resynthesizing facial animation through 3d model … · resynthesizing facial animation through 3d...
TRANSCRIPT

Resynthesizing Facial Animation through 3D Model-Based Tracking
Frederic Pighiny Richard Szeliski z David H. Salesinyz
yUniversity of WashingtonzMicrosoft Research
AbstractGiven video footage of a person's face, we present new tech-niques to automatically recover the face position and the fa-cial expression from each frame in the video sequence. A 3Dface model is fitted to each frame using a continuous opti-mization technique. Our model is based on a set of 3D facemodels that are linearly combined using 3D morphing. Ourmethod has the advantages over previous techniques of fit-ting directly a realistic 3-dimensional face model and of re-covering parameters that can be used directly in an anima-tion system. We also explore many applications, includingperformance-driven animation (applying the recovered posi-tion and expression of the face to a synthetic character to pro-duce an animation that mimics the input video), relightingthe face, varying the camera position, and adding facial orna-ments such as tattoos and scars.
1 IntroductionThere are many techniques and tools that can be used to cre-ate facial animations. These tools can be as simple as a penciland a sketchpad or as complex as a physically-based 3D facemodel. In either case, creating believable facial animations isa very delicate task that only talented and well-trained ani-mators can achieve. An alternative is to generate facial ani-mations based on video footage of a real person's face. Theface can be tracked throughout the video by recovering theposition and expression at each frame. This information canthen be optionally modified further to create a novel anima-tion.
Recovering the face position and the facial expression au-tomatically from a video is a difficult problem. The difficultycomes from the wide range of appearances than can be gen-erated by the human face under different orientations, illu-mination conditions and facial expressions. The creation of amodel that encompasses these variations and allows the ro-bust estimation of the face parameters is thus a very challeng-ing task.
This problem can be made easier by using markers onthe face such as heavy makeup [23] or a set of colored dotsstuck onto the actor's face [12, 25]. Once the position of themarkers has been determined, the position of the face and
the facial features can easily be derived. Williams [25] pio-neered this technique, tracking 2D points on a single image.Guenter et al. [12] extended this approach to tracking pointsin 3D using multiple images.
The use of markers on the face limits the type of videothat can be processed; instead, computer vision techniquescan be leveraged to extract information from a video of an un-marked face. These tracking techniques can be classified intotwo groups depending on whether they use a two-dimensionalor three-dimensional model.
Two-dimensional facial feature trackers can be based ondeformable or rigid patches [3, 7, 13], or on edge or fea-ture detectors [4, 16, 18]. The use of a 2D model limits therange of face orientations that can be handled. For large vari-ations of face orientation, the three-dimensional properties ofthe face need to be modeled.
Different approaches have been taken to fit a 3D face modelto an image or a sequence of images. One approach is to builda physically-based model that describes the muscular struc-ture of the face. These models are fitted by computing whichset of muscle activations best correspond to the target image.Terzopoulos and Waters [23] estimated muscle contractionsfrom the displacement of a set of face markers. Other tech-niques compute an optical flow from the image sequence anddecompose the flow into muscle activations. Essa and Pent-land [11] built a physically-based face model and developeda control-theoretic technique to fit it to a sequence of images.Decarlo and Metaxas [8] employed a similar model that in-corporates possible variations in head shape using anthropo-metric measurements. Comparable techniques [1, 6, 17] areused in model-based image coding schemes where the modelparameters provide a compact representation of video frames.These approaches use a 3D articulated face model to derive amodel for facial motion. Using the estimated motion, the 3Dmodel can be animated to synthesize an animation similar tothe input sequence. However, the synthesized images are notused for the analysis.
More recent techniques employ an analysis-by-synthesisapproach where target face images are analyzed by compar-ing them to synthetic face images. La Cascia et al. [15] modelthe face with a texture-mapped cylinder. The textures are ex-

tracted by building a mosaic from the input image sequence.Schodl et al. [22] use a more detailed geometric model toestimate the face position and orientation. These two mod-els however allow neither the facial expression nor the iden-tity of the face in the target image to be estimated. Vetter andBlanz [24] built a more general statistical model of the humanface by processing a set of example faces that includes vari-ations in identity and expression. Their model consists of alinear combination of scanned 3D face models. They assumethat the head pose is known and compute which linear combi-nation of the sample faces best fit the target image. Vetter andBlanz's linear combination approach is similar to ours. Ourmorphing technique however is different. Their model sepa-rates shape and texture information. We believe these quan-tities are correlated, and we consider expression vectors thatinclude both shape and texture. Our goal too is different; wedo not attempt to estimate the identity of the person but ratherto track the person's facial expression and head pose.
