parsymony: scalable parallel data mining
DESCRIPTION
PARSYMONY: Scalable Parallel Data Mining. Alok N. Choudhary Northwestern University (ACK: Harsha Nagesh (Bell Labs) and Sanjay Goil (Sun). Outline. Overview of PARSIMONY MAFIA (Subspace clustering) pMAFIA (Parallel Subspace Clustering) Performance Results PARSIMONY - PowerPoint PPT PresentationTRANSCRIPT

Alok Choudhary [email protected] 1 Northwestern University
PARSYMONY: Scalable Parallel Data Mining
Alok N. ChoudharyNorthwestern University
(ACK: Harsha Nagesh (Bell Labs) and Sanjay Goil (Sun)

Alok Choudhary [email protected] 2 Northwestern University
Outline
• Overview of PARSIMONY• MAFIA (Subspace clustering)• pMAFIA (Parallel Subspace Clustering)• Performance Results• PARSIMONY
– multidimensional data analysis– parallel classification
• Summary

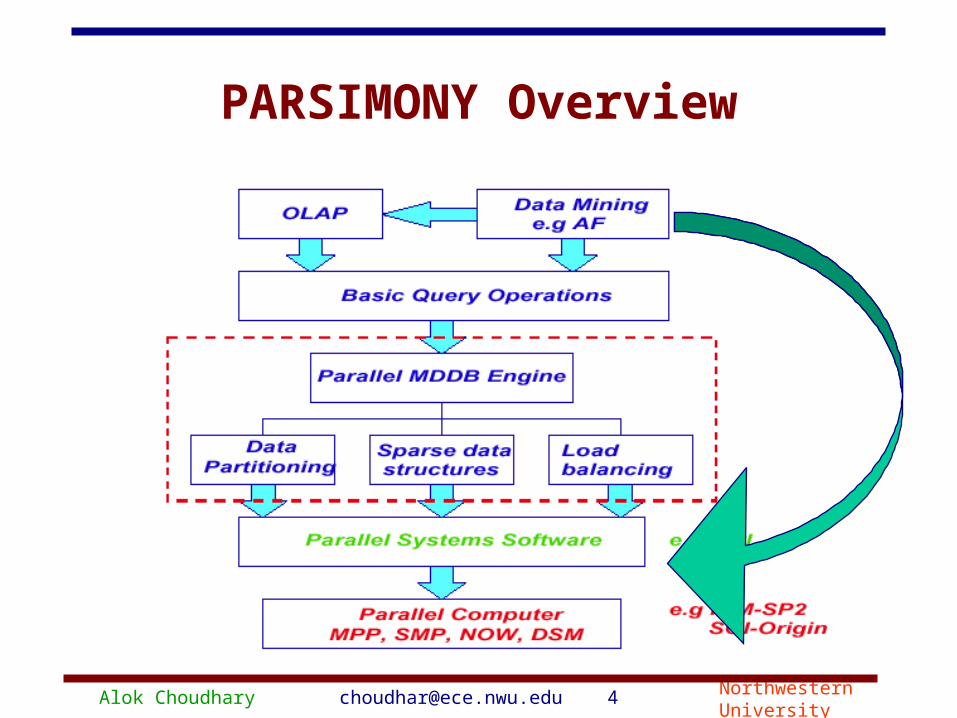

Alok Choudhary [email protected] 5 Northwestern University
MAFIA: Subspace Clustering for High-Dimensional Data Sets
•Clustering and subspace clustering•Base MAFIA Algorithm•pMAFIA (parallelization)•Performance Results

Alok Choudhary [email protected] 7 Northwestern University
Clustering Multi-dimensional Dimensional Data Sets
Determine range of attributes in each dimension of the cluster(s)

Alok Choudhary [email protected] 8 Northwestern University
Issues to be addressed• Basic algorithm computational optimizations• Scalability with database size (out of core data
sets)• Scalability with the dimensionality of data • Efficient Parallelization• Recognition of arbitrary shaped clusters

Alok Choudhary [email protected] 9 Northwestern University
Related Work• Partition based Clustering:
– User specified k representative points taken as cluster centers and points assigned to cluster centers
• k-means, k-mediods, CLARANS (VLDB 94), BIRCH (SIGMOD 96),..• Consider clustering partitioning of points
• Hierarchical Clustering:– Each point is a cluster. Merge similar points together gradually.
• CURE (SIGMOD 98) (use sampling)• Categorical Clustering:
– Clustering of categorical data e.g automobile sales data: color, year, model, price, etc
– Best suited for non-numerical data• CACTUS (KDD 99), STIRR (VLDB 98)

