reconfigurable/fpga computing part 2
DESCRIPTION
reconfigurable/fpga computing part 2\nuse of fpga in hpc computing - PowerPoint PPT PresentationTRANSCRIPT

May 10, 2014 R.Innocente 63
Reconfigurable computing
Roberto Innocente
Part 2 of 2

May 10, 2014 R.Innocente 64
FPGA lingo

May 10, 2014 R.Innocente 65
Core
Core in FPGA lingo is a function ready to be instantiated into your design as a “black box”. It can be suppliad as HDL or schematic.
It supports design re-use.

May 10, 2014 R.Innocente 66
Soft/hard coresOn FPGAs functional modules can be implemented :
- using std FPGA resources(logic blocks, DSPs, memory blocks) : softcores
- as an ASIC on the FPGA : hardcores
When the manufacturer puts a processor as an hardcore on the FPGA then it sells this as a SoC (Sytem On Chip) : Dual ARM on Zync-7000 chip, PowerPC on Altera FPGA

May 10, 2014 R.Innocente 67
IP/open cores
The soft attribute is implied.
Hardware designs in an HDL(eventually using vendor libraries):
- opensource cores : http://opencores.org/
OpenRISC 1000 architecture from the OpenCores community,
the Lattice Semiconductor LM32, the LEON3 from Aeroflex
Gaisler and the OpenSPARC family from Oracle
- proprietary : IP(Intellectual Property) cores
Floating point operators, fft, matrix computations

May 10, 2014 R.Innocente 68
Commercial offers

May 10, 2014 R.Innocente 69
PicocomputingSC6 1U Upto 16 FPGA SC6 4U upto 48
EX-600EX-800
FromPICOCOMPUTING

May 10, 2014 R.Innocente 70
Bittware Terabox16 altera stratix-V
From Bittware

May 10, 2014 R.Innocente 71
DINIGROUP Cluster of 4 Virtex7
From DINIGROUP
May 10, 2014 R.Innocente 72
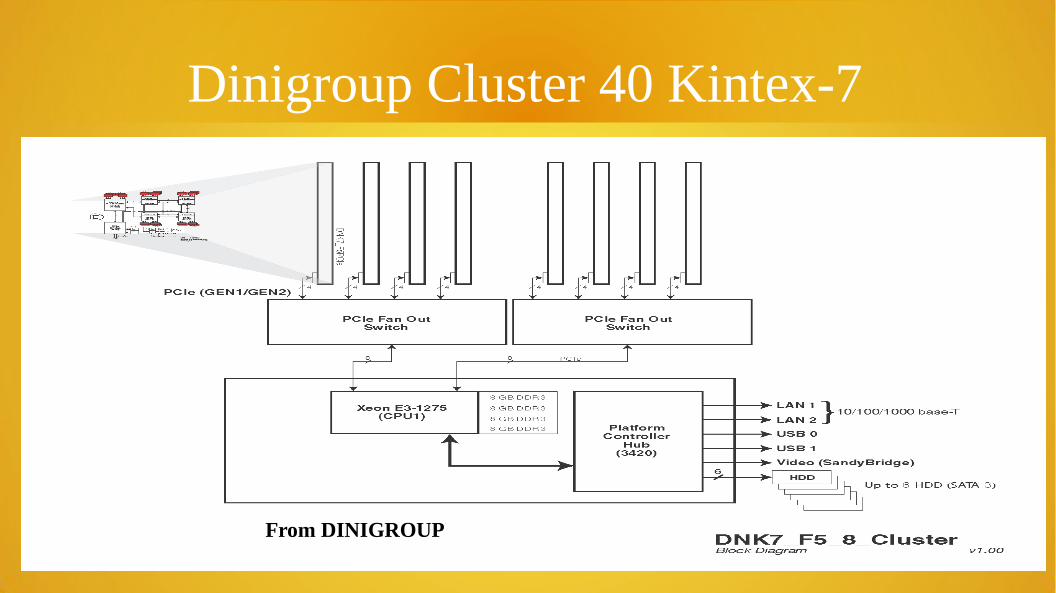
Dinigroup Cluster 40 Kintex-7
From DINIGROUP

May 10, 2014 R.Innocente 73
Maxeler MPC-X
Daresbury Lab UK :The dataflow supercomputer will feature Maxeler developed MPC-X nodes capable of an equivalent 8.52TFLOPs per 1U and 8.97 GFLOPs/Watt.

