randomized control trials (rcts): key considerations and technical components
DESCRIPTION
Randomized Control Trials (RCTs): Key Considerations and Technical Components. Making Cents 2012 -Washington DC. Outline. What makes an RCT Common Questions and Concerns Key Considerations Technical Components Evaluation Example. What makes an RCT. - PowerPoint PPT PresentationTRANSCRIPT

RANDOMIZED CONTROL TRIALS
(RCTS):KEY CONSIDERATIONS AND TECHNICAL COMPONENTS
Making Cents 2012 -Washington DC

Outline
What makes an RCT Common Questions and Concerns Key Considerations Technical Components Evaluation Example

What makes an RCT
Impact evaluation is one type of program evaluation
Randomized Control Trial is one type of impact evaluation

What makes an RCT
Goal: to document the impact of a program or intervention Did the program change lives? What would
have happened if the program hadn’t existed?Compare:
what happened and what would have happened without the
program aka the counterfactual

What makes an RCT
Defining feature: random assignment of units individual beneficiaries, schools, health
clinics, etc to treatment and control groups
allows us to assess the causal effects of an intervention

Questions and Concerns
ExpensiveSample sizeProgram started EthicsTechnical capacity

Key Considerations What types of
questions? Specific – targeted, focused:
test a certain hypothesis Testable - has outcomes that
can be measured Important - will lead to
lessons that will affect the way we plan or implement programs
Micro – macro, expansive questions not appropriate

Key Considerations
Right project to evaluate? Important, specific and
testable question Timing--not too early and
not too late Program is representative
not gold plated Time, expertise, and
money to do it right Results can be used to
inform programming and policy

Key Considerations
Right project to evaluate? Plan and randomize
before the program starts
Randomly assign who gets the program
Evaluation design should occur with project design
Need sampling frame on intended subjects
Randomize after the baseline survey

Key ConsiderationsNot the right project?
Premature and still requires considerable “tinkering” to work well
Too small of a scale to compare into two “representative groups”
Unethical or politically unfeasible to deny a program while conducting evaluation, ie if a positive impact proven
Program has already begun and not expanding elsewhere
Impact evaluation too time-consuming or costly and therefore not cost-effective

Key Considerations
Impact
Counterfactual
Intervention starts
Prim
ary
Out
com
e
TimingHave to do randomization before program starts

Technical Components: Sample
Sample size and unit of randomizationSample size determined by effect sizeWhat effect size if feasible?
Small program impact .1 standard deviation change
Moderate program impact .2 greater standard deviation change
Large program impact .3 or greater standard deviation change

Technical Components: Effect sizes
Define effect size that is “worthwhile” What is the smallest effect that should justify
the program being adopted? If the effect is smaller than that, it might as
well be zero: we are not interested in proving that a very small effect is different from zero
In contrast, if any effect larger than that would justify adopting this program: we want to be able to distinguish it from zero
Statistical significance vs policy significance

Technical Components: Effect sizes
Program manager: “We think our program will increase average income by 20%”
Researcher: “OK. That’s equivalent to an effect size of… (frantically calculates)… 0.4 standard deviations… which means you need a sample size of… 2200 beneficiaries.”
(Time and money is spent on data collection, monitoring intervention, etc etc. One year passes.)
Researcher: “Well, we did not find a 20% increase in income. Maybe you should scrap the program.”
Program manager: “WAIT!! The program is still worthwhile if it only increases income by 10%!!”
Researcher: “Ooops. We don’t have the power to detect that. We would have needed a sample size of 6000..”
Punchline: Define effect size that is “worthwhile”… NOT what you think will happen

An effect size of…
Is considered…
…and it means that…
0.2 Modest The average member of the treatment group had a better outcome than the 58th percentile of the control group
0.5 Large The average member of the treatment group had a better outcome than the 69th percentile of the control group
0.8 Whoa…that’s a big effect size!
The average member of the treatment group had a better outcome than the 79th percentile of the control group
Technical Components: Effect sizes

