research article improved emotion recognition using...
TRANSCRIPT

Research ArticleImproved Emotion Recognition Using Gaussian Mixture Modeland Extreme Learning Machine in Speech and Glottal Signals
Hariharan Muthusamy1 Kemal Polat2 and Sazali Yaacob3
1School of Mechatronic Engineering Universiti Malaysia Perlis (UniMAP) Campus Pauh Putra 02600 Perlis Perlis Malaysia2Department of Electrical and Electronics Engineering Faculty of Engineering and Architecture Abant Izzet Baysal University14280 Bolu Turkey3Universiti Kuala Lumpur Malaysian Spanish Institute Kulim Hi-Tech Park 09000 Kulim Kedah Malaysia
Correspondence should be addressed to Hariharan Muthusamy hariunimapedumy
Received 25 August 2014 Accepted 29 December 2014
Academic Editor Gen Qi Xu
Copyright copy 2015 Hariharan Muthusamy et al This is an open access article distributed under the Creative Commons AttributionLicense which permits unrestricted use distribution and reproduction in any medium provided the original work is properlycited
Recently researchers have paid escalating attention to studying the emotional state of an individual from hisher speech signalsas the speech signal is the fastest and the most natural method of communication between individuals In this work new featureenhancement using Gaussian mixture model (GMM) was proposed to enhance the discriminatory power of the features extractedfrom speech and glottal signals Three different emotional speech databases were utilized to gauge the proposed methods Extremelearning machine (ELM) and k-nearest neighbor (119896NN) classifier were employed to classify the different types of emotions Severalexperiments were conducted and results show that the proposed methods significantly improved the speech emotion recognitionperformance compared to research works published in the literature
1 Introduction
Spoken utterances of an individual can provide informationabout hisher health state emotion language used genderand so on Speech is the one of the most natural form ofcommunication between individuals Understanding of indi-vidualrsquos emotion can be useful for applications like webmovies electronic tutoring applications in-car board systemdiagnostic tool for therapists and call center applications [1ndash4] Most of the existing emotional speech database containsthree types of emotional speech recordings such as simulatedelicited and natural ones Simulated emotions tend to bemore expressive than real ones and most commonly used[4] In the elicited category emotions are nearer to thenatural database but if the speakers know that they are beingrecorded the quality will be artificial Next in the naturalcategory all emotions may not be available and difficult tomodel because these are completely naturally expressedMostof the researchers have analysed four primary emotions suchas anger joy fear and sadness either in stimulated domain orin natural domainHigh emotion recognition accuracieswere
obtained for two-class emotion recognition (high arousalversus low arousal) but multiclass emotion recognition isstill disputing This is due to the following reasons (a) whichspeech features are information-rich and parsimonious (b)different sentences speakers speaking styles and rates (c)more than one perceived emotion in the same utterance and(d) long-termshort-term emotional states [1 3 4]
To improve the accuracy of multiclass emotion recogni-tion a new GMM based feature enhancement was proposedand tested using 3 different emotional speech databases(Berlin emotional speech database (BES) Surrey audio-visualexpressed emotion (SAVEE) database and SahandEmotionalSpeech database (SES)) Both speech signals and its glottalwaveforms were used for emotion recognition experimentsTo extract the glottal and vocal tract characteristics from thespeech waveforms several techniques have been proposed[5ndash8] In this work we extracted the glottal waveformsfrom the emotional speech signals by using inverse filteringand linear predictive analysis [5 6 9] Emotional speechsignals and its glottal waveforms were decomposed into 4levels using discrete wavelet packet transform and relative
Hindawi Publishing CorporationMathematical Problems in EngineeringVolume 2015 Article ID 394083 13 pageshttpdxdoiorg1011552015394083
2 Mathematical Problems in Engineering
energy and entropy features were calculated for each of thedecomposition nodes A total of 120 features were obtainedHigher degree of overlap between the features of differentclasses may degrade the performance of classifiers whichresults in poor recognition of speech emotions To decreasethe intraclass variance and to increase the interclass varianceamong the features GMM based feature enhancement wasproposed which results in improved recognition of speechemotions Both raw and enhanced features were subjected toseveral experiments to validate their effectiveness in speechemotion recognition The rest of this paper is organized asfollows Some of the significant works on speech emotionrecognition are discussed in Section 2 Section 3 presentsthe materials and methods used Experimental results anddiscussions are presented in Section 4 Finally Section 5concludes the paper
2 Previous Works
Several speech features have been successfully applied forspeech emotion recognition and can be mainly classified intofour groups such as continuous features qualitative featuresspectral features and nonlinear Teager energy operator basedfeatures [1 3 4] Various types of classifiers have beenproposed for speech emotion recognition such as hiddenMarkov model (HMM) Gaussian mixture model (GMM)support vector machine (SVM) artificial neural networks(ANN) and 119896-NN [1 3 4] This section describes some ofthe recently published works in the area of multiclass speechemotion recognition Table 1 shows the list of some of therecent works in multiclass speech emotion recognition usingBES and SAVEE databases
Though speech related features are widely used for speechemotion recognition there is a strong correlation between theemotional states and features derived from glottal waveformsGlottal waveform is significantly affected by the emotionalstate and speaking style of an individual [10ndash12] In [10ndash12]researchers have investigated that the glottal waveform wasaffected due to the excessive tension or lack of coordinationin the laryngeal musculature under different emotional statesand the speech produced under stress The classification ofclinical depression using the glottal features was carried outby Moore et al in [13 14] In [15] authors have obtained85 of the correct emotion recognition rate by using theglottal flow spectrum as a possible cue for depression andnear-term suicide risk Iliev and Scordilis have investigatedthe effectiveness of glottal features derived from the glottalairflow signal in recognizing emotions [16] The averageemotion recognition rate of 665 for all six emotions(happiness anger sadness fear surprise and neutral) and99 for four emotions (happiness neutral anger and sad-ness) was achieved He et al have proposed wavelet packetenergy entropy features for emotion recognition from speechand glottal signals with GMM classifier [17] They achievedaverage emotion recognition rates for BES database between51 and 54 In [18] prosodic features spectral featuresglottal flow features and AM-FM features were utilized andtwo-stage feature reductionwas proposed for speech emotionrecognition The overall emotion recognition rate of 8518
for gender-dependent and 8009 for gender-independentwas achieved using SVM classifier
Several feature selectionreduction methods were pro-posed to selectreduce the course of dimensionality of speechfeatures Although all the above works are novel contri-butions to the field of speech emotion recognition it isdifficult to compare them directly since division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulatedor naturalistic speech emotion databases and lack of uni-formity in computation and presentation of the resultsMost of the researchers have commonly used 10-fold crossvalidation and conventional validation (one training set +one testing set) and some of them have tested their meth-ods under speaker-dependent speaker-independent gender-dependent and gender-independent environments In thisregard the proposed methods were validated using three dif-ferent emotional speech databases and emotion recognitionexperiments were also conducted under speaker-dependentand speaker-independent environments
3 Materials and Methods
31 Emotional Speech Databases In this work three differentemotional speech databases were used for emotion recog-nition and to test the robustness of the proposed methodsFirst Berlin emotional speech database (BES)was usedwhichconsists of speech utterances in German [19] 10 professionalactorsactresses were used to simulate 7 emotions (anger 127disgust 45 fear 70 neutral 79 happiness 71 sadness 62and boredom 81) Secondly Surrey audio-visual expressedemotion (SAVEE) database [20] was used and it is an audio-visual emotional database which includes seven emotioncategories of speech utterances (anger 60 disgust 60 fear60 neutral 120 happiness 60 sadness 60 and surprise 60)from four native English male speakers aged from 27 to 31years 3 common 2 emotion-specific and 10 generic sen-tences from 15 TIMIT sentences per emotion were recordedIn this work only audio samples were utilized LastlySahand Emotional Speech database (SES) was used [21] andit was recorded at Artificial Intelligence and InformationAnalysis Lab Department of Electrical Engineering SahandUniversity of Technology IranThis database contains speechutterances of five basic emotions (neutral 240 surprise240 happiness 240 sadness 240 and anger 240) from 10speakers (5 male and 5 female) 10 single words 12 sentencesand 2 passages in Farsi language were recorded which resultsin a total of 120 utterances per emotion Figures 1(a)ndash1(d)show an example of portion of utterance spoken by a speakerin the four different emotions (neutral anger happinessand disgust) It can be observed from the figures that thestructure of the speech signals and its glottal waveformsare considerably different for speech spoken under differentemotional states
32 Features for Speech Emotion Recognition Extraction ofsuitable features for efficiently characterizing different emo-tions is still an important issue in the design of a speech
Mathematical Problems in Engineering 3
Table 1 Some of the significant works on speech emotion recognition
Ref number Database Signals Number of emotions Methods Best result
[49] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Nonlinear dynamic features+ prosodic + spectralfeatures + SVM classifier
8272(females)
8590 (males)
[50] BES Speech signals Neutral fear and anger Nonlinear dynamic features+ neural network
9378
[51] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Modulation spectralfeatures (MSFs) +multiclass SVM
8560
[30] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Combination of spectralexcitation source features +autoassociative neuralnetwork
8216
[27] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Combination ofutterancewise global andlocal prosodic features +SVM classifier
6243
[52] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
LPCCs + formants + GMMclassifier
68
[28] BES Speech signalsAnger boredom fearhappiness sadness andneutral
Discriminative bandwavelet packet powercoefficients (db-WPPC)with Daubechies filter oforder 40 + GMM classifier
7564
[53] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Low level audio descriptorsand high level perceptualdescriptors with linearSVM
877
[54] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
MPEG-7 low level audiodescriptors + SVM withradial basis function kernel
7788
[55] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Mel-frequency cepstralcoefficients + signal energy+ correlation based featureselection + SVMwith radialbasis function kernels
79
[56] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Energy intensity + pitch +standard deviation + jitter +shimmer + 119896NN
7439
[57] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Audio features + LDAfeature reduction + singlecomponent Gaussianclassifier
63
[20] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Pitch + energy + duration +spectral + Gaussianclassifier
592
emotion recognition system Short-term features were widelyused by the researchers called frame-by-frame analysisAll the speech samples were downsampled to 8 kHz Theunvoiced portions between words were removed by seg-menting the downsampled emotional speech signals intononoverlapping frames with a length of 32ms (256 samples)based on the energy of the frames Frames with low energywere discarded and the rest of the frames (voiced portions)
were concatenated and used for feature extraction [17] Thenthe emotional speech signals (only voiced portions) arepassed through a first-order low pass filter to spectrally flattenthe signal and to make it less susceptible to finite precisioneffects later in the signal processing [22] The first-orderpreemphasis filter is defined as
119867(119911) = 1 minus 119886 lowast 119911minus1
09 le 119886 le 10 (1)
4 Mathematical Problems in Engineering
0 001 002 003 004 005 006 007 008
00204
Neutral-speech signal
Time (ms)
0 001 002 003 004 005 006 007 008
005
115
Neutral-glottal signal
Time (ms)
minus04
minus02
minus1
minus05
(a)
0 001 002 003 004 005 006
00102
Anger-speech signal
Time (ms)
0 001 002 003 004 005 006
0020406
Anger-glottal signal
Time (ms)
minus04minus02
minus02
minus01
minus03
(b)
0 001 002 003 004 005 006
00204
Happiness-speech signal
Time (ms)
0 001 002 003 004 005 006
00204
Happiness-glottal signal
Time (ms)
minus04
minus02
minus04
minus02
(c)
0 001 002 003 004 005 006
0020406
Disgust-speech signal
Time (ms)
0 001 002 003 004 005 006
005
1Disgust-glottal signal
Time (ms)
minus04minus02
minus08minus06
minus05
(d)
Figure 1 ((a)ndash(d)) Emotional speech signals and its glottal waveforms (BES database)
The commonly used 119886 value is 1516 = 09375 or 095 [22]In this work the value of 119886 is set equal to 09375 Extractionof glottal flow signal from speech signal is a challengingtask In this work glottal waveforms were estimated basedon the inverse filtering and linear predictive analysis fromthe preemphasized speech waveforms [5 6 9] Wavelet orwavelet packet transform has the ability to analyze anynonstationary signals in both time and frequency domainsimultaneously The hierarchical wavelet packet transformdecomposes the original emotional speech signalsglottalwaveforms into subsequent subbands InWP decompositionboth low and high frequency subbands are used to generatethe next level subbands which results in finer frequencybands Energy of the wavelet packet nodes is more robustin representing the original signal than using the waveletpacket coefficients directly Shannon entropy is a robustdescription of uncertainty in the whole signal duration[23ndash26] The preemphasized emotional speech signals andglottal waveforms were segmented into 32ms frames with50 overlap Each frame was decomposed into 4 levelsusing discrete wavelet packet transform and relative waveletpacket energy and entropy features were derived for each of
the decomposition nodes as given in (4) and (7) Consider thefollowing
EGY119895119896
= log10
(sum10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
119871
2
) (2)
EGYtot = sumEGY119895119896
(3)
Relative wavelet packet energy RWPEGY =EGY119895119896
EGYtot (4)
EPY119895119896
= minussum10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
2
log10
10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
2
(5)
EPYtot = sumEPY119895119896
(6)
Relative wavelet packet entropy RWPEPY =EPY119895119896
EPYtot (7)
where 119895 = 1 2 3 119898 119896 = 0 1 2 2119898
minus 1 119898 isthe number of decomposition levels and 119871 is the lengthof wavelet packet coefficients at each node (119895 119896) In this
Mathematical Problems in Engineering 5
work Daubechies wavelets with 4 different orders (db3 db6db10 and db44) were used since Daubechies wavelets arefrequently used in speech emotion recognition and providebetter results [1 17 27 28] After obtaining the relativewaveletpacket energy and entropy based features for each frame theywere averaged over all frames and used for analysis Four-level wavelet decomposition gives 30 wavelet packet nodesand features were extracted from all the nodes which yield60 features (30 relative energy features + 30 relative entropyfeatures) Similarly the same features were extracted fromemotional glottal signals Finally a total of 120 features wereobtained
33 Feature Enhancement Using Gaussian Mixture Model Inany pattern recognition applications escalating the interclassvariance and diminishing the intraclass variance of theattributes or features are the fundamental issues to improvethe classification or recognition accuracy [24 25 29] In theliterature several research works can be found to escalatethe discriminating ability of the extracted features [24 2529] GMM has been successfully applied in various patternrecognition applications particularly in speech and imageprocessing applications [17 28ndash36] however its capabilityof escalating the discriminative ability of the features orattributes is not being extensively explored Different appli-cations of GMM motivate us to suggest GMM based featureenhancement [17 28ndash36] High intraclass variance and lowinterclass variance among the features may degrade theperformance of classifiers which results in poor emotionrecognition rates To decrease the intraclass variance and toincrease the interclass variance among the features GMMbased clustering was suggested in this work to enrich thediscriminative ability of the relative wavelet packet energyand entropy features GMM model is a probabilistic modeland its application to labelling is based on the assumptionthat all the data points are generated from a finite mixture ofGaussian mixture distributions In a model-based approachcertain models are used for clustering and attempting tooptimize the fit between the data andmodel Each cluster canbe mathematically represented by a Gaussian (parametric)distribution The entire dataset 119911 is modeled by a weightedsum of 119872 numbers of mixtures of Gaussian componentdensities and is given by the equation
119901 (119911119894
| 120579) =
119872
sum
119896=1
120588119896
119891 (119911119894
| 120579119896
) (8)
where 119911 is the 119873-dimensional continuous valued relativewavelet packet energy and entropy features 120588
119896
119896 = 1 2 3
119872 are the mixture weights and 119891(119911119894
| 120579119896
) 120579119896
=
(120583119896
Σ119896
) 119894 = 1 2 3 119872 are the component Gaussiandensities Each component density is an 119873-variate Gaussianfunction of the form
119891 (119911119894
| 120579119896
) =1
(2120587)1198992
1003816100381610038161003816Σ119894100381610038161003816100381612
sdot exp [minus12(119911 minus 120583
119894
)119879
Σminus1
119894
(119911 minus 120583119894
)]
(9)
Relative wavelet packet energy and entropy features
(120 features)
Calculate the component means (cluster centers) using GMM
Calculate the ratios of means of features to their centers and
multiply these ratios with each respective feature
Enhanced relative waveletpacket energy and entropy
features
Figure 2 Proposed GMM based feature enhancement
where 120583119894
is the mean vector and Σ119894