May 10, 2014 R.Innocente 74
Convey HC-2 , HC-2ex

May 10, 2014 R.Innocente 75
Cray XT5h
“Cray introduces an hybrid supercomputer thatcan integrate multiple processor architectures into a single system and accelerate high performance computing (HPC) workflows. The Cray XT5h delivers higher sustained performance, by applying alternative processor architectures across selected applications within an HPC workflow. The Cray XT5h supports avariety of processor technologies, including scalar processors based on AMD OpteronTM dual and quad-core technologies, vectorprocessors, and FPGA accelerators.”

May 10, 2014 R.Innocente 76
CHRECCenter for High PerformanceReconfigurable ComputingUF/BYU/GWU/VTECH

May 10, 2014 R.Innocente 77
CHREC Novo-G 384 FPGAs“Novo-G is the most powerful reconfigurable supercomputer in the known world. This unique machine features 192 top-end, 40nm FPGAs (Altera Stratix-IV E530) and 192 top-end, 65nm FPGAs (Stratix-III E260). “
http://www.chrec.org/
(pronounce it as shreck)

May 10, 2014 R.Innocente 78
BLAST like Smith-Waterman computes local alignment of 2 sequences :
- Novo-BLAST Novo-G/CHREC implementation : faster, same sensitivity
IPC(Isotope Pattern Calculator) of Protein Identification Algorithm :
- speed up 52-366 on single fpga, 1259 on 4 fpgas, 3340 on a node(16 fpgas)
CHREC/2

May 10, 2014 R.Innocente 79
References forApplications

May 10, 2014 R.Innocente 80
Linear Algebra for RC
Juan Gonzalez and Rafael C. NúñezLAPACKrc: Fast linear algebra kernels/solvers for FPGAaccelerators(JP 2009)DOD funded

May 10, 2014 R.Innocente 81
DCT, FFT on FPGAs
Digital Signal Processing with Field Programmable Gate Arrays ,3d edition(2007)
U.Mayer Baese, Springer Verlag

May 10, 2014 R.Innocente 82
MD on FPGA There are many papers about porting Molecular Dynamics algorithms on FPGAs with substantial positive conclusions about experiments on 1-2 FPGAs. But in the last years there is an embarassing comparison with ANTON (Shaw et al.).
We cant forget that ANTON is a really huge machine consuming over 100 KW !!!!
And is made out of 512 dedicated ASICs at 1ghz!
The comparison with some FPGAs consuming 40/60 W is improper.
FPGA-Accelerated Molecular Dynamics(2013) M. A. Khan,M. Chiu, M. C. Herbordt

May 10, 2014 R.Innocente 83
Neural networks on FPGAs
Editors : Omondi , Rajakapse (2006)
FPGA implementation of neural networks
ANN(Artificial Neural Network) in integer arithmetic performs 40x better than on GPP (old FPGA, 3 generation old)

May 10, 2014 R.Innocente 84
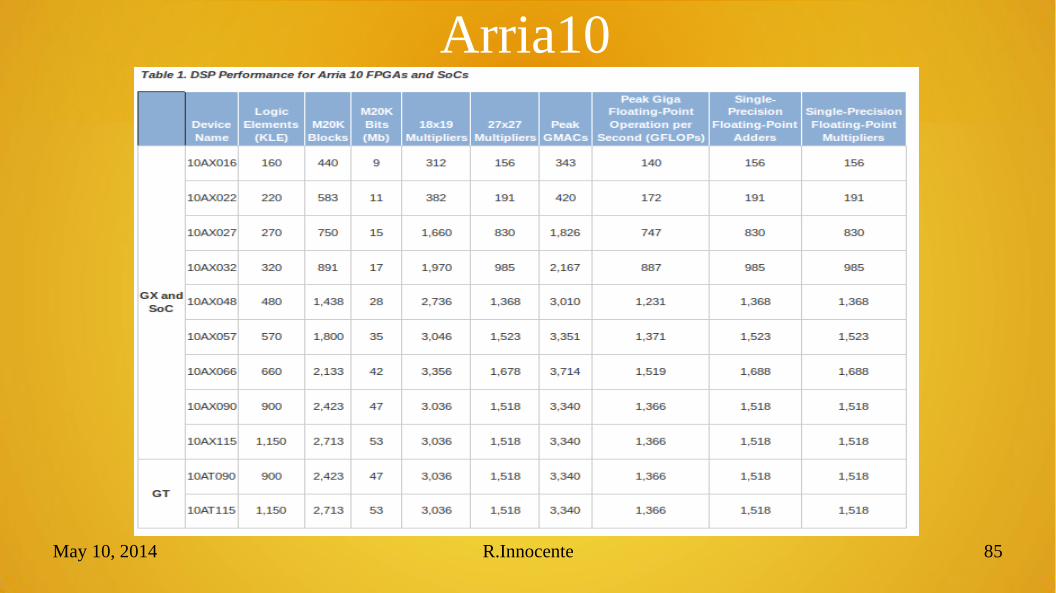
Altera Arria 10
May 10, 2014 R.Innocente 85
Arria10

