proyectos de sistemas de software - cs.uns.edu.arcs.uns.edu.ar/~gis/pss/downloads/teoria/(pss)...
TRANSCRIPT

Proyectos de Sistemas de SoftwareIngeniería en Sistemas de Información
Uso de métricas
para la toma de decisiones (II)
Probabilidades, estadísticas y razonamiento causal
Profesor: Gerardo I. Simari
Depto. de Ciencias e Ingeniería de la Computación
Universidad Nacional del Sur – Bahía Blanca, Argentina
2do. Cuatrimestre de 2018

Uso de métricas• Como ya vimos, hay distintos tipos de métricas y escalas
de medición aplicables según el dominio y el propósito.
• La toma de medidas según un conjunto o plan de métricas es sólo el primer paso.
• La interpretación adecuada de las medidas tomadas es absolutamente fundamental para el éxito del esfuerzo.
• Ahora nos enfocaremos en algunos conceptos básicos de estadística y probabilidad para evitar errores comunes de interpretación.
2

Límites de análisis estadísticos simples• Supongamos que estamos a cargo de una financiera en
Reino Unido y queremos decidir cuánto crecerá la economía el año que viene.
• Estamos en el primer trimestre de 2008 y disponemos de datos tomados cada trimestre desde 1993.
• Veamos primero los datos crudos tabulados, y luego en un gráfico de curvas...
3

Crecimiento trimestral anualizado de Reino Unido ajustado por inflación (Q1 1993–Q1 2008)
4
[FN2013]
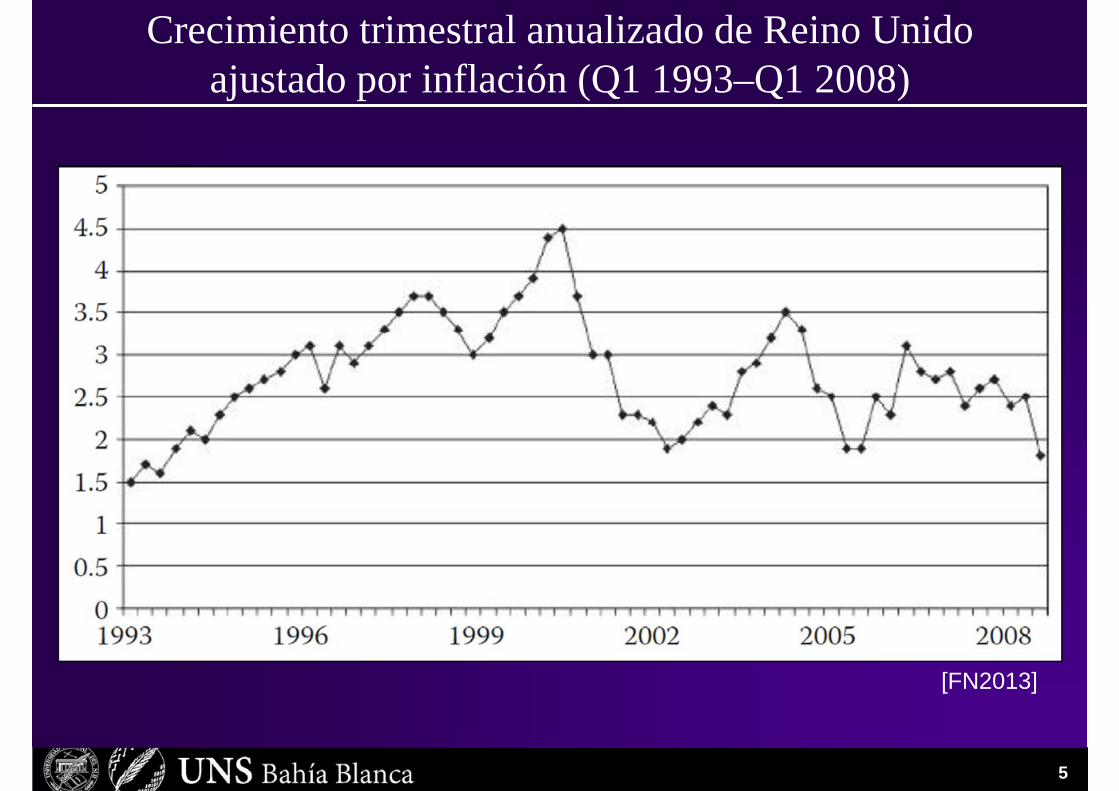
Crecimiento trimestral anualizado de Reino Unido ajustado por inflación (Q1 1993–Q1 2008)
5
[FN2013]

