piglet - arxiv
TRANSCRIPT

PIGLeT:Language Grounding Through Neuro-Symbolic Interaction in a 3D World
Rowan Zellers♠ Ari Holtzman♠ Matthew Peters♥Roozbeh Mottaghi♥ Aniruddha Kembhavi♥ Ali Farhadi♠ Yejin Choi♠♥
♠Paul G. Allen School of Computer Science & Engineering, University of Washington♥Allen Institute for Artificial Intelligence
https://rowanzellers.com/piglet
Abstract
We propose PIGLeT: a model that learns phys-ical commonsense knowledge through interac-tion, and then uses this knowledge to groundlanguage. We factorize PIGLeT into a physi-cal dynamics model, and a separate languagemodel. Our dynamics model learns not justwhat objects are but also what they do: glasscups break when thrown, plastic ones don’t.We then use it as the interface to our languagemodel, giving us a unified model of linguis-tic form and grounded meaning. PIGLeT canread a sentence, simulate neurally what mighthappen next, and then communicate that re-sult through a literal symbolic representation,or natural language.
Experimental results show that our model ef-fectively learns world dynamics, along withhow to communicate them. It is able to cor-rectly forecast “what happens next” given anEnglish sentence over 80% of the time, outper-forming a 100x larger, text-to-text approach byover 10%. Likewise, its natural language sum-maries of physical interactions are also judgedby humans as more accurate than LM alter-natives. We present comprehensive analysisshowing room for future work.
1 Introduction
As humans, our use of language is linked to thephysical world. To process a sentence like “therobot turns on the stove, with a pan on it” (Figure 1)we might imagine a physical Pan object. Thismeaning representation in our heads can be seenas a part of our commonsense world knowledge,about what a Pan is and does. We might reasonablypredict that the Pan will become Hot – and ifthere’s an Egg on it, it would become Cooked .
As humans, we learn such a commonsense worldmodel through interaction. Young children learnto reason physically about basic objects by manip-ulating them: observing the properties they have,
Language ModelPIGLeT
t t+1
The robot turns on the stove, with a pan on it.
isBroken: True
isCooked: False
Temperature: RoomTemp
Name: Egg
...
isBroken: True
isCooked: True
Temperature: Hot
Name: Egg
...
<heatUp, Pan>
Physical Dynamics Model
The pan is now hot and the egg becomes cooked.
Figure 1: PIGLeT. Through physical interaction in a 3Dworld, we learn a model for what actions do to objects.We use our physical model as an interface for a lan-guage model, jointly modeling elements of languageform and meaning. Given an action expressed symbol-ically or in English, PIGLeT can simulate what mighthappen next, expressing it symbolically or in English.
and how they change if an action is applied onthem (Smith and Gasser, 2005). This process ishypothesized to be crucial to how children learnlanguage: the names of these elementary objectsbecome their first “real words” upon which otherlanguage is scaffolded (Yu and Smith, 2012).
In contrast, the dominant paradigm today is totrain large language or vision models on staticdata, such as language and photos from the web.Yet such a setting is fundamentally limiting, assuggested empirically by psychologists’ failed at-tempts to get kittens to learn passively (Held andHein, 1963). More recently, though large Trans-formers have made initial progress on benchmarks,they also have frequently revealed biases in thosesame datasets, suggesting they might not be solv-ing underlying tasks (Zellers et al., 2019b). Thishas been argued philosophically by a flurry of re-
1
arX
iv:2
106.
0018
8v2
[cs
.CL
] 3
0 Ja
n 20
22

The robot throws the vase onto the coffee
table.The robot is holding a vase, and there is a laptop on the coffee table that is on.
The laptop and the vase both break, with the vase shattering into smaller pieces, and the laptop powers off.
isTurnedOn: TrueisTurnedOn: False
Size: mediumisBroken: False
isPickedUp: True
Size: mediumName: Vase Name: Laptop
isBroken: FalseisPickedUp: False
Thro
w o
bjec
t X a
t Y:
<throwHeldObjectAt, laptop>
isTurnedOn: FalseisTurnedOn: False
Size: mediumisBroken: False
isPickedUp: False
Size: mediumName: Vase Name: Laptop
isBroken: TrueisPickedUp: False
......
Figure 2: PIGPeN, a setting for few-shot language-world grounding. We collect data for 280k physical interactionsin THOR, a 3D simulator with 20 actions and 125 object types, each with 42 attributes (e.g. isBroken). We annotate2k interactions with English sentences describing the initial world state, the action, and the action result.
cent work arguing that no amount of language formcould ever specify language meaning (McClellandet al., 2019; Bender and Koller, 2020; Bisk et al.,2020); connecting back to the Symbol GroundingProblem of Harnad (1990).
In this paper, we investigate an alternate strategyfor learning physical commonsense through inter-action, and then transferring that into language.We introduce a model named PIGLeT, short forPhysical Interaction as Grounding for LanguageTransformers. We factorize an embodied agent intoan explicit model of world dynamics, and a modelof language form. We learn the dynamics modelthrough interaction. Given an action heatUp ap-plied to the Pan in Figure 1, the model learns thatthe Egg on the pan becomes Hot and Cooked , andthat other attributes do not change.
We integrate our dynamics model with a pre-trained language model, giving us a joint modelof linguistic form and meaning. The combinedPIGLeT can then reason about the physical dynam-ics implied by English sentences describing actions,predicting literally what might happen next. It canthen communicate that result either symbolicallyor through natural language, generating a sentencelike ‘The egg becomes hot and cooked.” Our sep-aration between physical dynamics and languageallows the model to learn about physical common-sense from the physical world itself, while alsoavoiding recurring problems of artifacts and biasesthat arise when we try to model physical worldunderstanding solely through language.
We study this through a new environment andevaluation setup called PIGPeN, short for PhysicalInteraction Grounding Paired with Natural Lan-guage. In PIGPeN, a model is given unlimited ac-cess to an environment for pretraining, but only 500examples with paired English annotations. Modelsin our setup must additionally generalize to novel‘unseen’ objects for which we intentionally do notprovide paired language-environment supervision.We build this on top of the THOR environment
(Kolve et al., 2017), a physics engine that enablesagents to perform contextual interactions (Fig 2)on everyday objects.
Experiments confirm that PIGLeT performs wellat grounding language with meaning. Given a sen-tence describing an action, our model predicts theresulting object states correctly over 80% of thetime, outperforming even a 100x larger model (T5-11B) by over 10%. Likewise, its generated naturallanguage is rated by humans as being more correctthan equivalently-sized language models. Last, itcan generalize in a ‘zero-shot’ way to objects thatit has never read about before in language.
In summary, we make three key contributions.First, we introduce PIGLeT, a model decouplingphysical and linguistic reasoning. Second, we in-troduce PIGPeN, to learn and evaluate the transferof physical knowledge to the world of language.Third, we perform experiments and analysis sug-gesting promising avenues for future work.
2 PIGPeN: A Resource forNeuro-Symbolic Language Grounding
We introduce PIGPeN as a setting for learning andevaluating physically grounded language under-standing. An overview is shown in Figure 2. Theidea is that an agent gets access to an interactive3D environment, where it can learn about the worldthrough interaction – for example, that objects suchas a Vase can become Broken if thrown. The goalfor a model is to learn natural language meaninggrounded in these interactions.
Task definition. Through interaction, an agentobserves the interplay between objects o ∈ O (rep-resented by their attributes) and actions a ∈ Athrough the following transition:
{o1, . . . ,oN}︸ ︷︷ ︸~o, state pre-action
×a→ {o′1, . . . ,o′N}︸ ︷︷ ︸~o′, state post-action
. (1)
Actions change the state of a subset of objects:turning on a Faucet affects a nearby Sink , but itwill not change a Mirror on the wall.
2

To encourage learning from interaction, and notjust language, an agent is given a small numberof natural language annotations of transitions. Wedenote these sentences as s~o, describing the statepre-action, sa the action, and s~o′ the state post-action respectively. During evaluation, an agentwill sometimes encounter new objects o that werenot part of the paired training data.
We evaluate the model’s transfer in two ways:a. PIGPeN-NLU. A model is given object states
~o, and an English sentence sa describing an ac-tion. It must predict the grounded object states~o′ that result after the action is taken.
b. PIGPeN-NLG. A model is given object states~o and a literal action a. It must generate asentence s~o′ describing the state post-action.
We next describe our environment, feature rep-resentation, and language annotation process.
2.1 Environment: THOR
We use AI2-THOR as an environment for this task(Kolve et al., 2017). In THOR, a robotic agentcan navigate around and perform rich contextualinteractions with objects in a house. For instance,it can grab an Apple , slice it, put it in a Fridge ,drop it, and so on. The state of the Apple , such aswhether it is sliced or cold, changes accordingly;this is not possible in many other environments.
In this work, we use the underlying THOR sim-ulator as a proxy for grounded meaning. WithinTHOR, it can be seen as a ‘complete’ meaning rep-resentation (Artzi et al., 2013), as it fully specifiesthe kind of grounding a model can expect in itsperception within THOR.
Objects. The underlying THOR representationof each object o is in terms of 42 attributes; we pro-vide a list in Appendix B. We treat these attributesas words specific to an attribute-level dictionary;for example, the temperature Hot is one of threepossible values for an object’s temperature; theothers being Cold and RoomTemp .
Actions. An action a in THOR is a function thattakes up to two objects as arguments. Actions arehighly contextual, affecting not only the argumentsbut potentially other objects in the scene (Figure 2).We also treat action names as words in a dictionary.
Filtering out background objects. Most ac-tions change the state of only a few objects, yetthere can be many objects in a scene. We keep an-notation and computation tractable by having mod-els predict (and humans annotate) possible changes
of at most two key objects in the scene. As knowingwhen an object doesn’t change is also important,we include non-changing objects if fewer than twochange.
Exploration. Any way of exploring the environ-ment is valid for our task, however, we found thatexploring intentionally was needed to yield goodcoverage of interesting states. Similar to prior workfor instruction following (Shridhar et al., 2020), wedesigned an oracle to collect diverse and interest-ing trajectories {~o,a, ~o′}. Our oracle randomlyselects one of ten high level tasks, see Appendix Bfor the list. These in turn require randomly choos-ing objects in the scene; e.g. a Vase and a Laptopin Figure 2. We randomize the manner in whichthe oracle performs the task to discover diversesituations.