is the covariance matrixUsing the linear combination of mean vectors covariancematrices and mixture weights overall probability densityfunction is estimated [17 28ndash36] Gaussian mixture modeluses an iterative expectation maximization (EM) algorithmthat converges to a local optimum and assigns posteriorprobabilities to each component density with respect to eachobservation The posterior probabilities for each point indi-cate that each data point has some probability of belonging toeach cluster [17 28ndash36] The working of GMM based featureenhancement is summarized (Figure 2) as follows firstly thecomponent means (cluster centers) of each feature belongingto dataset using GMM based clustering method was foundNext the ratios of means of features to their centers werecalculated Finally these ratios were multiplied with eachrespective feature
After applying GMM clustering based feature weightingmethod the raw features (RF) were known as enhancedfeatures (EF)
The class distribution plots of raw relative wavelet packetenergy and entropy features were shown in Figures 3(a) 3(c)3(e) and 3(g) for different orders of Daubechies wavelets(ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo) From the figures it canbe seen that there is a higher degree of overlap amongthe raw relative wavelet packet energy and entropy featureswhich results in the poor performance of the speech emotionrecognition system The class distribution plots of enhancedrelative wavelet packet energy and entropy features wereshown in Figures 3(b) 3(d) 3(f) and 3(h) From the figuresit can be observed that the higher degree of overlap can bediminished which in turn improves the performance of thespeech emotion recognition system
34 Feature Reduction Using Stepwise Linear DiscriminantAnalysis Curse of dimensionality is a big issue in all patternrecognition problems Irrelevant and redundant features maydegrade the performance of the classifiers Feature selec-tionreduction was used for selecting the subset of relevantfeatures from a large number of features [24 29 37] Severalfeature selectionreduction techniques have been proposedto find most discriminating features for improving the per-formance of the speech emotion recognition system [18 2028 38ndash43] In this work we propose the use of stepwiselinear discriminant analysis (SWLDA) since LDA is a lineartechnique which relies on the mixture model containing
6 Mathematical Problems in Engineering
009 011 013 015 017
0059006100630065
00670055
0060065
0070075
Feature 7Feature 77
Feat
ure 1
08
(a)
02 06 102061
005
1
Feature 7Feature 77
Feat
ure 1
08
minus1minus06
minus02
minus1minus06
minus02
minus1
minus05
(b)
009 011 013 015 017
0120124012801320136
014023
0235024
0245025
0255026
0265
Feature 7Feature 67
Feat
ure 9
4
(c)
02 06 102061
0206
1
Feature 7Feature 67
Feat
ure 9
4
minus1minus06
minus02
minus1minus06
minus02
minus1
minus06
minus02
(d)
009 011 013 015 017
004006
00801
006008
01012014016018
Feature 7Feature 15
Feat
ure 4
3
(e)
02 06 102061
0206
1
Feat
ure 4
3
Feature 15 Feature 7minus1
minus06minus02
minus1minus06
minus02
minus1
minus06
minus02
(f)
009 011 013 015 017
00601
014018046047048049
05051052
Feature 7Feature 41
Feat
ure 9
2
AngerBoredomDisgustFear
HappinessSadnessNeutral
(g)
02 06 102061
0206
1
Feature 7
Feature 41
Feat
ure 9
2
minus1 minus1minus06
minus06
minus02minus02
minus1
minus06
minus02
AngerBoredomDisgustFear
HappinessSadnessNeutral
(h)
Figure 3 ((a) (c) (e) and (g)) Class distribution plots of raw features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo ((b) (d) (f) and (h)) Classdistribution plots of enhanced features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo
the correct number of components and has limited flexibilitywhen applied to more complex datasets [37 44] StepwiseLDA uses both forward and backward strategies In theforward approach the attributes that significantly contributeto the discrimination between the groups will be determinedThis process stops when there is no attribute to add in
the model In the backward approach the attributes (lessrelevant features) which do not significantly degrade thediscrimination between groups will be removed 119865-statisticor 119901 value is generally used as predetermined criterion toselectremove the attributes In this work the selection ofthe best features is controlled by four different combinations
Mathematical Problems in Engineering 7
of (005 and 01 SET1 001 and 005 SET2 001 and 0001SET3 0001 and 00001 SET4)119901 values In a feature entry stepthe features that provide the most significant performanceimprovement will be entered in the feature model if the 119901value lt 005 In the feature removal step attributes whichdo not significantly affect the performance of the classifierswill be removed if the 119901 value gt 01 SWLDA was applied tothe enhanced feature set to select best features and to removeirrelevant features
The details of the number of selected enhanced featuresfor every combination were tabulated in Table 2 FromTable 2 it can be seen that the enhanced relative energy andentropy features of the speech signals were more significantthan the glottal signals Approximately between 32 and82 of insignificant enhanced features were removed in allthe combination of 119901 values (005 and 01 001 and 005001 and 0001 and 0001 and 00001) and speaker-dependentand speaker-independent emotion recognition experimentswere carried out using these significant enhanced featuresThe results were compared with the original raw relativewavelet packet energy and entropy features and some of thesignificant works in the literature
35 Classifiers
351 119896-Nearest Neighbor Classifier 119896NN classifier is a type ofinstance-based classifiers and predicts the correct class labelfor the new test vector by relating the unknown test vector toknown training vectors according to some distancesimilarityfunction [25] Euclidean distance function was used andappropriate 119896-value was found by searching a value between1 and 20
352 Extreme Learning Machine A new learning algorithmfor the single hidden layer feedforward networks (SLFNs)called ELM was proposed by Huang et al [45ndash48] It hasbeenwidely used in various applications to overcome the slowtraining speed and overfitting problems of the conventionalneural network learning algorithms [45ndash48] The brief ideaof ELM is as follows [45ndash48]
For the given 119873 training samples the output of a SLFNnetwork with 119871 hidden nodes can be expressed as thefollowing
119891119871
(119909119895
) =
119871
sum
119894
120573119894
119892 (119908119894
sdot 119909119895
+ 119887119894
) 119895 = 1 2 3 119873 (10)
It can be written as 119891(119909) = ℎ(119909)120573 where 119909119895
119908119894
and 119887119894
are the input training vector input weights and biases tothe hidden layer respectively 120573
119894
are the output weights thatlink the 119894th hidden node to the output layer and 119892(sdot) is theactivation function of the hidden nodes Training a SLFNis simply finding a least-square solution by using Moore-Penrose generalized inverse
120573 = 119867dagger119879 (11)
where 119867dagger = (1198671015840
119867)minus1
1198671015840 or 1198671015840(1198671198671015840)minus1 depending on the
singularity of1198671015840119867 or1198671198671015840 Assume that1198671015840119867 is not singular
the coefficient 1120576 (120576 is positive regularization coefficient) isadded to the diagonal of1198671015840119867 in the calculation of the outputweights 120573
119894
Hence more stable learning system with bettergeneralization performance can be obtained
The output function of ELM can be written compactly as
119891 (119909) = ℎ (119909)1198671015840
(1
120576+ 119867119867
1015840
)
minus1
119879 (12)
In this ELM kernel implementation the hidden layer featuremappings need not be known to users and Gaussian kernelwas used Best values for positive regularization coefficient(120576) as 1 and Gaussian kernel parameter as 10 were foundempirically after several experiments
4 Experimental Results and Discussions
This section describes the average emotion recognition ratesobtained for speaker-dependent and speaker-independentemotion recognition environments using proposed meth-ods In order to demonstrate the robustness of the pro-posed methods 3 different emotional speech databases wereused Amongst 2 of them were recorded using professionalactorsactresses and 1 of them was recorded using universitystudents The average emotion recognition rates for theoriginal raw and enhanced relative wavelet packet energyand entropy features and for best enhanced features weretabulated in Tables 3 4 and 5 Table 3 shows the resultsfor the BES database 119896NN and ELM kernel classifiers wereused for emotion recognition From the results ELM kernelalways performs better compared to 119896NN classifier in termsof average emotion recognition rates irrespective of differentorders of ldquodbrdquo wavelets Under speaker-dependent experi-mentmaximumaverage emotion recognition rates of 6999and 9898 were obtained with ELM kernel classifier usingthe raw and enhanced relative wavelet packet energy andentropy features respectively Under speaker-independentexperiment maximum average emotion recognition rates of5661 and 9724 were attained with ELM kernel classifierusing the raw and enhanced relative wavelet packet energyand entropy features respectively 119896NN classifier gives onlymaximum average recognition rates of 5914 and 4912under speaker-dependent and speaker-independent experi-ment respectively
The average emotion recognition rates for SAVEEdatabase are tabulated in Table 4 Only audio signals fromSAVEE database were used for emotion recognition experi-ment According to Table 4 ELM kernel has achieved betteraverage emotion recognition of 5833 than 119896NN clas-sifier which gives only 5031 using all the raw relativewavelet packet energy and entropy features under speaker-dependent experiment Similarly maximum emotion recog-nition rates of 3146 and 2875 were obtained underspeaker-independent experiment using ELMkernel and 119896NNclassifier respectively
After GMMbased feature enhancement average emotionrecognition rate was improved to 9760 and 9427 usingELM kernel classifier and 119896NN classifier under speaker-dependent experiment During speaker-independent experi-ment maximum average emotion recognition rates of 7792
8 Mathematical Problems in Engineering
Table2Num
bero
fsele
cted
enhanced
features
usingSW
LDA
Different
orderldquodbrdquo
wavele
ts119875value
BES
SAVEE
SES
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
db3
005ndash0
121
2612
1218
2110
1319
2516
19001ndash0
05
1722
811
1720
710
1624
1316
0001ndash001
1618
78
1417
65
1522
58
000
01ndash0
001
713
57
1313
55
818
56
db6
005ndash0
118
2313
1418
2017
1918
2313
14001ndash0
05
1322
712
1621
1717
1322
712
0001ndash001
1219
710
1319
1110
1219
710
000
01ndash0
001
1413
77
1319
1110
1413
77
db10
005ndash0
122
2212
125
94
420
2312
13001ndash0
05
1717
1110
59
44
1919
1212
0001ndash001
1415
67
59
44
1618
99
000
01ndash0
001
1415
65
59
43
1211
68
db44
005ndash0
125
2714
1514
207
1125
2714
15001ndash0
05
2024
99
1420
710
2024
99
0001ndash001
1515
87
1419
69
1515
87
000
01ndash0
001
1213
45
1318
53
1213
45
Mathematical Problems in Engineering 9
Table 3 Average emotion recognition rates for BES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 6999 9824 9852 9815 9750 9815db6 6855 9565 9639 9731 9667 9713db10 6877 9852 9778 9769 9685 9639db44 6743 9870 9843 9898 9889 9861
kNNdb3 5914 9519 9657 9611 9583 9630db6 5868 8972 8731 9130 9065 9167db10 5793 9704 9657 9657 9546 9528db44 5763 9546 9556 9556 9500 9611
Speaker independentELM kernel
db3 5661 9604 9707 9724 9640 9640db6 5470 9226 9126 9183 9162 9148db10 5208 9212 9413 9337 9300 9293db44 5360 9304 9313 9410 9367 9433
kNNdb3 4912 9175 9332 9201 9279 9390db6 4821 8193 8222 8143 8218 8277db10 4517 9064 8981 8946 9023 9015db44 4687 9169 9015 9057 9035 9199
Table 4 Average emotion recognition rates for SAVEE database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 5563 9635 9677 9521 9583 9604db6 5563 9635 9552 9760 9573 9635db10 5823 9677 9135 9260 9333 9167db44 5833 9604 9552 9563 9583 9635
119896NNdb3 4708 9063 8990 9052 9156 9177db6 4781 9354 9281 9427 9229 9375db10 4656 9323 9396 9333 9260 9417db44 5031 9021 9104 9177 9010 9135
Speaker independentELM kernel
db3 2792 7000 6917 6854 7021 7000db6 3104 6792 7271 7375 7625 7625db10 3104 7792 7688 7688 7688 7667db44 3146 7083 7646 7604 7625 7667
kNNdb3 2875 6396 6250 6250 6313 6438db6 2792 6375 6604 6542 6625 6625db10 2792 6917 6750 6750 6750 6771db44 2750 6417 6250 6271 6167 6250
10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

2 Mathematical Problems in Engineering
energy and entropy features were calculated for each of thedecomposition nodes A total of 120 features were obtainedHigher degree of overlap between the features of differentclasses may degrade the performance of classifiers whichresults in poor recognition of speech emotions To decreasethe intraclass variance and to increase the interclass varianceamong the features GMM based feature enhancement wasproposed which results in improved recognition of speechemotions Both raw and enhanced features were subjected toseveral experiments to validate their effectiveness in speechemotion recognition The rest of this paper is organized asfollows Some of the significant works on speech emotionrecognition are discussed in Section 2 Section 3 presentsthe materials and methods used Experimental results anddiscussions are presented in Section 4 Finally Section 5concludes the paper
2 Previous Works
Several speech features have been successfully applied forspeech emotion recognition and can be mainly classified intofour groups such as continuous features qualitative featuresspectral features and nonlinear Teager energy operator basedfeatures [1 3 4] Various types of classifiers have beenproposed for speech emotion recognition such as hiddenMarkov model (HMM) Gaussian mixture model (GMM)support vector machine (SVM) artificial neural networks(ANN) and 119896-NN [1 3 4] This section describes some ofthe recently published works in the area of multiclass speechemotion recognition Table 1 shows the list of some of therecent works in multiclass speech emotion recognition usingBES and SAVEE databases
Though speech related features are widely used for speechemotion recognition there is a strong correlation between theemotional states and features derived from glottal waveformsGlottal waveform is significantly affected by the emotionalstate and speaking style of an individual [10ndash12] In [10ndash12]researchers have investigated that the glottal waveform wasaffected due to the excessive tension or lack of coordinationin the laryngeal musculature under different emotional statesand the speech produced under stress The classification ofclinical depression using the glottal features was carried outby Moore et al in [13 14] In [15] authors have obtained85 of the correct emotion recognition rate by using theglottal flow spectrum as a possible cue for depression andnear-term suicide risk Iliev and Scordilis have investigatedthe effectiveness of glottal features derived from the glottalairflow signal in recognizing emotions [16] The averageemotion recognition rate of 665 for all six emotions(happiness anger sadness fear surprise and neutral) and99 for four emotions (happiness neutral anger and sad-ness) was achieved He et al have proposed wavelet packetenergy entropy features for emotion recognition from speechand glottal signals with GMM classifier [17] They achievedaverage emotion recognition rates for BES database between51 and 54 In [18] prosodic features spectral featuresglottal flow features and AM-FM features were utilized andtwo-stage feature reductionwas proposed for speech emotionrecognition The overall emotion recognition rate of 8518
for gender-dependent and 8009 for gender-independentwas achieved using SVM classifier
Several feature selectionreduction methods were pro-posed to selectreduce the course of dimensionality of speechfeatures Although all the above works are novel contri-butions to the field of speech emotion recognition it isdifficult to compare them directly since division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulatedor naturalistic speech emotion databases and lack of uni-formity in computation and presentation of the resultsMost of the researchers have commonly used 10-fold crossvalidation and conventional validation (one training set +one testing set) and some of them have tested their meth-ods under speaker-dependent speaker-independent gender-dependent and gender-independent environments In thisregard the proposed methods were validated using three dif-ferent emotional speech databases and emotion recognitionexperiments were also conducted under speaker-dependentand speaker-independent environments
3 Materials and Methods
31 Emotional Speech Databases In this work three differentemotional speech databases were used for emotion recog-nition and to test the robustness of the proposed methodsFirst Berlin emotional speech database (BES)was usedwhichconsists of speech utterances in German [19] 10 professionalactorsactresses were used to simulate 7 emotions (anger 127disgust 45 fear 70 neutral 79 happiness 71 sadness 62and boredom 81) Secondly Surrey audio-visual expressedemotion (SAVEE) database [20] was used and it is an audio-visual emotional database which includes seven emotioncategories of speech utterances (anger 60 disgust 60 fear60 neutral 120 happiness 60 sadness 60 and surprise 60)from four native English male speakers aged from 27 to 31years 3 common 2 emotion-specific and 10 generic sen-tences from 15 TIMIT sentences per emotion were recordedIn this work only audio samples were utilized LastlySahand Emotional Speech database (SES) was used [21] andit was recorded at Artificial Intelligence and InformationAnalysis Lab Department of Electrical Engineering SahandUniversity of Technology IranThis database contains speechutterances of five basic emotions (neutral 240 surprise240 happiness 240 sadness 240 and anger 240) from 10speakers (5 male and 5 female) 10 single words 12 sentencesand 2 passages in Farsi language were recorded which resultsin a total of 120 utterances per emotion Figures 1(a)ndash1(d)show an example of portion of utterance spoken by a speakerin the four different emotions (neutral anger happinessand disgust) It can be observed from the figures that thestructure of the speech signals and its glottal waveformsare considerably different for speech spoken under differentemotional states
32 Features for Speech Emotion Recognition Extraction ofsuitable features for efficiently characterizing different emo-tions is still an important issue in the design of a speech
Mathematical Problems in Engineering 3
Table 1 Some of the significant works on speech emotion recognition
Ref number Database Signals Number of emotions Methods Best result
[49] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Nonlinear dynamic features+ prosodic + spectralfeatures + SVM classifier
8272(females)
8590 (males)
[50] BES Speech signals Neutral fear and anger Nonlinear dynamic features+ neural network
9378
[51] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Modulation spectralfeatures (MSFs) +multiclass SVM
8560
[30] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Combination of spectralexcitation source features +autoassociative neuralnetwork
8216
[27] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Combination ofutterancewise global andlocal prosodic features +SVM classifier
6243
[52] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
LPCCs + formants + GMMclassifier
68
[28] BES Speech signalsAnger boredom fearhappiness sadness andneutral
