persistent autonomous flightnicholas lawrance reinforcement learning for soaring cdmrg – 24 may...
Post on 21-Dec-2015
233 views
TRANSCRIPT

Persistent Autonomous FlightNicholas Lawrance
Reinforcement Learning for Soaring
CDMRG – 24 May 2010
Nick Lawrance

Persistent Autonomous FlightNicholas Lawrance
Reinforcement Learning for Soaring
• What I want to do• Have a good understanding of the
dynamics involved in aerodynamic soaring in known conditions but:1. Dynamic soaring requires energy loss
actions for net energy gain cycles which can be difficult using traditional control or path generation methods
2. Wind is difficult to predict; guidance and nav must be done on-line whilst simultaneously maintaining reasonable energy levels and safety requirements
3. Classic exploration-exploitation problem with the added catch that exploration requires energy gained through exploitation

Persistent Autonomous FlightNicholas Lawrance

Persistent Autonomous FlightNicholas Lawrance
Reinforcement Learning for Soaring
• Why reinforcement learning• Previous work focused on understanding
soaring and examining alternatives for generating energy-gain paths.
• Always have the issue of balancing exploration and exploitation, my code ended up being long sequences of heuristic rules
• Reinforcement learning could provide the link from known good paths towards optimal paths

Persistent Autonomous FlightNicholas Lawrance
Monte Carlo, TD, Sarsa & Q-learning
• Monte Carlo – Learn an average reward for actions taken during series of episodes
• Temporal Difference – Simultaneously estimate expected reward and value function
• Sarsa – using TD for on-policy control
• Q-learning – off-policy TD control
•
Persistent Autonomous FlightNicholas Lawrance
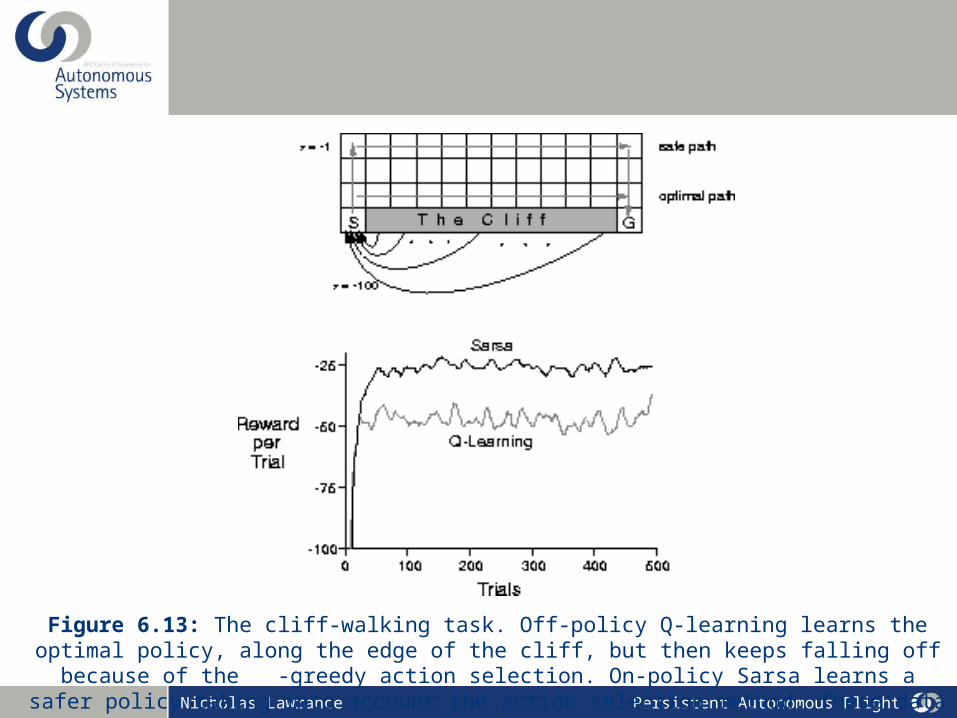
Figure 6.13: The cliff-walking task. Off-policy Q-learning learns the optimal policy, along the edge of the cliff, but then keeps falling off because of the -greedy action selection. On-policy Sarsa learns a safer policy taking into account the action selection method. These data are from a single run, but smoothed.

Persistent Autonomous FlightNicholas Lawrance
Eligibility Traces
• TD(0) is effectively one-step backup of Vπ
(reward only counts to previous action)
• Eligibility traces extend this to reward the sequence of actions that lead to the current reward.

