preparing openshmem for exascale
TRANSCRIPT

Oak Ridge National Laboratory
Computing and Computational Sciences
HPC Advisory Council Stanford Conference
California
Feb 2, 2015
Preparing OpenSHMEM for Exascale
Presented by:
Pavel Shamis (Pasha)

2 Preparing OpenSHMEM for Exascale
Outline
• CORAL overview
– Summit
• What is OpenSHMEM ?
• Preparing OpenSHMEM for Exascale
– Recent advances

3 Preparing OpenSHMEM for Exascale
CORAL
• CORAL – Collaboration of ORNL, ANL, LLNL
• Objective – Procure 3 leadership computers to be sited at Argonne, Oak Ridge and Lawrence Livermore in 2017
– Two of the contracts have been awarded with the Argonne contract in process
• Leadership Computers
– RFP requests >100 PF, 2 GB/core main memory, local NVRAM, and science performance 5x-10x Titan or Sequoia

4 Preparing OpenSHMEM for Exascale
The Road to Exascale
CORAL SystemJaguar: 2.3 PFMulti-core CPU7 MW
Titan: 27 PFHybrid GPU/CPU9 MW
2010 2012 2017 2022
OLCF5: 5-10x Summit~20 MWSummit: 5-10x Titan
Hybrid GPU/CPU10 MW
Since clock-rate scaling ended in 2003, HPC performance has been achieved through increased parallelism. Jaguar scaled to 300,000 cores.
Titan and beyond deliver hierarchical parallelism with very powerful nodes. MPI plus thread level parallelism through OpenACC or OpenMP plus vectors

5 Preparing OpenSHMEM for Exascale
System Summary
Mellanox® Interconnect
Dual-rail EDR Infiniband®
IBM POWER
• NVLink™
NVIDIA Volta
• HBM
• NVLink
Compute Node
POWER® Architecture Processor
NVIDIA®Volta™
NVMe-compatible PCIe 800GB SSD
> 512 GB HBM + DDR4
Coherent Shared Memory
Compute Rack
Standard 19”
Warm water cooling
Compute System
Summit: 5x-10x Titan
10 MW

6 Preparing OpenSHMEM for Exascale
Summit VS Titan
12 SC’14 Summit - Bland Do Not Release Prior to Monday, Nov. 17, 2014
How does Summit compare to Titan
Feature Summit Titan
Application Performance 5-10x Titan Baseline
Number of Nodes ~3,400 18,688
Node performance > 40 TF 1.4 TF
Memory per Node >512 GB (HBM + DDR4) 38GB (GDDR5+DDR3)
NVRAM per Node 800 GB 0
Node Interconnect NVLink (5-12x PCIe 3) PCIe 2
System Interconnect (node injection bandwidth)
Dual Rail EDR-IB (23 GB/s) Gemini (6.4 GB/s)
Interconnect Topology Non-blocking Fat Tree 3D Torus
Processors IBM POWER9
NVIDIA Volta™
AMD Op
t er on™
NVIDIA Ke p ler™
File System 120 PB, 1 TB/s, GP FS™ 32 PB, 1 TB/s, Lustre®
Peak power consumption 10 MW 9 MW
Present and Future Leadership Computers at OLCF, Buddy Bland
https://www.olcf.ornl.gov/wp-content/uploads/2014/12/OLCF-User-Group-Summit-12-3-2014.pdf

7 Preparing OpenSHMEM for Exascale
Challenges for Programming Models
• Very powerful compute nodes
– Hybrid architecture
– Multiple CPU/GPU
– Different types of memory
• Must be fun to program ;-)
– MPI + X

8 Preparing OpenSHMEM for Exascale
What is OpenSHMEM ?
• Communication library and interface specification that implements a Partitioned Global Address Space (PGAS) programming model
• Processing Element (PE) an OpenSHMEM process
• Symmetric objects have same address (or offset) on all PEsPE N-1
Global and Static Variables
Symmetric Heap
Local Variables
PE 0
Global and Static Variables
Symmetric Heap
Local Variables
PE 1
Global and Static Variables
Symmetric Heap
Local Variables
Rem
ote
ly A
cce
ssib
le S
ym
me
tric
Data
Obje
cts
Variable: X Variable: X Variable: X
X = shmalloc(sizeof(long))
Priva
te D
ata
Ob
jects