Alok Choudhary [email protected] 10 Northwestern University
Related Work • Density and Grid Based Clustering :
– Clusters are high density regions than its surroundings• WaveCluster (VLDB 98), DBSCAN, CLIQUE (SIGMOD 98)
– Number of subspaces is exponential in the data dimensionality– Multidimensional space divided into grids. The histogram in each
hyper-rectangle is found. Grid regions with a significant histogram value are cluster regions.
– Post-processing done to grow the connected cluster regions.– Fine grid size results in explosion in the number hyper-rectangles,
coarser grids fail to detect clusters.– Correct Grid Size is very critical !

Alok Choudhary [email protected] 12 Northwestern University
Subspace Clustering • Observation: “If a collection of points S is a cluster in
a k-dimensional space, then S is also a part of a cluster in any (k-1) dimensional projection of the space”
• Algorithm : Growing clusters…candidate dense units in any k dimensions are obtained by merging dense units in (k-1) dimensions which share any (k-2) dimensions.– Ex: ( {a1,b7,d9}, {b7,c8,d9} ) --> {a1,b7,c8,d9}– Candidate dense units are populated by a pass on the data set
and the dense units are found out in each dimension.– Dense units found are combined to form candidate dense units.– Algorithm terminates when no more candidate dense units
found.

Alok Choudhary [email protected] 13 Northwestern University
Adaptive Grids (reducing computation in practice)
• Automatic Grid fitting based on data distribution– MAFIA : Merging of Adaptive Finite Intervals !
• Optimal Bins in each dimension leads to very few units in the grid (candidate dense units)
– (a) : CLIQUE– (b) : MAFIA

Alok Choudhary [email protected] 14 Northwestern University
Base MAFIA Algorithm• Divide each dimension into very fine regions.• Compute histogram in these regions along every
dimension.• Set the value of a sliding window to the
maximum histogram value in the window.• Adjacent units which have nearly same histogram
values are merged together to form larger bins.• Threshold of each bin formed is computed
automatically. • A bin having a histogram value much greater (by a factor 2~3)
than that of equi-distribution of data is DENSE.

Alok Choudhary [email protected] 15 Northwestern University

Alok Choudhary [email protected] 16 Northwestern University
MAFIA Algorithm (merging dense units) Algorithm : Candidate dense units in any k
dimensions are obtained by merging dense units in (k-1) dimensions which share any (k-2) dimensions.
Ex: ( {a1,c7,b8}, {c7,b8,d9} ) --> {a1,c7,b8,d9}
Alok Choudhary [email protected] 17 Northwestern University
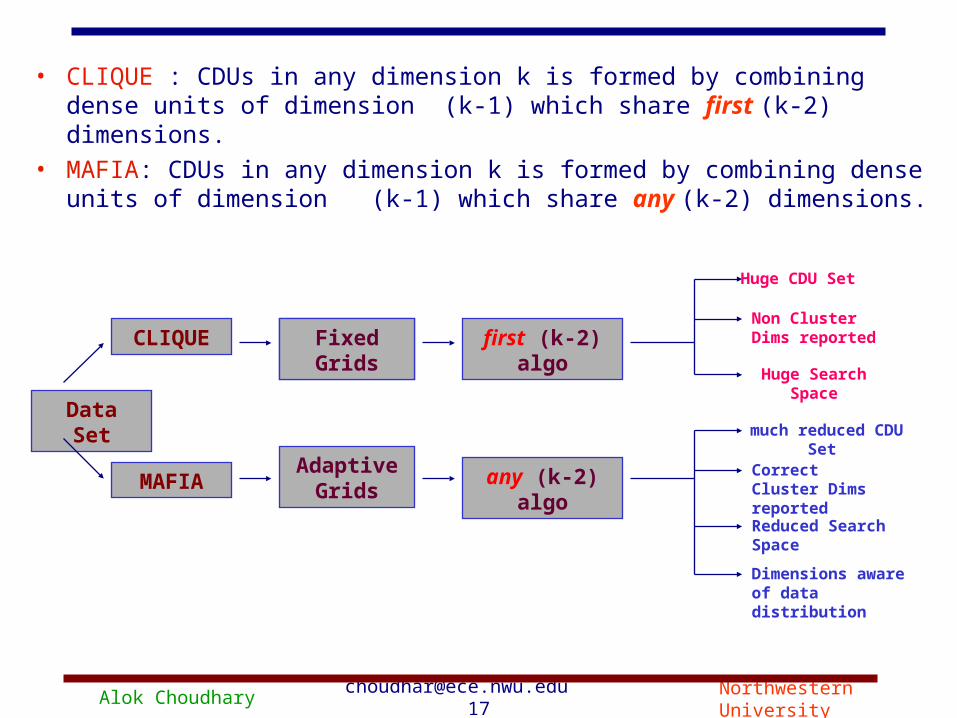
• CLIQUE : CDUs in any dimension k is formed by combining dense units of dimension (k-1) which share first (k-2) dimensions.
• MAFIA: CDUs in any dimension k is formed by combining dense units of dimension (k-1) which share any (k-2) dimensions.
Data Set
CLIQUE
MAFIA
Fixed Grids
Adaptive Grids
Fixed Grids first (k-2) algo
any (k-2) algo
Huge CDU Set
Non Cluster Dims reported
Huge Search Space
much reduced CDU Set
Correct Cluster Dims reported
Reduced Search Space
Dimensions aware of data distribution