In total, we sampled 20k trajectories. From thesewe extracted 280k transitions (Eqn 1’s) where atleast one object changes state, for training.
2.2 Annotating Interactions with Language
2.2.1 Data Selection for AnnotationWe select 2k action state-changes from trajectoriesheld out from the training set. We select them whilealso balancing the distribution of action types toensure broad coverage in the final dataset. We arealso interested in a model’s ability to generalize tonew object categories – beyond what it has readabout, or observed in a training set. We thus se-lect 30 objects to be “unseen,” and exclude thesefrom paired environment-language training data.We sample 500 state transitions, containing only“seen” objects to be the training set; we use 500 forvalidation and 1000 for testing.
2.2.2 Natural Language AnnotationWorkers on Mechanical Turk were shown an envi-ronment in THOR before and after a given actiona. Each view contains the THOR attributes of thetwo key objects. Workers then wrote three En-glish sentences, corresponding to s~o, sa, and s~o′
respectively. Workers were instructed to write at aparticular level of detail: enough so that a readercould infer “what happens next” from s~o and sa,yet without mentioning redundant attributes.Weprovide more details in Appendix C.
3 Modeling PIGLeT
In this section, we describe our PIGLeT model.First, we learn a neural physical dynamics model
3

The robot is holding a glass vase.
The robot throws the vase.
Language Model
Size: medium
isPickedUp: True
isTurnedOn: False
isBroken: False
Name: Vase
ObjectEncoder
Action: ThrowHeldObjectAt
Target: Floor
ActionEncoder
Action Application
...... Object
Decoder
Size: medium
isPickedUp: False
isTurnedOn: False
isBroken: True
Name: Vase
~o<latexit sha1_base64="Tk3HXnFVIrKVryije/QEdnLVRCo=">AAADMHicfVJLb9NAEN66BVrzSoEbF4sICXGI7IIExwo4cEEUibSV4igabybOKvuwZtelqeX/0isc+TVwQr3yK9gkPuCEMtJqvv3mubOTFVJYF8c/t4LtnRs3b+3uhbfv3L13v7P/4Niakjj2uZGGTjOwKIXGvhNO4mlBCCqTeJLN3i7sJ2dIVhj92c0LHCrItZgIDs5To86j9Ax5lWZGju1ceVWZuh51unEvXkq0CZIGdFkjR6P9YCcdG14q1I5LsHaQxIUbVkBOcIl1mJYWC+AzyHHgoQaFdlgt26+jp54ZRxND/mgXLdm/IypQdtGc91TgpnbdtiD/ZRuUbvJ6WAldlA41XxWalDJyJlrMIhoLQu7k3APgJHyvEZ8CAXd+Yq0qqpROkPnSeknFQfI2kxMUU8HP2yyhtOKiPYZrUpJx/md03mYz1b6XJNeSGcLNEpkxMweZvbbwO/S/RfjBT+5jgQTO0PMqBcoVnNdVo//nJvTKzeswDP3eJOtbsgmOD3rJi1786WX38E2zQbvsMXvCnrGEvWKH7D07Yn3G2QW7ZF/Zt+B78CP4FVytXIOtJuYha0nw+w/LmQ/3</latexit> ~o0
<latexit sha1_base64="dSJfxBPnRwowtpN8zynXN7N+BKY=">AAADMXicfVJLb9NAEN6aAsW8UhAnLhYRAnGI7IIExwo4cEEUibSV4igabybJKvuwZtelYeUfwxWO/JreEFf+BJvEB5xQRlrNt988d3aKUgrr0vRiJ7qye/Xa9b0b8c1bt+/c7ezfO7amIo59bqSh0wIsSqGx74STeFoSgioknhTzN0v7yRmSFUZ/cosShwqmWkwEBxeoUedBfobc54WRY7tQQXlT109GnW7aS1eSbIOsAV3WyNFoP9rNx4ZXCrXjEqwdZGnphh7ICS6xjvPKYgl8DlMcBKhBoR36Vf918jgw42RiKBztkhX7d4QHZZfdBU8FbmY3bUvyX7ZB5Savhl7osnKo+brQpJKJM8lyGMlYEHInFwEAJxF6TfgMCLgLI2tVUZV0gszn1ks8B8nbzJSgnAl+3mYJpRVf2mO4JCUZF75GT9tsodr3iuRGMkO4XaIwZu6gsJcWfovhtwjfh8l9KJHAGXrmc6CpgvPaN/p/bkKv3YKO4zjsTba5Jdvg+KCXPe+lH190D183G7THHrJH7CnL2Et2yN6xI9ZnnHn2lX1j36Mf0UX0M/q1do12mpj7rCXR7z9kcRAo</latexit>
a<latexit sha1_base64="elI5FeejPpeM9uUnRf3IQjSevxU=">AAADKHicfVJLb9NAEN6aQot5tXDkYhEhIQ6RTZHgWAEHLogikbZSEqrxZuKssg9rdlwarPwPrnDk13BDvfJL2CQ+4IQy0mq+/ea5s5OXWnlO08ut6Nr29Rs7uzfjW7fv3L23t3//2LuKJPak045Oc/ColcUeK9Z4WhKCyTWe5NPXC/vJOZJXzn7kWYlDA4VVYyWBA/VpkDs98jMTVA3zs71O2k2XkmyCrAEd0cjR2X60PRg5WRm0LDV438/Skoc1ECupcR4PKo8lyCkU2A/QgkE/rJdtz5PHgRklY0fhWE6W7N8RNRi/6C14GuCJX7ctyH/Z+hWPXw5rZcuK0cpVoXGlE3bJYgbJSBFK1rMAQJIKvSZyAgSSw6RaVUylWZH73HpJLUHLNlMQlBMlL9osofbqS3sMV6Qkx+FHbNFmc9O+V6TXkjnCzRK5c1OG3F9Z+A2G3yJ8Fyb3vkQCdvS0HgAVBi7mdaP/56bsyi3oOI7D3mTrW7IJjp91s4Nu+uF55/BVs0G74qF4JJ6ITLwQh+KtOBI9IQWJr+Kb+B79iH5Gv6LLlWu01cQ8EC2Jfv8B/q8M6g==</latexit>
Tenc<latexit sha1_base64="FAlDcCJyxBBe5Frg+r9it6VUkmA=">AAADNXicfVJLb9NAEN6aAsW8UjghLhYREuIQOQUJjhVw4IIoUtNWiqNovRk7q+zDmh1DgmXxa7jCkd/CgRviyl9gnfqAE8pIq/n2m5mdnUdaKOkojr/vBJd2L1+5unctvH7j5q3bvf07J86WKGAkrLJ4lnIHShoYkSQFZwUC16mC03TxsrGfvgd00ppjWhUw0Tw3MpOCk6emvXuJ5jRPs+q4nlYJwZJQV2BEXU97/XgQryXaBsMW9FkrR9P9YDeZWVFqMCQUd248jAuaVBxJCgV1mJQOCi4WPIexh4ZrcJNqXUMdPfTMLMos+mMoWrN/R1RcO7fSqfdsfuw2bQ35L9u4pOz5pJKmKKmpa50oK1VENmoaEs0kgiC18oALlP6vkZhz5IJ82zpZdKlIov3QqaQSXIkukyMv5lIsuyyCcvJjtw0XPImW/HhM3mVT3b2XqDYeswjbKVJrF8RTd2HiV+CnhfDGd+5tAcjJ4uMq4ZhrvqyrVv/PTZpzN6/DMPR7M9zckm1wcjAYPhnE7572D1+0G7TH7rMH7BEbsmfskL1mR2zEBPvEPrMv7GvwLfgR/Ax+nbsGO23MXdaR4PcfWwoSPA==</latexit>
Tdec<latexit sha1_base64="2gP2+xYkdi+qahQkMatfm5CHGxA=">AAADNXicfVLNjtMwEPaGhV3CXxdOiEtEhYQ4VOmCxB5XwIELYpG2uys1VTVxJ6lVO47sCbRYEU/DFY48CwduiCuvgNvmQFqWkSx//uZ/PGkphaU4/r4TXNm9em1v/3p44+at23c6B3fPrK4MxwHXUpuLFCxKUeCABEm8KA2CSiWep7OXS/35ezRW6OKUFiWOFOSFyAQH8tS4cz9RQNM0c6f12CWEczLKTZDX9bjTjXvxSqJt0G9AlzVyMj4IdpOJ5pXCgrgEa4f9uKSRA0OCS6zDpLJYAp9BjkMPC1BoR27VQx098swkyrTxp6Boxf7t4UBZu1Cpt1xWbDd1S/JfumFF2dHIiaKsCAu+TpRVMiIdLQcSTYRBTnLhAXAjfK0Rn4IBTn5srSyqkiSM/tDqxHGQvM3kBsqp4PM2a1Ba8bE9hktCGk3+e4q8zaaq/a6M3AimDW6nSLWeEaT20sSv0P+WwTd+cm9LNEDaPHEJmFzBvHbN/T8zUazN/B2God+b/uaWbIOzw17/aS9+96x7/KLZoH32gD1kj1mfPWfH7DU7YQPG2Sf2mX1hX4NvwY/gZ/BrbRrsND73WEuC338AP8USMg==</latexit>
MLPapply<latexit sha1_base64="zPFXFrp2Awq1em5tGLQOTqO0h4o=">AAADOXicfVJNj9MwEPWGhV3CVxeOCCmiQkIcqmRBYo8r4MCBFUWiuyu1VTVxp6lVO7bsCbREOfFruMKRX8KRG+LKH8Btg0RalpEsP795M2OPJzVSOIrjbzvBpd3LV/b2r4bXrt+4eat1cPvU6cJy7HEttT1PwaEUOfZIkMRzYxFUKvEsnT1f+s/eoXVC529pYXCoIMvFRHAgT41a9waEc7KqPHnVrUblnxMYIxdVNWq14068smgbJDVos9q6o4NgdzDWvFCYE5fgXD+JDQ1LsCS4xCocFA4N8Blk2PcwB4VuWK7eUUUPPDOOJtr6lVO0Yv+OKEE5t1CpVyqgqdv0Lcl/+foFTY6GpchNQZjzdaFJISPS0bIp0VhY5CQXHgC3wt814lOwwMm3rlFFFZKE1e8bLyk5SN5kMgtmKvi8yVqUTnxotuGClFaT/6I8a7Kpap4LKzeSaYvbJVKtZwSpu7DwC/S/ZfHEd+61QQuk7aNyADZTMK/Kev+fTORrmd/DMPRzk2xOyTY4Pewkjzvxmyft42f1BO2zu+w+e8gS9pQds5esy3qMs4/sE/vMvgRfg+/Bj+DnWhrs1DF3WMOCX78ByRUUGw==</latexit>
