review of icassp 2004 arthur chan. part i of this presentation (6 pages) pointers of icassp 2004 (2...
Post on 21-Dec-2015
222 views
TRANSCRIPT

Review of ICASSP 2004
Arthur Chan

Part I of This presentation (6 pages)
Pointers of ICASSP 2004 (2 pages) NIST Meeting Transcription Workshop (2
pages)

Session Summary
Speech Processing Sessions (SpL1-L11, SpP1-16) Many people because of SARS in Hong Kong last year. Speech/Speaker recognition, TTS/Voice morphing, speech
coding,
Signal Processing Sessions (Sam*, Sptm*, Ae-P6) Image Processing Sessions (Imdsp*) Machine Learning Sessions (Mlsp*) Multimedia Processing Sessions (Msp*) Applications (Itt*)

Quick Speech Paper Pointer Acoustic Modeling and Adaptation (SP-P2, SP-P3, SP-P 14) Noisy Speech Processing/Recognition (SP-P6, SP-P13) Language Modeling (SP-L11) Speech Processing in the meeting domain.
R04 Rich Transcription in meeting domain. Handbook can be obtained from Arthur.
Speech Application/Systems (ITT-P2, MSP-P1, MSP-P2) Speech Understanding (SP-P4) Feature-analysis (SP-P6, SP-L6) Voice Morphing (SP-L1) TTS

Meeting Transcription Workshop
Message : Meeting transcription is hard Problems in core technology
Cross talk causes a lot of trouble on SR and speaker segmentation.
Problems in evaluation Cross talk causes a lot of trouble in string evaluation.
Problems in resource creation Transcription becomes very hard Tool is not yet available.

Speech Recognition
Big challenge in speech recognition ~65% average ERR using state-of-the art technology of
Acoustic modeling and language modeling Speaker adaptation Discriminative training Signal Processing using multi-distance microphones
Observations Speech recognition become poorer when there are more
speakers. Multi-distance is a big win. May be microphone array will
also be.

End of Part I
Jim asked about why FA is counted at Jun 18, 2004
Q: “Is it reasonable to give the same weighting to FA as to Missing Speaker and Wrong Speaker?”

Part II :
More on Diarization Error Measurement (7 pages) Is the current DER reasonable?
Lightly Supervised Training (6 pages)

More on Diarization Error Measurement (7 pages)
Its Goal: Discover how many persons are involved in the
conversation Assign speech segments to a particular segments Usually assume no prior knowledge of the
speakers Application:
Unsupervised speaker adaptation, Automatic archiving and indexing acoustic data.

Usual procedures of Speaker Diarization
1, Speaker Segmentation Segment a N-speaker audio document into segm
ents which is believed to be spoken by one speaker.
2, Speaker Clustering Assign segments to hypothesized speakers
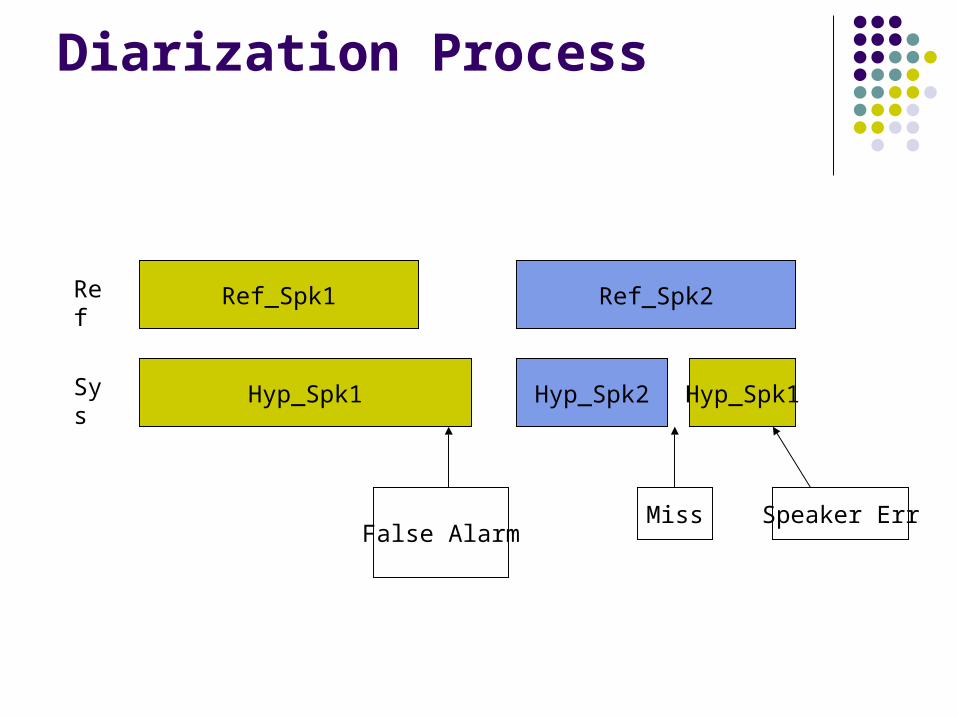
Diarization Process
Ref_Spk1Ref
Sys
Ref_Spk2
Hyp_Spk1
False Alarm
Hyp_Spk1Hyp_Spk2
Miss Speaker Err

