privacy-preserving data mining: current research and … · privacy-preserving data mining: current...
TRANSCRIPT

Privacy-preserving Data Mining: current research and trends
Stan MatwinSchool of Information Technology and Engineering
University of Ottawa, [email protected]

2
Few words about our researchUniversit[é|y] [d’|of] Ottawa is thelargest bilingual university in Canada
• Applied research and tech transfer – Profiles of digital game players/ active learning, co-
training, instance selection– Classification of medical abstracts
• Privacy-aware Data Mining
• Text Analysis and Machine Learning group
• Learning with previous knowledge

3
Plan • What is [data] privacy?• Privacy and Data Mining• Privacy-preserving Data mining: main
approaches– Anonymization– Obfuscation– Cryptographic hiding
• Challenges– Definition of privacy– Mining mobile data– Mining medical data

4
Privacy
• Freedom to be left alone• …ability to control who knows what about
us [Westin; Moor] [=database views]• Jeopardized with the Internet – greased
data• Moral obligation for the community to find
solutions

5
Privacy and data mining
• Individual Privacy– Nobody should know more about any entity after the
data mining than they did before– Approaches: Data Obfuscation, Value swapping
• Organization Privacy– Protect knowledge about a collection of entities– Individual entity values are not disclosed to all parties
• The results alone need not violate privacy

6
Basic ideas
• Camouflage • Hiding
obfuscation k-anonymity

7
Why naïve anonymization does not work
• The [Sweeney 01] experiment• purchased the voter registration list for Cambridge, MA
– 54,805 people
• 69% unique on postal code and birth date; 87% US-wide with all three
• Also, we do not know with what other data sources we may do joins in the future
• Solution: k-anonymization

8
Randomization Approach Overview
50 | 40K | ...30 | 70K | ... ...
...
Randomizer Randomizer
ReconstructDistribution
of Age
ReconstructDistributionof Salary
ClassificationAlgorithm Model
65 | 20K | ... 25 | 60K | ... ...Age 30
becomes 65
(30+35)
Salary 70K
becomes 20K
Alice’s age

9
Reconstruction Problem
• Original values x1, x2, ..., xn from probability distribution X (unknown)
• To hide these values, we use y1, y2, ..., ynfrom known distribution Y
• Given– x1+y1, x2+y2, ..., xn+yn
– the probability distribution of Y Estimate the probability distribution of X.

10
Intuition (Reconstruct single point)
• Use Bayes' rule for density functions
10 90Age
V
Original distribution for AgeProbabilistic estimate of original value of V

11
Works well
0
200
400
600
800
1000
1200
20 60
Age
Num
ber
of P
eopl
e
OriginalRandomizedReconstructed

12
Recap: Why is privacy preserved?
• Cannot reconstruct individual values accurately.
• Can only reconstruct distributions.

13
Classification
• Naïve Bayes– Assumes independence between attributes.
• Decision Tree– Correlations are weakened by randomization,
not destroyed.

14
Decision Tree Example
Age Salary Repeat Visitor?
23 50K Repeat17 30K Repeat43 40K Repeat68 50K Single32 70K Single20 20K Repeat
Age < 25
Salary < 50K
Repeat
Repeat
Single
Yes
Yes
No
No

15
Decision Tree Experiments
Fn 1 Fn 2 Fn 3 Fn 4 Fn 550
60
70
80
90
100
Acc
urac
y Original
Randomized
Reconstructed
100% Randomization Level
100% privacy: attribute cannot be estimated(with 95% confidence) any closer than the entire range for the attribute

16
• For very high privacy, discretization will lead to a poor model
• Gaussian provides more privacy at higher confidence levels
• In fact, it can be de-randomized using advanced control theory approach [Kargupta 2003]
Issues

17
Association Rule Mining Algorithm [Agrawal et al. 1993]
1. = large 1-itemsets2. for do begin3. 4. for all candidates do begin5. compute c.count 6. end7. 8. end9. Return
1L);;2( 1 ++≠= − kLk k φ)( 1−−= kk LgenaprioriC
kCc ∈
sup}min.|{ −≥∈= countcCcL kk
kk LL U=
c.count is the frequency count for a given itemset.
Key issue: to compute the frequency count, we needs to access attributes that belong to different parties.