Discriminative bandwavelet packet powercoefficients (db-WPPC)with Daubechies filter oforder 40 + GMM classifier
7564
[53] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Low level audio descriptorsand high level perceptualdescriptors with linearSVM
877
[54] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
MPEG-7 low level audiodescriptors + SVM withradial basis function kernel
7788
[55] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Mel-frequency cepstralcoefficients + signal energy+ correlation based featureselection + SVMwith radialbasis function kernels
79
[56] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Energy intensity + pitch +standard deviation + jitter +shimmer + 119896NN
7439
[57] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Audio features + LDAfeature reduction + singlecomponent Gaussianclassifier
63
[20] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Pitch + energy + duration +spectral + Gaussianclassifier
592
emotion recognition system Short-term features were widelyused by the researchers called frame-by-frame analysisAll the speech samples were downsampled to 8 kHz Theunvoiced portions between words were removed by seg-menting the downsampled emotional speech signals intononoverlapping frames with a length of 32ms (256 samples)based on the energy of the frames Frames with low energywere discarded and the rest of the frames (voiced portions)
were concatenated and used for feature extraction [17] Thenthe emotional speech signals (only voiced portions) arepassed through a first-order low pass filter to spectrally flattenthe signal and to make it less susceptible to finite precisioneffects later in the signal processing [22] The first-orderpreemphasis filter is defined as
119867(119911) = 1 minus 119886 lowast 119911minus1
09 le 119886 le 10 (1)
4 Mathematical Problems in Engineering
0 001 002 003 004 005 006 007 008
00204
Neutral-speech signal
Time (ms)
0 001 002 003 004 005 006 007 008
005
115
Neutral-glottal signal
Time (ms)
minus04
minus02
minus1
minus05
(a)
0 001 002 003 004 005 006
00102
Anger-speech signal
Time (ms)
0 001 002 003 004 005 006
0020406
Anger-glottal signal
Time (ms)
minus04minus02
minus02
minus01
minus03
(b)
0 001 002 003 004 005 006
00204
Happiness-speech signal
Time (ms)
0 001 002 003 004 005 006
00204
Happiness-glottal signal
Time (ms)
minus04
minus02
minus04
minus02
(c)
0 001 002 003 004 005 006
0020406
Disgust-speech signal
Time (ms)
0 001 002 003 004 005 006
005
1Disgust-glottal signal
Time (ms)
minus04minus02
minus08minus06
minus05
(d)
Figure 1 ((a)ndash(d)) Emotional speech signals and its glottal waveforms (BES database)
The commonly used 119886 value is 1516 = 09375 or 095 [22]In this work the value of 119886 is set equal to 09375 Extractionof glottal flow signal from speech signal is a challengingtask In this work glottal waveforms were estimated basedon the inverse filtering and linear predictive analysis fromthe preemphasized speech waveforms [5 6 9] Wavelet orwavelet packet transform has the ability to analyze anynonstationary signals in both time and frequency domainsimultaneously The hierarchical wavelet packet transformdecomposes the original emotional speech signalsglottalwaveforms into subsequent subbands InWP decompositionboth low and high frequency subbands are used to generatethe next level subbands which results in finer frequencybands Energy of the wavelet packet nodes is more robustin representing the original signal than using the waveletpacket coefficients directly Shannon entropy is a robustdescription of uncertainty in the whole signal duration[23ndash26] The preemphasized emotional speech signals andglottal waveforms were segmented into 32ms frames with50 overlap Each frame was decomposed into 4 levelsusing discrete wavelet packet transform and relative waveletpacket energy and entropy features were derived for each of
the decomposition nodes as given in (4) and (7) Consider thefollowing
EGY119895119896
= log10
(sum10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
119871
2
) (2)
EGYtot = sumEGY119895119896
(3)
Relative wavelet packet energy RWPEGY =EGY119895119896
EGYtot (4)
EPY119895119896
= minussum10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
2
log10
10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
2
(5)
EPYtot = sumEPY119895119896
(6)
Relative wavelet packet entropy RWPEPY =EPY119895119896
EPYtot (7)
where 119895 = 1 2 3 119898 119896 = 0 1 2 2119898
minus 1 119898 isthe number of decomposition levels and 119871 is the lengthof wavelet packet coefficients at each node (119895 119896) In this
Mathematical Problems in Engineering 5
work Daubechies wavelets with 4 different orders (db3 db6db10 and db44) were used since Daubechies wavelets arefrequently used in speech emotion recognition and providebetter results [1 17 27 28] After obtaining the relativewaveletpacket energy and entropy based features for each frame theywere averaged over all frames and used for analysis Four-level wavelet decomposition gives 30 wavelet packet nodesand features were extracted from all the nodes which yield60 features (30 relative energy features + 30 relative entropyfeatures) Similarly the same features were extracted fromemotional glottal signals Finally a total of 120 features wereobtained
33 Feature Enhancement Using Gaussian Mixture Model Inany pattern recognition applications escalating the interclassvariance and diminishing the intraclass variance of theattributes or features are the fundamental issues to improvethe classification or recognition accuracy [24 25 29] In theliterature several research works can be found to escalatethe discriminating ability of the extracted features [24 2529] GMM has been successfully applied in various patternrecognition applications particularly in speech and imageprocessing applications [17 28ndash36] however its capabilityof escalating the discriminative ability of the features orattributes is not being extensively explored Different appli-cations of GMM motivate us to suggest GMM based featureenhancement [17 28ndash36] High intraclass variance and lowinterclass variance among the features may degrade theperformance of classifiers which results in poor emotionrecognition rates To decrease the intraclass variance and toincrease the interclass variance among the features GMMbased clustering was suggested in this work to enrich thediscriminative ability of the relative wavelet packet energyand entropy features GMM model is a probabilistic modeland its application to labelling is based on the assumptionthat all the data points are generated from a finite mixture ofGaussian mixture distributions In a model-based approachcertain models are used for clustering and attempting tooptimize the fit between the data andmodel Each cluster canbe mathematically represented by a Gaussian (parametric)distribution The entire dataset 119911 is modeled by a weightedsum of 119872 numbers of mixtures of Gaussian componentdensities and is given by the equation
119901 (119911119894
| 120579) =
119872
sum
119896=1
120588119896
119891 (119911119894
| 120579119896
) (8)
where 119911 is the 119873-dimensional continuous valued relativewavelet packet energy and entropy features 120588
119896
119896 = 1 2 3
119872 are the mixture weights and 119891(119911119894
| 120579119896
) 120579119896
=
(120583119896
Σ119896
) 119894 = 1 2 3 119872 are the component Gaussiandensities Each component density is an 119873-variate Gaussianfunction of the form
119891 (119911119894
| 120579119896
) =1
(2120587)1198992
1003816100381610038161003816Σ119894100381610038161003816100381612
sdot exp [minus12(119911 minus 120583
119894
)119879
Σminus1
119894
(119911 minus 120583119894
)]
(9)
Relative wavelet packet energy and entropy features
(120 features)
Calculate the component means (cluster centers) using GMM
Calculate the ratios of means of features to their centers and
multiply these ratios with each respective feature
Enhanced relative waveletpacket energy and entropy
features
Figure 2 Proposed GMM based feature enhancement
where 120583119894
is the mean vector and Σ119894
is the covariance matrixUsing the linear combination of mean vectors covariancematrices and mixture weights overall probability densityfunction is estimated [17 28ndash36] Gaussian mixture modeluses an iterative expectation maximization (EM) algorithmthat converges to a local optimum and assigns posteriorprobabilities to each component density with respect to eachobservation The posterior probabilities for each point indi-cate that each data point has some probability of belonging toeach cluster [17 28ndash36] The working of GMM based featureenhancement is summarized (Figure 2) as follows firstly thecomponent means (cluster centers) of each feature belongingto dataset using GMM based clustering method was foundNext the ratios of means of features to their centers werecalculated Finally these ratios were multiplied with eachrespective feature
After applying GMM clustering based feature weightingmethod the raw features (RF) were known as enhancedfeatures (EF)
The class distribution plots of raw relative wavelet packetenergy and entropy features were shown in Figures 3(a) 3(c)3(e) and 3(g) for different orders of Daubechies wavelets(ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo) From the figures it canbe seen that there is a higher degree of overlap amongthe raw relative wavelet packet energy and entropy featureswhich results in the poor performance of the speech emotionrecognition system The class distribution plots of enhancedrelative wavelet packet energy and entropy features wereshown in Figures 3(b) 3(d) 3(f) and 3(h) From the figuresit can be observed that the higher degree of overlap can bediminished which in turn improves the performance of thespeech emotion recognition system
34 Feature Reduction Using Stepwise Linear DiscriminantAnalysis Curse of dimensionality is a big issue in all patternrecognition problems Irrelevant and redundant features maydegrade the performance of the classifiers Feature selec-tionreduction was used for selecting the subset of relevantfeatures from a large number of features [24 29 37] Severalfeature selectionreduction techniques have been proposedto find most discriminating features for improving the per-formance of the speech emotion recognition system [18 2028 38ndash43] In this work we propose the use of stepwiselinear discriminant analysis (SWLDA) since LDA is a lineartechnique which relies on the mixture model containing
6 Mathematical Problems in Engineering
009 011 013 015 017
0059006100630065
00670055
0060065
0070075
Feature 7Feature 77
Feat
ure 1
08
(a)
02 06 102061
005
1
Feature 7Feature 77
Feat
ure 1
08
minus1minus06
minus02
minus1minus06
minus02
minus1
minus05
(b)
009 011 013 015 017
0120124012801320136
014023
0235024
0245025
0255026
0265
Feature 7Feature 67
Feat
ure 9
4
(c)
02 06 102061
0206
1
Feature 7Feature 67
Feat
ure 9
4
minus1minus06
minus02
minus1minus06
minus02
minus1
minus06
minus02
(d)
009 011 013 015 017
004006
00801
006008
01012014016018
Feature 7Feature 15
Feat
ure 4
3
(e)
02 06 102061
0206
1
Feat
ure 4
3
Feature 15 Feature 7minus1
minus06minus02
minus1minus06
minus02
minus1
minus06
minus02
(f)
009 011 013 015 017
00601
014018046047048049
05051052
Feature 7Feature 41
Feat
ure 9
2
AngerBoredomDisgustFear
HappinessSadnessNeutral
(g)
02 06 102061
0206
1
Feature 7
Feature 41
Feat
ure 9
2
minus1 minus1minus06
minus06
minus02minus02
minus1
minus06
minus02
AngerBoredomDisgustFear
HappinessSadnessNeutral
(h)
Figure 3 ((a) (c) (e) and (g)) Class distribution plots of raw features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo ((b) (d) (f) and (h)) Classdistribution plots of enhanced features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo
the correct number of components and has limited flexibilitywhen applied to more complex datasets [37 44] StepwiseLDA uses both forward and backward strategies In theforward approach the attributes that significantly contributeto the discrimination between the groups will be determinedThis process stops when there is no attribute to add in
the model In the backward approach the attributes (lessrelevant features) which do not significantly degrade thediscrimination between groups will be removed 119865-statisticor 119901 value is generally used as predetermined criterion toselectremove the attributes In this work the selection ofthe best features is controlled by four different combinations
Mathematical Problems in Engineering 7
of (005 and 01 SET1 001 and 005 SET2 001 and 0001SET3 0001 and 00001 SET4)119901 values In a feature entry stepthe features that provide the most significant performanceimprovement will be entered in the feature model if the 119901value lt 005 In the feature removal step attributes whichdo not significantly affect the performance of the classifierswill be removed if the 119901 value gt 01 SWLDA was applied tothe enhanced feature set to select best features and to removeirrelevant features
The details of the number of selected enhanced featuresfor every combination were tabulated in Table 2 FromTable 2 it can be seen that the enhanced relative energy andentropy features of the speech signals were more significantthan the glottal signals Approximately between 32 and82 of insignificant enhanced features were removed in allthe combination of 119901 values (005 and 01 001 and 005001 and 0001 and 0001 and 00001) and speaker-dependentand speaker-independent emotion recognition experimentswere carried out using these significant enhanced featuresThe results were compared with the original raw relativewavelet packet energy and entropy features and some of thesignificant works in the literature
35 Classifiers
351 119896-Nearest Neighbor Classifier 119896NN classifier is a type ofinstance-based classifiers and predicts the correct class labelfor the new test vector by relating the unknown test vector toknown training vectors according to some distancesimilarityfunction [25] Euclidean distance function was used andappropriate 119896-value was found by searching a value between1 and 20
352 Extreme Learning Machine A new learning algorithmfor the single hidden layer feedforward networks (SLFNs)called ELM was proposed by Huang et al [45ndash48] It hasbeenwidely used in various applications to overcome the slowtraining speed and overfitting problems of the conventionalneural network learning algorithms [45ndash48] The brief ideaof ELM is as follows [45ndash48]
For the given 119873 training samples the output of a SLFNnetwork with 119871 hidden nodes can be expressed as thefollowing
119891119871
(119909119895
) =
119871
sum
119894
120573119894
119892 (119908119894
sdot 119909119895
+ 119887119894
) 119895 = 1 2 3 119873 (10)
It can be written as 119891(119909) = ℎ(119909)120573 where 119909119895
119908119894
and 119887119894
are the input training vector input weights and biases tothe hidden layer respectively 120573
119894
are the output weights thatlink the 119894th hidden node to the output layer and 119892(sdot) is theactivation function of the hidden nodes Training a SLFNis simply finding a least-square solution by using Moore-Penrose generalized inverse
120573 = 119867dagger119879 (11)
where 119867dagger = (1198671015840
119867)minus1
1198671015840 or 1198671015840(1198671198671015840)minus1 depending on the
singularity of1198671015840119867 or1198671198671015840 Assume that1198671015840119867 is not singular
the coefficient 1120576 (120576 is positive regularization coefficient) isadded to the diagonal of1198671015840119867 in the calculation of the outputweights 120573
119894
Hence more stable learning system with bettergeneralization performance can be obtained
The output function of ELM can be written compactly as
119891 (119909) = ℎ (119909)1198671015840
(1
120576+ 119867119867
1015840
)
minus1
119879 (12)
In this ELM kernel implementation the hidden layer featuremappings need not be known to users and Gaussian kernelwas used Best values for positive regularization coefficient(120576) as 1 and Gaussian kernel parameter as 10 were foundempirically after several experiments
4 Experimental Results and Discussions
This section describes the average emotion recognition ratesobtained for speaker-dependent and speaker-independentemotion recognition environments using proposed meth-ods In order to demonstrate the robustness of the pro-posed methods 3 different emotional speech databases wereused Amongst 2 of them were recorded using professionalactorsactresses and 1 of them was recorded using universitystudents The average emotion recognition rates for theoriginal raw and enhanced relative wavelet packet energyand entropy features and for best enhanced features weretabulated in Tables 3 4 and 5 Table 3 shows the resultsfor the BES database 119896NN and ELM kernel classifiers wereused for emotion recognition From the results ELM kernelalways performs better compared to 119896NN classifier in termsof average emotion recognition rates irrespective of differentorders of ldquodbrdquo wavelets Under speaker-dependent experi-mentmaximumaverage emotion recognition rates of 6999and 9898 were obtained with ELM kernel classifier usingthe raw and enhanced relative wavelet packet energy andentropy features respectively Under speaker-independentexperiment maximum average emotion recognition rates of5661 and 9724 were attained with ELM kernel classifierusing the raw and enhanced relative wavelet packet energyand entropy features respectively 119896NN classifier gives onlymaximum average recognition rates of 5914 and 4912under speaker-dependent and speaker-independent experi-ment respectively
The average emotion recognition rates for SAVEEdatabase are tabulated in Table 4 Only audio signals fromSAVEE database were used for emotion recognition experi-ment According to Table 4 ELM kernel has achieved betteraverage emotion recognition of 5833 than 119896NN clas-sifier which gives only 5031 using all the raw relativewavelet packet energy and entropy features under speaker-dependent experiment Similarly maximum emotion recog-nition rates of 3146 and 2875 were obtained underspeaker-independent experiment using ELMkernel and 119896NNclassifier respectively
After GMMbased feature enhancement average emotionrecognition rate was improved to 9760 and 9427 usingELM kernel classifier and 119896NN classifier under speaker-dependent experiment During speaker-independent experi-ment maximum average emotion recognition rates of 7792
8 Mathematical Problems in Engineering
Table2Num
bero
fsele
cted
enhanced
features
usingSW
LDA
Different
orderldquodbrdquo
wavele
ts119875value
BES
SAVEE
SES
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
db3
005ndash0
121
2612
1218
2110
1319
2516
19001ndash0
05
1722
811
1720
710
1624
1316
0001ndash001
1618
78
1417
65
1522
58
000
01ndash0
001
713
57
1313
55
818
56
db6
005ndash0
118
2313
1418
2017
1918
2313
14001ndash0
05
1322
712
1621
1717
1322
712
0001ndash001
1219
710
1319
1110
1219
710
000
01ndash0
001
1413
77
1319
1110
1413
77
db10
005ndash0
122
2212
125
94
420
2312
13001ndash0
05
1717
1110
59
44
1919
1212
0001ndash001
1415
67
59
44
1618
99
000
01ndash0
001
1415
65
59
43
1211
68
db44
005ndash0
125
2714
1514
207
1125
2714
15001ndash0
05
2024
99
1420
710
2024
99
0001ndash001
1515
87
1419
69
1515
87
000
01ndash0
001
1213
45
1318
53
1213
45
Mathematical Problems in Engineering 9
Table 3 Average emotion recognition rates for BES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 6999 9824 9852 9815 9750 9815db6 6855 9565 9639 9731 9667 9713db10 6877 9852 9778 9769 9685 9639db44 6743 9870 9843 9898 9889 9861
