putting the mongo in mongodb
TRANSCRIPT

Putting the mongo in MongoDB
Scaling your reads and writes for “web-scale” performance

About me
• Joris Kuipers, @jkuipers
• Manager Technology Delivery at Orange11 Software Pilot at Trifork Amsterdam
• Former SpringSource consultant
• Primary consultant in Trifork’s partnership with 10gen

Agenda
• MongoDB intro
• Replication Sets
• Sharding

Intro

Intro

Why so popular?

Why so popular?

Replication

Replication?
Multi-node setup with primary and two or more replicating secondaries
Primary use case:Automatic failover in case of node failure

Replica Set - Creation

Replica Set - Initialization

Replica Set - Failure
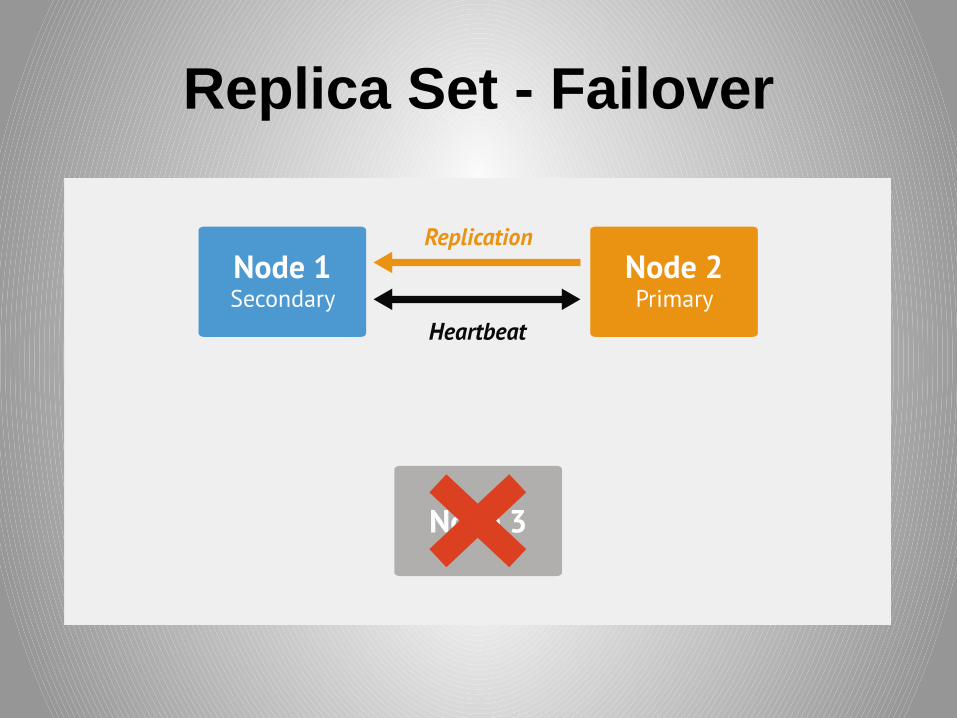
Replica Set - Failover
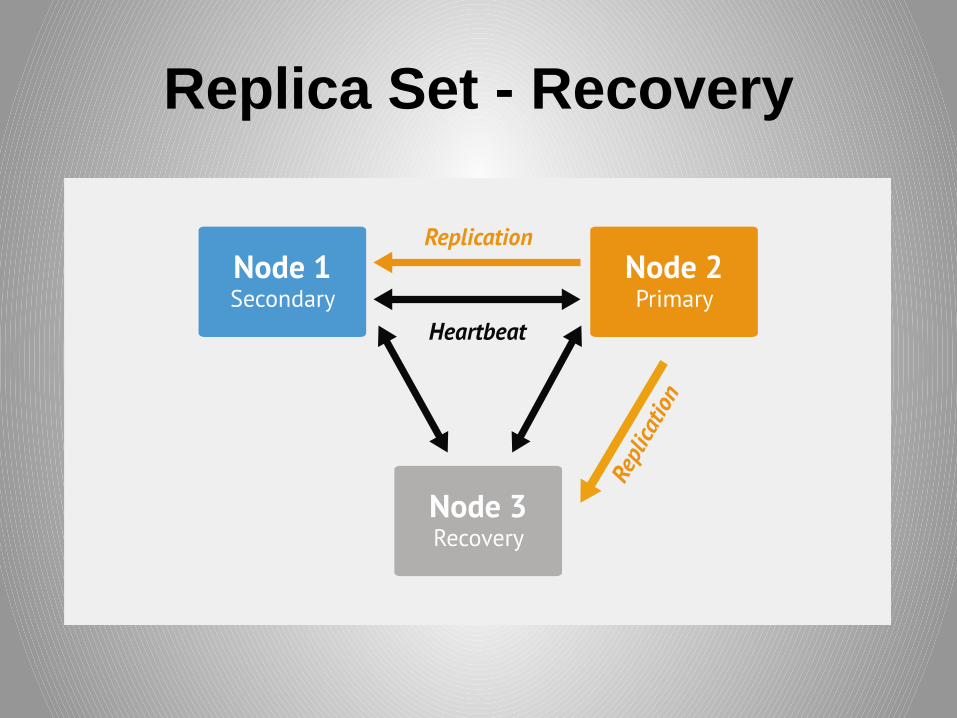
Replica Set - Recovery
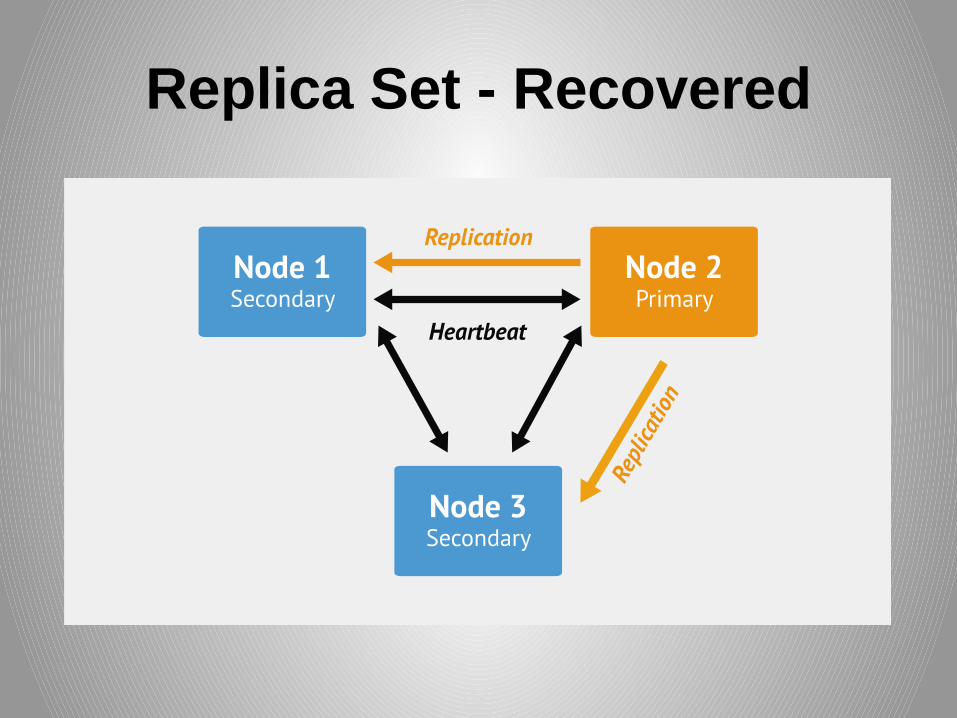
Replica Set - Recovered

