praccallycostlesscoherence forgpusand( manycore...
TRANSCRIPT

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
1
Prac%cally Costless Coherence for GPUs and Manycore
Accelerators PEGPUM/HiPEAC 2013
1
Stefanos Kaxiras & Alberto Ros
2/3/13 Uppsala University/Uppsala Innova%on 1
1. Ros & Kaxiras, "Complexity-‐Effec%ve Mul%core Coherence” PACT2012 2. Kaxiras & Ros "Efficient, Snoopless, System-‐On-‐Chip Coherence" IEEE System on Chip Conference (SOCC) 2012

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
2
Mo%va%on: Why Simplify? Directory/Snooping Coherence is a relic of NUMA/SMP systems of the past: • “Invisible” to memory consistency à supports SC in the
presence of data races (which may not be needed) – Invalida%ons, directories, snoops, broadcasts …
• Does not take into account LLC – e.g., Owned state for $-‐2-‐$
• MESI is already complex (30+ hidden and stable states) – any new op%miza%on à verify from scratch
• but what the heck, we know how to do it … • Cost (area + power):
– Directories, indirec%on, … – Snooping on busses, dual tags, …
2/3/13 2 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
3
Mo%va%on: Why Simplify?
• Not a big issue for few fat cores … • But: a new class of manycores with many simple cores: GPUs, accelerators, … – Desire to make them coherent with GP cores on the same chip (coherent Shared Virtual Memory – cSVM)
– Coherence overhead (area, power) is a big issue à don’t want to pay much per core
– Coherence is sporadically needed à why pay always?
• Simple coherence à simple memory system & NoC
2/3/13 3 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
4
Simplifying Coherence: Write Through
• Write-‐through protocols are simple – Only Valid and Invalid states in the caches – BUT they are terrible because of many write misses
• Most of the write misses due to private data (≈ 90%)
2/3/13 4 Uppsala University/Uppsala Innova%on
Barnes
CholeskyFFT
FMM LUOcean
Radiosity
Raytrace
Volrend
Water-Nsq
Water-Sp
Em3d
Tomcatv
Swaptions
x264
Average
0.010.020.030.040.050.060.070.080.090.0
100.0
Pe
rce
nta
ge
of
write
mis
ses
Private Shared

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
5
VIPS
• Dynamic write policy in the L1s (private caches, in general) based on a classifica%on of data to Private/Shared:
• Write-‐back (WB) for Private lines – Simple (no coherence required) as in uniprocessors – Efficient: no extra misses
• Write-‐through (WT) for Shared lines – Simple (only two states, VI) – Efficient: WT à coherence misses
• VIPS: Valid/Invalid Private/Shared 2/3/13 5 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
6
Private/Shared Classifica%on
• Classify data (cache lines) into Private and Shared – Private are accessed by one core only and DO NOT NEED COHERENCE
– Shared are (poten%ally) accessed by more than one core and need coherence
– Not a temporal classifica%on! but for the life %me of the program (think of variable declara%on as private or shared)
• Private/Shared classifica%on orthogonal to the rest of the protocol. – Several ways to do it; here: based on Page Table/TLBs
2/3/13 6 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
7
Private/Shared Classifica%on (cont.)
• Page-‐level classifica%on by the OS: – Used in various contexts (Hardavellas et al., ISCA’09, NUCA, Cuesta et al., ISCA’11, directory reduc%on)
• Technique: – Each page (PTE/TLB) has a P/S bit – The first access of a page by a core sets it to P – Subsequent accesses by other cores set it to S, interrupt the single core that first set it to P and correct it
2/3/13 7 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
8
Delayed Write-‐Throughs
S%ll some write misses for shared blocks (~20% of a full WT policy) • Delay WTs to coalesce as many writes as possible on the same cache line for performance
• WTs are delayed in the MSHRs • End result:
MESI WB Traffic ~ 6.5% of FULL WT traffic VIPS (Private WB + Shared Delayed WT) ~ 9% of FULL WT traffic (difference of 2.5%)
2/3/13 8 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
9
VIPS Protocol (cont.)
• Simplifies the protocol to just two states (VI) • Write-‐throughs eliminate the need to track writers at the directory → Area reduc%on
• No indirec%on for read misses (performance win) → Correct shared data always at the LLC
• Supports sequen%al consistency – Same consistency model as the more complex MESI – But s%ll … requires invalida%ons, directory, directory blocking … L
2/3/13 9 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
10
VIPS-‐M: directorlyless/invalida%onless
• But what if we have weak consistency? – Provide SC for DATA-‐RACE-‐FREE (DRF) programs [Adve & Hill]
– Significant simplifica%ons are possible!
• Self-‐Invalida%on (SI) for the shared data: – Selec%vely Self-‐Invalidate shared data upon synchroniza%on points (fences, atomic instruc%ons, LL/SC)
– Eliminates INVALIDATION – No need to track readers anymore à no directory – BUT is only compa%ble with Data-‐Race-‐Free (DRF) opera%on: offers SC for DRF
2/3/13 10 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
11
VIPS-‐M: WT Diffs
• SI works for DRF @ cache-‐line granularity – Does not work w/ false sharing because there are no invalida%ons
• Solved by Wri%ng Through DIFFs – Send only the words (or bytes) that are modified – Merge them in the LLC à Mul%ple Writers & Merge (–M)
• NO NEED for per-‐word(byte) dirty bits for the cache! – Dirty bits are only needed while a Delayed WT is
outstanding (V* state) à Delayed WTs & dirty-‐bits exist only while in MSHRs
2/3/13 Uppsala University/Uppsala Innova%on 11

