presenter : nageeb yahya alsurmi gs21565 ameen mohammad gs22872 ameen mohammad gs22872 yasien ahmad...
Post on 19-Dec-2015
217 views
TRANSCRIPT

Presenter : Nageeb Yahya Alsurmi GS21565 Ameen Mohammad GS22872
Yasien Ahmad GS24259 Atiq Alemadi GS21798
Lecturer :Dr. NOR ASILAH WATI ABDUL HAMID
Test Suite for Evaluating Performance of MPI Implementations That Support
MPI_THREAD_MULTIPLEBy: Rajeev Thakur and William Gropp
Argonne National Laboratory, USA
HPC SKR 5800 UPM University

Introduction Literature Review Problem Statement Problem Objective MPI and threads overview Methodology
◦ Test Suite ( 8- benchmark)◦ Experimental Result
Conclusion and Future work References
Outline

Introduction 1/2 With thread-safe MPI implementations becoming
increasingly common. MPI process is a process that may be
multithreaded. Each thread can issue MPI calls. Threads are not separately addressable: a rank
in a send or receive call identifies a process, not a thread.
A message sent to a process can be received by any thread in this process.
The user can make sure that two threads in the same process will not issue conflicting communication calls by using distinct communicators at each thread.

Introduction 2/2
The two main requirements for a thread-compliant implementation:◦ 1- All MPI calls are thread-safe.◦ 2- Blocking MPI calls will block the calling thread
only, allowing another thread to execute, if available.

Literature Review The MPI benchmarks from Ohio State University
only contain a multithreaded latency test. The latency test is a ping-pong test with one
thread on the sender side and two (or more) threads on the receiver side.
There are a number of MPI benchmarks exist, such as SKaMPI and Intel MPI Benchmarks, but they do not measure the performance of multithreaded MPI programs (this is the key issue of this paper).

Problem statement With thread-safe MPI implementations becoming
increasingly common, users are able to write multithreaded MPI programs that make MPI calls concurrently from multiple threads.
Developing a thread-safe MPI implementation is a fairly complex task.
Users, therefore, need a way to measure the outcome and determine how efficiently an implementation can support multiple threads.

Objective The authors proposed a test suite that can shed
light on the performance of an MPI implementation in the multithreaded case.
To illustrate the results provided by the test suite and how these results should be analyzed

Overview of MPI and Threads 1/2
To understand the test suite you have first to understand the thread-safety specification in MPI.
MPI defines four “levels” of thread safety:◦ 1-MPI_THREAD_SINGLE Each process has a single thread
of execution.
2. MPI_THREAD_FUNNELED A process may be multithreaded, but only the Main thread that initialized MPI may make MPI calls.
T P1
T
Tm
T
P1
T
Tm
T
P2
P2 TMPI Call
MPI Call
MPI Call
MPI Call

Overview of MPI and Threads 2/2
◦ 3. MPI THREAD SERIALIZED A process may be multithreaded, but only one thread at a time may make MPI calls.
◦ 4. MPI THREAD MULTIPLE A process may be multithreaded, and multiple threads may simultaneously call MPI functions (with some restrictions mentioned below).
T
T
P1
T
T
P1
T
1
2
3 MPI Call
MPI Call
MPI Call
T
MPI CallMPI CallMPI Call
Our case

thread-safe. if your code access the same memory location
from multiple threads with protection, it is most likely thread-safe.
A blocked MPI call in one thread will not obstruct MPI operations in other threads.
the risk that one thread will interfere and modify data elements of another thread is eliminated.
This is fairly minimal thread safety since you must ensure that your programs logic is thread safe, that is if your application is multithreaded.
In this context thread safety means that execution of multiple threads does not in itself corrupt the state of your objects.