May 10, 2014 R.Innocente 86
Arria 10 variable precision DSP block
Altera
A
B
CD
A+C*D = 2 flop

May 10, 2014 R.Innocente 87
Arria10 estimated sp fp performance
- 2 flops per cycle
- 1688 fp single precision DSP (GX660)
1688*2 = 3376 flops per cycle
3376 * 0.5 ghz ~ 1.7 Teraflops in single precision

May 10, 2014 R.Innocente 88
Hard single prec FP on FPGA ?!?
For people that can live with single precision this seems a very attractive new feature.
But many think that it is too much a waste of generic resources and claim that what was missing were simpler blocks !

May 10, 2014 R.Innocente 89
Back of the envelopeperformance estimation

May 10, 2014 R.Innocente 90
Back of the envelope performance estimation
Given number of
- LUTs
- FFs
- DSPs
offered by an FPGA,
and utilization of resources by operators, estimate the max number of operators that can be implemented on the FPGA
Today FPGA clocks are ~500Mhz=0.5GHz(unavoidable price for flexibility)2000 flops per cycle = 1 Teraflops

May 10, 2014 R.Innocente 91
Xilinx Virtex-7 family
Virtex-7 slices : 4 x 6-input LUTs, 8 FFsVirtex-7 DSPs : 48 bits pre-adder, 25x18 multiplier, 48 bits accumulatorVirtex LUT ~ 1.6 standard LUT

May 10, 2014 R.Innocente 92
Custom precision 17/24 bits floating
dsp lut+ff lut ff # tot dsp tot lut tot ff* 2 103 90 112 1080 2160 208440 232200
1 113 97 104 0 0 0 00 377 336 376 0 0 00 0 0 0 0 0 0
0 0 0+ 0 369 301 393 1510 0 1011700 1150620
0 0 0 0 0 0 0 0
Tot 2590 2160 1220140 1382820
Virtex-7 V2000T available resources
slices LUT x FF x dsp 6 input ff
slice slice LUT305400 4 8 2160 1221600 2443200
1.6standard LUTs 1954560

