predictable+integraon++ of+safety4cri/cal+so6ware++ … · 2013-04-08 · predictable+integraon++...
TRANSCRIPT

Predictable Integra/on of Safety-‐Cri/cal So6ware
on COTS-‐based Embedded Systems
Marco Caccamo
University of Illinois at Urbana-‐Champaign

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems 2
• Part of this research is joint work with prof. Lui Sha and prof. Rodolfo Pellizzoni
• This presenta/on is from selected research sponsored by – Na/onal Science Founda/on (NSF), Office of Naval Research (ONR) – Lockheed Mar/n Corpora/on – Rockwell Collins
• Graduate students and Postdocs involved in this research: Stanley Bach, Heechul Yun, Renato Mancuso, Roman Dudko, Emiliano BeU, Gang Yao
References • E. BeU, S. Bak, R. Pellizzoni, M. Caccamo and L. Sha, "Real-‐Time I/O Management System with COTS
Peripherals”, IEEE Transac/ons on Computers (TC), Vol. 62, No. 1, pp. 45-‐58, January 2013. • R. Pellizzoni, E. BeU, S. Bak, G. Yao, J. Criswell, M. Caccamo, R. Kegley, "A Predictable Execu/on Model
for COTS-‐based Embedded Systems", Proceedings of 17th RTAS, Chicago, USA, April 2011. • G. Yao, R. Pellizzoni, S. Bak, E. BeU, and M. Caccamo, "Memory-‐centric scheduling for mul/core hard
real-‐/me systems", Real-‐Time Systems Journal, Vol. 48, No. 6, pp. 681-‐715, November 2012. • H. Yun, G. Yao, R. Pellizzoni, M. Caccamo, L. Sha, "MemGuard: Memory Bandwidth Reserva/on System
for Efficient Performance Isola/on in Mul/-‐core Plagorms", to appear at IEEE RTAS, April 2013. • R. Mancuso, R. Dudko, E. BeU, M. Cesa/, M. Caccamo, R. Pellizzoni, "Real-‐Time Cache Management
Framework for Mul/-‐core Architectures", to appear at IEEE RTAS, Philadelphia, USA, April 2013.
Acknowledgements
1

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Outline
• Mo/va/on • PRedictable Execu/on Model (PREM)
– Peripheral scheduler & real-‐/me bridge – Memory-‐centric scheduling
• MemGuard – Memory bandwidth Isola/on
• Colored Lockdown – Cache space management
3

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Real-‐Time Applica/ons
4
• Resource intensive real-‐/me applica/ons – Mul/media processing(*), real-‐/me data analy/c(**), object tracking
• Requirements – Need more performance and cost less è Commercial Off-‐The Shelf (COTS) – Performance guarantee (i.e., temporal predictability and isola/on)
(*) ARM, QoS for High-‐Performance and Power-‐Efficient HD Mul;media, 2010 (**) Intel, The Growing Importance of Big Data and Real-‐Time Analy;cs, 2012

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Modern System-‐on-‐Chip (SoC)
• More cores – Freescale P4080 has 8 cores
• More sharing – Shared memory hierarchy (LLC, MC, DRAM) – Shared I/O channels
5
More performance Less energy, Less cost
But, isola;on?

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
• In a mul/core chip, memory controllers, last level cache, memory, on chip network and I/O channels are globally shared by cores. Unless a globally shared resource is over provisioned, it must be par//oned/reserved/scheduled. Otherwise – Complexity, cost and schedule: The schedulability analysis, tes/ng and temporal cer/fica/on of an IMA par//on in a core will also depend on tasks running in other cores
– Safety Concerns: The change of so6ware in one core could cause the tasks in other cores’ IMA par//ons missing their deadlines. This is unacceptable!
6
SoC: challenges for RT safety-‐cri/cal systems

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Problem: Shared Memory Hierarchy
• Shared hardware resources • OS has linle control
Core1 Core2 Core3 Core4
DRAM
App 1 App 2 App 3 App 4
7
Memory Controller (MC)
Shared Last Level Cache (LLC) Space sharing
Access conten/on