In this paper, we present our model-based face trackingtechnique. Our technique consists of fitting a 3D face modelto each frame in the input video. This face model is based onthe work of Pighin et al. [20] and uses a linear combination of3D face models, each corresponding to a particular facial ex-pression. The use of realistic face models allows us to matchrealistic renderings of faces to the target images. Moreover,we directly recover parameters that can be used in an anima-tion system. To fit the model, we minimize an error functionover the set of facial expressions and face positions spannedby the model. The fitting process employs a continuous opti-mization technique.
Tracking faces can be employed to create novel facial an-imations. For instance the extracted facial parameters can bereused to animate synthetic faces. Such performance-drivenanimations produce a sequence that mimics the original inputvideo [10, 19, 25]. Performance-driven animations are usefulfor avatar control, identity hiding, and easy home-made ani-mations. Another application is to modify the input video toproduce a novel animation or special effects. For instance,Bregler et al. [5] segment the input video into small unitscorresponding to visemes. These video segments can then berescheduled according to a different soundtrack to produce anovel video.
In this paper, we present several applications. We reusethe recovered face parameters to generate performance-drivenanimations. Moreover, since the fitted model provides us withan approximation of the geometry of the face, we can alterthe input video. These alterations include changing the light-ing conditions, changing the camera angle, and adding facialdecorations such as tattoos and scars.
The remainder of this paper first describes the model fittingtechnique we developed and then illustrates several ways togenerate novel animations or special effects from the originalfootage.
1
w
w
0
α
α
ww*
0
2
1
Figure 1: Relationship between blending weights and expres-sion parameters with 3 basic expressions.
2 Model fittingIn this section, we describe how we build the face model andhow it is parameterized. We also discuss in detail the opti-mization technique used to fit the model to a sequence of im-ages.
2.1 3D face modelThe model we propose to fit to the video is a linear com-bination of 3D texture-mapped models, each correspondingto a particular basic facial expression. Examples of basic ex-pressions are joy, anger, sadness, surprise, disgust, pain. Byvarying locally the percentage of each basic expression ondifferent parts of the face, a wide range of expressions can begenerated.
We synthesize realistic face models using a technique de-veloped by Pighin et al. [20]. The 3D models are recoveredby fitting a generic face model to a set of photographs of aperson's face. The texture map is extracted by combining thedifferent photographs into a single cylindrical texture map.
Our model represents a full human head, but only the facialmask is parameterized, while the rest of the face (e.g., neckand hair) is constant. The face is parameterized by a vector ofparameters p = p1, ..., pn. These parameters form two subsets:the position parameters and the expression parameters. Theposition parameters include a translation t, which indicatesthe position of the center of the face, and a rotation R, whichindicates its orientation. The facial expression is determinedby a set of blending weights w1, ..., wn, one for each basicexpression in the model. We constrain these weights to sumto 1. To enforce this constraint, we use a set of expressionparameters �1, ...,�n�1, which are obtained by projecting theweights wk onto the hyperplane
Pk wk = 1. The vector of
blending weights w = (w1, ..., wn) is decomposed using thevector of expressions parameters � = (�1, ...,�n�1):

w = Q� + w� (1)
where Q is a matrix whose column vectors span the hyper-plane
Pk wk = 0 and w� is a vector belonging to
Pk wk = 1.
Figure 1 illustrates the relationship between the blendingweights and the expression parameters. To span a wider rangeof facial expressions, the face is split into several regions thatcan each be controlled independently. We thus use a set ofexpression parameters f�lg for each region. The partition weused in our experiments is shown in figure 2.