Alok Choudhary [email protected] 18 Northwestern University
Parallel MAFIA
• pMAFIA: Parallel Subspace Clustering– Scalable in data size and number of dimensions
Grid and Density based clustering algorithm– Parallelization provides speedup for the subspace
clustering algorithm.

Alok Choudhary [email protected] 19 Northwestern University
pMAFIA Algorithm:
Each processor reads part of the data in a Data Parallel fashion and constructs histogram in every dimension. // Data read in chunks (out of core) of data
Reduce communication to obtain global histogram. All processors build Adaptive grids using the histogram. // Each bin formed is a Candidate Dense Unit.
Current Dimension k = 1 while (no more dense units found)
if( k > 1) Build Candidate Dense units();
Populate the candidate dense units in a data parallel fashion and in chunks (out-of-core) of B records.
Reduce communication to obtain global CDU population. Identify the dense units (); Build dense unit data structures(); // for the next higher dimension

Alok Choudhary [email protected] 20 Northwestern University
Build-Candidate-Dense-Units Current Dimension(k) = 3.

Alok Choudhary [email protected] 22 Northwestern University
Build Candidate Dense Units• Each dense unit is compared with every other dense unit to form CDUs,
resulting in an O(Ndu2) algorithm.(Ndu-number of dense units)• For large values of Ndu CDUs built in parallel. Processors 0,..,(p-1) work in parallel on parts of total Ndu dense units.
Processor k compares dense units between Ni and Ni+1 with all the other dense units; for optimal task partitioning we have
• Identical CDUs generated during the process need to be discarded. Each generated CDU compared with every other CDU to identify similar ones
resulting in O(Ncdu2) algorithm.

Alok Choudhary [email protected] 24 Northwestern University
Parallelization (Building CDUs)
Total work done by Pi is shown

Alok Choudhary [email protected] 25 Northwestern University
pMAFIA : ANALYSIS• Data parallelism in populating the CDUs in every dimension : effective for massive data sets.• Gains of task parallelism realized when data contains large number of dense units (clusters).
– A ‘k’ dimensional dense unit allocated just 2k bytes of memory, k bytes for dimensions and k for bin indices.
– Data structures in form of linear arrays of bytes: communicate very small message buffers, space optimization.
• Although bottom-up algorithm is exponential in the data dimension, for low subspace coverage, with use of Adaptive grids and parallel formulation very promising results.– k dimension of the highest dimension dense unit, we explore all possible subspaces of these k
dimensions ==> O(ck)– For k passes over the data set O( (N/pB) * k*Tio),
• N-total number of records, p-processors, • B- records per chunk, Tio-I/O access time for a block of B records.
– Communication overhead results in O(Tcomm * S * p * k), • Tcomm - constant for communication, S- size of message exchanged,.
O(ck + (N/pB) * k*Ti + Tcomm * S * p * k )

Alok Choudhary [email protected] 26 Northwestern University
pMAFIA Outline
• Clustering and subspace clustering• Base MAFIA Algorithm• pMAFIA (parallelization)• Performance Results
– Adaptivity performance – Scalability with data set size.– Scalability with data dimensionality.– Scalability with cluster dimensionality.– Some Real world data sets.

