principais conceitos e técnicas em vetorização
TRANSCRIPT

Principais conceitos e técnicas em vetorização
Workshop em Computação CientíficaCENAPAD-SP – 20 ANOS
Igor Freitas [email protected]

2
LEGAL DISCLAIMERSINFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT.
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to http://www.intel.com/performance
Relative performance is calculated by assigning a baseline value of 1.0 to one benchmark result, and then dividing the actual benchmark result for the baseline platform into each of the specific benchmark results of each of the other platforms, and assigning them a relative performance number that correlates with the performance improvements reported.
Intel does not control or audit the design or implementation of third party benchmarks or Web sites referenced in this document. Intel encourages all of its customers to visit the referenced Web sites or others where similar performance benchmarks are reported and confirm whether the referenced benchmarks are accurate and reflect performance of systems available for purchase.
Intel® Turbo Boost Technology requires a Platform with a processor with Intel Turbo Boost Technology capability. Intel Turbo Boost Technology performance varies depending on hardware, software and overall system configuration. Check with your platform manufacturer on whether your system delivers Intel Turbo Boost Technology. For more information, see http://www.intel.com/technology/turboboost
Intel processor numbers are not a measure of performance. Processor numbers differentiate features within each processor series, not across different processor sequences. See http://www.intel.com/products/processor_number for details. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. All dates and products specified are for planning purposes only and are subject to change without notice
Intel product plans in this presentation do not constitute Intel plan of record product roadmaps. Please contact your Intel representative to obtain Intel’s current plan of record product roadmaps. Product plans, dates, and specifications are preliminary and subject to change without notice
For more information go to http://www.intel.com/performance
Any difference in system hardware or software design or configuration may affect actual performance
Copyright © 2014 Intel Corporation. All rights reserved. Intel, the Intel logo, Xeon, Xeon logo, Xeon Phi, and Xeon Phi logo are trademarks of Intel Corporation in the U.S. and/or other countries. All dates and products specified are for planning purposes only and are subject to change without notice.
*Other names and brands may be claimed as the property of others.

Agenda
3
Introdução
Auto-vetorização
Diretivas - #pragma
Vetorização com Intel® Cilk™ Plus
Intrinsics
Conclusões
Iniciativas da Intel em HPC no Brasil


Caminho para o Exascale Computing
Intel is only company on the planet that is targeting the broad range of technologies and devices to bring a great solution to every segment of the Technical Computing market.
Network& Fabrics
Software& Services
ComputeIntel® Xeon®
Intel® Xeon Phi™
I/O & Storage
CAS
Intel®ClusterReadyIntel® Enterprise
Editionfor Lustre* software
Power efficiencyResiliencyReliability

6
IntroduçãoModelos de Programação Paralela
1. Decidir a divisão dos blocos de dados entre os processadores2. Mesma operação, dados diferentes por unidade de execução
Ex: Encontrar o maior elemento em um vetor
UP 0 UP 1 UP 2 UP 3
Decomposição de domínio “Data Decomposition”
UP = Unidade de Processamento