I thought this was about scaling?
• Secondaries can be queried
• Eventually consistent reads
• Secondaries can be hidden
• Dedicated node for e.g. analytics

Strong Consistency

Delayed Consistency

Read Preferences Mode
5 modes :
• primary (only) - Default
• primaryPreferred
• secondary
• secondaryPreferred
• nearest
Closest node always used for reads (all modes but primary)

Replica Sets for scaling
• Similar limitations to RDBMSs:
– Loses consistency
– Scales reads only
– No help if working set > RAM of single node
• Real scalability requires distributing data

Sharding
“Shards are the secret ingredient in the web scale sauce. They just work”

When Working Set > RAM

When R/W throughput > I/O

What is sharding?
• Distributing data across nodes in cluster
• Requires some form of partitioning
• Hard to do manually
–What if nodes are not balanced?
–What if you add or remove nodes?
• Automatic and at the core of MongoDB

Partition data based on ranges
• User defines shard key
• Shard key defines range of data
• Key space is like points on a line
• Range is a segment of that line

Data distributed in chunks across nodes
• Initially 1 chunk
• Default max chunk size: 64mb
• Chunks automatically split & migrated when max reached

MongoDB manages data
• Queries routed to specific shards
• MongoDB balances cluster
• MongoDB migrates data to new nodes

MongoDB Auto-Sharding
• Minimal effort required
– Same interface as single mongod
• Two steps
– Enable Sharding for a database
– Shard collection within database
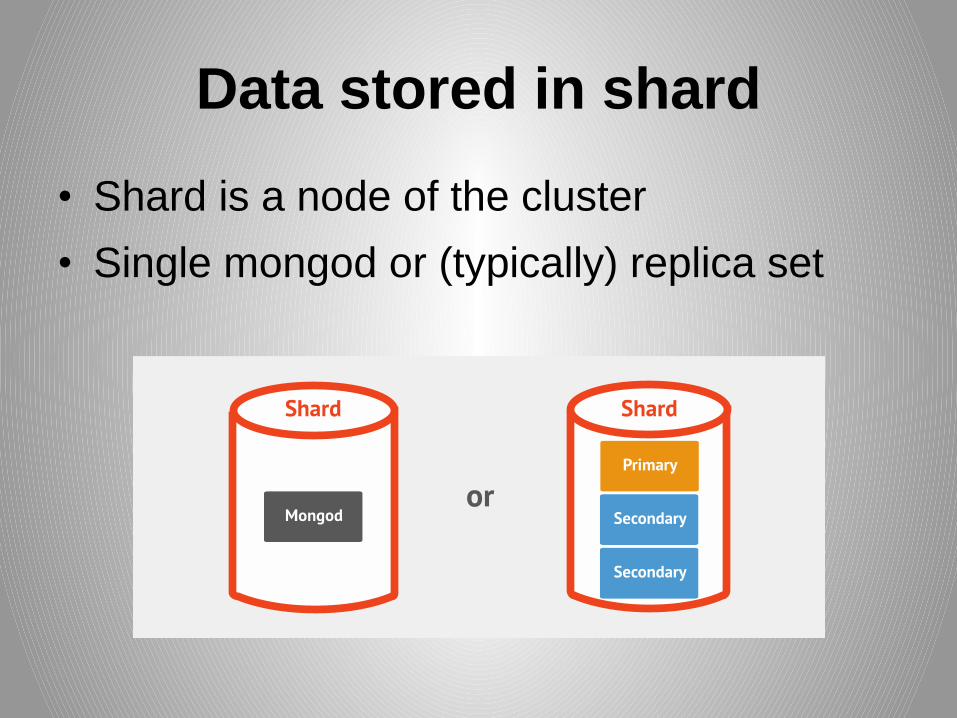
Data stored in shard
• Shard is a node of the cluster
• Single mongod or (typically) replica set

Config server stores meta data
• Stores cluster chunk ranges and locations
• Must have 3 (1 for dev/test only)
• Two phase commit (not a replica set)

