rights / license: research collection in copyright - non ...38062/et… · tp-ttp rewrite string rp...
TRANSCRIPT

Research Collection
Doctoral Thesis
A framework for syntactic and morphological analysis and itsapplication in a text-to speech system
Author(s): Russi, Thomas
Publication Date: 1990
Permanent Link: https://doi.org/10.3929/ethz-a-000578710
Rights / License: In Copyright - Non-Commercial Use Permitted
This page was generated automatically upon download from the ETH Zurich Research Collection. For moreinformation please consult the Terms of use.
ETH Library

Diss. ETH No. 9328
A Framework for
Syntactic and MorphologicalAnalysis and its Applicationin a Text-to-Speech System
A dissertation submitted to the
SWISS FEDERAL INSTITUTE OF TECHNOLOGY
ZÜRICH
for the degree of
Doctor of Technical Sciences
presented byTHOMAS RUSSI
Dipl. El.-Ing. ETHborn December 13, 1960
Citizen of Andermatt, Switzerland
aecepted on the recommendation of
Prof. Dr. W. Guggenbühl, examiner
Prof. Dr. A. Kündig, co-examiner
1990
<< C.

Acknowledgements
The work presented in this thesis was carried out within the Speech
Synthesis Project in the Group for Speech and Language Procesing at
the Institute of Electronics at ETH Zürich.
First and foremost, I would like to thank my advisor,Prof. W. Guggenbühl, for his continuous support throughout the
project. I am also indebted to Prof. A. Kündig, who was willing to
be the co-examiner and made many helpful suggestions.
I profited a great deal from discussions with colleagues in and outside
of our research group. They considerably enriched my background in
speech and language processing as well as in Computer science. In par¬
tieular, I would like to thank Beat Pfister for coordinating the various
parts of the speech synthesis project and for carefully reading the final
draft of this thesis. Ruth Rothenberger and Hans Huonker contributed
significantly to my understanding of linguistic issues. Karl Huber and
Christof Traber, who were also involved in the speech synthesis projectfrom the very beginning, encouraged me in numerous produetive discus¬
sions. I would also like to acknowledge Carlo Bernasconi, Hans-Peter
Hutter, Hubert Kaeslin and Ina Kraan. Peter Sempert provided the
agreeable Computing environment. Patrick Shann helped clarify a num¬
ber of issues concerning chart parsing.
Finally, I wish to thank the Swiss National Science Foundation and
the Swiss PTT, who generously supported this research.

Leere Seite\nBlank

Contents
Abstraet vii
Kurzfassung ix
List of Symbols xi
List of Abbreviations xiii
1 Overview 1
1.1 Introduction 1
1.2 Syntactic and Morphological Analysis 3
1.3 Architecture of the Text-to-Speech System 5
1.4 Summary of Results 6
2 Formalisms 9
2.1 Two-Level Formalism 11
2.1.1 Two-Level Model 12
2.1.2 Rule Syntax 14
2.1.3 Ruies and Finite Automata 17
2.2 Features 21
2.2.1 First-Order Terms 22
2.2.2 Feature Structures 24
2.2.3 Lattices and Features 26
2.3 The UTN Formalism 28
2.3.1 Recursive Transition Networks 30
2.3.2 Unification-Based Transition Networks 36
3 Algorithms 43
3.1 Unification 43
in

iv Contents
3.1.1 Unification as the Solution of a Set of Equations 44
3.1.2 Overview and Evaluation 45
3.1.3 Term Unification Algorithms 48
3.1.4 Graph Unification Algorithms 52
3.2 Parsing 53
3.3 Chart Parsing 56
3.3.1 Top-Down Strategies 63
3.3.2 Bottom-Up Strategies 67
3.3.3 Computational Complexity 70
Comparison of Algorithms 73
4.1 Introduction 73
4.2 Unification Algorithms 75
4.3 Rule Invocation Strategy 77
4.3.1 Complexity Measure 77
4.3.2 Sample Grammars 78
4.3.3 Sample Sentences 79
4.3.4 Experiments and Results 80
4.3.5 Discussion 82
Implementation 85
5.1 Requirements and Design Considerations 85
5.2 System Overview 87
5.3 Description of Packages 89
5.3.1 Interface Package 89
5.3.2 Parser Package 90
5.3.3 Grammar Package 91
5.3.4 Lexicon Package 91
5.3.5 Twol Package 92
5.3.6 Unification Package 92
Evaluation and Extensions 95
6.1 Evaluation 95
6.1.1 From the Perspective of Formalisms 96
6.1.2 As Applied in a TTS-System 98
6.2 Extensions 101
6.2.1 Extensions to the Formalism 101
6.2.2 Extensions to the Software 102
6.3 Condusion 103
Syntax of Two-Level Ruies 105

Contents
B Syntax of UTN Formalism 107
C Sample Grammars 111
D Sample Sentences 119
E Empirical Raw Data 129
List of Figures 137
List of Tables 139
Bibliography 141

Leere Seite\nBlank

Abstraet
This dissertation presents a computationally effective and linguisticallywell-motivated framework for syntactic and morphological analysis. It
is based on a new declarative grammar formalism, called Unification-
based Transition Network (UTN) formalism, and an extended version
of Koskenniemi's two-level model. The UTN formalism is used to en¬
code word and sentence grammars. Two-level ruies are used to encode
morphographemic and morphophonetic alternations.
We define the above formalisms and present a number of examples.We also describe and compare the parsing and unification algorithmswhich are used to process UTN grammars. These algorithms determine
the overall effiency of the analysis process. In a series of experiments,we measure the efficiency of a number of rule invocation strategies for
chart parsing and of a number of unification algorithms for terms of
first-order predicate logic and for feature structures.
Our approach to syntactic and morphological analysis has been fully
implemented in the Software package Syma. We describe the use of
Syma as a text analysis module in a text-to-speech system for the Ger¬
man language. In the text-to-speech system, Syma parses a text sen¬
tence by sentence, analyzing the morphological strueture of each word,
establishing the surface syntactic strueture of each sentence and per¬
forming the grapheme-to-phoneme conversion. Since the syntactic and
morphological analyzer embodies a general approach, it can be used for
other languages as well as for other applications.
Keywords. Natural Language Processing, Syntactic and Morpholog¬ical Analysis, Text-to-Speech Conversion, Parsing, Unification.
vu

Leere Seite\nBlank

Kurzfassung
In dieser Dissertation wird ein linguistisch fundiertes und effizientes
Verfahren für die syntaktische und morphologische Analyse natürlicher
Sprache vorgestellt. Es basiert auf einem neuen deklarativen Gram¬
matikformalismus, genannt UTN-Formalismus (Unification-based Tran¬
sition Network Formalism), und auf einer erweiterten Version des two-
level Modells von Koskenniemi. Der UTN-Formalismus wird zur For¬
mulierung von Satz- und Wortgrammatiken, der Two-level Formalismus
zur Formulierung von morphographemischen und morphophonetischenAlternationen verwendet.
Die oben erwähnten Formalismen werden definiert und an Beispie¬len erläutert. Weiter werden die Parsing- und Unifikationsalgorith¬men beschrieben, die den Kern des Verarbeitungsmodells für den UTN-
Formalismus bilden. In einer Reihe von Experimenten vergleichen wir
die Effizienz verschiedener Parsingstrategien, die alle auf der Technik der
aktiven Chart-Analyse aufbauen. Ebenfalls vergleichen wir die Effizienz
verschiedener Unifikationsalgorithmen für Terme der Prädikatenlogikerster Ordnung und für Attribut-Wert-Paare.
Das Verfahren für die syntaktische und morphologische Analyseist im Softwarepaket Syma vollständig implementiert worden. Wir
beschreiben die Anwendung von Syma als Textanalyse-Modul in einem
Sprachsynthese-System für die deutsche Sprache. In diesem Systemwird Syma dazu verwendet, einen Text satzweise zu analysieren. Dabei
wird der morphologische Aufbau jedes Worts sowie der syntaktischeAufbau jedes Satzes analysiert. Zusätzlich wird die phonetische Um¬
schrift des Textes erzeugt. Da unser Ansatz jedoch sprach- und app¬
likationsunabhängig ist, kann er sowohl für andere Sprachen als auch in
anderen Anwendungen zum Einsatz kommen.
ix

Leere Seite\nBlank

List of Synibols
Symbol Meaning Page
a_B a is a member of set B 18
a $_ B a is not a member of set B 67
C,__
Containment relation and its negation 18
Aö B union of sets A and B 22
AflB intersection of sets A and B 22
/l - B difference of sets A and B 25
yl x B Cartesian produet of sets A and B 18
=,^ equality, inequality 18
V, 3 universal quantifier, existential quantifier 23
P <r>Q P is logically equivalent to Q 23
<,> generalized ordering relation 26
T top of a lattiee 24
1 bottom of a lattiee 27
V_3 least upper bound (supremum) of B 27
Ai? greatest lower bound (infimum) of B 27
a\l b join of a and b 27
a Ab meet of a and b 27
a__
b a subsumes 6 21
a U b unification of a and b 23
a n b generalization of a and b 21
xi

xii List of Symbols
V set of feature structures 21
\Di\ domain of feature strueture Di 25
E aiphabet (for automata) 18
S* free monoid generated by aiphabet __
(set of all strings over 5_) 18
e empty string (consisting of zero elements) 18
6 transition funetion (for automata) 18
P{A) power set of A 31
tp-ttp rewrite string rp as string tf> 35
a=>ß derivation relation 62
a^ß transitive closure of the derivation relation 62
V,NV class of languages recognizable by a deterministic
(nondeterministic) Turing machine in polynomial time 73

List of Abbreviations
Abbreviation Meaning Page
ATN Augmented Transition Network 30
AE number of active edges 80
Bi i'-th bottom-up rule invocation strategy 80
CL Common Lisp 6
CLOS Common Lisp Object System 90
DCG Definite Clause Grammar 30
DFA deterministic finite automaton 18
FA finite automaton 18
FR number of applications of the fundamental
rule of chart parsing 80
FUG Functional Unification Grammar 28
GPSG Generalized Phrase Strueture Grammar 28
gib greatest lower bound 27
IE number of inactive edges 80
iff if and only if 23
LFG Lexical Functional Grammar 28
LPC linear predictive coding 6
lub least upper bound 27
MGU most general unifier 23
NLP natural language processing 1
xm

xiv List of Abbreviations
NFA nondeterministic finite automaton 31
PATR PArse and TRanslate 30
poset partially ordered set 21
RTN recursive transition network 30
Syma SYntactic and Morphological Analyzer 2
Ti i-th top-down rule invocation strategy 80
TOT number of total (active and inactive) edges 80
TTS text-to-speech 3
UTN Unification-based Transition Network 10

Chapter 1
Overview
1.1 Introduction
Natural language analysis is the study of the strueture, meaning and
use of language commonly employed by people to transmit information.
In the past 30 years, analysis of natural language1 has shifted from
informal and discursive descriptions to more formal ones using mathe¬
matical modeis to capture the abstraet properties of language strueture
and meaning. The fundamental work of N. Chomsky [Cho65] provides
linguists with a formal tool for the precise description of syntactic phe¬nomena. With the development of digital Computers, natural language
processing (NLP), the investigation of computationally effective mech¬
anisms for communication by means of natural language, became an
active and highly interdisciplinary research field involving theoretical
linguistics, formal language theory, Computer science, artificial intelli¬
gence and psycholinguistics.
Computer modeis of natural language have been investigated and
formulated for both theoretical and practical purposes. From a theoret¬
ical point of view, Computer modeis help to gain better insight into the
'The term natural language includes both the spoken and the Orthographie form
and distinguishes human language from artificially defined languages such as formal
languages in mathematics and Computer science.