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems 7
Problem: Task-‐Peripheral conflict (1 core)
• Task-‐peripheral conflict: – Master peripheral working for Task B. – Task A suffers cache miss. – Processor ac/vity can be stalled due to
interference at the FSB level.
• How relevant is the problem? – Up to 49% increased wcet for memory
intensive tasks. – Conten/on for access to main memory
can greatly increase a task worst-‐case computa/on /me!
CPU
Front Side Bus
DDRAM
Host PCI Bridge
Master peripheral
Slave peripheral
Task A Task B
This effect MUST be considered in wcet computa/on!!
Sebas>an Schonberg, Impact of PCI-‐Bus Load on Applica>ons in a PC Architecture, RTSS 03
PCI Bus

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Experiment: Task and Peripherals
• Experiment on Intel Plagorm, typical embedded system speed. • PCI-‐X 133Mhz, 64 bit fully loaded by traffic generator peripheral. • Task suffers con/nuous cache misses. • Up to 44% wcet increase.
8

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Experiment: 2 Cores Interference
• Task A suffers max number of cache misses (92% stall /me). • Task B has variable cache stall /me.
WCET increase propor>onal to cache stall >me
Max WCET increase ~= cache stall >me of task A
• Adding PCI-‐E peripheral interference -‐> 196% WCET increase!
Mul/core interference is a serious problem!!!
9

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Transac>on Length
Bandwidth (256B)
No interference 596MB/s (100%)
128 bytes 441MB/s (74%)
256 bytes 346MB/s (58%)
512 bytes 241MB/s (40%)
Problem: Bus Conten/on
• Two DMA peripherals transmiUng at full speed on PCI-‐X bus.
• Round-‐robin arbitra/on does not allow /ming guarantees. RAM
CPU
10

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Problem: Bus Conten/on
0 8 16
t
t
3
NO BUS SHARING
RAM
6
• Two DMA peripherals transmiUng at full speed on PCI-‐X bus.
• Round-‐robin arbitra/on does not allow /ming guarantees.
CPU
11

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Problem: Bus Conten/on
RAM
0 8 16
t
t
6
BUS CONTENTION, 50% / 50%
10
4
• Two DMA peripherals transmiUng at full speed on PCI-‐X bus.
• Round-‐robin arbitra/on does not allow /ming guarantees.
CPU
11

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Problem: Bus Conten/on
RAM
0 8 16
t
t
9
BUS CONTENTION, 33% / 66%
9
Integra/on Nightmare!!!
• Two DMA peripherals transmiUng at full speed on PCI-‐X bus.
• Round-‐robin arbitra/on does not allow /ming guarantees.
CPU
11
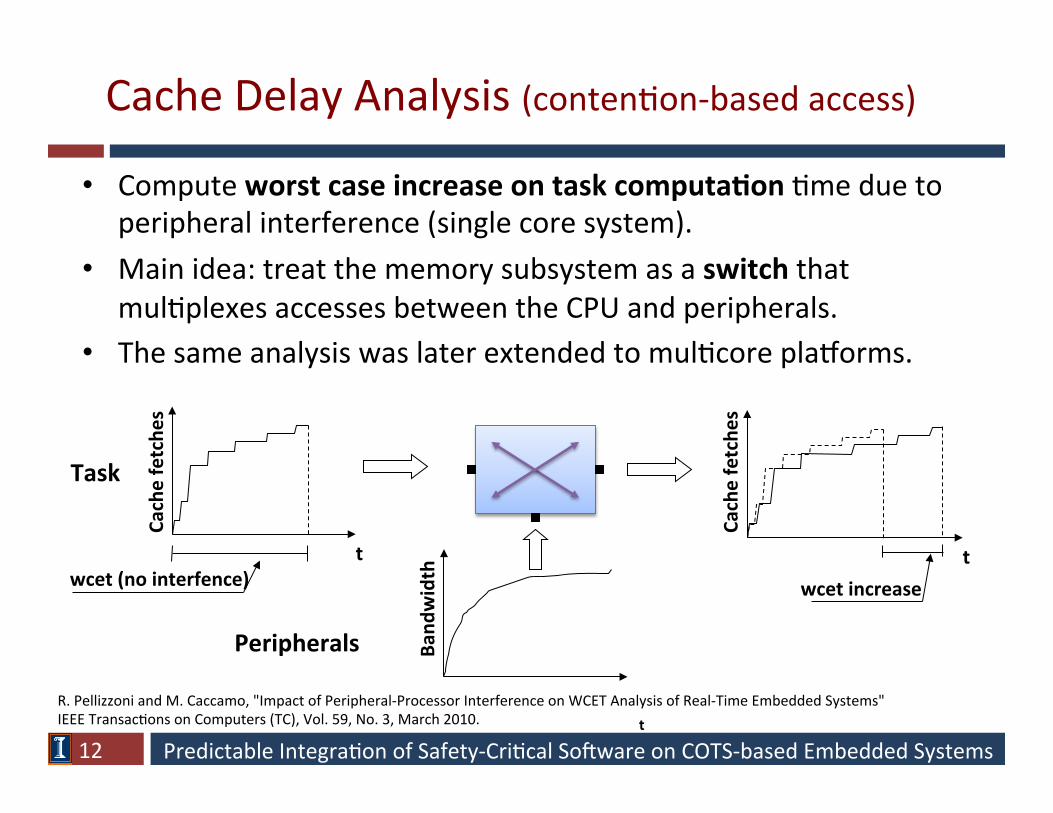
Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
• Compute worst case increase on task computa>on /me due to peripheral interference (single core system).
• Main idea: treat the memory subsystem as a switch that mul/plexes accesses between the CPU and peripherals.
• The same analysis was later extended to mul/core plagorms.
Cache Delay Analysis (conten/on-‐based access)
t
Cache fetche
s
t
Band
width t
Cache fetche
s
wcet increase
Task
Peripherals
wcet (no interfence)
12
R. Pellizzoni and M. Caccamo, "Impact of Peripheral-‐Processor Interference on WCET Analysis of Real-‐Time Embedded Systems" IEEE Transac/ons on Computers (TC), Vol. 59, No. 3, March 2010.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Modeling I/O traffic: Peripheral Arrival Curve
• Key idea: the maximum task delay depends on the amount of peripheral traffic (single core).
• : maximum amount of /me required by all peripherals to access main memory.
)(tiα
• Can be obtained using… – Measurement – Distributed traffic analysis – Enforced through engineering solu/on (more on that later…)
14
)(tiα