Rendering the model is done by linearly combining the ba-sic expressions using 3D morphing. A consensus geometry iscomputed by linearly interpolating the basic expression ge-ometries using the blending weights wk. The model is ren-dered multiple times, once for each basic expression. Theserenderings Ik, are then blended together using the weights wk
to produce the final image I:
I =X
k
wk Ik (2)
2.2 Optimization procedureFitting a linear combination of faces to an image has alreadybeen explored by different research groups. Edwards et al. [9]developed a model built out of registered face images. In theirwork, a principal component analysis is applied to the set offaces to extract a set of parameters. The dependencies be-tween the parameters and the images generated by the modelare approximated by a linear function. This approximation isthen used in an iterative optimization technique, using a vari-ant of the steepest descent algorithm. Jones and Poggio [14]constructed a similar 2D model and use a more sophisticatedfitting technique. They use a stochastic gradient method thatestimates the derivatives by sampling a small number of pix-els. The technique we develop uses second-order derivativesof the error function. We also investigate both analytical andfinite-difference computations of the partial derivatives.
To fit our model to a target face image It, we developedan optimization method whose goal is to compute the modelparameters p yielding a rendering of the model I(p) that bestresembles the target image. An error function �(p) is used toevaluate the discrepancy between It and I(p):
�(p) =12kIt � I(p)k
2+ D(p)
=12
Xj
[It(xj, yj)� I(p)(xj, yj)]2 + D(p)(3)
where (xj, yj) corresponds to a location of a pixel on the imageplane and D(p) is a penalty function that forces each blend-ing weight to remain close to the interval [0..1]. The functionD(p) is a piecewise-quadratic function of the following form:
Figure 2: Partitioning of the face. The different regions arerendered with different colors.
D(p) = cX
k
[min(0, wk)2 + max(0, wk � 1)2] (4)
where c is a constant.The parameters are fitted in several phases that optimize
different sets of parameters. We start by estimating the posi-tion parameters and then independently estimate the expres-sion parameters in each region. Treating these parameters in-dependently allows us to apply different optimization meth-ods to them. All the parameters are estimated using variantsof the Levenberg-Marquardt (LM) algorithm [21] to mini-mize the function �. We tried other optimization techniquessuch as steepest descent and Newton (BFGS), but the LMalgorithm produced better results for the estimation of the ex-pression parameters.
The LM algorithm is a continuous optimization techniquebased on a second-order Taylor expansion of �. This iterativealgorithm starts from an initial estimate of the parameters andcomputes at each iteration a new set of values that reduces �further. The parameters are updated by taking a step �p ateach iteration. This step is given by the expression:
[J(p)TJ(p) + �I + H(p)]�p = �J(p)T[It � I(p)]�rD(p)(5)
where I is the identity matrix, J(p) is the Jacobian of I(p),rD(p) and H(p) are the gradient and Hessian of D(p), respec-tively and � is a parameter used to stabilize the optimization.
2.3 Computing the Jacobian imagesWe explored two ways of computing the Jacobian J(p). Thefirst one uses finite differences and requires sampling the er-ror function multiple times at each iteration. The second one

Figure 3: Tracking sequence. The bottom row shows the result of fitting our model to the target images on the top row.
uses an analytical expression of the Jacobian and does not re-quire evaluating �. On the one hand, the analytical Jacobiancan be more efficient than the finite-difference approxima-tion if evaluating the error function is expensive. On the otherhand, using finite differences may produce better results ifthe error function is not smooth enough. In our case evalu-ating the error function is fairly time consuming because itinvolves rendering the 3D face model.
Finite differences
We use central differences to approximate the value of theJacobian. This is more costly than using forward differencesbut produces a better approximation of the derivatives. Eachentry of the Jacobian matrix is computed using the followingformula:
dIdpi
(p) �I(p +�piei)� I(p��piei)
2�pi(6)
where ei is the i-th vector of the canonical basis and �pi isa variation of the parameter pi. In practice, we determinedappropriate values for�pi by experimentation.