PrediccionesAlgunas preguntas que nos gustaría poder contestar:
• ¿Cuál es la probabilidad de que el crecimiento de este año esté entre 1,5% y 3,5%? Esto representaría una economía estable.
• ¿Cuál es la probabilidad de que el crecimiento sea menor a 1,5% en cada uno de los tres trimestres siguientes?
• ¿Cuál es la probabilidad de que en el espacio de un año haya crecimiento negativo (recesión)?
Una aproximación típica a estas preguntas es ajustar los datos a una distribución Normal:
6
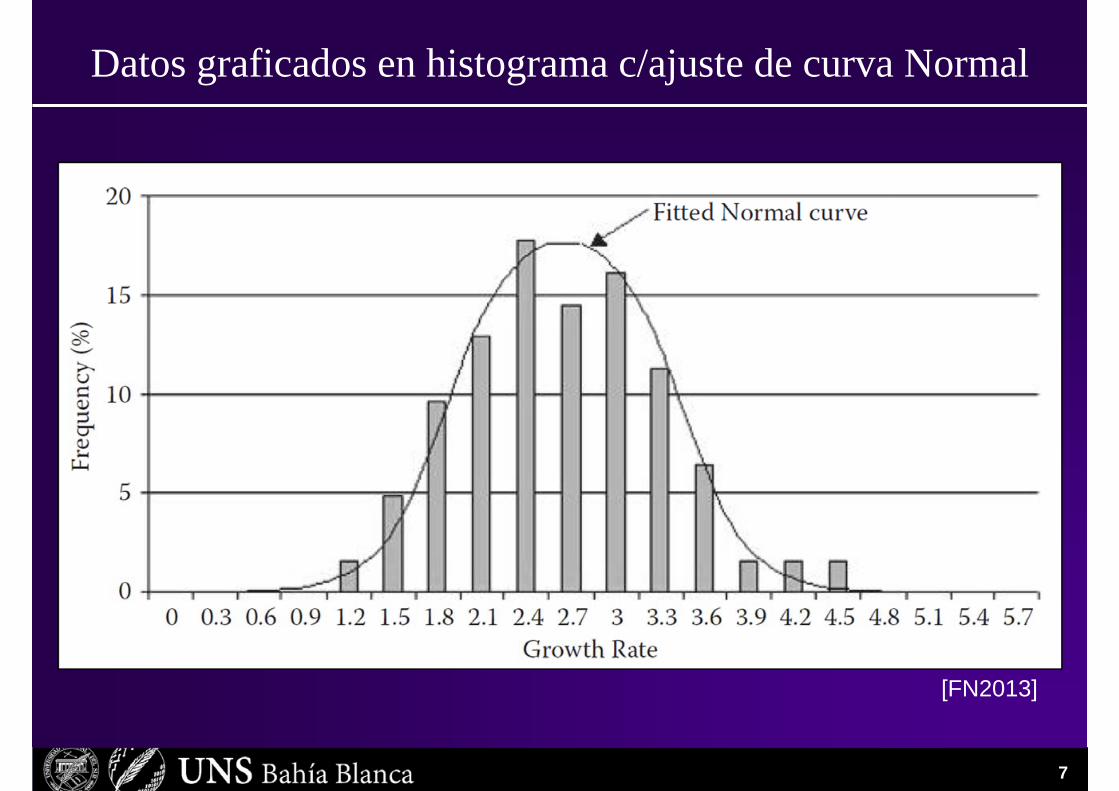
Datos graficados en histograma c/ajuste de curva Normal
7
[FN2013]

Distribución NormalBreve repaso de la distribución Normal:
• La distribución es simétrica alrededor de un punto llamado la media;
• Por lo tanto, exactamente la mitad de la población tiene valor mayor que la media (por lo tanto, la otra mitad tiene valor menor).
• La dispersión (qué tanto varían los números de la media) se captura con el desvío estándar.
• Propiedad: 95% de la masa de la distribución yace entre la media más/menos 1,96 veces el desvío estándar.
• La distribución tiene dos colas infinitas que se aproximan asintóticamente al eje X (es decir, valor cero en el eje Y).
8

Distribución Normal
9
[FN2013]

Distribución Normal
10
[FN2013]

PrediccionesVolvamos a nuestras preguntas; si tomamos el modelo que surge de ajustar una curva Normal, tenemos:
• ¿Cuál es la probabilidad de que el crecimiento de este año esté entre1,5% y 3,5%?
Respuesta: Aproximadamente 72%
• ¿Cuál es la probabilidad de que el crecimiento sea menor a 1,5% en cada uno de los tres trimestres siguientes?
Respuesta: 0,0125% (1 en 8.000)
• ¿Cuál es la probabilidad de que en el espacio de un año haya crecimiento negativo (recesión)?
• Respuesta: 0,0003% (menos de 1 en 30.000)
11

PrediccionesLa realidad sorprendió a todos cuando la economía colapsó y entró en una recesión que duró varios trimestres:
Aun usando datos de más años, este tipo de modelo no es adecuado porque las condiciones de 2008 eran únicas.
12
[FN2013]