May 10, 2014 R.Innocente 93
IEEE single precision – 32 bits
dsp lut+ff lut ff # tot dsp tot lut tot ff* 3 120 103 105 700 2100 156100 157500
2 160 128 160 0 0 0 01 331 283 331 0 0 00 665 629 669 0 0 0
0 0 0+ 2 293 225 327 25 50 12950 15500
0 500 407 541 1160 0 1052120 1207560
Tot 1885 2150 1221170 1380560
Virtex-7 V2000T available resources
slices LUT x FF x dsp 6 input ff
slice slice LUT305400 4 8 2160 1221600 2443200
1.6standard LUTs 1954560
May 10, 2014 R.Innocente 94
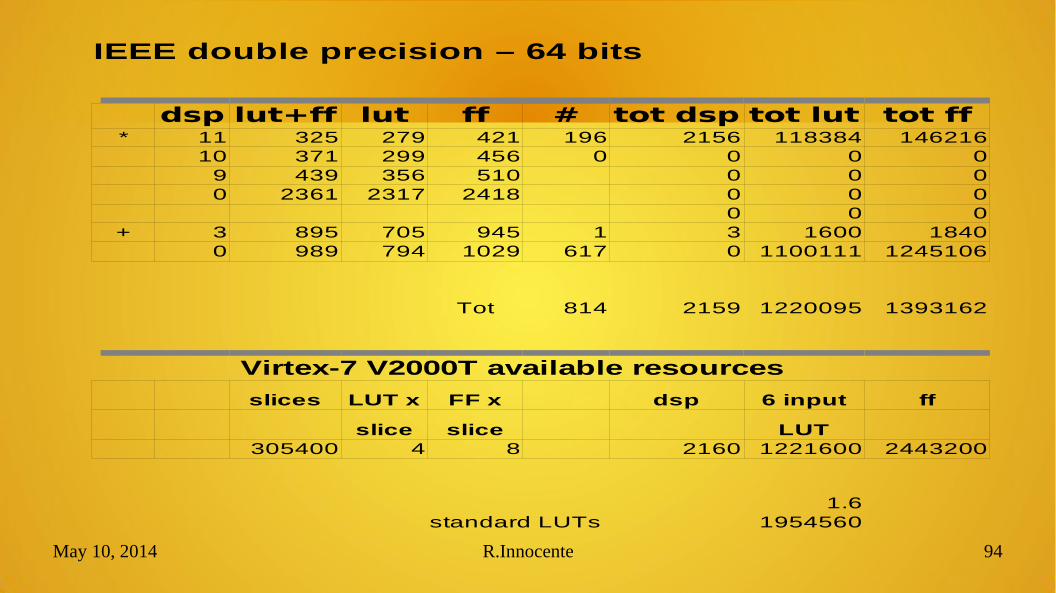
IEEE double precision – 64 bits
dsp lut+ff lut ff # tot dsp tot lut tot ff* 11 325 279 421 196 2156 118384 146216
10 371 299 456 0 0 0 09 439 356 510 0 0 00 2361 2317 2418 0 0 0
0 0 0+ 3 895 705 945 1 3 1600 1840
0 989 794 1029 617 0 1100111 1245106
Tot 814 2159 1220095 1393162
Virtex-7 V2000T available resources
slices LUT x FF x dsp 6 input ff
slice slice LUT305400 4 8 2160 1221600 2443200
1.6standard LUTs 1954560

May 10, 2014 R.Innocente 95
Virtex UltraScale XCVU440 20nm -sampling outIEEE double precision – 64 bits
dsp lut+ff lut ff # tot dsp tot lut tot ff* 11 325 279 421 261 2871 157644 194706
10 371 299 456 0 0 0 09 439 356 510 0 0 00 2361 2317 2418 0 0 0
0 0 0+ 3 895 705 945 3 9 4800 5520
0 989 794 1029 1321 0 2355343 2665778
Tot 1585 2880 2517787 2866004
Virtex Ultra Scale - available resources
slices LUT x FF x dsp 6 input ff
slice slice LUT314820 8 16 2880 2518560 5037120
1.6standard LUTs 4029696

May 10, 2014 R.Innocente 96
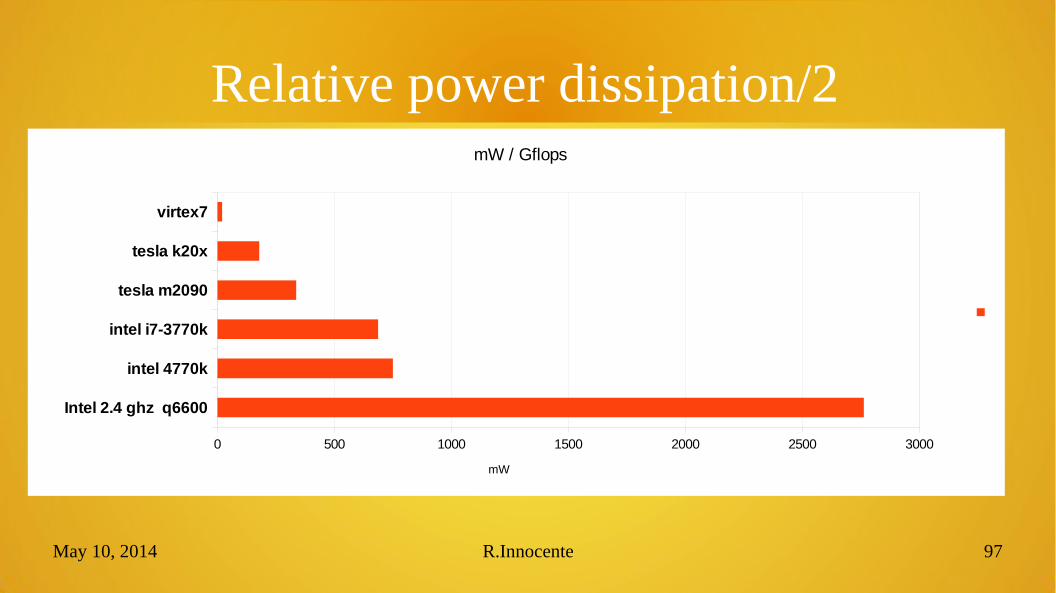
Relative power dissipation/1TDP/peak nominal double fp performance :
Intel Q6600 2.4ghz 105W/ 38 gflops = 2763mW/gflops
Intel Haswell i7-4770K 3.5ghz 84W/ 112 gflops = 750mW/gflops
Intel IvyBridge 3770K 3.5ghz 77W/ 112 gflops = 687mW/gflops
Nvidia Tesla M2090 225W/ 666 gflops = 337mW/gflops
Nvidia Tesla K20X 235W/1310gflops = 179mW/gflops
Xilinx Virtex-US 20W/ 800gflops = 25mW/gflops C ol um n 1C ol um n 2C ol um n 3
FPGA computing = green computing
}} ~10x
~30x
May 10, 2014 R.Innocente 97
Relative power dissipation/2
Intel 2.4 ghz q6600
intel 4770k
intel i7-3770k
tesla m2090
tesla k20x
virtex7
0 500 1000 1500 2000 2500 3000
mW / Gflops
mW

