resilient distributed datasets
TRANSCRIPT

RESILIENT DISTRIBUTED DATASETS:A FAULT-TOLERANT ABSTRACTION FOR
IN-MEMORY CLUSTER COMPUTING
Matei Zaharia et al.University of California, Berkeley

Alessandro MenabòPolitecnico di Torino, Italy

INTRODUCTION

Motivations
Interactive (real-time) data mining
Reuse of intermediate results (iterative algorithms)
Examples:
Machine learning
K-means clustering
PageRank

Limitations of current frameworks
Data reuse usually through disk storage
Disk IO latency and serialization
Too high-level abstractions
Implicit memory management
Implicit work distribution
Fault tolerance through data replication and logging
High network traffic

Goals
Keep frequently used data in main memory
Efficient fault recovery
Log data transformations rather than data itself
User control

RESILIENT DISTRIBUTED DATASETS (RDDs)

What is an RDD?
Read-only, partitioned collection of records in key-value form
Created through transformations
From stored data or other RDDs
Coarse-grained: same operation on the whole dataset
Examples: map, filter, join
Lineage: sequence of transformations that created the RDD
Key to efficient fault recovery
Used through actions
Return a result or store data
Examples: count, collect, save

What is an RDD? (cont’d)
Lazy computation
RDDs are computed only when the first action is invoked
Persistence control
Choose RDDs to be reused, and how to store them (e.g. in memory)
Partitioning control
Define how to distribute RDDs across cluster nodes
Minimize inter-node communication

Implementation
Apache Spark cluster computing framework
Open source
Based on Hadoop Distributed File System (HDFS) (by Apache)
Scala programming language
Derived from Java, compiles to Java bytecode
Object-oriented and functional programming
Statically typed, efficient and concise

Spark programming interface
Driver program
Defines and invokes actions on RDDs
Tracks RDDs’ lineage
Assigns workload to workers
Workers
Persistent processes on cluster nodes
Perform actions on data
Can store partitions of RDDs in RAM
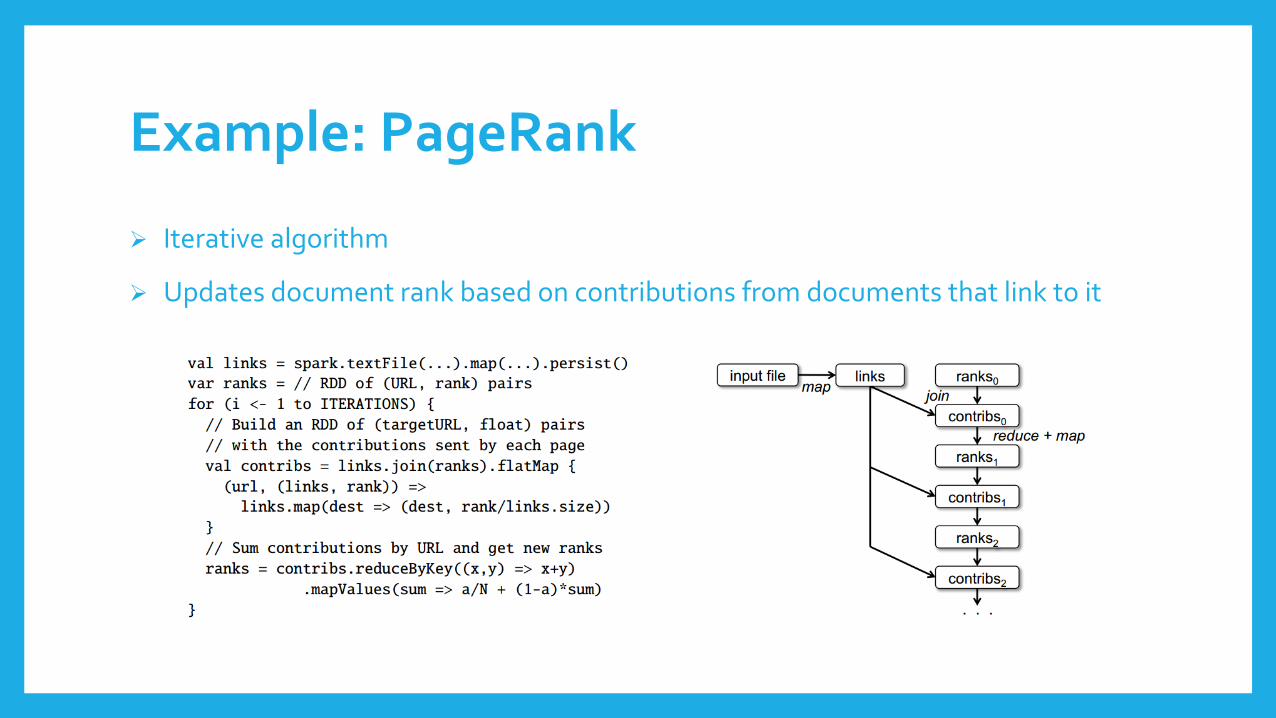
Example: PageRank
Iterative algorithm
Updates document rank based on contributions from documents that link to it