CorrelacionesSi tenemos dos variables, las herramientas estándar para determinar relaciones entre ellas son las correlaciones y valores de significancia (valores p):
• Coeficiente de correlación: número entre −1 y 1; un valor de 1 indica una correlación positiva y −1 una negativa.
• La confianza en la relación no sólo depende del coeficiente, sino también de la cantidad de pares analizados.
• El valor p es un número entre 0 y 1 que representa la probabilidad de que se dé la muestra si la relación fuera en realidad inexistente.
• Esto se puede calcular fácilmente con planillas de cálculo.
13

CorrelacionesExisten varias razones por las cuales debemos tener cuidado al interpretar este tipo de resultados:
• El valor p se fija de manera arbitraria, y generalmente no tiene relación con lo que nos interesa, como la magnitud del impacto en la relación.
• Sólo estamos analizando preguntas existenciales e ignoramos causas.
• Falacia del condicional transpuesto:
– Tenemos la probabilidad de observar los datos dado que la hipótesis nula es verdadera (es decir, que no hay correlación).
– No es lo mismo que la probabilidad de que la hipótesis nula sea verdadera dados los datos.
– Este error lógico es similar al siguiente: “Si está soleado, Alicia va a pasear.”; ahora, “veo que Alicia sale a pasear, por lo tanto está soleado”.
14

Correlaciones• Supongamos que estamos evaluando dos drogas para
perder peso: Precision y Oomph.
• Para cada una hacemos un estudio para probar la hipótesis nula: “Tomar la droga no lleva a perder peso.”
– Para Precision: pérdida promedio de 5lbs. y cada uno de los 100 participantes pierde entre 4,5lbs y 5,5lbs.
– Para Oomph: pérdida promedio de 20lbs. y cada uno de los 100 participantes pierde entre 10lbs y 30lbs.
• Oomph parece ser mejor, pero el valor p de Precisionresulta mucho menor; esto se da porque estos análisis “premian” la baja varianza sobre la magnitud del impacto.
15

Correlaciones inesperadas
Fuente: http://tylervigen.com/spurious-correlations16

Correlaciones inesperadas
Fuente: http://tylervigen.com/spurious-correlations17

Fábrica de correlaciones• Notablemente, este tipo de correlaciones surge bastante
fácilmente aun en datos totalmente aleatorios.
• Supongamos que queremos “fabricar” una correlación entre algún comportamiento y el éxito al rendir exámenes finales.
• Pensemos unos 18 comportamientos que se pueden caracterizar con un número del 1 al 10; por ejemplo:– Porcentaje de clases a la que asiste el alumno– Horas por día de estudio– Cantidad de partidos de fútbol jugados– Porcentaje de días a la semana en la que consume pasta– ...
18

Fábrica de correlacionesCon una planilla de cálculo generamos una tabla al azar:
Las columnas A a R son los factoresanalizados.
La columna S es la nota del examen.
Cada fila representa un alumno.
19
[FN2013]

Fábrica de correlaciones: Resultados• En este caso, los números obtenidos en H y S tienen un
coeficiente de correlación de 0,59, lo cual indica una correlación bastante fuerte.
• Dado que la tabla fue creada aleatoriamente, H bien podría representar la cantidad de partidos de fútbol jugados.
• También surgen correlaciones entre las columnas de comportamiento; por ejemplo, B y Q tienen un coeficiente de 0,62.
• Esto podría terminar en una conclusión como:
“Consumir pasta ayuda a estudiar muchas horas por día.”
20

21
Medidas de tendencia central

Promedios• Supongamos que Alicia y Beto estudian la misma carrera y
ambos están compitiendo por una beca.
• En dos años hacen 10 materias, con los siguientes resultados:
– Promedios del 1er año: Alicia: 50, Beto: 40
– Promedios del 2do año: Alicia: 70, Beto: 62
– Promedios de estos resultados: Alicia: 60, Beto: 51
• Al terminar el 2do año, la Universidad determina que Beto tuvo mejores notas y le da la beca; ¿cómo puede ser?
22

Promedios• El problema yace en que desconocemos la cantidad de
materias que hizo cada uno en cada año:
– Alicia hizo 7 en el 1er año y 3 en el 2do.
– Beto hizo 2 en el 1ero y 8 en el 2do.
• Con esta información, podemos calcular sus verdaderos promedios generales:
– Alicia: (7 ∗ 50 + 3 ∗ 70) / 10 = 56
– Beto: (2 ∗ 40 + 8 ∗ 62) / 10 = 57,6
• Ahora vemos que a Beto en realidad le fue un poco mejor.
23