Chapter 1. Overview
human language processing faculty and serve as a touchstone for linguis-tic theories. From a practical point of view, Computer programs which
incorporate (parts of) the human language faculty are of great practicaluse and will probably become indispensable as Computers become more
powerful and ubiquitous. Language is the easiest and most natural way
for man to communicate with machines, allowing unskilled people to
interact with digital Computers in their own language. Applications of
NLP, some of which are already commerdally available, include:
• natural language front ends (using spoken and/or written lan¬
guage) to databases,
• natural language interfaces and explanation generators for expert
Systems,
• communication with robot Systems by means of spoken language,
• text-to-speech Systems,
• machine translation Systems,
• word processing tools such as spelling and grammar checkers.
This dissertation Covers a partieular aspect of NLP, namely the anal¬
ysis of the strueture of words and sentences. It describes formalisms and
computational methods for syntactic and morphological analysis. The
proposed mechanisms have been implemented and tested as a module
in a high-quality text-to-speech system for German. The Computer pro¬
gram Syma (SYntactic and Morphological Analyzer) is a tool to designlexicons as well as word and sentence grammars, to test linguistic theo¬
ries and to build practical applications. In its current configuration, it
analyzes a text sentence by sentence, thereby making explicit the mor¬
phological strueture of each word and the syntactic strueture of each
sentence and generating the phonetic transcription of the text. The
formalism and the Software have been designed to be general enough to
model the syntax and morphology of various languages, e.g., German,
English or French. The Syma system is designed to be a general tool,
independent of any specific applieation or language. It is not intended
to serve as a psycholinguistic model of the human language processing
faculty.

1.2. Syntactic and Morphological Analysis
1.2 Syntactic and Morphological Analysis
This section states our motivation for conducting syntactic and mor¬
phological analysis in a text-to-speech system and gives an overview of
the Syma system.
In order to convert text to speech, an underlying abstraet linguis-tic representation for the text must be derived [Kla87]. There are at
least two reasons why a direct approach (e.g., letter-to-sound ruies) is
inadequate. First, ruies for pronouncing words must take into consider¬
ation morpheme strueture, e.g., <sch> is pronouneed differently in the
German words lösch+en (to extinguish) and Hös+chen (diminutive of
trousers), and syntactic strueture, e.g., to solve noun-verb ambiguitiessuch as Sucht (addiction) and sucht (third person singular of to search).Second, sentence duration pattern and fundamental frequency contour
depend largely on the strueture of the sentence.
While most commercial, but also some laboratory text-to-speech
(TTS) Systems use letter-to-sound ruies without taking into account
the morphological strueture ofa word, recently developed Systems (e.g.,[PK86], [AHK87], [Dae88], [SR90], [CCL90]) incorporate morphological
analysis. Furthermore, although the influence of syntax on prosodyis widely acknowledged ([OSh90], [Kla87], [BFW86]), most TTS Sys¬
tems lack syntax analysis ([PK86], [Dae88], [SR90]) or use some kind of
phrase-level parsing ([AHK87], [Mon90]) to obtain information on the
syntactic strueture of a sentence. This is motivated more by current
technological limitations than by linguistic insights. We are convinced
that, in order to achieve highly intelligible and natural-sounding speech,not only the phonological and morphological, but also the syntactic, se¬
mantic and even discourse strueture ofa text ([HLPW87], [Hir90]) must
be taken into account - although this is not yet feasible. As a step to¬
ward such a model, we have developed a morphological and syntactic
analyzer that is based on simple but powerful formalisms which are
linguistically well-motivated and computationally effective.
Our approach to morphological and syntactic processing lies within
the paradigms of finite-state morphology [Kay87] and unification-based
(also called constraint-based) grammar formalisms [Shi86]. In the Syma
system, morphological analysis consists of three stages (see Figure 1.1):segmentation, parsing and generation. The segmentation stage (Lexical

Chapter 1. Overview
WordGrammar
Orthographieword
(
• word strueture- morph. features- phon. transcription
MorphographemicRules C Morpheme
LexiconMorphophonetic
Ruies
Figure 1.1: Morphological analyzer
Analyzer) finds possible ways to partition the input string into lexicon
entries (morphemes). Spelling changes, e.g., schwa-insertion or elision,are covered by morphographemic ruies. The parsing stage of the mor¬
phological analysis (Word Parser) uses a word grammar to accept or
reject combinations of lexicon entries and to percolate features from the
lexicon to the syntactic analyzer. The generation stage of the morpho¬
logical analysis (Lexical Generator) generates a phonetic transcription
by concatenating the phonetic strings, which are stored as part of each
morpheme entry, and by applying morphophonetic ruies.
The syntactic analysis (see Figure 1.2) is based on a sentence gram¬
mar and a parser that takes as input the results of the morphologicalanalyzer2. It assigns to each sentence its surface syntactic strueture.
The syntactic strueture of the sentence and the phonetic transcriptionof each word are used at a later stage to determine prosodic features
such as duration pattern and fundamental frequency contour.
2The architecture of the SYMA system allows maintaining a fullform lexicon in
addition to the morpheme lexicon. The fullform lexicon serves to störe entries which
are not covered by the morphological analyzer, e.g., abbreviations or proper names.

1.3. Architecture ofthe Text-to-Speech System
r~
SentenceGrammar
>
\ )
,r
ice
SentenceParser
¦ syntax tree
(annotatedfeatures)
- phon. transcription
MorphologicalAnalyzer
Figure 1.2: Syntactic analyzer
1.3 Architecture of the Text-to-Speech
System
This section gives a short overview of the architecture of the text-to-
speech system developed at ETH Zürich [HHP*87] (see Figure 1.3). The
system consists of four major modules:
• The Syntax and Morphology Module ([Rus90b], [Rus90a])analyzes an input text sentence by sentence and generates its pho¬netic and its surface-syntactic representation.
• The Phrasing and Accentuation Module [TR88] determines
phrase level boundaries and computes the distribution of stress
markers from the syntactic and morphological strueture. In addi¬
tion, based on the sentence-level context, it performs some recod-
ing of the initial phonetic transcription.
• The Sound Production Module selects diphones from an in¬
ventory of German diphones ([Kae85], [Kae86]), controls the dura-

Chapter 1. Overview
tion of each diphone ([HGL88], [Hub90b], [Hub90a]) and generatesthe fundamental frequency contour [T_a90].
• The Synthesis Module is based on LPC (linear predictive cod¬
ing) synthesis. It converts the set of LPC parameters stored with
each diphone and the fundamental frequency and duration infor¬
mation into a speech signal. Speech samples are produced at a rate
of 10kHz and then converted to analog form via a D/A Converter
and low-pass filter.
In order to have a flexible text-to-speech system which is easy to
experiment with, each of the above-mentioned modules were designedto be relatively independent of each other. This was quite useful, as, in
the course of the project, several different approaches were experimentedwith, e.g., rule-based, Statistical and neural network-based approaches.Since the text-to-speech system is first and foremost a research tool, the
minimization of memory and CPU resources was not a primary objee¬tive. The programming languages Common Lisp (CL) and Prolog were
used for symbolic computations, while the language Modula-2 was used
for numerical computations. The entire system runs on a Workstation,and most of the Software is machine independent.
1.4 Summary of Results
The research contribution presented in this dissertation includes:
1. A linguistically well-motivated and computationally effective ap¬
proach to morphological and syntactic analysis and its applieationin a high-quality text-to-speech system for the German language.
2. The development of a new grammar formalism based on recursive
transition networks and unification. This formalism has been used
to implement several word and sentence grammars.
3. The development of an extended version of the two-level model of
Koskenniemi and its applieation to grapheme-to-phoneme conver¬
sion.

1.4. Summary of Results
text
i.Syntactic andMorphological
Analysis
syntactic and morph. strueture,
, phonetic string, lexical stress
Phrasing andAccentuation
phonetic string, stress markers,, phrase boundaries
Prosody Control
(Duration andFund. Frequency)Diphonization
diphone string, segm. duration,,fundamental frequency contour
LPC Synthesizer
synthetic speech
Figure 1.3: Architecture of the text-to-speech system

Chapter 1. Overview
4. The implementation and comparison of several rule invocation
strategies within the framework of a general chart parser.
5. The evaluation, implementation and comparison of several unifi¬
cation algorithms for first-order terms and feature structures.
Chapter 2 introduces the formalism for morphological and syntactic
analysis in detail. Chapter 3 discusses several parsing and unification
algorithms which have been evaluated and implemented. Chapter 4
presents the results of a comparison of the parsing and unification al¬
gorithms. Chapter 5 shows a survey of the implementation. Chapter 6
evaluates the Syma System and suggests some extensions.

Chapter 2
Formalisms
Linguistic formalisms are specialized (meta-)languages to provide a
computer-interpretable charaeterization of natural languages, e.g., to
speeify the set of strings a language encompasses or the structural prop¬
erties or meanings of words and sentences. Linguistic formalisms can
be eoneeived as specialized programming languages. Following a gen¬
eral trend in computational linguistics (and Computer science), we use
declarative formalisms, which allow a clear Separation between the for¬
mulation and the interpretation of linguistic knowledge.
The Syma system embodies several linguistic knowledge bases (seeFigures 1.1 and 1.2) containing "static knowledge" such as lexical entries
and "dynamic knowledge" such as different types of ruies. In partieular,the following knowledge is represented in the system:
• A morpheme lexicon, where each entry consists of a graphemic
string (the citation form), a phonetic string (pronunciation) and
a set of morphological features.
• A fullform lexicon, where each entry consists of a graphemic string,a phonetic string and a set of morphosyntactic features. The word
lexicon contains words which are not covered by the morphologicalanalyzer, such as names of cities and countries and proper names
(e.g., Luzern, Appenzell or Furgler) or highly irregulär words (e.g.,

If) Chapter 2. Formalisms
Paradoxon). In addition, the word lexicon can be used to störe
words which have already been analyzed by the morphologicalanalyzer to speed up morphological analysis (a kind of "cache"
lexicon or "short-term memory").
•
•
Ruies expressing the spelling and phonological changes which oc¬
cur when morphemes such as stems and affixes are combined.
Ruies describing the strueture of words, i.e., how morphemes can
be combined to form words and what the resulting morphosyn-tactic features are.
• Ruies describing the surface syntactic strueture of sentences by
defining the immediate dominance and the linear precedence re¬
lation of words and constituents.
In the following sections, we describe the formalisms used in the
Syma system to encode lexical entries, spelling and phonological ruies
and word and sentence grammars. Section 2.1 presents the two-level
formalism used to encode morphographemic and morphophonetic ruies.
Section 2.2 introduces the notation of first-order terms and feature
structures used to describe linguistic objects such eis morphemes, words
and constituents. Section 2.3 describes a grammar formalism we termed
Unification-based Transition Network (UTN) formalism, which is ap¬
plied to speeify word and sentence grammars.
As guidelines for the design of these formalisms, we adopted the
following general eriteria of Shieber ([Shi85], [SKP84]):
• Linguistic felicity, i.e., to which extent a formalism allows linguiststo state linguistic phenomena in as natural and direct a manner
as they would wish to state them.
• Expressiveness, i.e., which class of language in terms of formal
language theory can be stated at all.
• Computational effectiveness, i.e., whether the formalisms are com¬
putationally tractable and what their computational limitations
are.
The formalisms used in the Syma system are evaluated accordingto these eriteria in Chapter 6.

2.1. Two-Level Formalism 11
2.1 Two-Level Formalism
Morphology describes word formation, i.e., inflection, derivation and
compounding. A base form of a word, e.g., sammeln (to gather) can be
inflected in aparadigmof forms (sammle, sammelst, sammelt, sammelte,
sammelten, etc.), and new words related to it can be produced by usingderivational affixes (e.g., das Gesammelte, the things gathered). Mor¬
phology relies on a lexicon and ruies for handling derived, compoundedand inflected forms by relating them to existing entries in the lexicon.
Word formation consists of three tasks:
1. Specifying the meaning of the entry form from the meaning of the
components.
2. Specifying the components (word roots, derivational and inflec-
tional affixes) and the order in which they can be combined.
3. Specifying how the components are realized in the written or pro¬
nouneed word form.
Although our formalisms are powerful enough to encode semantics
within morphology, the first teisk is not readized in the Syma system and
is not discussed here. The second task, i.e., defining the morphotacticstrueture of words, is discussed in Section 2.3. The third task, which
consists of applying ruies governing spelling and morphophonologicalalternations, is described in this section.
The "dictionary lookup" stage1 in a sophisticated natural languagesystem involves more than simple retrieval. The combination of stems
and inflectional endings, for example, can change spelling, part-of-
speech and meaning in a systematie way. Morphological analysis in
NLP Systems is often carried out by means of language-speeifie pro¬
cedures with little reference to linguistic theories. A straightforwardmethod is to proeeed by Stripping endings from the end of the word form
and by tentatively undoing morphological alternations ([FN88], [FN86],[Ber82], [PK86]). Inflectionally simple languages like English can be
handled successfully in this way; other languages (e.g., Finnish, French
'This stage is similar to the lexical analyzer in a Compiler for a programming lan¬
guage. The entire syntactic and morphological analysis can be compared to syntactic
analysis in a Compiler.