9 Preparing OpenSHMEM for Exascale
OpenSHMEM Operations
• Remote memory Put and Get
– void shmem_getmem(void *target, const void *source, size_t len, int pe);
– void shmem_putmem(void *target, const void *source, size_t len, int pe);
• Remote memory Atomic operations
– long long shmem_int_add(int *target, int value, int pe);
• Collective
– broadcast, reductions, etc
• Synchronization operations
– Point-to-point
– Global
• Ordering operations
• Distributed lock operations
PE N-1
Global and Static Variables
Symmetric Heap
Local Variables
PE 0
Global and Static Variables
Symmetric Heap
Local Variables
PE 1
Global and Static Variables
Symmetric Heap
Local Variables
Rem
ote
ly A
cce
ssib
le S
ym
me
tric
Data
Obje
cts
Variable: X Variable: X Variable: X
X = shmalloc(sizeof(long))
Priva
te D
ata
Ob
jects

10 Preparing OpenSHMEM for Exascale
OpenSHMEM Code Example
1
2
3
4

11 Preparing OpenSHMEM for Exascale
OpenSHMEM Code Example
• You just learned program OpenSHMEM !
– Library initialization
– AMO/PUT/GET
– Synchronization
– Done 1
2
3
4

12 Preparing OpenSHMEM for Exascale
OpenSHMEM
• OpenSHMEM is a one-sided communications library
– C and Fortran API
– Uses symmetric data objects to efficiently communicate across processes
• Advantages:
– Good for irregular applications, latency-driven communication
• Random memory access patterns
– Maps really well to hardware/interconnects
OpenSHMEM InfniBand (Mellanox) Gemini/Aries (Cray)
RMA PUT/GET V V
Atomics V V
Collectives V V

13 Preparing OpenSHMEM for Exascale
OpenSHMEM Key Principles
• Keep it simple
– The specification is only ~ 80 pages
• Keep it fast
– As close as possible to hardware
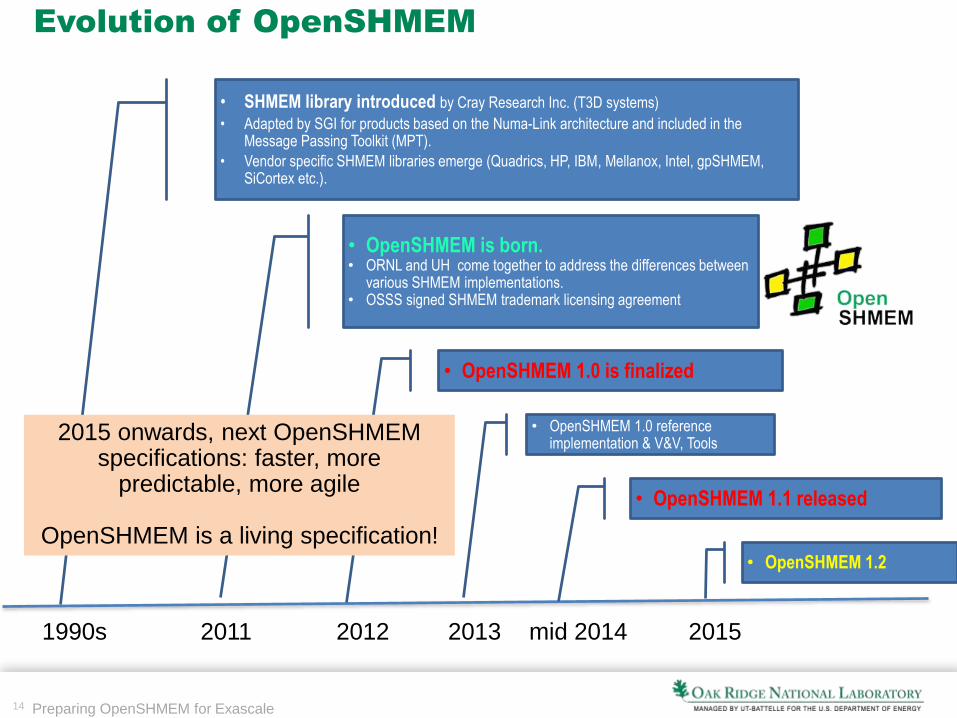
14 Preparing OpenSHMEM for Exascale
Evolution of OpenSHMEM
2011 20131990s 20152012
• SHMEM library introduced by Cray Research Inc. (T3D systems)
• Adapted by SGI for products based on the Numa-Link architecture and included in the Message Passing Toolkit (MPT).
• Vendor specific SHMEM libraries emerge (Quadrics, HP, IBM, Mellanox, Intel, gpSHMEM, SiCortex etc.).
• OpenSHMEM is born.• ORNL and UH come together to address the differences between
various SHMEM implementations.• OSSS signed SHMEM trademark licensing agreement
• OpenSHMEM 1.0 is finalized
• OpenSHMEM 1.0 reference implementation & V&V, Tools
• OpenSHMEM 1.1 released
mid 2014
• OpenSHMEM 1.2
2015 onwards, next OpenSHMEMspecifications: faster, more
predictable, more agile
OpenSHMEM is a living specification!