Alok Choudhary [email protected] 29 Northwestern University
Advantage of Adaptive Grids
• 300,000 records in a 15 Dimension space with 1 cluster of 5 dimensions.– A speedup of 80 obtained
over CLIQUE. – CLIQUE failed to produce
results with our modified CDU generation algorithm even in 2 hours on 16 processors.
– This relatively small data set mined in 32 seconds on 1 processor

Alok Choudhary [email protected] 30 Northwestern University
Scalability with Data Set Size
• 20 Dimension data with 5 clusters in 5 different subspaces
• data sets :up to 11.8 million records
• Clusters detected in just about 3 minutes on 16 processors !
• Almost Linear with the increase in the data set size (because most time in scanning)
Alok Choudhary [email protected] 31 Northwestern University
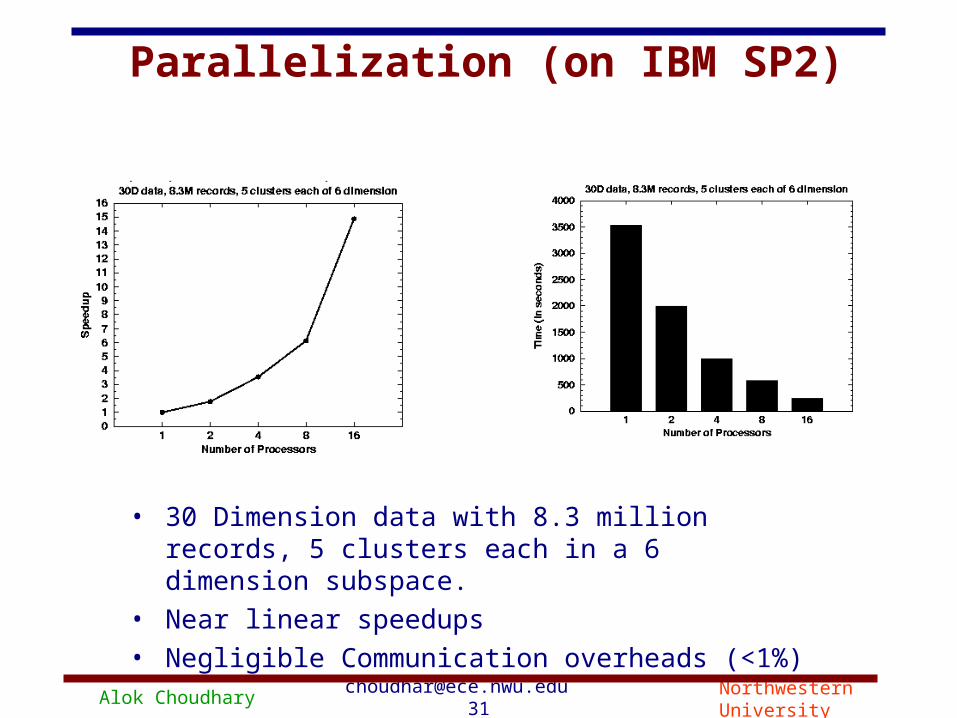
Parallelization (on IBM SP2)
• 30 Dimension data with 8.3 million records, 5 clusters each in a 6 dimension subspace.
• Near linear speedups• Negligible Communication overheads (<1%)

Alok Choudhary [email protected] 32 Northwestern University
Data Dimensionality
• 250,000 records, 3 clusters in different 5 dimensional subspaces.
• Near linear behavior with data dimensionality : Algorithm depends on the maximum number of dimensions in a clusters and not on the data dimensionality.