MongoS manages data
• Acts as a router / balancer
• No local data
– lightweight process
– persists to config database
• Can have 1 or many
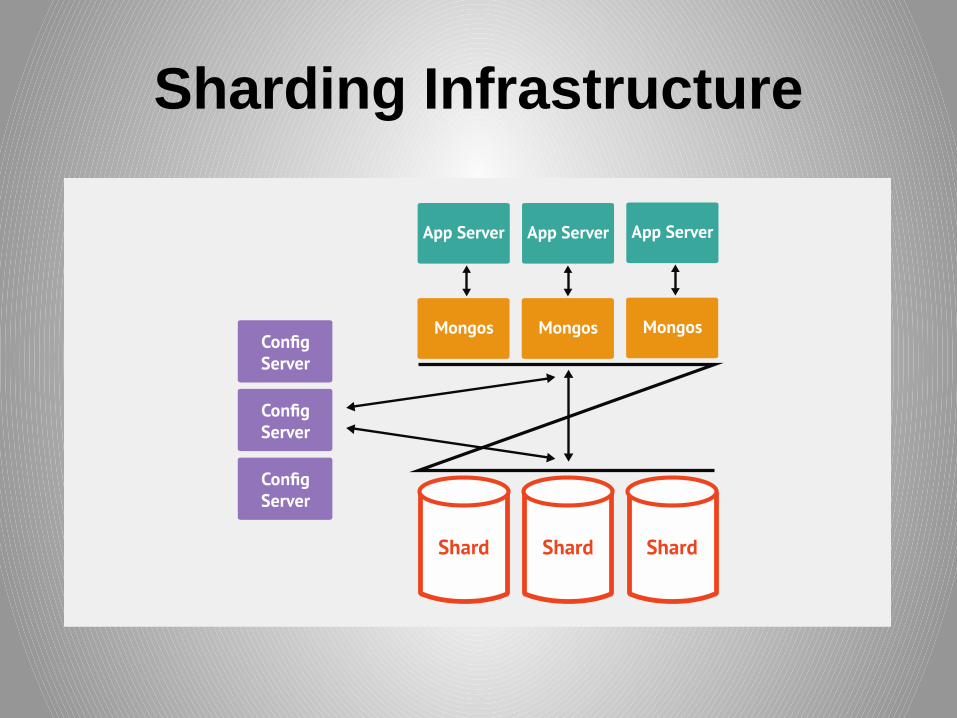
Sharding Infrastructure

Mechanics

Partitioning
• Remember: range-based

Chunk is section of full range

Chunk Splitting
• Chunk split if > maximum size
• No split point if all docs have same shard key
• Chunk split is a logical operation
• Balancing round if chunk count diff > X

Balancing
• Balancer runs on mongos
• Starts when chunk count diff between most dense and least dense shard > migration threshold

Acquiring Balancing Lock
• Mongos balancer takes “balancer lock”
• Status stored in config.locks