Promedios• Este es un ejemplo de la Paradoja de Simpson.
• La paradoja surge cuando versiones estratificadas (de los mismos datos) producen resultados diferentes a versiones no estratificadas.
Ejemplo de pruebas de efectividad de una droga:
24
[FN2013]

Promedios• Este es un ejemplo de la Paradoja de Simpson.
• La paradoja surge cuando versiones estratificadas (de los mismos datos) producen resultados diferentes a versiones no estratificadas.
Ejemplo de pruebas de efectividad de una droga:
25
[FN2013]
Este cuadro muestra que al tomar la droga se recuperaron 20 de las 40 personas (50%)Comparando con el placebo, vemos que sólo 16 de 40 (40%) se recuperan.
Estratificando por sexo tenemos:Mujeres: 60% droga vs. 70% placeboHombres: 20% droga vs. 30% placebo
¡En ambos la tasa de recuperación es mayor sin la droga!

La Paradoja de Simpson
26
[https://www.methodsman.com/blog/pasta-bmi-and-simpsons-paradox]

La Paradoja de Simpson
27
[https://www.methodsman.com/blog/pasta-bmi-and-simpsons-paradox]

La Paradoja de Simpson
28
[https://www.methodsman.com/blog/pasta-bmi-and-simpsons-paradox]
Mismos datos, pero estratificados según la categoría de peso (los naranjas corresponden a pesos más altos, los verdes a los más bajos.

Medidas de tendencia central• La media aritmética (o promedio) es sólo una de las
posibles medidas de tendencia central de una muestra.
• Otras muy usadas son:
– Mediana: el valor que queda en la posición central al ordenar a todos los valores de menor a mayor.
– Moda: el valor que más se repite.
• Si la distribución no es Normal ni Uniforme, estos valores pueden ser muy diferentes entre sí.
• Veamos un ejemplo...
29

Distribución de sueldos de una ciudad
30
[FN2013]

Medidas de tendencia central• En esta población, el 83% de las personas tiene salarios
entre $10.000 y $50.000.
• Sin embargo, un 2% tiene salarios de más de $1.000.000.
• Esta asimetría hace que:
– la mediana sea de $23.000
– la media aritmética sea de: $137.000
• Veamos qué puede suceder si estos valores se confunden o no se comprende la diferencia entre ellos...
31

Usar la media cuando se necesita la mediana• Usted es el intendente de la ciudad en la que vive la
población cuyos sueldos analizamos antes.
• Dada la distribución observada, decide implementar un paquete de redistribución de la riqueza:
– Cada trabajador que cobra por encima del promedio pagará un impuesto adicional de $100.
– Cada trabajador que cobra por debajo cobrará un adicional de $100.
– Su plan es que esto debería ser neutral para las arcas de la Ciudad, dado que los valores se cancelan entre sí.
32

Usar la media cuando se necesita la mediana• Lamentablemente, usted se confunde y utiliza la media en
vez de la mediana:
– Sólo 5.000 trabajadores pagan los $100 extra; entran $500.000 a las arcas.
– A 95.000 trabajadores les corresponden los $100 adicionales; se necesitan $9.500.000.
• Si bien mucha gente está contenta, ahora usted debe conseguir $9.000.000 de presupuesto adicional para financiar la medida.
33

Usar la mediana cuando se necesita la media• Ahora, usted debe recolectar $100.000.000 para financiar un
proyecto de mejora de infraestructura.
• Decide que todos los trabajadores contribuirán un monto fijopara el proyecto.
• Dado su error anterior, utiliza la mediana y concluye que cada uno debe contribuir el 4,3% de su sueldo.
• Dado que el promedio es $137.000, su impuesto adicional recauda unos $600 millones.
• La Ciudad tiene ahora dinero para varios proyectos, pero usted pierde su próxima elección por cobrar muchos impuesto.
34

El promedio a veces no basta• Hay casos en los que un promedio, sin importar cómo se
calcula, no basta para tomar una decisión racional:– La temperatura promedio de un lugar al que irá de vacaciones es
de 27 grados; pero, ¿el rango cuál es?
– Si no sabe nadar y le dicen que le profundidad promedio de un río es de 1,50m y su altura es de 1,70m, ¿se arriesgaría a cruzar?
• Una manera de atacar esto es mediante estimaciones de tres (o más) puntos.
• Sin embargo, éstas tampoco sirven en todos los casos.
• En general, se necesita conocer toda la distribución (lo cual a veces se logra conociendo unos pocos parámetros).
35

36
Razonamiento bajo
incertidumbre

Conocimiento incierto vs. incompletoConsideremos las siguientes afirmaciones:
• José de San Martín pronunció 3.000 palabras el día 01/02/1845.
Esto es verdadero o falso, pero nadie lo sabe con certeza.
• El profesor de la materia tiene a lo sumo 40 años de edad.
También es verdadero o falso, pero alguna gente lo sabe con certeza y el resto puede tener datos que informan la creencia.
• Argentina ganará la Copa América 2019.
Afirmación diferente, dado que el evento aun no ha sucedido. De todas formas, hay gente que tiene más información que otra acerca de la probabilidad del evento.
37

