning to use the ioping tool to
measure IO latency;
• Objective 3: Data collection and analysis;
• Objective 4: Learning how to interact with remote
code repositories like github;
nci.org.au
Lab 1 – Background – Tools
• What is FIO?
fio is a tool that will spawn a number of
threads or processes doing a particular type
of io action as specified by the user
• What is ioping?
A tool to monitor I/O latency in real time. It
shows disk latency in the same way as ping
shows network latency

5/11/2017
64
nci.org.au
Lab 1 – ioping Tasks – 1/3
a) Log into Raijin and in your /short/c04 area create a
directory called Lab1, then check out the following Git
repos:
a.1) FIO: https://github.com/axboe/fio.git
a.2) ioping: https://github.com/koct9i/ioping.git
b) Build both repos for FIO and ioping in your
raijin:/short/c04 area
nci.org.au
Lab 1 – ioping Tasks – 2/3
c) Raijin has three filesystems accessible to end-users: /home, /jobfs and /short
c.1) Measuring latency for single threaded sequential workloads
Using ioping, measure the IO latency for /short. Construct PBS jobs or
use the express queue to use 1 CPU and run the ioping executable and record latency (in milliseconds),
IOPS and B/W for block sizes of 4KB, 128KB and 1MB and working sets of 10MB, 100MB, 1024MB.
An example run:
% /short/z00/jxa900/ioping -c 20 -s 8KB -C -S 1024MB /home/900/jxa900 # run ioping for 20 requests, 8KB block size and for working set of 1GB on my home directory
...
8 KiB from /home/900/jxa900 (lustre 10.9.103.3@o2ib3:10.9.103.4@o2ib3:/homsys): request=20 time=29 us
--- /home/900/jxa900 (lustre 10.9.103.3@o2ib3:10.9.103.4@o2ib3:/homsys) ioping statistics ---
20 requests completed in 2.79 ms, 160 KiB read, 7.16 k iops, 55.9 MiB/s
min/avg/max/mdev = 28 us / 139 us / 289 us / 103 us
From the above experiment, the corresponding data values are:
Title: Working Set (MB), Block Size (KB), Time Taken (ms), Data Read (KB), IOPS, B/W (MB/sec)
Row: 1024, 8, 2.79, 160, 7160, 55.9

5/11/2017
65
nci.org.au
Lab 1 – ioping Tasks – 3/3
From the previous experiment, note down in a table :
Can you explain the observed trends for IOPS and B/W for the three working set sizes, on changing the request block size?
Extra credit: Run this Lab on a Raijin compute nodes’ /jobfs and compare
Working Set
(MB)
Block Size
(KB)
Time Taken
(ms)
Data Read
(KB)
IOPS B/W
(MB/sec)
10 4
10 128
10 1024
100 4
100 128
100 1024
1024 4
1024 128
1024 1024
nci.org.au
Lab 1 – FIO Tasks – 1/2
Using FIO, measure read and write IOPS for two, four and eight threads of IO running on /short for a block sizes 1MB with
filesize of 1024MB. These can be set when calling FIO using the --bs=1024M and --size=1024MB flags. For a sequential write
workload add –readwrite=write.
Fill in below table.
SEQUENTIAL WRITE IO PERFORMANCE:
No. of
Threads
Working
Set (MB)
Block Size
(KB)
Time
Taken (ms)
Data Written
(MB)
IOPS B/W
(MB/sec)
2 1024 1024
4 1024 1024
8 1024 1024