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
The Need for Engineering Solu/ons
• Analysis bounds are /ght but depend on very peculiar arrival panerns.
• Average case significantly lower than worst case. – Main issue: COTS arbiters are not designed for predictability.
• We propose engineering solu/ons to: 1. schedule memory accesses at high level (coarse granularity)
è memory-‐centric real-‐/me scheduling, 2. control cores’ memory bandwidth usage, 3. manage cache space in a predictable manner
26

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Outline
• Mo/va/on • PRedictable Execu/on Model (PREM)
– Peripheral scheduler & real-‐/me bridge – Memory-‐centric scheduling
• MemGuard – Memory bandwidth Isola/on
• Colored Lockdown – Cache space management
18

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Peripheral Scheduling
CPU
RAM
IMPLICIT SCHEDULE ENFORCEMENT
0 8 16
t
t
3
BLOCK BLOCK
• Solu/on: enforce peripheral schedule (single resource scheduling).
• No need to know low-‐level parameters! COTS peripherals do not provide
block func/onality, so how do we do this?
28

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Real-‐Time I/O Management System
• Real-‐Time Bridge interposed between peripheral and bus.
• RT-‐Bridge buffers incoming/
outgoing data and delivers it predictably.
• Peripheral Scheduler enforces traffic isola/on.
CPU
North Bridge PCIe
South Bridge
ATA
PCI-‐X
RT Bridge
RT Bridge
RT Bridge
RT Bridge
Peripheral Scheduler
RAM
29
E. BeU, S. Bak, R. Pellizzoni, M. Caccamo and L. Sha, "Real-‐Time I/O Management System with COTS Peripherals" IEEE Transac/ons on Computers (TC), Vol. 62, No. 1, pp. 45-‐58, January 2013.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Peripheral Scheduler • Peripheral Scheduler receives data_rdyi informa/on from
Real-‐Time Bridges and outputs blocki signals. • Server provides isola/on by enforcing a /ming reserva/on. • Fixed priority, cyclic execu/ve etc. can be implemented in HW
with very linle area.
Server1 Scheduler (FP)
READY1
EXEC1 EXEC1 = READY1
EXEC2 = READY2 and not EXEC1
EXECi = READYi and not EXEC1 … and not EXECi-‐1
. . .
. . .
READY2
EXEC2
READYi
EXECi
. . .
. . .
data_rdy1 block1
data_rdy2 block2
data_rdyi blocki
Server2
Serveri
30