ha<latexit sha1_base64="IpTzzwZ9IjK0OgGcISMVC68hBQ0=">AAADN3icfVJLb9NAEN66BYp5peXYi0WEhDhENiDBsaI9cEEUibSV4igab8bOKvuwdtdtw8oHfg1XOPJTOHFDXPkHrBMfcEIZaTXffjO788xKzoyN4+9bwfbOjZu3dm+Hd+7eu/+gt7d/alSlKQ6p4kqfZ2CQM4lDyyzH81IjiIzjWTY/auxnF6gNU/KDXZQ4FlBIljMK1lOT3kEqwM6y3M3qiUszxadmIbxyUNeTXj8exEuJNkHSgj5p5WSyF+ykU0UrgdJSDsaMkri0YwfaMsqxDtPKYAl0DgWOPJQg0Izdsoo6euyZaZQr7Y+00ZL9+4UDYZrkvGeTs1m3NeS/bKPK5q/GjsmysijpKlBe8ciqqGlJNGUaqeULD4Bq5nON6Aw0UOsb14kiKm6ZVpedShwFTrtMoaGcMXrVZTVywz5223DNl1pZPyBZdNlMdO+V5mufKY2bITKl5hYyc23gY/TT0vjWd+5diRqs0k9dCroQcFW7Vv/PjcmVm9dhGPq9Sda3ZBOcPhskzwfx+xf9w9ftBu2SA/KIPCEJeUkOyRtyQoaEkk/kM/lCvgbfgh/Bz+DXyjXYat88JB0Jfv8B94ETIg==</latexit>
ho1<latexit sha1_base64="CqR6VsVzGuZlPuXKLqpMZY9btz4=">AAADOXicfVJLj9MwEPaGBZbw6sIRIUVUSIhDlQASHFfAgcuKRaK7KzVVNHEnqVU/ItuBLVZO/BqucOSX7JEb4sofwGlzIC3LSNZ8/mbseeYVZ8bG8flOcGn38pWre9fC6zdu3ro92L9zbFStKY6p4kqf5mCQM4ljyyzH00ojiJzjSb541dpPPqA2TMn3dlnhVEApWcEoWE9lg/upADvPCzdvMpfmis/MUnjlVJMlTTYYxqN4JdE2SDowJJ0cZfvBbjpTtBYoLeVgzCSJKzt1oC2jHJswrQ1WQBdQ4sRDCQLN1K3qaKKHnplFhdL+SBut2L9fOBCmTc97tlmbTVtL/ss2qW3xYuqYrGqLkq4DFTWPrIrapkQzppFavvQAqGY+14jOQQO1vnW9KKLmlmn1sVeJo8Bpnyk1VHNGz/qsRm7Yp34bLvhSK+tHJMs+m4v+vdZ84zOlcTtErtTCQm4uDPwa/bQ0HvrOva1Qg1X6sUtBlwLOGtfp/7kxuXbzOgxDvzfJ5pZsg+Mno+TpKH73bHjwstugPXKPPCCPSEKekwPyhhyRMaHkM/lCvpJvwffgR/Az+LV2DXa6N3dJT4LffwAIhRPU</latexit>
ho2<latexit sha1_base64="QDwIL9dC1n1EUQ5JgckmT4EFRp4=">AAADOXicfVJLj9MwEPaGBZbw6sIRIUVUSIhDlewiwXEFHLggFonurtRU0cSdpFb9iGwHtlg58Wu4wpFfwpEb4sofwGlzIC3LSNZ8/mbseeYVZ8bG8fed4NLu5StX966F12/cvHV7sH/nxKhaUxxTxZU+y8EgZxLHllmOZ5VGEDnH03zxorWfvkdtmJLv7LLCqYBSsoJRsJ7KBvdTAXaeF27eZC7NFZ+ZpfDKqSY7aLLBMB7FK4m2QdKBIenkONsPdtOZorVAaSkHYyZJXNmpA20Z5diEaW2wArqAEiceShBopm5VRxM99MwsKpT2R9poxf79woEwbXres83abNpa8l+2SW2LZ1PHZFVblHQdqKh5ZFXUNiWaMY3U8qUHQDXzuUZ0Dhqo9a3rRRE1t0yrD71KHAVO+0ypoZozet5nNXLDPvbbcMGXWlk/Iln22Vz077XmG58pjdshcqUWFnJzYeCX6Kel8bXv3JsKNVilH7sUdCngvHGd/p8bk2s3r8Mw9HuTbG7JNjg5GCWHo/jtk+HR826D9sg98oA8Igl5So7IK3JMxoSST+Qz+UK+Bt+CH8HP4NfaNdjp3twlPQl+/wELPRPV</latexit>
ho01<latexit sha1_base64="0abHHpkgF29PUVVxn/YJE6aKEYY=">AAADQXicfVLNjtMwEPaGBZbw14Ujl4hqBeJQJQsSHFfAgQtikejuSk0VTdxJatU/ke3AFitPwNNwhSNPwSNwQ1y54LQ5kJZlJGs+fzP2/OYVZ8bG8fed4NLu5StX966F12/cvHV7sH/nxKhaUxxTxZU+y8EgZxLHllmOZ5VGEDnH03zxorWfvkdtmJLv7LLCqYBSsoJRsJ7KBgdROgfrUgF2nhdu3jSZS3PFZ2YpvHIqS5oHTTYYxqN4JdE2SDowJJ0cZ/vBbjpTtBYoLeVgzCSJKzt1oC2jHJswrQ1WQBdQ4sRDCQLN1K3qaaIDz8yiQml/pI1W7N8vHAjT5uc927zNpq0l/2Wb1LZ4NnVMVrVFSdeBippHVkVtc6IZ00gtX3oAVDOfa0TnoIFa38JeFFFzy7T60KvEUeC0z5Qaqjmj531WIzfsY78NF3yplfWjkmWfzUX/Xmu+8ZnSuB0iV2phITcXBn6JfloaX/vOvalQg1X6kUtBlwLOG9fp/7kxuXbzOgxDvzfJ5pZsg5PDUfJ4FL99Mjx63m3QHrlH7pOHJCFPyRF5RY7JmFDyiXwmX8jX4FvwI/gZ/Fq7Bjvdm7ukJ8HvP1cnFvw=</latexit>
ho02<latexit sha1_base64="lCctrn5jUI+pPItihMG7PAcLL3k=">AAADQXicfVLNjtMwEPaGBZbw14Ujl4hqBeJQpQsSHFfAgQtikejuSk0VTdxJYtU/ke3AFitPwNNwhSNPwSNwQ1y54LQ5kJZlJGs+fzP2/GYVZ8bG8fed4NLu5StX966F12/cvHV7sH/nxKhaU5xQxZU+y8AgZxInllmOZ5VGEBnH02zxorWfvkdtmJLv7LLCmYBCspxRsJ5KBwdRUoJ1iQBbZrkrmyZ1Sab43CyFV06lh82DJh0M41G8kmgbjDswJJ0cp/vBbjJXtBYoLeVgzHQcV3bmQFtGOTZhUhusgC6gwKmHEgSamVvV00QHnplHudL+SBut2L9fOBCmzc97tnmbTVtL/ss2rW3+bOaYrGqLkq4D5TWPrIra5kRzppFavvQAqGY+14iWoIFa38JeFFFzy7T60KvEUeC0zxQaqpLR8z6rkRv2sd+GC77UyvpRyaLPZqJ/rzXf+Exp3A6RKbWwkJkLA79EPy2Nr33n3lSowSr9yCWgCwHnjev0/9yYXLt5HYah35vx5pZsg5PD0fjxKH77ZHj0vNugPXKP3CcPyZg8JUfkFTkmE0LJJ/KZfCFfg2/Bj+Bn8GvtGux0b+6SngS//wBZ4Rb9</latexit>
sa<latexit sha1_base64="LeR1JAfP96tE2MTQrXBVv0E7xEo=">AAADO3icfVI7bxNBEN4cAcLxcqCk4ISFhCisu4AEZQQUNIgg4SSSbVlz6/F55X2cducgZnUlv4YWSn4INR2ipWdtX5GzCSOt5ttvZnYeO3kphaM0/bETXdq9fOXq3rX4+o2bt2539u8cO1NZjn1upLGnOTiUQmOfBEk8LS2CyiWe5POXS/vJB7ROGP2eFiWOFBRaTAUHCtS4c3+YGzlxCxWUd/XYn79DXY873bSXriTZBlkDuqyRo/F+tDucGF4p1MQlODfI0pJGHiwJLrGOh5XDEvgcChwEqEGhG/lVJ3XyMDCTZGpsOJqSFXs+woNyy+KCpwKauU3bkvyXbVDR9PnIC11WhJqvE00rmZBJlmNJJsIiJ7kIALgVodaEz8ACpzC8VhZVSRLWfGx14jlI3mYKC+VM8LM2a1E68ak9hguetIbCJ+mizeaqfa+s3HjMWNxOkRszJ8jdhYlfYfgti2/C5N6WaIGMfeyHYAsFZ7Vv9P/chF67BR3HcdibbHNLtsHxQS970kvfPe0evmg2aI/dYw/YI5axZ+yQvWZHrM84+8y+sK/sW/Q9+hn9in6vXaOdJuYua0n05y+veRUa</latexit> TLM
<latexit sha1_base64="bWXv2O8NNh4H6P1ViAQ01k2Mz6E=">AAADK3icfVJLb9NAEN6aAsU8mpYjF4sICXGIbECCYwU9cKCilZq2UhJF483YWWUf1u4YGiz/Eq5w5NdwAnHlf3ST+IATykir+fab585OWkjhKI5/bgU3tm/eur1zJ7x77/6D3c7e/pkzpeXY50Yae5GCQyk09kmQxIvCIqhU4nk6e7uwn39E64TRpzQvcKQg1yITHMhT487uUAFN06w6rcfV+6N63OnGvXgp0SZIGtBljRyP94Lt4cTwUqEmLsG5QRIXNKrAkuAS63BYOiyAzyDHgYcaFLpRtey8jp54ZhJlxvqjKVqyf0dUoJybq9R7Lvp067YF+S/boKTs9agSuigJNV8VykoZkYkWY4gmwiInOfcAuBW+14hPwQInP6xWFVVKEtZ8ar2k4iB5m8ktFFPBL9usRenE5/YYrklpDflP0XmbTVX7Xlq5lsxY3CyRGjMjSN21hQ/R/5bFIz+5DwVaIGOfVUOwuYLLumr0/9yEXrl5HYah35tkfUs2wdnzXvKiF5+87B68aTZohz1ij9lTlrBX7IC9Y8eszzgr2Rf2lX0Lvgc/gl/B75VrsNXEPGQtCf5cARg6DUM=</latexit>
Language Model
TLM<latexit sha1_base64="bWXv2O8NNh4H6P1ViAQ01k2Mz6E=">AAADK3icfVJLb9NAEN6aAsU8mpYjF4sICXGIbECCYwU9cKCilZq2UhJF483YWWUf1u4YGiz/Eq5w5NdwAnHlf3ST+IATykir+fab585OWkjhKI5/bgU3tm/eur1zJ7x77/6D3c7e/pkzpeXY50Yae5GCQyk09kmQxIvCIqhU4nk6e7uwn39E64TRpzQvcKQg1yITHMhT487uUAFN06w6rcfV+6N63OnGvXgp0SZIGtBljRyP94Lt4cTwUqEmLsG5QRIXNKrAkuAS63BYOiyAzyDHgYcaFLpRtey8jp54ZhJlxvqjKVqyf0dUoJybq9R7Lvp067YF+S/boKTs9agSuigJNV8VykoZkYkWY4gmwiInOfcAuBW+14hPwQInP6xWFVVKEtZ8ar2k4iB5m8ktFFPBL9usRenE5/YYrklpDflP0XmbTVX7Xlq5lsxY3CyRGjMjSN21hQ/R/5bFIz+5DwVaIGOfVUOwuYLLumr0/9yEXrl5HYah35tkfUs2wdnzXvKiF5+87B68aTZohz1ij9lTlrBX7IC9Y8eszzgr2Rf2lX0Lvgc/gl/B75VrsNXEPGQtCf5cARg6DUM=</latexit>
The vase breaks and is no longer being held.