12 Chapter 2. Formalisms
or German) and other morphological phenomena (e.g., compounding or
derivation) are much more difficult to cope with.
2.1.1 Two-Level Model
A computationally efficient approach to describe the process of word
formation is provided by the two-level model of Koskenniemi ([Kos83b],[Kos83a], [Kos84], [KKK87]). The two-level model consists of a lexicon
system and a rule component. The lexicon system contains a set of lex-
icons, some for word roots and others for various classes of endings. A
linking mechemism using continuation classes defines the morphotacticstrueture of words. The two-level model is concemed with the represen¬tation of a word at two distinct levels, the dictionary or lexical level and
the surface level. At the surface level, words are represented the way
they appear in the text. At the lexicon level, words consist of sequencesof prefixes, stems, affixes, diacritics and boundary markers that have
been concatenated without any change. For example, the German sur¬
face form sammle (Ist person singular of to gather) can be representedas sammel+e at the lexical level, and Häuser (houses) correspondinglyas HAus+er2.
Two-level ruies express correspondences between lexical and surface
forms. Ruies consist of a correspondence part, i.e., a pair of symbolsfrom the lexical and surface aiphabet, of an Operator and of a surround¬
ing context, which is speeified by referring to the lexical and surface
environments. Two-level ruies are expressed as regulär expressions over
sets of pairs of lexical and surface characters. Two-level ruies are bidi-
rectional, i.e., they can be applied either to segment surface word forms
into underlying (lexical) morphemes or to generate surface word forms
when the underlying morphemes are given.
The two-level model was developed around 1983. Since then, it
has been modified and extended in several respects ([Bea86], [Bea88a],[Dom90], [RPRB86], [RPBR87]). It has been applied, besides to
Finnish, to such different languages as English, Rumanian, Japanese,French and Arabic. We deeided to implement an extended version of
this model for the following three reasons:
2In this example, the symbol A is an archiphoneme which is realized as o in the
singular form Haus and as ä in the plural form Häuser.

2.1. Two-Level Formalism 13
• It is a general, language-independent and linguistically well-
motivated model to express phonological and Orthographiechanges that occur as a consequence of combining morphemes.It provides a clear Separation between language-speeifie ruies and
general processing mechanisms.
• The reversibility of the two-level model makes it especially at¬
tractive for applications such as text-to-speech Systems. The
grapheme-to-phoneme conversion3 can be done by analyzing the
surface graphemic word form (using morphographemic ruies),looking up the phonetic transcription of each underlying mor¬
pheme and generating the surface phonetic word form (using mor¬
phophonetic ruies). To our knowledge, this is the first time that
the two-level model is used in a text-to-speech system.
• The two-level model can be implemented very effieiently. By com-
piling the two-level ruies to finite automata, an efficient computa¬tional interpretation is achieved.
The applieation of the two-level formalism to several languagesdemonstrated its basie generality and expressiveness, but also revealed
some of its flaws. The version we have implemented as the lexical an¬
alyzer of the Syma system is an extension of the original model. The
concept of mini-lexica and the continuation-class mechanism to encode
co-occurrence restrictions between morpheme classes has been replaced
by an explicit word grammar. The Organization of the dictionary com¬
ponent in the original model has only finite-state power. No additional
mechanism is provided to encode constraints. This has been criticized as
inappropriate to encode morphotax, especially discontinuous dependen¬eies. In our analyzer, the lexicon system consists of a single morphemelexicon and a word grammar. The formalism used for the word grammaris the same as the one used for the sentence grammar and is explainedin detail in Section 2.3. The experience gained in encoding a non-trivial
part of German morphology showed this extension to be linguisticallyadequate and more transparent than the original model.
In the next subsection, we describe a high-level notation to define
3 In our text-to-speech applieation, we use narrow phonetic transcription as de¬
fined in Duden [Man74]. However, it is for the user of Syma to deeide whether
a phonemic or a phonetic transcription should be used and to define the set of
phonemes or phonetic Segments.

14 Chapter 2. Formalisms
alphabets and two-level ruies. The notation is similar to that of Kosken-
niemi [KKK87] and the Edinburgh/Cambridge system [RPBR87]. Ap¬pendix A gives a füll definition of the formalism in EBNF notation.
2.1.2 Rule Syntax
A set of spelling (or phonological) ruies consists of declarations and def¬
initions of character sets and two-level ruies. The surface aiphabet is
the set of symbols that can be used to compose words as they appear in
a sentence. The lexical aiphabet is the set of symbols that can be used
to compose the citation forms of lexical entries. Subsets of these two
alphabets can be declared to facilitate formulating more compact ruies.
The following examples are slightly simplified versions of the alphabets,set definitions and ruies of the two-level morphology for Germern devel¬
oped for our text-to-speech system4.
SurfaceAlphabet ;; definition of the surface aiphabet
{abcdefghijklmnopqrstuvwxyzäöü}
SurfaceSet ;; definition of the surface sets
C is {bcdf ghklmnpqrstvwxyz}
Cl is {bdf gkpstvwxz}
V is {aeij ouäöü}
LexicalAlphabet ;; definition of the lexical aiphabet
{abcdef ghijklmnopqr stuvwxy zäöüABCD + #}
LexicalSet ;; definition of the lexical sets
C is {bcdfghklmnpqrstvwxyz}
Cl is {bdf gkpstvwx_}
V is {aeij» ouäö«}
NullChar 0 ;; special NULL symbol
AnyChar = ;; special ANY sybol
4The two-level ruies for German in our TTS system were developed by Ruth
Rothenberger [Rot91].

2.1. Two-Level Formalism 15
In this example, the lexical symbols A, B, C, D denote morphologicalfeatures which encode the type of a verb stem, + marks a morpheme
boundeiry emd # a word boundeiry. The special symbol 0 (the null) is
used when a lexical character (e.g., a morpheme boundary) correspondsto nothing on the surface.
Two-level ruies are speeified as pairs of symbols (lexical symbol :
surface symbol), ein Operator and a left and right context to speeifywhere the pair is allowed:
<rule> ::- <name> <pair> <operator><leftcontext> " "
<rightcontext>
For exeimple, the deletion of an . in the ending of certain German verbs
in the present tense ceui be described as follows:
s-deletion
_:0 *-> <{s:s z: zx:x} + :0> <t:t>
A lexical . corresponds to a surface 0 after an _¦;_*, z:z or _._
followed by a morpheme boundary +:0 and before t:t. Otherwise,a lexical s corresponds to a surface s.
Examples: ras+st «-+ rast, fliess+st <-» fliesst, sitz+st «-» sitzt,
fix+st *-* fixt
The left and right contexts are basically regulär expressions, with an¬
gle brackets indicating sequences of items, curly braces indicating dis-
junetive choiees and ordinary parentheses enclosing optional items. Al¬
ternative contexts can be speeified with context expressions by using
disjunetions or by fully listing all possible contexts.
The epenthesis rule for German verbs is an example of how alterna¬
tive contexts for the symbol pair + : e can be stated:
e-insertion
< {. : . _ : d}{A : 0 C : 0} >_
< (s : s) t: t >
+ :e *-* ^ < {s : s z : z x : x}C :0> < s : st :t >
< Cl: Cl {m : m n : n}A :0> <(s : s)t:t>

16 Chapter 2. Formalisms
The epenthesis rule describes the insertion of an e in the surface
form between verb stems (present and past tense) and endings.
Examples: arbeitA+st *-* arbeitest, wartA+st «-» wartest,
leidA+t ?-+ leidet, hiessC+st *-* hiessest ebnA+st *-* ebnest,widmA+st *-* widmest
The morphological feature indicating the type of stem is encoded
into the citation (and phonetic) form5 with special symbols which are
deleted (realized as null symbols) in the surface form.
In the previous example, the *-+ Operator was used to define that an
e can be inserted at the morpheme boundary in the surface form if and
only if one of the context restriction holds. Although this Operator is byfar the most frequently used, there are two other Operators which can be
used as well. The Operators have the same meaning as in Koskenniemi
[Kos83b, p 37 ff]:
context restriction: a : b —? LC RC
The lexical character o matches the surface character . only when
it is in the context of LC and RC. The pair a:b cannot appear in
any other context.
surface coercion: a : b«— LC RC
In the context LC and RC, a lexical character a matches only a
surface character b and nothing eise.
combined rule: a : b *-* LC RC
This is a combination of the context restriction and surface co¬
ercion ruies. It states that the lexical character o matches the
surface character b only in the context LC and RC and that a:b
is the only pair allowed in that context.
In the next section, we relate two-level ruies with finite automata
and give a procedural interpretation for two-level ruies.
5The encoding of morphological features into the lexical (graphemic and phone¬
mic) string is somewhat awkward and introduces redundancy in lexical entries. Sev¬
eral modifications have been proposed ([Eme88], [Bea88b], [Bea88a], [Tro90]), which
basically add an additional mechanism to the two-level ruies to access lexical features.

2.1. Two-Level Formalism 17
2.1.3 Ruies and Finite Automata
Two-level ruies use regulär expressions to state in declarative manner
the set of strings of pairs consisting of a lexical and a surface symbol.There are two basic approaches to processing regulär expressions. One
possibiUty is to have them processed directly by an interpreter. This
approach is pursued by Bear [Beei86], who implemented em extended
version of the two-level model. In Bear's system, ruies are directly inter¬
preted as constraints on pairings of surface strings and lexical strings.The second approach is to apply a well-known theorem of automata
theory, which says that, for every regulär expression r, a deterministic
automaton can be constructed which accepts the language L(r) (see,for example, Hopcroft [HU79, p 28 ffj). The compiling of two-level ruies
into finite automata was put forward by Koskenniemi [Kos83b] and is
pursued in this project as well. The description of such a Compiler does
not lie within the scope of this dissertation (see, for example, Kartun-
nen [KKK87]). However, we introduce the definitions of finite automata
and transition graphs for the following reasons:
• The operational semantics revealed by the finite automaton nota¬
tion is contrasted to the declarative notation of the two-level rule.
This leads to a better understanding of the procedural interpre¬tation.
• The transition network formalism described in Section 2.3 is based
on the concept of finite automata.
In the following sections we shall strive to use the same symbols to
denote the same things. We adopt the notation of Hopcroft [HU79] as
far as possible. Unless it is stated otherwise, the reader may assume
that:
1. Q is the set of states of an automaton, qo is the initial state, and
the symbols q and p, with or without subscripts, are states.
2. E is an input aiphabet; symbols a and b are input symbols.
3. 6 is a state transition funetion.
4. F is a set of final states.

18 Chapter 2. Formalisms
5. w, _ and z are strings of input symbols; . denotes the empty string
(consisting of zero symbols).
A deterministic finite automaton (DFA) consists of a finite set of
states and a set of transitions from state to state that occur on input
symbols. We formedly define a DFA as follows:
Definition 2.1 A deterministic finite automaton (DFA) M is a 5-tuple
(Q,E,6,q0,F) where
(1) Q is a finite set of states,
(2) E ts a finite set of input symbols,
(3) 6 is a - possibly partial - mapping from Qx_ to Q, called state
transition funetion,
(4) <_o G Q is the initial state and
(5) F C Q is the set of final states.
To describe the behavior ofa DFA on a string, the transition funetion
_ is extended to apply to a state and a string rather than a state and a
symbol.
Definition 2.2 A funetion 6* from Q x E* to Q is defined such that
(1) 6*(q,e) = q and
(2) 6*(q,wa) = 6(6*(q,w),a) for w G E* and a € E.
We can now define the set of strings aecepted (or recognized) by a finite
automaton (DFA).
Definition 2.3 Let M be a finite automaton M = (Q,Ij,6,q0,F). The
language aecepted by M is the set of strings L(M) = {_ | S*(qo, x) € F}.A language aecepted by a finite automaton M is called a regulär set.