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Real-‐Time Bridge
FPGA CPU
PLB
Interrupt Controller
DMA Engine
Local RAM
PCI
Bridge
IntMain
IntFPG
A
block
System + PCI
Host CPU
Main Memory
PCI Controlled Peripheral
FPGA
• FPGA System-‐on-‐Chip design with CPU, external memory, and custom DMA Engine.
• Connected to main system and peripheral through available PCI/PCIe bridge modules.
Memory Controller
PCI
Bridge
31
data_rdy

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Real-‐Time Bridge
• The controlled peripheral reads/writes to/from Local RAM instead of Main Memory (completely transparent to the peripheral).
• DMA Engine transfers data from/to Main Memory to/from Local RAM.
FPGA CPU
PLB
Interrupt Controller
DMA Engine
Local RAM
PCI
Bridge
IntMain
IntFPG
A
block
data_rdy
System + PCI
Host CPU
Main Memory
PCI Controlled Peripheral
FPGA
Memory Controller
PCI
Bridge
32

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Peripheral Virtualiza/on
• RT-‐Bridge supports peripheral virtualiza/on.
• Single peripheral (ex: Network Interface Card) can service different so6ware par//ons.
• HW virtualiza/on enforces strict /ming isola/on.
33

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Implemented Prototype
• Xilinx TEMAC 1Gb/s ethernet card (integrated on FPGA). • Op/mized virtual driver implementa/on with no so6ware
packet copy (PowerPC running Linux). • Full VHDL HW code and SW implementa/on available.
34

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Evalua/on • 3 x Real-‐Time Bridges, 1 x Traffic
Generator with synthe/c traffic.
• Rate Monotonic with Sporadic Servers.
Scheduling flows without peripheral scheduler (block always low) leads to deadline misses!
Peripheral Transfer Time
Budget Period
RT Bridge 7.5ms 9ms 72ms
Generator 4.4ms 5ms 8ms
U/liza/on 1, harmonic periods.
Generator
RT-‐Bridge
RT-‐Bridge
RT-‐Bridge
35

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Evalua/on Peripheral Transfer
Time Budget Period
RT Bridge 7.5ms 9ms 72ms
Generator 4.4ms 5ms 8ms
No deadline misses with peripheral scheduler
Generator
RT-‐Bridge
RT-‐Bridge
RT-‐Bridge
• 3 x Real-‐Time Bridges, 1 x Traffic Generator with synthe/c traffic.
• Rate Monotonic with Sporadic Servers.
36

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Testbed (single core, distributed)
• Embedded testbed used to prove the applicability of our techniques.
• System objec/ve: control a 3DOF Quanser helicopter. – Non-‐linear control. – 100 Hz sensing and actua/on.
• End-‐to-‐end delay control using: – I/O Management System. – Real-‐Time Bridge
38

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
• Sensor Node performs sensing/actua/on. • Control node executes control algorithm. • Data exchanged on real-‐/me network.
Testbed (single core, distributed)
Sensor Node
Control Node
Quanser 3DOF helicopter RT Network
39

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Testbed
Sensing / actua/on node
Control Node
RT Switch
CPU RAM Mem logic
Peripheral Scheduler
PCI
RT Bridge
Traffic Generator
RT NIC Card
RT NIC Card
ADC/DAC Card
NIC
GUI Node
NIC
Sensing data
Actua/on
Disturb
40