kNNdb3 5914 9519 9657 9611 9583 9630db6 5868 8972 8731 9130 9065 9167db10 5793 9704 9657 9657 9546 9528db44 5763 9546 9556 9556 9500 9611
Speaker independentELM kernel
db3 5661 9604 9707 9724 9640 9640db6 5470 9226 9126 9183 9162 9148db10 5208 9212 9413 9337 9300 9293db44 5360 9304 9313 9410 9367 9433
kNNdb3 4912 9175 9332 9201 9279 9390db6 4821 8193 8222 8143 8218 8277db10 4517 9064 8981 8946 9023 9015db44 4687 9169 9015 9057 9035 9199
Table 4 Average emotion recognition rates for SAVEE database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 5563 9635 9677 9521 9583 9604db6 5563 9635 9552 9760 9573 9635db10 5823 9677 9135 9260 9333 9167db44 5833 9604 9552 9563 9583 9635
119896NNdb3 4708 9063 8990 9052 9156 9177db6 4781 9354 9281 9427 9229 9375db10 4656 9323 9396 9333 9260 9417db44 5031 9021 9104 9177 9010 9135
Speaker independentELM kernel
db3 2792 7000 6917 6854 7021 7000db6 3104 6792 7271 7375 7625 7625db10 3104 7792 7688 7688 7688 7667db44 3146 7083 7646 7604 7625 7667
kNNdb3 2875 6396 6250 6250 6313 6438db6 2792 6375 6604 6542 6625 6625db10 2792 6917 6750 6750 6750 6771db44 2750 6417 6250 6271 6167 6250
10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of
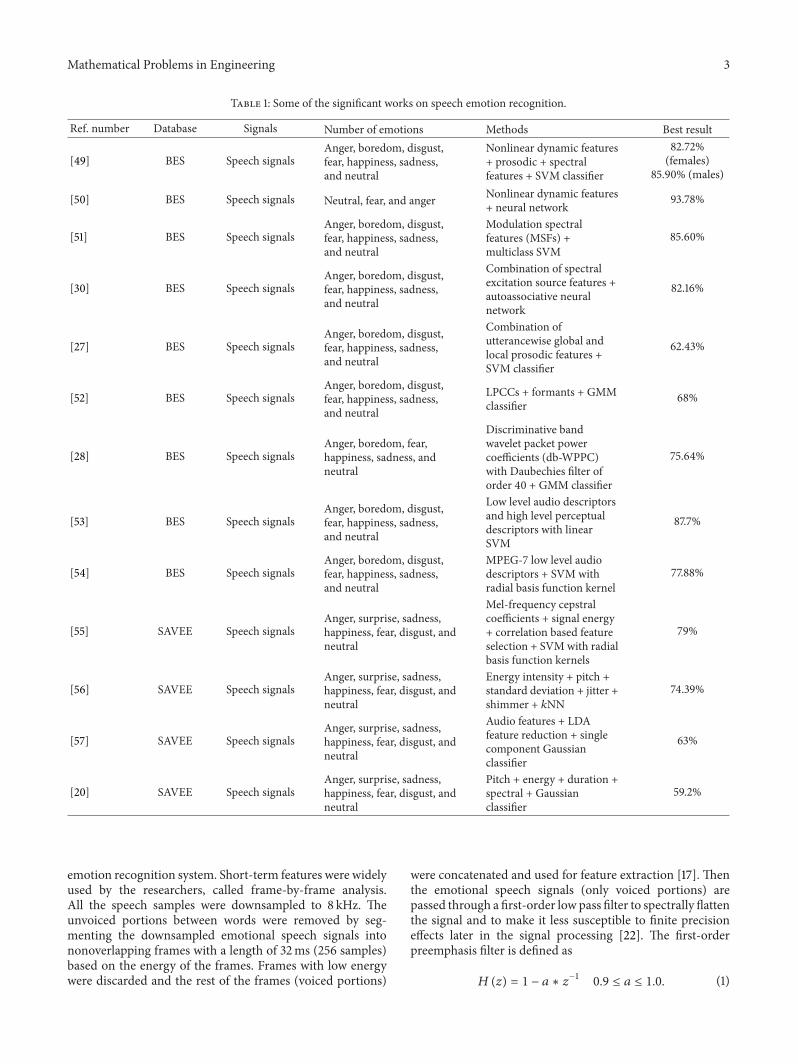
Mathematical Problems in Engineering 3
Table 1 Some of the significant works on speech emotion recognition
Ref number Database Signals Number of emotions Methods Best result
[49] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Nonlinear dynamic features+ prosodic + spectralfeatures + SVM classifier
8272(females)
8590 (males)
[50] BES Speech signals Neutral fear and anger Nonlinear dynamic features+ neural network
9378
[51] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Modulation spectralfeatures (MSFs) +multiclass SVM
8560
[30] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Combination of spectralexcitation source features +autoassociative neuralnetwork
8216
[27] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Combination ofutterancewise global andlocal prosodic features +SVM classifier
6243
[52] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
LPCCs + formants + GMMclassifier
68
[28] BES Speech signalsAnger boredom fearhappiness sadness andneutral
Discriminative bandwavelet packet powercoefficients (db-WPPC)with Daubechies filter oforder 40 + GMM classifier
7564
[53] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
Low level audio descriptorsand high level perceptualdescriptors with linearSVM
877
[54] BES Speech signalsAnger boredom disgustfear happiness sadnessand neutral
MPEG-7 low level audiodescriptors + SVM withradial basis function kernel
7788
[55] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Mel-frequency cepstralcoefficients + signal energy+ correlation based featureselection + SVMwith radialbasis function kernels
79
[56] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Energy intensity + pitch +standard deviation + jitter +shimmer + 119896NN
7439
[57] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Audio features + LDAfeature reduction + singlecomponent Gaussianclassifier
63
[20] SAVEE Speech signalsAnger surprise sadnesshappiness fear disgust andneutral
Pitch + energy + duration +spectral + Gaussianclassifier
592
emotion recognition system Short-term features were widelyused by the researchers called frame-by-frame analysisAll the speech samples were downsampled to 8 kHz Theunvoiced portions between words were removed by seg-menting the downsampled emotional speech signals intononoverlapping frames with a length of 32ms (256 samples)based on the energy of the frames Frames with low energywere discarded and the rest of the frames (voiced portions)
were concatenated and used for feature extraction [17] Thenthe emotional speech signals (only voiced portions) arepassed through a first-order low pass filter to spectrally flattenthe signal and to make it less susceptible to finite precisioneffects later in the signal processing [22] The first-orderpreemphasis filter is defined as
119867(119911) = 1 minus 119886 lowast 119911minus1
09 le 119886 le 10 (1)
4 Mathematical Problems in Engineering
0 001 002 003 004 005 006 007 008
00204
Neutral-speech signal
Time (ms)
0 001 002 003 004 005 006 007 008
005
115
Neutral-glottal signal
Time (ms)
minus04
minus02
minus1
minus05
(a)
0 001 002 003 004 005 006
00102
Anger-speech signal
Time (ms)
0 001 002 003 004 005 006
0020406
Anger-glottal signal
Time (ms)
minus04minus02
minus02
minus01
minus03
(b)
0 001 002 003 004 005 006
00204
Happiness-speech signal
Time (ms)
0 001 002 003 004 005 006
00204
Happiness-glottal signal
Time (ms)
minus04
minus02
minus04
minus02
(c)
0 001 002 003 004 005 006
0020406
Disgust-speech signal
Time (ms)
0 001 002 003 004 005 006
005
1Disgust-glottal signal
Time (ms)
minus04minus02
minus08minus06
minus05
(d)
Figure 1 ((a)ndash(d)) Emotional speech signals and its glottal waveforms (BES database)
The commonly used 119886 value is 1516 = 09375 or 095 [22]In this work the value of 119886 is set equal to 09375 Extractionof glottal flow signal from speech signal is a challengingtask In this work glottal waveforms were estimated basedon the inverse filtering and linear predictive analysis fromthe preemphasized speech waveforms [5 6 9] Wavelet orwavelet packet transform has the ability to analyze anynonstationary signals in both time and frequency domainsimultaneously The hierarchical wavelet packet transformdecomposes the original emotional speech signalsglottalwaveforms into subsequent subbands InWP decompositionboth low and high frequency subbands are used to generatethe next level subbands which results in finer frequencybands Energy of the wavelet packet nodes is more robustin representing the original signal than using the waveletpacket coefficients directly Shannon entropy is a robustdescription of uncertainty in the whole signal duration[23ndash26] The preemphasized emotional speech signals andglottal waveforms were segmented into 32ms frames with50 overlap Each frame was decomposed into 4 levelsusing discrete wavelet packet transform and relative waveletpacket energy and entropy features were derived for each of
the decomposition nodes as given in (4) and (7) Consider thefollowing
EGY119895119896
= log10
(sum10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
119871
2
) (2)
EGYtot = sumEGY119895119896
(3)
Relative wavelet packet energy RWPEGY =EGY119895119896
EGYtot (4)
EPY119895119896
= minussum10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
2
log10
10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
2
(5)
EPYtot = sumEPY119895119896
(6)
Relative wavelet packet entropy RWPEPY =EPY119895119896
EPYtot (7)
where 119895 = 1 2 3 119898 119896 = 0 1 2 2119898
minus 1 119898 isthe number of decomposition levels and 119871 is the lengthof wavelet packet coefficients at each node (119895 119896) In this
Mathematical Problems in Engineering 5
work Daubechies wavelets with 4 different orders (db3 db6db10 and db44) were used since Daubechies wavelets arefrequently used in speech emotion recognition and providebetter results [1 17 27 28] After obtaining the relativewaveletpacket energy and entropy based features for each frame theywere averaged over all frames and used for analysis Four-level wavelet decomposition gives 30 wavelet packet nodesand features were extracted from all the nodes which yield60 features (30 relative energy features + 30 relative entropyfeatures) Similarly the same features were extracted fromemotional glottal signals Finally a total of 120 features wereobtained
33 Feature Enhancement Using Gaussian Mixture Model Inany pattern recognition applications escalating the interclassvariance and diminishing the intraclass variance of theattributes or features are the fundamental issues to improvethe classification or recognition accuracy [24 25 29] In theliterature several research works can be found to escalatethe discriminating ability of the extracted features [24 2529] GMM has been successfully applied in various patternrecognition applications particularly in speech and imageprocessing applications [17 28ndash36] however its capabilityof escalating the discriminative ability of the features orattributes is not being extensively explored Different appli-cations of GMM motivate us to suggest GMM based featureenhancement [17 28ndash36] High intraclass variance and lowinterclass variance among the features may degrade theperformance of classifiers which results in poor emotionrecognition rates To decrease the intraclass variance and toincrease the interclass variance among the features GMMbased clustering was suggested in this work to enrich thediscriminative ability of the relative wavelet packet energyand entropy features GMM model is a probabilistic modeland its application to labelling is based on the assumptionthat all the data points are generated from a finite mixture ofGaussian mixture distributions In a model-based approachcertain models are used for clustering and attempting tooptimize the fit between the data andmodel Each cluster canbe mathematically represented by a Gaussian (parametric)distribution The entire dataset 119911 is modeled by a weightedsum of 119872 numbers of mixtures of Gaussian componentdensities and is given by the equation
119901 (119911119894
| 120579) =
119872
sum
119896=1
120588119896
119891 (119911119894
| 120579119896
) (8)
where 119911 is the 119873-dimensional continuous valued relativewavelet packet energy and entropy features 120588
119896
119896 = 1 2 3
119872 are the mixture weights and 119891(119911119894
| 120579119896
) 120579119896
=
(120583119896
Σ119896
) 119894 = 1 2 3 119872 are the component Gaussiandensities Each component density is an 119873-variate Gaussianfunction of the form
119891 (119911119894
| 120579119896
) =1
(2120587)1198992
1003816100381610038161003816Σ119894100381610038161003816100381612
sdot exp [minus12(119911 minus 120583
119894
)119879
Σminus1
119894
(119911 minus 120583119894
)]
(9)
Relative wavelet packet energy and entropy features
(120 features)
Calculate the component means (cluster centers) using GMM
Calculate the ratios of means of features to their centers and
multiply these ratios with each respective feature
Enhanced relative waveletpacket energy and entropy
features
Figure 2 Proposed GMM based feature enhancement
where 120583119894
is the mean vector and Σ119894
is the covariance matrixUsing the linear combination of mean vectors covariancematrices and mixture weights overall probability densityfunction is estimated [17 28ndash36] Gaussian mixture modeluses an iterative expectation maximization (EM) algorithmthat converges to a local optimum and assigns posteriorprobabilities to each component density with respect to eachobservation The posterior probabilities for each point indi-cate that each data point has some probability of belonging toeach cluster [17 28ndash36] The working of GMM based featureenhancement is summarized (Figure 2) as follows firstly thecomponent means (cluster centers) of each feature belongingto dataset using GMM based clustering method was foundNext the ratios of means of features to their centers werecalculated Finally these ratios were multiplied with eachrespective feature
After applying GMM clustering based feature weightingmethod the raw features (RF) were known as enhancedfeatures (EF)
The class distribution plots of raw relative wavelet packetenergy and entropy features were shown in Figures 3(a) 3(c)3(e) and 3(g) for different orders of Daubechies wavelets(ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo) From the figures it canbe seen that there is a higher degree of overlap amongthe raw relative wavelet packet energy and entropy featureswhich results in the poor performance of the speech emotionrecognition system The class distribution plots of enhancedrelative wavelet packet energy and entropy features wereshown in Figures 3(b) 3(d) 3(f) and 3(h) From the figuresit can be observed that the higher degree of overlap can bediminished which in turn improves the performance of thespeech emotion recognition system
34 Feature Reduction Using Stepwise Linear DiscriminantAnalysis Curse of dimensionality is a big issue in all patternrecognition problems Irrelevant and redundant features maydegrade the performance of the classifiers Feature selec-tionreduction was used for selecting the subset of relevantfeatures from a large number of features [24 29 37] Severalfeature selectionreduction techniques have been proposedto find most discriminating features for improving the per-formance of the speech emotion recognition system [18 2028 38ndash43] In this work we propose the use of stepwiselinear discriminant analysis (SWLDA) since LDA is a lineartechnique which relies on the mixture model containing
6 Mathematical Problems in Engineering
009 011 013 015 017
0059006100630065
00670055
0060065
0070075
Feature 7Feature 77
Feat
ure 1
08
(a)
02 06 102061
005
1
Feature 7Feature 77
Feat
ure 1
08
minus1minus06
minus02
minus1minus06
minus02
minus1
minus05
(b)
009 011 013 015 017
0120124012801320136
014023
0235024
0245025
0255026
0265
Feature 7Feature 67
Feat
ure 9
4
(c)
02 06 102061
0206
1
Feature 7Feature 67
Feat
ure 9
4
minus1minus06
minus02
minus1minus06
minus02
minus1
minus06
minus02
(d)
009 011 013 015 017
004006
00801
006008
01012014016018
Feature 7Feature 15
Feat
ure 4
3
(e)
02 06 102061
0206
1
Feat
ure 4
3
Feature 15 Feature 7minus1
minus06minus02
minus1minus06
minus02
minus1
minus06
minus02
(f)
009 011 013 015 017
00601
014018046047048049
05051052
Feature 7Feature 41
Feat
ure 9
2
AngerBoredomDisgustFear
HappinessSadnessNeutral
(g)
02 06 102061
0206
1
Feature 7
Feature 41
Feat
ure 9
2
minus1 minus1minus06
minus06
minus02minus02
minus1
minus06
minus02
AngerBoredomDisgustFear
HappinessSadnessNeutral
(h)
Figure 3 ((a) (c) (e) and (g)) Class distribution plots of raw features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo ((b) (d) (f) and (h)) Classdistribution plots of enhanced features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo
the correct number of components and has limited flexibilitywhen applied to more complex datasets [37 44] StepwiseLDA uses both forward and backward strategies In theforward approach the attributes that significantly contributeto the discrimination between the groups will be determinedThis process stops when there is no attribute to add in
the model In the backward approach the attributes (lessrelevant features) which do not significantly degrade thediscrimination between groups will be removed 119865-statisticor 119901 value is generally used as predetermined criterion toselectremove the attributes In this work the selection ofthe best features is controlled by four different combinations
Mathematical Problems in Engineering 7
of (005 and 01 SET1 001 and 005 SET2 001 and 0001SET3 0001 and 00001 SET4)119901 values In a feature entry stepthe features that provide the most significant performanceimprovement will be entered in the feature model if the 119901value lt 005 In the feature removal step attributes whichdo not significantly affect the performance of the classifierswill be removed if the 119901 value gt 01 SWLDA was applied tothe enhanced feature set to select best features and to removeirrelevant features
The details of the number of selected enhanced featuresfor every combination were tabulated in Table 2 FromTable 2 it can be seen that the enhanced relative energy andentropy features of the speech signals were more significantthan the glottal signals Approximately between 32 and82 of insignificant enhanced features were removed in allthe combination of 119901 values (005 and 01 001 and 005001 and 0001 and 0001 and 00001) and speaker-dependentand speaker-independent emotion recognition experimentswere carried out using these significant enhanced featuresThe results were compared with the original raw relativewavelet packet energy and entropy features and some of thesignificant works in the literature
35 Classifiers
351 119896-Nearest Neighbor Classifier 119896NN classifier is a type ofinstance-based classifiers and predicts the correct class labelfor the new test vector by relating the unknown test vector toknown training vectors according to some distancesimilarityfunction [25] Euclidean distance function was used andappropriate 119896-value was found by searching a value between1 and 20
352 Extreme Learning Machine A new learning algorithmfor the single hidden layer feedforward networks (SLFNs)called ELM was proposed by Huang et al [45ndash48] It hasbeenwidely used in various applications to overcome the slowtraining speed and overfitting problems of the conventionalneural network learning algorithms [45ndash48] The brief ideaof ELM is as follows [45ndash48]
For the given 119873 training samples the output of a SLFNnetwork with 119871 hidden nodes can be expressed as thefollowing
119891119871
(119909119895
) =
119871
sum
119894
120573119894
119892 (119908119894
sdot 119909119895
+ 119887119894
) 119895 = 1 2 3 119873 (10)
It can be written as 119891(119909) = ℎ(119909)120573 where 119909119895
119908119894
and 119887119894
are the input training vector input weights and biases tothe hidden layer respectively 120573
119894
are the output weights thatlink the 119894th hidden node to the output layer and 119892(sdot) is theactivation function of the hidden nodes Training a SLFNis simply finding a least-square solution by using Moore-Penrose generalized inverse
120573 = 119867dagger119879 (11)
where 119867dagger = (1198671015840
119867)minus1
1198671015840 or 1198671015840(1198671198671015840)minus1 depending on the
singularity of1198671015840119867 or1198671198671015840 Assume that1198671015840119867 is not singular
the coefficient 1120576 (120576 is positive regularization coefficient) isadded to the diagonal of1198671015840119867 in the calculation of the outputweights 120573
119894
Hence more stable learning system with bettergeneralization performance can be obtained
The output function of ELM can be written compactly as
119891 (119909) = ℎ (119909)1198671015840
(1
120576+ 119867119867
1015840
)
minus1
119879 (12)
In this ELM kernel implementation the hidden layer featuremappings need not be known to users and Gaussian kernelwas used Best values for positive regularization coefficient(120576) as 1 and Gaussian kernel parameter as 10 were foundempirically after several experiments
4 Experimental Results and Discussions
This section describes the average emotion recognition ratesobtained for speaker-dependent and speaker-independentemotion recognition environments using proposed meth-ods In order to demonstrate the robustness of the pro-posed methods 3 different emotional speech databases wereused Amongst 2 of them were recorded using professionalactorsactresses and 1 of them was recorded using universitystudents The average emotion recognition rates for theoriginal raw and enhanced relative wavelet packet energyand entropy features and for best enhanced features weretabulated in Tables 3 4 and 5 Table 3 shows the resultsfor the BES database 119896NN and ELM kernel classifiers wereused for emotion recognition From the results ELM kernelalways performs better compared to 119896NN classifier in termsof average emotion recognition rates irrespective of differentorders of ldquodbrdquo wavelets Under speaker-dependent experi-mentmaximumaverage emotion recognition rates of 6999and 9898 were obtained with ELM kernel classifier usingthe raw and enhanced relative wavelet packet energy andentropy features respectively Under speaker-independentexperiment maximum average emotion recognition rates of5661 and 9724 were attained with ELM kernel classifierusing the raw and enhanced relative wavelet packet energyand entropy features respectively 119896NN classifier gives onlymaximum average recognition rates of 5914 and 4912under speaker-dependent and speaker-independent experi-ment respectively