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
12
VIPS-‐M: WT Diffs
• SI works for DRF @ cache-‐line granularity – Does not work w/ false sharing because there are no invalida%ons
• Solved by Wri%ng Through DIFFs – Send only the words (or bytes) that are modified – Merge them in the LLC à Mul%ple Writers & Merge (–M)
• NO NEED for per-‐word(byte) dirty bits for the cache! – Dirty bits are only needed while a Delayed WT is
outstanding à Delayed WTs & dirty-‐bits exist only while in MSHRs
2/3/13 Uppsala University/Uppsala Innova%on 12

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
13
• Eliminate invalida%ons/directory, allow mul%ple writers à magic happens
• Shared read/write protocol SAME as private data – Only difference is WHEN are data put back in the LLC
• Private data à on replacement (Write_BACK) • Shared data à on writes (Write_THROUGH) / sync.
V PrW
DIFF
V
2/3/13 Uppsala University/Uppsala Innova%on 13
VIPS-‐M: Mul%ple-‐Writer-‐Merge (cont.)

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
14
What about data races? • Private & DRF data OK. What about synchroniza%on
data accessed through atomic RMW (Test&Set, Compare&Swap, LL/SC, etc.)?
• The problem is that readers are NOT invalidated – Readers never “see” a new write (unless they get flushed from the cache)
• A synchroniza%on (inten%onal) data-‐race must “see” new writes: For data accessed via atomic instruc%ons: 1. Do not create an L1 copy à Go directly to the LLC where the
Write_throughs are visible 2. For atomic RMW block the LLC line un%l the write_through
2/3/13 Uppsala University/Uppsala Innova%on 14

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
15
Blocking in the LLC is finite: number of cores that can RMW simultaneously
Lock Acquired Lock Released
Lock Acquired Lock Released
2/3/13 Uppsala University/Uppsala Innova%on 15
Synchroniza%on (data race) protocol
L1 Core0
L1 Core1
LLC

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
16
Evalua%on (does it work?)
• Simulated a 16 %led mul%core (16K-‐64K, 8MB L2, 512K %les), SIMICS GEMS – NoC based design – Also have Bus results
• Automa%c classifica%on of data to private, shared (& read-‐only) through the page table/TLB – Page granularity (1 word shared à whole page shared) – One way only (Priv. à Shared, RO à W) – Be|er results with finer grain classifica%on
2/3/13 16 Uppsala University/Uppsala Innova%on 16

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
17
Performance Results
• VIPS-‐M be|er than MESI (~5%)
2/3/13 17 Uppsala University/Uppsala Innova%on 17
Barnes
CholeskyFFT
FMM LUOcean
Radiosity
Raytrace
Volrend
Water-Nsq
Water-Sp
Em3d
Tomcatv
Cannealx264
Average
0.00.20.40.60.81.01.21.41.61.82.0
No
rma
lize
d e
xecu
tion
tim
e
Hammer Directory Write-through VIPS VIPS-M
2.83 2.42 2.85 2.19 2.13 2.12 2.21
faster writes (no write-misses), faster reads (no directory indirection), and less traffic in the NoC.

