recommendation systems, ms web dataset use case
TRANSCRIPT

Recommendation Systems(MS Web dataset use case: https://archive.ics.uci.edu/ml/datasets/Anonymous+Microsoft+Web+Data)
Amir Krifa - Software Engineer @ Alcméon

Road Map- Dataset && Goals- Recommendation systems
- Discussing options- Evaluation methodology + some results
- Clustering- Discussing options- Evaluation methodology + some results
- Conclusion && related work
2

Road Map- Dataset && Goals- Recommendation systems
- Discussing options- Evaluation methodology + some results
- Clustering- Discussing options- Evaluation methodology + some results
- Conclusion && related work
3

- MS Web dataset: describes the use of www.microsoft.com by 38000 anonymous users through one week.
- For each user, - all the areas of the web site that user visited in a one week
timeframe (in February, 1998).- Number of Instances
- Number of areas: 294- Training:
- Number of users: 32711- Testing:
- Number of users: 5000
Dataset description
4

5
- Average nbr of visits/area: 346- Average nbr of visited areas/user: 3
Dataset description

Goals (1 - Recommendation system)- Areas to visit recommendation system:
- Input: - The visit history for N users over M areas,- a specific user u with visit history set V(u)
- Output: - recommend k areas to the user u that he might be
interested in visiting.
6

Goals (2 - Users/Areas clustering)- Users/Areas clustering
- Input:- Visit history for N users over M areas (training data)
- Output:- Define a distance among the Users/Areas- Unsupervised clustering algorithms to discover clusters out
of the training data set
7

Road Map- Data && Goals- Recommendation systems
- Discussing options- Evaluation methodology + some results
- Clustering- Discussing options- Evaluation methodology + some results
- Conclusion && related work
8
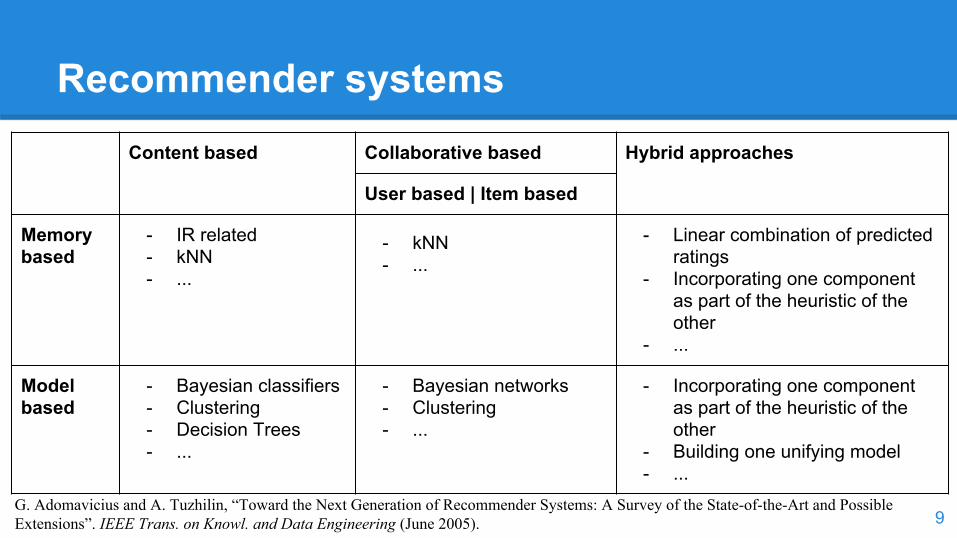
Recommender systems
9
Content based Collaborative based Hybrid approaches
User based | Item based
Memory based
- IR related- kNN - ...
- kNN- ...
- Linear combination of predicted ratings
- Incorporating one component as part of the heuristic of the other
- ...
Model based
- Bayesian classifiers- Clustering - Decision Trees- ...
- Bayesian networks- Clustering- ...
- Incorporating one component as part of the heuristic of the other
- Building one unifying model- ...
G. Adomavicius and A. Tuzhilin, “Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions”. IEEE Trans. on Knowl. and Data Engineering (June 2005).