2.1. Two-Level Formalism 19
One way to represent DFAs are transition graphs.
Definition 2.4 Let M = (Q,H,6,qo,F) be a finite automaton. The
transition graph Gm = (T, N) is an unordered labeled graph where the
nodes N of Gm are labeled with the names of the states and, for each
transition t = (p, _,<_), there exists an a € E such that q 6 6(p,a).
As an example, we illustrate how a two-level rule can be transformed
to an DFA and how strings are recognized by such an DFA. The s-
deletion rule of the previous section can be compiled to the followingDFA M = (Q,V,6,q0,F), where
(1) Q = {qo,quq2,q3,q4},
(2) E = {(_ : s), (. : 0), (t: .), (z : z), (_ : x), (+ : 0), (=:=)} and
(3) F={qo,qi,q2,qrt}.
The DFA which encodes the s-deletion rule can be represented as
a transition table of the state transition funetion (see Table 2.1) or as
a transition graph (see Figure 2.1). The transition table contains the
value of the state transition funetion for each state and each pair of
input symbols. The numbers 0 to 4 denote the states go to q±, the
symbol'-' the error state. For the purpose of readability, the transition
graph of Figure 2.1 contains only a subset of the transitions defined bythe transition funetion. The error state is indicated by a filled-in circle.
The DFA proeeeds as follows: For each input word, the automaton
is reset to the initial state and performs a number of transitions. On
each transition, a pair of symbols is aecepted. If the entire string has
been processed and the DFA is in a final state, the string has been
aecepted. As an example, suppose we have the pair of strings ras+st
(lexical form) and rasOOt (surface form) as input. Then, the sequence
of states {<__,<__,<_i)<.2)<_3)<7o}, where qo 6 F, recognizes the string pair.

20 Chapter 2. Formalisms
state
inputss s z x + t =
s z x 0 t =
(lexical char)(surface char)
Qo
9i
92
93
94
- 1 1 1 0 0 0
- 1 1 1 2 0 0
3 4 110 0 0
0 -
- 1 1 1 0 - 0
(normal state)(left context)(left context)(require t)(forbid t)
Table 2.1: Transition table for the DFA "s-deletion"
Figure 2.1: Part of the transition graph of the DFA "s-deletion"

2.2. Features 21
2.2 Features
The use of feature notations to speeify linguistic objects has a longtradition in linguistics, especially in phonology, morphology emd syntax.Features are usually thought of as attribute-value pairs, for example,
(case: nominative) or (cat: verb). While the values of phonological or
morphological features are traditionally atomic (e.g., Ist, nominative,
singular, voieed), most current linguistic theories allow features with
complex values. For example, in German, it may be useful to postulatea feature agreement whose value is a set of features that speeify values
for case, gender and number:
agreement:
case: nominative
gender: masculine
number: singular
In noun phrases (NP), e.g., der bissige Hund (the snappish dog),determiner, adjeetive and noun must agree in case, gender and number.
This is easily expressed by demanding that the veilue of the feature
agreement of each word be "compatible".
Linguistic objects such as morphemes, words or constituents can be
described by stating their properties. The more information such a de¬
scription contains, the more precisely the linguistic objects are speeified.For example, a description specifying only the category NP includes all
possible NPs, such as singular and plural NPs in all cases.
A description Di is more specific than a description D2 if D2 con¬
tains only a subset of the information of Dt. D2 is then said to carry less
information or to subsume Di. The precise definition of "subsumes" or
"carries less information" depends on the notation used and is defined
formally in the following subsections. The binary relation subsumption
(denoted by C) is transitive, reflexive and antisymmetric. All possible
descriptions V, together with the subsumption relation C,form a par¬
tially ordered set (V, C), also called poset. Two Operations on feature
descriptions, unification (iL) and generalization (\l), can be defined as
mappings from V x V to V. The unification of two descriptions Di and
D2 is roughly a description D3 which combines the information con¬
tained in Di and D2. Unification fails if the two descriptions contain

22 Chapter 2. Formalisms
conflicting information. The generalization of two descriptions Di and
D2 is roughly a description D3 containing only the information which
is shared by Di and D2.
In the following subsections, we describe two notations to represent
linguistic objects, namely terms of first-order predicate logic and fea¬
ture structures. We define the relation subsumption and the Operationunification. In addition, we relate features and term structures to the
concept of lattices and give an algebraic and an order-theoretic defini¬
tion. Feature and term structures, together with the Operation unifica¬
tion, are elements of the UTN grammar formalism, which is presentedin Section 2.3.
2.2.1 First-Order Terms
Terms of first-order predicate logic are the first notation we introduce
to speeify linguistic objects. First, we speeify the synteix of first-order
terms, then, we introduce subsumption and unification on terms.
Let A = öAi, for i = 0,1,... with Ai il Aj = 0 for t ^ j, be a ranked
aiphabet where Ai contains the i-adic funetion symbols (the elements
of A0 being constant symbols). Furthermore, let V be the aiphabet of
variables. Variables are written as strings beginning with capital letters— for instance X, Y or Z. Function and constant symbols are written
as strings beginning with lower-case letters — for instance et, 6 or c.
Terms eure defined recursively:
(1) Constant symbols and variables are terms.
(2) U ti,...,t„forn > 1 are terms and / € An, then f(t\,...,tn) is
a term.
The terms f(X,g(Y),c) and np(agreement(Case, Gender, Number))are well-formed first-order terms.
We introduce the notion of Substitution to define subsump¬tion and unification. A Substitution
. is a mapping from vari¬
ables to terms, represented by a finite set of ordered pairs 1? =

2.2. Features 23
{(.i,__i)(.2,__2),...,(tm,Xm)}, where the .,• eire terms and the Xiare distinct variables. To apply a Substitution t, to a term
.,we si¬
multaneously Substitute all occurrences in . of every variable Xi in a
pair (U,Xi) of . with the corresponding term U. For example, the
Substitution ti — {(g(a,b),X),(h(a,X),Y)} applied once to the term
t = f(X,Y) results in _>(.) = f(g(a,b),h(a,X)), and a second appliea¬tion gives tf(t?(.)) = f(g(a,b),h(a,g(a,b))).
Subsumption as the ordering relation on first-order terms is defined
as follows:
Definition 2.5 A term ti subsumes a term tj iff there exists a Substi¬
tution d which, applied to..,
renders ti identical to tj.
U__ tj <* 3x9 | tj = tf(..)
For example, the term U = f(X, Y) subsumes the term tj = f(a, f(b)),since applying the Substitution ti = {(_,__),(/(.), Y)} to ti renders
.,
identical to tj.
Based on the subsumption relation, unification can be defined as
follows:
Definition 2.6 Two terms ti and tj are unifiable iff there exist a Sub¬
stitution t? such that #(.,-) = fl(tj). Then fl is called a unifier ofU and
tj, and .(.,) or d(tj) is called a unification ofti and tj.
U U tj «> 3. | . (tj) = . (U)
Definition 2.7 A unifier . of two terms ti and tj is called a most
general unifier (MGU) ofti and tj iff, for any other unifier 6, there is
a Substitution r such that rd = 6.
For example, 9 = {(a,X),(b,Y)} is a unifier of the terms.,= f(a,Y)
and tj = f(X,Y), while i? = {(a,X)} is the most general unifier. It can
be composed with r = {(6, Y)} to obtain r_ = 9.

24 Chapter 2. Formalisms
Robinson [Rob65] proved that two first-order terms, if uninable, have
a unique most general unifier, up to the renaming of variables. He
gave an algorithm for Computing the MGU and proved it to be cor¬
rect. Reynolds [Kni89] proved the existence of a unique most specific
genereilizer (MSG) for first-order terms.
2.2.2 Feature Structures
Feature structures (also called complex categories) are the second no¬
tation to speeify linguistic objects by sets of features and values. For
example, the singular noun phrase der Mann mit dem Auto (the man
with the car) can be speeified by the following set of feature-value pairs:
D =
cat: NP
case: nominative
agreement: gender: masculine
number: singular
A feature strueture can be defined recursively as a) an atomic value
or b) a set of feature-value pairs, where the features are symbols from
a finite aiphabet and the values are either atomic or themselves feature
structures. More formally: Given a (finite) set of features F and a set
of atomic values C, we can define a set V of complex values as the union
of the sets T>., where Vo = C and X>< is the set of all partial funetions
(complex feature structures) D : F —? öVj for j < i. A partial funetion
D has the finite domain |D|. A value of a partial funetion is either a
constant or itself a partial funetion with a finite domain from features
to values. In addition, the symbol T in the equation D(f) = T is used
to state that the partial funetion D is undefined for the argument /.
Subsumption for complex feature structures can be defined formally as
follows:
Definition 2.8 A complex feature strueture Di subsumes another com¬
plex feature strueture Dj iff all features of Dj are subsumed by the fea¬tures ofDi. More formally: Di C Dj iff both are identical atomic values
or both are partial funetions such that |D.| C \Dj\ and, for all f € |D.|,
Di(f)CDj(f).

2.2. Features 25
The unification of two feature structures is defined as follows:
Definition 2.9 Two categories Di and Dj are unifiable (consistent) iffthere exists a category Dk with Di C D*. and Dj C Dfc.
The least upper bound of two categories corresponds to the most generalunifier of terms.
Definition 2.10 A category Dk is the unification or least upper bound
(supremum) of two categories Di and Dj iff
f Di(f)UDj(f) /€|A-|n|D.|D^D.UD,^ Di(f) f€\Di\-\Dj\ J_r/_|D,|U|D.,|
[ Dj(f) fe\Dj\-\Di\
For example, the unification of the feature structures Di and D2 is the
feature strueture Dz = D1UD2.
Di =
cat: NP
agreement: [ number: singular ]
D2 = agreement:case: nominative
gender: masculine
D,=
cat: NP
case: nominative
agreement: gender: masculine
number: singular
In the examples above, a matrix notation was used to represent com¬
plex feature structures. Another way of representing feature structures
are directed, labeled, aeyclic graphs (dags), a more implementation-oriented notation. For a more detailed discussion of the representation

26 Chapter 2. Formalisms
and linguistic use of feature structures, see Shieber [Shi86]. The rela¬
tionship between feature structures and logical modeis is discussed in
Pereira [Per87].
Feature structures resemble first-order terms, yet are different in
some important respects, namely:
• Substructures are labeled symbolicalry _u_d not by argument posi¬tion (unordered, labeled graph versus ordered, unlabeled graph).
• Arity is not fixed, i.e., structures can be extended both in depthand width.
• In first-order terms, funetion symbols have a special place. In
feature structures, all information has equal Status.
• Variables and co-reference are treated in different ways. In terms,co-reference is realized by using the same variable, which impliesthat constraints are restricted to the leaves of a term.
Nevertheless, feature structures and term structures are equivalent in
expressive power. Thus, feature structures can be converted to term
structures and vice versa.
2.2.3 Lattices and Features
Lattice theory provides a framework for a mathematical treatment of
feature descriptions and the relations and Operations defined on them
(for an introduction to lattiee theory, see, for example, Partee et al.
[PMW90]). First, we expleiin lattices in order-theoretic terms. For this
purpose, we define partial Orders.
Definition 2.11 A binary relation < on a set A is a partial order on
A iff, for all elements a, b and c £ A:
(1) a <a (Reflexivity)
(2) a <b and b<a implies a = b (Antisymmetry)