7
1. Dividir tarefas entre os processadores
2. Decidir quais elementos de dados serão acessados por qual processador (leitura/escrita)
f()
s()
r()q()h()
g()
UP 1
UP 0
UP 2
f()
g()
r()h() q()
r()
s()
Decomposição de tarefas – “Task paralellism”
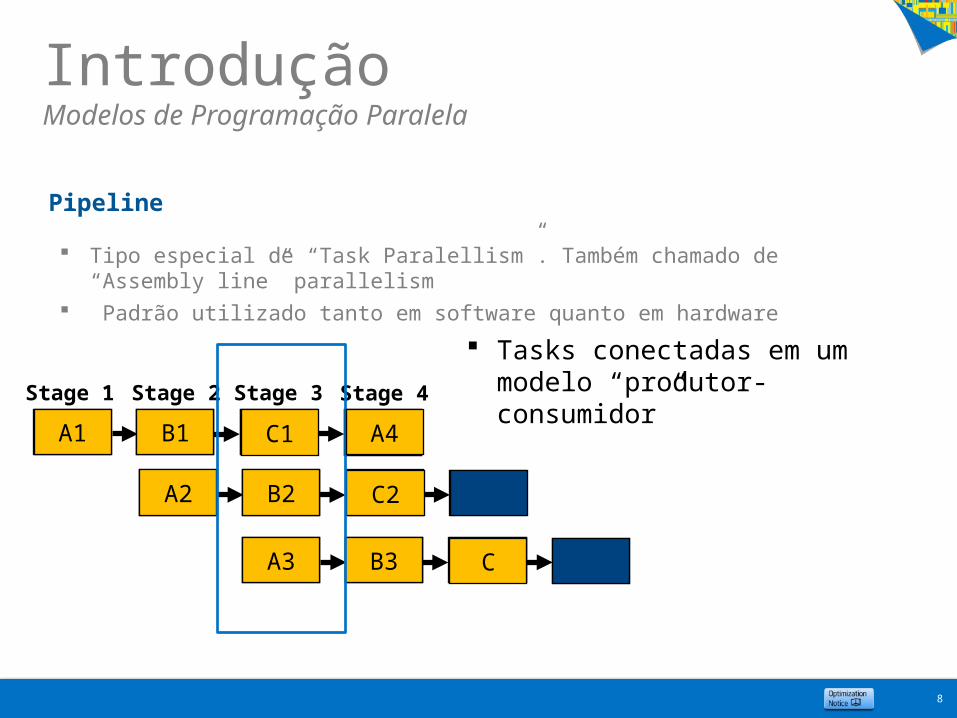
IntroduçãoModelos de Programação Paralela
8
Tipo especial de “Task Paralellism”. Também chamado de “Assembly line” parallelism
Padrão utilizado tanto em software quanto em hardware
Tasks conectadas em um modelo “produtor-consumidor”
Pipeline
Stage 4Stage 3Stage 2Stage 1
A1 B1 C1
A2 B2 C2
A3 B3 C
A4
IntroduçãoModelos de Programação Paralela
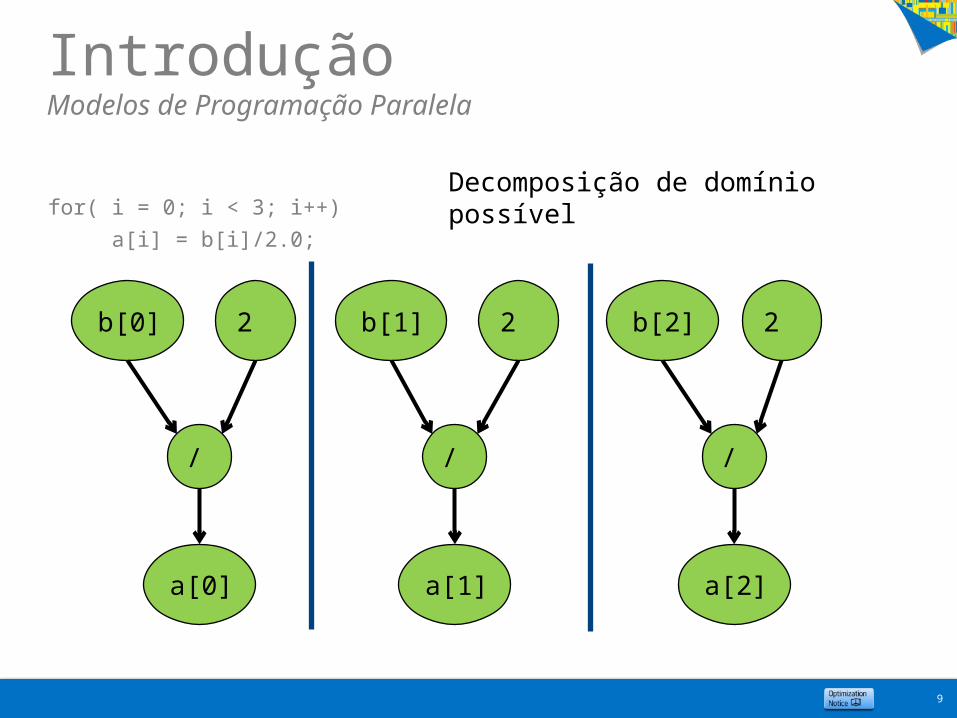
for( i = 0; i < 3; i++)
a[i] = b[i]/2.0;
9
b[0] b[1] b[2]
a[0] a[1] a[2]
///
2 2 2
Decomposição de domínio possível
IntroduçãoModelos de Programação Paralela

for( i = 1; i < 4; i++)
a[i] = a[i-1]*b[i];
10
b[1] b[2] b[3]
a[1] a[2] a[3]
***
a[0]
Decomposição de domínio falha neste caso
IntroduçãoModelos de Programação Paralela
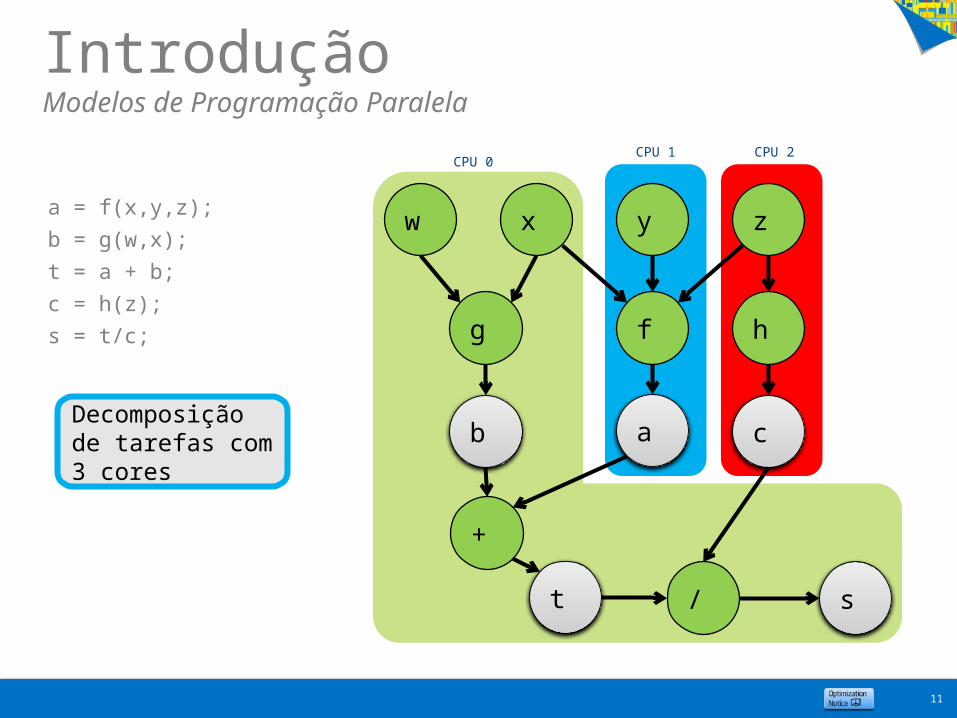
a = f(x,y,z);
b = g(w,x);
t = a + b;
c = h(z);
s = t/c;
11
Decomposição de tarefas com 3 cores
x
f
w y z
ab
g
t
c
s/
h
+
CPU 0CPU 1 CPU 2
IntroduçãoModelos de Programação Paralela