Technical Components: Sample
Individual level If expecting .2 effect size
one intervention as compared to control
.8 power – 770 people .9 power – 1040 people
two interventions as compared to control
.8 power – 1150 people
If expecting .1 effect size one intervention as compared
to control .8 power – 3150

Technical Components: Sample
Cluster level If expecting .2 effect size -
one intervention With Clusters of 10 people .8
power – 115 clusters With Clusters of 20 people .8
power – 80 clusters lf expecting .2 effect size -
two interventions With Clusters of 30 ppl .8
power – 65 clusters Clusters of 50 ppl .8 power –
56 clusters

Technical Components: Randomization
Clients/beneficiaries are randomly assigned to receive the program or different program models
Everyone has an equal chance of being assigned to all groups
The only difference between the two groups is whether they are assign to receive the new service
Potential Beneficiaries
Randomization
Treatment (receive program)
Control (no or delayed program)

How do we normally select participants
HQHQ
Closest to the main roads? Biggest advocate for program services? Greatest need? Not served by other organizations?

Random assignment
Pre-program
Randomization allows us to be sure we have a reliable and similar comparison group.
When everyone had an equal chance of getting the program and randomization worked – we have our counterfactual. We know what would have happened without the program. We know outcomes in blue villages are similar to outcomes in red villages.

But how can we be sure they are similar
Income per person, per day in leones, before the program
5000
0
0
Treat Compare
10,05710,057

What non random assignment might look like
HQHQIncome per person, per day, leones
5000
0Treat Compare
8990
12470
Blue villages don’t make a good counterfactual. These villages are different. They are better off.

Pre-program income – randomized
Income per person, per day in leones, before the program
5000
0
0
Treat Compare
10,05710,057
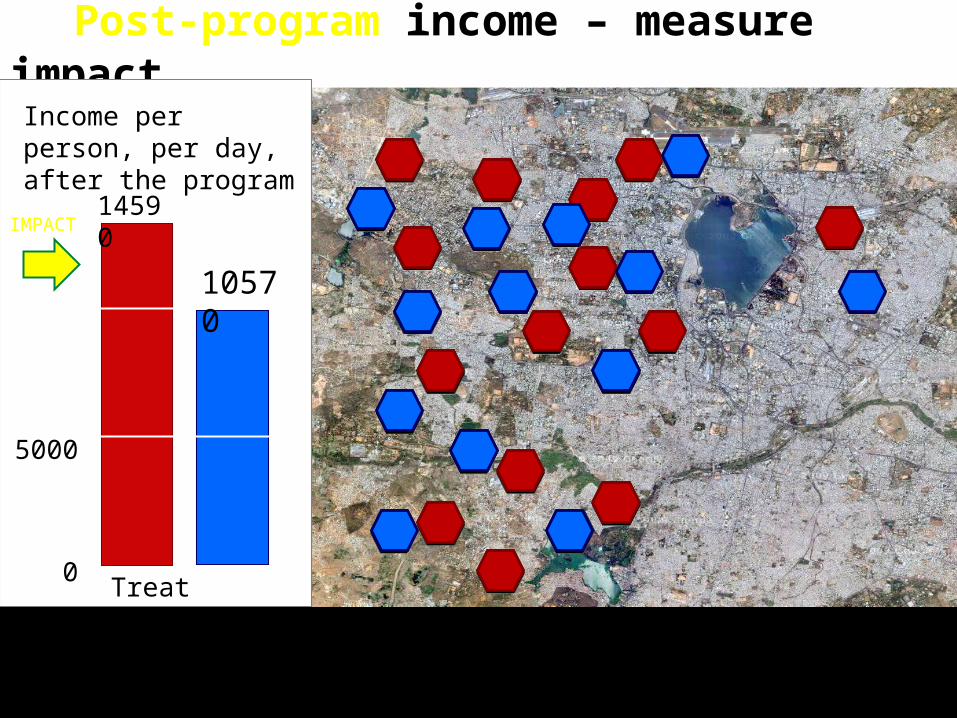
Post-program income – measure impact
Income per person, per day, after the program
5000
0 Treat Compare
10570
14590
Post-program and impact
IMPACT