15 Preparing OpenSHMEM for Exascale
OpenSHMEM - Roadmap
• OpenSHMEM v1.1 (June 2014)
– Errata, bug fixes
– Ratified (100+ tickets resolved)
• OpenSHMEM v1.2 (Early 2015)
– API naming convention
– finalize(), global_exit()
– Consistent data type support
– Version information
– Clarifications: zero-length, wait
– shmem_ptr()
• OpenSHMEM v1.5 (Late 2015)
– Non-blocking communication semantics (RMA, AMO)
– teams, groups
– Thread safety
• OpenSHMEM v1.6
– Non-blocking collectives
• OpenSHMEM v1.7
– Thread safety update
• OpenSHMEM Next Generation (2.0)
– Let’s go wild !!! (Exascale!)
– Active set + Memory context
– Fault Tolerance
– Exit codes
– Locality
– I/O
White paper:
OpenSHMEM Tools API

16 Preparing OpenSHMEM for Exascale
OpenSHMEM Community Today
Academia
Vendors
Government

17 Preparing OpenSHMEM for Exascale
OpenSHMEM Implementations
• Proprietary
– SGI SHMEM
– Cray SHMEM
– IBM SHMEM
– HP SHMEM
– Mellanox Scalable SHMEM
• Legacy
– Quadrics SHMEM
• Open Source
– OpenSHMEM Reference Implementation (UH)
– Portals SHMEM
– Oshmpi / Open SHMEM over MPI (under development)
– OpenSHMEM with OpenMPI
– OpenSHMEM with MvapichMPI (OSU)
– TSHMEM (UFL)
– GatorSHMEM (UFL)

18 Preparing OpenSHMEM for Exascale
OpenSHMEM Eco-system
OpenSHMEM
Reference
Implementation
ANALYZER
Vampir

19 Preparing OpenSHMEM for Exascale
OpenSHMEM Eco-system
• OpenSHMEM Specification
– http://www.openshmem.org/site/Downloads/Source
• Vampir
– https://www.vampir.eu
• TAU
– http://www.cs.uoregon.edu/research/tau/home.php
• DDT
– www.allinea.com/products/ddt
• OpenSHMEM Analyzer
– https://www.openshmem.org/OSA
• UCCS
– http://uccs.github.io/uccs/

20 Preparing OpenSHMEM for Exascale
Upcoming Challenges for OpenSHMEM
• Based on what we know about the upcoming architecture…
• Communication across different components of system
• Locality of resources
Hybrid Architecture
• Thread Safety (without performance sacrifices)
• Threads locality
• Scalability
Multiple CPU/GPU
• Address spacesDifferent Types
of memory

21 Preparing OpenSHMEM for Exascale
Hybrid Architecture Challenges and Ideas
• OpenSHMEM for accelerators
• “TOC-Centric Communication: a case study with NVSHMEM”, OUG/PGAS 2014, Shreeram Potluri
– http://www.csm.ornl.gov/OpenSHMEM2014/documents/NVIDIA_Invite_OUG14.pdf
– Preliminary study, prototype concept