12
Como aplicar tais padrões de programação paralela ? Das linguagens de programação mais populares, nenhuma foi
criada com o objetivo de explorar paralelismo
Necessidade de adaptação destas linguagens “modernização de código”
Objetivos Performance + Produtividade + Portabilidade
Sequencial
Paralelo
Clusters
IntroduçãoModelos de Programação Paralela

Principles of Delivered Performance
*Other logos, brands and names are the property of their respective owners.All products, computer systems, dates and figures specified are preliminary based on current expectations, and are subject to change without notice.Intel® Xeon® Processor generations from left to right in each chart: 64-bit, 5100 series, 5500 series, 5600 series, E5-2600, E5-2600 v2Intel® Xeon Phi™ Product Family from left to right in each chart: Intel® Xeon Phi™ x100 Product Family (formerly codenamed Knights Corner), Knights Landing (next-generation Intel® Xeon Phi™ Product Family)
WorkTime = Work
InstructionInstruction
Cyclex CycleTimex
FrequencyIPC
Não podemos mais contar somente com aumento da frequência
Algoritmo eficiente mesma carga de trabalho com menos instruções
Compilador reduz as instruções e melhora IPC
Uso eficiente da Cache: melhora IPC
Vetorização: mesmo trabalho com menos instruções
Paralelização: mais instruções por ciclo
Path LengthPerformance
Addressing All Operands with Common CPU Approach

14
for (i=0;i<=MAX;i++) c[i]=a[i]+b[i];
+
c[i+7] c[i+6] c[i+5] c[i+4] c[i+3] c[i+2] c[i+1] c[i]
b[i+7]b[i+6]b[i+5]b[i+4]b[i+3]b[i+2]b[i+1]b[i]
a[i+7]a[i+6]a[i+5]a[i+4]a[i+3]a[i+2]a[i+1]a[i]Vector
- Uma instrução- Oito operações
+
C
B
AScalar
- Uma instrução- Uma operação
• O que é e ? • Capacidade de realizar uma
operação matemática em dois ou mais elementos ao mesmo tempo.
• Por que Vetorizar ?• Ganho substancial em
performance !
IntroduçãoVetorização

15
Código C/C++ ou Fortran
Thread 0 / Core 0
Thread 1/ Core1
Thread 2 / Core
2
Thread 12 /
Core12
...
Thread 0/Core0
Thread 1/Core1
Thread 2/Core2
Thread 244
/Core61
...
128 Bits 256 Bits
Vector Processor Unit por Core Vector Processor Unit por Core
Paralelismo (Multithreading)
Vetorização
512 Bits
IntroduçãoVetorização

16
MMX™ instructions (1997)
Intel® Streaming SIMD Extensions (Intel® SSE in 1999 to Intel® SSE4.2 in 2008)
Intel® Advanced Vector Extensions (Intel® AVX in 2011 and Intel® AVX2 in 2013)
Intel® Many Integrated Core Architecture (Intel® MIC Architecture in 2012)
Intel® Pentium® processor (1993)
IntroduçãoVetorização

17
X4
Y4
X4opY4
X3
Y3
X3opY3
X2
Y2
X2opY2
X1
Y1
X1opY1
064
X4
Y4
X4opY4
X3
Y3
X3opY3
X2
Y2
X2opY2
X1
Y1
X1opY1
0128
MMX™ Vector size: 64bitData types: 8, 16 and 32 bit integersVL: 2,4,8For sample on the left: Xi, Yi 16 bitintegers
Intel® SSE Vector size: 128bitData types: 8,16,32,64 bit integers 32 and 64bit floats VL: 2,4,8,16Sample: Xi, Yi bit 32 int / float
IntroduçãoVetorização