May 10, 2014 R.Innocente 98
Gflops per Wattpeak nominal double fp performance/TDP :
Intel Q6600 2.4ghz 38 gflops/105 W = 0.36 gflops/W
Intel Haswell i7-4770K 3.5ghz 112 gflops/84 W = 1.33 gflops/W
Intel IvyBridge 3770K 3.5ghz 112 gflops/77 W = 1.45 gflops/W
Nvidia Tesla M2090 666 gflops/225 W = 2.96 gflops/W
Nvidia Tesla K20X 1310 gflops/235 W = 5.57 gflops/W
Xilinx Virtex-US 800 gflops/20 W = 40 gflops/W C ol um n 1C ol um n 2C ol um n 3
FPGA computing = green computing
}} ~10x
~30x

May 10, 2014 R.Innocente 99
Top green500 listgreen500_ranktotal_power Year name Total CoresName ManufacturerCountry
1 28 4,503 2013 2720 TSUBAME-KFC NEC Japan2 53 3,632 2013 5120 Wilkes Dell United Kingdom3 79 3,518 2013 4864 HA-PACS TCA Cray Inc. Japan4 1,754 3,186 2012 115984 Cray Inc. Switzerland5 81 3,131 2013 5720 romeo Bull SA France6 923 3,069 2013 74358 TSUBAME 2.5 NEC/HP Japan7 54 2,702 2013 3080 IBM United States8 270 2,629 2013 15840 IBM Germany9 56 2,629 2013 3264 IBM United States
10 71 2,359 2010 4620 CSIRO GPU Cluster Xenon SystemsAustralia11 179 2,351 2012 38400 SANAM Saudi Arabia12 82 2,299 2011 16384 IBM United States13 82 2,299 2012 16384 Cetus IBM United States14 82 2,299 2012 16384 IBM Poland15 82 2,299 2013 16384 IBM United States16 82 2,299 2012 16384 Vesta IBM United States17 82 2,299 2012 16384 IBM United States18 237 2,243 2013 10920 HPCC Hewlett-PackardUnited States
Mflops/WattLX 1U-4GPU/104Re-1G Cluster, Intel Xeon E5-2620v2 6C 2.100GHz, Infiniband FDR, NVIDIA K20xDell T620 Cluster, Intel Xeon E5-2630v2 6C 2.600GHz, Infiniband FDR, NVIDIA K20Cray 3623G4-SM Cluster, Intel Xeon E5-2680v2 10C 2.800GHz, Infiniband QDR, NVIDIA K20xCray XC30, Xeon E5-2670 8C 2.600GHz, Aries interconnect , NVIDIA K20xPiz DaintBull R421-E3 Cluster, Intel Xeon E5-2650v2 8C 2.600GHz, Infiniband FDR, NVIDIA K20xCluster Platform SL390s G7, Xeon X5670 6C 2.930GHz, Infiniband QDR, NVIDIA K20xiDataPlex DX360M4, Intel Xeon E5-2650v2 8C 2.600GHz, Infiniband FDR14, NVIDIA K20xiDataPlex DX360M4, Intel Xeon E5-2680v2 10C 2.800GHz, Infiniband, NVIDIA K20xiDataPlex DX360M4, Intel Xeon E5-2680v2 10C 2.800GHz, Infiniband, NVIDIA K20xNitro G16 3GPU, Xeon E5-2650 8C 2.000GHz, Infiniband FDR, Nvidia K20mAdtech, ASUS ESC4000/FDR G2, Xeon E5-2650 8C 2.000GHz, Infiniband FDR, AMD FirePro S10000AdtechBlueGene/Q, Power BQC 16C 1.60 GHz, CustomBlueGene/Q, Power BQC 16C 1.600GHz, Custom InterconnectBlueGene/Q, Power BQC 16C 1.600GHz, Custom InterconnectBlueGene/Q, Power BQC 16C 1.600GHz, Custom InterconnectBlueGene/Q, Power BQC 16C 1.60GHz, CustomBlueGene/Q, Power BQC 16C 1.60GHz, CustomCluster Platform SL250s Gen8, Xeon E5-2665 8C 2.400GHz, Infiniband FDR, Nvidia K20m