18
An Example
• c.count is the vector product.• Let’s use A to denote Alice’s
attribute vector and B to denote Bob’s attribute vector.
• AB is a candidate frequent itemset, then c.count = A • B = 3.
• How to conduct this computation across parties without compromising each party’s data privacy?
A B
Alice Bob
11101
01111

19
Homomorphic Encryption [Paillier 1999]
• Privacy-preserving protocols are based on Homomorphic Encryption.
• Specifically, we use the following additive homomorphism property:
• Where e is an encryption function and is the data to be encrypted and .
)()()()( 2121 nn mmmemememe +++=××× LL
im0)( ≠ime

20
Digital Envelope[Chaum85]
• A digital envelope is a random number (a set of random numbers) only known by the owner of private data.
V V + R VV
21
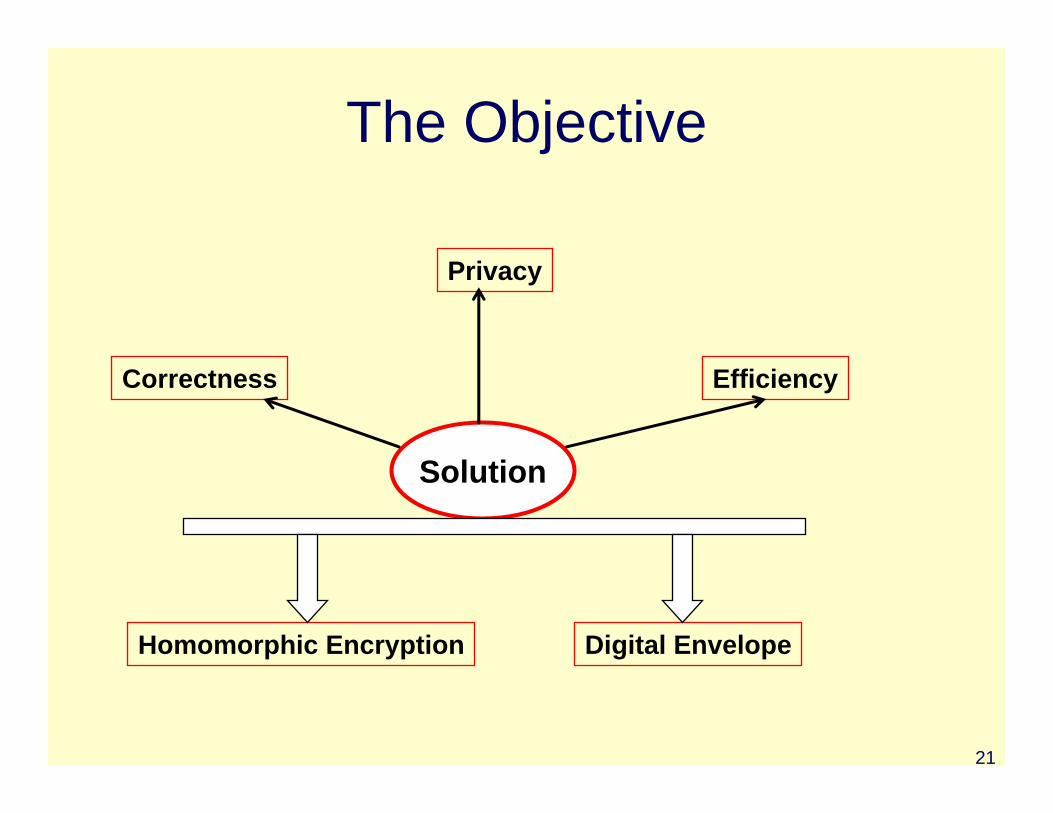
The Objective
Solution
Homomorphic Encryption Digital Envelope
Correctness
Privacy
Efficiency