18
Intel® AVX Vector size: 256bitData types: 32 and 64 bit floatsVL: 4, 8, 16Sample: Xi, Yi 32 bit int or float
Intel® MICVector size: 512bitData types: 32 and 64 bit integers 32 and 64bit floats (some support for 16 bits floats) VL: 8,16Sample: 32 bit float
X4
Y4
X4opY4
X3
Y3
X3opY3
X2
Y2
X2opY2
X1
Y1
X1opY1
0127X8
Y8
X8opY8
X7
Y7
X7opY7
X6
Y6
X6opY6
X5
Y5
X5opY5
128255
X4
Y4
…
X3
Y3
…
X2
Y2
…
X1
Y1
X1opY1
0X8
Y8
X7
Y7
X6
Y6
...
X5
Y5
…
255…
…
…
…
…
…
…
…
…
X9
Y9
X16
Y16
X16opY16
…
…
…
...
…
…
…
…
…
511
X9opY9 X8opY8 …
IntroduçãoVetorização

19
Cinco possíveis abordagens:
Bibliotecas matemáticas– Ex.: Intel® Math Kernel Library (MKL)
Auto-vetorização– Trabalho a cargo do Compilador
Array Notation – Cilk Plus– Notação vetorial na linguagem de programação explicitando a vetorização
Semi auto-vetorização– SIMD
– IVDEP
– VECTOR E NOVECTOR
C/C++ Vector classes– Intrinsics
IntroduçãoVetorização

20
Facilidade de Uso
Ajuste Fino
Vectors
Intel® Math Kernel Library
Array Notation: Intel® Cilk™ Plus
Auto vectorization
Semi-auto vectorization:#pragma (vector, ivdep, simd)
C/C++ Vector Classes(F32vec16, F64vec8)
Devemos avaliar três fatores:
Necessidade de
performance
Disponibilidade de recursos
para otimizar o código
Portabilidade do código
IntroduçãoVetorização
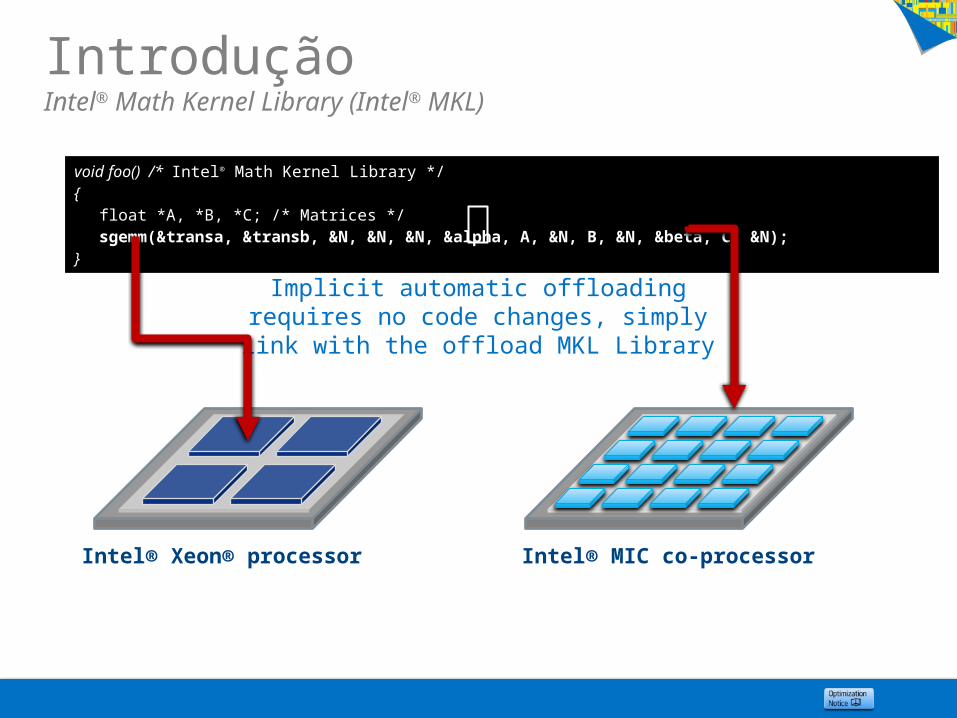
void foo() /* Intel® Math Kernel Library */ { float *A, *B, *C; /* Matrices */ sgemm(&transa, &transb, &N, &N, &N, &alpha, A, &N, B, &N, &beta, C, &N);}
Intel® Xeon® processor Intel® MIC co-processor
Implicit automatic offloading requires no code changes, simply link with the
offload MKL Library
IntroduçãoIntel® Math Kernel Library (Intel® MKL)


1º Passo: Parâmetros para o Compilador
vec-report[n] : relatório do que foi e do que pode ser vetorizado . “n” determina o nível de detalhes
guide : GAP – Guided Auto-parallelization . Sugestões de como vetorizar/paralelizar
O[n] : Nível de otimização O2 (default) já inclui auto-vetorização
x[code] : Otimiza as instruções de acordo com a arquitetura do processador. -xAVX , -xCORE-AVX2, -xSSE4.2, -xSSE4.1, -xSSSE3, -xSSE3
xHost: Compilador checa o processador e aplica a melhor instrução suportada
msse2 (default): (Windows: /arch:SSE2)
23
Auto-vetorização

m<extension>: checagem para processadores “não Intel®” Não aplica otimizações específicas para processadores Intel® Compatibilidade para processadores Intel® e “não Intel®” Instruções AVX suportadas em processadores “não Intel®”
ax<extension> Compilador gera dois caminhos: “genérico” e “otimizado” Ex: “icc -axCORE-AVX2 –axSSE4.2 codigo.c “ em um processador que suporta
somente SSE 4.2, o compilador ignora a instrução CORE-AVX2
24
Auto-vetorização