Moving The Chunk
• mongos:“moveChunk” cmd to source shard
• Source shard notifies target shard
• Target claims chunk’s shard-key range and starts pulling documents from source
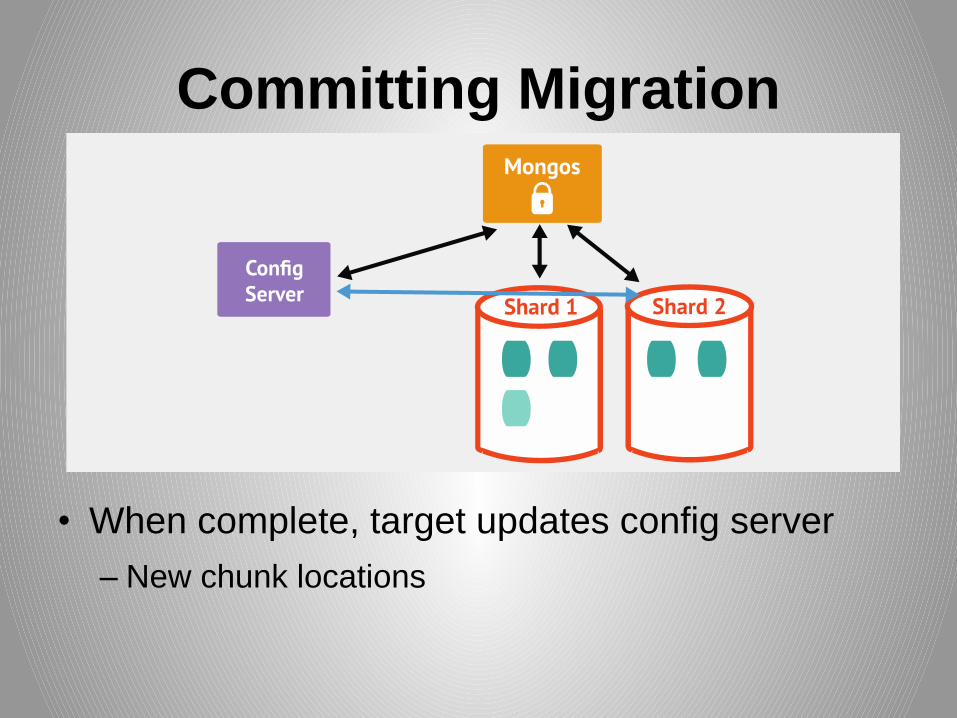
Committing Migration
• When complete, target updates config server
– New chunk locations
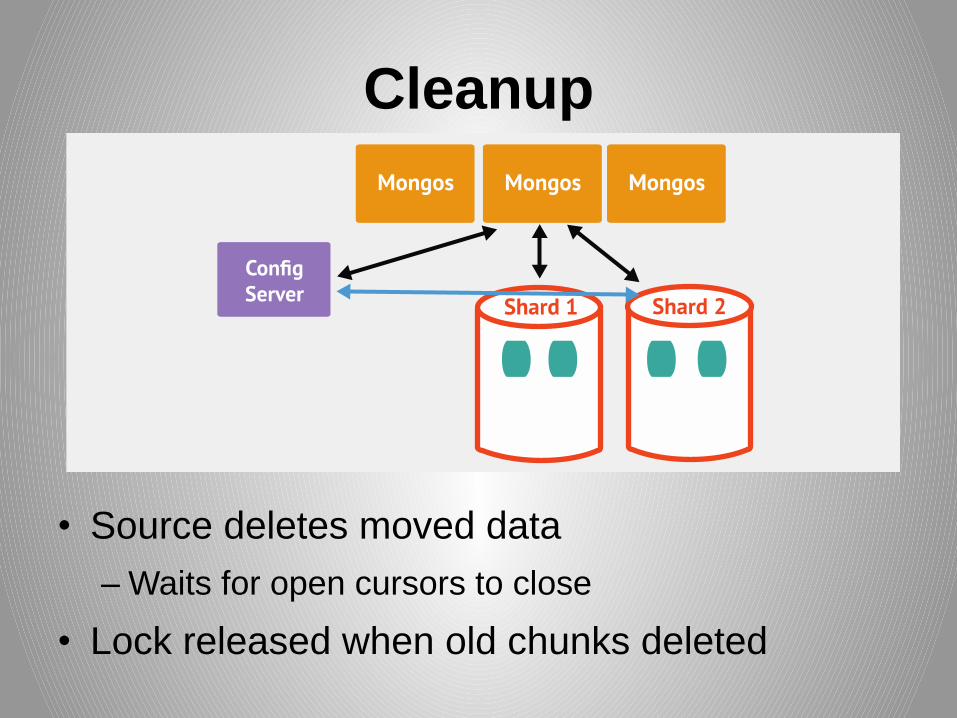
Cleanup
• Source deletes moved data
–Waits for open cursors to close
• Lock released when old chunks deleted

Querying a sharded cluster

Cluster Request Routing
• Targeted Queries
– Include shard key
– Aim for large query % to be targeted!
• Scatter Gatter Queries
– Do not include shard key
• Note: queries include inserts/updates/deletes

Targeted Query Routing
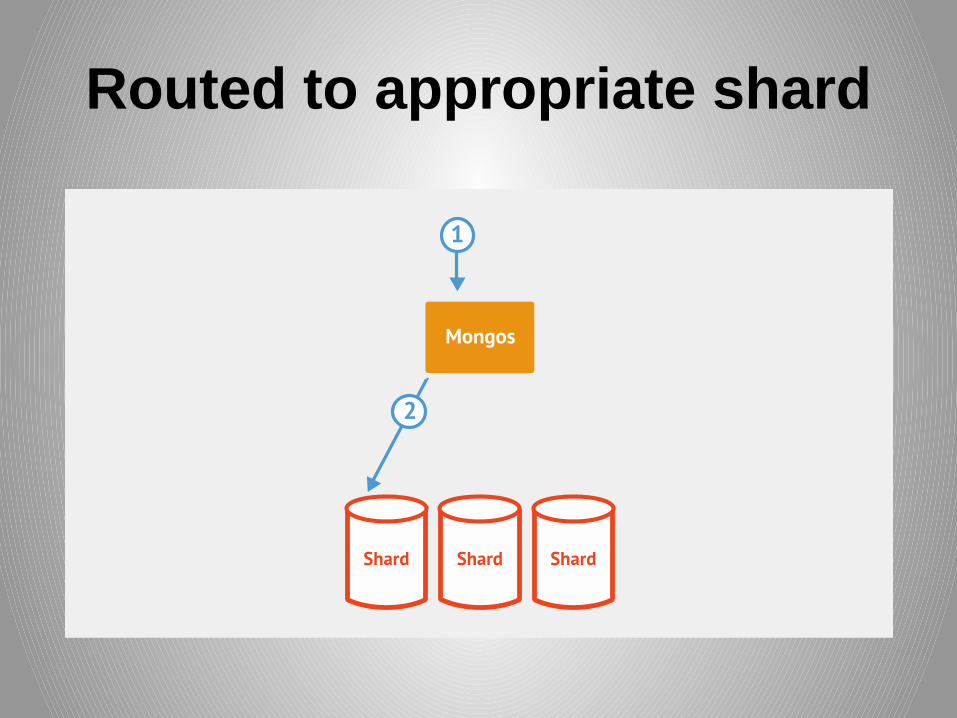
Routed to appropriate shard