Blocking MPI functions Deadlock occurs when a process holds a lock and
then attempts to acquire a second lock. If the second lock is already held by another process, the first process will be blocked. If the second process then attempts to acquire the lock held by the first process, the system has "deadlocked": no progress will ever be made
They cause blocking, which means some threads/processes have to wait until a lock (or a whole set of locks) is released
Process 0 Process 1Thread 0 Thread 1 Thread 1Thread 0
MPI_Recv(src1) MPI_Send(dest1) MPI_Recv(src0) MPI_Send(dest0)
Buffer fullWait for thread 1 to complete the send operation to start reading from the buffer
The buffer is full but still a data are sending so thread 1 wait for thread 0 to
empty (read) the buffer

MPI implementations There are many MPI implementations but in this
paper , just used four implementations:◦ MPICH2 it’s a library and portable
It’s a library (not compiler), It can achieve parallelism using networked machines or using multitasking on a single machine.
portable implementation of MPI, a standard for message-passing .
can be used for communication between processors.◦ OPEN MPI
merger between three well-known MPI implementations (FT-MPI, LA-MPI, LAM/MPI).
◦ (MPI) SUN MPI run on SUN machines It is Sun Microsystems' implementation of MPI
◦ IBM’s MPI runs on IBM SP systems and AIX workstation clusters.

Experiment test: The test suit has carried on multiple MPI
implementation with different platforms. Linux Cluster (4node,AMD Opetron DualCore 2.8GHz)
◦ MPICH2 V 1.0.7 , OpenMPI V1.2.6◦ Gigabit Ethernet networking
SUN T5120 server with 8 Core 1.4GHz (SUN cluster)◦ SUN MPI.
IBM p566+ SMP has 8 Power4+ CPU 1.7GHz◦ IBM MPI

The Test Suite The test has three categorization: 1-Cost of thread safety test
◦ 1-1 MPI THREAD MULTIPLE overhead 2-Concurrent progress test
◦ 2-1 Concurrent bandwidth◦ 2-2 Concurrent latency◦ 2-3 Message Rate◦ 2-4 Concurrent short-long messages
3-Computation/ communication tests◦ 3-1 Computation/ communication overlap ◦ 3-2 Concurrent collective operation◦ 3-3 Concurrent collective and computation

1-Cost of thread safety test MPI THREAD MULTIPLE Overhead test (small
messages) Initializing MPI with just MPI_Init and initializing it
with MPI_Init_ thread for MPI-THREAD-MULTIPLE◦Ping pong Latency (command : mprun –np
2 ./latency)◦ Command (with-thread) : mprun –np 2
./latency_threaded
Without Thread With Thread
Ping
Pong
Ping
Pong
The difference
= Overhead
MPI_Init(&argc,&argv) MPI_Init_thread(MPI_THREAD_MULTIPLE);

1-Cost of thread safety result MPI THREAD MULTIPLE Overhead Results:
◦ Linux Cluster -- MPICH2 & OpenMPI overhead average <= o.5 us
◦ IBM cluster -- IBM MPI Overhead avearage < 0.25 us
◦ SUN Cluster --- SUN MPI Overhead avearage > 3 us overhead was observed is to ensure the thread safety
for the MPI_THREAD_MULTIPLE case, which is typically implemented by acquiring and releasing mutex locks.P P
T T
P P

2-Concurrent progress test 1/3 2-1- concurrent bandwidth (cumulative
bandwidth) Test on Large Messages (point to point
communication)◦ Process ( 4 processes at each node)◦ Threads ( 2 processes each one has 2 threads)P1
P2
P3P4
P4
P2
P3
P2
P1
P2
P3
P4
P1
P1P1
T1
T2
T1
T2
T1
T2
T1
T1
T2
T2
T1
T1
T2
T2
T1
T1
T2
+ +
Large message Large message
cumulative bandwidth

2-1 concurrent bandwidth result 2/3
Command : mprun –np 8 ./bandwidth Command : mprun –np 2 ./bandwidth_th 4
(thread version) how much thread locks affect the cumulative
bandwidth.◦Linux Cluster (AMD Opetron two dual-core)
MPICH2 no measurable difference in bandwidth between threads and processes.
OpenMPI there is a decline in bandwidth with threads.
◦ IBM MPI & SUN MPI there is a substantial decline
◦ (more than 50% in some cases) in the bandwidth when threads were used.
◦ It is harder to provide low overhead in these shared memory environments because the communication bandwidths are so high