Conocimiento incierto vs. incompletoSupongamos que un amigo va a tirar un dado y nos pregunta: “¿saldrá un 3?”
• Generalmente se aceptaría una respuesta como: “la probabilidad de que salga un 3 es de 1/6”.
• Supongamos que ahora nuestro amigo tira el dado, esconde el resultado, lo anota en un papel, y ahora pregunta: “el número que anoté, ¿es un 3?”
• ¿Deberíamos tratar las dos preguntas de manera diferente?
• Adoptamos la concepción del razonamiento probabilístico que no distingue entre conocimiento incierto e incompleto.
38

Conocimiento incierto vs. incompletoEsta distinción puede parecer puramente académica, pero consideremos, por ejemplo, un jurado o juez que intenta determinar si una persona es culpable de un delito.
• El delito ya fue cometido, por lo que el acusado es o bien culpable o inocente.
• Lo que hace que algunas personas rechacen este tipo de razonamiento es que dependiendo de a quién le preguntemos podemos recibir respuestas diferentes:
– Nuestro amigo sabe con certeza el número que salió; si le contó a un tercero que el número es menor que 4, éste dirá 1/3 y no 1/6.
– En el caso del delito, depende del acceso a la evidencia.
39

Ojo con los cálculos probabilísticos (1)El problema del cumpleaños compartido:
Supongamos que en un curso hay 23 alumnos; ¿cuál es la probabilidad de que al menos dos de ellos cumplan años el mismo día y mes?
• Las personas que nunca vieron este problema rara vez contestan bien; la respuesta más común es 23/365 (≈ 1/16).
• La respuesta correcta es 0,51:
1 − 364/365 ∗ 363/365 ∗ ... ∗ 343/365 = 0,51
Importante: Esta respuesta vale sólo si se asume independencia entre pares de nacimientos y distribución uniforme.
40

Ojo con los cálculos probabilísticos (2)El problema de Monty Hall:
En un juego de TV el conductor (Monty) nos ofrece 3 puertas; detrás de una hay un auto y de las otras, cabras.
El participante elige una puerta y, acto seguido, Monty procede a abrir una de las puertas que no contiene el auto y nos pregunta si queremos cambiar la elección inicial.
Suponiendo que nos interesa ganar el auto, ¿conviene cambiar o seguir con la elección inicial?
• Respuesta: probabilísticamente, conviene cambiar.
• Este problema suele causar muchas discusiones…
41

El problema de Monty HallVeamos informalmente por qué conviene cambiar la elección:
Hay tres casos posibles:
1) Elegimos el auto
2) Elegimos la cabra 1
3) Elegimos la cabra 2
Inicialmente, cada uno tiene probabilidad 1/3
En el primer caso, perdemos si cambiamos.
Sin embargo, en los otros dos, ¡ganamos! Esto es porque Monty no puede elegir y debe descartar la cabra no elegida.
42

El problema de Monty Hall
Si nos quedamos:
P(ganar) = 1/3
Si cambiamos:
P(ganar) = 1/3 + 1/3 = 2/3
43
[FN2013]

Ojo con los cálculos probabilísticos (3)La falacia del abogado:
Se ha cometido un crimen y se encuentra evidencia que nos da el tipo de sangre del delincuente; es un tipo poco común, sólo una de cada 1.000 personas lo tiene.
La policía encuentra a un sospechoso con el mismo tipo de sangre, y el fiscal argumenta:
“La probabilidad de que una persona inocente tenga ese tipo de sangre es sólo una en mil. Esta persona tiene ese tipo de sangre, y por lo tanto la probabilidad de que sea inocente es tan sólo una en mil.”
44

La falacia del abogado• Claramente, este razonamiento no es válido.
• Supongamos que en la ciudad hay 10.000 personas que pudieron haber cometido el hecho:
– Una de ellas es la culpable
– De las 9.999 restantes, aproximadamente 10 tienen el mismo tipo de sangre (9.999 ∗ 1/10.000).
– Si nuestro sospechoso fue tomado al azar entre los que tienen el tipo de sangre (es decir, no hay más evidencia que esa), la probabilidad de inocencia es mucho mayor (≈ 0.91).
– Veremos cómo calcularla exactamente más adelante.
45

Gráficamente
46
[FN2013]

