predicate-aware scheduling: a technique for reducing resource constraints mikhail smelyanskiy, scott...
Post on 19-Dec-2015
213 views
TRANSCRIPT

Predicate-Aware Scheduling:A Technique for Reducing
Resource Constraints
Mikhail Smelyanskiy, Scott Mahlke, Edward Davidson
Department of EECS
University of Michigan
Hsien-Hsin (Sean) LeeSchool of ECE
Georgia Institute of Technology

2
Motivation
Predication eliminates branch instructions• but increases resource requirements
Predicate-aware scheduling oversubscribes resources• reduces resource requirements
• reduces schedule length
Abr cond 0: A
1: p1,p2=pred_def(cond)
2: B if p1
3: C if p2
4: D
B
D
C
FT
0: A
1: p1,p2=pred_def(cond)
2: B if p1 C if p2
3: D

3
Potential for Disjoint Operations
Combining reduces dynamic operation count by 13%
40
50
60
70
80
90
100
cjpeg
djpeg
epic
unep
ic
g721
enco
de
g721
deco
de
ghos
tscrip
t
gsm
deco
de
gsm
enco
de
mes
amipm
ap
mpe
g2dec
mpe
g2enc
pegw
itdec
pegw
itenc
rasta
rawca
udio
rawda
udio
aver
age
%
87

4
Outline
Motivation Resource Pressure Problem in Predicated Code PRAVO: PRedicate-Aware VLIW Processor Predicate-aware Scheduling Performance Results Conclusion and Future Work

5
Modulo Scheduling Example
for(i=0; i < im_size; i++) {
if (q_im[i] ≥ 1)
res[i] = q_im[i] * bin_size – correction;
else if (q_im[i] ≤ -1)
res[i] = q_im[i] * bin_size + correction;
else
res[i] = bin_size + correction;
}
op1: t1 = load(i1, q_im) if Top2: p1,p2=pred_def (t1 ≥ 1) if Top3: t2 = multsub(t1, tbs, tcor) if p1op4: store(i1, res, t2) if p1op5: p3,p4 = pred_def (t1 ≤ -1) if p2op6: t2 = multadd(t1, tbs, tcor) if p3op7: store(i1, res, t2) if p3op8: t2 = add(tbs, tcor) if p4op9: store(i1++, res, t2) if p4op10: if (i++ < im_size) goto op1 if T
Source Code Predicated Code
Three control paths: PT, PFT, PFF

6
Traditional Modulo Schedule (Rau 94)
Time Iteration i Iteration i + 1
0 op1
1
2 op2
3 op5
4 op3 op10
5 op6 op1
6 op8
7 op4 op2
8 op7 op5
9 op9 op3 op10
10 op6
11 op8
12 op4
13 op7
14 op9
Modulo Schedule Modulo Scheduled
Loop Kernel
ALU MEM BR
I0 op6 op1
I1 op8
I2 op2 op4
I3 op5 op7
I4 op3 op9 op10
II=5
II=5

7
Two Predicate-Aware Modulo Schedules
Modulo Scheduled Loop Kernel 1
ALU MEM BR
op3 op6 op1
op8 op7
op2 op9
op5 op4 op10
FW = 3 II = 4
Modulo Scheduled Loop Kernel 2
ALU MEM BR
op3 op6 op8 op1
op5 op4 op7
op2 op9 op10
FW = 4 II = 3
Resource oversubscription can produce more efficient schedules (if colored operations can share entry)
Larger Fetch Width (FW) allows more oversubscription and faster schedule

8
Must-use Resources May-use
Baseline Architecture Model
Predicate Register File is only accessed in EXECUTE stageResources from FETCH to EXECUTE are unconditionally
reserved
FE
TC
H
DIS
PA
TC
H
DE
CO
DE
RE
GIS
TE
R
RE
AD
WR
ITE
BA
CK
Predicate Register File
PR
ED
RE
AD
& EX
EC
UT
E

9
PR
ED
RE
AD
& DIS
PA
TC
H
DE
CO
DE
Must-use Resources May-use ResourcesF
ET
CH
RE
GIS
TE
R
RE
AD
WR
ITE
BA
CK
Predicate Register File (PRF)
EX
EC
UT
E
Predicate-aware Architecture (PRAVO)
PRF is accessed early in DISPATCH stage• increases predicate defining operation latency

10
PR
ED
RE
AD
& DIS
PA
TC
H
DE
CO
DE
Must-use Resources May-use ResourcesF
ET
CH
RE
GIS
TE
R
RE
AD
WR
ITE
BA
CK
EX
EC
UT
E
Predicate-aware Architecture (PRAVO)
DECODE and DISPATCH are reversed
Predicate Register File (PRF)