25
Ajudando o compilador a vetorizar Evitar “loop unrolling” manual pois:
Atrela otimização a arquitetura de hardware (Vector Processor Unit) Prejudica a leitura do código Parâmetro ao compilador: -unroll[=n]
Auto-vetorização
Unrolling Loop
1. double acc1 = 0, accu2 = 0, acc3 = 0, acc4 =0;2. for (i=0; i<NUM; i+=4) { 3. acc1 = src1[i+0] * src2 + acc1;4. acc2 = src1[i+1] * src2 + acc1;5. acc3 = src1[i+2] * src2 + acc1;6. acc4 = src1[i+3] * src2 + acc1;7. }8. accu = acc1 + acc2 + acc3 + acc4;
Forma simplificada
double acc = 0;// #pragma unroll(4) // #pragma nounroll for (i=0; i<NUM; i++) { accu = src1[i]*src2 + accu;}

26
Requisitos para um loop ser vetorizado
Em loops encadeados, o loop mais interno será vetorizado
Deve conter apenas blocos básicos, ex.: uma única linha de código sem
condições (if statements) ou saltos (go to)
Quantidade de iterações do loop deve ser conhecida antes de sua execução,
mesmo que em tempo de execução
Sem dependências entre os elementos a serem calculados
GAP – Guided Autoparallelization (Intel® Compiler “-guide” ) pode ajudar
Loop Não Vetorizável – Dependência sobre a[i-1]for (i=1; i<MAX; i++) { d[i] = e[i] – a[i-1]; a[i] = b[i] + c[i];}
Auto-vetorização


28
Tipos de diretivas: SIMD
Permissão total ao compilador vetorizar
Responsabilidade da vetorização é do programador
Mais agressivo que IVDEP ou VECTOR ALWAYS
IVDEP
Remove dependências entre ponteiros nos vetores
VECTOR e NOVECTOR
“Dicas” que mudam a heurística default do compilador
Habilita/desabilita vetorização
Alinhamento de dados, vetorização de loops sobressalentes
Diretivas - #pragma

29
Diretivas SIMD: forçando a vetorização
#pragma simd [clause[ [,] clause] ... ] Guia o compilador para casos onde a auto-vetorização não é possível
Atributos padrão:
VECTORLENGTH N : tamanho do vetor (2, 4, 8 ou 16)
VECTORLENGTHFOR (data-type) : tamanho_vetor/sizeof(type)
PRIVATE (VAR1[, VAR2]...) : variável privada para cada iteração do loop
FIRSTPRIVATE (VAR1[, VAR2]...) : broadcast do valor inicial a todas as outras instâncias para cada iteração
LASTPRIVATE (VAR1[, VAR2]...) : broadcast do valor original as outras instâncias no final do loop
LINEAR (var1:step [, var2:step2]...) : incrementa número de steps para cada variável em um loop, unit-stride vector
REDUCTION (oper:var1[, var2]...) : Aplica operação de redução (+, *, -, AND, OR, EQV, NEQV) nas variáveis indicadas
ASSERT : Direciona o compilador a produzir um erro ou um warning quando a vetorização falha
Diretivas - #pragma

30
Diretivas SIMD: forçando a vetorização
Programador é responsável por checar a validade dos resultados
Diretivas - #pragma
Diretivas SIMD Adição de vetores – C/C++
1.__declspec(align(16)) float a[MAX], b[MAX],
c[MAX];
2.#pragma simd
3.for (i=0; i<MAX; i++)
4. c[i] = a[i]+b[i];

31
Diretivas VECTOR
#pragma vector aligned | unaligned : comunica ao compilador que os dados estão alinhados
#pragma vector nontemporal | temporal ou “-opt-streaming-store always” : uso ótimo do cache em casos de write-only; os dados não precisam ser armazenados na cache, e sim diretamente na memória. Usar “#pragma vector aligned” antes.
#pragma novector : Instrui o compilador a não vetorizar. Útil em loops com muitas condições (ifs)
#pragma vector always : força vetorização automática independente da heurística do compilador
Diretivas - #pragma

32
Diretivas VECTORStreaming stores (Xeon and Xeon Phi) Escritas na memória que não necessitam de prévias operações de
leitura. Evita prefetch da memória para a cache
Nontemporal buffer Otimiza bandwith -opt-streaming-stores [always | never | auto ] #pragma vector nontemporal[(var1[, var2, ...])]
https://software.intel.com/en-us/articles/memcpy-memset-optimization-and-control
https://software.intel.com/sites/default/files/article/326703/streaming-stores-2.pdf
Diretivas - #pragma