Definition of Diarization Error
Sref
Scorrectsysref
SNSdur
SNSNSNSdurDiaErr
)}(*)({
))}())(),((max(*)({
)(SDur
Rough segmentation are first provided as reference. Another stage of acoustic segmentation will also be applied
on the segmentation
Definition:
)(SN ref)(SN sys
)(SNcorrect
:Duration of the segment
:Number of speakers in the Reference
:Number of speakers provided by the system
:Number of speaker in the reference which is hypothesize correctly by the system

Breakdown to three types of errors Speaker that is attributed to the wrong speaker (or speaker
error time), sum of
Missed Speaker time: sum of segments where more reference speaker than system speakers.
False Alarm: sum of segments where more system speakers than the reference.
))()((*)( SNSNSdur refsys
))())(),((max(*)( SNSNSNSdur correctsysref
))()((*)( SNSNSdur sysref

Re: Jim, possible extension of the measure Current measures is weighted by the number of mistakes
made
)(
)()(#)()(#)()(#
SDurN
WSDurWSMSDurMSFADurFA
ref
Possible way to extend the definition
)()()(
)()(#)()(#)()(#
WSDurNwMSDurNwFADurNw
WSDurWSwMSDurMSwFADurFAw
refWSrefMSrefFA
WSMSFA

Other Practical Concerns of Measuring DER
In NIST evaluation guideline: Only rough segmentation is provided at the
beginning. 250 ms time collar is provided in the evalution
Breaks of a speaker less than 0.3s doesn’t count.

My Conclusion
Weakness of current measure: Because of FA, DER can be larger than 100.
But most systems perform much better than that Constraints are also provided to make the measure
reasonable. Also, as in WER
It is pretty hard to decide how to weigh deletion and insertion errors.
So, current measure is imperfect however, it might be to extend it to be more reasonable

Further References
Spring 2004 (RT-04S) Rich Transcription Meeting Recognition Plan,http://www.nist.gov/speech/tests/rt/rt2004/spring/documents/rt04s-meeting-eval-plan-v1.pdf
Speaker Segmentation and Clustering in Meetings by Qin Jin et al. Can be found in RT 2004 Spring Meeting Recogni
tion Workshop

Lightly supervised Training (6 pages) Lightly supervision in acoustic model training > 1000 hours training (by BBN) using TDT (Topic
detection tracking) corpus The corpus (totally 1400 hrs)
Contains News from ABC/CNN (TDT2), MSNBC and NBC (TDT3 and 4)
Lightly supervised training, using only closed-caption transcription, not transcribed by human.
“Decoding as a second opinion: Adapted results: BL (hub4) WERR 12.7%
-> tdt4 12.0% -> + tdt2 11.6% + tdt3 10.9% -> w MMIE 10.5%

How does it work?
Require very strict automatic selection criterion What kills the recognizer is insertion and deletion
of phrases. CC : “The republican leadership council is going t
o air ads promoting Ralph Nadar” Actual : “The republican leadership council, a mo
derate group, is going to air ads the Green Party candidate, Ralph Nadar. “
-> Corrupt phoneme alignments.


Point out the Error : Biased LM for lightly supervise decoding Instead of using standard LM
Use LM with biased on the CC LM Arguments: Good recognizer can figure out whether there
is error. However, it is not easy to automatically know that
there is an error. High Biased of LM will result in low WERR in certain CC.
Can point out error better. However, High Biased of LM cause recognizer making
same errors as CC. Make recognizer biased to the CC
Authors : “ … the art is such as way the recognizer can confirm correct words …. and point out the errors”

Selection of Sentences: Lightly supervised decoding
Lightly supervised decoding Use a 10xRT decoder to run through 1400 hrs of
speech. (1.5 year in 1 single processor machine) Authors: “It takes some time to run.”
Selection Only choose the files with 3 or more contiguous
words correct (Or files with no error) Only 50% data is selected. (around 700 hrs)

Model Scalability and Conclusion
No. of hours from 141h -> 843h Speakers from 7k -> 31k Codebooks from 6k -> 34k Gaussians from 164k -> 983k

Conclusion and Discussion
A new challenge for speech recognition Are we using the right method in this task? Is increasing the number of parameters
correct? Will more complex models (n-phones, n-
grams) work better in cases > 1000 hrs?

Related work in ICASSP 2004
Lightly supervised acoustic model using consensus network (LIMSI on TDT4 Mandarin)
Improving broadcast news transcription by lightly supervised discriminative training (Very similar work by Cambridge.) Use a faster decoder (5xRT) Discriminative training is the main theme.