11
Predicate defining operation edge latency adjustment ResMII computation Predicate-Aware Reservation Table
Three Main Changes to Conventional Scheduler
Build DDG
Cyclic Scheduler
Acyclic Scheduler
Compute ResMII / RecMII
Reservation
Tables51
2 3
4

12
Data Dependence Graph Latency Adjustment
Time A M
0 p1,p2= pred_def
1 +1 if p1 ld if p2
2 +3 if p2
3 +4 if p2
4 +2 if p1
Time A M
0 p1,p2= pred_def
1
2 +1 if p1 ld if p2
3 +3 if p2 +2 if p1
4 +4 if p2
Time A M
0 p1,p2= pred_def
1 ld if p2
2 +1 if p1 +3 if p2
3 +2 if p1 +4 if p2
Original Brute force Selective
p1,p2=pred_def
+1 if p1 ld if p2
+3 if p2
+4 if p2
1 1
+2 if p1
1 1
1
p1,p2=pred_def
+1 if p1 ld if p2
+3 if p2
+4 if p2
2 2
+2 if p1
1 1
1
p1,p2=pred_def
+1 if p1 ld if p2
+3 if p2
+4 if p2
2 1
+2 if p1
1 1
1

13
Mmay
Computation of Resource-Constrained Lower Bound
Predicate-aware ResMII computation• “first-fit” combining
• Fetch Width (FW) resource constraint
FWmust
Original (ResMII=5) Predicate-Aware (ResMII=3)
MA
+3 if p2
+4 if p2
+1 if p1
+2 if p1
Amay
p1,p2=
+3 if p2
+4 if p2
ld if p
FW
ld if p2
+2 if p1
p,p=
+1 if p1
p1,p2=pred_def
+1 if p1 ld if p2
+3 if p2
+4 if p2
1 1
+2 if p1
1 1
1
14
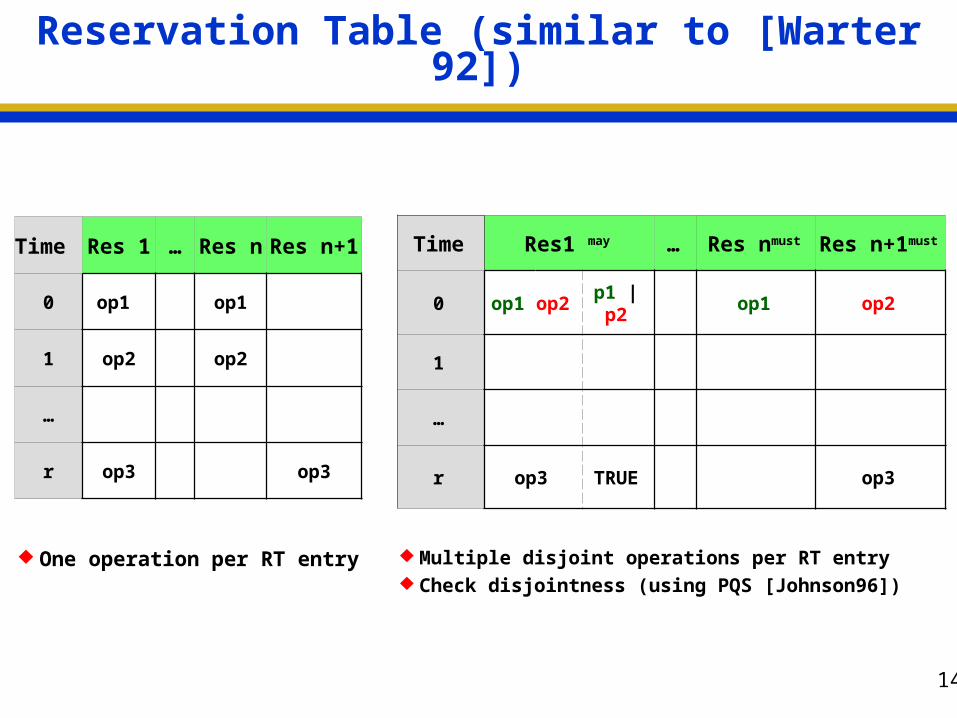
Reservation Table (similar to [Warter 92])
One operation per RT entry
Time Res 1 … Res n Res n+1
0 op1 op1
1 op2 op2
…
r op3 op3
Time Res1 may … Res nmust Res n+1must
0 op1 op2 p1 | p2 op1 op2
1
…
r op3 TRUE op3
Multiple disjoint operations per RT entry Check disjointness (using PQS [Johnson96])
15
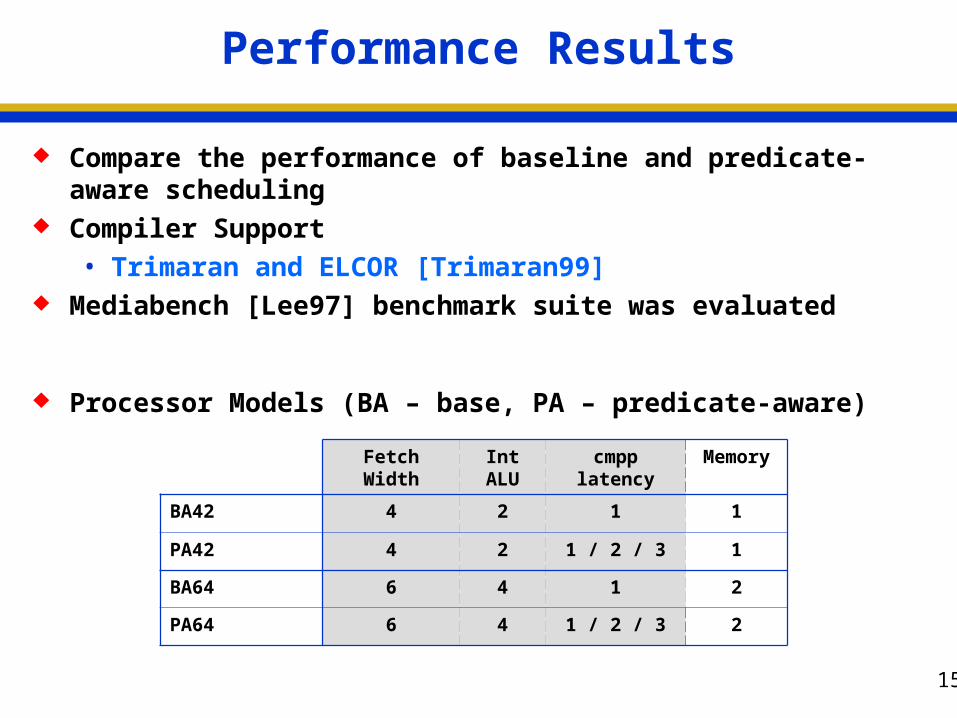
Performance Results
Compare the performance of baseline and predicate-aware scheduling
Compiler Support
• Trimaran and ELCOR [Trimaran99] Mediabench [Lee97] benchmark suite was evaluated
Processor Models (BA – base, PA – predicate-aware)
Fetch Width Int ALU cmpp latency Memory
BA42 4 2 1 1
PA42 4 2 1 / 2 / 3 1
BA64 6 4 1 2
PA64 6 4 1 / 2 / 3 2