22
Frequency Count Protocol• Assume Alice’s attribute vector is A and Bob’s
attribute vector is B.• Each vector contains N elements.• : the ith element of A.• : the ith element of B.• One of parties is randomly chosen as a key
generator, e.g, Alice, who generates (e, d) and an integer X > N. e and X will be shared with Bob.
• Let’s use e(.) to denote encryption and d(.) to denote decryption.
iA
iB

23
……
Alice
XRA ×+ 11
Digital envelopes
XRA ×+ 22 XRA NN ×+
NRRR ,, 21 L A set of random integers generated by Alice

24
XRA ×+ 22XRA NN ×+……
Alice
)( 11 XRAe ×+ )( 22 XRAe ×+ )( XRAe NN ×+……
XRA ×+ 11

25
)( 22 XRAe ×+ )( XRAe NN ×+……)( 11 XRAe ×+
Alice
Bob
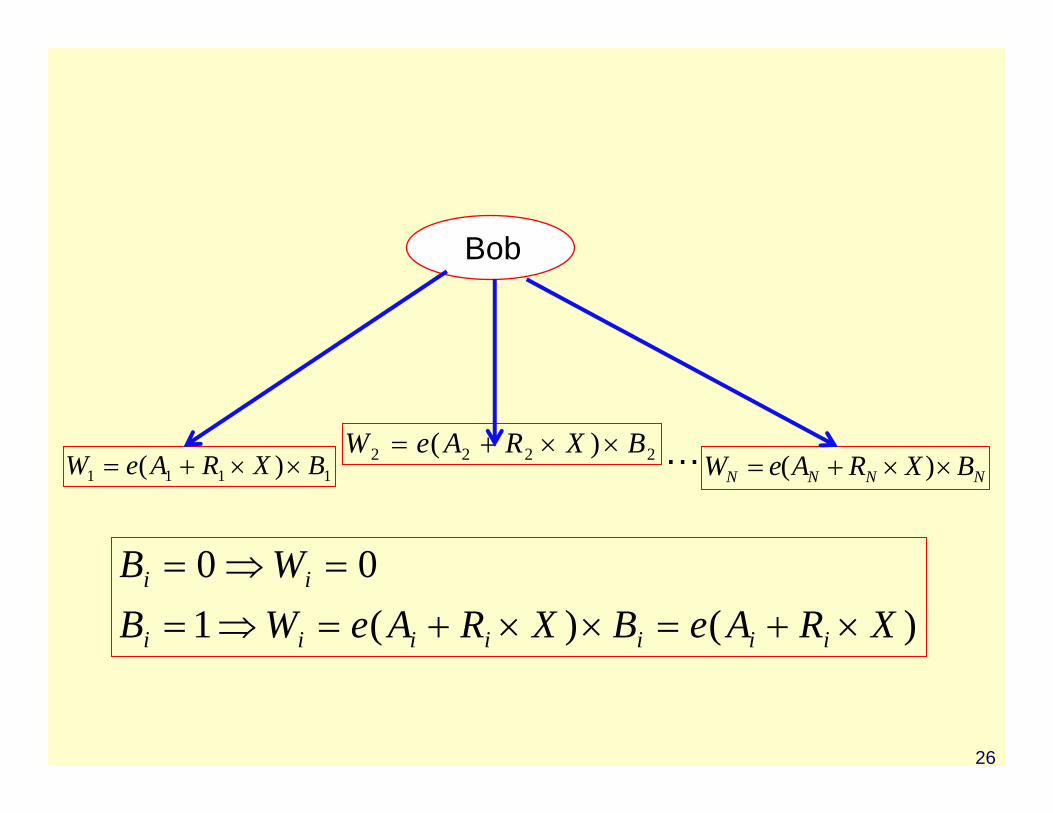
26
1111 )( BXRAeW ××+= 2222 )( BXRAeW ××+=NNNN BXRAeW ××+= )(…
Bob
)()(100
XRAeBXRAeWBWB
iiiiiii
ii
×+=××+=⇒==⇒=