The average emotion recognition rates for SAVEEdatabase are tabulated in Table 4 Only audio signals fromSAVEE database were used for emotion recognition experi-ment According to Table 4 ELM kernel has achieved betteraverage emotion recognition of 5833 than 119896NN clas-sifier which gives only 5031 using all the raw relativewavelet packet energy and entropy features under speaker-dependent experiment Similarly maximum emotion recog-nition rates of 3146 and 2875 were obtained underspeaker-independent experiment using ELMkernel and 119896NNclassifier respectively
After GMMbased feature enhancement average emotionrecognition rate was improved to 9760 and 9427 usingELM kernel classifier and 119896NN classifier under speaker-dependent experiment During speaker-independent experi-ment maximum average emotion recognition rates of 7792
8 Mathematical Problems in Engineering
Table2Num
bero
fsele
cted
enhanced
features
usingSW
LDA
Different
orderldquodbrdquo
wavele
ts119875value
BES
SAVEE
SES
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
db3
005ndash0
121
2612
1218
2110
1319
2516
19001ndash0
05
1722
811
1720
710
1624
1316
0001ndash001
1618
78
1417
65
1522
58
000
01ndash0
001
713
57
1313
55
818
56
db6
005ndash0
118
2313
1418
2017
1918
2313
14001ndash0
05
1322
712
1621
1717
1322
712
0001ndash001
1219
710
1319
1110
1219
710
000
01ndash0
001
1413
77
1319
1110
1413
77
db10
005ndash0
122
2212
125
94
420
2312
13001ndash0
05
1717
1110
59
44
1919
1212
0001ndash001
1415
67
59
44
1618
99
000
01ndash0
001
1415
65
59
43
1211
68
db44
005ndash0
125
2714
1514
207
1125
2714
15001ndash0
05
2024
99
1420
710
2024
99
0001ndash001
1515
87
1419
69
1515
87
000
01ndash0
001
1213
45
1318
53
1213
45
Mathematical Problems in Engineering 9
Table 3 Average emotion recognition rates for BES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 6999 9824 9852 9815 9750 9815db6 6855 9565 9639 9731 9667 9713db10 6877 9852 9778 9769 9685 9639db44 6743 9870 9843 9898 9889 9861
kNNdb3 5914 9519 9657 9611 9583 9630db6 5868 8972 8731 9130 9065 9167db10 5793 9704 9657 9657 9546 9528db44 5763 9546 9556 9556 9500 9611
Speaker independentELM kernel
db3 5661 9604 9707 9724 9640 9640db6 5470 9226 9126 9183 9162 9148db10 5208 9212 9413 9337 9300 9293db44 5360 9304 9313 9410 9367 9433
kNNdb3 4912 9175 9332 9201 9279 9390db6 4821 8193 8222 8143 8218 8277db10 4517 9064 8981 8946 9023 9015db44 4687 9169 9015 9057 9035 9199
Table 4 Average emotion recognition rates for SAVEE database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 5563 9635 9677 9521 9583 9604db6 5563 9635 9552 9760 9573 9635db10 5823 9677 9135 9260 9333 9167db44 5833 9604 9552 9563 9583 9635
119896NNdb3 4708 9063 8990 9052 9156 9177db6 4781 9354 9281 9427 9229 9375db10 4656 9323 9396 9333 9260 9417db44 5031 9021 9104 9177 9010 9135
Speaker independentELM kernel
db3 2792 7000 6917 6854 7021 7000db6 3104 6792 7271 7375 7625 7625db10 3104 7792 7688 7688 7688 7667db44 3146 7083 7646 7604 7625 7667
kNNdb3 2875 6396 6250 6250 6313 6438db6 2792 6375 6604 6542 6625 6625db10 2792 6917 6750 6750 6750 6771db44 2750 6417 6250 6271 6167 6250
10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of
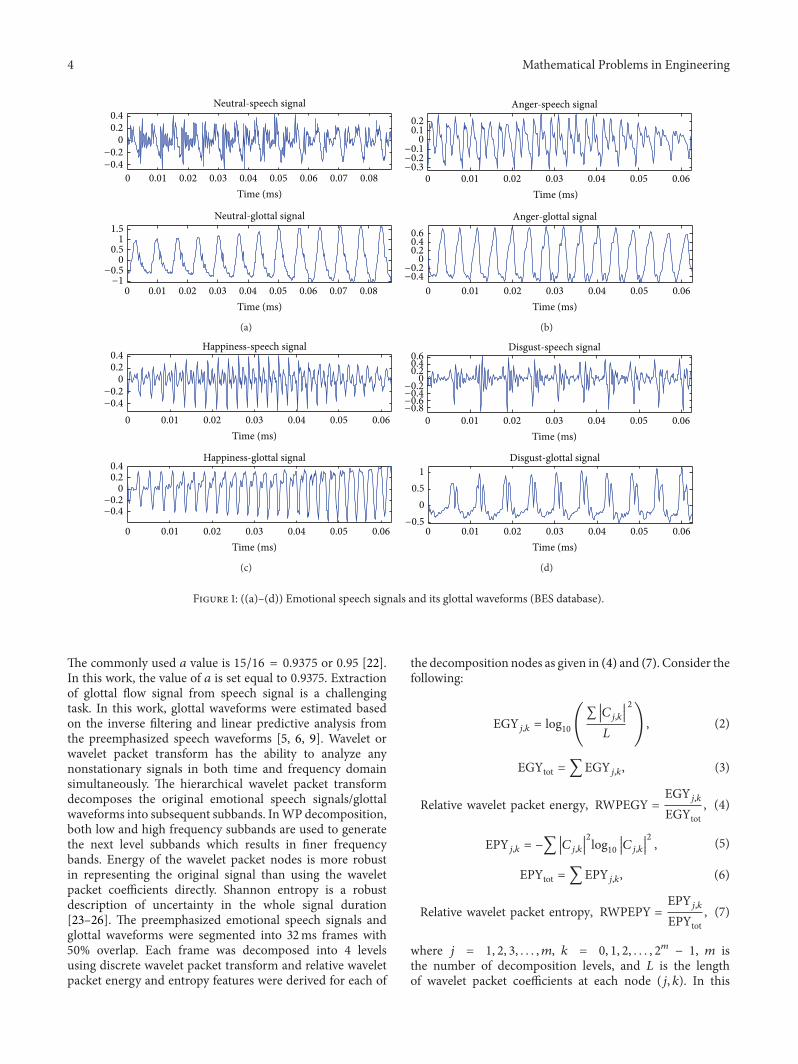
4 Mathematical Problems in Engineering
0 001 002 003 004 005 006 007 008
00204
Neutral-speech signal
Time (ms)
0 001 002 003 004 005 006 007 008
005
115
Neutral-glottal signal
Time (ms)
minus04
minus02
minus1
minus05
(a)
0 001 002 003 004 005 006
00102
Anger-speech signal
Time (ms)
0 001 002 003 004 005 006
0020406
Anger-glottal signal
Time (ms)
minus04minus02
minus02
minus01
minus03
(b)
0 001 002 003 004 005 006
00204
Happiness-speech signal
Time (ms)
0 001 002 003 004 005 006
00204
Happiness-glottal signal
Time (ms)
minus04
minus02
minus04
minus02
(c)
0 001 002 003 004 005 006
0020406
Disgust-speech signal
Time (ms)
0 001 002 003 004 005 006
005
1Disgust-glottal signal
Time (ms)
minus04minus02
minus08minus06
minus05
(d)
Figure 1 ((a)ndash(d)) Emotional speech signals and its glottal waveforms (BES database)
The commonly used 119886 value is 1516 = 09375 or 095 [22]In this work the value of 119886 is set equal to 09375 Extractionof glottal flow signal from speech signal is a challengingtask In this work glottal waveforms were estimated basedon the inverse filtering and linear predictive analysis fromthe preemphasized speech waveforms [5 6 9] Wavelet orwavelet packet transform has the ability to analyze anynonstationary signals in both time and frequency domainsimultaneously The hierarchical wavelet packet transformdecomposes the original emotional speech signalsglottalwaveforms into subsequent subbands InWP decompositionboth low and high frequency subbands are used to generatethe next level subbands which results in finer frequencybands Energy of the wavelet packet nodes is more robustin representing the original signal than using the waveletpacket coefficients directly Shannon entropy is a robustdescription of uncertainty in the whole signal duration[23ndash26] The preemphasized emotional speech signals andglottal waveforms were segmented into 32ms frames with50 overlap Each frame was decomposed into 4 levelsusing discrete wavelet packet transform and relative waveletpacket energy and entropy features were derived for each of
the decomposition nodes as given in (4) and (7) Consider thefollowing
EGY119895119896
= log10
(sum10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
119871
2
) (2)
EGYtot = sumEGY119895119896
(3)
Relative wavelet packet energy RWPEGY =EGY119895119896
EGYtot (4)
EPY119895119896
= minussum10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
2
log10
10038161003816100381610038161003816119862119895119896
10038161003816100381610038161003816
2
(5)
EPYtot = sumEPY119895119896
(6)
Relative wavelet packet entropy RWPEPY =EPY119895119896
EPYtot (7)
where 119895 = 1 2 3 119898 119896 = 0 1 2 2119898
minus 1 119898 isthe number of decomposition levels and 119871 is the lengthof wavelet packet coefficients at each node (119895 119896) In this
Mathematical Problems in Engineering 5
work Daubechies wavelets with 4 different orders (db3 db6db10 and db44) were used since Daubechies wavelets arefrequently used in speech emotion recognition and providebetter results [1 17 27 28] After obtaining the relativewaveletpacket energy and entropy based features for each frame theywere averaged over all frames and used for analysis Four-level wavelet decomposition gives 30 wavelet packet nodesand features were extracted from all the nodes which yield60 features (30 relative energy features + 30 relative entropyfeatures) Similarly the same features were extracted fromemotional glottal signals Finally a total of 120 features wereobtained
33 Feature Enhancement Using Gaussian Mixture Model Inany pattern recognition applications escalating the interclassvariance and diminishing the intraclass variance of theattributes or features are the fundamental issues to improvethe classification or recognition accuracy [24 25 29] In theliterature several research works can be found to escalatethe discriminating ability of the extracted features [24 2529] GMM has been successfully applied in various patternrecognition applications particularly in speech and imageprocessing applications [17 28ndash36] however its capabilityof escalating the discriminative ability of the features orattributes is not being extensively explored Different appli-cations of GMM motivate us to suggest GMM based featureenhancement [17 28ndash36] High intraclass variance and lowinterclass variance among the features may degrade theperformance of classifiers which results in poor emotionrecognition rates To decrease the intraclass variance and toincrease the interclass variance among the features GMMbased clustering was suggested in this work to enrich thediscriminative ability of the relative wavelet packet energyand entropy features GMM model is a probabilistic modeland its application to labelling is based on the assumptionthat all the data points are generated from a finite mixture ofGaussian mixture distributions In a model-based approachcertain models are used for clustering and attempting tooptimize the fit between the data andmodel Each cluster canbe mathematically represented by a Gaussian (parametric)distribution The entire dataset 119911 is modeled by a weightedsum of 119872 numbers of mixtures of Gaussian componentdensities and is given by the equation
119901 (119911119894
| 120579) =
119872
sum
119896=1
120588119896
119891 (119911119894
| 120579119896
) (8)
where 119911 is the 119873-dimensional continuous valued relativewavelet packet energy and entropy features 120588
119896
119896 = 1 2 3
119872 are the mixture weights and 119891(119911119894
| 120579119896
) 120579119896
=
(120583119896
Σ119896
) 119894 = 1 2 3 119872 are the component Gaussiandensities Each component density is an 119873-variate Gaussianfunction of the form
119891 (119911119894
| 120579119896
) =1
(2120587)1198992
1003816100381610038161003816Σ119894100381610038161003816100381612
sdot exp [minus12(119911 minus 120583
119894
)119879
Σminus1
119894
(119911 minus 120583119894
)]
(9)
Relative wavelet packet energy and entropy features
(120 features)
Calculate the component means (cluster centers) using GMM
Calculate the ratios of means of features to their centers and
multiply these ratios with each respective feature
Enhanced relative waveletpacket energy and entropy
features
Figure 2 Proposed GMM based feature enhancement
where 120583119894
is the mean vector and Σ119894
is the covariance matrixUsing the linear combination of mean vectors covariancematrices and mixture weights overall probability densityfunction is estimated [17 28ndash36] Gaussian mixture modeluses an iterative expectation maximization (EM) algorithmthat converges to a local optimum and assigns posteriorprobabilities to each component density with respect to eachobservation The posterior probabilities for each point indi-cate that each data point has some probability of belonging toeach cluster [17 28ndash36] The working of GMM based featureenhancement is summarized (Figure 2) as follows firstly thecomponent means (cluster centers) of each feature belongingto dataset using GMM based clustering method was foundNext the ratios of means of features to their centers werecalculated Finally these ratios were multiplied with eachrespective feature
After applying GMM clustering based feature weightingmethod the raw features (RF) were known as enhancedfeatures (EF)
The class distribution plots of raw relative wavelet packetenergy and entropy features were shown in Figures 3(a) 3(c)3(e) and 3(g) for different orders of Daubechies wavelets(ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo) From the figures it canbe seen that there is a higher degree of overlap amongthe raw relative wavelet packet energy and entropy featureswhich results in the poor performance of the speech emotionrecognition system The class distribution plots of enhancedrelative wavelet packet energy and entropy features wereshown in Figures 3(b) 3(d) 3(f) and 3(h) From the figuresit can be observed that the higher degree of overlap can bediminished which in turn improves the performance of thespeech emotion recognition system
34 Feature Reduction Using Stepwise Linear DiscriminantAnalysis Curse of dimensionality is a big issue in all patternrecognition problems Irrelevant and redundant features maydegrade the performance of the classifiers Feature selec-tionreduction was used for selecting the subset of relevantfeatures from a large number of features [24 29 37] Severalfeature selectionreduction techniques have been proposedto find most discriminating features for improving the per-formance of the speech emotion recognition system [18 2028 38ndash43] In this work we propose the use of stepwiselinear discriminant analysis (SWLDA) since LDA is a lineartechnique which relies on the mixture model containing
6 Mathematical Problems in Engineering
009 011 013 015 017
0059006100630065
00670055
0060065
0070075
Feature 7Feature 77
Feat
ure 1
08
(a)
02 06 102061
005
1
Feature 7Feature 77
Feat
ure 1
08
minus1minus06
minus02
minus1minus06
minus02
minus1
minus05
(b)
009 011 013 015 017
0120124012801320136
014023
0235024
0245025
0255026
0265
Feature 7Feature 67
Feat
ure 9
4
(c)
02 06 102061
0206
1
Feature 7Feature 67
Feat
ure 9
4
minus1minus06
minus02
minus1minus06
minus02
minus1
minus06
minus02
(d)
009 011 013 015 017
004006
00801
006008
01012014016018
Feature 7Feature 15
Feat
ure 4
3
(e)
02 06 102061
0206
1
Feat
ure 4
3
Feature 15 Feature 7minus1
minus06minus02
minus1minus06
minus02
minus1
minus06
minus02
(f)
009 011 013 015 017
00601
014018046047048049
05051052
Feature 7Feature 41
Feat
ure 9
2
AngerBoredomDisgustFear
HappinessSadnessNeutral
(g)
02 06 102061
0206
1
Feature 7
Feature 41
Feat
ure 9
2
minus1 minus1minus06
minus06
minus02minus02
minus1
minus06
minus02
AngerBoredomDisgustFear
HappinessSadnessNeutral
(h)
Figure 3 ((a) (c) (e) and (g)) Class distribution plots of raw features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo ((b) (d) (f) and (h)) Classdistribution plots of enhanced features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo
the correct number of components and has limited flexibilitywhen applied to more complex datasets [37 44] StepwiseLDA uses both forward and backward strategies In theforward approach the attributes that significantly contributeto the discrimination between the groups will be determinedThis process stops when there is no attribute to add in
the model In the backward approach the attributes (lessrelevant features) which do not significantly degrade thediscrimination between groups will be removed 119865-statisticor 119901 value is generally used as predetermined criterion toselectremove the attributes In this work the selection ofthe best features is controlled by four different combinations
Mathematical Problems in Engineering 7
of (005 and 01 SET1 001 and 005 SET2 001 and 0001SET3 0001 and 00001 SET4)119901 values In a feature entry stepthe features that provide the most significant performanceimprovement will be entered in the feature model if the 119901value lt 005 In the feature removal step attributes whichdo not significantly affect the performance of the classifierswill be removed if the 119901 value gt 01 SWLDA was applied tothe enhanced feature set to select best features and to removeirrelevant features
The details of the number of selected enhanced featuresfor every combination were tabulated in Table 2 FromTable 2 it can be seen that the enhanced relative energy andentropy features of the speech signals were more significantthan the glottal signals Approximately between 32 and82 of insignificant enhanced features were removed in allthe combination of 119901 values (005 and 01 001 and 005001 and 0001 and 0001 and 00001) and speaker-dependentand speaker-independent emotion recognition experimentswere carried out using these significant enhanced featuresThe results were compared with the original raw relativewavelet packet energy and entropy features and some of thesignificant works in the literature
35 Classifiers
351 119896-Nearest Neighbor Classifier 119896NN classifier is a type ofinstance-based classifiers and predicts the correct class labelfor the new test vector by relating the unknown test vector toknown training vectors according to some distancesimilarityfunction [25] Euclidean distance function was used andappropriate 119896-value was found by searching a value between1 and 20
352 Extreme Learning Machine A new learning algorithmfor the single hidden layer feedforward networks (SLFNs)called ELM was proposed by Huang et al [45ndash48] It hasbeenwidely used in various applications to overcome the slowtraining speed and overfitting problems of the conventionalneural network learning algorithms [45ndash48] The brief ideaof ELM is as follows [45ndash48]
For the given 119873 training samples the output of a SLFNnetwork with 119871 hidden nodes can be expressed as thefollowing
119891119871
(119909119895
) =
119871
sum
119894
120573119894
119892 (119908119894
sdot 119909119895
+ 119887119894
) 119895 = 1 2 3 119873 (10)
It can be written as 119891(119909) = ℎ(119909)120573 where 119909119895
119908119894
and 119887119894
are the input training vector input weights and biases tothe hidden layer respectively 120573
119894
are the output weights thatlink the 119894th hidden node to the output layer and 119892(sdot) is theactivation function of the hidden nodes Training a SLFNis simply finding a least-square solution by using Moore-Penrose generalized inverse
120573 = 119867dagger119879 (11)
where 119867dagger = (1198671015840
119867)minus1
1198671015840 or 1198671015840(1198671198671015840)minus1 depending on the
singularity of1198671015840119867 or1198671198671015840 Assume that1198671015840119867 is not singular
the coefficient 1120576 (120576 is positive regularization coefficient) isadded to the diagonal of1198671015840119867 in the calculation of the outputweights 120573
119894
Hence more stable learning system with bettergeneralization performance can be obtained
The output function of ELM can be written compactly as
119891 (119909) = ℎ (119909)1198671015840
(1
120576+ 119867119867
1015840
)
minus1
119879 (12)
In this ELM kernel implementation the hidden layer featuremappings need not be known to users and Gaussian kernelwas used Best values for positive regularization coefficient(120576) as 1 and Gaussian kernel parameter as 10 were foundempirically after several experiments
4 Experimental Results and Discussions
This section describes the average emotion recognition ratesobtained for speaker-dependent and speaker-independentemotion recognition environments using proposed meth-ods In order to demonstrate the robustness of the pro-posed methods 3 different emotional speech databases wereused Amongst 2 of them were recorded using professionalactorsactresses and 1 of them was recorded using universitystudents The average emotion recognition rates for theoriginal raw and enhanced relative wavelet packet energyand entropy features and for best enhanced features weretabulated in Tables 3 4 and 5 Table 3 shows the resultsfor the BES database 119896NN and ELM kernel classifiers wereused for emotion recognition From the results ELM kernelalways performs better compared to 119896NN classifier in termsof average emotion recognition rates irrespective of differentorders of ldquodbrdquo wavelets Under speaker-dependent experi-mentmaximumaverage emotion recognition rates of 6999and 9898 were obtained with ELM kernel classifier usingthe raw and enhanced relative wavelet packet energy andentropy features respectively Under speaker-independentexperiment maximum average emotion recognition rates of5661 and 9724 were attained with ELM kernel classifierusing the raw and enhanced relative wavelet packet energyand entropy features respectively 119896NN classifier gives onlymaximum average recognition rates of 5914 and 4912under speaker-dependent and speaker-independent experi-ment respectively
The average emotion recognition rates for SAVEEdatabase are tabulated in Table 4 Only audio signals fromSAVEE database were used for emotion recognition experi-ment According to Table 4 ELM kernel has achieved betteraverage emotion recognition of 5833 than 119896NN clas-sifier which gives only 5031 using all the raw relativewavelet packet energy and entropy features under speaker-dependent experiment Similarly maximum emotion recog-nition rates of 3146 and 2875 were obtained underspeaker-independent experiment using ELMkernel and 119896NNclassifier respectively