2.2. Features 27
(3) a <b and b<c implies a <c (Transitivity)
Given a partially ordered set (A, <), henceforth called a poset, we
define an upper bound of B C A as an element a £ A, such that, for
all b € B, b < a. An upper bound a is the least upper bound of B (lubof B) or supremum of B (sup of B) if, for any upper bound c of B,a < c holds. Correspondingly, we define a lower bound of B C A as
an element a £ A such that, for all b € 5, a < b. A lower bound is
the greatest lower bound of B (gib of _3) or infimum of 2? (in/ of B) if,for emy lower bound c of i., c < a. If we add an element T (called top
element) and an element _. (called bottom element) to the set A such
that T < b for any b e A and b < _L for any 6 €E A, we obtain a bounded
lattiee.
Definition 2.12 A poset (A,<) is a lattiee iff, for every a,b € A, both
sup{a, 6} and inf{a, b} exist.
Besides the order-theoretic definition, lattices can also be defined as
algebras, where A is a set and two Operations meet and join are defined
on A.
Definition 2.13 A lattiee is an ordered triple (A,V,A) with a (non¬empty) set A and two binary Operations V (join) and A (meet) such
that, for all elements a, b, c in A, the following laws hold:
LI aV b = b\l a a Ab = bAa (Commutativity)L2 a V (. V c) = (a V 6) V c a A (b A c) = (a A b) A c (Associativity)L3 a V a = a aAa = a (Idempotence)Z/4 a = a V (a A 6) a = a A (a V 6) (Aosorph'on)
The algebraic and order-theoretic definitions of lattices are fully equiv¬alent [Bla90].
How do these two definitions of lattices correspond to term and
feature structures, subsumption, unification and generalization? De¬
scriptions based on the notation of first-order terms or complex feature
structures, together with the subsumption relation, form a poset. The
most unspeeified description corresponds to the top element and the

28 Chapter 2. Formalisms
most speeified (inconsistent) description to the bottom element. The
unification and generalization Operations are instances of the join and
meet Operations, respectively. Consequently, the laws of idempotence,commutativity, associativity and absorption hold for unification and
generalization.
Figure 2.2 shows a portion of the lattiee of first-order terms. The
terms .i= g(a,Y,Z) and t2 = g(X,Y,c), for example, subsume the
term g(a, b, c). Unification corresponds to finding the least upper bound
of two terms in a lattiee. Thus, the term _?(_, Y, c) is the unification of
terms .i and t2. Generalization corresponds to finding the greatest lower
bound of two terms in the lattiee. For example, terms ti = g(a, b, Z) and
t2 = g(X, b, c) are generalized by the term J3 = g(X, b, Z). The bottom
of the lattiee (±), which is a unifier of all pairs of terms, represents
inconsistency. The top of the lattiee (T), which is a generalizer of all
pairs of terms, is called the universal term.
2.3 The UTN Formalism
This section presents the UTN (Unification-based Transition Network)formalism, a new grammar formalism which has been developed as a
part of this work and which has been used in our text-to-speech systemto implement several word and sentence grammars. We present the basic
ideas underlying the formalism and give some examples. Appendix B
gives the speeification of the UTN formalism and Appendix C conteiins
two sample grammars.
Contemporary grammar theories such as Generalized Phrase Strue¬
ture Grammeurs (GPSG), Functional Unification Grammar (FUG) or
Lexical Functional Grammar (LFG) have several properties in common
(see, for example, [Sel85], [Kay84]), which can be eharaeterized as fol¬
lows:
1. They have declarative semantics, i.e., the associations between
strings and informational elements are defined declaratively.
2. They are basically founded on type-2 grammar ruies, i.e., they use
a context-free skeleton.

2.3. The UTN Formalism 29
T (top)
¦ •¦¦¦¦_
g(X,Y,z)
g(a,Y,Z) g(X,b,Z) g(X,Y,c)t
generalization
unification
g(a,b,Z) g(a,Y,c) g(X,b,c) . j
¦ ¦
g(a,b,c)¦ ii
l (bottom)
Figure 2.2: A segment ofthe lattiee of first-order terms

30 Chapter 2. Formalisms
3. They use category sets based on recursively defined trees or di-
rected aeyclic graphs.
4. They are surface-oriented, i.e., they provide a direct charaeteriza¬
tion of the surface order of the string elements in a sentence.
These common properties have significantly influenced the design of
recently developed grammar formalisms, e.g., PATR ([Shi85], [Shi86],[Shi88]), DCG [PW80] and also the UTN formalism. In the seven-
ties, the Augmented Transition Network (ATN) formalism ([Woo70],[Bat78]) was developed, a widespread procedural network formahsm
strongly influenced by transformational grammar theory. By the mid-
eighties, a new trend towards declarative, surface-oriented formalisms
could be observed. This trend is based both on new grammar theories
and the growing interest in logical modeis and logic and constraint-based
programming within Computer science and computational linguistics.The UTN formalism presented in the following sections combines the
coneepts of transition networks, feature structures and unification. It
is designed eis a general, declarative grammar formalism to implementdifferent grammar theories.
In the following sections, we will first discuss recursive transition
networks, an extension of nondeterministic finite automata and then
introduce two variants of the UTN formalism.
2.3.1 Recursive Transition Networks
The UTN formalism is an extension of recursive transition networks
(RTNs). Therefore, we first introduce RTNs, then give an example
grammar and finally discuss the limitations of RTNs when used to char¬
acterize the syntax of natural languages.
A recursive transition network is a directed labeled graph with a dis-
tinguished State called the initial state and a distinguished set of states
called final states. In Section 2.1, we introduced deterministic finite au¬
tomata to capture morphographemic and morphophonetic alternations.
RTNs are an extension of nondeterministic finite automata.
Nondeterministic finite automata extend deterministic finite au¬
tomata by allowing more than zero or one transitions from a state on

2.3. The UTN Formalism 31
the same input symbol. Formally, we define a nondeterministic finite
automaton (NFA) by a 5-tuple (Q,~S,6,qo,F), where Q,E,go and F
(states, input symbols, initial state and final states) have the same
meaning as for DFAs, but_
is a mapping from Q x E —? p(Q) (thepower set of Q).
The transition funetion . can be extended for NFAs to a funetion .
*
mapping QxE*-* jp(Q) as follows:
(1) 6*(q,e) = {q]
(2) 6*(q,wa) = {p | for some state r 6 6*(q,w) with p € ö(r,a)}.
The funetion _>* defines the set of states a NFA can reaeh after
processing an input sequence.
It can be proven (see, for example, Hopcroft [HU79, p 26 ff]) that,for every language L aecepted by any NFA, there exists an DFA that
aeeepts the same language.
For the next sections we will use the following Conventions:
1. The capital letters A, B,C, D and S denote nonterminal symbols;S is the start symbol.
2. The lower-case letters a, b, c, d are terminals.
3. The lower-case letters u, ., iü, _, y, _ denote strings of terminals.
4. The lower-case Greek letters a, ß, 7 denote strings of nonterminal
and terminal symbols.
Although finite automata can recognize non-finite languages, i.e.,
languages that contain an infinite set of strings, there are many non-
finite languages which they cannot recognize. In partieular, languageswhich allow a string to be embedded in another string an unrestricted
number of times, e.g., anbn, n > 0, cannot be described by a DFA.
Furthermore, the recursive strueture of most natural languages cannot
be modeled adequately by DFAs.

32 Chapter 2. Formalisms
Recursive transition networks are an elegant extension of NFAs. The
transitions of FAs are labeled with terminal symbols (or e). The transi¬
tions of RTNs are labeled either with terminal symbols (including c) or
with nonterminal symbols. For eeich nonterminal symbol, there is a cor¬
responding network. A "terminal" transition from s,- to Sj is one which
processes a single terminal symbol a, i.e., Sj € 6(si,a). A "nonterminal"
transition from _,• to Sj is one that processes a string i_ recognized byanother network Ma (labeled A), i.e., Sj € 6(si,Ä).
A recursive transition network grammar thus consists of a set of
terminal symbols, a set of nonterminal symbols aaid a set of recursive
transition networks. It can be defined formally as follows:
Definition 2.14 A recursive transition network grammar Grtn -s a
4-tuple (_V,E,M,5) where
(1) N is a finite set of nonterminal symbols,
(2) E is a finite set of terminal symbols,
(3) S € N is the start symbol and
(J.) M is a set of recursive transition networks with M = {M„ | _ 6
N} for each nonterminal symbol. Each RTN Mv is a 4-tuple
(Qv,qv,6v,Fv) where qv € QV,FV C Qv and 6 : Qv x (N U E) -*
p(Qv)-
Each M., v_ N, defines an acceptance set L(MV), i.e., the set of all
strings which are aecepted by that network. A string w belongs to the
acceptance set of M„ if w can be partitioned into substrings wi• • •
wn
such that there exists a sequence of transitions 6f,(qv,wi ¦ ¦ -wn) 6 Fv
and, for eeich «;,•:
• 6v(qj-i,Wi) = qj and tu; € E or
• -„(<7j_i, A) = qj, Ae N emd wi is in the acceptance set of Ma-
The language aecepted by an RTN grammar Grtn is the acceptanceset of the "top-level" network Ms.

2.3. The UTN Formalism 33
Cd C2) Cc3)
Figure 2.3: Transition network grammar Gl for the language anbncT'
Figure 2.3 shows a transition network grammar Gl consisting of
three networks. The top-level network S (equivalent to the start symbolof formal grammars) consists of three nodes and two transitions. The
transition from state si to state s2 recognizes the strings {_"."}, n > 0,
by recursively traversing the network A. The transition from state s2
to .3 recognizes the strings {cm}, m > 0, by traversing the network C.
The network grammar Gl recognizes the language:
L(M3) = {xe {a,b,c}* | x = anbncm and n,m > 0}
An RTN grammar not only speeifies the set of strings a language
encompasses, but also assigns to each string a constituent strueture tree.
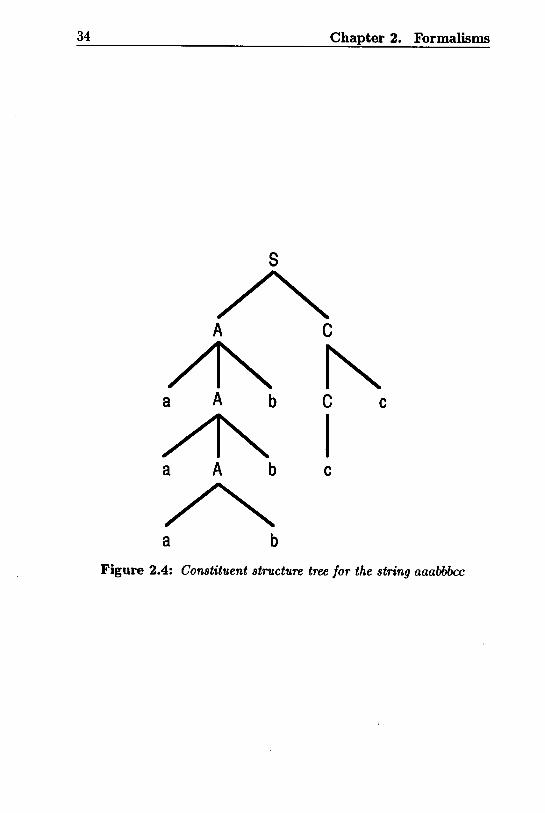
Figure 2.4 shows a constituent strueture tree for the string aaabbbcc.
Constituent strueture trees represent three kinds of information on the
syntactic strueture of a string:
1. The hierarchical grouping of the string into constituents (domi¬nance relation).
34 Chapter 2. Formalisms
y\\ ka A b C c
yy ia A b c
a b
Figure 2.4: Constituent strueture tree for the string aaabbbcc

2.3. The UTN Formalism 35
2. The grammatical type of each constituent.
3. The left-to-right order of the constituents (precedence relation).
RTNs have certain obvious notational advantages over DFAs. Com¬
monly oecurring subpattems can be expressed as named networks, and
large grammeirs can be split into modular networks. In addition, RTNs
reflect the recursive strueture of language in a natural way.
RTNs are equivalent to context-free grammars in their generative ca¬
pacity. For example, the network grammar of Figure 2.3 cem be mappedinto a strongly equivalent context-free grammeir G = (Vr, Vn,S,P),where
(1) the terminal aiphabet is Vt = {_,&,_},
(2) the nonterminal aiphabet is Vn = {S,A,C},
(3) the start symbol is 5 € Vn and
S^AC C^Cc
(4) the grammeir ruies are R= ^ A—taAb C —* c
A->ab
However, RTNs have severe limitations in specifying the syntax of
natural languages. First, there are linguistic phenomena which exceed
the generative capacity of context-free grammars. For example, cross-
serial ordering of subordinate clauses in Swiss German6 can be formallystated as the string ambncmdn, which cannot be expressed by RTNs
or type-2 ruies. Second, other frequent linguistic phenomena, for ex¬
ample, case-gender-number agreement between determiners and nouns
in German, can be expressed as RTNs (or context-free ruies) only by
introdueing a large number of transitions (or ruies). This obscures the
real nature of agreement.
6An example of cross-serial dependency in Swiss German is the subordinate clause
... Jan säit, dass mer d 'Chind em Hans es Huus händ welle laa hälfe aastriche
This is an instance of the pattern NP™NPjV™VJ1, m aecusative NPs followed byn dative NPs, followed by m aecusative-demanding verbs and n dative-demandingverbs. For a detailed description including a proof, see Shieber [Shi87].