Persistent Autonomous FlightNicholas Lawrance
Sarsa(λ)
• Initialize Q(s,a) arbitrarily and e(s,a) = 0, for all s, a• Repeat (for each episode):
• Initialize s, a • Repeat (for each step of episode):
• Take action a, observe r, s’• Choose a’ from s’ using policy derived from Q (ε-
greedy)
• For all s,a:
• until s is terminal

Persistent Autonomous FlightNicholas Lawrance
Sarsa(λ)

Persistent Autonomous FlightNicholas Lawrance
Simplest soaring attempt
• Square grid, simple motion, energy sinks and sources
• Movement cost, turn cost, edge cost

Persistent Autonomous FlightNicholas Lawrance
Simulation - Static
5 10 15 20 25 30
5
10
15
20
25
30
-1.5
-1
-0.5
0
0.5
1
0
10
20
30
0
10
20
30-5000
0
5000
10000
15000
20000
1000 2000 3000 4000 5000 6000 7000 8000 9000 10000-0.5
0
0.5
1
1.5
2
Persistent Autonomous FlightNicholas Lawrance
1000 2000 3000 4000 5000 6000 7000 8000 9000 10000-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5
3
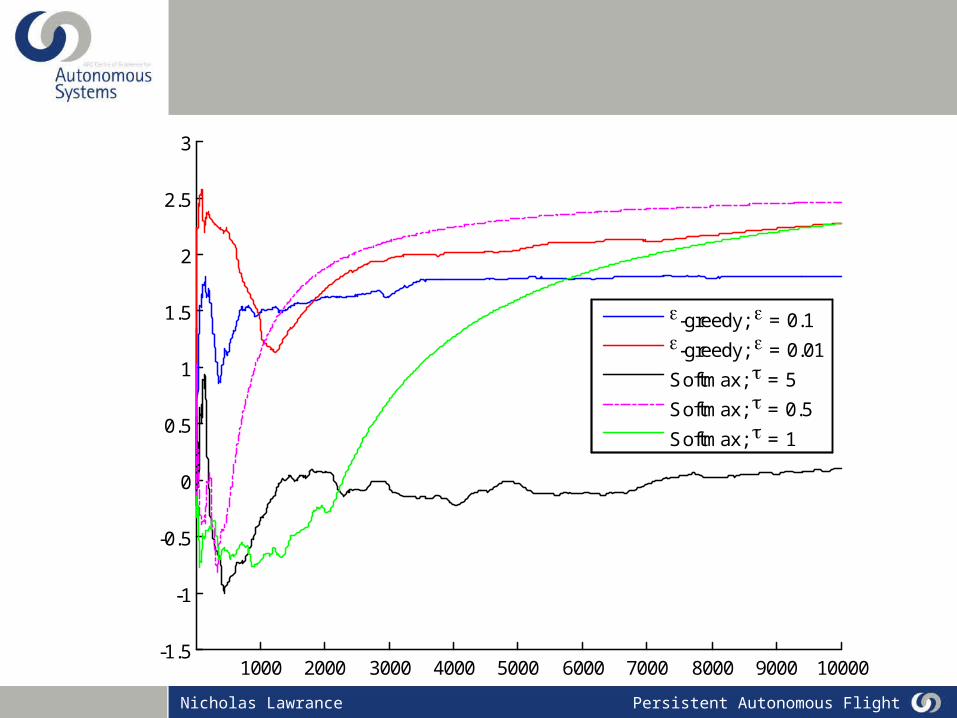
-greedy; = 0.1-greedy; = 0.01
Softmax; = 5
Softmax; = 0.5
Softmax; = 1
Persistent Autonomous FlightNicholas Lawrance
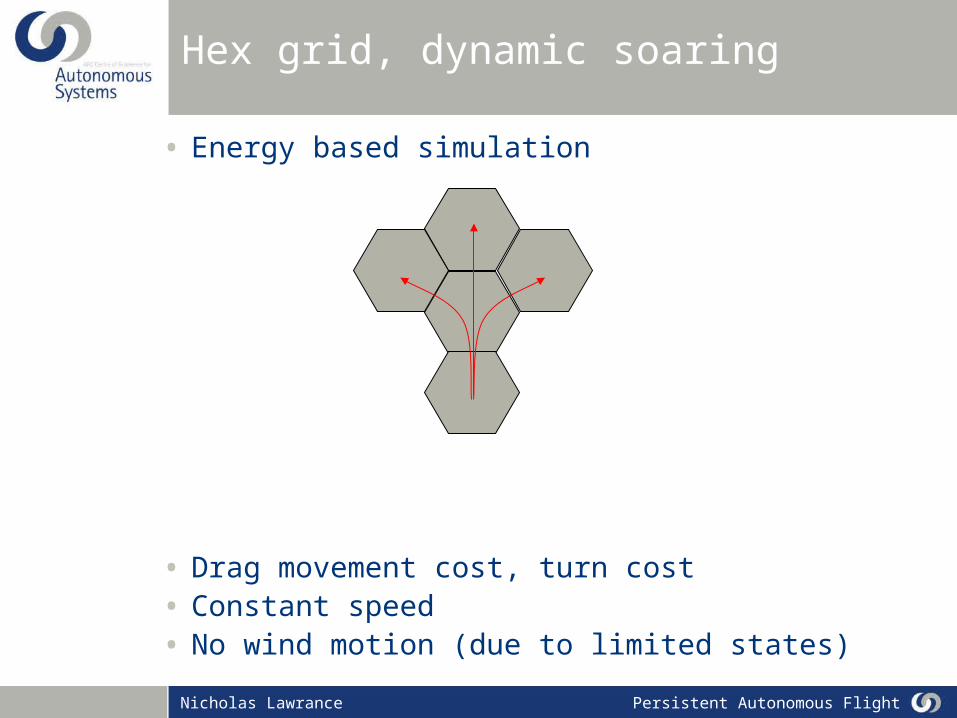
Hex grid, dynamic soaring
• Energy based simulation
• Drag movement cost, turn cost• Constant speed• No wind motion (due to limited states)