2-2- concurrent bandwidth graph 3/3
Sun & IBM ,It is harder to provide low overhead in these shared memory environments because the communication bandwidths are so high , Bandwidth = size/time

2-2-concurrent latency test 1/3 This is similar to the concurrent bandwidth test
except that it measures the time for individual short messages.
P1
P2
P3P4
P4
P2
P3
P2
P1
P2
P3
P4
P1
P1P1
T1
T2
T1
T2
T1
T2
T1
T1
T2
T2
T1
T1
T2
T2
T1
T1
T2
Short message series Short message series
Process Mutti threading

2-2-concurrent latency result 2/3
overhead in latency when using concurrent threads instead of processes
Linux cluster◦ MPICH2 overhead is about 20 μs.◦ Open MPI overhead is about 30 μs.
IBM MPI & SUN MPI ◦ the latency with threads is about 10 times the
latency with processes. But still the IBM & SUN has the low latency
compared with MPICH & Open MPI.

2-2-Concurrent Latency Graph 3/3
• But still the IBM & SUN has the low latency compared with MPICH & Open MPI.
• Careful design and tuning of code is needed to minimize the overhead

This test is similar to the concurrent latency test except that it measures the message rate for zero-byte sends.
The individual message rates are summed to determine the total message rate.
Sun &IBM SMPs., the overall MR are much higher because all communication takes place within a node using
shared memory. MPICH has best MR.
2-3 Message Rate (MR)

2-4 Concurrent Short-Long Messages Test 1/2 This test is a blend of the concurrent bandwidth
and concurrent latency tests This test tests the fairness of thread scheduling
and locking. If they were fair, one would expect each of the
short messages to take roughly the same amount of time.
P1P2P0
P1
P2
P3
P1P1P0
T1
T2
T1
T2
T1
T2
T1
T2
T2
T1
T1
T2Short message series Short message series
Long message
P2
Long message
ProcessMulti Threads

2-4 Concurrent Short-Long Messages Results 2/2
This result demonstrates that, in the threaded. case, locks are fairly held and released and that
the thread blocked in the long message send does not block the other thread.

3-1 Computation/ communication overlap test 1/3
To study the impact of non-blocking communication (send and recive) over computation operation
This technique effectively simulates asynchronous progress by the MPI implementation.
If total time ( threading mode) < total time (non threading) there is no overlap communication with computation.
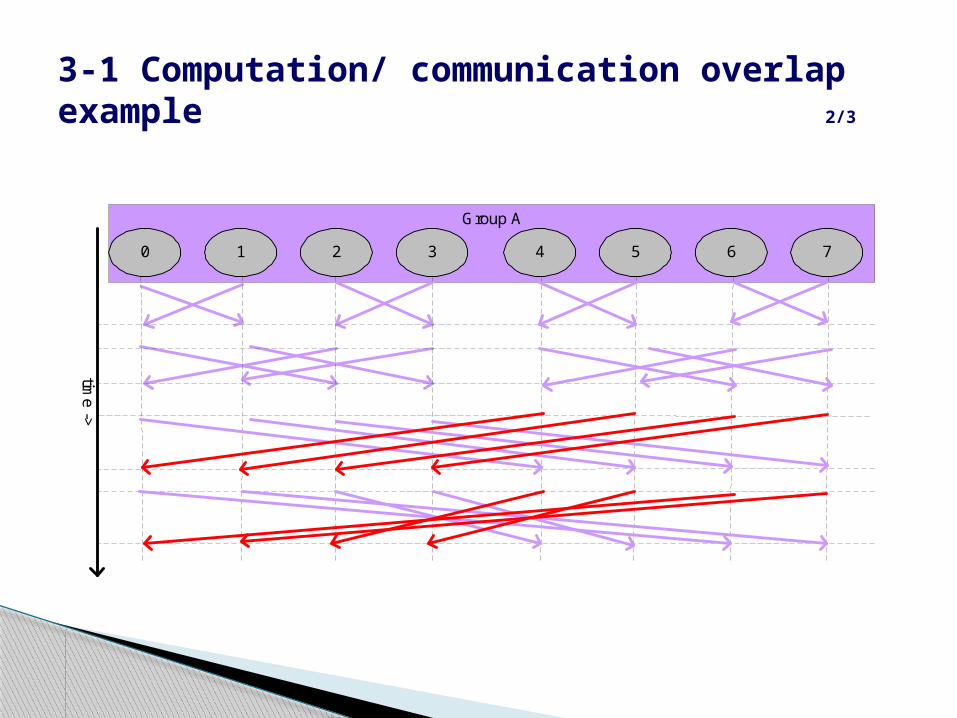
3-1 Computation/ communication overlap example 2/3
Group A
0 54321
time
->
6 7