May 10, 2014 R.Innocente 100
Power/Energy efficiency

May 10, 2014 R.Innocente 101
Power Dissipation
PT=kCV 2 f +Ps
Ed=12CV 2
A chip is made of millions of CMOS FETs. When input switches, you need to charge the small capacitance :
f times a second gives, together with some constant static dissipation :
Anyway increasing a lot the frequency, the chip becomes unstable unless you increase also the voltage(leakage). Therefore there is in fact a superlinear behaviour vs f:

May 10, 2014 R.Innocente 102
Dennard scaling(1974)
1
S
S3
S2 = 2x moretransistors
S = 1.4x lowercapacitance
Scale Vdd by S => S2 = 2x lower energy
S2S = 1.4x fastertransistors
Performance scales as S3 = 2.8 while power density stays constant across generations

May 10, 2014 R.Innocente 103
Fred Pollack(Intel) famous graph(1999)
Power density increases !!!In 2004/2005 we hit the power wall => stop frequency increases
“New microarchitecture challenges in the coming generations of CMOS process technology” F.Pollack
May 10, 2014 R.Innocente 104
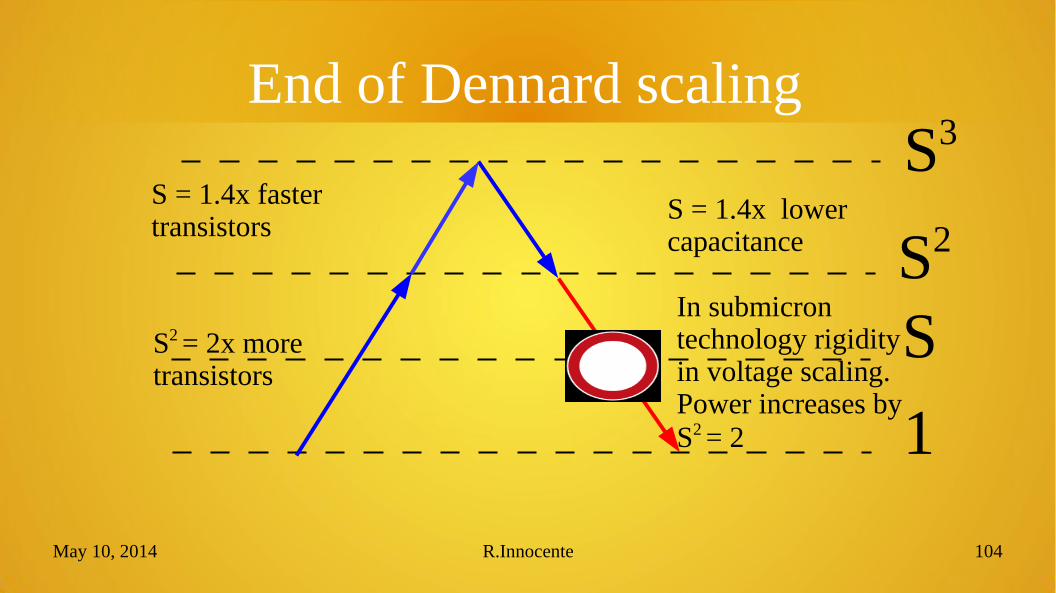
End of Dennard scaling
1
S
S3
S2 = 2x moretransistors
S = 1.4x lowercapacitance S2
S = 1.4x fastertransistors
In submicron technology rigidity in voltage scaling. Power increases by S2 = 2

May 10, 2014 R.Innocente 105
MOS subthreshold currentScaling down geometry you scale down drain voltage to avoid high electric fields and to decrease energy required to switch. You have to scale down also the threshold voltage to sustain the 30% decrease of gate delay. The small voltage swing that remains is not able to completely turn off the transistor. Subthreshold leakage that was ignored in the past can on modern VLSI chips consume up to ½ of the total power.