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
18
Power Results
• Power for LLC & NoC • VIPS-‐M be|er than MESI (25%): no superfluous coherence traffic, no directory access, WT DIFFs
2/3/13 18 Uppsala University/Uppsala Innova%on 18
Barnes
CholeskyFFT
FMM LUOcean
Radiosity
Raytrace
Volrend
Water-Nsq
Water-Sp
Em3d
Tomcatv
Cannealx264
Average
0.0
0.5
1.0
1.5
2.0
2.5
3.0
No
rma
lize
d e
ne
rgy
con
sum
ptio
n
LLC Network
8.3 5.3 4.2 5.0 8.8 22.9 5.1 15.5 9.6 56.2 3.3 7.0
1. Hammer 2. Directory 3. Write-through 4. VIPS 5. VIPS-M

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
19
VIPS Unique Proper%es
• VIPS-‐M à Self-‐Invalida%on AND Self-‐Downgrade: – VIPS coherence is truly distributed. Coherence decisions are taken independently without any inter-‐core interac%on à Simplifies whole system design
• Strictly Request-‐Response from the L1s to the LLC – No requests from LCC to L1s – No traffic among L1s – Only L1àLLC
• Implica%ons …
2/3/13 19 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
20
Implica%ons
• NOC simplifica%on: – No need to talk to other nodes, only to LLC – Simple topologies: cores “around” the LLC, fat trees with the LLC at the root, …
• Seamless scaling to Mul%ple Buses • Simplifies all aspects of the memory hierarchy, e.g., NoC or virtual caches
2/3/13 20 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
21
Mul%ple Buses
2/3/13 21 Uppsala University/Uppsala Innova%on
C
L1
C
L1
C
L1
C
L1
Bus
LLC

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
22
Mul%ple Buses (cont.)
2/3/13 22 Uppsala University/Uppsala Innova%on
C
L1
C
L1
C
L1
C
L1
Bus LL0
LL1
LL2
LL3
Bus
Bus
Bus
Snooping on 4 buses ? à 5 tag arrays or à 5-ported tags …
VIPS does not have Snooping … à Multiple buses for free!
BW Bottleneck à Snooping Bottleneck

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
23
Physical Address Coherence
2/3/13 23 Uppsala University/Uppsala Innova%on
C
T
L1
C
T
L1
C
T
L1
C
T
L1
Network
LLC/Directory (for MESI)
C: Core T: TLB
Virtual Address
Physical Address

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
24
Virtual Address Coherence
2/3/13 24 Uppsala University/Uppsala Innova%on
C
L1
C
L1
C
L1
C
L1
Network
LLC/Directory (for MESI)
Virtual Address
Physical Address
T/B T/B T/B T/B VA à PA Reverse PA à VA
VA à PA à VA
VIPS-M has only L1 à LLC req.-resp. traffic
C: Core T/B: TLB and BLT (reverse TLB)

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
25
Virtual Address Coherence
ARM Nov. 2 2012 25 Uppsala University/Uppsala Innova%on
C
L1
C
L1
C
L1
C
L1
LLC
Virtual Address
Physical Address
T
Network
VIPS allows a single TLB (not practical for MESI)
NO TLB COHERENCE NEDDED!

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
26
Virtual Address Coherence
ARM Nov. 2 2012 26 Uppsala University/Uppsala Innova%on
C
L1
C
L1
C
L1
C
L1
LLC
Virtual Address
Physical Address
T
Network ARM
L1
T
System Network
Can Freely mix VA & PA coherence

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
27
Virtual Address Coherence
ARM Nov. 2 2012 27 Uppsala University/Uppsala Innova%on
C
L1
C
L1
C
L1
C
L1
LLC
Virtual Address
Physical Address
T
Network
ARM
L1
T
System Network
ARM
L1
T

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
28
Summary • Simplest, cost-‐less protocols, exceeding MESI:
– VIPS: Simpler than MESI, directory protocol, SC – VIPS-‐M: directory-‐less (broadcast-‐less/snoop-‐less) DRF – Support for synchroniza%on (DR) without invalida%ons – On a NoC: Eliminates directories, (coherent) write misses, Read indirec%on (always find correct data in the LLC)
– On a bus: Eliminates all snooping • Significant implica%ons on NoC, Bus and VM
– Allows coherence of virtual caches (even with synonyms) • A la Carte Coherence: there when you need it
(mul%threaded workloads); gone when you don’t (mul%programmed workloads or message passing)
2/3/13 Uppsala University/Uppsala Innova%on 28