36 Chapter 2. Formalisms
2.3.2 Unification-Based Transition Networks
To overcome the limitations of RTNs, we have extended the concept in
two important respects:
1. Terminal and nonterminal symbols are no longer monadic
(atomic) symbols, but name-term pairs or feature structures.
2. In addition to the linear precedence and immediate dominance
relations encoded in the topology of the networks, additional con¬
straints between terminals and constituents can be speeified byusing unification equations.
These extensions considerably increase the generative power of the
formalism, which now includes indexed and fully context-sensitive gram¬
mars, without changing the simplicity and declarativeness of RTNs.
We have developed two variants of the UTN formalism. The variant
we describe first is based on the notation of terms of first-order predicatelogic as described in Section 2.2.2. The second variant is based on
complex feature structures as described in Section 2.2.3.
To explain the two variants of the UTN formalism, we use the gram¬mar G2 (see Figure 2.5), a transition network grammar consisting of four
networks for simple Germern sentences. Network 5, the top-level net¬
work, speeifies an (infinite) set of sentences consisting of a noun phrase(NP) and a verb phrase (VP). The NP consists of
• an (optional) determiner, zero, one or more eidjectives and a noun,
e.g., der sternenübersäte Himmel (the star-spangled sky), or
• a proper name, e.g., Herbert, or
• a pronoun, e.g., er (he), or
• a recursively defined noun phrase followed by a prepositionalphrase (PP), e.g., umweltfreundliche Autos mit niedrigem Ben¬
zinverbrauch (non-polluting cars with low petrol consumption).

2.3. The UTN Formalism 37
>QPrePfrQ NP»Q
Figure 2.5: Transition network grammar G2 for simple German sen¬
tences
The VP consists of em intransitive verb or of a transitive verb fol¬
lowed by an NP. A VP can also have a number of PPs attached to it.
This grammar recognizes sentences such as Die berühmte Astronomin
beobachtet den sternenübersäten Himmel im Observatorium mit dem Ra¬
dioteleskop (The famous woman astronomer observes the star-spangled
sky in the observatory with the radio telescope). Appendix C contains
the code for this example grammeir. There is one version of this gram¬
mar based on name-term pairs and a second version based on feature
structures.
UTN and First-Order Terms
The first variant of the UTN formalism is based on the notation of
• sets of name-term pairs to represent terminals and constituents
and
• unification equations to speeify constraints that must be satisfied
between terminals and constituents.

38 Chapter 2. Formalisms
Terminals and constituents are represented as an (unordered) set of
name-term pairs
<name-terni pair> ::= »(»{"(" <na__e> <term> ")" } ")"
where <name> is a symbol and <term> is either a constant, a variable
(a symbol prefixed by "?") or an optional functor and a series of terms
in peurentheses (infix notation).
<term> ::= <constant>
I <variable>
I "(" <term> {<term>} ")"
For exeimple, a noun phrase can be represented as a set of name-term
pairs in the following way:
/ (cat: NP) \
\ (agreement: (nom singular third masculine)) J
Here cat is the label for the (atomic) term NP, emd agreement is the
label for the (functor-less) term (nom singular third masculine).
Each transition of a network is either labeled with the name of a
terminal symbol (CAT-transition) or a nonterminal symbol (CALL- or
REPLY-transition). Epsilon transitions (JUMP-transitions) are not la¬
beled. In addition, a (possibly empty) set of term equations is attributed
to each transition. A term equation consists of two term expressions,where a term expression is either a <term> or a <feature expr>.
<term equation> ::= "(" <term expr> "=" <term expr> ")"
<term expr> ::= <term> | <feature expr>
Feature expressions are used to access features of a terminal or nonter¬
minal corresponding to a transition. Therefore, feature expressions are
permitted only on CAT- and CALL-transitions.
<feature expr> ::= "(" "feature" <name> ")"

2.3. The UTN Formalism 39
For example, agreement between determiner and noun in grammar G2
(see Figure 2.5) can be speeified as follows:
(feature case) = lease
(feature number) = Inumber
(feature gender) = 1gender
This means that the features case, number and gender of the tran¬
sition under consideration must be unifiable with the logical variables
lease, ".number emd Igender. If these variables were already bound
in previously evaluated equations, it is tested whether these bindingsare compatible (unifiable) with the currently evaluated equations. If
the variables are unbound, they are simply bound and the bindings
propagated to subsequently evaluated equations. For example, in the
grammar G2 of Figure 2.5, the three variables mentioned above can
be bound when evaluating the transition labeled with category det and
tested when the transition labeled with the category noun is evaluated.
This forces agreement in case, gender and number between determiner
and noun in NPs, e.g., der Bruder (the brother). It is important to
note that the result of solving sets of unification equations does not de¬
pend on the order in which these sets are evaluated, as unification is
associative and commutative.
The dummy tremsition (reply) of the final state of a network serves
as an interface to other networks. The reply tremsition speeifies the set
of name-term pairs of a constituent. For example, the set of name-term
pairs of the VP network (see Figure 2.5) could be stated as:
(cat: VP)(subject: (Ipers Inumber))(form: Urans)
This set indicates that the constituent is of category VP and subjectis the label for the term consisting of the value of the current bindingof the variables Iperson and Inumber. These features can be used, for
example, for the subjeet-verb agreement in the _> network.
As long as the number of logical variables in a network is small
and the grammar writer does not use deeply nested terms, grammars
written in this notation are easy to modify and debug. However, the
notation of terms has several properties which become awkward as soon
as a grammar is heavily based on deeply nested terms:

40 Chapter 2. Formalisms
• An argument in a term can be accessed only by indicating its
position, not by using a label.
• There is no simple way to access a single feature in a nested term
without specifying the entire pattern.
• Two terms are unifiable only if they are of same arity. Each time
a term is modified, all terms that can be unified with this term
must be modified as well.
To avoid these disadvantages, we have implemented a second version
of the UTN formalism, which is based on complex feature structures (seeSection 2.2.2) and path equations.
UTN and Complex Features
The second variant of the UTN formalism is based on feature structures
as defined in Section 2.2. The main differences between this variant and
the previous one are:
a) The concept of name-term pairs is replaced by that of complexfeature structures.
b) Term equations are replaced by path equations.
A complex feature is defined as follows:
<complex ieature> ::= <constant>
I <variable>
I "(" { "(" <name> <complex feature> ")" } ")"
The NP given above in feature term notation can be speeified as a
complex feature strueture as follows:
/ cat: NP \f
case: nominative \number: singular
aqreement: ... .
person: third
^ \ gender: masculine ) )

2.3. The UTN Formalism 41
Path equations are used to constrain feature structures, e.g., to de¬
fine agreement between two constituents. A path equation consists of
two path specifiers:
<path-equation> ::= "(" <path-spec> "=" <path-spec> ")"
A <path-spec> is a speeification ("path description") of a feature in a
complex feature strueture. It can also be interpreted as a sequence of
labeis in a directed aeyclic graph.
<path-spec> ::= <constant>
I "(" <feature> {<_eature>} ")"
For example, the path equation
( (noun agreement) = (det agreement) )
which is part of the det transition of the NP-net in grammar G2 (seeFigure 2.5), enforces agreement in case, gender and number of the fol¬
lowing two complex feature structures:
der
( cat:
agreement:
det
case: nominative
number: singular
gender: masculine
\
Mann
{ cat:
\agreement:
noun
case:
number:
gender:
nominative
singularmasculine )
This notation of complex feature structures and path equations is
similar to that of other unification-based formalisms such as PATR
[Shi86] or FUG [Kay84]. The main difference is that the UTN formal¬
ism is based on transition networks instead of type-2 ruies. Transition
networks urge a linguist to moduleirize a grammar. This is a very impor¬tant feature especially when designing large grammars, a feature which
rule-based formalisms such as PATR lack.

Leere Seite\nBlank

Chapter 3
Algorithms
This chapter describes several unification and parsing algorithms which
have been evaluated and implemented as part of this dissertation. These
algorithms constitute the kernel of the Syma system. Section 1 is con¬
cemed with algorithms which unify terms and feature structures. Sec¬
tion 2 relates the problem of parsing to those of search and deduc-
tion. Section 3 highlights the specific properties of natural languageswhich motivate the use of a well-formed substring table and describes
the principle of active chart parsing. Several chart parsing algorithmsare presented and the computational complexity of chart parsing brieflydiscussed.
3.1 Unification
In Chapter 2, we introduced terms of first-order predicate logic and
feature stmctures as notations to represent linguistic objects and sub¬
sumption as an ordering relation on these objects. In addition, we
defined the Operations generalization and unification and showed how
unification equations are used in the UTN formalism to speeify gram-
matical constreiints. In this section, we discuss algorithms which unifyfirst-order terms and feature structures. First, we present some general
coneepts underlying several algorithms. Then, we briefly survey some
43

44 Chapter 3. Algorithms
of the major algorithms found in the hterature. Finally, we discuss in
more detail the algorithms we have implemented in the Syma system.
3.1.1 Unification as the Solution of a Set of Equa¬tions
For the introductory discussion, we use term notation only, as terms and
feature stmctures are of equal expressive power and can be converted
one to the other. The problem of term unification can be stated as that
of solving of a set of equations:
tj = tj, iorj = l,...,k
Each t • and t • denotes a term. A Solution of such a set of unification
equations, if it exists, is called a unifier, which is any Substitution t?
which renders all terms tj and tj identical. There are transformations
which can be applied to such a set of equations to simplify the equationswhile preserving the set of unifiers. A set of equations is in solved formiff the following two conditions are satisfied:
1. All equations are of the form Xj = tj, where Xj is a variable and
tj a term.
2. Every variable on the left side of an equation oecurs only there.
Martelli and Montanari [MM82] presented a nondeterministic algo¬rithm to transform a set of equations into solved form, if such a form
exists. This algorithm is based on the two transformations term redue¬
tion and variable elimination, which are defined as follows:
Term reduetion: An equation of the form f(t1,t2... ,tn) =
/(*i 112 >• • •
i tn) can De repleiced by a set of simpler equations
/ „
ti = ^
'„ = *„

3.1. Unification 45
Variable Elimination: Let X = t be an equation where t is a term
and X is a variable. Apply to all other equations the Substitution
0 = {(.,*)}.
Figure 3.1 shows the algorithm of Martelli and Montanari. For ex¬
ample, the term equation
g(h(Xi),Xi,X2,a) = g(Xi,h(X3),X3,X3)
can be transformed by applying the unification algorithm of Figure 3.1.
After one term reduetion and two variable eliminations, the equationsare in solved form, thereby defining the most general unifier:
_
= {(a,X2),(a,X3),(h(a),Xi),(h(h(a)),X4)}
A number of known algorithms can be derived from this scheme
by determining the order in which the equations are processed and by
specifying data stmctures.
3.1.2 Overview and Evaluation
This section gives an overview of several well-known unification algo¬rithms. These are compared with respeet to computational complexityand ease of implementation. Since unification is an active field of re¬
search, this overview cannot be exhaustive. For a detailed survey of
unification theory, see Siekmann [Sie87], which includes a large biblio-
graphy. The paper of Knight [Kni89] gives an multidiseiplinary survey
of unification.
Term Unification
One ofthe first and still most widely implemented unification algorithmsis that of Robinson [Rob65]. Due to the use of simple data structures,it is rather efficient for small terms. However, its worst-case complexityis exponential in time and space. Boyer and Moore [BM72] investigatedstrueture sharing and proposed a unification algorithm which is efficient
in space consumption, but still has exponential time complexity.