Alok Choudhary [email protected] 33 Northwestern University
Cluster Dimensionality
• 50 dimension data with 1 cluster, 650,000 records; cluster dimension from 3 to 10.
• Behavior in line with the order of the algorithm : increases with subspace coverage of the cluster.
Alok Choudhary [email protected] 34 Northwestern University
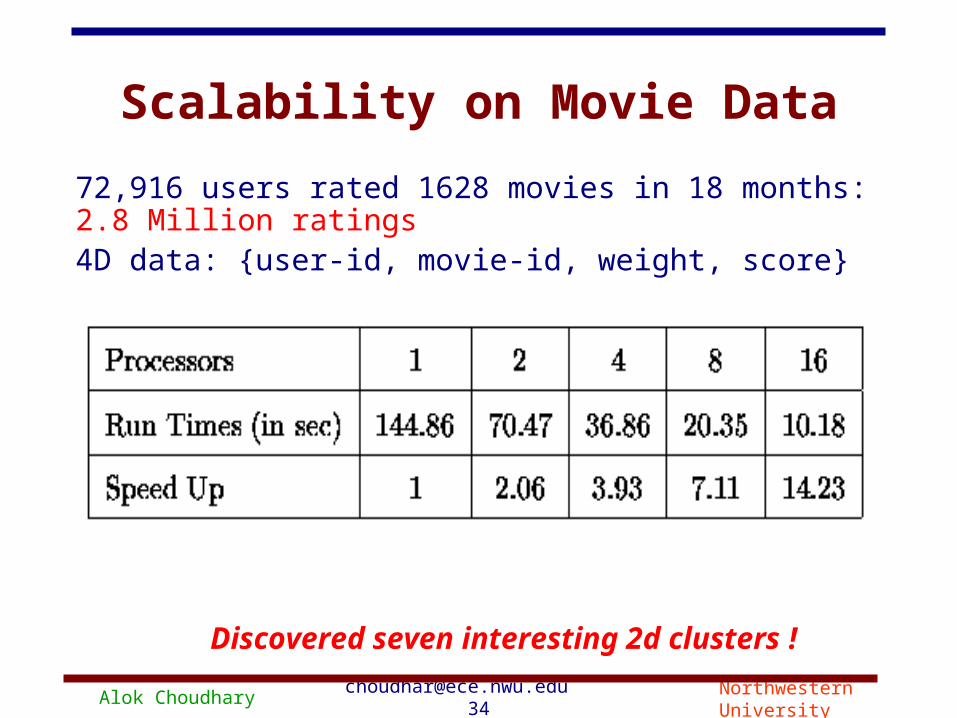
Scalability on Movie Data
72,916 users rated 1628 movies in 18 months: 2.8 Million ratings
4D data: {user-id, movie-id, weight, score}
Discovered seven interesting 2d clusters !

Alok Choudhary [email protected] 35 Northwestern University
Other Data Sets
• One day Ahead Prediction of DAX (German Stock Exchange)– DAX prediction data set was based on a 12 input time series like stock indices, bond
indices, gold prices, etc– 22 dimensions with 2757 records: Major gains from task parallelism– Mined clusters in 8.16 seconds on 8 processors.– Unique clusters discovered in 3,4,5 and 6 dimensional subspaces.
• Ionosphere data: (UCI repository)– Radar data collected in Goose Bay, Labrador
• 34 dimension data, 351 records.• Discovered unique clusters only in 3 and 4 dimensional sub spaces.

Alok Choudhary [email protected] 37 Northwestern University
Summary and Conclusions for pMAFIA
• MAFIA : unsupervised subspace clustering algorithm• Introduced the adaptive grids formulation• First parallel subspace clustering algorithm for
massive data sets– Incorporates both task and data parallelism. .
• pMAFIA : Scalable and Parallel Implementation in data size, no of dimensions
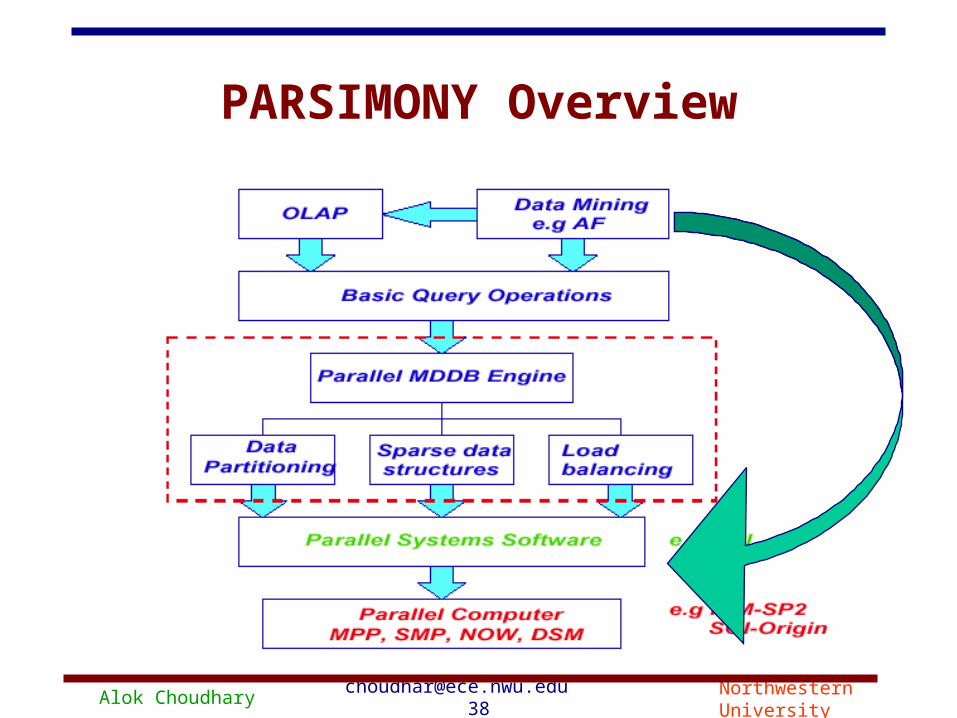

