psy 307 – statistics for the behavioral sciences chapter 10-11 – introduction to hypothesis...
Post on 22-Dec-2015
215 views
TRANSCRIPT

PSY 307 – Statistics for the Behavioral Sciences
Chapter 10-11 – Introduction to Hypothesis Testing

Why Hypothesis Tests?
The first step in any study is to test against chance.
We cannot draw any conclusions about our results without making sure our results are not accidental.
We never know for sure what the true situation is, but we try to minimize possibility of error.

Kinds of Hypothesis Testing
Testing against 0 (zero) Testing against chance Testing the null hypothesis versus
an alternative hypothesis Testing two hypotheses that predict
different or incompatible outcomes Modeling Exploratory data analysis

Hypotheses are about Underlying Populations
Underlying Population
Sample
What can we know about the population by measuring the sample?

Guessing about the Population
? ?
Null PopulationAlternative
Population(s)
Sample
Which population is the true underlying population for our sample?
We assume the null population is true, then see how likely the sample would be to occur under those circumstances.
We cannot know for sure.

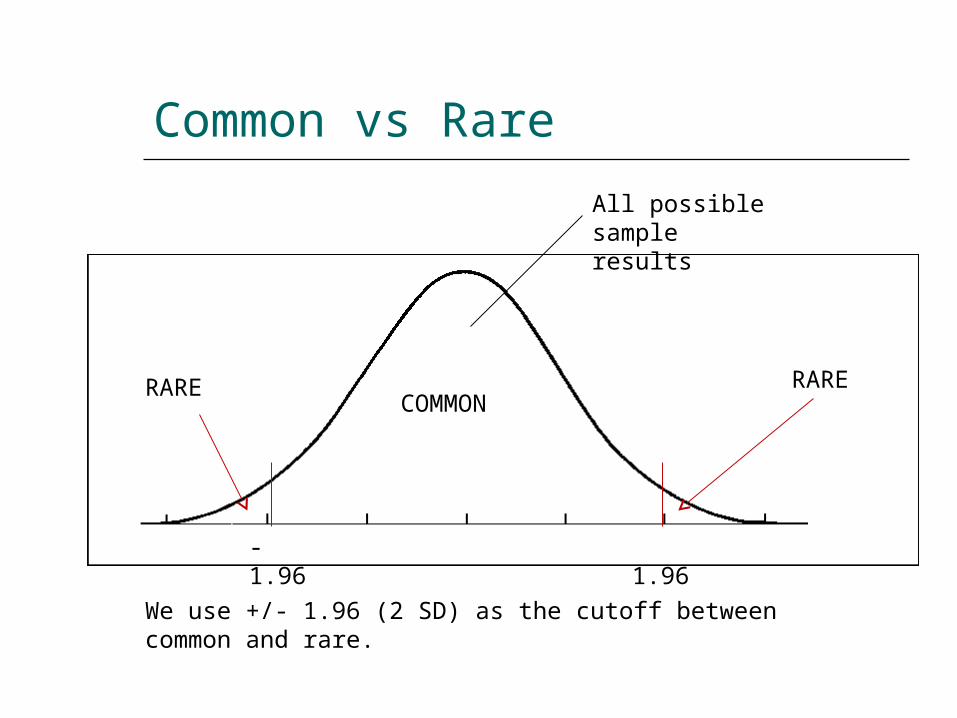
Common vs Rare Outcomes
We always start with the assumption that the null population is true. In that case we ask: How likely would our current result be if
the null population were the true underlying population?
A result in the center of the normal curve is highly likely (common).
A result in the tails of the normal curve is much less likely (rare).
Common vs Rare
-1.96 1.96
RARERARECOMMON
We use +/- 1.96 (2 SD) as the cutoff between common and rare.
All possible sample results

Hypothesis Testing
A hypothesis is a prediction about the results of a study.
Null hypothesis (H0) – a prediction that the null population is the true underlying population.
The null is a hypothetical sampling distribution – what would exist if nothing special were happening. Results are compared against it.

Manipulations
A comparison is being made: A sample against a known population. Two groups are compared with each
other (e.g., males vs females). Two groups are compared after a
manipulation (e.g., treatment vs control.
The expected differences are stated as the alternative hypothesis (H1).

Null Hypothesis
-1.96 1.96
RARERARE
COMMON
Null hypothesis is true (always assumes no difference)
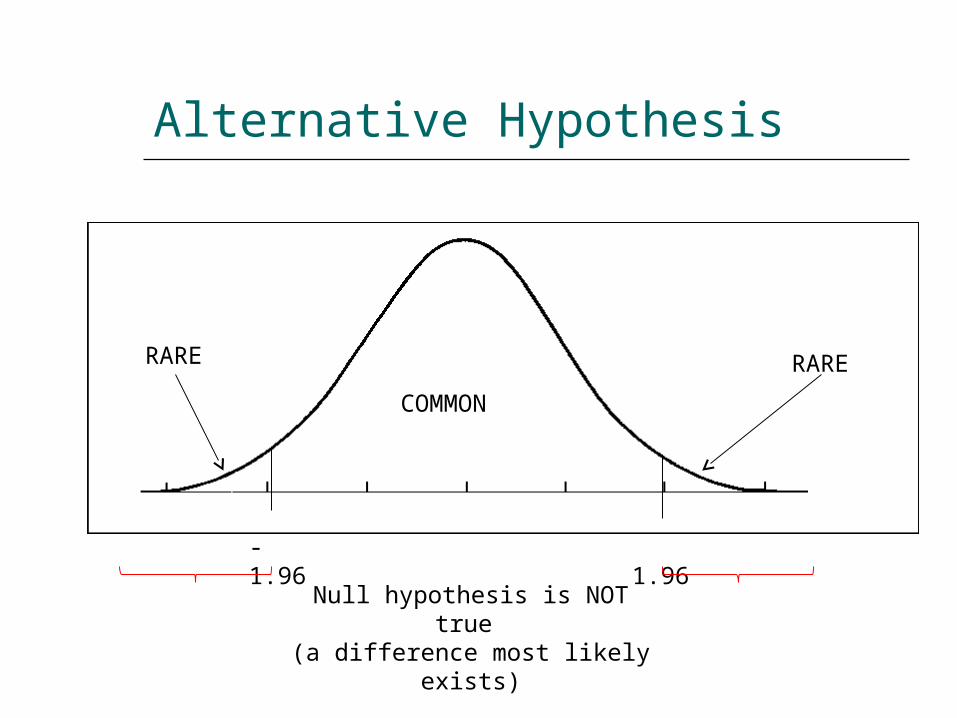
Alternative Hypothesis
-1.96 1.96
RARERARE
COMMON
Null hypothesis is NOT true (a difference most likely exists)