La falacia del abogado desde otro punto de vista
• Por otra parte, el acusado podría caer en una falacia similar, afirmando:
“Haciendo bien las cuentas, vemos que la probabilidad de inocencia es muy alta; por lo tanto, la evidencia es inútil y debe ser descartada.”
• Este argumento tampoco es adecuado, dado que no admite que la probabilidad de inocencia cambió de 0,0001 a 0,09 (¡un factor de casi 1.000!).
• Por lo tanto, si bien la evidencia en sí sola no es suficiente, no debe ser descartada.
47

48
Factores causales

Decisiones bajo incertidumbre• Las actividades de planificación en el desarrollo de software
involucran necesariamente un grado de incertidumbre.
• Consideremos un ejemplo real:
Una compañía quiere aplicar un programa de métricas para mejorar sus procesos mediante el aprendizaje basado en el estudio de las actividades llevadas a cabo en el pasado.
Con este fin, la compañía buscó aquellos proyectos que, desde el punto de vista de las métricas, fueron considerados los más exitosos; por ejemplo, que tuvieran muy baja incidencia de defectos reportados por clientes, medida en defectos por KLOC. La idea era identificar los procesos que caracterizaron a dichos proyectos.
49

Decisiones bajo incertidumbreSe identificó un conjunto de “proyectos estrella”, incluyendo algunos que alcanzaron el mítico objetivo de cero defectos por KLOC en los primeros seis meses luego de su lanzamiento. La compañía terminó aprendiendo algo distinto de lo que buscaba, dado que muy pocos de estos proyectos fueron exitosos desde un punto de vista comercial.
La principal explicación para el número excepcionalmente bajo de defectos reportados por clientes fue que los productos eran tan pobres que nunca fueron realmente usados.
• Lo que se puede aprender de este caso es que no se puede confiar a ciegas en las métricas.
• En particular: La ignorancia de factores causales puede ser desastrosa.
50

Factores causales• Escenario: Usted está administrando un proyecto y le
informan que durante una etapa crítica de testing se encontraron muy pocos defectos. ¿Es una buena noticia?
• ¡Depende del proceso de testing utilizado!
• El peligro es asumir que el número de defectos encontrados durante el testing está correlacionado con el número encontrado en operación (la cantidad incierta a predecir).
• Peligro similar: construir modelos de regresión en donde algunas variables (como tamaño y complejidad) actúan como independientes para predecir otras dependientes (como defectos y esfuerzo de mantenimiento).
51

Causalidad• Como vimos antes con los ejemplos absurdos, no se puede
asumir que la correlación implica causalidad.
• Una de las herramientas más populares para atacar a este problema es la del razonamiento Bayesiano:
– Es una manera racional de actualizar las creencias (predicciones, etc.) acerca de un atributo en base a la evidencia observada.
– Cuando se manejan múltiples métricas dependientes entre sí, se utiliza este método junto con modelos causales.
– Uno de los modelos más usados es el de Redes Bayesianas (“BNs”, por sus siglas en inglés).
– Veremos estos modelos en detalle más adelante.
52

Correlación y regresión vs. causalidadTomemos un ejemplo del mundo real:
53
Mes Accidentes fatales Temperatura promedio (F)
Enero 297 17.0
Febrero 280 18.0
Marzo 267 29.0
Abril 350 43.0
Mayo 328 55.0
Junio 386 65.0
Julio 419 70.0
Agosto 410 68.0
Septiembre 331 59.0
Octubre 356 48.0
Noviembre 326 37.0
Diciembre 311 22.0
[FB2014]

Correlación y regresión vs. causalidad• Parece haber una clara relación entre el número de
accidentes y la temperatura: ambos crecen juntos.
• Aplicando técnicas estadísticas estándar, llegaríamos a la conclusión de que la correlación es altamente significativa:
54
[FB2014]

Correlación y regresión vs. causalidad• El peligro es la tentación de concluir que: “a mayores
temperaturas, ocurren más accidentes fatales”.
• Si esto fuera así, podríamos utilizar la ecuación:
N = 2,144 * T + 243,55
para intentar predecir cuántos accidentes ocurrirían si la temperatura promedio fuera de 80°F (serían 415).
• Sin embargo, este modelo no tiene poder de explicación.
• En este caso, hasta sugiere lo contrario de la realidad, ya que sostiene que en invierno (cuando las rutas son más peligrosas por el hielo) ¡ocurren menos accidentes!
55

Correlación y regresión vs. causalidadInvestigando un poco, se puede concluir que:
• La temperatura influye sobre las condiciones de las rutas: empeoran al caer la temperatura).
• La temperatura influye sobre la cantidad de km recorridos: en verano y primavera la gente viaja más.
• Cuando las rutas están en condiciones pobres, los conductores suelen reducir su velocidad: las condiciones de ruta influyensobre la velocidad.
• El número de accidentes no sólo está influenciado por la cantidad de viajes, sino también por la velocidad.
56

Correlación y regresión vs. causalidadEsto se puede graficar de la siguiente manera:
57
[FB2014]