Action Summarizer
MLP�<latexit sha1_base64="J5yL7sR91yRU8/LfFSoplTfAVlE=">AAADMXicfVJLb9NAEN6aAsW8UhAnLhYREuIQ2YAExwp64EBFkEhbKY6i8WbirLIPa3cMCZZ/DFc48mt6Q1z5E2wSH3BCGWk1337z3NnJCikcxfHFXnBl/+q16wc3wpu3bt+52zm8d+pMaTkOuJHGnmfgUAqNAxIk8bywCCqTeJbN36zsZ5/QOmH0R1oWOFKQazEVHMhT486DlHBBVlUn7/r1uEqPURLU40437sVriXZB0oAua6Q/Pgz204nhpUJNXIJzwyQuaFSBJcEl1mFaOiyAzyHHoYcaFLpRte6/jh57ZhJNjfVHU7Rm/46oQDm3VJn3VEAzt21bkf+yDUuavhpVQhcloeabQtNSRmSi1TCiibDISS49AG6F7zXiM7DAyY+sVUWVkoQ1n1svqThI3mZyC8VM8EWbtSid+NIewyUprSH/NTpvs5lq30srt5IZi7slMmPmBJm7tPAx+t+yeOIn975AC2Ts0yoFmytY1FWj/+cm9MbN6zAM/d4k21uyC06f9ZLnvfjDi+7R62aDDthD9og9YQl7yY7YW9ZnA8ZZxb6yb+x78CO4CH4GvzauwV4Tc5+1JPj9B9KOD/M=</latexit>
s~o0<latexit sha1_base64="99UQbAsrvAY02F4vviNX5hJslv0=">AAADQnicfVLNbhMxEHaXAmX5S+HIZUXEjzhEuwWpPVbAgQuiSKStlI2iWWeyseK1V/ZsabD2DXgarnDkJXgFbogrB5xkD92EMpI1n7/59XiyUgpLcfxjK7iyffXa9Z0b4c1bt+/c7ezeO7a6Mhz7XEttTjOwKIXCPgmSeFoahCKTeJLNXi3sJ2dorNDqA81LHBaQKzERHMhTo87jNNNybOeFV87WI5eeIXcXSV3XT+pRpxv34qVEmyBpQJc1cjTaDbbTseZVgYq4BGsHSVzS0IEhwSXWYVpZLIHPIMeBhwoKtEO3fFAdPfLMOJpo44+iaMlejHBQ2EV73rMAmtp124L8l21Q0eRg6IQqK0LFV4UmlYxIR4vpRGNhkJOcewDcCN9rxKdggJOfYatKUUkSRn9svcRxkLzN5AbKqeDnbdagtOJTewyXpDSa/F+pvM1mRfteGbmWTBvcLJFpPSPI7KWFX6P/LYNv/eTelWiAtHnmUjB5Aee1a/T/3IRauXkdhqHfm2R9SzbB8V4ved6L37/oHr5sNmiHPWAP2VOWsH12yN6wI9ZnnH1mX9hX9i34HvwMfgW/V67BVhNzn7Uk+PMXrAYYJw==</latexit>
Figure 3: PIGLeT architecture. We pretrain a model of physical world dynamics by learning to transform objects ~oand actions a into new updated objects ~o′. Our underlying world dynamics model – the encoder, the decoder, andthe action application module, can augment a language model with grounded commonsense knowledge.
from interactions, and second, integrate with a pre-trained model of language form.
3.1 Modeling Physical Dynamics
We take a neural, auto-encoder style approach tomodel world dynamics. An object o gets encodedas a vector ho ∈ Rdo . The model likewise encodesan action a as a vector ha ∈ Rda , using it to ma-nipulate the hidden states of all objects. The modelcan then decode any object hidden representationback into a symbolic form.
3.1.1 Object Encoder and Decoder
We use a Transformer (Vaswani et al., 2017) toencode objects into vectors o ∈ Rdo , and thenanother to decode from this representation.
Encoder. Objects o are provided to the encoderas a set of attributes, with categories c1,..., cn. Eachattribute c has its own vocabulary and embeddingEc. For each object o, we first embed all the at-tributes separately and feed the result into a Trans-former encoder Tenc. This gives us (with positionembeddings omitted for clarity):
ho = Tenc
(E1(o1), . . . ,Ecn(ocn)
)(2)
Decoder. We can then convert back into the origi-nal symbolic representation through a left-to-rightTransformer decoder, which predicts attributes one-by-one from c1 to cn. This captures the inherentcorrelation between attributes, while making no in-dependence assumptions, we discuss our orderingin Appendix A.2. The probability of predicting thenext attribute oci+1 is then given by:
p(oci+1|ho,o:ci)=Tdec
(ho,E1(o1),...,Eci(oci)
)(3)
3.1.2 Modeling actions as functions
We treat actions a as functions that transform thestate of all objects in the scene. Actions in ourenvironment take at most two arguments, so weembed the action a and the names of its arguments,concatenate them, and pass the result through amultilayer perceptron; yielding a vector representa-tion ha.
Applying Actions. We use the encoded actionha to transform all objects in the scene, obtainingupdated representations ho′ for each one. We takea global approach, jointly transforming all objects.This takes into account that interactions are contex-tual: turning on a Faucet might fill up a Cup ifand only if there is one beneath it.
Letting the observed objects in the interactionbe o1 and o2, with encodings ho1 and ho2 respec-tively, we model the transformation via the follow-ing multilayer perceptron:
[ho′1, ho′
2] = MLPapply
([ha,ho1 ,ho2
]). (4)
The result can be decoded into symbolic formusing the object decoder (Equation 3).
3.1.3 Loss function and training
We train our dynamics model on (~o,a,~o′) transi-tions. The model primarily learns by running ~o,athrough the model, predicting the updated outputstate ho′ , and minimizing the cross-entropy of gen-erating attributes of the real changed object ~o′. Wealso regularize the model by encoding objects ~o, ~o′
and having the model learn to reconstruct them. Weweight all these cross-entropy losses equally. Wediscuss our architecture in Appendix A.1; it uses3-layer Transformers, totalling 17M parameters.
4

3.2 Language Grounding
After pretraining our physical dynamics model, weintegrate it with a Transformer Language Model(LM). In our framework, the role of the LM willbe to both encode natural language sentences ofactions into a hidden state approximating ha, aswell as summarizing the result of an interaction(~o,a,~o′) in natural language.
Choice of LM. Our framework is compatiblewith any language model. However, to explore theimpact of pretraining data on grounding later inthis paper, we pretrain our own with an identicalarchitecture to the smallest GPT2 (Radford et al.(2019); 117M). To handle both classification andgeneration well, we mask only part of the attentionweights out, allowing the model to encode a “prefix”bidirectionally; it generates subsequent tokens left-to-right (Dong et al., 2019). We pretrain the modelon Wikipedia and books; details in Appendix D.
We next discuss architectural details of perform-ing the language transfer, along with optimization.
3.2.1 Transfer ArchitectureEnglish actions to vector form. Given a natu-ral language description sa of an action a, like“The robot throws the vase,” for PIGPeN-NLU, ourmodel will learn to parse this sentence into a neuralrepresentation ha, so the dynamics model can sim-ulate the result. We do this by encoding sa throughour language model, TLM , with a learned lineartransformation over the resulting (bidirectional) en-coding. The resulting vector hsa can then be usedby Equation 4.
