recognizing and tracking human action josephine sullivan and stefan carlsson
Post on 21-Dec-2015
215 views
TRANSCRIPT

Recognizing and Tracking Human Action
Josephine Sullivan and Stefan Carlsson

Define Tracking

Traditional tracking
• Kalman Filters• Condensation• HMM• Matching articulated 3d models• Similarities?• Problems?

New approach
• What is the difference between tracking and recognition?
• Assume Pose recognition and activity recognition are equivalent.
• Now track activity by repeating recognition of key frames

Discussion: reasons for previous approach
• Why the distinction between tracking and recognition?
• Applications?– Projectile tracking– Motion capture

Object descriptors
• Embedding global data in local descriptors
• Order Structure• Shape context
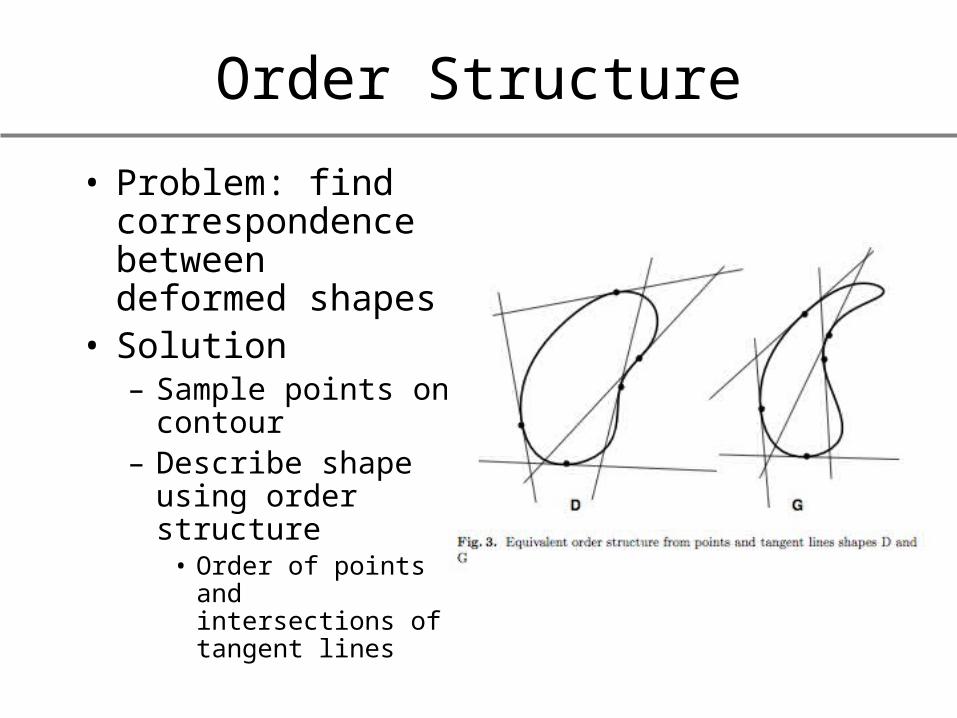
Order Structure
• Problem: find correspondence between deformed shapes
• Solution– Sample points on
contour– Describe shape
using order structure
• Order of points and intersections of tangent lines

Order Structure
• Many transformations preserve order structure– Superset of Affine and Projective
transformations– Encodes perceptual similarity
• Encodes properties of point sets, lines, and combinations of points and lines.
• Descriptor for Point sets - orientation• Set {a,b,c} has + orientation if traversing
them in order means anti-clockwise rotation

Order Structure
• Descriptor for Sets of lines– Uses: points and lines are projectively
dual– p - homogeneous coord’s for a point– q - oriented homogeneous line coord’s
for line thru p, then: qTp = 0– q = (a,1,b) where ax+y+b = 0.– Order type for a set of 3 lines is then

Order Structure
• Descriptor for combinations of points and lines– Oriented coordinates => every line has a
direction• Assign a left-right position for every point w.r.t every
line
• Unique order structure for arbitrary set of points
• Order structure for a set characterized by an index
qi = linepj = point