Technical Components: Randomization
Impact
Counterfactual
Intervention
Prim
ary
Out
com
e
TimeRandomization is unique – it gives us this reliable counterfactual

Random Sampling vs. Random Assignment
Random Sampling: each individual has the same probability of being included in the sample • Only survey/interview some households
out of a community• May select representative sample of
villages out of district• Can select random sample and conduct
needs assessment
Random Assignment: each individual is as likely as any other to be assigned to the treatment or control group – gives us comparison group to measure impact

Randomly samplefrom area of interest (select some eligible participants/ villages)
Randomly assignto treatmentand control out of sample
Random sampling and random assignment
Randomly samplefor surveys (from both treatment and control)

Mechanics of randomized assignment
Need pre-existing list of all potential beneficiaries
Many methods of randomization Public lottery
Selection from hat/bucket In office private
Random number generator Computer program code
Staggered/phase-in Rotation
Pulling names/communities out of a hat to select program beneficiaries is random assignment

Is random fair?

Treatment 1
Treatment 2
Treatment 3
Multiple treatments: comparing programs

Phase-in design: slow program roll out
Round 1Treatment: 1/3Control: 2/3
Round 2Treatment: 2/3Control: 1/3
11
11
11
11
11
11
11
1111
11
11
22
22
2222
22
22
2222
22
22
2222
22
22
333333
33
3333
3333
33
3333
33
33
33 33
Randomized evaluation ends

Technical Components: Ethics Program proven to work Sufficient resources Doing harm Clear expectations Transparent process

Technical Components: Budget
Impact evaluations require a significant budget line $30,000 - $400,000
The budget is influenced by Sample size Numbers of waves of data collection Logistical costs in-country Methods of data collection
PDAs vs. paper-based tools Length of tool Qualitative vs. quantitative
Staffing

Overall Goal: Evidence Based Policy
Cost-BenefitCost-BenefitAnalysisAnalysis
Process Process EvaluationEvaluation
ImpactImpactEvaluationEvaluation
Needs Needs AssessmentAssessment
Opportunity costs of money
Quantification of costs
Benefits
Cost Benefit Analysis

35
Overall Goal: Evidence Based Policy

Example: Cash transfers for vocational trainingThe Northern Uganda Social Action Fund (NUSAF)

NUSAF “Youth Opportunity Program”
Cash grants of about $7000 per group ($377/person)
Intended for acquiring vocational skills and tools
Goals:1. Raise incomes and employment 2. Increase community cohesion and reduce
conflict3. Build capacity of local institutions
Experiment: Groups randomly assigned to receive the grant

Average age: 25Average education: 8th gradeAverage cash earnings: $0.48/day PPPAverage employment: 10 hours/weekFemale: 33%

535 groups, with 18,000 youth
265 treatment groups receive
grant
Program allocated by lottery among eligible applicants
270 groups assigned to a
control group

Timeline of events2006 Tens of thousands apply, hundreds of groups
funded2007 Funds remain for 265 groups in 10 districtsGovernment selects, screens and approves 535 groups2/2008 Baseline survey with 5 people per group
Randomization at group level7-9/2008 Government transfers funds to
treatment groups10/2010 Mid-term survey commences roughly 2 years
after transferEffective attrition rate of 8%
2/2012 Next survey planned

The Results
•Economic Outcomes: Improved Employment, Incomes and High Returns on Investment
•Social Cohesion, Reconciliation and Conflict: Improvements for Men, Mixed Results for Women
•Governance and Corruption: No Evidence of Widespread Leakage