Summarizing the result of an action. ForPIGPeN-NLG, our model simulates the result of anaction a neurally, resulting in a predicted hiddenstate ho for each object in the scene o. To writean English summary describing “what changed,”we first learn a lightweight fused representationof the transition, aggregating the initial and finalstates, along with the action, through a multilayerperceptron. For each object oi we have:
h∆oi = MLP∆([hoi , ho′i,ha]). (5)
We then use the sequence [h∆o1 ,h∆o2 ] as bidi-rectional context for our our LM to decode from.Additionally, since our test set includes novel ob-jects not seen in training, we provide the names ofthe objects as additional context for the LM genera-tor (e.g. ‘Vase, Laptop’); this allows a LM to copythose names over rather than hallucinate wrong
ones. Importantly we only provide the surface-form names, not underlying information aboutthese objects or their usage as with few-shot scenar-ios in the recent GPT-3 experiments (Brown et al.,2020) – necessitating that PIGLeT learns what thesenames mean through interaction.
3.2.2 Loss functions and training.Modeling text generation allows us to incorporatea new loss function, that of minimizing the log-likelihood of generating each s~o′ given previouswords and the result of Equation 5:
p(sposti+1|s~o′,1:i
) = TLM(h∆o1 ,h∆o2 , s~o′,1:i). (6)
We do the same for the object states s~o pre-action,using hoi as the corresponding hidden states.
For PIGPeN-NLU, where no generation isneeded, optimizing Equation 5 is not strictly nec-essary. However, as we will show later, it helpsprovide additional signal to the model, improvingoverall accuracy by several percentage points.
4 ExperimentsWe test our model’s ability to encode language intoa grounded form (PIGPeN-NLU), and decode thatgrounded form into language (PIGPeN-NLG).
4.1 PIGPeN-NLU Results.We first evaluate models by their performance onPIGPeN-NLU: given objects ~o, and a sentence sadescribing an action, a model must predict the re-sulting state of objects ~o′. We primarily evaluatemodels by accuracy; scoring how many objects forwhich they got all attributes correct. We comparewith the following strong baselines:a. No Change: this baseline copies the initial state
of all objects ~o as the final state ~o′.b. GPT3-175B (Brown et al., 2020), a very large
language model for ‘few-shot’ learning usinga prompt. For GPT3, and other text-to-textmodels, we encode and decode the symbolicobject states in a JSON-style dictionary format,discussed in Appendix A.4.
c. T5 (Raffel et al., 2019). With this model, weuse the same ‘text-to-text’ format, howeverhere we train it on the paired data from PIG-PeN. We consider varying sizes of T5, fromT5-Small – the closest in size to PIGLeT, upuntil T5-11B, roughly 100x the size.
d. (Alberti et al., 2019)-style. This paper origi-nally proposed a model for VCR (Zellers et al.,
5
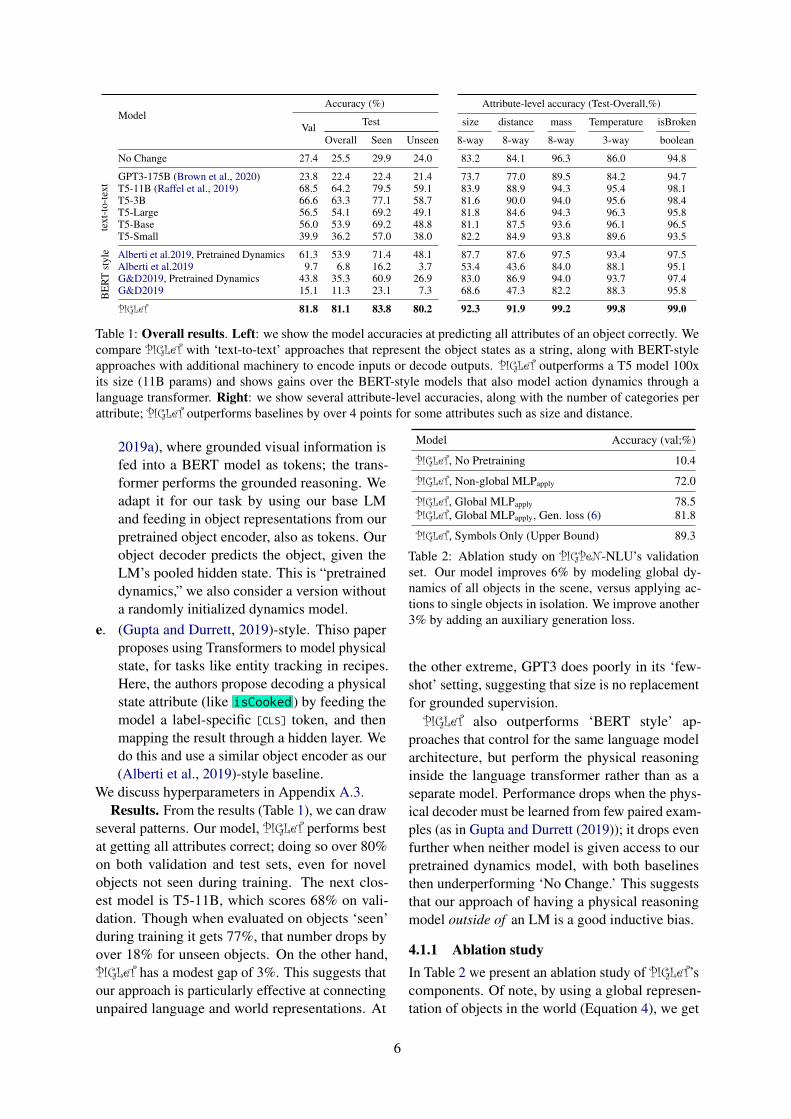
ModelAccuracy (%)
Val Test
Overall Seen Unseen
No Change 27.4 25.5 29.9 24.0
text
-to-
text
GPT3-175B (Brown et al., 2020) 23.8 22.4 22.4 21.4T5-11B (Raffel et al., 2019) 68.5 64.2 79.5 59.1T5-3B 66.6 63.3 77.1 58.7T5-Large 56.5 54.1 69.2 49.1T5-Base 56.0 53.9 69.2 48.8T5-Small 39.9 36.2 57.0 38.0
BE
RT
styl
e Alberti et al.2019, Pretrained Dynamics 61.3 53.9 71.4 48.1Alberti et al.2019 9.7 6.8 16.2 3.7G&D2019, Pretrained Dynamics 43.8 35.3 60.9 26.9G&D2019 15.1 11.3 23.1 7.3
PIGLeT 81.8 81.1 83.8 80.2
Attribute-level accuracy (Test-Overall,%)
size distance mass Temperature isBroken
8-way 8-way 8-way 3-way boolean
83.2 84.1 96.3 86.0 94.8
73.7 77.0 89.5 84.2 94.783.9 88.9 94.3 95.4 98.181.6 90.0 94.0 95.6 98.481.8 84.6 94.3 96.3 95.881.1 87.5 93.6 96.1 96.582.2 84.9 93.8 89.6 93.5
87.7 87.6 97.5 93.4 97.553.4 43.6 84.0 88.1 95.183.0 86.9 94.0 93.7 97.468.6 47.3 82.2 88.3 95.8
92.3 91.9 99.2 99.8 99.0
Table 1: Overall results. Left: we show the model accuracies at predicting all attributes of an object correctly. Wecompare PIGLeT with ‘text-to-text’ approaches that represent the object states as a string, along with BERT-styleapproaches with additional machinery to encode inputs or decode outputs. PIGLeT outperforms a T5 model 100xits size (11B params) and shows gains over the BERT-style models that also model action dynamics through alanguage transformer. Right: we show several attribute-level accuracies, along with the number of categories perattribute; PIGLeT outperforms baselines by over 4 points for some attributes such as size and distance.
2019a), where grounded visual information isfed into a BERT model as tokens; the trans-former performs the grounded reasoning. Weadapt it for our task by using our base LMand feeding in object representations from ourpretrained object encoder, also as tokens. Ourobject decoder predicts the object, given theLM’s pooled hidden state. This is “pretraineddynamics,” we also consider a version withouta randomly initialized dynamics model.
e. (Gupta and Durrett, 2019)-style. Thiso paperproposes using Transformers to model physicalstate, for tasks like entity tracking in recipes.Here, the authors propose decoding a physicalstate attribute (like isCooked ) by feeding themodel a label-specific [CLS] token, and thenmapping the result through a hidden layer. Wedo this and use a similar object encoder as our(Alberti et al., 2019)-style baseline.
We discuss hyperparameters in Appendix A.3.Results. From the results (Table 1), we can draw
several patterns. Our model, PIGLeT performs bestat getting all attributes correct; doing so over 80%on both validation and test sets, even for novelobjects not seen during training. The next clos-est model is T5-11B, which scores 68% on vali-dation. Though when evaluated on objects ‘seen’during training it gets 77%, that number drops byover 18% for unseen objects. On the other hand,PIGLeT has a modest gap of 3%. This suggests thatour approach is particularly effective at connectingunpaired language and world representations. At
Model Accuracy (val;%)
PIGLeT, No Pretraining 10.4
PIGLeT, Non-global MLPapply 72.0
PIGLeT, Global MLPapply 78.5PIGLeT, Global MLPapply, Gen. loss (6) 81.8
PIGLeT, Symbols Only (Upper Bound) 89.3
Table 2: Ablation study on PIGPeN-NLU’s validationset. Our model improves 6% by modeling global dy-namics of all objects in the scene, versus applying ac-tions to single objects in isolation. We improve another3% by adding an auxiliary generation loss.
the other extreme, GPT3 does poorly in its ‘few-shot’ setting, suggesting that size is no replacementfor grounded supervision.PIGLeT also outperforms ‘BERT style’ ap-
proaches that control for the same language modelarchitecture, but perform the physical reasoninginside the language transformer rather than as aseparate model. Performance drops when the phys-ical decoder must be learned from few paired exam-ples (as in Gupta and Durrett (2019)); it drops evenfurther when neither model is given access to ourpretrained dynamics model, with both baselinesthen underperforming ‘No Change.’ This suggeststhat our approach of having a physical reasoningmodel outside of an LM is a good inductive bias.