Order Structure
• Algorithm• Voting matrix
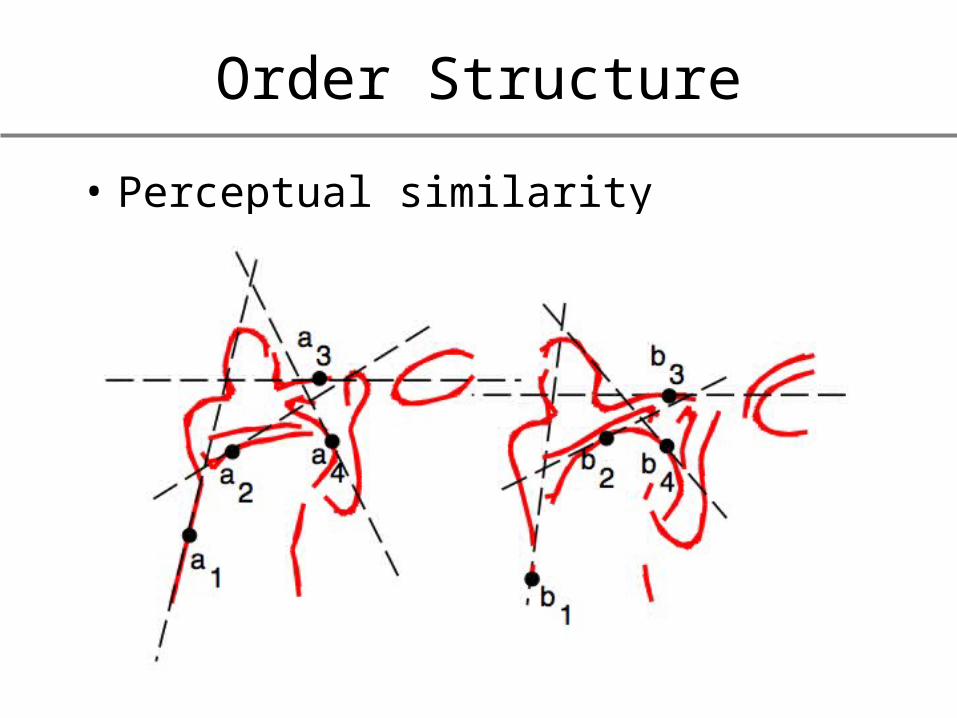
Order Structure
• Perceptual similarity example: human pose

Shape Context descriptor
• Sample points from edges in image• Each point’s descriptor is a
histogram of the relative coordinates of all other points.

Action Recognition using Key Frames
• Deciding images are related– pa
i and pbi are coordinates of
corresponding points in images A and B.
– T is class of transformations that define relation between A and B. (known a priori)
– Matching Distance• General case
• Using pure translation

Action recognition using Key Frames
• 30 second tennis sequence• “Coarse” automatic tracking• Edge detection done on upper half of
player– No deletion of background edges
• Selected a key frame and computed matching score wrt. each other frame.
• 9 local minima shown, each the start of a forehand stroke.

Action recognition using Key Frames

Tracking
• Point transferral– Each key frame is marked
manually– For each point in key frame, a
subset of points in the image are chosen, and a translation is estimated.
Point in keyframe R
Simple local translation
Point corresponding to Pk
R in image It

Updating the Voting Matrix
• Extra information to improve accuracy• Use “standard tracker” for head and
body localization. (Brand, “Shadow Puppetry”)
• Set V(piR, pj
t) = 0 if the points aren’t close to the corresponding lines in corresponding matched head/body quadrangles.

Further constraints
• Want to enforce similar arrangement of interior points in images that are matched to key frames
• Also incorporate intensity around points
• Monte-Carlo smoothing is used to correct outlying points

Tracking using Shape Context
• Mori & Malik• Very similar technique, using
shape context descriptor• Very clear that frames are
processed independently• Tested on standard data

Tracking w/Shape Context Movie
QuickTime™ and aVideo decompressor
are needed to see this picture.

Discussion & Questions
• Results - how effective?• Effect of rate of motion?• Efficiency of “closed loop system”?• No need for background subtraction?• Flexibility to multiple actions?• Do they give a specific order to key
frames?• Is the coarse tracking too simple?• What about poses facing away from
camera?