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Real-‐Time Bridge Demo
41

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Predictable Execu/on Model (PREM uni-‐core)
• (The rule) Real-‐/me embedded applica/ons should be compiled according to a new set of rules to achieve predictability
• (The effect) The execu/on of a task can be dis/nguished between a memory intensive phase (with cache prefetching) and a local computa/on phase (with cache hits)
• (The benefit)High-‐level coscheduling can be enforced among all ac/ve components of a COTS system è conten/on for accessing shared resources is implicitly resolved by the high-‐level coscheduler without relaying on low level arbiters
30
R. Pellizzoni, E. BeU, S. Bak, G. Yao, J. Criswell, M. Caccamo, R. Kegley, "A Predictable Execu/on Model for COTS-‐based Embedded Systems", Proceedings of 17th IEEE Real-‐Time and Embedded Technology and Applica/ons Symposium (RTAS), Chicago, USA, April 2011.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Memory-‐centric scheduling (mul/core)
• It uses the PREM task model: each task is composed by a sequence of intervals, each including a memory phase followed by a computa/on phase.
• It enforces a coarse-‐grain TDMA schedule for gran/ng memory access to each core.
• Each core can be analyzed in isola;on as if tasks were running on a “single-‐core equivalent ” pla[orm.
G. Yao, R. Pellizzoni, S. Bak, E. BeU, and M. Caccamo, "Memory-‐centric scheduling for mul/core hard real-‐/me systems", Real-‐Time Systems Journal, Vol. 48, No. 6, pp. 681-‐715, November 2012.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Two cores example: TDMA slot of core 1
memory phase computa/on phase
J1 J2 J3
4 12 8 0
With a coarse-‐grained TDMA, tasks on one core can perform the memory access only when the TDMA slot is granted
Core Isola>on

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Memory-‐centric scheduling: three rules
• Assump/on: fixed priority, par//oned scheduling
• Rule 1: enforce a coarse-‐grain TDMA schedule among the cores for gran/ng access to main memory;
• Rule 2: raise scheduling priority of memory phases over execu/on phases when TDMA memory slot is granted;
• Rule 3: memory phases are non-‐preemp/ve.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Raise priority of mem. phases during TDMA slot
memory phase computa/on phase
J1 J2 J3
4 12 8 0
J1 J2 J3

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Make memory phases non-‐preemp/ve
J1 J2 J3
4 12 8 0
J1 J2 J3
4 12 8 0

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Summary of two cores example
43
J1 J2 J3
4 12 8 0
J1 J2 J3
4 12 8 0
J1 J2 J3
4 12 8 0
Execution Phase Memory Phase TDMA Memory Slot
(a) TDMA-only Scheduling
(b) TDMA + Memory Promotion Scheduling
(c) Real-Time Memory Centric Scheduling
Rule 1 – TDMA memory schedule
Rule 2 – Priori/ze memory phases during a TDMA memory slot
Rule 3 – memory phases are non-‐preemp/ve

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
J1 J2 J3
0
J4 J5
10 20 30 40
Intui/on of response /me analysis
The linearized TDMA model: 1. b is the memory bandwidth assigned to the core (b = TDMA_slot/ TDMA_period). 2. each memory phase is inflated by a factor 1/b; each execu/on phase is inflated
by a factor 1/(1-‐b); 3. Interfering jobs that contribute to worst case response /me can be separated as
a memory chain followed by an execu/on chain;
Execu/on chain Memory chain

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
J1 J2 J3
0
J4 J5
10 20 30 40
Pipelining memory and exec. phases
key observa>ons:
• The inflated memory and execu/on phases can run in parallel. • Only ONE joint job contributes to both memory and execu/on chains (in this
figure, J3 is the joint job).
Execu/on chain Memory chain

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Worst-‐case response /me of Job Ji
2. Memory blocking from one lower priority job
3. Either memory or computa/on from hp(i)
4. Computa/on of job under analysis
1. Upper bound of the memory phase of the joint job
1. Both the memory and the computa/on of the joint job 2. Longest memory phase of one job with lower priority (due to non-‐preemp/ve
memory) 3. The max of memory and computa/on phase for each higher priority job 4. The computa/on phase of the job under analysis

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Schedulability of synthe/c tasks
In an 8-‐core, 10-‐task system, the memory-‐centric scheduling bound is superior to the conten/on-‐based scheduling bound.
Schedulability ra/o

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Schedulability of synthe/c tasks Schedulability
ra/o Ra>o = .5
The contour line at 50% schedulable level

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Outline
• Mo/va/on • PRedictable Execu/on Model (PREM)
– Peripheral scheduler & real-‐/me bridge – Memory-‐centric scheduling
• MemGuard – Memory bandwidth Isola/on
• Colored Lockdown – Cache space management
49

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Memory Interference
• Key observa/ons: – Memory bandwidth(variable) != CPU bandwidth (constant) – Memory controller è queuing/access delay is unpredictable
50
Core
Shared Memory
Core
foreground X-‐axis
background 470.lbm
Intel Core2
L2 L2
1.0
1.2
1.4
1.6
1.8
2.0
2.2
437.leslie3d 462.libquantum 410.bwaves 471.omnetpp
Foreground slowdown ra;o
(1.6GB/s) (1.5GB/s) (1.5GB/s) (1.4GB/s)
(2.1GB/s)