Content based recommender ?
- Approach:- Create a set of discriminative features to describe user profile
starting from the items the user liked,- Comparing the user profile with candidate items expressed in the
same set of features,- The top-k best matched or most similar items are recommended to
the user- Remarks:
- MS dataset: no way to retrieve more details about the areas visited by a given user nor a given user details!
10

Collaborative User based recommender ?
- Approach:- Use kNN (user -> areas vector (1 if visited by user else 0))
- Similarity between users -> U: set of top similar users - Recommendation phase
- Remarks:- Lack of scalability- Users database changes very fast, high churn
11

Collaborative Item based recommender ?
- Approach:- Use kNN (area -> users vector (1 if visited by user else 0))
- Similarity between areas -> A: set of top similar areas - Recommendation phase
- Remarks:- Small nbr of areas, scale independently of nbr of users- Areas does not change so often, minimal churn
12

Collaborative model based recommender ?
- Approach:- Use users visited areas data to learn a model- Use the model to make rating predictions - Model building (# machine learning techniques):
- Bayesian network (formulates a probabilistic model)- Clustering (treats the problem as a classification one), ...
- Remarks:- Fast and scalable- Real-time recommendations on the basis of very large datasets
13J. Breese, D. Heckerman., C. Kadie, “Empirical Analysis of Predictive Algorithms for Collaborative Filtering”, Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, Madison, WI, July, 1998.

Commonly used similarity/distance measures
- Pearson correlation- Cosine similarity- Jaccard index- ...- Perf-improvement modifications:
- Default voting (useful when users visit small number of areas)- TF*IDF (decrease the weight of the user that visited all the areas)- Case amplification
14

Choi, Seung-Seok, Sung-Hyuk Cha, and Charles C. Tappert. "A survey of binary similarity and distance measures." Journal of Systemics, Cybernetics and Informatics,2010.

Road Map- Dataset && Goals- Recommendation systems
- Discussing options- Evaluation methodology + some results
- Clustering- Discussing options- Evaluation methodology + some results
- Conclusion && related work
15

Evaluation methodology- Recommendations are presented to the user on an
Item-by-item basis- Used methodology:
- For each user in the test data- Split (User visited areas A) -> Already observed A1+ to predict A2- Use A1 to predict A2- Calculate the average absolute deviation for the user
- Average over all the users- Protocolos: Allbut1, Given2, Given5, ...
16
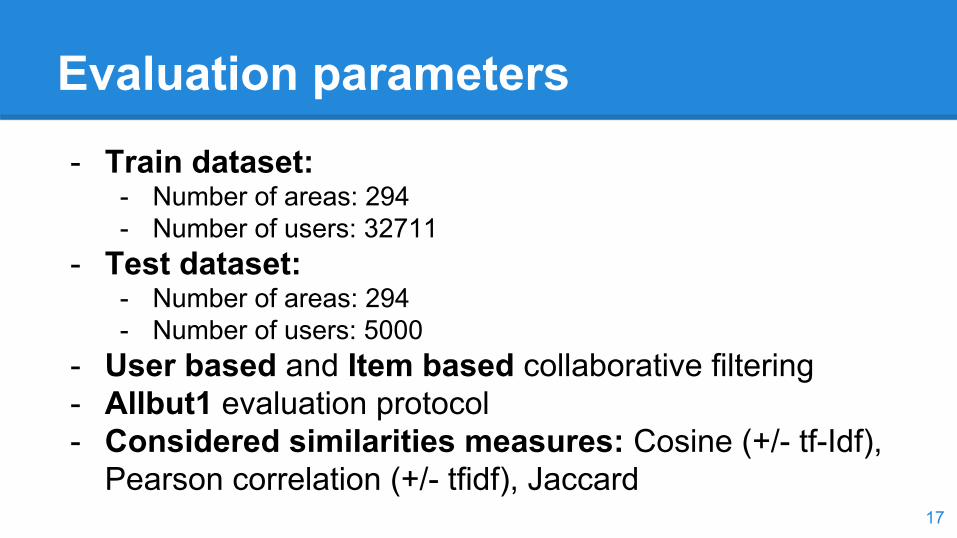
Evaluation parameters- Train dataset:
- Number of areas: 294- Number of users: 32711
- Test dataset: - Number of areas: 294- Number of users: 5000
- User based and Item based collaborative filtering- Allbut1 evaluation protocol- Considered similarities measures: Cosine (+/- tf-Idf),
Pearson correlation (+/- tfidf), Jaccard17