May 10, 2014 R.Innocente 106
Subthreshold leakage

May 10, 2014 R.Innocente 107
VT
design tradeoff
VGS
log IDS
- Low VT for high ON current :
- High VT for low OFF current
Phenomenology :60-200 mV of V
GS swing decreases I
DS by
one order of magnitude. Today 0.5-0.2V
T doesn't allow the needed swing of V
GS to
shutoff the transistor.
I Dsat∝(V DD−V T )2
Low VT
=> high IDS
good for ON condition
High VT => low leakage
good for OFF condition

May 10, 2014 R.Innocente 108
Multicore scaling
65 nm 45 nm 32 nm
4-core 8-core 16-core
Every generation 2x cores, at same or slightly increasing frequency.

May 10, 2014 R.Innocente 109
Multicore scaling at constant frequency
1
SS2
S2 = 2x moretransistors
S = 1.4x lowercapacitance
} S = 1.4x lowerutilization
We hit the utilization wall => dark silicon

May 10, 2014 R.Innocente 110
End of multicore scaling
65 nm 32 nm
4 cores 8 cores
Every generation 1.4x cores, at same or slightly increasing frequency.
Dark or dim silicon(“uncore”)
45 nm
5.7 cores

May 10, 2014 R.Innocente 111
Dark silicon and the end of multicore scaling
Doug Burger (Microsoft) at HiPEAC 2013 :
- till 2004: each semiconductor generation gave transistors smaller, faster and that consume less
- from 2004 to now: we still got smaller transistors, but we could not run them faster (power wall)
- in the future : we will still get smaller transistors but we will not be able to use all of them together(dark silicon) or at max speed.

May 10, 2014 R.Innocente 112
Scaling the utilization wallG.Venkatesh ASPLOS 10 :
“while the area budget continues to increase exponentially, the power budget has become a first-order design constraint in current processors. In this regime, utilizing transistors to design specialized cores that optimize energy-per-computation becomes an effective approach to improve the system performance.
”The Utilization Wall : With each successive process generation, the percentage of a chip that can switch at full frequency drops exponentially due to power constraints. [Venkatesh, ASPLOS ‘10]
Single chip heterogeneous computer (E.Chung)
Greater energy efficiency combining GPP with unconventional cores (U-cores) : GPU,FPGA,DSP,ASICs ..

May 10, 2014 R.Innocente 113
3D FinFET promiseBelow 20nm the roadmap is to use 3D FinFETs :- Faster : +37%- Dynamic Power: -50%- Static Power: -90%
KAIST demonstrated a 3nmFinFET in lab

May 10, 2014 R.Innocente 114
The trouble with multicoreA famous article of David Patterson (of “Computer architecture: a quantitative approach” fame) on IEEE Spectrum, 2010 :
“Chipmakers are busy designing microprocessors that most programmers can’t program”
“... the semiconductor industry threw the equivalent of a Hail Mary pass when it switched from making microprocessors run faster to putting more of them on a chip - doing so without any clear notion of how such devices would in general be programmed. The hope is that someone will be able to figure out how to do that, but at the moment, the ball is still in the air.”

May 10, 2014 R.Innocente 115
Verilog

May 10, 2014 R.Innocente 116
Using VerilogYou write a functional specification (usually) splitted in modules that documents the exact behaviour of the system.
LogicSynthesis
Place &Route
HDL (Verilog)
FPGAASIC
Functionaldesign
Physicaldesign
Gatenetlist
Simulated annealing used here !
NB. place and route of a large design can take 1 day of a fast CPU !!