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Memory Access Panern
• Memory access panerns vary over /me • Sta/c resource reserva/on is inefficient
51
Time(ms)
LLC misses LLC misses
Time(ms)

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Memory Bandwidth Isola/on
• MemGuard provides an OS mechanism to enforce memory bandwidth reserva/on for each core
52
H. Yun, G. Yao, R. Pellizzoni, M. Caccamo, L. Sha, "MemGuard: Memory Bandwidth Reserva/on System for Efficient Performance Isola/on in Mul/-‐core Plagorms", to appear at IEEE RTAS, April 2013.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
MemGuard
• Characteris/cs – Memory bandwidth reserva>on system – Memory bandwidth: guaranteed + best-‐effort – Predic>on based dynamic reclaiming for efficient u/liza/on of guaranteed bandwidth
– Maximize throughput by u/lizing best-‐effort bandwidth whenever possible
• Goal – Minimum memory performance guarantee – A dedicated (slower) memory system for each core in mul/-‐core systems
53

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Memory Bandwidth Reserva/on
• Idea – Control interference by regula/ng per-‐core memory traffic – OS monitor and enforce each core’s memory bandwidth usage
• Using per-‐core HW performance counter(PMC) and scheduler
54
10 20 0 Dequeue tasks
Enqueue tasks
Dequeue tasks
Budget
Core ac;vity
2 1
computation memory fetch

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Guaranteed Bandwidth: rmin
• Defini/on – Minimum memory transfer rate
• when requests are back-‐logged in the DRAM controller • worst-‐case access panern: same bank & row miss
• Example (PC6400-‐DDR2*) – Peak B/W: 6.4GB/s – Measured minimum B/W: 1.2GB/s
55 (*) PC6400-‐DDR2 with 5-‐5-‐5 (RAS-‐CAS-‐CL latency seUng)

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Memory Bandwidth Reserva/on
• System-‐wide reserva/on rule – up to the guaranteed bandwidth rmin
m: #of cores
• Memguard approximates a dedicated (ideal) memory subsystem – bandwidth: Bi (bytes/sec) – latency: 1/Bi (sec/byte)
56
Bi ≤ rmin1
m
∑

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Memory Bandwidth Reclaim
• Key objec/ve – U/lize guaranteed bandwidth efficiently
• Regulator – Predicts memory usage based on history – Donates surplus to the reclaim manager at the beginning of every period
– When remaining budget (assigned – donated) is depleted, tries to reclaim from the reclaim manager
• Reclaim manager – Collects the surplus from all cores – Grants reclaimed bandwidth to individual cores on demand
57

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Hard/So6 Reserva/on on MemGuard
• Hard reserva/on (w/o reclaiming) – Guarantee memory bandwidth Bi regardless of other cores – Selec/vely applicable on per-‐core basis
• So6 reserva/on (w/ reclaiming) – Does not guarantee reserved bandwidth due to poten/al mispredic/on
– Error cases can occur due to mispredic/on – Error rate is small (shown in evalua/on)
• Best-‐effort bandwidth – A`er all cores use their given budgets, and before the next period begins, MemGuard broadcasts all cores to con/nue to execute
58

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Evalua/on Plagorm
• Intel Core2Quad 8400, 4MB L2 cache, PC6400 DDR2 DRAM • Modified Linux kernel 3.6.0 + MemGuard kernel module
– hnps://github.com/heechul/memguard/wiki/MemGuard • Used the en/re 29 benchmarks from SPEC2006 and synthe/c benchmarks
59
Core 0
L1-‐I L1-‐D
L2 Cache
Intel Core2Quad
Core 1
L1-‐I L1-‐D
Core 2
L1-‐I L1-‐D
L2 Cache
Core 3
L1-‐I L1-‐D
System Bus
DRAM

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Isola/on Effect of Reserva/on
• Sum b/w reserva/on ≤ rmin (1.2GB/s)à Isola/on – 1.0GB/s(X-‐axis) + 0.2GB/s(lbm) = rmin
60
Isola;on
Core 0: 1.0 GB/s for X-‐axis
Core 2: 0.2 – 2.0 GB/s for lbm
Solo [email protected]/s