Results returned to mongos
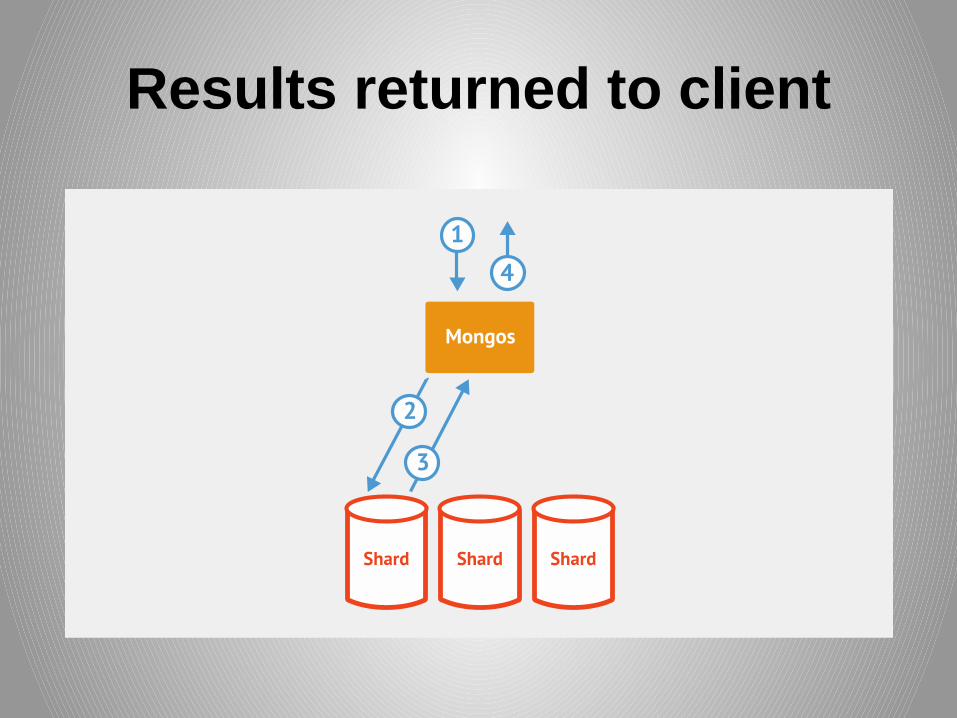
Results returned to client