Persistent Autonomous FlightNicholas Lawrance
Hex grid, dynamic soaring
0 5 10 15 20 25
5
10
15
20
25
30
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 2 3 4 5 6 7 8 9 10
x 104
-1000
-800
-600
-400
-200
0
200
400
Time step (t = 1s)
Ave
rage
rew
ard
(W)
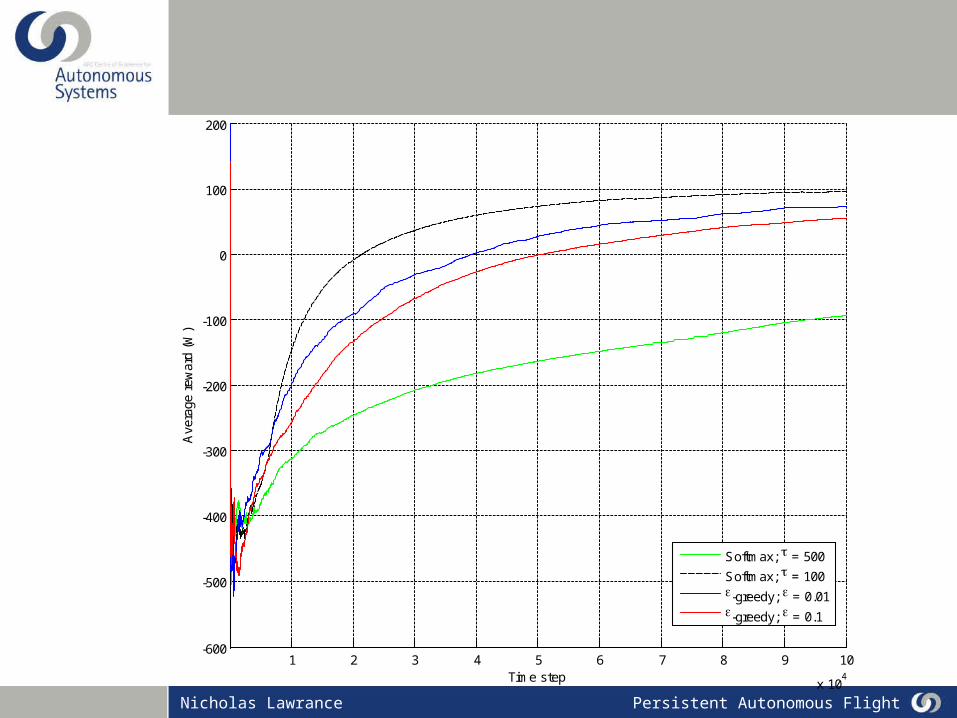
Softmax; = 50
Softmax; = 500-greedy; = 0.01

Persistent Autonomous FlightNicholas Lawrance
5 10 15 20 25
5
10
15
20
25
30
-150
-100
-50
0
50
100
Persistent Autonomous FlightNicholas Lawrance
1 2 3 4 5 6 7 8 9 10
x 104
-600
-500
-400
-300
-200
-100
0
100
200
Time step
Ave
rage
rew
ard
(W)
Softmax; = 500
Softmax; = 100-greedy; = 0.01-greedy; = 0.1

Persistent Autonomous FlightNicholas Lawrance
5 10 15 20 25
5
10
15
20
25
30
-150
-100
-50
0
50
100

Persistent Autonomous FlightNicholas Lawrance
1 2 3 4 5 6 7 8 9 10
x 104
-140
-120
-100
-80
-60
-40
-20
0
20
40
60
Time step (t = 1s)
Ave
rage
rew
ard
(W)
Softmax; = 100
Softmax; = 500-greedy; = 0.01-greedy; = 0.1

Persistent Autonomous FlightNicholas Lawrance
Next
• Reinforcement learning has advantages to offer our group, but our contribution should probably be focused in well defined areas
• For most of our problems, the state spaces are very large and usually continuous; we need estimation methods
• We usually have a good understanding of at least some aspects of the problem; how can/should we use this information to give better solutions?