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Effects of Reclaiming and Spare Sharing
• Guarantee foreground ([email protected]/s) • Improve throughput of background ([email protected]/s): 368%
61

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Effect of MemGuard
• So6 real-‐/me applica/on on each core. • Provides differen/ated memory bandwidth
– weight for each core=1:2:4:8 for the guaranteed b/w, spare bandwidth sharing is enabled
62

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Outline
• Mo/va/on • PRedictable Execu/on Model (PREM)
– Peripheral scheduler & real-‐/me bridge – Memory centric scheduling
• MemGuard – Memory bandwidth Isola/on
• Colored Lockdown – Cache space management
63

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
LVL3 Cache & Storage Interference
• Inter-‐core interference – The biggest issue wrt modular cer/fica/on – Fetches by one core might evict cache blocks owned by another core
– Hard to analyze!
• Inter-‐task/inter-‐par//on interference • Intra-‐task interference
– Also present in single-‐core systems; intra-‐task interference is mainly a result of cache self-‐evic/on.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Inter-‐Core Interference: Op/ons
• Private cache – It is o6en not the case: majority of COTS mul/core plagorms have last
level cache shared among cores
• Cache-‐Way Par//oning – Easy to apply, but inflexible – Reducing number of ways per core can greatly increase cache conflicts
• Colored Lockdown ç – Our proposed approach – Use coloring to solve cache conflicts – Fine-‐grained assignment of cache resources (page size – 4Kbytes) – Use cache locking instruc/ons to lock “hot” pages of rt cri/cal tasks
è locked pages can not be evicted from cache R. Mancuso, R. Dudko, E. BeU, M. Cesa/, M. Caccamo, R. Pellizzoni, "Real-‐Time Cache Management Framework for Mul/-‐core Architectures", to appear at IEEE RTAS, Philadelphia, USA, April 2013.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
How Coloring Works Dynamic Page ColoringWhen cache conflicts occur
1
2
3
4
...
5
Cache lines IndexPhys Addr. SpaceTask
T1
T2
1
3
3
4
1
= Cache conflict
➔ The position inside the cache of a data chunk depends on the value
of a subset of those bits which compose the physical address. This
group of bits is the so called index
➔ Thus, if two or more pages from the same or different tasks have the
same index, they could map into the same set of cache lines,
causing undesired (self) evictions
02:26 AM
10 23/
startup
memory
access
execution
critical
region
• The posi/on inside the cache of a cache block depends on the value of index bits within the physical address.
• Key idea: the OS decides the physical memory mapping of task’s virtual memory pages è manipulate the indexes to map different pages into non-‐overlapping sets of cache lines (colors)

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
How Coloring Works
• The posi/on inside the cache of a cache block depends on the value of index bits within the physical address.
• Key idea: the OS decides the physical memory mapping of task’s virtual memory pages è manipulate the indexes to map different pages into non-‐overlapping sets of cache lines (colors)
Dynamic Page ColoringPlaying with indexes
1
2
3
4
...
5
Cache lines IndexPhys Addr. SpaceTask
T1
T2
1
3
5
4
2
= Cache conflict
➔ Key idea: manipulate the indexes in order to map different pages
into non-overlapping sets of cache lines
➔ Manipulating indexes means playing with the physical addresses of
the tasks. The aim is to obtain something like this:
02:26 AM
11 23/
startup
memory
access
execution
critical
region

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
How Coloring Works
• You can think of a set associa/ve cache as an array…
. . .
32 ways
16 colors

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
How Coloring Works
• You can think of a set associa/ve cache as an array… • Using only cache-‐way par//oning, you are restricted to assign
cache blocks by columns. • Note: assigning one way turns it into a direct-‐mapped cache!
. . .

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
How Coloring + Locking Works
• You can think of cache as an array… • Combining coloring and locking, you can assign arbitrary
posi/on to cache blocks independently of replacement policy
. . .