Non-targeted Query Routing
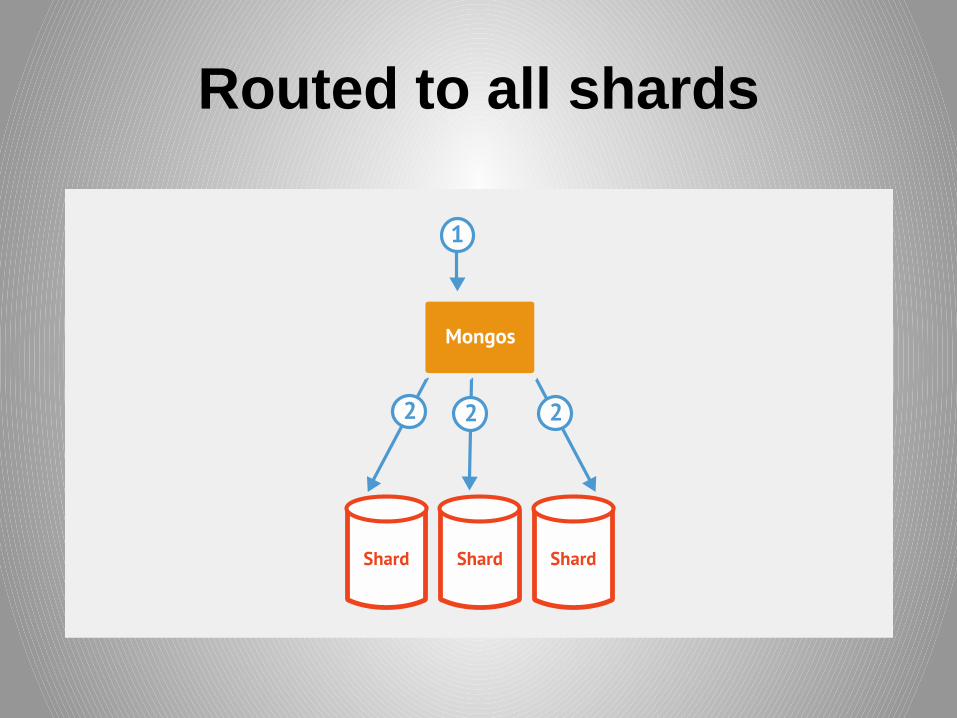
Routed to all shards

Results returned to mongos
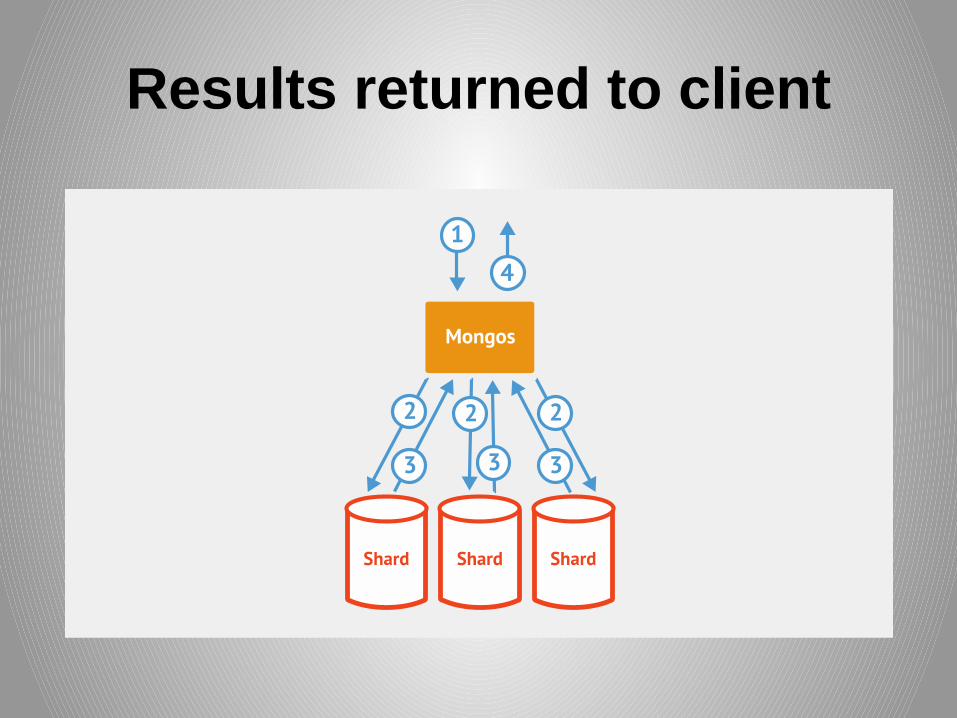
Results returned to client

Shard Key
• Key and value immutable
– Choose wisely
– Key’s field(s) require index
• Considerations:
– Cardinality
–Write distribution
– Query isolation
– Data distribution

Conclusion
• Sharding is key to true scalability with Mongo
• Mechanism is automatic
• Understanding it is essential
– Choice in sharding key
–Writing efficient queries
– Don’t lock yourself in
–Monitor runtime behavior

Questions?