46 Chapter 3. Algorithms
Algorithm: 1
Input: A set of term equations.
Output: A set of term equations in solved form or failure.
Method: Given a set of equations, select an equation and apply one
of the following transformations. Repeat this step until no more
transformations can be applied.
1. If the equation is of the form t = X, where X is a veiriable
and t is either a constant or a nonvetriable term, rewrite this
equation as X = t.
2. If the equation is of the form X = X, where X is a variable,delete the equation.
3. If the equation is of the form t = t", where f emd t" are
nonvariable terms: If the funetion symbols differ, stop with
failure, eise apply term reduetion.
4. If the equation is of the form t = X, where X is a variable
and t zjk X and X oecurs elsewhere in the set of equations,
apply variable elimination.
Figure 3.1: Nondeterministic unification algorithm

3.1. Unification 47
There are also a number of quadratic, almost linear and truly linear
algorithms. Most of these algorithms make use of homogeneous and
vaüd equivalence relations, which are defined below. One example of
an almost linear algorithm, developed by Huet [Hue75], uses equiva¬lence classes and mns in 0(na(n)) time, where a is a very slow-growingfunetion. Another algorithm, with a time complexity of 0(n log n), wasproposed by Martelü and Montanari [MM82]. Paterson and Wegman
[PW78] gave the first tmly linear algorithm for unification. However,this algorithm is mainly of theoretical interest, owing to the use of com¬
plex data structures. Escalada-Imaz and Ghallab [EG88] reported an
algorithm, also based on equivalence classes, which has an almost linear
worst-case complexity due to an efficient UNION and FIND algorithm[Tar75]. The simplicity of the data stmctures makes this algorithm at¬
tractive for practical applications. It has a good average Performance for
terms of varying length and various situations such as frequent clashes,cyeles or success of unification.
Of the unification algorithms above, we have implemented that of
Escalada-Imaz and Ghallab and that of Robinson. We chose the for¬
mer because of its efficiency and simple data stmctures and the latter
because it is Standard and performs well for small terms.
Graph Unification
The hterature on unification algorithms for feature structures is much
sparser than that on first-order terms. We survey only the hterature
which discusses algorithms for the "Standard" feature strueture notation
used in the UTN formahsm. However, a number of extensions for feature
stmctures have been proposed in the past few years. Among these
are disjunetive features [Kas87], negative features and cyclic features
[Shi86].
The algorithms we found in the literature are variations of the al¬
gorithm of Robinson adapted to feature stmctures. Therefore, they all
have exponential time complexity. Several researchers, however, have
detected that the costs of copying the information from the two fea¬
ture structures to be unified to the one resulting from unification are
very high. Therefore, several methods have been suggested to minimize
copying or to use some kind of strueture sharing.

48 Chapter 3. Algorithms
Karttunen [KK85] suggests a kind of strueture sharing by using bi-
neury trees to represent feature stmctures and a "lazy" copying scheme.
The algorithm of Pereira [Per85] is based on stmcture sharing analogousto that of Boyer and Moore [BM72]. However, this strueture sharinghas its own cost, and the algorithm is difficult to implement. Wrob-
lewsky [Wro87] pursued emother approach by implementing a copyingscheme which avoids copying a) too early, i.e., before unification steirts,and b) too much. The algorithm described by Gazdar [GM89] is a
straightforward adaptation of Robinson's algorithm. In addition, it re¬
duces copying to a certain extent by implementing a kind of stmcture
sharing. We deeided to implement1 the algorithms of Wroblewsky and
Gazdar because these algorithms approach the same problem from dif¬
ferent perspectives and are straightforward to implement.
3.1.3 Term Unification Algorithms
The first unification algorithm implemented in Syma is a slightly im¬
proved version of the well-known algorithm of Robinson.
Algorithm of Robinson
The algorithm of Robinson [Rob65] can be regarded as an instance of
the general scheme of Martelli and Montanari. It implements the set
of equations as a Stack. Figure 3.2 shows a variant of Robinson's algo¬rithm. The funetion unify has two terms as input and a boolean value
indicating success or failure of unification and a set of variable-term
bindings as output. The funetion proeeeds from left to right, applyingsubstitutions before each recursive call and composing the unifier re-
turned from the called funetion and that of the calling funetion. The
version of the algorithm presented in Figure 3.2 lacks an oecurs check.
The complete algorithm (and our implementation) includes this check,which tests whether a variable oecurs in the corresponding term before
a variable-term pair is added to the unifier. This test detects cyclic
bindings such as X — f(X).
'We also implemented Pereira's algorithm and an adaptation of the algorithmof Escalada-Imaz and Ghallab for feature structures. The results are presented in
[Coz90].

3.1. Unification 49
Algorithm: 2
Input: Two terms tj and t2.
Output: The value of the boolean variable unifiable, indicating success
or failure of unification, and the most general unifier t? (as a list
of variable-term bindings)
Method: funetion UNIFY(ti,t2)
if tj is a veiriable X and t2 is a term then
(unifiable,ti) *- (true,{(X,t2)})eise if t2 is a variable X and ti is a term then
(unifiaUe,ti) *- (true,{(X,ti)})eise if ti is a constant and t2 is a constant and ti = t2 then
(unifiable, _) <— (true, {})eise if tj = /(Xi,... ,__¦„) and t2 = g(Yu. ..,Ym)and f = g and m = n then
k *- 1 and (unifiable, _) <— (trwe, {})while fc < m and unifiable do
(unifiable,T) +- UNIFY(d(Xk),d(Yk))if unifiable then i? <— compose(T, i9)k*-k + l
ret\ini(unifiable, t,).
Figure 3.2: Version of Robinson's unification algorithm
The algorithm has exponential time and space complexity. For ex¬
ample, in the unification of the terms
^1 = /(-^r»)-^n-l,---,-^l)
h = f(9(Xn+i,Xn+i,Xn+i),...,g(X2,X2,X2))
the unifier grows exponentially. By not explicitly replacing the variables
in the subterms by their bindings, space complexity can be reduced
considerably. A kind of strueture sharing is achieved when terms share
common subterms.

50 Chapter 3. Algorithms
Algorithm of Escalada and Ghallab
This unification algorithm relies on the explicit constmction of equiv¬alence classes of variables and funetion terms. The algorithm can be
eoneeived as a realization of the scheme of Martelli and Montanari. The
algorithm makes use of the following two definitions:
Definition 3.1 A homogeneous equivalence relation holds between two
terms t and t iff:
(1) One of the two terms is a variable or
(2) t' and t are nonvariable terms with the same constant or funetion
symbol and all their subterms t: and tj are pairwise equivalent.
A homogeneous equivalence relation is a valid equivalence relation
under the following conditions:
Definition 3.2 A valid equivalence relation holds between two terms t"
.rr
and t iff:
(i) A homogeneous equivalence relation holds between t and t and
(ii) the equivalence classes formed by their sti&terms are partially or¬
dered such that a subterm t is before the class of term t,- if ti is a
subterm oft.
An important theorem [Hue75], which is the common basis of several
unification algorithms, is based on these two definitions. The theorem
states that two terms t and t are unifiable iff there exists a valid
equivalence relation that makes the terms equivalent. If such a relation
exists, then the equivalence classes define the most general unifier of the
terms.
The unification algorithm by Escalada-Imaz and Ghallab is based
on definitions 3.1 and 3.2. We briefly sketch its principle. A detailed
description of the algorithm together with the proof of its correctness
can be found in [EG88].

3.1. Unification 51
1. The first step builds the homogeneous equivalence classes by
traversing the two terms from left to right. For each equiva¬lence class, a directed graph is constructed which connects all vari¬
ables and funetion terms within the same class. Each class maycontain at most one nonvariable term. For example, the terms
*i = /(_f(-*i»a)»X2,X4) and h = f(X2,X3,h(X2,b)) define two
equivalence classes, represented as directed graphs:
X2 -+ __3 -+ g(Xi,a) X4-* h(X2,b)
Equivalence classes consisting of variables only may contain a loop.During the construction of these equivalence classes, the most fre¬
quent Operation is to collapse two classes or to find the class of
a variable. For these two Operations, the algorithm uses the effi¬
cient and well-understood UNION and FIND algorithm [Tar75],These two Operations determine the almost linear complexity of
the unification algorithm.
2. The second step tests whether a homogeneous equivalence relation
is a valid equivalence relation according to definition 3.2. For this
purpose, a graph Gv is constructed from the graph representingthe equivalence classes. The graph Gv contains all nodes of the
equiveilence classes. In addition, for each node which consists of a
funetion term, all variables are connected with their equivalenceclasses. An equivalence relation is valid iff any loop in the cor¬
responding graph Gv contains only variables. If a looping graphcontains a funetion term, then a term t has a subterm t,- which
again contains term t as a subterm, e.g., X = f(X). This test for
cyeles corresponds to the oecurs check in Robinson's algorithm.The unifier is constructed in parallel with the cyclicity test. For
the example above, the result of unification is the following unifier:
.= {(g(Xi,a),X3),(g(Xua),X2)(h(g(Xi,a),b),Xi)}
In the algorithm of Robinson, the oecurs check is carried out each
time a variable-term pair is unified. Since this test is separate from the
construction of the unifier, it can be omitted to gain efficiency2. In the
algorithm of Escalada-Imaz and Ghallab, the oecurs check is embedded
in the construction of the unifier and cannot be omitted.
2For this reason, most Prolog interpreters omit the oecurs check.

52 Chapter 3. Algorithms
3.1.4 Graph Unification Algorithms
Algorithm of Gazdar
The graph unification algorithm of Gazdar and Mellish [GM89] is a
straightforward transformation of the term unification algorithm of
Robinson. The algorithm, which is non-destractive, recursively unifies
two feature structures by Computing a Substitution which makes the two
feature stmctures identical. Each feature stmcture is represented as a
tuple consisting of a skeleton and a Substitution. A skeleton is a hst of
feature-value pairs, where a feature is a constant and a value is either
a constant, a variable or a hst of feature-value pairs. A Substitution
contains the variable bindings to extend a skeleton. This corresponds
largely to the term Substitution notation of first-order terms as used in
Robinson's algorithm. One important difference between terms and fea¬
ture structures is that the number of arguments in a feature strueture
can grow during unification. Therefore, a special feature is attached to
each feature strueture at the last position whose value can be bound to
an extension of a feature strueture. By separating the representation of
feature stmctures into skeletons and substitutions, it is easy to imple¬ment a non-destruetive unification algorithm without construeting the
resulting feature strueture from Scratch, thereby implementing a kind
of stmcture sharing.
Algorithm of Wroblewsky
The unification algorithm of Wroblewsky [Wro87] is eilso based on the
algorithm of Robinson. It is a non-destruetive algorithm, i.e., the fea¬
ture stmctures to be unified are left unchanged. The basic motivation
behind this algorithm is to avoid extensive copying of feature structures
and eomplicated strueture sharing. Destmctive unification algorithmsoften make a füll copy of both feature stmctures during the unifica¬
tion process. This is termed over copying, since not all features of both
structures are used to create the resulting feature stmcture. In addition,the copies are often made before unification starts. This is called early
copying. Whenever unification fails, copying is a wasted effort. Wrob¬
lewsky suggested that an efficient copying approach is to be preferred to
a strueture-sharing approach. In his algorithm, feature structures are

3.2. Parsing 53
implemented as directed aeyclic graphs (dags), where each node con¬
tains the Ust of outgoing arcs and copy information. The process of
copying is elosely tied to unification. A node is copied as soon as the
unification algorithm reaches it. Depending on whether the two nodes
to be unified are both copies or not, a destmctive or non-destmetive
version of unification is applied. The algorithm of Wroblewsky alwaysavoids early copying of nodes. In most cases, it also avoids over copying.
3.2 Parsing
This section first introduces some parsing terminology and relates pars¬
ing to the problems of deduetion and search. Then, it presents a scheme
to classify parsing algorithms, which is used in the subsequent sections.
Finally, it discusses the parsing algorithms implemented in the syntacticand morphological analyzer.
The term parsing3 has slightly different meanings, depending on
whether it is used in formal language theory, computational linguisticsor artificial intelligence (for a discussion of these different meanings, see,
for example, Karttunen [KZ85]). In the context of this work, the term
parsing is used to denote the process of finding the syntactic structure(s)associated with an input string. A sentence w is said to be parsed if:
(1) It has been shown that w is in the set of sentences defined by a
grammar G and
(2) one (or all) derivation trees have been constructed.
A parsing algorithm is a procedure which parses an input string byexecuting a finite number of elementary instruetions. For each type of
grammar according to the language hierarchy of Chomsky, there are
various parsing algorithms with different time and space complexity.
The problem of parsing bears a close relationship to those of search
and deduetion, and parsing algorithms are similar to algorithms knownto solve those problems.
3The term parsing is derived from the Latin expression pars orationis, which
means part of speech.