Correlación y regresión vs. causalidad• El mensaje principal es que el modelo ya no es una simple
relación entre dos medidas.
• La información disponible (factores objetivos) se combina con causas estudiadas (factores subjetivos).
• Estos factores interactúan de manera posiblemente compleja para ayudarnos a explicar las observaciones.
• El modelo de regresión no incluía la velocidad promedio porque ésta no figuraba en la base de datos.
• Esto se conoce como “condicionamiento sobre los datos”, y favorece la practicidad a costo de la precisión.
58

Correlación y regresión vs. causalidad• Los modelos causales nos ayudan a buscar más allá de los
datos y encontrar relaciones ricas que se pierden en los modelos estadísticos simplistas.
• Esta es una herramienta valiosa en el control del riesgo y la incertidumbre.
• El modelo simplista de regresión visto no nos da una respuesta a la pregunta principal: ¿qué podemos hacer para influir en la reducción de accidentes?
• Dado que el clima no se puede controlar, el modelo no nos ayuda en nada.
59

Correlación y regresión vs. causalidadUn ejemplo del dominio del desarrollo de software:
La relación entre fallas detectadas pre-lanzamiento y post-lanzamiento (el atributo que queremos predecir):
60
[FB2014]

Correlación y regresión vs. causalidad• Hay correlación negativa: los módulos con mayor cantidad
de fallas pre suelen exhibir menor cantidad de fallas post.
• Una posibilidad para explicar esto es que los módulos con muchas fallas pre fueron testeados exhaustivamente.
• Otra es que el uso operacional influye: un módulo que nunca se ejecuta no exhibirá ninguna falla post.
• La falta de factores causales que expliquen la variación de un atributo suele ocurrir en otros usos de métricas:
Esfuerzo = F(tamaño, calidad del proceso, calidad del producto)
Tiempo = F(tamaño, calidad del proceso, calidad del producto)
61

Correlación y regresión vs. causalidadEstos modelos tienen varias limitaciones:
– Se basan en datos de proyectos pasados, que pueden haber generado productos de baja calidad (más allá de la intención).
– No incorporan relaciones causales: hacen la suposición de que, por ejemplo, el tamaño de la solución influye en la cantidad de recursos necesarios. Es decir, se tiene:Entrada F Salidaen vez de:Salida F Entrada
– Asumen que los proyectos no tienen restricciones particulares; éstas no se contemplan en los modelos simples.
62

Correlación y regresión vs. causalidadEstos modelos tienen varias limitaciones (cont.):
– Los modelos son cajas negras que esconden o ignoran suposiciones cruciales que explican las relaciones y tradeoffsentre las entradas y salidas.
– Suelen no proveer ninguna información acerca de la incertidumbre inevitable asociada con sus predicciones.
• Para poder hacer un manejo efectivo del riesgo y tomar decisiones informadas, debemos poder responder diferentes tipos de preguntas...
63

Correlación y regresión vs. causalidadPara poder hacer un manejo efectivo del riesgo y tomar decisiones informadas, debemos poder responder:
– Para un problema de un tamaño y recursos disponibles dados, ¿qué tan probable es que logre un producto de calidad adecuada?
– ¿Cuánto puedo reducir los recursos si estoy preparado para aceptar un producto con calidad especificada menor?
64

Correlación y regresión vs. causalidadPara poder hacer un manejo efectivo del riesgo y tomar decisiones informadas, debemos poder responder (cont.):
– El modelo predice que necesito 4 personas durante 2 años para construir un sistema de un tamaño dado, pero sólo tengo dinero para 3 personas por un año.Si no puedo sacrificar calidad, ¿qué tan bueno debe ser el equipo para alcanzar el objetivo?
– Alternativamente, si mi equipo tiene habilidad promedio y no puedo cambiarlo, ¿cuánta funcionalidad debo reducir para lograr un producto con la calidad requerida?
65

Análisis probabilístico del riesgo• Como vimos anteriormente, una aproximación común al
análisis del riesgo es medir, para cada uno:
– La probabilidad de que ocurra
– El impacto que tendría si ocurriera
• Esto genera un cuadro llamado “mapa de calor”.
• Por falta de tiempo y por la dificultad de cuantificar, muchas veces este modelo se simplifica asignando valores como “bajo”, “medio” y “alto”.
• Si bien este modelo simple puede ser muy útil, no deben ignorarse las dependencias entre los eventos.
66

Mapas de calor
67
Riesgos mayores
Riesgos menores
Riesgos intermedios
[FN2013]