33
Diretivas IVDEP
#pragma ivdep: Ignora dependências de variáveis
“-restrict” (necessário parâmetro ao compilador “-restrict”) : similar a “ivdep” , informa que determinada variável não possui restrições/dependências
Diretivas - #pragma
//-restrict necessario ao compilador neste casovoid vectorize (float* restrict a, float* restrict b, float* c, float* d, int n){ int i; for (i =0; i<n; i++) { a[i] = c[i] * d[i]; b[i] = a[i] + c[i] - d[i]; } ou #pragma ivdepvoid vectorize(float* a, float* b, float* c, float* d, int n) { … }

34
#pragma loop count : Informa ao compilador o número de loops . Útil para melhores predições de vetorização
__assume_aligned : elimita checagem se os dados estão alinhados, porém e´specífico para cada vetor
Diretivas - #pragma
void myfunc( double p[] ) {__assume_aligned(p, 64);for (int i=0; i<n; i++){p[i]++;}
int i;int mysum(int start, int end, int a){
int iret=0;#pragma loop_count min(3), max(10), avg(5) for (i=start;i<=end;i++) iret += a; return iret;
}

35
__attribute__((aligned(64)) ou __mm_malloc() / __mm__free() : alocação estática e dinâmica de dados alinhados
-opt-assume-safe-padding : Avisa o compilador que vetores com bytes extras, para que fiquem múltiplos do tamanho da cache, serão inseridos . Evita “loop sobressalente”
https://software.intel.com/en-us/articles/utilizing-full-vectors
Diretivas - #pragma
float data[n] __attribute__((aligned(64))); (Linux)
__declspec(align(64)) float A[n]; (Windows)
float *A = (float*)_mm_malloc(n*sizeof(float), 16);// ..._mm_free(A);

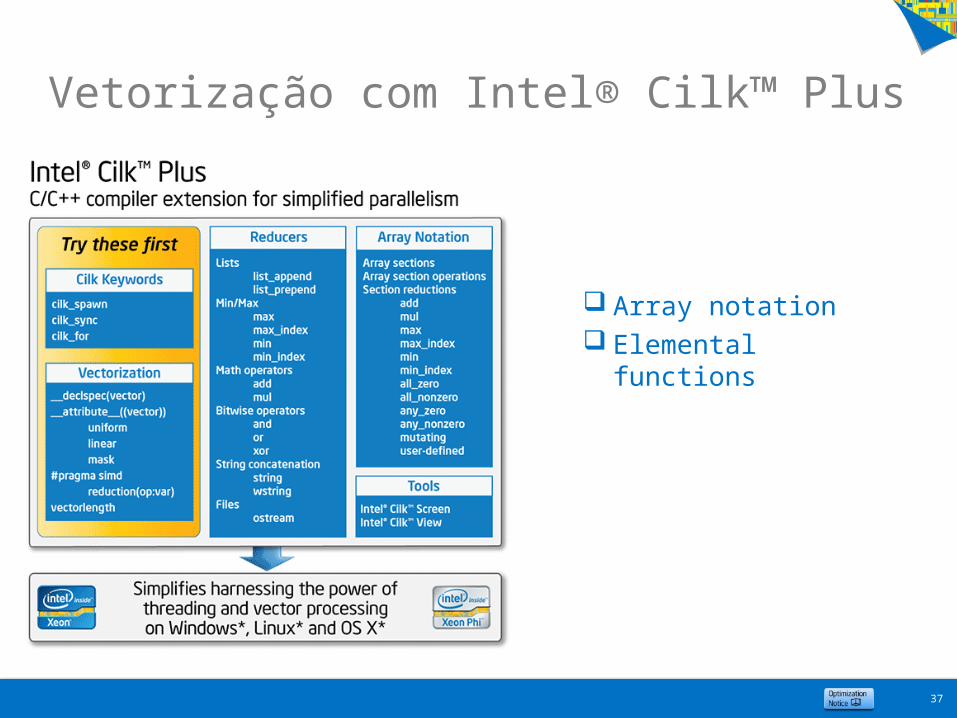
37
Array notation Elemental functions
Vetorização com Intel® Cilk™ Plus

38
Vetorização com Intel® Cilk™ Plus
Array notations
Extensões C++ Intel® Cilk Plus™ para operações com vetores
Notação vetorial em C/C++
https://software.intel.com/en-us/articles/getting-started-with-intel-cilk-plus-array-notations

39
A[:] += B[:]; // todo o vetor é computado
A[0:16] += B[32:16]; // A(0 até 15) + B(32 até 47)
A[0:16:2] += B[32:16:4] // A(0, 2, 4, ...30) + B(32, 36, 38, ... 92)
Compatibilidade com compiladores não-Intel
#ifdef __INTEL_COMPILER A[:] += B[:];#else for (int i=0; i<16; i++) A[i] += B[i];#endif
Vetorização com Intel® Cilk™ Plus
Array notations

40
Adição de vetores – C/C++ - Dados alinhados
1.__declspec(align(16)) float a[MAX], b[MAX], c[MAX];
2.c[i:MAX] = a[i:MAX]+b[i:MAX];
Vetorização com Intel® Cilk Plus
Array notations