16
Predicate-aware Speedup over Baseline
(PA42 vs. BA42)
0.97
1
1.03
1.06
1.09
1.12
1.15
1.18
1.21
Sp
eed
up
cmpplat1
cmpplat2
cmpplat3
1.39 / 1.37 / 1.35
Speedup is only due to improvable PA regions Speedup decreases for higher latency and wider machine
aver
age
17
1
1.04
1.08
1.12
1.16
1.2
cmpplat1 cmpplat2 cmpplat3 cmpplat1 cmpplat2 cmpplat3
Sp
eed
up
Overall PA Acyclic - 29% of Execution Time PA Cyclic - 39% of Execution Time
4-wide PRAVO vs. 4-wide BASE 6-wide PRAVO vs. 6-wide BASE
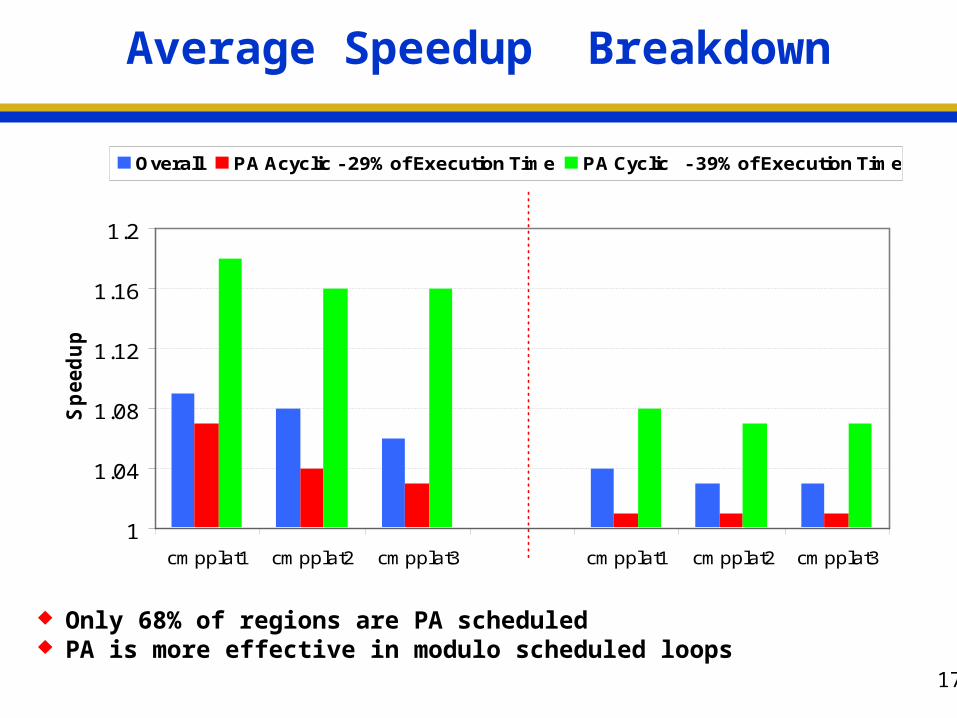
Average Speedup Breakdown
Only 68% of regions are PA scheduled PA is more effective in modulo scheduled loops