After GMMbased feature enhancement average emotionrecognition rate was improved to 9760 and 9427 usingELM kernel classifier and 119896NN classifier under speaker-dependent experiment During speaker-independent experi-ment maximum average emotion recognition rates of 7792
8 Mathematical Problems in Engineering
Table2Num
bero
fsele
cted
enhanced
features
usingSW
LDA
Different
orderldquodbrdquo
wavele
ts119875value
BES
SAVEE
SES
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
db3
005ndash0
121
2612
1218
2110
1319
2516
19001ndash0
05
1722
811
1720
710
1624
1316
0001ndash001
1618
78
1417
65
1522
58
000
01ndash0
001
713
57
1313
55
818
56
db6
005ndash0
118
2313
1418
2017
1918
2313
14001ndash0
05
1322
712
1621
1717
1322
712
0001ndash001
1219
710
1319
1110
1219
710
000
01ndash0
001
1413
77
1319
1110
1413
77
db10
005ndash0
122
2212
125
94
420
2312
13001ndash0
05
1717
1110
59
44
1919
1212
0001ndash001
1415
67
59
44
1618
99
000
01ndash0
001
1415
65
59
43
1211
68
db44
005ndash0
125
2714
1514
207
1125
2714
15001ndash0
05
2024
99
1420
710
2024
99
0001ndash001
1515
87
1419
69
1515
87
000
01ndash0
001
1213
45
1318
53
1213
45
Mathematical Problems in Engineering 9
Table 3 Average emotion recognition rates for BES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 6999 9824 9852 9815 9750 9815db6 6855 9565 9639 9731 9667 9713db10 6877 9852 9778 9769 9685 9639db44 6743 9870 9843 9898 9889 9861
kNNdb3 5914 9519 9657 9611 9583 9630db6 5868 8972 8731 9130 9065 9167db10 5793 9704 9657 9657 9546 9528db44 5763 9546 9556 9556 9500 9611
Speaker independentELM kernel
db3 5661 9604 9707 9724 9640 9640db6 5470 9226 9126 9183 9162 9148db10 5208 9212 9413 9337 9300 9293db44 5360 9304 9313 9410 9367 9433
kNNdb3 4912 9175 9332 9201 9279 9390db6 4821 8193 8222 8143 8218 8277db10 4517 9064 8981 8946 9023 9015db44 4687 9169 9015 9057 9035 9199
Table 4 Average emotion recognition rates for SAVEE database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 5563 9635 9677 9521 9583 9604db6 5563 9635 9552 9760 9573 9635db10 5823 9677 9135 9260 9333 9167db44 5833 9604 9552 9563 9583 9635
119896NNdb3 4708 9063 8990 9052 9156 9177db6 4781 9354 9281 9427 9229 9375db10 4656 9323 9396 9333 9260 9417db44 5031 9021 9104 9177 9010 9135
Speaker independentELM kernel
db3 2792 7000 6917 6854 7021 7000db6 3104 6792 7271 7375 7625 7625db10 3104 7792 7688 7688 7688 7667db44 3146 7083 7646 7604 7625 7667
kNNdb3 2875 6396 6250 6250 6313 6438db6 2792 6375 6604 6542 6625 6625db10 2792 6917 6750 6750 6750 6771db44 2750 6417 6250 6271 6167 6250
10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 5
work Daubechies wavelets with 4 different orders (db3 db6db10 and db44) were used since Daubechies wavelets arefrequently used in speech emotion recognition and providebetter results [1 17 27 28] After obtaining the relativewaveletpacket energy and entropy based features for each frame theywere averaged over all frames and used for analysis Four-level wavelet decomposition gives 30 wavelet packet nodesand features were extracted from all the nodes which yield60 features (30 relative energy features + 30 relative entropyfeatures) Similarly the same features were extracted fromemotional glottal signals Finally a total of 120 features wereobtained
33 Feature Enhancement Using Gaussian Mixture Model Inany pattern recognition applications escalating the interclassvariance and diminishing the intraclass variance of theattributes or features are the fundamental issues to improvethe classification or recognition accuracy [24 25 29] In theliterature several research works can be found to escalatethe discriminating ability of the extracted features [24 2529] GMM has been successfully applied in various patternrecognition applications particularly in speech and imageprocessing applications [17 28ndash36] however its capabilityof escalating the discriminative ability of the features orattributes is not being extensively explored Different appli-cations of GMM motivate us to suggest GMM based featureenhancement [17 28ndash36] High intraclass variance and lowinterclass variance among the features may degrade theperformance of classifiers which results in poor emotionrecognition rates To decrease the intraclass variance and toincrease the interclass variance among the features GMMbased clustering was suggested in this work to enrich thediscriminative ability of the relative wavelet packet energyand entropy features GMM model is a probabilistic modeland its application to labelling is based on the assumptionthat all the data points are generated from a finite mixture ofGaussian mixture distributions In a model-based approachcertain models are used for clustering and attempting tooptimize the fit between the data andmodel Each cluster canbe mathematically represented by a Gaussian (parametric)distribution The entire dataset 119911 is modeled by a weightedsum of 119872 numbers of mixtures of Gaussian componentdensities and is given by the equation
119901 (119911119894
| 120579) =
119872
sum
119896=1
120588119896
119891 (119911119894
| 120579119896
) (8)
where 119911 is the 119873-dimensional continuous valued relativewavelet packet energy and entropy features 120588
119896
119896 = 1 2 3
119872 are the mixture weights and 119891(119911119894
| 120579119896
) 120579119896
=
(120583119896
Σ119896
) 119894 = 1 2 3 119872 are the component Gaussiandensities Each component density is an 119873-variate Gaussianfunction of the form
119891 (119911119894
| 120579119896
) =1
(2120587)1198992
1003816100381610038161003816Σ119894100381610038161003816100381612
sdot exp [minus12(119911 minus 120583
119894
)119879
Σminus1
119894
(119911 minus 120583119894
)]
(9)
Relative wavelet packet energy and entropy features
(120 features)
Calculate the component means (cluster centers) using GMM
Calculate the ratios of means of features to their centers and
multiply these ratios with each respective feature
Enhanced relative waveletpacket energy and entropy
features
Figure 2 Proposed GMM based feature enhancement
where 120583119894
is the mean vector and Σ119894
is the covariance matrixUsing the linear combination of mean vectors covariancematrices and mixture weights overall probability densityfunction is estimated [17 28ndash36] Gaussian mixture modeluses an iterative expectation maximization (EM) algorithmthat converges to a local optimum and assigns posteriorprobabilities to each component density with respect to eachobservation The posterior probabilities for each point indi-cate that each data point has some probability of belonging toeach cluster [17 28ndash36] The working of GMM based featureenhancement is summarized (Figure 2) as follows firstly thecomponent means (cluster centers) of each feature belongingto dataset using GMM based clustering method was foundNext the ratios of means of features to their centers werecalculated Finally these ratios were multiplied with eachrespective feature
After applying GMM clustering based feature weightingmethod the raw features (RF) were known as enhancedfeatures (EF)
The class distribution plots of raw relative wavelet packetenergy and entropy features were shown in Figures 3(a) 3(c)3(e) and 3(g) for different orders of Daubechies wavelets(ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo) From the figures it canbe seen that there is a higher degree of overlap amongthe raw relative wavelet packet energy and entropy featureswhich results in the poor performance of the speech emotionrecognition system The class distribution plots of enhancedrelative wavelet packet energy and entropy features wereshown in Figures 3(b) 3(d) 3(f) and 3(h) From the figuresit can be observed that the higher degree of overlap can bediminished which in turn improves the performance of thespeech emotion recognition system
34 Feature Reduction Using Stepwise Linear DiscriminantAnalysis Curse of dimensionality is a big issue in all patternrecognition problems Irrelevant and redundant features maydegrade the performance of the classifiers Feature selec-tionreduction was used for selecting the subset of relevantfeatures from a large number of features [24 29 37] Severalfeature selectionreduction techniques have been proposedto find most discriminating features for improving the per-formance of the speech emotion recognition system [18 2028 38ndash43] In this work we propose the use of stepwiselinear discriminant analysis (SWLDA) since LDA is a lineartechnique which relies on the mixture model containing
6 Mathematical Problems in Engineering
009 011 013 015 017
0059006100630065
00670055
0060065
0070075
Feature 7Feature 77
Feat
ure 1
08
(a)
02 06 102061
005
1
Feature 7Feature 77
Feat
ure 1
08
minus1minus06
minus02
minus1minus06
minus02
minus1
minus05
(b)
009 011 013 015 017
0120124012801320136
014023
0235024
0245025
0255026
0265
Feature 7Feature 67
Feat
ure 9
4
(c)
02 06 102061
0206
1
Feature 7Feature 67
Feat
ure 9
4
minus1minus06
minus02
minus1minus06
minus02
minus1
minus06
minus02
(d)
009 011 013 015 017
004006
00801
006008
01012014016018
Feature 7Feature 15
Feat
ure 4
3
(e)
02 06 102061
0206
1
Feat
ure 4
3
Feature 15 Feature 7minus1
minus06minus02
minus1minus06
minus02
minus1
minus06
minus02
(f)
009 011 013 015 017
00601
014018046047048049
05051052
Feature 7Feature 41
Feat
ure 9
2
AngerBoredomDisgustFear
HappinessSadnessNeutral
(g)
02 06 102061
0206
1
Feature 7
Feature 41
Feat
ure 9
2
minus1 minus1minus06
minus06
minus02minus02
minus1
minus06
minus02
AngerBoredomDisgustFear
HappinessSadnessNeutral
(h)
Figure 3 ((a) (c) (e) and (g)) Class distribution plots of raw features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo ((b) (d) (f) and (h)) Classdistribution plots of enhanced features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo
the correct number of components and has limited flexibilitywhen applied to more complex datasets [37 44] StepwiseLDA uses both forward and backward strategies In theforward approach the attributes that significantly contributeto the discrimination between the groups will be determinedThis process stops when there is no attribute to add in
the model In the backward approach the attributes (lessrelevant features) which do not significantly degrade thediscrimination between groups will be removed 119865-statisticor 119901 value is generally used as predetermined criterion toselectremove the attributes In this work the selection ofthe best features is controlled by four different combinations
Mathematical Problems in Engineering 7
of (005 and 01 SET1 001 and 005 SET2 001 and 0001SET3 0001 and 00001 SET4)119901 values In a feature entry stepthe features that provide the most significant performanceimprovement will be entered in the feature model if the 119901value lt 005 In the feature removal step attributes whichdo not significantly affect the performance of the classifierswill be removed if the 119901 value gt 01 SWLDA was applied tothe enhanced feature set to select best features and to removeirrelevant features
The details of the number of selected enhanced featuresfor every combination were tabulated in Table 2 FromTable 2 it can be seen that the enhanced relative energy andentropy features of the speech signals were more significantthan the glottal signals Approximately between 32 and82 of insignificant enhanced features were removed in allthe combination of 119901 values (005 and 01 001 and 005001 and 0001 and 0001 and 00001) and speaker-dependentand speaker-independent emotion recognition experimentswere carried out using these significant enhanced featuresThe results were compared with the original raw relativewavelet packet energy and entropy features and some of thesignificant works in the literature
35 Classifiers
351 119896-Nearest Neighbor Classifier 119896NN classifier is a type ofinstance-based classifiers and predicts the correct class labelfor the new test vector by relating the unknown test vector toknown training vectors according to some distancesimilarityfunction [25] Euclidean distance function was used andappropriate 119896-value was found by searching a value between1 and 20
352 Extreme Learning Machine A new learning algorithmfor the single hidden layer feedforward networks (SLFNs)called ELM was proposed by Huang et al [45ndash48] It hasbeenwidely used in various applications to overcome the slowtraining speed and overfitting problems of the conventionalneural network learning algorithms [45ndash48] The brief ideaof ELM is as follows [45ndash48]
For the given 119873 training samples the output of a SLFNnetwork with 119871 hidden nodes can be expressed as thefollowing
119891119871
(119909119895
) =
119871
sum
119894
120573119894
119892 (119908119894
sdot 119909119895
+ 119887119894
) 119895 = 1 2 3 119873 (10)
It can be written as 119891(119909) = ℎ(119909)120573 where 119909119895
119908119894
and 119887119894
are the input training vector input weights and biases tothe hidden layer respectively 120573
119894
are the output weights thatlink the 119894th hidden node to the output layer and 119892(sdot) is theactivation function of the hidden nodes Training a SLFNis simply finding a least-square solution by using Moore-Penrose generalized inverse
120573 = 119867dagger119879 (11)
where 119867dagger = (1198671015840
119867)minus1
1198671015840 or 1198671015840(1198671198671015840)minus1 depending on the
singularity of1198671015840119867 or1198671198671015840 Assume that1198671015840119867 is not singular
the coefficient 1120576 (120576 is positive regularization coefficient) isadded to the diagonal of1198671015840119867 in the calculation of the outputweights 120573
119894
Hence more stable learning system with bettergeneralization performance can be obtained
The output function of ELM can be written compactly as
119891 (119909) = ℎ (119909)1198671015840
(1
120576+ 119867119867
1015840
)
minus1
119879 (12)
In this ELM kernel implementation the hidden layer featuremappings need not be known to users and Gaussian kernelwas used Best values for positive regularization coefficient(120576) as 1 and Gaussian kernel parameter as 10 were foundempirically after several experiments
4 Experimental Results and Discussions
This section describes the average emotion recognition ratesobtained for speaker-dependent and speaker-independentemotion recognition environments using proposed meth-ods In order to demonstrate the robustness of the pro-posed methods 3 different emotional speech databases wereused Amongst 2 of them were recorded using professionalactorsactresses and 1 of them was recorded using universitystudents The average emotion recognition rates for theoriginal raw and enhanced relative wavelet packet energyand entropy features and for best enhanced features weretabulated in Tables 3 4 and 5 Table 3 shows the resultsfor the BES database 119896NN and ELM kernel classifiers wereused for emotion recognition From the results ELM kernelalways performs better compared to 119896NN classifier in termsof average emotion recognition rates irrespective of differentorders of ldquodbrdquo wavelets Under speaker-dependent experi-mentmaximumaverage emotion recognition rates of 6999and 9898 were obtained with ELM kernel classifier usingthe raw and enhanced relative wavelet packet energy andentropy features respectively Under speaker-independentexperiment maximum average emotion recognition rates of5661 and 9724 were attained with ELM kernel classifierusing the raw and enhanced relative wavelet packet energyand entropy features respectively 119896NN classifier gives onlymaximum average recognition rates of 5914 and 4912under speaker-dependent and speaker-independent experi-ment respectively
The average emotion recognition rates for SAVEEdatabase are tabulated in Table 4 Only audio signals fromSAVEE database were used for emotion recognition experi-ment According to Table 4 ELM kernel has achieved betteraverage emotion recognition of 5833 than 119896NN clas-sifier which gives only 5031 using all the raw relativewavelet packet energy and entropy features under speaker-dependent experiment Similarly maximum emotion recog-nition rates of 3146 and 2875 were obtained underspeaker-independent experiment using ELMkernel and 119896NNclassifier respectively
After GMMbased feature enhancement average emotionrecognition rate was improved to 9760 and 9427 usingELM kernel classifier and 119896NN classifier under speaker-dependent experiment During speaker-independent experi-ment maximum average emotion recognition rates of 7792
8 Mathematical Problems in Engineering
Table2Num
bero
fsele
cted
enhanced
features
usingSW
LDA
Different
orderldquodbrdquo
wavele
ts119875value
BES
SAVEE
SES
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
db3
005ndash0
121
2612
1218
2110
1319
2516
19001ndash0
05
1722
811
1720
710
1624
1316
0001ndash001
1618
78
1417
65
1522
58
000
01ndash0
001
713
57
1313
55
818
56
db6
005ndash0
118
2313
1418
2017
1918
2313
14001ndash0
05
1322
712
1621
1717
1322
712
0001ndash001
1219
710
1319
1110
1219
710
000
01ndash0
001
1413
77
1319
1110
1413
77
db10
005ndash0
122
2212
125
94
420
2312
13001ndash0
05
1717
1110
59
44
1919
1212
0001ndash001
1415
67
59
44
1618
99
000
01ndash0
001
1415
65
59
43
1211
68
db44
005ndash0
125
2714
1514
207
1125
2714
15001ndash0
05
2024
99
1420
710
2024
99
0001ndash001
1515
87
1419
69
1515
87
000
01ndash0
001
1213
45
1318
53
1213
45
Mathematical Problems in Engineering 9
Table 3 Average emotion recognition rates for BES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 6999 9824 9852 9815 9750 9815db6 6855 9565 9639 9731 9667 9713db10 6877 9852 9778 9769 9685 9639db44 6743 9870 9843 9898 9889 9861
kNNdb3 5914 9519 9657 9611 9583 9630db6 5868 8972 8731 9130 9065 9167db10 5793 9704 9657 9657 9546 9528db44 5763 9546 9556 9556 9500 9611
Speaker independentELM kernel
db3 5661 9604 9707 9724 9640 9640db6 5470 9226 9126 9183 9162 9148db10 5208 9212 9413 9337 9300 9293db44 5360 9304 9313 9410 9367 9433
kNNdb3 4912 9175 9332 9201 9279 9390db6 4821 8193 8222 8143 8218 8277db10 4517 9064 8981 8946 9023 9015db44 4687 9169 9015 9057 9035 9199
Table 4 Average emotion recognition rates for SAVEE database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 5563 9635 9677 9521 9583 9604db6 5563 9635 9552 9760 9573 9635db10 5823 9677 9135 9260 9333 9167db44 5833 9604 9552 9563 9583 9635
119896NNdb3 4708 9063 8990 9052 9156 9177db6 4781 9354 9281 9427 9229 9375db10 4656 9323 9396 9333 9260 9417db44 5031 9021 9104 9177 9010 9135
Speaker independentELM kernel
db3 2792 7000 6917 6854 7021 7000db6 3104 6792 7271 7375 7625 7625db10 3104 7792 7688 7688 7688 7667db44 3146 7083 7646 7604 7625 7667
kNNdb3 2875 6396 6250 6250 6313 6438db6 2792 6375 6604 6542 6625 6625db10 2792 6917 6750 6750 6750 6771db44 2750 6417 6250 6271 6167 6250
10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of
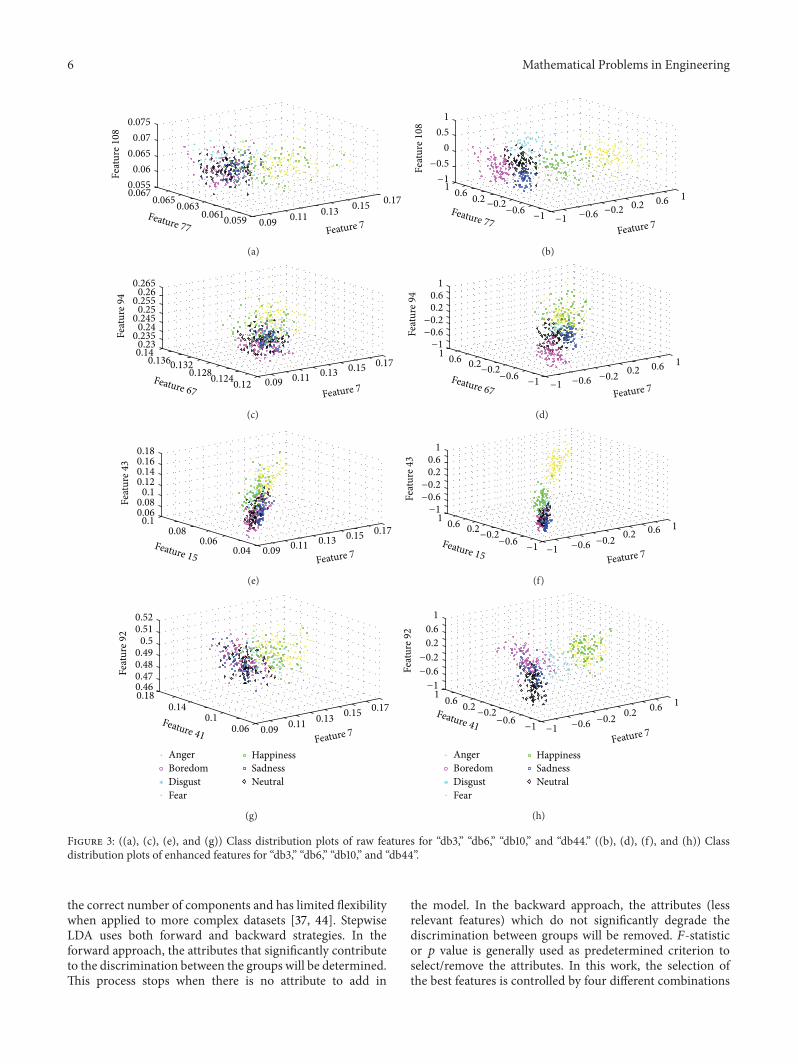
6 Mathematical Problems in Engineering
009 011 013 015 017
0059006100630065
00670055
0060065
0070075
Feature 7Feature 77
Feat
ure 1
08
(a)
02 06 102061
005
1
Feature 7Feature 77
Feat
ure 1
08
minus1minus06
minus02
minus1minus06
minus02
minus1
minus05
(b)
009 011 013 015 017
0120124012801320136
014023
0235024
0245025
0255026
0265
Feature 7Feature 67
Feat
ure 9
4
(c)
02 06 102061
0206
1
Feature 7Feature 67
Feat
ure 9
4
minus1minus06
minus02
minus1minus06
minus02
minus1
minus06
minus02
(d)
009 011 013 015 017
004006
00801
006008
01012014016018
Feature 7Feature 15
Feat
ure 4
3
(e)
02 06 102061
0206
1
Feat
ure 4
3
Feature 15 Feature 7minus1