27
• Bob multiplies all the for those that are not equal to 0. In other words, Bob computes the multiplication of all non-zero , e.g., where .
sWi sBi
sWi ∏= iWW
0≠iW
jWWWW ×××= L21

28
jWWWW ×××= L21
])([])([])([ 222111 jjj BXRAeBXRAeBXRAe ××+××××+×××+= L||
1
||
1
||
1

29
jWWWW ×××= L21
]1)([]1)([]1)([ 2211 ××+××××+×××+= XRAeXRAeXRAe jjL

30
jWWWW ×××= L21
)()()( 2211 XRAeXRAeXRAe jj ×+×××+××+= L
))(( 2121 XRRRAAAe jj ×+++++++= LL
According to the property of homomorphic encryption

31
• Bob generates an integer .
• Bob then computes
'R
)'(' XReWW ××=
Alice
))'(( 2121 XRRRRAAAe jj ×++++++++= LL
According to the property of homomorphic encryption

32
The Final Step
• Alice decrypts and computes modulo X.
• She then obtains for those Aj for which corresponding Bj are 0, which is = c.count
'W
XXRRRRAAAedcountc
jj mod)))'(((.
2121 ×++++++++= LL
0mod))'((
)(
21
21
=×++++
<≤+++
XXRRRR
XNAAA
j
j
L
L
1 2 jA A A+ + +L

33
Privacy Analysis
• All the information that Bob obtains from Alice is.
• Since Bob doesn’t know the decryption key d, he cannot get Alice’s original data values.
)(,),(),( 2211 XRAeXRAeXRAe NN ×+×+×+ L
Goal: Bob never sees Alice’s data values.

34
Privacy Analysis
The information that Alice obtains from Bob is for those .
Alice computes . She only obtains the frequencycount and cannot know Bob’s original data values.
XWd mod)'(
))'((' 2121 XRRRRAAAeW jj ×++++++++= LL 1=iB
Goal: Alice never sees Bob’s data values.

35
Complexity Analysis
)1( +Nα αwhere N is the total number transactions and is the number of bits for each encrypted element.
Linear in the number of transactions
The total number elements in each attribute vector

36
Complexity Analysis
The computational cost is (10N + 20 + g) where N is the total numbertransactions and g is the computational cost for generating a key pair.
Linear in the number of transactions

37
Other Privacy-Oriented Protocols
Multi-Party Frequency Count Protocol
Multi-Party Summation Protocol
Multi-Party Comparison Protocol
Multi-Party Sorting Protocol
[Zhan et al. 2005 (a)]
[Zhan et al. 2005 (f)]
[Zhan et al. 2006 (a)]
[Zhan et al. 2006 (a)]

38
What about the results of DM?
• Can DM results reveal personal information?• In some cases, yes [Atzori et al. 05]:Suppose an association rule is found:
This meansthen therefore has support=1, and
identifies one person!!
1 2 3 4[sup 80, 98.7%]a a a a conf∧ ∧ ⇒ = =
1 2 3 4a a a a∧ ∧ ∧¬
1 2 3 4sup({ , , , }) 80a a a a =1 2 3 4
1 2 3sup({ , , , }) 0.8sup({ , , }) 81.05
0.987 .0987a a a aa a a = = =

39
• They propose an approach called k-anonymous patterns and an algorithm (inference channels) which detects violations of k-anonymity
• The algorithm is expensive computationally• We have a new approach which embeds k-
anonimity into the concept lattice association rule algorithm [Zaki, Ogihara 98]

40
Conclusion
• Important problem, challenge for the field• Lots of creative work, but lack of systematic
approach• Medical data particularly sensitive, but also
makes de-identification easier: genotype-phenotype inferences, location-visit patterns, family structures, etc. [Malin 2005]
• Lack of an operational, agreed upon definition of privacy: inspiration in economics?