Análisis causal del riesgoUn riesgo puede ser caracterizado como un evento complejoque involucra por lo menos:
1. El evento en sí
2. Al menos un evento consecuencia que caracteriza al impacto.
3. Uno o más eventos disparadores
4. Uno o más eventos de control para detener el evento consecuencia.
5. Uno o más eventos mitigadores que evitan que suceda el evento consecuencia en mayor medida.
68
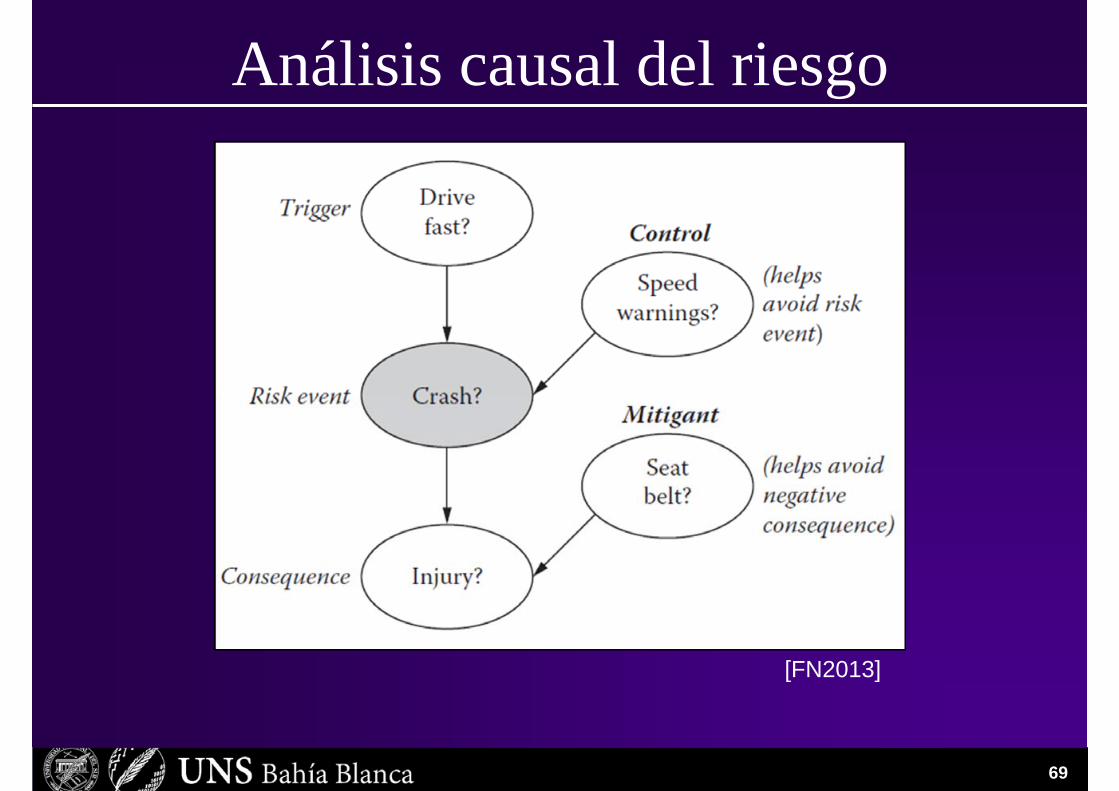
Análisis causal del riesgo
69
[FN2013]

Mismo análisis para oportunidades
70
[FN2013]

Modelo unificado de riesgos y oportunidades
71
[FN2013]

Análisis causal del riesgo• Como vimos en estos ejemplos, los riesgos son mejor
caracterizados a través de conjuntos de eventos.
• Estos eventos no existen en aislación, sino que están relacionados a través de una estructura causal.
• La incertidumbre asociada al riesgo surge de cómo se relaciona cada evento con los demás.
• Una vez que se analizan los eventos en detalle, pueden surgir modelos flexibles que sirven para análisis de diferentes perspectivas.
• Veamos un ejemplo...
72

Perspectiva de las autoridades municipales
73
[FN2013]

Perspectiva de los habitantes
74
[FN2013]

Perspectiva del abogado de la Municipalidad
75
[FN2013]
Estos factores cambiaron de clase con respecto a los modelos anteriores.

Análisis causal del riesgoLos principales beneficios de estos modelos son:
• La medición del riesgo es más significativa:
– La estructura causal cuenta una historia.
– Esto es mucho más informativo que el mapa de calor.
• La incertidumbre puede estar cuantificada; en cualquier momento podemos calcular las probabilidades asociadas con los eventos de interés según las condiciones actuales.
• Es un mecanismo visual y formal para almacenar y verificar probabilidades subjetivas.
76

Referencias• [FB2014] N. Fenton & J. Bieman: “Software Metrics: A Rigorous
and Practical Approach”, 3rd Ed. CRC Press, 2014.
• [FN2013] N. Fenton & M. Neil: “Risk Assessment and Decision Analysis with Bayesian Networks”. CRC Press, 2013.
77