quadratic programming solver for image deblurring engine rahul rithe, michael price massachusetts...
TRANSCRIPT

Quadratic Programming Solver for Image Deblurring Engine
Rahul Rithe, Michael Price
Massachusetts Institute of Technology

Image Deblurring
Blur Kernel
• For image deblurring, the solution is constrained to be non-negative l = 0, u = +∞
2

Cauchy Point Computation:
First local minima along the gradient projected on to the search space
Algorithm
3
Gradient (Ax – b)

OptimizationsDimension Reduction• Ignore the dimensions that
have active constraints by holding their solution to zero till the next outer iteration
• If all but 100 constraints are active: 100×100 matrix/vector operations instead of 1000×1000
4
Gradient (Ax – b)

OptimizationsIncremental Update• Incrementally update
matrix/vector product in CP• Incrementally update
gradient throughout both CP and CG steps, based on incremental changes to x
• At the end of each CG refinement, recalculate cost using updated gradients
• Avoids explicit computation of Ax product every outer iteration
5
Gradient (Ax – b)

OptimizationsPerformance Improvement• N outer iterations with M1
breakpoints checked for CP and M2 CG iterations per outer iteration
• Direct implementation: N(3+M1+M2) matrix/vector multiplications
• Optimized implementation:1+N(2+M2
) matrix/vector multiplications
6
Gradient (Ax – b)
Optimized implementation typically achieves ~ 50% performance improvement

Architecture
• Control logic determines resource access • Memory controller connects the design to external
DDR2 memory
• A, b, x stored in DRAM• On-chip SRAMs used for
temporary variables• Single-precision floating
point arithmetic• Iterative execution of CP
and CG• Use non-concurrency of
CP and CG to share SRAMs
7

Matrix Multiplier
8
Multiplication in chunks of m:• m elements of A are fetched per clock cycle from DRAM• One element of x, b can be accessed per clock cycle from
SRAM

Matrix Multiplier
Active Columns• Check if any columns in
a group of m columns are active
• Skip over the group if no active columns
Active Rows• Check if any rows in a
group of m rows are active
• Skip over the group if no active rows
9

Matrix Multiplier
10

Sort
• Cauchy Point Computation requires sorting an array of breakpoints
• Sort implemented using merge sort
11

Main Modules• The control logic in both CP and CG modules are FSMs
that sequence the external operators • Each state corresponds to a discrete step of the
algorithm• Each step evaluates as many operations as possible
concurrently
Conjugate Gradient Architecture
12

FPGA ImplementationVitrex-5 LX110T• QP Solver design integrated with DDR2 memory using a
Request/Response interface• Integrated with Sce-Mi to communicate between a
processor and the FPGA• Verified in simulation• Performance after
synthesis: 51.3 MHz
Total LUTs 78743/69120 113%
LUTs as Logic
76975/51200 150%
LUTs as Memory
1768/17920 9%
FF 69485/69120 100%
Resource utilization during placement13

FPGA ImplementationKintex-7 K325T• QP Solver design integrated with DDR3 memory using a
Request/Response interface• Integrated with USB interface to communicate between a
processor and the FPGA• Performance after synthesis: 67.2 MHz
14

FPGA ImplementationKintex-7 K325T• QP Solver design integrated with DDR3 memory using a
Request/Response interface• Integrated with USB interface to communicate between a
processor and the FPGA• Performance after synthesis: 67.2 MHz
Dual Port RAMs 33
Simple Dual Port RAMs 610
Block RAMs 114/148 77%
DSP48s 58/840 6%
Total LUTs 69073 33%
Resource utilization after synthesis
Slice LUTs 64,522/203,800 31%
Slice Registers 55,406/407,600 13%
Occupied Slices 23,206/50,950 45%
DSP48E1s 58/840 6%
RAMB36E1/FIFO36E1s
113/445 25%
Resource utilization after placement
15
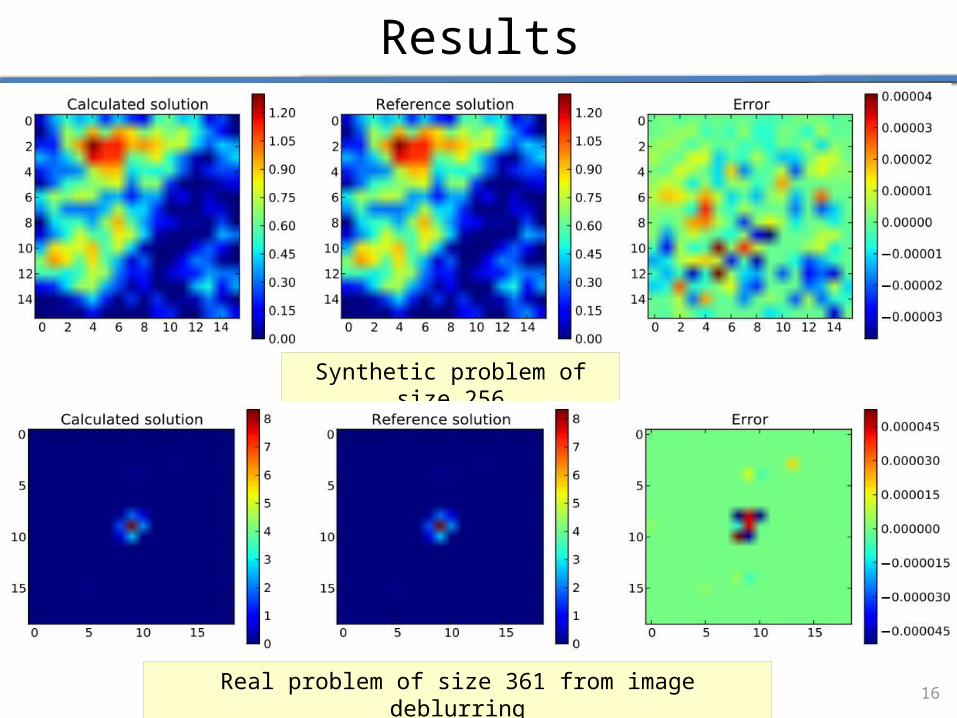
Results
Synthetic problem of size 256
Real problem of size 361 from image deblurring16

Results
FPGA implementation is faster for larger problem sizes
17

Conclusions• QP Solver module designed and implemented on
Kintex-7 FPGA• Optimized the implementation to reduce
matrix/vector multiplications• Maximized concurrent execution of processing steps• FPGA implementation verified to be functional for
problem sizes ranging from 16 to 361
18
Acknowledgements
Priyanka Raina
Richard Uhler, Myron King, Prof. Arvind