4.1.1 Ablation studyIn Table 2 we present an ablation study of PIGLeT’scomponents. Of note, by using a global represen-tation of objects in the world (Equation 4), we get
6

over 6% improvement over a local representationwhere objects are manipulated independently. Weget another 3% boost by adding a generation loss,suggesting that learning to generate summarieshelps the model better connect the world to lan-guage. Last, we benchmark how much headroomthere is on PIGPeN-NLU by evaluating model per-formance on a ‘symbols only’ version of the task,where the symbolic action a is given explicitly toour dynamics model. This upper bound is roughly7% higher than PIGLeT, suggesting space for futurework.
4.2 PIGPeN-NLG Results
Next, we turn to PIGPeN-NLG: given objects ~o,and the literal next action a, a model must generatea sentence s~o′ describing what will change in thescene. We compare with the following baselines:a. T5. We use a T5 model that is given a JSON-
style dictionary representation of both ~o and a,it is finetuned to generate summaries s~o′ .
b. LM Baseline. We feed our LM hidden statesho from our pretrained encoder, along withits representation of a. The key difference be-tween it and PIGLeT is that we do not allow itto simulate neurally what might happen next –MLPapply is never used here.
Size matters. Arguably the most important factorcontrolling the fluency of a language generator isits size (Kaplan et al., 2020). Since our LM couldalso be scaled up to arbitrary size, we control forsize in our experiments and only consider modelsthe size of GPT2-base (117M) or smaller; we thuscompare against T5-small as T5-Base has 220Mparameters. We discuss optimization and samplinghyperparameters in Appendix A.3.
Evaluation metrics. We evaluate models overthe validation and test sets. We consider threemain evaluation metrics: BLEU (Papineni et al.,2002) with two references, the recently proposedBERTScore (Zhang et al., 2020), and conduct ahuman evaluation. Humans rate both the fluency ofpost-action text, as well as its faithfulness to trueaction result, on a scale from −1 to 1.
Results. We show our results in Table 3. Of note,PIGLeT is competitive with T5 and significantlyoutperforms the pure LM baseline, which uses apretrained encoder for object states, yet has thephysical simulation piece MLPapply removed. Thissuggests that simulating world dynamics not onlyallows the model to predict what might happen
Model BLEU BERTScore Human (test; [91, 1])
Val Test Val Test Fluency Faithfulness
T5 46.6 43.4 82.2 81.0 0.82 0.15LM Baseline 44.6 39.7 81.6 78.8 0.91 -0.13PIGLeT 49.0 43.9 83.6 81.3 0.92 0.22
Human 44.5 45.6 82.6 83.3 0.94 0.71
Table 3: Text generation results on PIGPeN-NLG,showing models of roughly equivalent size (up to117M parameters). Our PIGLeT outperforms the LMbaseline (using the same architecture but omitting thephysical reasoning component) by 4 BLEU points, 2BERTScore F1 points, and 0.35 points in a human eval-uation of language faithfulness to the actual scene.
next, it leads to more faithful generation as well.
5 Analysis
5.1 Qualitative examples.
We show two qualitative examples in Figure 4, cov-ering both PIGPeN-NLU as well as PIGPeN-NLG.In the first row, the robot empties a held Mug that isfilled with water. PIGLeT gets the state, and gener-ates a faithful sentence summarizing that the mugbecomes empty. T5 struggles somewhat, emptyingthe water from both the Mug and the (irrelevant)Sink . It also generates text saying that the Sinkbecomes empty, instead of the Mug.
In the second row, PIGLeT correctly predicts thenext object states, but its generated text is incom-plete – it should also write that the mug becomesfilled wtih Coffee. T5 makes the same mistakein generation, and it also underpredicts the statechanges, omitting all changes to the Mug .
We suspect that T5 struggles here in part becauseMug is an unseen object. T5 only experiences itthrough language-only pretraining, but this mightnot be enough for a fully grounded representation.
5.2 Representing novel words
The language models that perform best today aretrained on massive datasets of text. However, thishas unintended consequences (Bender et al., 2021)and it is unlike how children learn language, withchildren learning novel words from experience(Carey and Bartlett, 1978). The large scale of ourpretraining datasets might allow models to learnto perform physical-commonsense like tasks forwrong reasons, overfitting to surface patterns ratherthan learning meaningful grounding.
We investigate the extent of this by traininga ‘zero-shot’ version of our backbone LM onWikipedia and books – the only difference is that
7

The sink is now empty.
isFilledWithLiquid:True
Name: Sink
State pre-action
isPickedUp: True
isFilledWithLiquid:True
Name: Mug
<emptyLiquid,
Mug>
t
Ground truth post-action states
Predicted post-action states
PIGLeT T5
The robot empties the mug.
isFilledWithLiquid:True
Name: Sink
isPickedUp: True
isFilledWithLiquid:False
Name: Mug
isFilledWithLiquid:False
Name: Sink
isPickedUp: True
isFilledWithLiquid:False
Name: Mug
isFilledWithLiquid:True
Name: Sink
isPickedUp: True
isFilledWithLiquid:False
Name: Mug
The mug is no longer filled with water.The mug is now empty.
t
Temperature: RoomTemp
isFilledWithLiquid:False
Name: Mug
containsObject: Mug
isTurnedOn: False
Name: CoffeeMachine
<toggleObject,
CoffeeMaker>
The robot turns on the coffee maker.
The coffee machine becomes on.
The coffee machine is turned on.
Temperature: Hot
isFilledWithLiquid:True
Name: Mug
containsObject: Mug
isTurnedOn: True
Name: CoffeeMachine
Temperature: RoomTemp
isFilledWithLiquid:False
Name: Mug
containsObject: Mug
isTurnedOn: True
Name: CoffeeMachine
Temperature: Hot
isFilledWithLiquid:True
Name: Mug
containsObject: Mug
isTurnedOn: True
Name: CoffeeMachine
The coffee maker is now on and the mug is hot and filled with coffee.
Figure 4: Qualitative examples. Our model PIGLeT reliably predicts what might happen next (like the Mug be-coming empty in Row 1), in a structured and explicit way. However, it often struggles at generating sentences forunseen objects like Mug that are excluded from the training set. T5 struggles to predict these changes, for example,it seems to suggest that emptying the Mug causes all containers in the scene to become empty.
Seen Objects0
20
40
60
80
100
Test
Acc
urac
y (%
) 83.8 81.9
Unseen Objects
80.273.4
Accuracy at predicting selected unseen objects
30.8
72.2
84.990.2
95.191.2
80.0
26.9
61.9
80.174.5 75.4
88.2
74.1
CellPhone
Microwave
MugSink
ToasterFridge
Egg
modelPIGLeTPIGLeTZeroShotLang
Figure 5: PIGPeN-NLU performance of a zero-shotPIGLeT, that was pretrained on Books and Wikipediawithout reading any words of our ‘unseen’ objects like‘mug.’ It outperforms a much bigger T5-11B overall,though is in turn beaten by PIGLeT on unseen objectslike ‘Sink’ and ‘Microwave.’
we explicitly exclude all mentioned sentences con-taining one of our “unseen” object categories. Inthis setting, not only must PIGLeT learn to groundwords like ‘mug,’ it must do so without having seenthe word ‘mug’ during pretraining. This is signifi-cant because we count over 20k instances of ‘Mug’words (including morphology) in our dataset.
We show results in Figure 5. A version ofPIGLeT with the zero-shot LM does surprisinglywell – achieving 80% accuracy at predicting thestate changes for “Mug” – despite never havingbeen pretrained on one before. This even out-performs T5 at the overall task. Nevertheless,PIGLeT outperforms it by roughly 7% at unseenobjects, with notable gains of over 10% on highlydynamic objects like Toasters and Sinks.
6 Related Work
Grounded commonsense reasoning. In thiswork, we study language grounding and common-
sense reasoning at the representation and conceptlevel. The aim is to train models that learn to ac-quire concepts more like humans, rather than per-forming well on a downstream task that (for hu-mans) requires commonsense reasoning. Thus, thiswork is somewhat different versus other 3D em-bodied tasks like QA (Gordon et al., 2018; Daset al., 2018), along with past work for measur-ing such grounded commonsense reasoning, likeSWAG, HellaSWAG, and VCR (Zellers et al., 2018,2019b,a). The knowledge covered is different, as itis self-contained within THOR. While VCR, for in-stance, includes lots of visual situations about whatpeople are doing, this paper focuses on learning thephysical properties of objects.
Zero-shot generalization. There has been a lotof past work involved with learning ‘zero-shot’:often learning about the grounded world in lan-guage, and transferring that knowledge to vision.Techniques for this include looking at word embed-dings (Frome et al., 2013) and dictionary defini-tions (Zellers and Choi, 2017). In this work, wepropose the inverse. This approach was used tolearn better word embeddings (Gupta et al., 2019)or semantic tuples (Yatskar et al., 2016), but weconsider learning a component to be plugged intoa deep Transformer language model.
Past work evaluating these types of zero-shotgeneralization have also looked into how wellmodels can compose concepts in language to-gether (Lake and Baroni, 2018; Ruis et al., 2020).Our work considers elements of compositional-ity through grounded transfer. For example, in
8

PIGPeN-NLG, models must generate sentencesabout the equivalent of dropping a ‘dax’, despitenever having seen one before. However, our workis also contextual, in that the outcome of ‘droppinga dax’ might depend on external attributes (likehow high we’re dropping it from).
Structured Models for Attributes and Ob-jects. The idea of modeling actions as functionsthat transform objects has been explored in thecomputer vision space (Wang et al., 2016). Pastwork has also built formal structured models forconnecting vision and language (Matuszek et al.,2012; Krishnamurthy and Kollar, 2013), we take aneural approach and connect today’s best modelsof language form to similarly neural models of asimulated environment.