Example: PageRank (cont’d)
The graph grows with the number of iterations
Replicate some intermediate results to speedupfault recovery
Reduce communication overhead
Partition both links and ranks by URL in the sameway
Joining them can be done on the same node

RDD representation
Goals
Easily track lineage
Support rich set of transformations
Keep system as simple as possible (uniform interface, avoid ad-hoc logic)
Graph-based structure
Set of partitions (pieces of the dataset)
Set of dependencies on parent RDDs
Function for computing the dataset from parent RDDs
Metadata about partitioning and data location

Dependencies
Narrow dependencies
Each partition of the parent is used by at mostone partition of the child
Example: map, filter, union
Wide dependencies
Each partition of the parent may be used by many partitions of the child
Example: join, groupByKey

Dependencies (cont’d)
Normal execution
Narrow pipelined (e.g. map + filter one element at a time)
Wide serial (all parents need to be available before computation starts)
Fault recovery
Narrow fast (only one parent partition has to be recomputed)
Wide full (one failed node may require all parents to be recomputed)

OVERVIEW OF SPARK
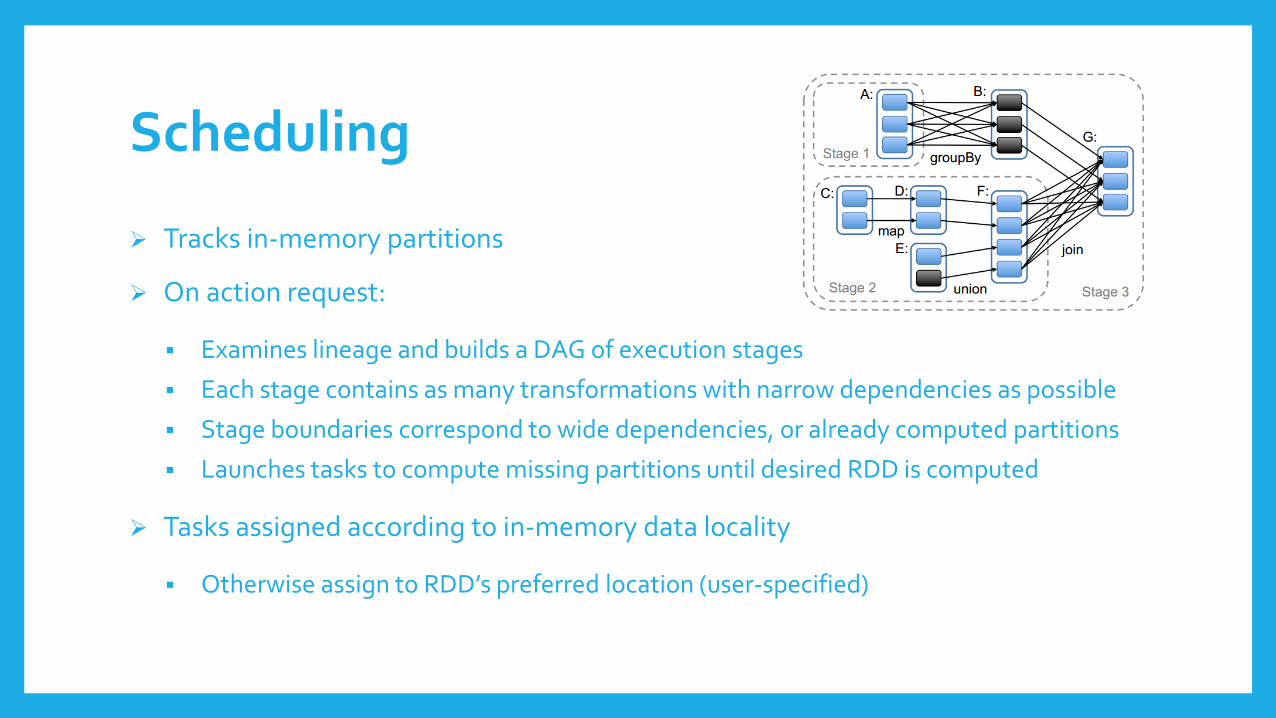
Scheduling
Tracks in-memory partitions
On action request:
Examines lineage and builds a DAG of execution stages
Each stage contains as many transformations with narrow dependencies as possible
Stage boundaries correspond to wide dependencies, or already computed partitions
Launches tasks to compute missing partitions until desired RDD is computed
Tasks assigned according to in-memory data locality
Otherwise assign to RDD’s preferred location (user-specified)