5/11/2017
66
nci.org.au
Lab 1 – FIO Tasks – 2/2
• Sample run for random IO:# Random Workload – set using --readwrite=randrw, ratio of reads and writes set using --rwmixread=50 (i.e. 50% read, 50% writes)
% /short/z00/jxa900/fio-src/fio --randrepeat=1 --ioengine=libaio --gtod_reduce=1 --bs=4k --iodepth=8 --size=1024MB --readwrite=randrw --rwmixread=50 --thread --numjobs=2 --name=test --filename=/short/jxa900/test.out
test: (g=0): rw=randrw, bs=4K-4K/4K-4K/4K-4K, ioengine=libaio, iodepth=64
...
fio-2.2.6-15-g3765
Starting 2 threads
Jobs: 2 (f=2): [m(2)] [100.0% done] [47712KB/0KB/0KB /s] [11.1K/0/0 iops] [eta 00m:00s]
test: (groupid=0, jobs=2): err= 0: pid=7014: Sat Apr 25 18:46:09 2015
mixed: io=2048.0MB, bw=43254KB/s, iops=10813, runt= 48485msec
cpu : usr=1.42%, sys=20.51%, ctx=243452, majf=0, minf=5
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued : total=r=524288/w=0/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
MIXED: io=2048.0MB, aggrb=43253KB/s, minb=43253KB/s, maxb=43253KB/s, mint=48485msec, maxt=48485msec
In the previous table note the data:
Title: Num Threads, Working Set (MB), Block Size (KB), Time Taken (ms), Data Read/Written (MB), IOPS, B/W (MB/sec)
Row: 2, 1024, 4, 48485, 2048, 10813, 42.2 (=43253/1024)
nci.org.au
Lab 2 – Lustre Striping Parameters on Raijin
Lustre allows you to modify three striping parameters for a shared file:
- the stripe count controls how many OSTs the file is striped over (for example, the stripe count is 4 for the
file shown above);
- the stripe size controls the number of bytes in each stripe; and
- the start index chooses where in the list of OSTs to start the round-robin assignment
(the default value -1 allows the system to choose the offset in order to load balance the file system).
The default parameters on Raijin:/short are [count=2, size=1MB, index=-1], but these can be changed and
viewed on a per-file or per-directory basis using the commands:
% lfs setstripe [file,dir] -c [count] -s [size] -i [index]
% lfs getstripe [file,dir]
A file automatically inherits the striping parameters of the directory it is created in, so changing the
parameters of a directory is a convenient way to set the parameters for a collection of files you are about to
create. For instance, if your application creates output files in a subdirectory called output/, you can set the
striping parameters on that directory once before your application runs, and all of your output files will
inherit those parameters.

5/11/2017
67
nci.org.au
Lab 2 – Tasks – 1/2
a) Create a directory under Raijin:/short and
run lfs getstripe <myDir>. Explain the output
of the command, use the man-pages if
required;
b) Re-run the lab exercise with FIO using the
following stripe sizes and counts for a 1GB file,
for a sequential write workload
Stripe Size: 1MB, 4MB
Stripe Count: -1, 2, 4
nci.org.au
Lab 2 – Tasks – 2/2
Stripe
Size (MB)
Stripe
Count
No. of
Threads
Working
Set (MB)
Block
Size
(KB)
Time
Taken
(ms)
Data
Written
(MB)
IOPS B/W
(MB/sec
)
1 -1 4 1024 1024
1 2 4 1024 1024
1 4 4 1024 1024
4 -1 4 1024 1024
4 2 4 1024 1024
4 4 4 1024 1024
Bonus Credit: Using your ANU UniID and password, log onto the NeCTAR cloudand bring up a single core VM using a CentOS or Ubuntu image on any NeCTAR node.Perform the same tests as in Lab 1.
URL for creating VMs: https://dashboard.rc.nectar.org.au/Setting up SSH keys: http://darlinglab.org/tutorials/instance_startup/

5/11/2017
68
nci.org.au
Lab 3 – MPI-IO – Tasks – 1/2
• Copy Lab3 into your /short area from /short/c07/src-io/Lab3
• Make and run the MPI-IO example helloworld
• Fix sine.c to output sine.dat to plot using gnuplot – see next slide. Remember to use ssh –XY [email protected] to get X11 forwarding working. There is a subtle bug that needs to be fixed AND you need to add in the MPI-IO code to write out the output from computing sin(x)
nci.org.au
Lab 3 – MPI-IO – Tasks 2/2