Analytical Jacobian
Given that I is a function of the position in the image plane(xj, yj) for a given pixel and of the model parameters pi, wehave:
dIdpi
=@ I@xj
@xj
@pi+
@ I@yj
@yj
@pi+
@ I@pi
, (7)
The vector ( @I@xj
, @I@yj
) is the intensity gradient of image I atpixel j. It is computed using a Sobel filter [2]. The par-
tial derivative @I@pi
can be computed by differentiating equa-tion (2):
@ I@pi
=X
k
@wk
@piIk. (8)
To compute the partial derivatives @xj
@piand @yj
@pi, we need to
study the dependencies between the coordinates in the imageplane (xj, yj) and the model's parameters. The 2D point (x j, yj)is obtained by projecting a 3D point, mj, onto the image plane.We can thus rewrite (xj, yj) = P(Rmj + t), where P is a pro-jection whose optical axis is the z-axis. The transformation Phas two components Px and Py, so that xj = Px(Rmj + t) andyj = Py(Rmj + t). Using the chain rule, we obtain:
@xj
@pi=@Px
@m0
j
T@m0
j
@pi(9)
@yj
@pi=@Py
@m0
j
T@m0
j
@pi
where m0
j = Rmj + t. We detail the computation of the partialderivatives of P, Rmj + t and wk in Appendix A.
2.4 Tracking resultsThe experiments we ran use a partition of the face into threeregions: the mouth area, the eyes area, and the forehead, asillustrated in figure 2. In all our experiments, the values of theparameters are initialized with a rough visual guess.
We tried different optimization variants and studied whichones were most appropriate for the different parameters. Forthe position parameters, the analytical Jacobian producedgood results and allowed faster computations. For the expres-sions parameters, the finite differences Jacobian producedbetter results than the analytical version. This difference can
0
1
2
3
4
5
6
0 10 20 30 40 50 60 70 80
(a)
-0.15
-0.1
-0.05
0
0.05
0.1
0.15
0 10 20 30 40 50 60 70 80
r0r1r2
(b)
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
0 10 20 30 40 50 60 70 80
angerneutral
joy
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
0 10 20 30 40 50 60 70 80
angerneutral
joy
(c)
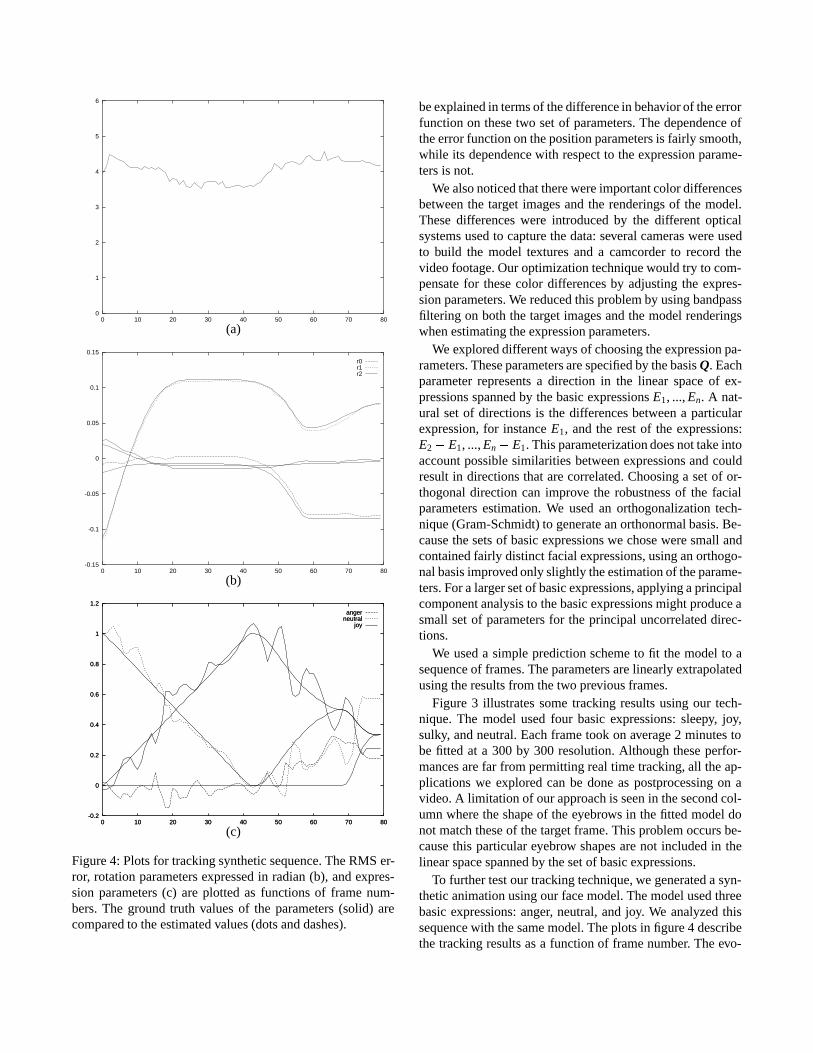
Figure 4: Plots for tracking synthetic sequence. The RMS er-ror, rotation parameters expressed in radian (b), and expres-sion parameters (c) are plotted as functions of frame num-bers. The ground truth values of the parameters (solid) arecompared to the estimated values (dots and dashes).