Alok Choudhary [email protected] 39 Northwestern University
Sparse Data Structures and Representations

Alok Choudhary [email protected] 40 Northwestern University
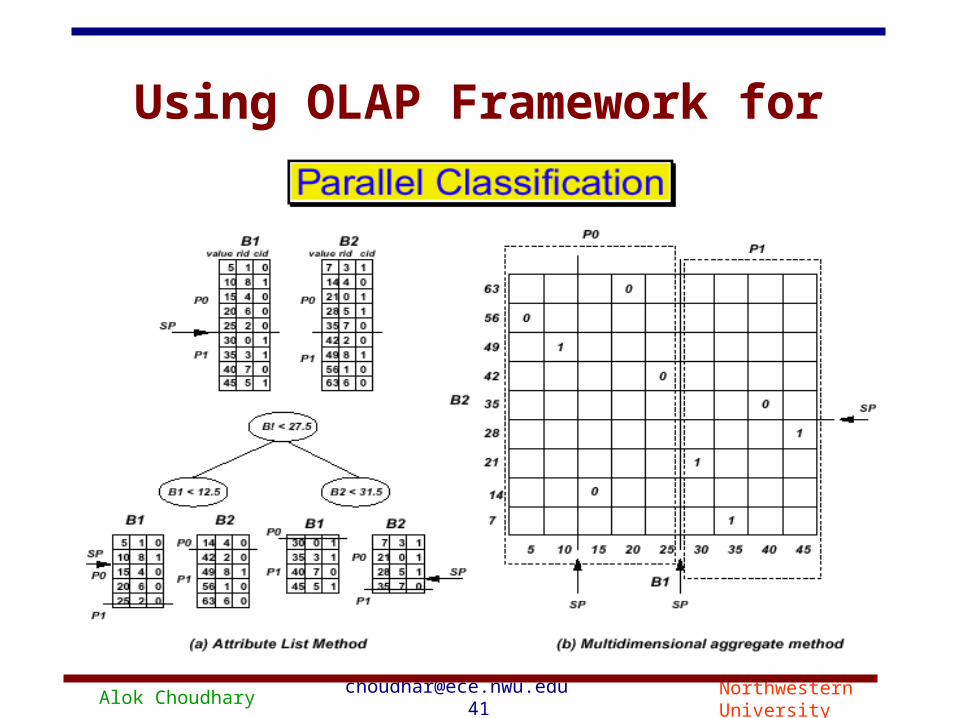