Scheduling (cont’d)
On task failure, re-run it on another node if all parents are still available
If stages become unavailable, re-run parent tasks in parallel
Scheduler failures not addressed
Replicate lineage graph?

Interactivity
Desirable given low-latency in-memory capabilities
Scala shell integration
Each line is compiled into a Java class and run in JVM
Bytecode shipped to workers via HTTP

Memory management
Persistent RDDs storage modes:
In-memory, deserialized object: fastest (native support by JVM)
In-memory, serialized object: more memory-efficient, but slower
On-disk: if RDD does not fit into RAM, but too costly to recompute every time
LRU eviction policy of entire RDD when new partition does not fit into RAM
Unless the new partition belongs to the LRU RDD
Separate memory space on each node

Checkpointing
Save intermediate RDDs to disk (replication)
Speedup recovery of RDDs with long lineage or wide dependencies
Pointless with short lineage or narrow dependencies (recomputing partitions in parallel isless costly than replicating the whole RDD)
Not strictly required, but nice to have
Easy because RDDs are read-only
No consistency issues or distributed coordination required
Done in the background, programs do not have to be suspended
Controlled by the user, no automatic checkpointing yet

EVALUATION

Testing environment
Amazon Elastic Compute Cloud (EC2)
m1.xlarge nodes
4 cores / node
15 GB of RAM / node
HDFS with 256 MB blocks
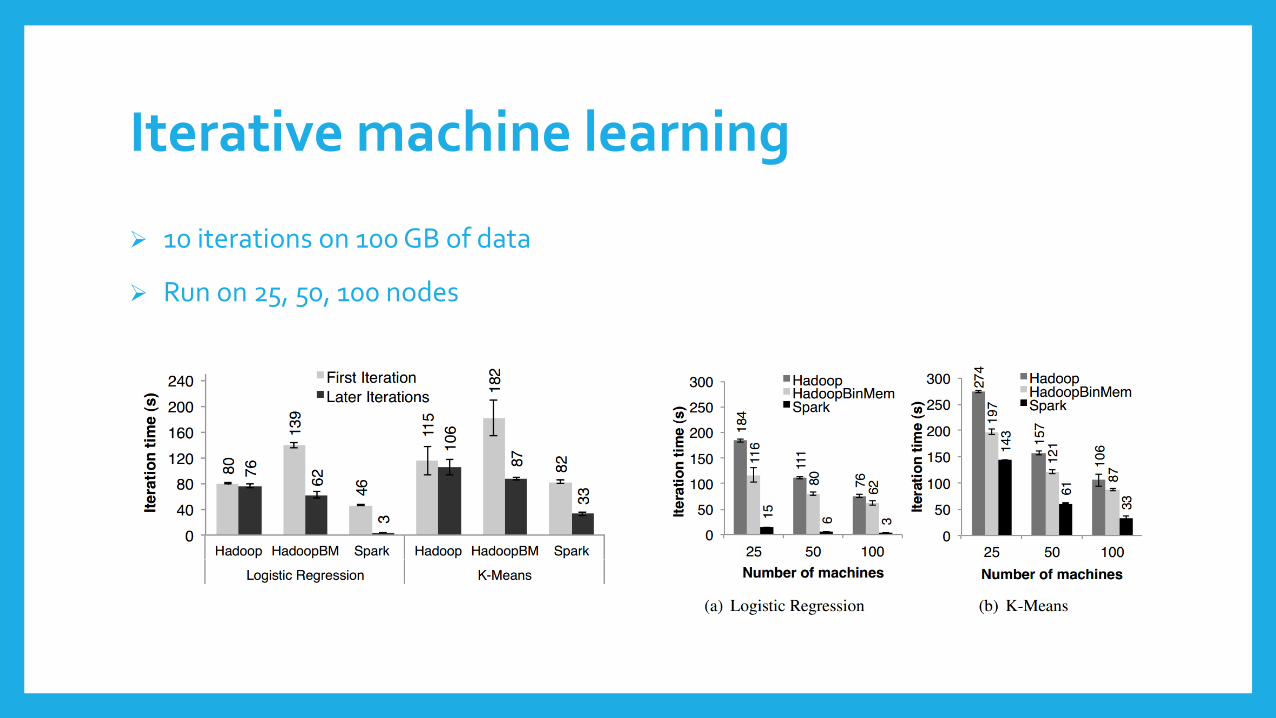
Iterative machine learning
10 iterations on 100 GB of data
Run on 25, 50, 100 nodes