Boundaries for Outcomes
Common outcome – small difference from the hypothesized population mean .
Rare outcome – too large a difference from the hypothesized mean to be probable.
A set of boundaries (critical values) can be found to decide whether an outcome is rare or common.

Different Critical Values can be Used
-1.96 1.96
RARERARE
COMMON
Null hypothesis is NOT true (a difference most likely exists)
p < .05

Critical Values can be Stricter
-2.58 2.58
RARERARE
COMMON
Null hypothesis is NOT true (a difference most likely exists)
p < .01

Or More Lenient
-1.65 1.65
RARERARE
COMMON
Null hypothesis is NOT true (a difference most likely exists)
p < .10

Decision Rule
The decision rule specifies precisely when the null hypothesis can be rejected (assumed to be untrue).
Critical score – the boundary for a rare outcome.
Most studies in psychology use a critical value of p < .05 unless they have a good reason not to.
Level of significance () – rarity.

Decision and Interpretation
Reject the null hypothesis when the observed mean results in a test statistic beyond the critical value. If your level of significance is p<.05
then a z-score above 1.96 or below -1.96 is rare.
With a rare result, conclude that the null hypothesis is untrue (reject it). With a common result, retain it.

One-Tailed & Two-Tailed Tests
Two-tailed tests (non-directional) divide the probability of error () between the two tails. Expressed using equality signs (=, /=).
One-tailed tests (directional) place all of the probability of error in a single tail in the direction of interest. Expressed using inequality signs (<,
>=)

One-tailed vs Two-tailed Tests
A two-tailed test only predicts a difference: H0: = 25, 1 = 2
H1: ≠= 25, 1 ≠ 2
A one-tailed test predicts a difference in a specific direction: H0: ≤ 25, 1 ≤ 2
H1: > 25, 1 > 2

One-Tailed Test (Upper Tail Critical)
1.65
RARE
COMMON
Null hypothesis is NOT true (a difference most likely exists)
p < .05

One-Tailed Test (Lower Tail Critical)
-1.65
RARE
COMMON
Null hypothesis is NOT true (a difference most likely exists)
p < .05

Two-tailed Test
-1.96 1.96
.025.025COMMON
= .05

One-tailed Test
1.65
.05COMMON
= .05

One-tailed Test (other direction)
-1.65
.05 COMMON
= .05

Two-tailed Test
-1.96 1.96
.025.025COMMON
= .05

Hypothesis Test Outcomes
A hypothesis test has four possible outcomes: H0 is true and H0 is retained – a correct
decision. H0 is true but H0 is rejected – a Type I
error (false alarm). H1 is true and H0 is rejected (H1 is
retained) – a correct decision. H1 is true but H1 is rejected and H0 is
retained – a Type II error (miss).

Possible Decisions
Reality – Null is True
Reality –Null is False
We decide that the Null Hypothesis is True
Correctly retain null
Retain null but make aType II error (miss)
We decide that the Null Hypothesis is False
Reject null and make aType I error (false alarm)
Correctly reject null

Strong and Weak Decisions
Retaining the null hypothesis (H0) is a weak decision because it is ambiguous and uninformative. H0 could be true or there may be a
difference but the study couldn’t demonstrate it, due to poor methods.
Rejecting the null hypothesis is a strong decision because it implies that H0 is probably false.

Decisions are Usually Correct
We never actually know what is true, H0 or H1.
Our test procedure produces a result that is usually correct when H0 is either true or seriously false.
Type I error – rejecting a true null hypothesis.
Type II error – retaining a false null hypothesis.

Probabilities of Error
Probability of a Type I error is . Most of the time = .05 A correct decision exists .95 of the time
(1 - .05 = .95). Probability of a Type II error is .
When there is a large effect, is very small.
When there is a small effect, can be large, making a Type II error likely.

Power Curves
Power equals the probability of detecting an effect. Power = 1 – or
(1 – probability of Type II error) Power curves show how power
varies with sample size. They specify what sample size will
show an effect if it is present. A way around arbitrary sample sizes.

Deciding Which to Use
To identify the type of test in an exam question or report: If the null hypothesis is expressed using
inequalities, it is directional. Look for directional words in text.
To choose a test-type in research: Use a non-directional (two-tailed) test
unless you have a strong reason to do otherwise.