Past work has also looked into training neuralmodels for a target domain – similar to our factor-ized model for physical interaction. For example,(Leonandya et al., 2019) and (Gaddy and Klein,2019) learn pretrained models for an instruction-following task in a blocks world, also using anautoencoder formulation. Our goal in this workis somewhat different: we are interested in learn-ing physical reasoning about everyday objects, thatmight be discussed loosely in language (but withrecurring issues of reporting bias (Gordon andVan Durme, 2013)). We thus build a model that canbe tied in with a pretrained language model, whilealso exhibiting generalization to new objects (thatwere not mentioned in language). We compare ourmodel to today’s largest language models that learnfrom text alone, and find better performance despitehaving 100x fewer parameters.
7 Conclusion
In this paper, we presented an approach PIGLeT forjointly modeling language form and meaning. Wepresented a testbed PIGPeN for evaluating ourmodel, which performs well at grounding languageto the (simulated) world.
Acknowledgments
We thank the reviewers for their helpful feedback,and the Mechanical Turk workers for doing a greatjob in annotating our data. Thanks also to ZakStone and the Google Cloud TPU team for helpwith the computing infrastructure. This work wassupported by the DARPA CwC program throughARO (W911NF-15-1-0543), the DARPA MCS pro-gram through NIWC Pacific (N66001-19-2-4031),
and the Allen Institute for AI.
ReferencesChris Alberti, Jeffrey Ling, Michael Collins, and David
Reitter. 2019. Fusion of detected objects in textfor visual question answering. In Proceedings ofthe 2019 Conference on Empirical Methods in Nat-ural Language Processing and the 9th InternationalJoint Conference on Natural Language Processing(EMNLP-IJCNLP), pages 2131–2140.
Yoav Artzi, Nicholas FitzGerald, and Luke S Zettle-moyer. 2013. Semantic parsing with combinatorycategorial grammars. ACL (Tutorial Abstracts), 3.
Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On thedangers of stochastic parrots: Can language modelsbe too big. Proceedings of FAccT.
Emily M. Bender and Alexander Koller. 2020. Climb-ing towards NLU: On meaning, form, and under-standing in the age of data. In Proceedings of the58th Annual Meeting of the Association for Compu-tational Linguistics, pages 5185–5198, Online. As-sociation for Computational Linguistics.
Yonatan Bisk, Ari Holtzman, Jesse Thomason, JacobAndreas, Yoshua Bengio, Joyce Chai, Mirella Lap-ata, Angeliki Lazaridou, Jonathan May, AleksandrNisnevich, et al. 2020. Experience grounds lan-guage. arXiv preprint arXiv:2004.10151.
Tom B Brown, Benjamin Mann, Nick Ryder, MelanieSubbiah, Jared Kaplan, Prafulla Dhariwal, ArvindNeelakantan, Pranav Shyam, Girish Sastry, AmandaAskell, et al. 2020. Language models are few-shotlearners. arXiv preprint arXiv:2005.14165.
S. Carey and E. Bartlett. 1978. Acquiring a single newword.
Abhishek Das, Samyak Datta, Georgia Gkioxari, Ste-fan Lee, Devi Parikh, and Dhruv Batra. 2018. Em-bodied question answering. In Proceedings of theIEEE Conference on Computer Vision and PatternRecognition, pages 1–10.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2019. Bert: Pre-training ofdeep bidirectional transformers for language under-standing. In Proceedings of the 2019 Conference ofthe North American Chapter of the Association forComputational Linguistics: Human Language Tech-nologies, Volume 1 (Long and Short Papers), pages4171–4186.
Li Dong, Nan Yang, Wenhui Wang, Furu Wei,Xiaodong Liu, Yu Wang, Jianfeng Gao, MingZhou, and Hsiao-Wuen Hon. 2019. Unifiedlanguage model pre-training for natural languageunderstanding and generation. arXiv preprintarXiv:1905.03197.
9

Andrea Frome, Greg Corrado, Jonathon Shlens, SamyBengio, Jeffrey Dean, Marc’Aurelio Ranzato, andTomas Mikolov. 2013. Devise: A deep visual-semantic embedding model.
David Gaddy and Dan Klein. 2019. Pre-learning envi-ronment representations for data-efficient neural in-struction following. In Proceedings of the 57th An-nual Meeting of the Association for ComputationalLinguistics, pages 1946–1956.
Daniel Gordon, Aniruddha Kembhavi, MohammadRastegari, Joseph Redmon, Dieter Fox, and AliFarhadi. 2018. Iqa: Visual question answering in in-teractive environments. In Proceedings of the IEEEConference on Computer Vision and Pattern Recog-nition (CVPR).
Jonathan Gordon and Benjamin Van Durme. 2013. Re-porting bias and knowledge acquisition. In Proceed-ings of the 2013 workshop on Automated knowledgebase construction, pages 25–30. ACM.
Aditya Gupta and Greg Durrett. 2019. Effective useof transformer networks for entity tracking. In Pro-ceedings of the 2019 Conference on Empirical Meth-ods in Natural Language Processing and the 9th In-ternational Joint Conference on Natural LanguageProcessing (EMNLP-IJCNLP), pages 759–769.
Tanmay Gupta, Alexander Schwing, and Derek Hoiem.2019. Vico: Word embeddings from visual co-occurrences. In Proceedings of the IEEE Interna-tional Conference on Computer Vision, pages 7425–7434.
Stevan Harnad. 1990. The symbol grounding prob-lem. Physica D: Nonlinear Phenomena, 42(1-3):335–346.
Richard Held and Alan Hein. 1963. Movement-produced stimulation in the development of visuallyguided behavior. Journal of comparative and physi-ological psychology, 56(5):872.
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld,Luke Zettlemoyer, and Omer Levy. 2020. Spanbert:Improving pre-training by representing and predict-ing spans. Transactions of the Association for Com-putational Linguistics, 8:64–77.
Jared Kaplan, Sam McCandlish, Tom Henighan,Tom B Brown, Benjamin Chess, Rewon Child, ScottGray, Alec Radford, Jeffrey Wu, and Dario Amodei.2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361.
Diederik P. Kingma and Jimmy Ba. 2014. Adam:A method for stochastic optimization. CoRR,abs/1412.6980.
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli Van-derBilt, Luca Weihs, Alvaro Herrasti, Daniel Gor-don, Yuke Zhu, Abhinav Gupta, and Ali Farhadi.2017. Ai2-thor: An interactive 3d environment forvisual ai. arXiv preprint arXiv:1712.05474.
Jayant Krishnamurthy and Thomas Kollar. 2013.Jointly learning to parse and perceive: Connectingnatural language to the physical world. Transac-tions of the Association for Computational Linguis-tics, 1:193–206.
Brenden Lake and Marco Baroni. 2018. Generalizationwithout systematicity: On the compositional skillsof sequence-to-sequence recurrent networks. In In-ternational Conference on Machine Learning, pages2873–2882. PMLR.
Rezka Leonandya, Dieuwke Hupkes, Elia Bruni, andGerman Kruszewski. 2019. The fast and the flex-ible: Training neural networks to learn to followinstructions from small data. In Proceedings ofthe 13th International Conference on ComputationalSemantics-Long Papers, pages 223–234.
Cynthia Matuszek, Nicholas FitzGerald, Luke Zettle-moyer, Liefeng Bo, and Dieter Fox. 2012. A jointmodel of language and perception for grounded at-tribute learning. In Proceedings of the 29th Inter-national Coference on International Conference onMachine Learning, pages 1435–1442.
James L McClelland, Felix Hill, Maja Rudolph, Ja-son Baldridge, and Hinrich Schutze. 2019. Ex-tending machine language models toward human-level language understanding. arXiv preprintarXiv:1912.05877.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic eval-uation of machine translation. In Proceedings of the40th annual meeting of the Association for Compu-tational Linguistics, pages 311–318.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan,Dario Amodei, and Ilya Sutskever. 2019. Languagemodels are unsupervised multitask learners. Techni-cal report, OpenAI.
Colin Raffel, Noam Shazeer, Adam Roberts, KatherineLee, Sharan Narang, Michael Matena, Yanqi Zhou,Wei Li, and Peter J. Liu. 2019. Exploring the limitsof transfer learning with a unified text-to-text trans-former. arXiv e-prints.
Laura Ruis, Jacob Andreas, Marco Baroni, DianeBouchacourt, and Brenden M Lake. 2020. A bench-mark for systematic generalization in grounded lan-guage understanding. Advances in Neural Informa-tion Processing Systems, 33.
Noam Shazeer and Mitchell Stern. 2018. Adafactor:Adaptive learning rates with sublinear memory cost.In International Conference on Machine Learning,pages 4603–4611.
Mohit Shridhar, Jesse Thomason, Daniel Gordon,Yonatan Bisk, Winson Han, Roozbeh Mottaghi,Luke Zettlemoyer, and Dieter Fox. 2020. Alfred:A benchmark for interpreting grounded instructionsfor everyday tasks. In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recog-nition, pages 10740–10749.
10

Linda Smith and Michael Gasser. 2005. The develop-ment of embodied cognition: Six lessons from ba-bies. Artificial life, 11(1-2):13–29.
Ashish Vaswani, Noam Shazeer, Niki Parmar, JakobUszkoreit, Llion Jones, Aidan N Gomez, ŁukaszKaiser, and Illia Polosukhin. 2017. Attention is allyou need. In Proceedings of the 31st InternationalConference on Neural Information Processing Sys-tems, pages 6000–6010. Curran Associates Inc.
Xiaolong Wang, Ali Farhadi, and Abhinav Gupta. 2016.Actions ˜ transformations. In CVPR.
Mark Yatskar, Vicente Ordonez, and Ali Farhadi. 2016.Stating the obvious: Extracting visual commonsense knowledge. In Proceedings of the 2016 Con-ference of the North American Chapter of the Asso-ciation for Computational Linguistics: Human Lan-guage Technologies, pages 193–198.
Chen Yu and Linda B Smith. 2012. Embodied at-tention and word learning by toddlers. Cognition,125(2):244–262.
Rowan Zellers, Yonatan Bisk, Ali Farhadi, and YejinChoi. 2019a. From recognition to cognition: Vi-sual commonsense reasoning. In The IEEE Confer-ence on Computer Vision and Pattern Recognition(CVPR).
Rowan Zellers, Yonatan Bisk, Roy Schwartz, andYejin Choi. 2018. SWAG: A large-scale adversar-ial dataset for grounded commonsense inference. InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing, pages 93–104, Brussels, Belgium. Association for Computa-tional Linguistics.