Iterative machine learning (cont’d)
Different algorithms
K-means is more compute-intensive
Logistic regression is more sensitive to IO and deserialization
Minimum overhead in Spark
25.3× / 20.7× with logistic regression
3.2× / 1.9× with K-means
Outperforms even HadoopBinMem (in-memory binary data)
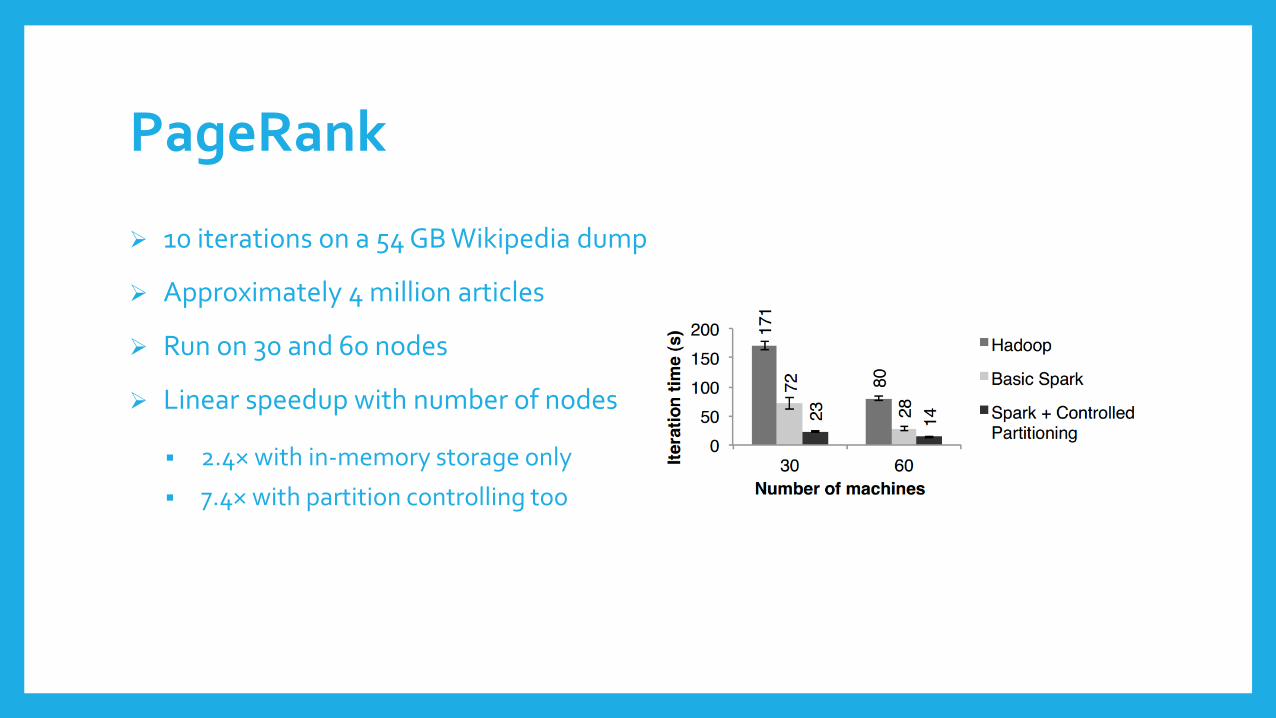