be explained in terms of the difference in behavior of the errorfunction on these two set of parameters. The dependence ofthe error function on the position parameters is fairly smooth,while its dependence with respect to the expression parame-ters is not.
We also noticed that there were important color differencesbetween the target images and the renderings of the model.These differences were introduced by the different opticalsystems used to capture the data: several cameras were usedto build the model textures and a camcorder to record thevideo footage. Our optimization technique would try to com-pensate for these color differences by adjusting the expres-sion parameters. We reduced this problem by using bandpassfiltering on both the target images and the model renderingswhen estimating the expression parameters.
We explored different ways of choosing the expression pa-rameters. These parameters are specified by the basis Q. Eachparameter represents a direction in the linear space of ex-pressions spanned by the basic expressions E1, ..., En. A nat-ural set of directions is the differences between a particularexpression, for instance E1, and the rest of the expressions:E2 � E1, ..., En � E1. This parameterization does not take intoaccount possible similarities between expressions and couldresult in directions that are correlated. Choosing a set of or-thogonal direction can improve the robustness of the facialparameters estimation. We used an orthogonalization tech-nique (Gram-Schmidt) to generate an orthonormal basis. Be-cause the sets of basic expressions we chose were small andcontained fairly distinct facial expressions, using an orthogo-nal basis improved only slightly the estimation of the parame-ters. For a larger set of basic expressions, applying a principalcomponent analysis to the basic expressions might produce asmall set of parameters for the principal uncorrelated direc-tions.
We used a simple prediction scheme to fit the model to asequence of frames. The parameters are linearly extrapolatedusing the results from the two previous frames.
Figure 3 illustrates some tracking results using our tech-nique. The model used four basic expressions: sleepy, joy,sulky, and neutral. Each frame took on average 2 minutes tobe fitted at a 300 by 300 resolution. Although these perfor-mances are far from permitting real time tracking, all the ap-plications we explored can be done as postprocessing on avideo. A limitation of our approach is seen in the second col-umn where the shape of the eyebrows in the fitted model donot match these of the target frame. This problem occurs be-cause this particular eyebrow shapes are not included in thelinear space spanned by the set of basic expressions.
To further test our tracking technique, we generated a syn-thetic animation using our face model. The model used threebasic expressions: anger, neutral, and joy. We analyzed thissequence with the same model. The plots in figure 4 describethe tracking results as a function of frame number. The evo-

(a) (b) (c) (d) (e)
(f) (g) (h) (i)
Figure 5: Applications. Animations of synthetic models are shown on the top row. The model (rendered in (b)) has been fittedto the target image (a). For the same frame, the facial expression can be exaggerated (c), the viewpoint can be changed (d), orthe animation parameters can be used for a different model (e). The bottom row illustrates modifications of the target frame (a).The lighting has been changed in (g) by introducing a synthetic light source. A greyscale rendering of the lighted estimatedgeometry (f) was used to modulate the target image. Finally, synthetic elements can be added to the face such as the tattoosin (i). These tattoos were rendered separately using the 3D model (h) and then composited on top of the target image.
lution of the root mean square error is given in figure 4(a).The estimated head position and the blending parameters inthe forehead region for the same sequence are illustrated infigure 4(b) and figure 4(c) respectively. The position and ori-entation parameters are estimated fairly precisely, whereasthe estimated values of the expression parameters are signif-icantly different from their true values. Although the expres-sion parameters are not accurately estimated, the rendered fit-ted model at each frame is very close to the input frames.