minus06minus02
minus1minus06
minus02
minus1
minus06
minus02
(f)
009 011 013 015 017
00601
014018046047048049
05051052
Feature 7Feature 41
Feat
ure 9
2
AngerBoredomDisgustFear
HappinessSadnessNeutral
(g)
02 06 102061
0206
1
Feature 7
Feature 41
Feat
ure 9
2
minus1 minus1minus06
minus06
minus02minus02
minus1
minus06
minus02
AngerBoredomDisgustFear
HappinessSadnessNeutral
(h)
Figure 3 ((a) (c) (e) and (g)) Class distribution plots of raw features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo ((b) (d) (f) and (h)) Classdistribution plots of enhanced features for ldquodb3rdquo ldquodb6rdquo ldquodb10rdquo and ldquodb44rdquo
the correct number of components and has limited flexibilitywhen applied to more complex datasets [37 44] StepwiseLDA uses both forward and backward strategies In theforward approach the attributes that significantly contributeto the discrimination between the groups will be determinedThis process stops when there is no attribute to add in
the model In the backward approach the attributes (lessrelevant features) which do not significantly degrade thediscrimination between groups will be removed 119865-statisticor 119901 value is generally used as predetermined criterion toselectremove the attributes In this work the selection ofthe best features is controlled by four different combinations
Mathematical Problems in Engineering 7
of (005 and 01 SET1 001 and 005 SET2 001 and 0001SET3 0001 and 00001 SET4)119901 values In a feature entry stepthe features that provide the most significant performanceimprovement will be entered in the feature model if the 119901value lt 005 In the feature removal step attributes whichdo not significantly affect the performance of the classifierswill be removed if the 119901 value gt 01 SWLDA was applied tothe enhanced feature set to select best features and to removeirrelevant features
The details of the number of selected enhanced featuresfor every combination were tabulated in Table 2 FromTable 2 it can be seen that the enhanced relative energy andentropy features of the speech signals were more significantthan the glottal signals Approximately between 32 and82 of insignificant enhanced features were removed in allthe combination of 119901 values (005 and 01 001 and 005001 and 0001 and 0001 and 00001) and speaker-dependentand speaker-independent emotion recognition experimentswere carried out using these significant enhanced featuresThe results were compared with the original raw relativewavelet packet energy and entropy features and some of thesignificant works in the literature
35 Classifiers
351 119896-Nearest Neighbor Classifier 119896NN classifier is a type ofinstance-based classifiers and predicts the correct class labelfor the new test vector by relating the unknown test vector toknown training vectors according to some distancesimilarityfunction [25] Euclidean distance function was used andappropriate 119896-value was found by searching a value between1 and 20
352 Extreme Learning Machine A new learning algorithmfor the single hidden layer feedforward networks (SLFNs)called ELM was proposed by Huang et al [45ndash48] It hasbeenwidely used in various applications to overcome the slowtraining speed and overfitting problems of the conventionalneural network learning algorithms [45ndash48] The brief ideaof ELM is as follows [45ndash48]
For the given 119873 training samples the output of a SLFNnetwork with 119871 hidden nodes can be expressed as thefollowing
119891119871
(119909119895
) =
119871
sum
119894
120573119894
119892 (119908119894
sdot 119909119895
+ 119887119894
) 119895 = 1 2 3 119873 (10)
It can be written as 119891(119909) = ℎ(119909)120573 where 119909119895
119908119894
and 119887119894
are the input training vector input weights and biases tothe hidden layer respectively 120573
119894
are the output weights thatlink the 119894th hidden node to the output layer and 119892(sdot) is theactivation function of the hidden nodes Training a SLFNis simply finding a least-square solution by using Moore-Penrose generalized inverse
120573 = 119867dagger119879 (11)
where 119867dagger = (1198671015840
119867)minus1
1198671015840 or 1198671015840(1198671198671015840)minus1 depending on the
singularity of1198671015840119867 or1198671198671015840 Assume that1198671015840119867 is not singular
the coefficient 1120576 (120576 is positive regularization coefficient) isadded to the diagonal of1198671015840119867 in the calculation of the outputweights 120573
119894
Hence more stable learning system with bettergeneralization performance can be obtained
The output function of ELM can be written compactly as
119891 (119909) = ℎ (119909)1198671015840
(1
120576+ 119867119867
1015840
)
minus1
119879 (12)
In this ELM kernel implementation the hidden layer featuremappings need not be known to users and Gaussian kernelwas used Best values for positive regularization coefficient(120576) as 1 and Gaussian kernel parameter as 10 were foundempirically after several experiments
4 Experimental Results and Discussions
This section describes the average emotion recognition ratesobtained for speaker-dependent and speaker-independentemotion recognition environments using proposed meth-ods In order to demonstrate the robustness of the pro-posed methods 3 different emotional speech databases wereused Amongst 2 of them were recorded using professionalactorsactresses and 1 of them was recorded using universitystudents The average emotion recognition rates for theoriginal raw and enhanced relative wavelet packet energyand entropy features and for best enhanced features weretabulated in Tables 3 4 and 5 Table 3 shows the resultsfor the BES database 119896NN and ELM kernel classifiers wereused for emotion recognition From the results ELM kernelalways performs better compared to 119896NN classifier in termsof average emotion recognition rates irrespective of differentorders of ldquodbrdquo wavelets Under speaker-dependent experi-mentmaximumaverage emotion recognition rates of 6999and 9898 were obtained with ELM kernel classifier usingthe raw and enhanced relative wavelet packet energy andentropy features respectively Under speaker-independentexperiment maximum average emotion recognition rates of5661 and 9724 were attained with ELM kernel classifierusing the raw and enhanced relative wavelet packet energyand entropy features respectively 119896NN classifier gives onlymaximum average recognition rates of 5914 and 4912under speaker-dependent and speaker-independent experi-ment respectively
The average emotion recognition rates for SAVEEdatabase are tabulated in Table 4 Only audio signals fromSAVEE database were used for emotion recognition experi-ment According to Table 4 ELM kernel has achieved betteraverage emotion recognition of 5833 than 119896NN clas-sifier which gives only 5031 using all the raw relativewavelet packet energy and entropy features under speaker-dependent experiment Similarly maximum emotion recog-nition rates of 3146 and 2875 were obtained underspeaker-independent experiment using ELMkernel and 119896NNclassifier respectively
After GMMbased feature enhancement average emotionrecognition rate was improved to 9760 and 9427 usingELM kernel classifier and 119896NN classifier under speaker-dependent experiment During speaker-independent experi-ment maximum average emotion recognition rates of 7792
8 Mathematical Problems in Engineering
Table2Num
bero
fsele
cted
enhanced
features
usingSW
LDA
Different
orderldquodbrdquo
wavele
ts119875value
BES
SAVEE
SES
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
db3
005ndash0
121
2612
1218
2110
1319
2516
19001ndash0
05
1722
811
1720
710
1624
1316
0001ndash001
1618
78
1417
65
1522
58
000
01ndash0
001
713
57
1313
55
818
56
db6
005ndash0
118
2313
1418
2017
1918
2313
14001ndash0
05
1322
712
1621
1717
1322
712
0001ndash001
1219
710
1319
1110
1219
710
000
01ndash0
001
1413
77
1319
1110
1413
77
db10
005ndash0
122
2212
125
94
420
2312
13001ndash0
05
1717
1110
59
44
1919
1212
0001ndash001
1415
67
59
44
1618
99
000
01ndash0
001
1415
65
59
43
1211
68
db44
005ndash0
125
2714
1514
207
1125
2714
15001ndash0
05
2024
99
1420
710
2024
99
0001ndash001
1515
87
1419
69
1515
87
000
01ndash0
001
1213
45
1318
53
1213
45
Mathematical Problems in Engineering 9
Table 3 Average emotion recognition rates for BES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 6999 9824 9852 9815 9750 9815db6 6855 9565 9639 9731 9667 9713db10 6877 9852 9778 9769 9685 9639db44 6743 9870 9843 9898 9889 9861
kNNdb3 5914 9519 9657 9611 9583 9630db6 5868 8972 8731 9130 9065 9167db10 5793 9704 9657 9657 9546 9528db44 5763 9546 9556 9556 9500 9611
Speaker independentELM kernel
db3 5661 9604 9707 9724 9640 9640db6 5470 9226 9126 9183 9162 9148db10 5208 9212 9413 9337 9300 9293db44 5360 9304 9313 9410 9367 9433
kNNdb3 4912 9175 9332 9201 9279 9390db6 4821 8193 8222 8143 8218 8277db10 4517 9064 8981 8946 9023 9015db44 4687 9169 9015 9057 9035 9199
Table 4 Average emotion recognition rates for SAVEE database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 5563 9635 9677 9521 9583 9604db6 5563 9635 9552 9760 9573 9635db10 5823 9677 9135 9260 9333 9167db44 5833 9604 9552 9563 9583 9635
119896NNdb3 4708 9063 8990 9052 9156 9177db6 4781 9354 9281 9427 9229 9375db10 4656 9323 9396 9333 9260 9417db44 5031 9021 9104 9177 9010 9135
Speaker independentELM kernel
db3 2792 7000 6917 6854 7021 7000db6 3104 6792 7271 7375 7625 7625db10 3104 7792 7688 7688 7688 7667db44 3146 7083 7646 7604 7625 7667
kNNdb3 2875 6396 6250 6250 6313 6438db6 2792 6375 6604 6542 6625 6625db10 2792 6917 6750 6750 6750 6771db44 2750 6417 6250 6271 6167 6250
10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 7
of (005 and 01 SET1 001 and 005 SET2 001 and 0001SET3 0001 and 00001 SET4)119901 values In a feature entry stepthe features that provide the most significant performanceimprovement will be entered in the feature model if the 119901value lt 005 In the feature removal step attributes whichdo not significantly affect the performance of the classifierswill be removed if the 119901 value gt 01 SWLDA was applied tothe enhanced feature set to select best features and to removeirrelevant features
The details of the number of selected enhanced featuresfor every combination were tabulated in Table 2 FromTable 2 it can be seen that the enhanced relative energy andentropy features of the speech signals were more significantthan the glottal signals Approximately between 32 and82 of insignificant enhanced features were removed in allthe combination of 119901 values (005 and 01 001 and 005001 and 0001 and 0001 and 00001) and speaker-dependentand speaker-independent emotion recognition experimentswere carried out using these significant enhanced featuresThe results were compared with the original raw relativewavelet packet energy and entropy features and some of thesignificant works in the literature
35 Classifiers
351 119896-Nearest Neighbor Classifier 119896NN classifier is a type ofinstance-based classifiers and predicts the correct class labelfor the new test vector by relating the unknown test vector toknown training vectors according to some distancesimilarityfunction [25] Euclidean distance function was used andappropriate 119896-value was found by searching a value between1 and 20
352 Extreme Learning Machine A new learning algorithmfor the single hidden layer feedforward networks (SLFNs)called ELM was proposed by Huang et al [45ndash48] It hasbeenwidely used in various applications to overcome the slowtraining speed and overfitting problems of the conventionalneural network learning algorithms [45ndash48] The brief ideaof ELM is as follows [45ndash48]
For the given 119873 training samples the output of a SLFNnetwork with 119871 hidden nodes can be expressed as thefollowing
119891119871
(119909119895
) =
119871
sum
119894
120573119894
119892 (119908119894
sdot 119909119895
+ 119887119894
) 119895 = 1 2 3 119873 (10)
It can be written as 119891(119909) = ℎ(119909)120573 where 119909119895
119908119894
and 119887119894
are the input training vector input weights and biases tothe hidden layer respectively 120573
119894
are the output weights thatlink the 119894th hidden node to the output layer and 119892(sdot) is theactivation function of the hidden nodes Training a SLFNis simply finding a least-square solution by using Moore-Penrose generalized inverse
120573 = 119867dagger119879 (11)
where 119867dagger = (1198671015840
119867)minus1
1198671015840 or 1198671015840(1198671198671015840)minus1 depending on the
singularity of1198671015840119867 or1198671198671015840 Assume that1198671015840119867 is not singular
the coefficient 1120576 (120576 is positive regularization coefficient) isadded to the diagonal of1198671015840119867 in the calculation of the outputweights 120573
119894
Hence more stable learning system with bettergeneralization performance can be obtained
The output function of ELM can be written compactly as
119891 (119909) = ℎ (119909)1198671015840
(1
120576+ 119867119867
1015840
)
minus1
119879 (12)
In this ELM kernel implementation the hidden layer featuremappings need not be known to users and Gaussian kernelwas used Best values for positive regularization coefficient(120576) as 1 and Gaussian kernel parameter as 10 were foundempirically after several experiments
4 Experimental Results and Discussions
This section describes the average emotion recognition ratesobtained for speaker-dependent and speaker-independentemotion recognition environments using proposed meth-ods In order to demonstrate the robustness of the pro-posed methods 3 different emotional speech databases wereused Amongst 2 of them were recorded using professionalactorsactresses and 1 of them was recorded using universitystudents The average emotion recognition rates for theoriginal raw and enhanced relative wavelet packet energyand entropy features and for best enhanced features weretabulated in Tables 3 4 and 5 Table 3 shows the resultsfor the BES database 119896NN and ELM kernel classifiers wereused for emotion recognition From the results ELM kernelalways performs better compared to 119896NN classifier in termsof average emotion recognition rates irrespective of differentorders of ldquodbrdquo wavelets Under speaker-dependent experi-mentmaximumaverage emotion recognition rates of 6999and 9898 were obtained with ELM kernel classifier usingthe raw and enhanced relative wavelet packet energy andentropy features respectively Under speaker-independentexperiment maximum average emotion recognition rates of5661 and 9724 were attained with ELM kernel classifierusing the raw and enhanced relative wavelet packet energyand entropy features respectively 119896NN classifier gives onlymaximum average recognition rates of 5914 and 4912under speaker-dependent and speaker-independent experi-ment respectively
The average emotion recognition rates for SAVEEdatabase are tabulated in Table 4 Only audio signals fromSAVEE database were used for emotion recognition experi-ment According to Table 4 ELM kernel has achieved betteraverage emotion recognition of 5833 than 119896NN clas-sifier which gives only 5031 using all the raw relativewavelet packet energy and entropy features under speaker-dependent experiment Similarly maximum emotion recog-nition rates of 3146 and 2875 were obtained underspeaker-independent experiment using ELMkernel and 119896NNclassifier respectively
After GMMbased feature enhancement average emotionrecognition rate was improved to 9760 and 9427 usingELM kernel classifier and 119896NN classifier under speaker-dependent experiment During speaker-independent experi-ment maximum average emotion recognition rates of 7792
8 Mathematical Problems in Engineering
Table2Num
bero
fsele
cted
enhanced
features
usingSW
LDA
Different
orderldquodbrdquo
wavele
ts119875value
BES
SAVEE
SES
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
db3
005ndash0
121
2612
1218
2110
1319
2516
19001ndash0
05
1722
811
1720
710
1624
1316
0001ndash001
1618
78
1417
65
1522
58
000
01ndash0
001
713
57
1313
55
818
56
db6
005ndash0
118
2313
1418
2017
1918
2313
14001ndash0
05
1322
712
1621
1717
1322
712
0001ndash001
1219
710
1319
1110
1219
710
000
01ndash0
001
1413
77
1319
1110
1413
77
db10
005ndash0
122
2212
125
94
420
2312
13001ndash0
05
1717
1110
59
44
1919
1212
0001ndash001
1415
67
59
44
1618
99
000
01ndash0
001
1415
65
59
43
1211
68
db44
005ndash0
125
2714
1514
207
1125
2714
15001ndash0
05
2024
99
1420
710
2024
99
0001ndash001
1515
87
1419
69
1515
87
000
01ndash0
001
1213
45
1318
53
1213
45
Mathematical Problems in Engineering 9
Table 3 Average emotion recognition rates for BES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 6999 9824 9852 9815 9750 9815db6 6855 9565 9639 9731 9667 9713db10 6877 9852 9778 9769 9685 9639db44 6743 9870 9843 9898 9889 9861
kNNdb3 5914 9519 9657 9611 9583 9630db6 5868 8972 8731 9130 9065 9167db10 5793 9704 9657 9657 9546 9528db44 5763 9546 9556 9556 9500 9611
Speaker independentELM kernel
db3 5661 9604 9707 9724 9640 9640db6 5470 9226 9126 9183 9162 9148db10 5208 9212 9413 9337 9300 9293db44 5360 9304 9313 9410 9367 9433
kNNdb3 4912 9175 9332 9201 9279 9390db6 4821 8193 8222 8143 8218 8277db10 4517 9064 8981 8946 9023 9015db44 4687 9169 9015 9057 9035 9199
Table 4 Average emotion recognition rates for SAVEE database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 5563 9635 9677 9521 9583 9604db6 5563 9635 9552 9760 9573 9635db10 5823 9677 9135 9260 9333 9167db44 5833 9604 9552 9563 9583 9635
119896NNdb3 4708 9063 8990 9052 9156 9177db6 4781 9354 9281 9427 9229 9375db10 4656 9323 9396 9333 9260 9417db44 5031 9021 9104 9177 9010 9135
Speaker independentELM kernel
db3 2792 7000 6917 6854 7021 7000db6 3104 6792 7271 7375 7625 7625db10 3104 7792 7688 7688 7688 7667db44 3146 7083 7646 7604 7625 7667
kNNdb3 2875 6396 6250 6250 6313 6438db6 2792 6375 6604 6542 6625 6625db10 2792 6917 6750 6750 6750 6771db44 2750 6417 6250 6271 6167 6250
10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of
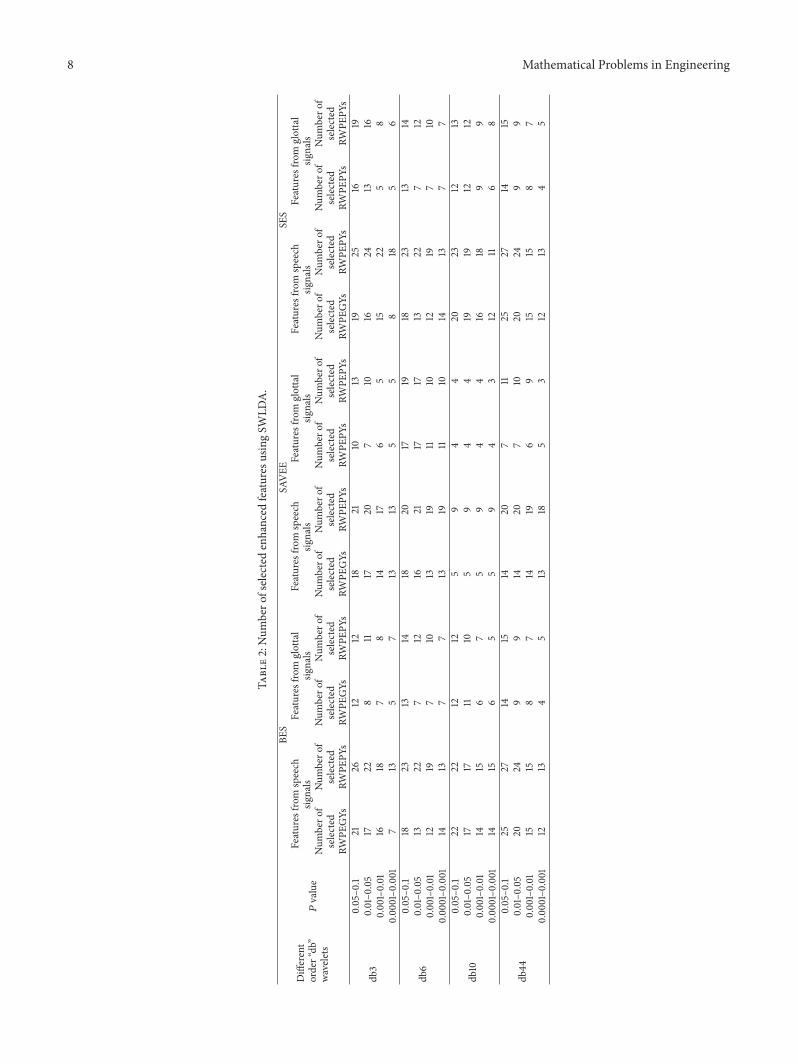
8 Mathematical Problems in Engineering
Table2Num
bero
fsele
cted
enhanced
features
usingSW
LDA
Different
orderldquodbrdquo
wavele
ts119875value
BES
SAVEE
SES
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Features
from
speech
signals
Features
from
glottal
signals
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
GYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
Num
bero
fselected
RWPE
PYs
db3
005ndash0
121
2612
1218
2110
1319
2516
19001ndash0
05
1722
811
1720
710
1624
1316
0001ndash001
1618
78
1417
65
1522
58
000
01ndash0
001
713
57
1313
55
818
56
db6
005ndash0
118
2313
1418
2017
1918
2313
14001ndash0
05
1322
712
1621
1717
1322
712
0001ndash001
1219
710
1319
1110
1219
710
000
01ndash0
001
1413
77
1319
1110
1413
77
db10
005ndash0
122
2212
125
94
420
2312
13001ndash0
05
1717
1110
59
44
1919
1212
0001ndash001
1415
67
59
44
1618
99
000
01ndash0
001
1415
65
59
43
1211
68
db44
005ndash0
125
2714
1514
207
1125
2714
15001ndash0
05
2024
99
1420
710
2024
99
0001ndash001
1515
87
1419
69
1515
87
000
01ndash0
001
1213
45
1318
53
1213
45
Mathematical Problems in Engineering 9
Table 3 Average emotion recognition rates for BES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 6999 9824 9852 9815 9750 9815db6 6855 9565 9639 9731 9667 9713db10 6877 9852 9778 9769 9685 9639db44 6743 9870 9843 9898 9889 9861
kNNdb3 5914 9519 9657 9611 9583 9630db6 5868 8972 8731 9130 9065 9167db10 5793 9704 9657 9657 9546 9528db44 5763 9546 9556 9556 9500 9611
Speaker independentELM kernel
db3 5661 9604 9707 9724 9640 9640db6 5470 9226 9126 9183 9162 9148db10 5208 9212 9413 9337 9300 9293db44 5360 9304 9313 9410 9367 9433
