python nltk
TRANSCRIPT

NLTK
Alberts Pumpurs

90% of world's data generated over last two years

commonInternet
user creates
Visual Textual
Flickr
Vscocam
Tumblr
Blogger
Emails
Costumer Reviews

Detecting hidden signals

World is full of unstructured, text-rich data. Everything from emails to customer tweets.
The information buried in all that text holds the potential to deliver
valuable business insights

Text analytics is the practice of using technology to gather, store and mine textual information for hidden signals that can be used to inform smarter business decisions

An explosion of unstructured data

Many types of organizations are experiencing explosive growth in their unstructured enterprise data.
Same time that they have access to external sources of data such as social media, blogs, and mobile data.

Until now, much of this information passed through the organization virtually unanalyzed. Today, new tools for handling large amounts of complex data makes it easier to squeeze value from such unlikely sources.

Text Processing use cases

sentiment analysisspam filteringtext categorizationtopic detectionkeyword frequencyplagiatism detection document similarityphrase extraction

Natural Language Tool Kit
leading platform for building
Python programs to work with human language data

NLTK Features

sentence and word tokenizationtext calsificationcorporaparsingclustringpart of speach taggingtext stemming
and mutch more..

Sentencetokenization

Wordtokenization

Part of speech tagging

Part of speech tagging explanationCC Coordinating conjunctinCD Cardinal NumberDT DeterminerEX Existing “ there“FW Foreign wordIN Preposition or subordination conjuctionJJ AdjectiveJJR Adjective- comparativeJJS Adjective- superlativeLS List item markerMD ModalNN Noun- singular or massNNS Non-PluralNP Proper noun- singular
nltk.help.upenn_tagset() //all tag sets

Chunking and NER

Text clasification Algorithms in NLTK
Naive BayesMaximum EntropyDecision Tree

Text clasification
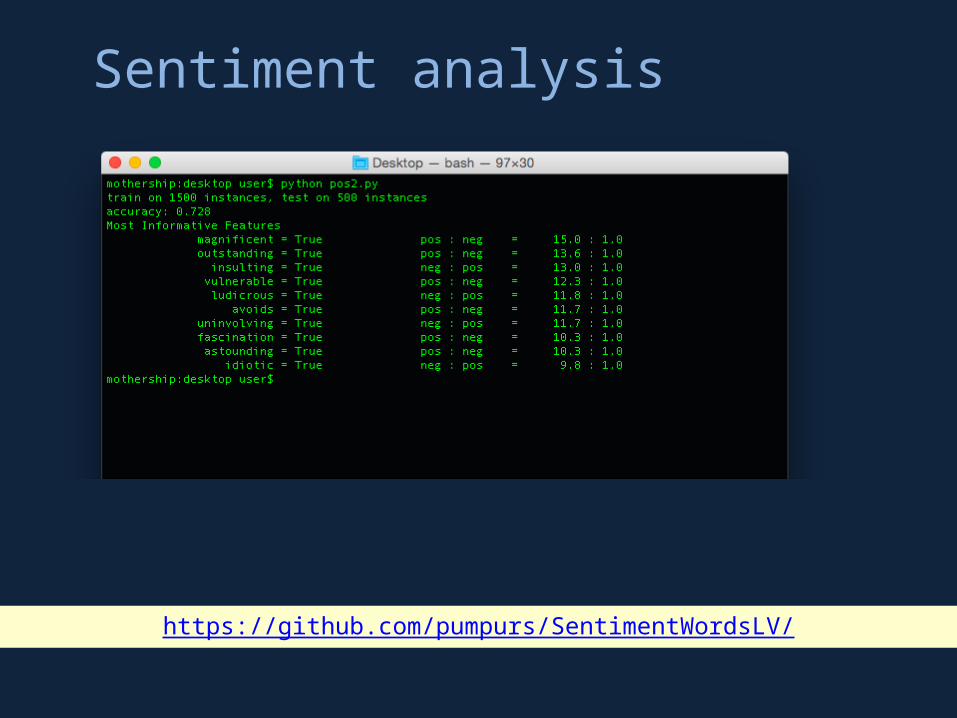
Sentiment analysis
https://github.com/pumpurs/SentimentWordsLV/

Document similarity detection
Tf-idf stands for term frequency-inverse document frequency, and the tf-idf weight is a weight often used in information retrieval and text mining. This weight is a statistical measure used to evaluate how important a word is to a document in a collection or corpus.

Similarity and concordance

Dispersion Plot

But where is the

“Market and product reserch”
“Social CMS” 1.97 b social network users
“Costumer profiling / analytics”70% of marketers used Facebook to
gain6.7 million people blog on blogging
sites