Alok Choudhary [email protected] 42 Northwestern University
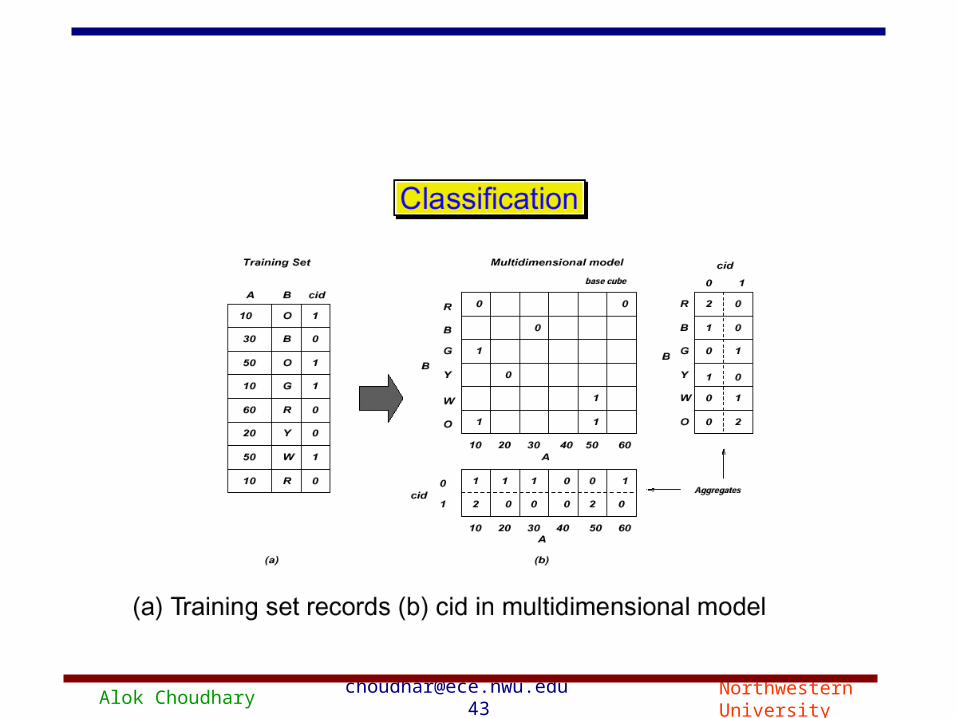
Alok Choudhary [email protected] 43 Northwestern University
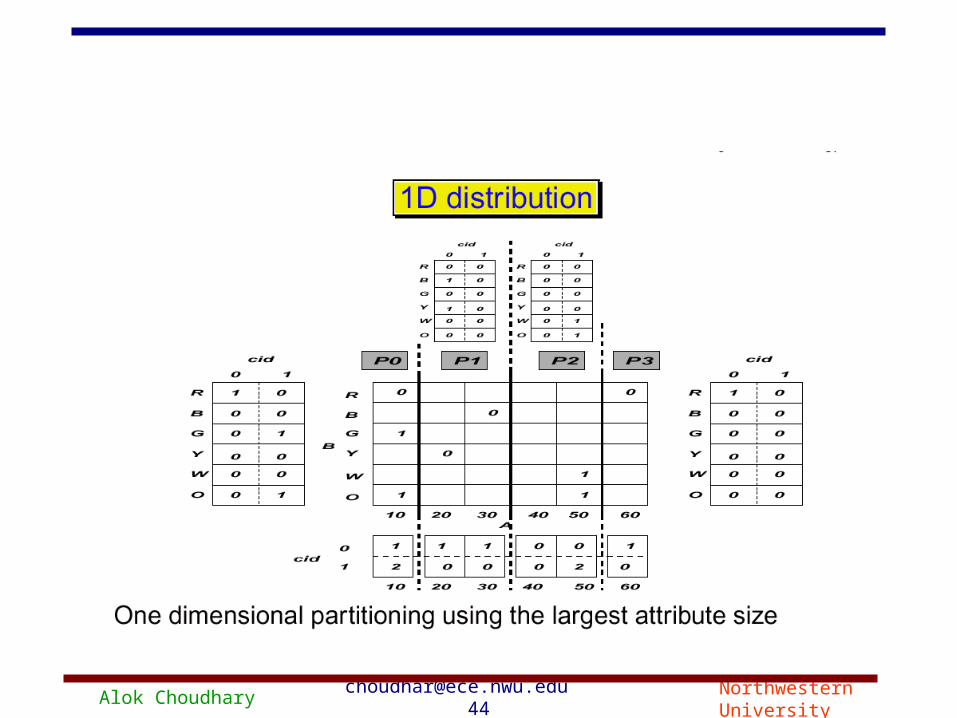
Alok Choudhary [email protected] 44 Northwestern University

Alok Choudhary [email protected] 45 Northwestern University

Alok Choudhary [email protected] 46 Northwestern University

Alok Choudhary [email protected] 47 Northwestern University