Item based - results
18
Nbr of correct predictions % of correct predictions
Cosine similarity 965 27,95
Pearson correlation 601 17,41
Cosine + tf-idf weighting 1011 29,28
Pearson + tf-idf weighting 520 15,06
Jaccard Index 1211 35,08
Python src code used for the evaluation: https://github.com/amirkrifa/ms-web-dataset
Allbut1 performance = f (similarity)

User based - results
19Python src code used for the evaluation: https://github.com/amirkrifa/ms-web-dataset
Top 10 neighbors
Top 100 neighbors
Top 1000 neighbors
All neighbors
Cosine similarity 14.42 % 23.40 % 35.80 % 30.01 %
Pearson correlation 12.39 % 18.80 % 35.39 % 30.01 %
Jaccard index 14.54 % 23.11 % 35.22 % 31.54 %
Allbut1 performance = f (similarity, nbr of top neighbors)

Road Map- Data && Goals- Recommendation systems
- Discussing options- Evaluation methodology + some results
- Clustering- Discussing options- Evaluation methodology + some results
- Conclusion && related work
20

Clustering- Context:
- Binary sparse data- Nbr of target clusters ? (depends on the target
application, subjective choice, silhouette)- Considered options:
- k-medoids- Agglomerative hierarchical clustering - EM
21

Road Map- Dataset && Goals- Recommendation systems
- Discussing options- Evaluation methodology + some results
- Clustering- Discussing options- Evaluation methodology + some results
- Conclusion && related work
22

Evaluation methodology
23
- Silhouette:- For any data point i
- a(i) average dissimilarity of i with all the other data within the same cluster cluster -> how well i is within its cluster
- b(i) the min average dissimilarity with all the other clusters- The silhouette of i -> s(i) = (b(i) - a(i))/max(a(i), b(i))
- >> 1 : i is well clustered- >> -1 : i is not correctly clustered- >> 0 : i is on the border of two clusters
- avg(s(i)) -> how appropriately the data has been clustered (k?)
http://scikit-learn.org/stable/modules/generated/sklearn.metrics.silhouette_samples.html

Areas - Hierarchical clustering - Input: precomputed distance matrix: 1 - jaccard- Considered methods: single, complete, weighted, and average- Silhouette = f(nbr clusters)
24Python src code used for the evaluation: https://github.com/amirkrifa/ms-web-dataset

Areas - EM clustering
25
EM clustering using WEKA:- Scheme:weka.clusterers.EM -I 100 -N -1 -M 1.0E-6 -S ?- Instances: 294, Attributes: 32710- Test mode:evaluate on training data- Clustered Instances- Time taken to build model (full training data) : 2154.74 seconds ~ 34 min
Weka input files: https://github.com/amirkrifa/ms-web-dataset
Seed value: 100 Seed value: 50
- Log likelihood: 43424.49857 - 0 27 ( 9%)- 1 267 ( 91%)
- Log likelihood: 44569.7144- 0 30 ( 10%)- 1 261 ( 89%)- 2 3 ( 1%)

Users - EM clustering
26
EM clustering using WEKA:- Scheme:weka.clusterers.EM -I 100 -N -1 -M 1.0E-6 -S 100- Instances: 32710, Attributes: 294- Test mode:evaluate on training data- Clustered Instances- Time taken to build model (full training data) : 18324.67 seconds ~ 5h
Nbr of Generated Clusters: 5 (Log likelihood: 801.27554)
0 1526 ( 5%)1 23251 ( 71%)2 2196 ( 7%)3 1483 ( 5%)4 4254 ( 13%)
Weka input files: https://github.com/amirkrifa/ms-web-dataset

Road Map- Dataset && Goals- Recommendation systems
- Discussing options- Evaluation methodology + some results
- Clustering- Discussing options- Evaluation methodology + some results
- Conclusion && related work
27

Conclusion && Beyond the MS web dataset
- Overview about the MS web dataset- Discussed some collaborative filtering/clustering solutions
with respect to the dataset- Interesting related work:
- "Google news personalization: scalable online collaborative filtering." Proceedings of the 16th international conference on World Wide Web. ACM, 2007.
- Combine recommendation from different models: mix of model + memory based approaches
- Important items/users churn- Redesign the Probabilistic Latent Semantic Indexing (PLSI) model as a MapReduce
computation -> highly scalable
28