41
Possibilita chamar versão vetorizada da função escalar
Excelente em casos onde as funções estão
implementadas em biblioteca de terceiros
https://software.intel.com/en-us/articles/elemental-
functions-writing-data-parallel-code-in-cc-using-intel-cilk-
plus
Vetorização com Intel® Cilk Plus
Elemental functions

42
Lib Xfloat my_simple_add(float x1, float x2){ return x1 + x2;}
Elemental Function
__attribute__(vector) float my_simple_add(float x1, float x2);
// ...em outro arquivo de código#pragma simdfor (int i=0; i < N, ++i) { output[i] = my_simple_add(inputa[i], inputb[i]); }
Ou my_simple_add(inputA[:], inputB[:]);
Vetorização com Intel® Cilk Plus
Elemental functions


44
O que é Intel® C++ Intrinsic ?
Provê acesso a ISA (Instruction Set Architecture) através de código C/C++ ao
invés de código Assembly
Ganho de performance próximo a códigos Assembly com a facilidade de C/C+
+
Vetorização – Extensões SIMD (Simple Instructions Multiple Data)
Intrinsics

45
MIC Intrinsics
SSE Intrinsics
Intrinsics SSE
for (int i=0; i<n; i+4){ __m128 vecA = _mm_load_ps(A+i); __m128 vecB = _mm_load_ps(B+i); vecA = _mm_add_ps(vecA, vecB); _mm_store_ps(A+i, vecA);}
vecA[0] vecA[1] vecA[2] vecA[3]
SSE Register – 128 bits4 packed single precision
vecB[0] vecB[1] vecB[2] vecB[3]
DRAM A* | B* | ...
addvecA[0] vecA[1] vecA[2] vecA[3]
Intrinsics AVX-512
for (int i=0; i<n; i+4){ __m512 vecA = _mm_load_ps(A+i); __m512 vecB = _mm_load_ps(B+i); vecA = _mm512_add_ps(vecA, vecB); _mm512_store_ps(A+i, vecA);}
Intrinsics


General Purpose vs. Specialty Hardware
Investment locked into one architecture
Reusable, Portable, Scalable
*Other logos, brands and names are the property of their respective owners.All products, computer systems, dates and figures specified are preliminary based on current expectations, and are subject to change without notice.
Device-Specific Applications
(Accelerators)
Applications Suitable for Many Architectures (CPU)

48
Conclusões
Vetorização
Permite obter mais performance
Uso de padrões abertos
Mesma técnica de programação para CPUs e Co-processadores
Vários maneiras de vetorizar: Facilidade ou “Ajuste fino”

49
Iniciativas da Intel® no Ecossistema de HPC do Brasil

Intel® Innovation Center &Intel ® Parallel Computing Centers Leverage Expertise & Application Development in HPC
Intel® Innovation Center
Competence Center Test & Dev. Environment HPC & Big Data Applications Universities / Government
HPC Educational Center Accelerator Program
Startup Incubator Accelerator Program
Solution Center “HPC as a Service” Prototyping PoCs in many verticals:
Oil & Gas, Heathcare & Life Sciences, Agriculture, Manufacture & Infra-structure, Financial
Universities
Research Centers
IndustryPrivate Sector
Government
Intel

Intel® Innovation Center &Intel® Parallel Computing Centers Leverage Expertise & Application Development in HPC
• Modernizing applications to increase parallelism and scalability
• Leverage cores, caches, threads, and vector capabilities of microprocessors and coprocessors.
• Current centers in Brazil (more to come):

HPC Verticals Leverage Expertise & Application Development in HPC
Oil & Gas
Ex. Petrobras, British Gas,
SENAI
Reservoir Simulation
Seismic Data Analysis
DataVisualization
Transport.
Ex. DENATRAN
Traffic Mgt
Traffic Surveillance
Taxes Payment
Parking Mgt
Tolls
Health Care Life Science
Ex. LNCC
Genome Projects (Cure of
Diseases)
Biology Systems
Image Processing for
Medicine
Modeling & Simulation for
Medicine
Agriculture
Ex. Embrapa
Modeling, Simulation & Forecast in Agricultural Production
Development of seeds more resistent to wheather conditions
Biofuels Production
Manufacture &Infra.
Ex. Embraer, Odebrecht
Construction & Engineering:• Structural Calculus / Design
of new Products• 3D / CAD / CAM
Aeronautics:• Aerodynamics• Flight Simulator• Virtual Reality
Automotive Industry:• Car Design• Crash Simulation
Computational Mechanics• Fluids & Dynamics• Thermodynamics• Solid Mechanics
Financial & TelcosEx. Itau
Derivatives trading
Stocks (Monte Carlo
simulations)
Our goal is to interact with each vertical in order to support the ecosystem.The next wave is to use HPC + Big Data solutions based on the “Software as a Service” model.
IaaS PaaS SaaS

53
Parallel is Your Path ForwardIntel® Solutions
for HPC

From CPU to Solutions
Intel is only company on the planet that is targeting the broad range of technologies and devices to bring a great solution to every segment of the Technical Computing market.
Network& Fabrics
Software& Services
ComputeIntel® Xeon®
Intel® Xeon Phi™
I/O & Storage
CAS
Intel®ClusterReadyIntel® Enterprise
Editionfor Lustre* software
Power efficiencyResiliencyReliability