18
Summary and Future Work
Summary
Predicate-aware Scheduling• reduces resource constraints in predicated code
• is supported by PRAVO architecture
• is effective in cyclic regions (16% speedup on 4-wide PRAVO)
Future work• More resource sharing can be achieved by combining
probabalistically disjoint operations

Q&A and Suggestions

Backup Foils

21
Modulo Scheduling Using PART
Time A may M may B maymust
IW1must
IW2must
IW3
0 op1 PT | PFT | PFF op1
1
2 op2 PT | PFT | PFF op2
3 op10 PT | PFT | PFF op10
4 op5 PT | PFT | PFF op5
5 op3 PT op3
6
7 op6 op8 PFT | PFF op6 op8
8
9 op4 op9 PT | PFF op4 op9
10 op7 PFT op7
11
22
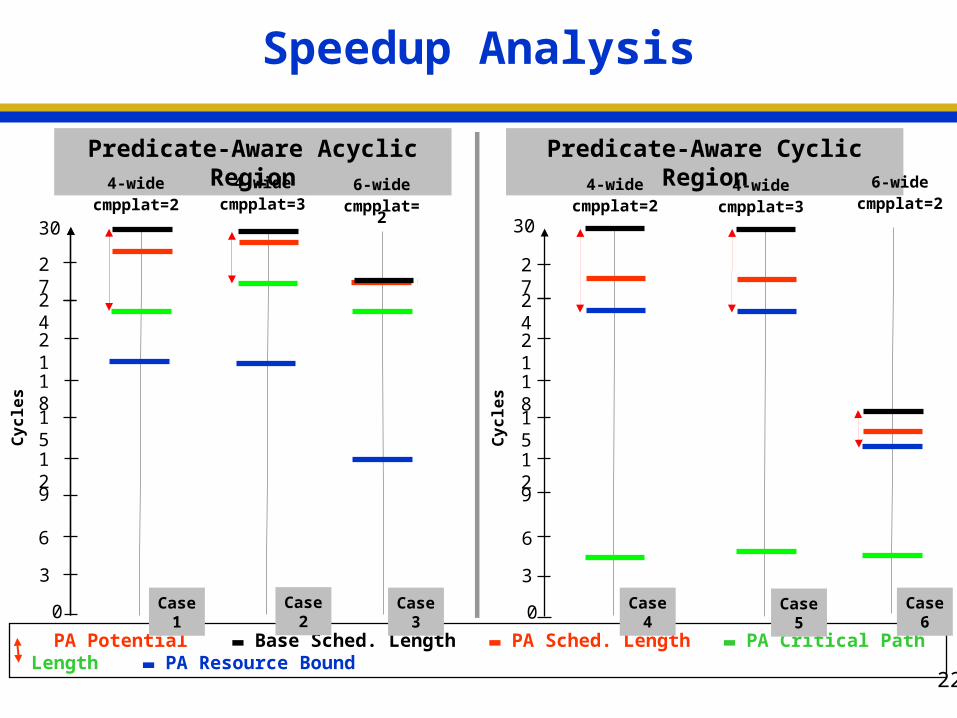
Speedup Analysis
PA Potential ▬ Base Sched. Length ▬ PA Sched. Length ▬ PA Critical Path Length ▬ PA Resource Bound
Predicate-Aware Acyclic Region Predicate-Aware Cyclic Region
0
Cyc
les
3
6
9
12
18
15
21
24
27
30
0
Cyc
les
3
6
9
12
18
15
21
24
27
30
4-widecmpplat=2
Case 1
6-widecmpplat=2
Case 3
6-widecmpplat=2
Case 6
4-widecmpplat=3
Case 2 Case 5
4-widecmpplat=3
4-widecmpplat=2
Case 4