3-1Computation/ communication overlap result 3/3
IBM only the one which has overlap because it has higher overhead of multiple thread and extra overhead for switching between threads

3-2 Concurrent Collectives test 1/3
compares the performance of concurrent calls to a collective function (MPI_Allreduce) issued from multiple threads to that when issued from multiple processes.
P1 P1
P1
Process

3-2 Concurrent Collectives test 2/3
Thread version – collective operation MPI_Allreduce
T1
T2T1
T2
P1 P1
P1
T1
T2
Multi Threads

3-2 Concurrent Collectives result 3/3
results on the Linux cluster. MPICH2 has relatively small overhead for the threaded version, compared with Open MPI.

3-3 Concurrent Collectives and Computation (final test) evaluates the ability to use a thread to hide the
latency of a collective operation while using all available processors to perform computations. (collective communication + computation)
Test 1: MPI_Allreduce function used for collective with computation
Test 2: no MPI_ allreduce used only computation operation.
Then compared two tests (the higher is the better).
MPICH2 demonstrates a better ability than Open MPI to hide the latency of the MPI_allreduce.

Conclusion & future work MPI implementations supporting MPI THREAD
MULTIPLE become increasingly available. The Authors have developed such a test suite
and show its performance on multiple platforms and implementations
Design and tuning of code is needed to minimize the overhead.
The results indicate◦Good performance with MPICH2 and Open
MPI on Linux clusters.◦Poor performance with IBM and Sun MPI on
IBM and Sun SMP systems The Authors plan to add more tests to the suite,
such as to measure the overlap of computation/communication with the MPI-2 file I/O and connect-accept features.

References 1. Francisco Garc´ıa, Alejandro Calder´on, and Jes´us Carretero. MiMPI: A
multithreadsafe implementation of MPI. In Recent Advances in Parallel Virtual Machine and Message Passing Interface, 6th European PVM/MPI Users’ Group Meeting, pages 207–214. Lecture Notes in Computer Science 1697, Springer, September 1999. 2. William Gropp and Rajeev Thakur. Issues in developing a thread-safe MPI
implementation. In Recent Advances in Parallel Virtual Machine and Message Passing Interface, 13th European PVM/MPI Users’ Group Meeting, pages 12–21. Lecture Notes in Computer Science 4192, Springer, September 2006. 3. Intel MPI benchmarks. http://www.intel.com. 4. OSU MPI benchmarks. http://mvapich.cse.ohio-state.edu/benchmarks. 5. Boris V. Protopopov and Anthony Skjellum. A multithreaded message passing interface (MPI) architecture: Performance and program issues. Journal of Parallel and Distributed Computing, 61(4):449–466, April 2001. 6. Ralf Reussner, Peter Sanders, and Jesper Larsson Tr¨aff. SKaMPI: A comprehensive benchmark for public benchmarking of MPI. Scientific Programming, 10(1):55–65, January 2002.

Any Questions @ MPI Multiple threading
Ada Soalan !!!!