22 Preparing OpenSHMEM for Exascale
NVSHMEM
• The problem
– Communication across GPU requires synchronization with Host
• Software overheads, hardware overhead of launching kernels, etc.
• Research idea/concept proposed by Nvidia
– GPU-initiated communication
– NVSHMEM communication primitives: nvshmem_put(), nvshmem_get()to/from remote GPU memory
– Emulated using CUDA IPC (CUDA 4.2)
The slide is based on “TOC-Centric Communication: a case study with NVSHMEM”,
OUG/PGAS 2014, Shreeram
Potlurihttp://www.csm.ornl.gov/OpenSHMEM2014/documents/NVIDIA_Invite_OUG14.pdf
CHANGE IN THE MODEL
Loop { Interior Compute (kernel launch) Pack Boundaries (kernel launch) Stream Synchronize Exchange (MPI/OpenSHMEM) Unpack Boundaries (kernel launch) Boundary Compute (kernel launch) Stream/Device Synchronize } - Kernel launch overheads
- CPU based blocking synchronization
Traditional
Compute, Exchange and Synchronize (single kernel launch) - Support SHMEM communication and synchronization primitives from inside GPU kernel
Envisioned
17

23 Preparing OpenSHMEM for Exascale
NVSHMEM
SIMPLIFIED 2DSTENCIL EXAMPLE
u[i][j] = u[i][j] + (v[i+1][j] + v[i-1][j]
+ v[i][j+1] + v[i][j+1])/x
16
Evaluation results from: “TOC-Centric Communication: a case study with NVSHMEM”,
OUG/PGAS 2014, Shreeram
Potlurihttp://www.csm.ornl.gov/OpenSHMEM2014/documents/NVIDIA_Invite_OUG14.pdf
PRELIMINARY RESULTS
Domain Size/
GPU Traditional Persistent Kernel
64 195.33 13.88
128 193.7 21.32
256 193.18 39.77
512 220.28 132.61
1024 375.8 389.65
2048 1319.74 1312.59
4096 5299.23 4776.31
8192 21480.32 18394.88
Time per Step (usec) (Ghost Width – 1; Boundary – 16)
(Threadsperblock – 512; blocks -15) (4 Processes – 1 Process/GPU)
tl
Time per Step (usec) (Domain size – 2048; Ghost Width – 1; Boundary – 2)
(Extrapolation by reducing problem size per GPU, assuming constant exchange and synchronization time)
Benchmark numbers, beware!!
GPU Count Traditional Persistent Kernel
4 375 389
16 226 132
64 196 39
256 194 21
1K 192 13
4K 202 13
16K 193 12
64K 194 13
0"
500"
1000"
1500"
64" 128" 256" 512" 1K" 2K"
Time%per%Step%(usec)%
Stencil%Size%%
tradi/ onal" persistent"kernel"
1"
10"
100"
1000"
4" 16" 64" 256" 1K" 4K" 16K" 64K"
Time%per%Step%(usec)%
Number%of%GPUs%
Tradi. onal" Persistent"Kernel"
23 4 K40m GPUs connected on a Xeon E5-2690 socket using PLX switches

24 Preparing OpenSHMEM for Exascale
Many-Core System Challenges
• It is challenging to provide high-performance THREAD_MULTIPLE support
– Locks / Atomic operations in communication path
• Even though MPI IMB benchmarks benefits from full process memory separation, multi-threaded UCCS obtains comparable performance
Aurelien Bouteiller, Thomas Herault and George Bosilca, “A Multithreaded Communication Substrate for OpenSHMEM”, OUG2014

25 Preparing OpenSHMEM for Exascale
Many-Core System Challenges – “Old” Ideas
• SHMEM_PTR (or SHMEM_LOCAL_PTR on Cray)
PE 0
Symmetric Heap
Local Variables
PE 1
Symmetric Heap
Local Variables
Variable: X Variable: X
Y = shmem_ptr(&X, PE1)
Variable: Y
Mem
ory M
apping