3 ApplicationsOnce we have recovered the position and the geometry of theface at each frame, we can use this information to generatenovel animations. We considered two different types of appli-cations. The first one is to apply the recovered parameters toa synthetic face to produce a performance-driven animation.The second set of applications is to alter the original videofootage using the recovered 3D geometry. These alterationsinclude changing the lighting, and adding computer graphicselements to decorate the face. Figure 5 illustrates these ap-plications. A set of mpeg movie files provide more completeexamples. A description of these files can be found in Ap-pendix B.
3.1 Performance-driven animationThe recovered parameters can be used to animate any facemodel using an animation tool. The animation parameters
can be edited to produce different animations; for instance,the expressions can be exaggerated or the viewpoint can bechanged. These applications are illustrated in figure 5. Thetarget image in figure 5(a) has been fitted to the model ren-dered in 5(b). As shown in figure 5(c), the same expressioncan be exaggerated. This exaggeration was obtained by mul-tiplying the expression parameters by a positive constant. Fora teleconferencing system the synthetic reconstruction can beseen from a different angle (figure 5(d)) to simulate the rela-tive positions of the different participants. Finally, the anima-tion parameters can be used to animate a different character(figure 5(e)).
3.2 Relighting
Relighting images of real scenes is a difficult problem since itrequires estimating the reflectance properties of the objects inthe scene. Yu and Malik [26] tackle this problem for imagesof buildings taken under different illumination conditions. Inour approach we did not try to recover the albedo of the face;instead, we just modulate the colors in the target image. Theaddition of a virtual light source is simulated as follows. First,the estimated face geometry is rendered in a grey color usingthe synthetic light source (figure 5(f)). Then this renderingis used to scale the colors in the original frame. Figure 5(g)shows the original frame with a dramatic change in lighting.

3.3 Adding facial decorations
The geometry and the texture of the face can be modified inthe original footage. For instance, we could modify the ge-ometry by adding a nose ring to the person in the video. Thismodification is done by rendering the modified face geometrywith the original frame as a texture map. The texture map co-ordinates are computed by projecting the mesh vertices ontothe image plane using the recovered camera parameters.
Modifying the face texture allows us to add decorationsto the face (e.g., tattoos and scars). These modifications areintroduced by rendering the recovered geometry with a cylin-drical texture map bearing the decorations (figure 5(h)). Therendering is then composited over the original frame (fig-ure 5(i)). Notice how the tattoos are deformed and occludedaccording to the face geometry. These effects would be im-possible to obtain using a 2D tracking technique.
4 Conclusion and future work
In this paper, we have introduced a novel technique for esti-mating the head's position and facial expression from videofootage. We use a realistic face model in an analysis-by-synthesis approach. Our model is a linear combination of3D face models, which can be generated by photogrammetrictechniques or 3D scanning. The quality of the model allowsbetter tracking results than with other methods. We use a con-tinuous optimization technique to fit the model and give ananalytical derivation of the computations.
We have also presented a wide range of applications thatdemonstrate the usefulness of this technique, including sim-ple performance-driven animations for changing viewpoint,identity, emotion, and more subtle special effects such as re-lighting the face or adding tattoos.
In the future, we would like to improve our system in dif-ferent ways:
We used bandpass filtering to correct for color differencesbetween the target images and the model renderings. Theseadjustments could also be done by adding a lighting model toour face model. The parameters of the lighting models wouldthen be estimated along with the rest of the face parameters.
Our 3D modeling-from-images technique results in a fairlycoarse approximation of the face geometry and texture. Usinga 3D scanner would provide more accurate models that couldsubstantially improve the tracking results.
Finally, we could employ more effective prediction tech-niques such as Kalman filtering.
As we try to build computer systems that interact with theirusers in a more natural fashion, analyzing face images is be-coming a key issue. We believe that modeling, animating, andtracking the human face as a linear combination of samplefaces is a powerful paradigm.