kNNdb3 4912 9175 9332 9201 9279 9390db6 4821 8193 8222 8143 8218 8277db10 4517 9064 8981 8946 9023 9015db44 4687 9169 9015 9057 9035 9199
Table 4 Average emotion recognition rates for SAVEE database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 5563 9635 9677 9521 9583 9604db6 5563 9635 9552 9760 9573 9635db10 5823 9677 9135 9260 9333 9167db44 5833 9604 9552 9563 9583 9635
119896NNdb3 4708 9063 8990 9052 9156 9177db6 4781 9354 9281 9427 9229 9375db10 4656 9323 9396 9333 9260 9417db44 5031 9021 9104 9177 9010 9135
Speaker independentELM kernel
db3 2792 7000 6917 6854 7021 7000db6 3104 6792 7271 7375 7625 7625db10 3104 7792 7688 7688 7688 7667db44 3146 7083 7646 7604 7625 7667
kNNdb3 2875 6396 6250 6250 6313 6438db6 2792 6375 6604 6542 6625 6625db10 2792 6917 6750 6750 6750 6771db44 2750 6417 6250 6271 6167 6250
10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of
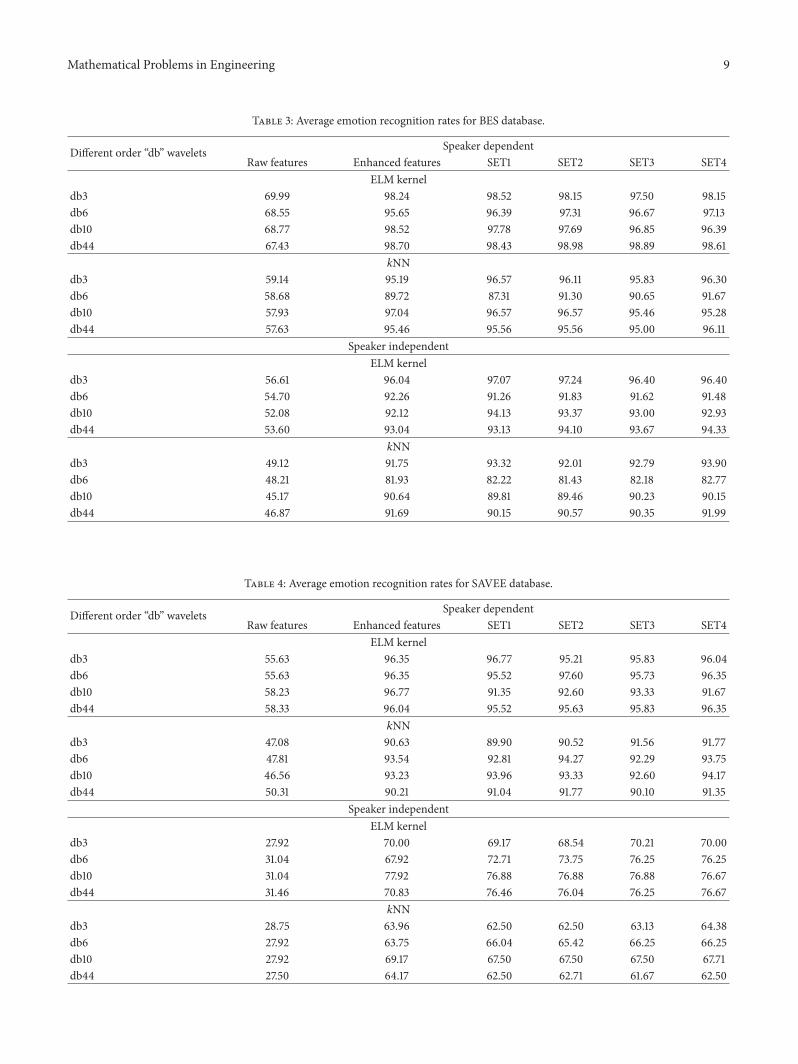
Mathematical Problems in Engineering 9
Table 3 Average emotion recognition rates for BES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 6999 9824 9852 9815 9750 9815db6 6855 9565 9639 9731 9667 9713db10 6877 9852 9778 9769 9685 9639db44 6743 9870 9843 9898 9889 9861
kNNdb3 5914 9519 9657 9611 9583 9630db6 5868 8972 8731 9130 9065 9167db10 5793 9704 9657 9657 9546 9528db44 5763 9546 9556 9556 9500 9611
Speaker independentELM kernel
db3 5661 9604 9707 9724 9640 9640db6 5470 9226 9126 9183 9162 9148db10 5208 9212 9413 9337 9300 9293db44 5360 9304 9313 9410 9367 9433
kNNdb3 4912 9175 9332 9201 9279 9390db6 4821 8193 8222 8143 8218 8277db10 4517 9064 8981 8946 9023 9015db44 4687 9169 9015 9057 9035 9199
Table 4 Average emotion recognition rates for SAVEE database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 5563 9635 9677 9521 9583 9604db6 5563 9635 9552 9760 9573 9635db10 5823 9677 9135 9260 9333 9167db44 5833 9604 9552 9563 9583 9635
119896NNdb3 4708 9063 8990 9052 9156 9177db6 4781 9354 9281 9427 9229 9375db10 4656 9323 9396 9333 9260 9417db44 5031 9021 9104 9177 9010 9135
Speaker independentELM kernel
db3 2792 7000 6917 6854 7021 7000db6 3104 6792 7271 7375 7625 7625db10 3104 7792 7688 7688 7688 7667db44 3146 7083 7646 7604 7625 7667
kNNdb3 2875 6396 6250 6250 6313 6438db6 2792 6375 6604 6542 6625 6625db10 2792 6917 6750 6750 6750 6771db44 2750 6417 6250 6271 6167 6250
10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

10 Mathematical Problems in Engineering
Table 5 Average emotion recognition rates for SES database
Different order ldquodbrdquo wavelets Speaker dependentRaw features Enhanced features SET1 SET2 SET3 SET4
ELM kerneldb3 4193 8992 9038 8900 8846 8621db6 4214 9279 9121 9204 9063 9121db10 4090 8883 8996 9004 8858 8867db44 4238 9000 8979 8883 8467 8213
kNNdb3 3115 7779 7950 7800 7842 7688db6 3280 8179 8217 8296 8146 8163db10 3123 7863 7938 8008 7979 8108db44 3208 7879 7938 7825 7463 7371
Speaker independentELM kernel
db3 2725 7875 7917 7825 7850 7750db6 2600 8367 8375 8458 8358 8342db10 2708 7942 8042 8025 8033 7992db44 2600 8050 8092 7867 7633 7492
kNNdb3 2592 6933 6967 6792 6817 6683db6 2550 7192 7367 7400 7217 7350db10 2633 7000 7100 7108 7117 7092db44 2467 6758 6950 6808 6608 6783
(ELM kernel) and 6917 (119896NN) were achieved using theenhanced relativewavelet packet energy and entropy featuresTable 5 shows the average emotion recognition rates forSES database As emotional speech signals were recordedfrom nonprofessional actorsactresses the average emo-tion recognition rates were reduced to 4214 and 2725under speaker-dependent and speaker-independent exper-iment respectively Using our proposed GMM based fea-ture enhancement method the average emotion recognitionrates were increased to 9279 and 8458 under speaker-dependent and speaker-independent experiment respec-tively The superior performance of the proposed methodsin all the experiments is mainly due to GMM based featureenhancement and ELM kernel classifier
A paired 119905-test was performed on the emotion recog-nition rates obtained using the raw and enhanced relativewavelet packet energy and entropy features respectively withthe significance level of 005 In almost all cases emotionrecognition rates obtained using enhanced features weresignificantly better than using raw features The results ofthe proposed method cannot be compared directly to theliterature presented in Table 1 since the division of datasetsis inconsistent the number of emotions used the numberof datasets used inconsistency in the usage of simulated ornaturalistic speech emotion databases and lack of uniformityin computation and presentation of the results Most of theresearchers have widely used 10-fold cross validation andconventional validation (one training set + one testing set)and some of them have tested their methods under speaker-dependent speaker-independent gender-dependent and
gender-independent environments However in this workthe proposed algorithms have been tested with 3 differentemotional speech corpora and also under speaker-dependentand speaker-independent environments The proposed algo-rithms have yielded better emotion recognition rates underboth speaker-dependent and speaker-independent environ-ments compared to most of the significant works presentedin Table 1
5 Conclusions
This paper proposes a new feature enhancement methodfor improving the multiclass emotion recognition based onGaussian mixture model Three different emotional speechdatabases were used to test the robustness of the proposedmethods Both emotional speech signals and its glottal wave-forms were used for emotion recognition experiments Theywere decomposed using discrete wavelet packet transformand relative wavelet packet energy and entropy featureswere extracted A new GMM based feature enhancementmethod was used to diminish the high within-class varianceand to escalate the between-class variance The significantenhanced features were found using stepwise linear discrimi-nant analysisThe findings show that the GMMbased featureenhancement method significantly enhances the discrimina-tory power of the relative wavelet packet energy and entropyfeatures and therefore the performance of the speech emotionrecognition system could be enhanced particularly in therecognition of multiclass emotions In the future work morelow-level and high-level speech features will be derived and
Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 11
tested by the proposed methods Other filter wrapper andembedded based feature selection algorithmswill be exploredand the results will be comparedThe proposed methods willbe tested under noisy environment and also in multimodalemotion recognition experiments
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This research is supported by a research grant under Funda-mental Research Grant Scheme (FRGS) Ministry of HigherEducation Malaysia (Grant no 9003-00297) and JournalIncentive Research Grants UniMAP (Grant nos 9007-00071and 9007-00117) The authors would like to express the deep-est appreciation to Professor Mohammad Hossein Sedaaghifrom Sahand University of Technology Tabriz Iran forproviding Sahand Emotional Speech database (SES) for ouranalysis
References
[1] S G Koolagudi and K S Rao ldquoEmotion recognition fromspeech a reviewrdquo International Journal of Speech Technologyvol 15 no 2 pp 99ndash117 2012
[2] R Corive E Douglas-Cowie N Tsapatsoulis et al ldquoEmotionrecognition in human-computer interactionrdquo IEEE Signal Pro-cessing Magazine vol 18 no 1 pp 32ndash80 2001
[3] D Ververidis and C Kotropoulos ldquoEmotional speech recogni-tion resources features andmethodsrdquo Speech Communicationvol 48 no 9 pp 1162ndash1181 2006
[4] M El Ayadi M S Kamel and F Karray ldquoSurvey on speechemotion recognition features classification schemes anddatabasesrdquo Pattern Recognition vol 44 no 3 pp 572ndash587 2011
[5] D Y Wong J D Markel and A H Gray Jr ldquoLeast squaresglottal inverse filtering from the acoustic speech waveformrdquoIEEE Transactions on Acoustics Speech and Signal Processingvol 27 no 4 pp 350ndash355 1979
[6] D E Veeneman and S L BeMent ldquoAutomatic glottal inversefiltering from speech and electroglottographic signalsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 33no 2 pp 369ndash377 1985
[7] P Alku ldquoGlottal wave analysis with pitch synchronous iterativeadaptive inverse filteringrdquo Speech Communication vol 11 no 2-3 pp 109ndash118 1992
[8] T Drugman B Bozkurt and T Dutoit ldquoA comparative studyof glottal source estimation techniquesrdquo Computer Speech andLanguage vol 26 no 1 pp 20ndash34 2012
[9] P A Naylor A Kounoudes J Gudnason and M BrookesldquoEstimation of glottal closure instants in voiced speech usingthe DYPSA algorithmrdquo IEEE Transactions on Audio Speech andLanguage Processing vol 15 no 1 pp 34ndash43 2007
[10] K E Cummings and M A Clements ldquoImprovements toand applications of analysis of stressed speech using glottalwaveformsrdquo in Proceedings of the IEEE International Conferenceon Acoustics Speech and Signal Processing (ICASSP 92) vol 2pp 25ndash28 San Francisco Calif USA March 1992
[11] K E Cummings and M A Clements ldquoApplication of theanalysis of glottal excitation of stressed speech to speakingstyle modificationrdquo in Proceedings of the IEEE InternationalConference on Acoustics Speech and Signal Processing (ICASSPrsquo93) pp 207ndash210 April 1993
[12] K E Cummings and M A Clements ldquoAnalysis of the glottalexcitation of emotionally styled and stressed speechrdquo Journal ofthe Acoustical Society of America vol 98 no 1 pp 88ndash98 1995
[13] E Moore II M Clements J Peifer and L Weisser ldquoInvestigat-ing the role of glottal features in classifying clinical depressionrdquoin Proceedings of the 25th Annual International Conference ofthe IEEE Engineering inMedicine and Biology Society pp 2849ndash2852 September 2003
[14] E Moore II M A Clements J W Peifer and L WeisserldquoCritical analysis of the impact of glottal features in the classi-fication of clinical depression in speechrdquo IEEE Transactions onBiomedical Engineering vol 55 no 1 pp 96ndash107 2008
[15] A Ozdas R G Shiavi S E Silverman M K Silverman andD M Wilkes ldquoInvestigation of vocal jitter and glottal flowspectrum as possible cues for depression and near-term suicidalriskrdquo IEEE Transactions on Biomedical Engineering vol 51 no9 pp 1530ndash1540 2004
[16] A I Iliev and M S Scordilis ldquoSpoken emotion recognitionusing glottal symmetryrdquo EURASIP Journal on Advances inSignal Processing vol 2011 Article ID 624575 pp 1ndash11 2011
[17] L He M Lech J Zhang X Ren and L Deng ldquoStudy of waveletpacket energy entropy for emotion classification in speech andglottal signalsrdquo in 5th International Conference on Digital ImageProcessing (ICDIP 13) vol 8878 of Proceedings of SPIE BeijingChina April 2013
[18] P Giannoulis and G Potamianos ldquoA hierarchical approachwith feature selection for emotion recognition from speechrdquoin Proceedings of the 8th International Conference on LanguageResources and Evaluation (LRECrsquo12) pp 1203ndash1206 EuropeanLanguage Resources Association Istanbul Turkey 2012
[19] F Burkhardt A Paeschke M Rolfes W Sendlmeier and BWeiss ldquoA database of German emotional speechrdquo inProceedingsof the 9th European Conference on Speech Communication andTechnology pp 1517ndash1520 Lisbon Portugal September 2005
[20] S Haq P J B Jackson and J Edge ldquoAudio-visual featureselection and reduction for emotion classificationrdquo in Proceed-ings of the International Conference on Auditory-Visual SpeechProcessing (AVSP 08) pp 185ndash190 Tangalooma Australia2008
[21] M Sedaaghi ldquoDocumentation of the sahand emotional speechdatabase (SES)rdquo Tech Rep Department of Electrical Engineer-ing Sahand University of Technology Tabriz Iran 2008
[22] L R Rabiner and B-H Juang Fundamentals of Speech Recog-nition vol 14 PTR Prentice Hall Englewood Cliffs NJ USA1993
[23] M Hariharan C Y Fook R Sindhu B Ilias and S Yaacob ldquoAcomparative study of wavelet families for classification of wristmotionsrdquo Computers amp Electrical Engineering vol 38 no 6 pp1798ndash1807 2012
[24] M Hariharan K Polat R Sindhu and S Yaacob ldquoA hybridexpert system approach for telemonitoring of vocal fold pathol-ogyrdquo Applied Soft Computing Journal vol 13 no 10 pp 4148ndash4161 2013
[25] M Hariharan K Polat and S Yaacob ldquoA new feature constitut-ing approach to detection of vocal fold pathologyrdquo InternationalJournal of Systems Science vol 45 no 8 pp 1622ndash1634 2014
12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

12 Mathematical Problems in Engineering
[26] M Hariharan S Yaacob and S A Awang ldquoPathological infantcry analysis using wavelet packet transform and probabilisticneural networkrdquo Expert Systems with Applications vol 38 no12 pp 15377ndash15382 2011
[27] K S Rao S G Koolagudi and R R Vempada ldquoEmotion recog-nition from speech using global and local prosodic featuresrdquoInternational Journal of Speech Technology vol 16 no 2 pp 143ndash160 2013
[28] Y Li G Zhang and Y Huang ldquoAdaptive wavelet packet filter-bank based acoustic feature for speech emotion recognitionrdquo inProceedings of 2013 Chinese Intelligent Automation ConferenceIntelligent Information Processing vol 256 of Lecture Notes inElectrical Engineering pp 359ndash366 Springer Berlin Germany2013
[29] MHariharan K Polat andR Sindhu ldquoA newhybrid intelligentsystem for accurate detection of Parkinsonrsquos diseaserdquo ComputerMethods and Programs in Biomedicine vol 113 no 3 pp 904ndash913 2014
[30] S R Krothapalli and S G Koolagudi ldquoCharacterization andrecognition of emotions from speech using excitation sourceinformationrdquo International Journal of Speech Technology vol 16no 2 pp 181ndash201 2013
[31] R Farnoosh and B Zarpak ldquoImage segmentation using Gaus-sian mixture modelrdquo IUST International Journal of EngineeringScience vol 19 pp 29ndash32 2008
[32] Z Zivkovic ldquoImproved adaptive Gaussian mixture model forbackground subtractionrdquo inProceedings of the 17th InternationalConference on Pattern Recognition (ICPR rsquo04) pp 28ndash31 August2004
[33] A Blake C Rother M Brown P Perez and P Torr ldquoInteractiveimage segmentation using an adaptive GMMRF modelrdquo inComputer VisionmdashECCV 2004 vol 3021 of Lecture Notes inComputer Science pp 428ndash441 Springer Berlin Germany2004
[34] VMajidnezhad and I Kheidorov ldquoA novel GMM-based featurereduction for vocal fold pathology diagnosisrdquo Research Journalof Applied Sciences vol 5 no 6 pp 2245ndash2254 2013
[35] D A Reynolds T F Quatieri and R B Dunn ldquoSpeakerverification using adapted Gaussian mixture modelsrdquo DigitalSignal Processing A Review Journal vol 10 no 1 pp 19ndash412000
[36] A I Iliev M S Scordilis J P Papa and A X Falcao ldquoSpokenemotion recognition through optimum-path forest classifica-tion using glottal featuresrdquo Computer Speech and Language vol24 no 3 pp 445ndash460 2010
[37] M H Siddiqi R Ali M S Rana E-K Hong E S Kim and SLee ldquoVideo-based human activity recognition using multilevelwavelet decomposition and stepwise linear discriminant analy-sisrdquo Sensors vol 14 no 4 pp 6370ndash6392 2014
[38] J Rong G Li and Y-P P Chen ldquoAcoustic feature selectionfor automatic emotion recognition from speechrdquo InformationProcessing amp Management vol 45 no 3 pp 315ndash328 2009
[39] J Jiang Z Wu M Xu J Jia and L Cai ldquoComparing featuredimension reduction algorithms for GMM-SVM based speechemotion recognitionrdquo in Proceedings of the Asia-Pacific Signaland Information Processing Association Annual Summit andConference (APSIPA 13) pp 1ndash4 Kaohsiung Taiwan October-November 2013
[40] P Fewzee and F Karray ldquoDimensionality reduction for emo-tional speech recognitionrdquo in Proceedings of the InternationalConference on Privacy Security Risk and Trust (PASSAT rsquo12) and
International Confernece on Social Computing (SocialCom rsquo12)pp 532ndash537 Amsterdam The Netherlands September 2012
[41] S Zhang andX Zhao ldquoDimensionality reduction-based spokenemotion recognitionrdquo Multimedia Tools and Applications vol63 no 3 pp 615ndash646 2013
[42] B-C Chiou and C-P Chen ldquoFeature space dimension reduc-tion in speech emotion recognition using support vectormachinerdquo in Proceedings of the Asia-Pacific Signal and Infor-mation Processing Association Annual Summit and Conference(APSIPA rsquo13) pp 1ndash6 Kaohsiung Taiwan November 2013
[43] S Zhang B Lei A Chen C Chen and Y Chen ldquoSpokenemotion recognition using local fisher discriminant analysisrdquo inProceedings of the IEEE 10th International Conference on SignalProcessing (ICSP rsquo10) pp 538ndash540 October 2010
[44] D J Krusienski E W Sellers D J McFarland T M Vaughanand J R Wolpaw ldquoToward enhanced P300 speller perfor-mancerdquo Journal of Neuroscience Methods vol 167 no 1 pp 15ndash21 2008
[45] G-B Huang H Zhou X Ding and R Zhang ldquoExtreme learn-ing machine for regression and multiclass classificationrdquo IEEETransactions on Systems Man and Cybernetics B Cyberneticsvol 42 no 2 pp 513ndash529 2012
[46] G-B Huang Q-Y Zhu and C-K Siew ldquoExtreme learningmachine theory and applicationsrdquoNeurocomputing vol 70 no1ndash3 pp 489ndash501 2006
[47] W Huang N Li Z Lin et al ldquoLiver tumor detection andsegmentation using kernel-based extreme learningmachinerdquo inProceedings of the 35th Annual International Conference of theIEEE Engineering in Medicine and Biology Society (EMBC rsquo13)pp 3662ndash3665 Osaka Japan July 2013
[48] S Ding Y Zhang X Xu and L Bao ldquoA novel extremelearning machine based on hybrid kernel functionrdquo Journal ofComputers vol 8 no 8 pp 2110ndash2117 2013
[49] A Shahzadi A Ahmadyfard A Harimi and K YaghmaieldquoSpeech emotion recognition using non-linear dynamics fea-turesrdquo Turkish Journal of Electrical Engineering amp ComputerSciences 2013
[50] P Henrıquez J B Alonso M A Ferrer C M Travieso andJ R Orozco-Arroyave ldquoApplication of nonlinear dynamicscharacterization to emotional speechrdquo inAdvances in NonlinearSpeech Processing vol 7015 ofLectureNotes inComputer Sciencepp 127ndash136 Springer Berlin Germany 2011
[51] S Wu T H Falk and W-Y Chan ldquoAutomatic speech emotionrecognition using modulation spectral featuresrdquo Speech Com-munication vol 53 no 5 pp 768ndash785 2011
[52] S R Krothapalli and S G Koolagudi ldquoEmotion recognitionusing vocal tract informationrdquo in Emotion Recognition UsingSpeech Features pp 67ndash78 Springer Berlin Germany 2013
[53] M Kotti and F Paterno ldquoSpeaker-independent emotion recog-nition exploiting a psychologically- inspired binary cascadeclassification schemardquo International Journal of Speech Technol-ogy vol 15 no 2 pp 131ndash150 2012
[54] A S Lampropoulos and G A Tsihrintzis ldquoEvaluation ofMPEG-7 descriptors for speech emotional recognitionrdquo inProceedings of the 8th International Conference on IntelligentInformation Hiding andMultimedia Signal Processing (IIH-MSPrsquo12) pp 98ndash101 2012
[55] N Banda and P Robinson ldquoNoise analysis in audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Multimodal Interaction pp 1ndash4 Alicante Spain November2011
Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 13
[56] N S Fulmare P Chakrabarti and D Yadav ldquoUnderstandingand estimation of emotional expression using acoustic analysisof natural speechrdquo International Journal on Natural LanguageComputing vol 2 no 4 pp 37ndash46 2013
[57] S Haq and P Jackson ldquoSpeaker-dependent audio-visual emo-tion recognitionrdquo in Proceedings of the International Conferenceon Audio-Visual Speech Processing pp 53ndash58 2009
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of