26 Preparing OpenSHMEM for Exascale
Many-Core System Challenges – “Old” Ideas
• Provides direct assess to “remote” PE element with memory load and store operations
• Supported on a systems where SHMEM_PUT/GET are implemented with memory load and store operations
– Usually implemented using XPMEM (https://code.google.com/p/xpmem/)
• Gabriele Jost, Ulf R. Hanebutte, James Dinan, “OpenSHMEM with Threads: A Bad Idea?”
• http://www.csm.ornl.gov/OpenSHMEM2014/documents/talk6_jost_OUG14.pdf
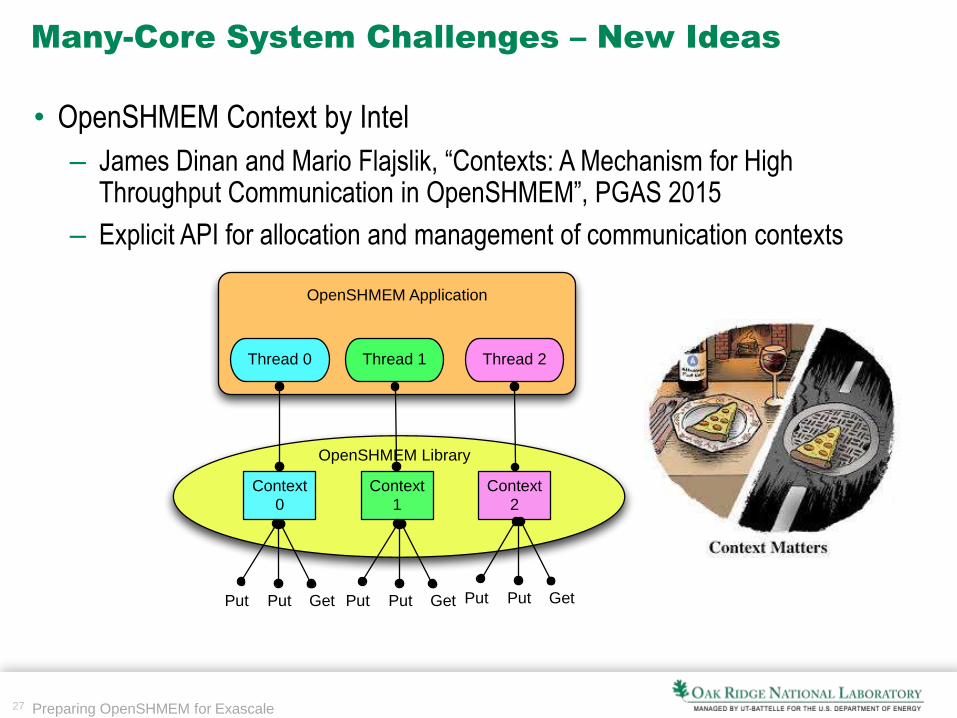
27 Preparing OpenSHMEM for Exascale
Many-Core System Challenges – New Ideas
• OpenSHMEM Context by Intel
– James Dinan and Mario Flajslik, “Contexts: A Mechanism for High Throughput Communication in OpenSHMEM”, PGAS 2015
– Explicit API for allocation and management of communication contexts
OpenSHMEM Application
Thread 0 Thread 1 Thread 2
Context 0
Context 1
Context 2
OpenSHMEM Library
Put Put Get Put Put Get Put Put Get

28 Preparing OpenSHMEM for Exascale
Many-Core System Challenges – New Ideas
• Cray’s proposal of “Hot” Threads
– Monika ten Bruggencate Cray Inc. “Cray SHMEM Update”, First OpenSHMEM Workshop: Experiences, Implementations and Tools
• http://www.csm.ornl.gov/workshops/openshmem2013/documents/presentations_and_tutorials/tenBruggencate_Cray_SHMEM_Update.pdf
– Idea: each thread is registered within OpenSHMEM library. The library allocates and automatically manages communication resources (context) for the application
– Compatible with current API

29 Preparing OpenSHMEM for Exascale
Address Space and Locality Challenges
• Symmetric heap is not flexible enough
– All PE have to allocate the same amount of memory
• No concept of locality
• How we manage different types of memory ?
• What is the right abstraction ?

30 Preparing OpenSHMEM for Exascale
Memory Spaces
• Aaron Welch , Swaroop Pophale , Pavel Shamis , Oscar Hernandez, Stephen Poole, Barbara Chapman, “Extending the OpenSHMEMMemory Model to Support User-Defined Spaces”, PGAS2014
• Concept of teams
– Original OpenSHMEM active-set (group of Pes) concept is outdates, BUT very lightweight (local operation)
• Memory Space
– Memory space association with a team
– Similar concepts can be found in MPI, Chapel, etc.