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
29
Thank you!
2/3/13 29 Uppsala University/Uppsala Innova%on
Prac%cally Costless Coherence for GPUs and Manycore Accelerators
30
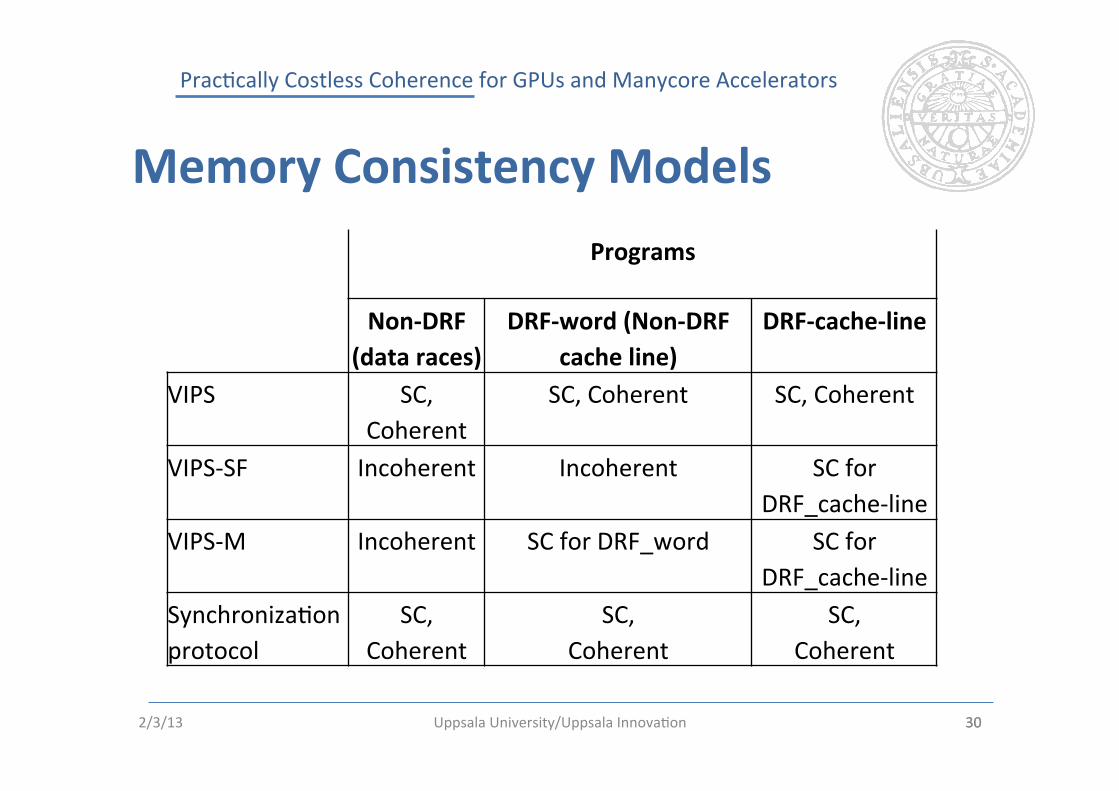
Memory Consistency Models Programs
Non-‐DRF (data races)
DRF-‐word (Non-‐DRF cache line)
DRF-‐cache-‐line
VIPS SC, Coherent
SC, Coherent SC, Coherent
VIPS-‐SF Incoherent Incoherent SC for DRF_cache-‐line
VIPS-‐M Incoherent SC for DRF_word SC for DRF_cache-‐line
Synchroniza%on protocol
SC, Coherent
SC, Coherent
SC, Coherent
2/3/13 Uppsala University/Uppsala Innova%on 30

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
31
Selec%ve Flush
Barnes
CholeskyFFT
FMM LUOcean
Radiosity
Raytrace
Volrend
Water-Nsq
Water-Sp
Em3d
Tomcatv
Cannealx264
Average
0.010.020.030.040.050.060.070.080.090.0
100.0
Pe
rce
nta
ge
of
blo
cks
Invalid Private Shared-Read-Only Shared-Written
2/3/13 31 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
32
Misses
2/3/13 32 Uppsala University/Uppsala Innova%on
Barnes
CholeskyFFT
FMM LUOcean
Radiosity
Raytrace
Volrend
Water-Nsq
Water-Sp
Em3d
Tomcatv
Cannealx264
Average
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
Ca
che
mis
s cl
ass
ifica
tion
Cold-cap-confCoherence
Selective-flushingWrite-through
5.2 1.71. Directory2. VIPS-M

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
33
In directory-‐based coherence:
• WT eliminates the need to track the writer @ the directory – Correct data are always @ the LLC
• SF eliminates the need to track readers @ the directory – No need to invalidate anyone
è The directory is gone
(Data classifica%on is handled by the Page Table & TLBs so no directory is needed) 2/3/13 33 Uppsala University/Uppsala Innova%on

Prac%cally Costless Coherence for GPUs and Manycore Accelerators
34
In snooping-‐based coherence:
• Data classifica%on + WT eliminate snoops on reads: – No need to see who else is reading to determine the degree of sharing (S state, from M,E)
– No need to see who is reading to supply it the data à no need to snoop on reads
• SF eliminates invalida%ons à no need to snoop on writes
è Snooping is gone
2/3/13 34 Uppsala University/Uppsala Innova%on