Rowan Zellers and Yejin Choi. 2017. Zero-shot activ-ity recognition with verb attribute induction. In Pro-ceedings of the 2017 Conference on Empirical Meth-ods in Natural Language Processing, pages 946–958.
Rowan Zellers, Ari Holtzman, Yonatan Bisk, AliFarhadi, and Yejin Choi. 2019b. HellaSwag: Cana machine really finish your sentence? In Pro-ceedings of the 57th Annual Meeting of the Asso-ciation for Computational Linguistics, pages 4791–4800, Florence, Italy. Association for ComputationalLinguistics.
Tianyi Zhang, V. Kishore, Felix Wu, Kilian Q. Wein-berger, and Yoav Artzi. 2020. Bertscore: Evaluatingtext generation with bert. ArXiv, abs/1904.09675.
11

A Model implementation details andhyperparameters.
We discuss the architectures and learning hyperpa-rameters of our various models in the subsectionsbelow.
A.1 Physical Dynamics Model
We implemented our dynamics model with threeTransformer layers for both the encoder and thedecoder, and a hidden dimension of 256 for objectsand actions. The resulting model has 17 millionparameters. We pretrained the model for 20 epochsover 280k state transitions, with a batch size of1024. We use an Adam optimizer (Kingma and Ba,2014) with a learning rate of 1e−3.
A.2 Ordering attributes in decoding.
Recall that we use a left-to-right transformer todecode into an attribute representation, predictingattributes one-by-one from c1 to cn. Our modelis agnostic to the actual order, as no matter whatthe order is, it still is modeling a decompositionof the joint probability of generating that object.However, we implemented this by using the nameas the first attribute c1 that is predicted, and orderedthe rest in a descending way by vocabulary size soas to predict harder attributes first.
A.3 Optimization Hyperparameters chosen
We finetuned PIGLeT for both tasks with an Adamoptimizer (Kingma and Ba, 2014). We did a smallgrid search for hyperparameter values, choosingthe best learning rate {2e−5, 1e−5, 1e−6} by accu-racy on the development set, and likewise the bestbatch size 16 or 32. We considered freezing thephysical dynamics backbone as another hyperpa-rameter. We found it slightly boosted performanceon PIGPeN-NLG when we froze the physical dy-namics backbone, but not so for PIGPeN-NLU. Wetrained our model for 80 epochs on paired data.
We trained the baseline models with the samebackbone in the same way, using similar hyperpa-rameters. However, we found that after 80 epochs,the baseline models without pretrained dynamicsfailed to converge, so we finetuned them for 200epochs total. For T5, we used similar identical hy-perparameter ranges as the other models. However,because T5 uses a different optimizer (AdaFac-tor; Shazeer and Stern (2018)), which operateson a slightly different scale, we used a different
set of learning rates. We chose the best one over{1e−4, 2e−4, 4e−4}.
Search. Both of our tasks involve left-to-rightdecoding. We used argmax (greedy) search forPIGPeN-NLU, finding that it worked well as a‘closed-ended generation’ style task. On the otherhand, we used Nucleus Sampling for PIGPeN-NLG as there are often several ways to communi-cate a state transition; here we set p = 0.8.
A.4 Encoding the input for text-to-textmodels
Text-to-text models, needless to say, can only han-dle text. We encode the world states into a represen-tation suitable for these models by formatting theobject states as a JSON-style dictionary of keys andvalues. We had to make several modifications to theencoding however from a default JSON, becausewe handle a lot of attributes in this task, and JSONhas quote characters ‘’‘ that take up a lot of space ina BPE encoding. We thus strip the quote charactersand lowercase everything (with this also helpingBPE-efficiency). We put parentheses around eachobject and give names to all ‘binned’ attributes.
An example encoding might be:Predict next object states: (objectname: bowl,
parentreceptacles: cabinet, containedobjects:
none, distance: 6 to 8 ft, mass: .5 to 1lb,
size: medium, temp: roomtemp, breakable: true,
cookable: false, dirtyable: true, broken: false,
cooked: false, dirty: false, filledwithliquid:
false, open: false, pickedup: false, sliced:
false, toggled: false, usedup: false, moveable:
false, openable: false, pickupable: true,
receptacle: true, sliceable: false, toggleable:
false, materials: glass) (objectname: egg,
parentreceptacles: none, containedobjects: none,
distance: 2 to 3ft, mass: .1 to .2lb, size: tiny,
temp: cold, breakable: true, cookable: true,
dirtyable: false, broken: false, cooked: false,
dirty: false, filledwithliquid: false, open:
false, pickedup: true, sliced: false, toggled:
false, usedup: false, moveable: false, openable:
false, pickupable: true, receptacle: false,
sliceable: true, toggleable: false, materials:
food) (action: throwobject10)
We have models decode directly into this kindof format when predicting state changes. Thoughthe T5 models usually get the format right, we of-ten have to sanitize the text in order for it to be avalid object state in our framework. This is espe-
12

cially an issue with GPT3, since it is given limitedsupervision (we squeeze 3 examples into the 2048-BPE token context window) and often makes upnew names and attributes. Thus, for each word notin an attribute’s vocabulary, we use a Levensteindistance heuristic to match the an invalid choicewith its closest (valid) option. If the model failsto generate anything for a certain attribute key –for example if it does not include something likeopenable somewhere, we copy the representationof the input object for that attribute, thereby mak-ing the default assumption that attributes do notchange.
B All THOR attributes
We list a table with all of the attributes we used forthis work in Table 4.
C Turk Annotation Details
We followed crowdsourcing best practices, suchas using a qualification exam, giving feedback toworkers, and paying workers well (above $15 perhour). Each of our HITs required writing three sen-tences, and we paid Mechanical Turk workers 57cents per HIT. We used three workers per example,allowing us to have multiple language referencesfor evaluation. A screenshot of our user interfaceis shown in Figure 6.
D Our Pretrained Language Model
We use our own pretrained language model primar-ily because it allows us to investigate the impact ofdata on model performance. We trained a prefix-masked language model (Dong et al., 2019) onWikipedia and Book data, mimicing the data usedby the original BERT paper (Devlin et al., 2019).We trained the model for 60000 iterations, at abatch size of 8192 sequences each of length 512.This corresponds to 50 epochs over the dataset. Wemasked inputs in the bidirectional prefix with Span-BERT masking (Joshi et al., 2020). Since BERT-style ‘masked’ out inputs are easier to predict thantokens generated left-to-right, we reduced the losscomponent of left-to-right generation by a factorof 20; roughly balancing the two loss components.
Figure 6: Our user interface for Mechanical Turk anno-tation.
0
100k
200k
300k
400k
500k
Cou
nts
Counts (in Wikipedia / Toronto Books) of our zero-shot words
Bed
Cel
lPho
neW
indo
wP
aint
ing
Pla
teE
ggM
irror
Cou
nter
Top
Bre
adP
otat
oS
ink
Dra
wer
Frid
geP
anM
ugV
ase
Mic
row
ave
Gar
bage
Can
Ket
tleB
linds
Tedd
yBea
rLe
ttuce
Ligh
tSw
itch
Toas
ter
Win
eBot
tle
Figure 7: Counts of zero-shot words that appear inBERT’s training data (Wikipedia and Toronto Books).For example, in the 4 billion words BERT is trainedon, it sees the word ‘Bed’ almost 500k times. Thismight allow it to perform superficially well at answer-ing questions about beds – while not necessarily pos-sessing deep physical knowledge about them.
13

Attribute Name Vocab size Values
objectName 126 One per object type,along with None
parentReceptacles 126 One per object type,along with None
receptacleObjectIds 126 One per object type,along with None
mass 8 8 binssize 8 8 binsdistance 8 8 binsObjectTemperature 3 Hot , Cold , RoomTempbreakable 2canBeUsedUp 2canFillWithLiquid 2cookable 2dirtyable 2isBroken 2isCooked 2isDirty 2isFilledWithLiquid 2isOpen 2isPickedUp 2isSliced 2isToggled 2isUsedUp 2moveable 2openable 2pickupable 2receptacle 2sliceable 1toggleable 2salientMaterials Ceramic 2salientMaterials Fabric 2salientMaterials Food 2salientMaterials Glass 2salientMaterials Leather 2salientMaterials Metal 2salientMaterials None 2salientMaterials Organic 2salientMaterials Paper 2salientMaterials Plastic 2salientMaterials Rubber 2salientMaterials Soap 2salientMaterials Sponge 2salientMaterials Stone 2salientMaterials Wax 2salientMaterials Wood 2
Table 4: All attributes that we consider for this work inTHOR. We list the attribute’s name, the size of the at-tribute vocabulary, and the range of values the attributecan take on. For attributes like ‘mass’, ‘size’, and ‘dis-tance’, we note that the underlying simulator storesthem as floats; we bin them to 8 values for this work.All the values for attributes with a vocabulary size of 2are boolean.
Generator Description
put_X_in_Y Samples an object X from the scene, and areceptacle Y . Tries to put it in Y .
throw_X_at_Y Samples two objects X and Y from thescene. Picks up X , moves to face Y , andthrows it forward with variable intensity.
toggle_X Samples an object X , and turns it on or off.slice_X Samples an object X and a surface Y .
Picks up X , places it on Y , and cuts it.dirty_X Samples an object X , and makes it dirty.clean_X Samples a dirty object X . Finds a Sink
nearby a Faucet , and places X inside.Turns on/off the Faucet , cleaning X .
toast_bread Finds some Bread , slicing it if necessary,places it in a Toaster , then turns it on.
brew_coffee Picks up a Mug , places it under aCoffeeMachine , and turns the machine on.
fry_X Picks up a food X , slices it if necessary,and puts it in a Pot or Pan . Brings it to aStoveBurner and turns the burner on.
microwave_X Picks up an object X and slices it if neces-sary. Places it in a Microwave , closes it, andthen turns it on.
fill_X Picks up an object X places it under aFaucet . Turns on/off the Faucet , thenpours out the liquid.
Table 5: Trajectory generation functions that we used tosample ‘interesting’ physical interactions, such as theeffects that actions will have on objects, and which ac-tions will succeed or not.
14