31 Preparing OpenSHMEM for Exascale
Teams
• Explicit method of grouping PEs
• Fully local objects and operations - Fast
• New (sub)teams created from parent teams
• Re-indexing of PE ids with respect to the team
• Strided teams and axial splits
– No need to maintain “translation” array
– All translations can be done with simple arithmetic
• Ability to specify team index for remote operations

32 Preparing OpenSHMEM for Exascale
Spaces

33 Preparing OpenSHMEM for Exascale
Spaces
• Spaces and teams creation is decoupled
• Faster memory allocation compared to “shmalloc”
• Future directions
– Different types of memory
– Locality
– Separate address spaces
– Asymmetric RMA access

34 Preparing OpenSHMEM for Exascale
Fault Tolerance ?
• How to run in presence of faults ?
• What is the responsibility of programming model and communication libraries
• Pengfei Hao, Pavel Shamis, Manjunath Gorentla Venkata, SwaroopPophale, Aaron Welch, Stephen Poole, Barbara Chapman, “Fault Tolerance for OpenSHMEM”, PGAS/OUG14
– http://nic.uoregon.edu/pgas14/oug_submissions/oug2014_submission_12.pdf

35 Preparing OpenSHMEM for Exascale
Fault Tolerance
• Basic idea
– In memory checkpoint of symmetric memory regions
– Symmetric recovery or only “memory recovery”

36 Preparing OpenSHMEM for Exascale
Fault Tolerance
• Code snippet

37 Preparing OpenSHMEM for Exascale
Fault Tolerance
• Work in progress…
• OpenSHMEM is just one piece of the puzzle
– Run-time, I/O, drivers, etc.
– The system has to provide fault tolerance infrastructure
• Error notification, coordination, etc.
• Leveraging existing work/research in the HPC community
– MPI, Hadoop, etc.

38 Preparing OpenSHMEM for Exascale
Summary
• This just a “snapshot” some of the ideas
– Other active research & development topics: non-blocking operations, counting operations, signaled operation, asymmetric memory access, etc
• These challenges are relevant for many other HPC programming models
• The key to success
– Co-design of hardware and software
– Generic solutions that target broader community
• The challenges are common across different fields: storage, analytics, big-data, etc.

39 Preparing OpenSHMEM for Exascale
How to get involved?
• Join the mailing list
– www.openshmem.org/Community/MailingList
• Join OpenSHMEM redmine
– www.openshmem.org/redmine
• GitHUB
– https://github.com/orgs/openshmem-org
• OpenSHMEM RF, test suites, benchmarks, etc.
• Participate in our upcoming events
– Workshop, user group meetings, and conference calls

40 Preparing OpenSHMEM for Exascale
Upcoming Events…
Workshop 2015August,4th-6th, 2015

41 Preparing OpenSHMEM for Exascale
www.csm.ornl.gov/OpenSHMEM2015/
Co-Located with
PGAS 20159th international Conference on
Partitioned Global Address SpaceProgramming Models
Washington, DC
Upcoming Events…

42 Preparing OpenSHMEM for Exascale
Acknowledgements
This work was supported by the United States Department of Defense & used resources of the Extreme Scale Systems Center at Oak Ridge
National Laboratory.
Empowering the Mission

43 Preparing OpenSHMEM for Exascale
Questions ?

44 Preparing OpenSHMEM for Exascale
Backup Slides

45 Preparing OpenSHMEM for Exascale
NVSHMEM Code Example
USING NVSHMEM Device Code __global__ void one_kernel (u, v, sync, …) { i = threadIdx.x; for (…) { if (i+1 > nx) { v[i+1] = nvshmem_float_g (v[1], rightpe) } if (i-1 < 1) { v[i-1] = nvshmem_float_g (v[nx], leftpe) } ------- u[i] = (u[i] + (v[i+1] + v[i-1] . . . contd….
contd…. /*peers array has left and right PE ids*/ if (i < 2) { nvshmem_int_p (sync[i], 1, peers[i]); nvshmem_quiet(); nvshmem_wait_until (sync[i], EQ, 1); } //intra-process sync ------- //compute v from u and sync } }
19 Evaluation results from: “TOC-Centric Communication: a case study with NVSHMEM”,
OUG/PGAS 2014, Shreeram
Potlurihttp://www.csm.ornl.gov/OpenSHMEM2014/documents/NVIDIA_Invite_OUG14.pdf