References[1] K. Aizawa and H. Harashima. Model-based analysis synthesisimage coding (MBASIC) system for a person's face. Signal Pro-cessing: Image Communication, pages 139–152, 1994.[2] D.H. Ballard and C.M. Brown. Computer Vision. Prentice-Hall,Englewood Cliffs, New Jersey, 1982.[3] M. Black and Y. Yacoob. Tracking and recognizing rigid andnon-rigid facial motions using local parametric models of imageotions. In Proceedings, International Conference on Computer Vi-sion, pages 374–381. 1995.[4] A. Blake and M. Isard. Active Contours: The Application ofTechniques from Graphics, Vision, Control Theory and Statistics toVisual Tracking of Shapes in Motion. Addison Wesley, 1998.[5] C. Bregler, M. Covell, and M. Slaney. Video Rewrite: driving vi-sual speech with audio. In SIGGRAPH 97 Conference Proceedings,pages 353–360. ACM SIGGRAPH, August 1997.[6] C.S. Choi, K. Aizawa, H. Harashima, and T. Takebe. Analy-sis and synthesis of facial image sequences in model-based imagecoding. IEEE Transactions on Circuits and Systems for Video Tech-nology, 4(3):257–274, June 1994.[7] M. Covell. Eigen-points: control-point location using principalcomponent analysis. In Proceedings, Second International Confer-ence on Automatic Face and Gesture Recognition, pages 122–127.October 1996.[8] D. Decarlo and D. Metaxas. Deformable model-based shape andmotion analysis from images using motion residual error. In Pro-ceedings, First International Conference on Computer Vision, pages113–119. 1998.[9] G.J. Edwards, C.J. Taylor, and T.F. Cootes. Interpreting face im-ages using active appearance models. In Proceedings, Third Work-shop on Face and Gesture Recognition, pages 300–305. 1998.
[10] I. Essa, S. Basu, T. Darell, and A. Pentland. Modeling, trackingand interactive animation of faces and heads using input from video.Computer Animation Conference, pages 68–79, June 1996.
[11] I. Essa and A. Pentland. Coding, analysis, interpretation, andrecognition of facial expressions. IEEE Transactions on PatternAnalysis and Machine Intelligence, 19(7):757–763, July 1997.
[12] B. Guenter, C. Grimm, D. Wood, H. Malvar, and F. Pighin. Mak-ing faces. In SIGGRAPH 98 Conference Proceedings, pages 55–66.ACM SIGGRAPH, July 1998.
[13] G.D. Hager and P.N. Belhumeur. Real-time tracking of imageregions with changes in geometry and illumination. In Proceedings,Computer Vision and Pattern Recognition, pages 403–410. 1996.
[14] M.J. Jones and T. Poggio. Hierarchical morphable models. InProceedings, International Conference on Computer Vision, pages820–826. 1998.
[15] M. La Cascia, J. Isidoro, and S. Sclaroff. Head tracking viarobust registration in texture map images. In Proceedings, IEEEConference on Computer Vision and Pattern Recognition. 1998.
[16] A. Lanitis, C.J. Taylor, and T.F. Cootes. A unified approach forcoding and interpreting face images. In Fifth International Confer-ence on Computer Vision (ICCV 95), pages 368–373. Cambridge,Massachusetts, June 1995.
[17] H. Li, P. Roivainen, and R. Forchheimer. 3-D motion estimationin model-based facial image coding. IEEE Transactions on PatternAnalysis and Machine Intelligence, 15(6):545–555, June 1993.
[18] K. Matsino, C.W. Lee, S. Kimura, and S. Tsuji. Automaticrecognition of human facial expressions. In Proceedings of the

IEEE, pages 352–359. 1995.[19] E. Petajean and H.P. Graf. Robust face feature analysis for au-
tomatic speechreading and character animation. In Proceedings odInternational Conference on Automatic Facial and Gesture Recog-nition, pages 357–362. 1996.
[20] F. Pighin, J. Hecker, D. Lischinski, R. Szeliski, and D. Salesin.Synthesizing realistic facial expressions from photographs. InSIGGRAPH 98 Conference Proceedings, pages 75–84. ACM SIG-GRAPH, July 1998.