May 10, 2014 R.Innocente 117
Verilog/1Basic module :
// comments in this waymodule name(input x0,x1,input [3:0]y, output out);// x0,x1 are wires, y is a 4 wires bus// out is an output wire// combinational logic use assign wire x0,x1, [3:0]y, outendmodule

May 10, 2014 R.Innocente 118
Verilog/2Combinatorial circuit :
// performs not a b c + a not b not cmodule dummy(input a,b,c, output y,z); wire a,b,c,y; assign y = ~a & b & c | a & ~b & ~c; assign z = ~c;endmodule
This is not C ! a,b,c,y,z are wires and y,z change whenever
a or b or c change. To avoid this drama for complex circuitswe use synchronous logic
(everything is stepped in docking stations = Flip flops)
May 10, 2014 R.Innocente 119
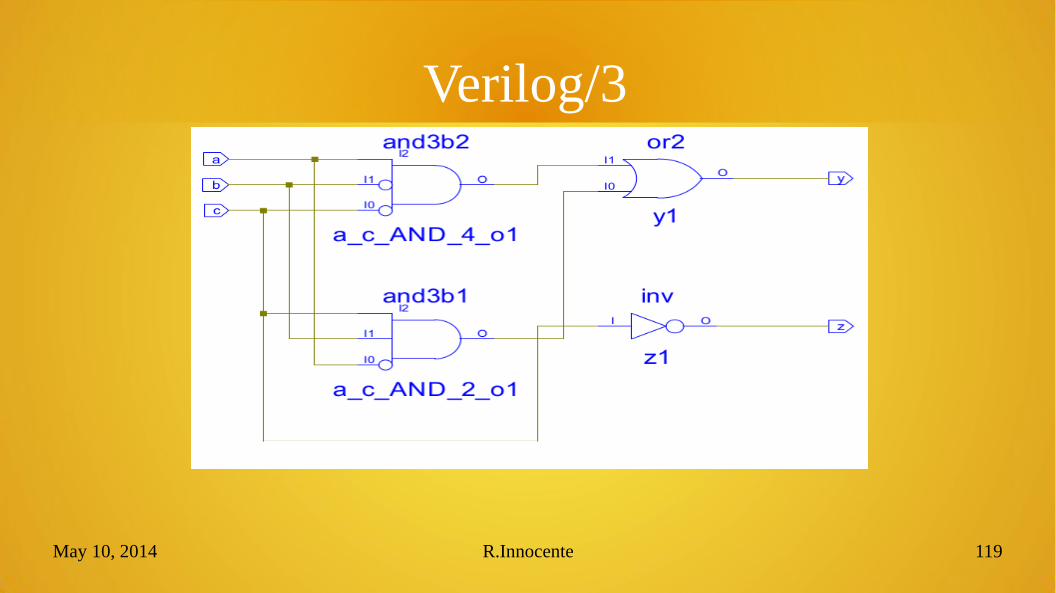
Verilog/3

May 10, 2014 R.Innocente 120
Verilog/4A sequential circuit :
// a flip flop described in verilogmodule ff(input d, clk, output q, qbar); wire d, clk; reg q, qbar; always @(posedge clk) begin q <= d; qbar <= ~d; endendmodule
At a raising edge of the wire clk copy the signal to q and the inverse of d to qbar

May 10, 2014 R.Innocente 121
Verilog/5

May 10, 2014 R.Innocente 122
Verilog/6A more complicate sequential circuit :
// in verilog FF with clear/resetmodule ff(input d, clk,clr, output q, qbar); wire d, clk; reg q, qbar; always @(posedge clk, posedge clr) if (clr) q <= 0; else begin q <= d; endendmodule
At a raising edge of the wire clr set q=0, at the raising edge
of clk copy the signal to q and the inverse of d to qbar

May 10, 2014 R.Innocente 123
Verilog/7

May 10, 2014 R.Innocente 124
BORPH : Berkeley Operating system for ReProgrammable HardwarePETALINUX : Xilinx linux for Zynq et al.

May 10, 2014 R.Innocente 125
- Idea of HW unix process : has pid, can be killed like a normal unix process, but in fact is an HW instance on FPGA
- ioreg Virtual File System interface
Borph : Berkeley Operating System

May 10, 2014 R.Innocente 126
Xilinx Petalinux
The PetaLinux Software Development Kit (SDK) is a development tool that contains everything necessary to build, develop, test and deploy Embedded Linux systems on : Zync-7000, Zedboard, Kintex-7 boards.
PetaLinux consists of : pre-configured binary bootable images, fully customizable Linux for the Xilinx device, and PetaLinux SDK which includes tools and utilities to automate complex tasks across configuration, build, and deployment.
PetaLinux is offered under two separate licenses :
No charge Evaluation license or Commercial licenses

May 10, 2014 R.Innocente 127
END