Next Intel® Xeon Phi™ Product Family Codenamed Knights Landing
All products, computer systems, dates and figures specified are preliminary based on current expectations, and are subject to change without notice.
Available in Intel cutting-edge 14 nanometer process
Stand alone CPU or PCIe coprocessor – not bound by ‘offloading’ bottlenecks
Integrated Memory - balances compute with bandwidth
Parallel is the path forward, Intel is your roadmap!
55

All products, computer systems, dates and figures specified are preliminary based on current expectations, and are subject to change without notice. 1Over 3 Teraflops of peak theoretical double-precision performance is preliminary and based on current expectations of cores, clock frequency and floating point operations per cycle. FLOPS = cores x clock frequency x floating-point operations per second per cycle. . 2Modified version of Intel® Silvermont microarchitecture currently found in Intel® AtomTM processors. 3Modifications include AVX512 and 4 threads/core support. 4Projected peak theoretical single-thread performance relative to 1st Generation Intel® Xeon Phi™ Coprocessor 7120P (formerly codenamed Knights Corner). 5 Binary Compatible with Intel Xeon processors using Haswell Instruction Set (except TSX) . 6Projected results based on internal Intel analysis of Knights Landing memory vs Knights Corner (GDDR5). 7Projected result based on internal Intel analysis of STREAM benchmark using a Knights Landing processor with 16GB of ultra high-bandwidth versus DDR4 memory only with all channels populated.
Unveiling Details of Knights Landing (Next Generation Intel® Xeon Phi™ Products)
Conceptual—Not Actual Package Layout
2nd half ’15 1st commercial
systems
3+ TFLOPS1 In One Package
Parallel Performance & Density
On-Package Memory: up to 16GB at launch
5X Bandwidth vs DDR47
Compute: Energy-efficient IA cores2
Microarchitecture enhanced for HPC3
3X Single Thread Performance vs Knights Corner4
Intel Xeon Processor Binary Compatible5
1/3X the Space6
5X Power Efficiency6
. . .
. . .
Integrated Fabric
Intel® Silvermont Arch.
Enhanced for HPC
Processor Package
. . . . . .
. . .
. . . . . .
. . . . . .
…
Platform Memory: DDR4 Bandwidth and Capacity Comparable to Intel® Xeon® Processors
Jointly Developed with Micron Technology

Intel® InfiniBand TechnologyOverview
END-TO-END INFINIBAND PRODUCT LINE
DESIGNED FROM THE START FOR HPC
OPTIMIZE HPC INTERCONNECT• High Messaging Rate
• Low End-to-End Latency - that scales
• Excellent Collectives Performance
• More Effective Bandwidth
PROVIDING BETTER HPC APPLICATION
PERFORMANCE AND SCALABILITY
(PRICE/PERFORMANCE)
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
See slide notes for more configuration and test details

Intel® OMNI Scale The Next-Generation Fabric
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
See slide notes for more configuration and test details
Designed for Next Generation HPC
Host and Fabric Optimized
Supports Entry to Extreme Scale
End-to-End Solution
Intel Omni Scale
Intel Omni Scale
Knights Landing
14nm generation
INTEGRATION
Intel® Processor
Fabric Controller
32 GB/sec
System IO Interface (PCIe) Fabric InterfaceToday
Intel ® Processor
Fabric Controller
100+ GB/sec
TomorrowFabric Interface
intel.com/OmniScale

59
Unleashing CPU Performance in HPC via Intel® Software
Cloud Computing
Virtualization
Open Source Cloud Mgt
Comerical Cloud Mgt
Applications
Dist. ComputeCloudera Hadoop Dist.
HPC ComputingIntel® Parallel Studio XE and Intel® Cluster Studio
XE
Intel® Cluster Ready
Intel ® Data Center Manager ( Power and Thermal Mgt)
Intel® Lustre
Intel® LustreIntel® True
Scale Fabric Management and Software Tools
Intel® True Scale fabric
Intel® Innovation Center Architecture

• Architecture, setup, and programming resources
• Self-guided training
• Case studies
• Information on tools and ecosystem
• Support through community forum
INTEL® XEON PHI™ COPROCESSOR DEVELOPER SITE
View at: http://software.intel.com/mic-developer/

©2014, Intel Corporation. All rights reserved. Intel, the Intel logo, Intel Inside, Intel Xeon, and Intel Xeon Phi are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others. 61

62
OPTIMIZATION NOTICE
Optimization Notice
Intel’s compilers may or may not optimize to the same degree for non-Intel
microprocessors for optimizations that are not unique to Intel microprocessors.
These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other
optimizations. Intel does not guarantee the availability, functionality, or
effectiveness of any optimization on microprocessors not manufactured by
Intel. Microprocessor-dependent optimizations in this product are intended for
use with Intel microprocessors. Certain optimizations not specific to Intel
microarchitecture are reserved for Intel microprocessors. Please refer to the
applicable product User and Reference Guides for more information regarding
the specific instruction sets covered by this notice.
Notice revision #20110804