[21] W.H. Press, B.P. Flannery, S.A. Teukolsky, and W. T. Vetterling.Numerical Recipes in C: The Art of Scientific Computing. Cam-bridge University Press, Cambridge, England, second edition, 1992.
[22] A. Schodl, A. Ario, and I. Essa. Head tracking using a texturedpolygonal model. In Workshop on Perceptual User Interfaces, pages43–48. 1998.
[23] D. Terzopoulos and K. Waters. Analysis and synthesis of facialimage sequences using physical and anatomical models. In IEEETransactions on Pattern Analysis and Machine Intelligence, pages569–579. june 1993.
[24] T. Vetter and V. Blanz. Estimating coloured 3D face modelsfrom single images: an example based approach. In Proceedings,European Conference on Computer Vision, pages 499–513. 1998.
[25] L. Williams. Performance-driven facial animation. In SIG-GRAPH 90 Conference Proceedings, volume 24, pages 235–242.August 1990.
[26] Y. Yu and J. Malik. Recovering photometric properties of ar-chitectural scenes from photographs. In SIGGRAPH 98 ConferenceProceedings, pages 207–217. ACM SIGGRAPH, July 1998.
AppendixAppendix A: Analytical JacobianWe detail further the computation of the analytical Jacobian startedin section 2.3. The partial derivatives of the projection P, the trans-formation Rmj + t, and the blending weight wk with respect to aparameter pi are examined.
Partial derivatives of P
The projection P is a mapping from 3D to 2D that takes a pointm = (X, Y , Z) as a parameter.
@Px
@m=
0@ f
Z0�f X
Z2
1A and
@Py
@m=
0@ 0
fZ�f Y
Z2
1A
Partial derivatives of Rmj + t
The partial derivative with respect to pi can be expanded as:
@(Rmj + t)@pi
=@R@pi
mj + R@mj
@pi+
@t@pi
This expression depends on the nature of pi.
� If pi is a blending weight (pi = �l): since the model geome-try is a linear combination of the basic expressions geometry,the point mj is a linear combination of points from the basic
expressions mjk. We can then apply the following derivation:
@(Rmj + t)@�l
= R@mj
@�l= R
@(P
k wkmjk)
@�l= RX
k
@wk
@�lmjk
� If pi = R: we replace the rotation matrix R with RR; where Ris parameterized by an angular velocity ! = (!x,!y,!z), andis given by Rodriguez's formula:
R(n, �) = I + sin�X(n) + (1� cos�)X2(n)
where � = k!k, n = !=� and X(n) is the cross product opera-tor:
X(!) =
"0 �!z !y
!z 0 �!x
�!y !x 0
#
A first-order approximation of R is given by I + X(!). The ro-tation RR is parameterized by the vector !. We are thus inter-ested in computing the partial derivatives of Rmj + t accordingto some !l, component of !:
@(Rmj + t)@!l
=@R@!l
mj =@(I + X(!))
@!lRmj =
@X(!)@!l
Rmj
Once a step in the LM algorithm has been computed, the rota-tion R is updated using
R RR
� If pi = tx, or pi = ty, or pi = tz, then the partial derivative isequal to (1, 0, 0), or (0, 1, 0), or (0, 0, 1) respectively.
Partial derivatives of wk
Clearly:
@wk
@pi= 0, if pi is not an expression parameter.
If pi is an expression parameter, for instance �l, then the partialderivative can be computed by differentiating equation (1):
@wk
@�l= Q(k, l)
Appendix B: Movie filesA set of mpeg files illustrating our tracking re-sults and applications are available on-line athttp://www.cs.washington.edu/research/projects/grail2/www/projects/realface/tracking.html.
Tracking results: trk1.mpg, trk2.mpg, trk3.mpg, and trk4.mpg.
Applications:� exg3.mpg: exaggeration of facial expressions.
� chv3.mpg: change in viewpoint.
� fem2.mpg: animation transposed to different model.
� rel2.mpg: relighting of video footage.
� tat2.mpg: addition of synthetic elements.