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
T1 CPU1
Colored Lockdown Final goal • Aimed model -‐ suffer cache misses in hot memory regions only once:
– During the startup phase, prefetch & lock the hot memory regions – Sharp improvement in terms of WCET reduc>on (and schedulability)
T2 CPU2
startup
memory access
execu/on
T1 CPU1
T2 CPU2
T2 CPU2
hotregion

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
• In the general case, the size of the cache is not enough to keep the working set of all running rt cri/cal tasks.
• For each rt cri/cal task, we can iden/fy some high usage virtual memory regions, called: hot memory regions ( ). Such regions can be iden/fied through profiling.
• Cri/cal tasks do NOT color dynamically linked libraries. Dynamic memory alloca>on is allowed only during the startup phase.
Detecting Hot Regions

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
• How can we detect hot pages? Given an addr. space:
Detecting Hot Regions
hotregion
Ø Their location is unknown
Ø Their absolute virtual memory addresses change from run to run
Process Addr. Space
data
text
heap

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
• Execute the unmodified task inside a profiling environment
• The output is the list of every single accessed virtual memory address
• We keep per-‐page access counters. Honer pages will record a higher number of accesses.
Detecting Hot Regions
Profiling Environment
Observed Task
Ø Instrumentation code added at run-time
Ø Memory accesses are caught

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Detecting Hot Regions
• Rank the virtual pages by number of accesses.
• Since absolute addresses change from run to run, iden/fy each page as a pair of values: – The index of the sec/on which contains the page – The offset, expressed in pages, from the beginning of the sec>on E.g.: virtual page #: 0x8040A → Section #3 (text) + 0x3
• Execute the task again outside the profiling environment to obtain an unaltered list of sec/ons.
• Compute the rela>ve posi/on of a hot page according to the unaltered list of sec/ons.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
• The final memory profile will look like:
Detecting Hot Regions
# + page offset
1 + 0x0002 1 + 0x0004 25 + 0x0000 1 + 0x0001 25 + 0x0003 3 + 0x0000 4 + 0x0000 6 + 0x0002 1 + 0x0005 1 + 0x0000
...
A B C D E I K O P Q
Ø Where A, B, … is the page ranking; Ø Where “#” is the section index;
Ø It can be fed into the kernel to perform selective Colored Lockdown
Ø How many pages should be locked per process? è Task WCET reduction as function of locked pages has approximately a convex shape; convex optimization can be used for allocating cache among rt critical tasks

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
• EEMBC Automo>ve benchmarks – Benchmarks converted into periodic tasks – Each task has a 30 ms period
• ARM-‐based plagorm – 1 GHz Dual-‐core Cortex-‐A9 CPU – 1 MB L2 cache + private L1 (disabled)
• Tasks observed on Core 0 – Each ploned sample summarizes execu/on of 100 jobs
• Interference generated with synthe>c tasks on Core 1
EEMBC Results

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
EEMBC Results • Angle to time conversion benchmark (a2time)
• Baseline reached when 4 hot pages are locked / 81% accesses caught

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
EEMBC Results • CAN remote data request benchmark (canrdr)
• Baseline reached when 3 pages are locked / 91% accesses caught

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
EEMBC Results • Same experiment executed on 7 EEMBC benchmarks
Benchmark Total Pages Hot Pages % Accesses in Hot Pages
a2time 15 4 81% basefp 21 6 97% bitmnp 19 5 80% cacheb 30 5 92% canrdr 16 3 85% rspeed 14 4 85% tblook 17 3 81%

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
EEMBC Results • One benchmark at the time scheduled on Core 0 • Only the hot pages are locked
No Prot. No Interf.
No Prot. Interf.
Prot. Interf.

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
EEMBC Results • Four benchmarks at the time scheduled on Core 0 • Only the hot pages are locked
Prio 4 (top priority)
Prio 3
Prio 2
Prio 1 (low priority)

Predictable Integra/on of Safety-‐Cri/cal So6ware on COTS-‐based Embedded Systems
Conclusions
• In a mul/core chip, memory controllers, last level cache, memory, on chip network and I/O channels are globally shared by cores. Unless a globally shared resource is over provisioned, it must be par//oned/reserved/scheduled.
• We proposed a set of engineering solu/ons to: 1. schedule memory accesses at high level (PREM + memory-‐centric
scheduling), 2. control cores’ memory bandwidth usage (MemGuard), 3. manage cache space in a predictable manner (Colored Lockdown).
• We demonstrated our techniques on different plagorms based on
Intel and ARM, and tested them against other op/ons.
• Ques/ons?