PageRank
10 iterations on a 54 GB Wikipedia dump
Approximately 4 million articles
Run on 30 and 60 nodes
Linear speedup with number of nodes
2.4× with in-memory storage only
7.4× with partition controlling too
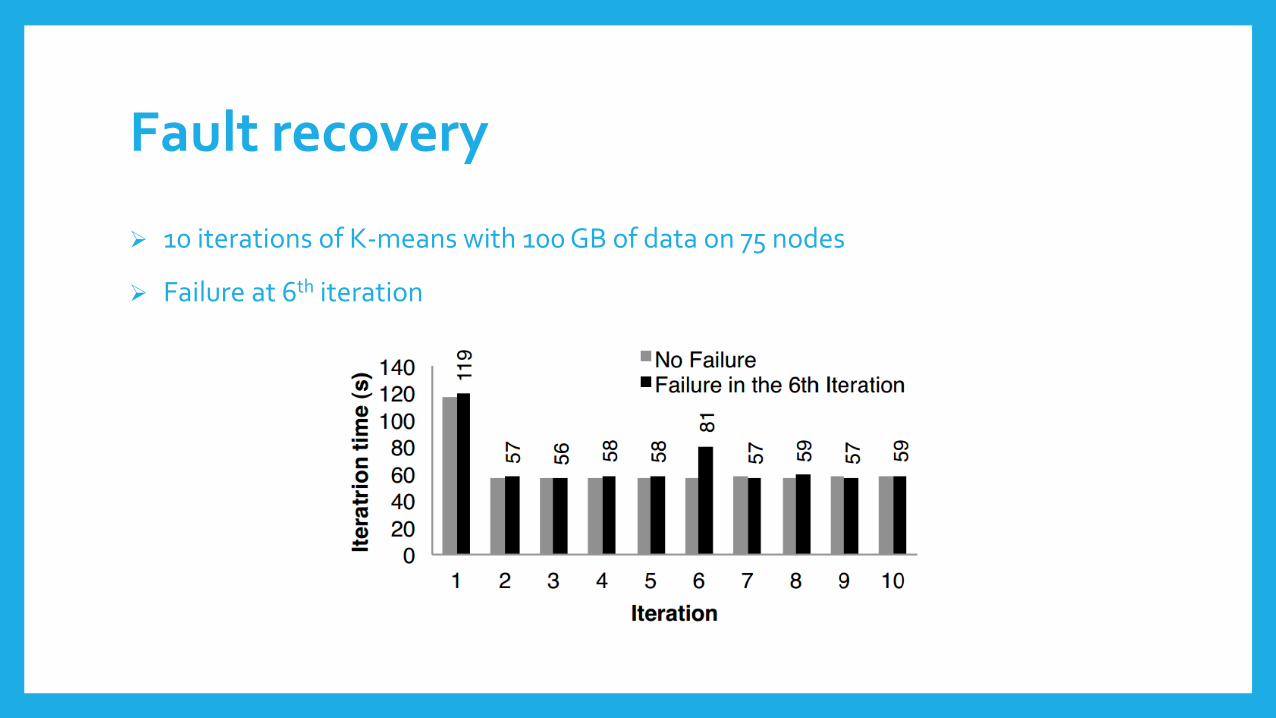
Fault recovery
10 iterations of K-means with 100 GB of data on 75 nodes
Failure at 6th iteration

Fault recovery (cont’d)
Loss of tasks and partitions on failed node
Task rescheduled on different nodes
Missing partitions recomputed in parallel
Lineage graphs less than 10 KB
Checkpointing would require
Running several iterations again
Replicate all 100 GB over the network
Consume twice the memory or write all 100 GB to disk
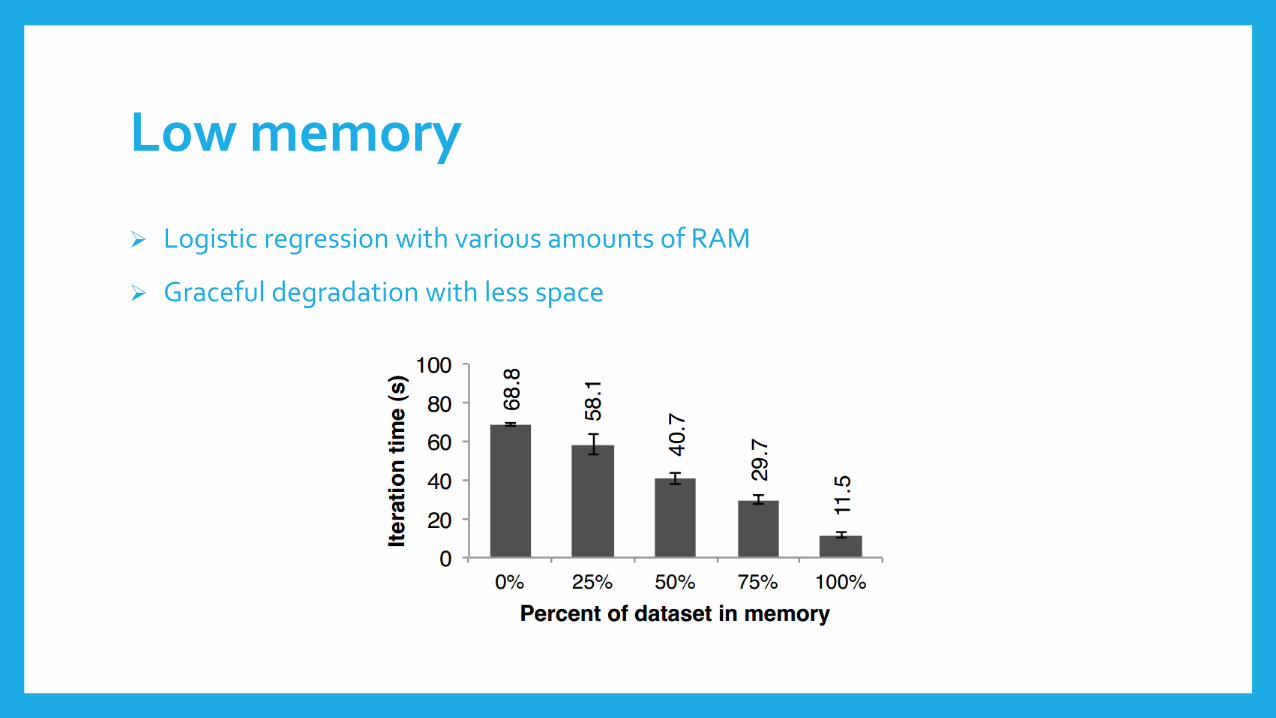
Low memory
Logistic regression with various amounts of RAM
Graceful degradation with less space
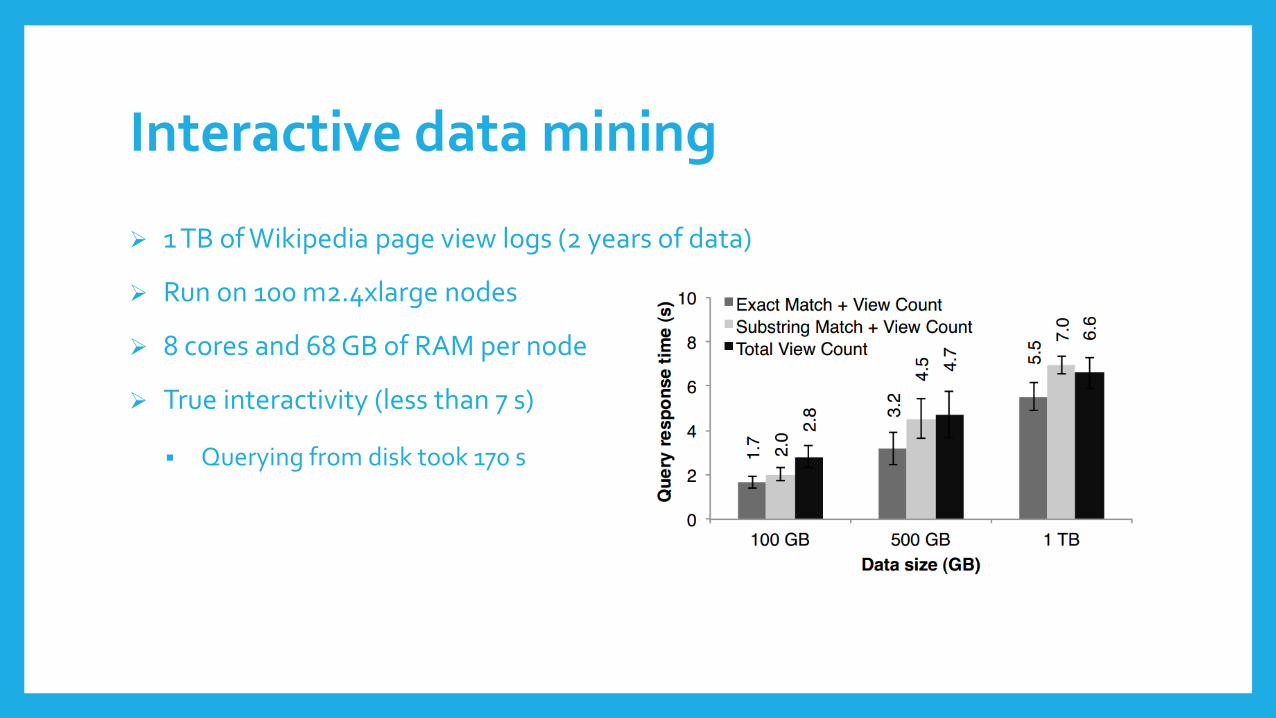
Interactive data mining
1 TB of Wikipedia page view logs (2 years of data)
Run on 100 m2.4xlarge nodes
8 cores and 68 GB of RAM per node
True interactivity (less than 7 s)
Querying from disk took 170 s

CONCLUSIONS

Applications
Nothing new under the sun
In-memory computing, lineage tracking, partitioning and fast recovery are alreadyavailable in other frameworks (separately)
RDDs can provide all these features in a single framework
RDDs can express existing cluster programming models
Same output, better performance
Examples: MapReduce, SQL, Google’s Pregel, batched stream processing (periodicallyupdating results with new data)

Advantages
Dramatic speedup with reused data (depending on application)
Fast fault recovery thanks to lightweight logging of transformations
Efficiency under control of user (storage, partitioning)
Graceful performance degradation with low RAM
High expressivity
Versatility
Interactivity
Open source

Limitations
Not suited for fine-grained transformations
Overhead from logging too many lineage graphs
Traditional data logging and checkpointing perform better

Thanks!