54 Chapter 3. Algorithms
Deduetion: A formal greimmeir is essentially a deductive system of
axioms emd ruies of inference which generates the sentences of a
language as a theorem. The axiom of a grammar is the start sym¬
bol, usually S, and the ruies of inference are the production mies.
The problem of parsing a sentence corresponds to the problem of
proving that a theorem follows from a set of axioms and mies of
inference. The process of parsing corresponds to the construction
of such a proof. First-order predicate logic is also a deductive
system of axioms and ruies of inference. Thus, a formal grammar
can be mapped into first-order predicate logic, and a general infer¬
ence mle (e.g., modus ponens or the resolution principle) can be
used to "parse" a sentence, i.e., to prove that a sentence is a the¬
orem. An example of such a mapping is the definite-clause gram¬
mar (DCG) formalism ([PW80], [PS87]), an extension of CFG
ruies that are translated into Hörn clauses (a subset of first-order
predicate logic). Linear input resolution, a proof procedure based
on the resolution principle, is used to "parse" a sentence. This
proof procedure is very similar to a top-down/left-to-right/depth-first/backtrack parsing algorithm.
Search: A formal grammar can also be eoneeived as a description of a
search space. All legal sentential forms derived from the start sym¬
bol S constitute the state space. The problem of parsing a stringcorresponds to the problem of finding a node in the search space
which contains this string as a sentence, i.e., as a sentential form
containing only terminal symbols. Parsing algorithms resemble
search algorithms in many respects. For parsing algorithms such
as top-down/depth-first, top-down/breadth-first or bottom-up al¬
gorithms, there are equivalent search algorithms. Heuristic search
strategies such as best-first, hill-climbing or __*-search [Tan87] cem
be tremsformed to parsing algorithms in a relatively straightfor¬ward manner ([Rus89], [HG88]).
In order to discuss and compare algorithms to parse natural lan¬
guage, we set up a Classification scheme. Parsing algorithms for natural
language can be eharaeterized according to the following three dimen¬
sions:
• The direction of processing, i.e., whether the input string is pro¬
cessed from left to right, from right to left or middle out (from

3.2. Parsing 55
any position in the string in both directions).
• The rule invocation strategy, i.e., whether new instances of a
mle are created top-down (expeetation driven), bottom-up (datadriven) or in a combined mode.
• The search strategy, i.e., whether the parser proeeeds depth-first,breadth-first or in some other manner, depending on the data
stmcture that manages the currently executable tasks.
The design of parsing algorithms for our synteictic and morpholog¬ical analyzer was guided by the following considerations. First, in ap¬
plications such as text-to-speech conversion, where the input consists of
syntactically correct Orthographie text, it seems appropriate to parse a
sentence from left to right, i.e., the same way a text is written and pro¬
nouneed. Therefore, our parser works from left to right. However, there
are applications, e.g., speech recognition, where it may be advantageousto have a parsing algorithm that proeeeds in both directions startingfrom a position in em utterance that has been recognized with high ac¬
curacy by the underlying phonological recognizer. Such algorithms are
often termed bi-directional or isknd-driven. Second, our parsing algo¬rithm has to find all possible syntax trees (all-path peirser). Therefore,it makes no difference whether a depth-first, breadth-first or heuris-
tic search strategy4 is used. The same number of nodes of the search
graph is visited in all of these search strategies. In the implementationdescribed in this thesis, a depth-first or breadth-first strategy can be
selected by setting a system parameter. Third, our parser has to find
all parses effieiently. It does so by pruning, as early as possible, search
paths which are bound to fail and by avoiding traversing the same partof the search space more than once. In general, it is not clear whether
a top-down or a bottom-up strategy performs better when parsing nat¬
ural language. Therefore, we have implemented several top-down and
bottom-up strategies and compared them on the basis of several gram¬
mars and test sets. The strategies have been implemented within the
framework of chart parsing. Chart parsing is a quite general and flex¬
ible scheme to implement and test different parsing strategies. Before
presenting the rule invocation strategies in detail, we briefly describe
the basic coneepts of active chart parsing.
4We have also condueted some experiments to compare different heuristic strate¬
gies ([Sch89], [Rus89]) to improve the Performance ofthe parser and to disambiguatesentences.

56 Chapter 3. Algorithms
3.3 Chart Parsing
Natural language utterances are often syntactically ambiguous. This
means that more than one parse tree can be derived for one input string.The phenomenon of ambiguity is one of the most striking features of
natural languages as opposed to programming languages, which eure de¬
signed to avoid ambiguity. Parsing the sentence Peter beobachtet den
Kometen mit dem feurigen Schweif (Peter observes the shooting planetwith the fiery tail) with grammar G2 (see Figure 2.5 of Chapter 2), for
example, results in two parse trees (see Figures 3.3 emd 3.4). Parse
trees derived from an ambiguous sentence often differ only slightly in
strueture. In the example above, both trees have the same constituents.
The only difference between them is the attachment of the prepositional
phrase (PP node) mit dem feurigen Schweif, which is either attached
to the verb phrase or to the object noun phrase. This simple examplereveals a characteristic of the ambiguity found in natural language: The
search space defined by a grammar is redundant, i.e., several parts of the
space are identical. If a parser is not capable of recognizing this redun-
dancy, Computing time emd memory is wasted. For example, depth-firstsearch with backtracking can traverse the same subpart of the search
space over and over again, which leads to a worst-case time complexityof 0(cn), where n corresponds to the length of the input. In the case of
blind breadth-first search, this leads to the same time complexity and
a worst-case Space complexity of 0(cn).
This waste of Computing time and memory can be avoided by in¬
trodueing a device called well-formed substring table (WFST), which is
used to keep a record of the phrases that have already been found. By
Consulting the WFST, a parser avoids parsing the same phrase more
than once. However, the use of a WFST cannot stop a parser from
investigating hypotheses that have failed previously. For this purpose,
it is necessary to have an explicit representation of the various goalsand hypotheses that the parser has at any one time. This extension of
a WFST is called an active chart
The idea of chart parsing was originally developed within compu¬
tational linguistics by Kay ([Kay73], [Kay77], [Kay82]) and refined by
Kaplan [Kap73]. Independent of and parallel to Kay and Kaplan, an
algorithm to parse general context-free grammeirs quite simileir to that
of Kay was developed by Earley [Ear72]. In the following, we will briefly

3.3. Chart Parsing 57
npr verb det noun prep det adj noun
Peter beobachtetden Kometenmitdem feurigenSchweif
Figure 3.3: Syntax tree (Ist Solution) for the sentence "Peter
beobachtet den Kometen mit dem feurigen Schweif."

58 Chapter 3. Algorithms
npr verb det noun prep det adj noun
Peter beobachtetden Kometen mitdem feurigenSchweif
Figure 3.4: Syntax tree (2nd Solution) for the sentence "Peter
beobachtet den Kometen mit dem feurigen Schweif."

3.3. Chart Parsing 59
describe the principle of chart parsing and then focus on the aspects of
rule invocation strategies. For a more comprehensive introduction to
chart parsing, see, for example, Gazdar et al. [GM89].
Let us define a chart as a directed labeled graph C = (V, E), where
V is a set of vertices and E a set of edges. An edge is defined as a
5-tuple [i,j,A,a,ß], where t and j are the numbers of the vertices the
edge starts and ends, respectively, A is the name of the constituent5, et
the string of daughters of A that have already been parsed and ß the
string of daughters that remains to be parsed. For example, the edgeei = [1,3, NP, det adj, noun] (see Figure 3.6) represents an instance of
the rule6 NP —» det adj noun. The edge starts at vertex 1 and ends at
vertex 3, and it is of category NP. The string a = det adj is the partof the mle which has already been recognized, the string ß — noun the
part which remains to be processed starting at edge 3.
An edge for which ß = e is called an inactive edge, which means that
the edge has been completely processed and a constituent recognizedin the input string. For example, [2,5, VP,verbNP,e] is an inactive
edge. Figure 3.5 shows the inactive edges of the chart after parsingthe sentence Peter beobachtet den Kometen mit dem feurigen Schweif
(Peter observes the shooting planet with the fiery tail). An edge for
which ß j= e is called an active edge, which means that this edge has
not yet been fully processed. For exeimple, [1,3, NP, det adj, noun] is an
active edge. Figure 3.6 shows a section of the chart for the sentence Das
weisse Haus steht auf dem Hügel (The white house Stands on the hill),which contains active as well as inactive edges.
Chart parsing is based on the data strueture chart as described above
and three processes:
(1) The applieation of the fundamental rule.
(2) The scheduling of multiple hypotheses.
(3) The invocation of grammar ruies.
The fundamental rule states that an eictive edge ei = [i, k, A, a, Cß]
5The name of the constituent corresponds to the left-hand side of a rule or the
label of a transition network.
6A rule corresponds to a path in a transition network.

60 Chapter 3. Algorithms
Peter beobachtet den Kometen mit dem feurigen Schweif
Figure 3.5: Example of a chart (only the inactive edges are shown)

3.3. Chart Parsing 61
[4,8,vP,(verbPP),ö]
(lANPidetadjnounM)]
[1,3,NP,(detadj),noun]
Figure 3.6: Part of a chart which contains active and inactive edges
and an inactive edge e2 — [k, l, C, 7, e] can be combined to form a new
edge e3 = [i,l,A,ctC,ß] if the target vertex of the active edge is the
source vertex of the inactive edge and the inactive edge satisfies the
conditions for extending the active edge. The new edge e3 is constructed
as follows:
• The source vertex is the source vertex of edge e_.
• The target vertex is the target vertex of edge e2.
• The category is the category of edge e_.
• Its contents are a funetion7 of the contents of ei and e2.
For example, the fundamental rule can be applied to the active
edge [4,5,VP,{PP}*]8 and the inactive edge [5,8,PP,prepNP,e] to
7The funetion depends on the grammar formalism used.
8Curly braces and the Kleene star are used to indicate zero, one or more repeti-tions. This corresponds to self-looping transitions as for example in the VP network
of grammar G2 (see Figure 2.5 of Chapter 2) in a transition network.

62 Chapter 3. Algorithms
form a new (inactive) edge [4,8, VP, verb PP, e] and a new (active) edge[4,8,VP,verbPP,{PP}*].
Scheduling deals with the order in which multiple hypotheses gen¬
erated by a nondeterministic grammar are processed. A data stmcture
called an agenda is used to störe the hypotheses to be explored, i.e.,the tuples of eictive emd ineictive edges to which the fundamental rule
can be apphed. The Organization of the agenda determines the search
strategy. If the agenda is implemented as a queue (first-in first-out),this leads to a breadth-first search strategy, where all hypotheses are
explored in parallel. If the agenda is implemented as a Stack (last-infirst-out), the parser behaves in a depth-first manner. If all alternatives
are sorted according to some heuristic rank funetion, a heuristic search
strategy such as best-first is obtained. Heuristic parsing strategies are
sometimes used to disambiguate sentences in the absenee of semantic
knowledge, improve search Performance [HG88] or model human pars¬
ing preferences.
The order of invocation of the grammar ruies is the third character¬
istic of chart parsing. It governs the invocation of the initial hypothesesin a top-down or a bottom-up manner. Besides these pure forms, there
are refined versions of rule invocation strategies. These are discussed in
the following two sections. They use additional information on a gram¬
mar, i.e., the FIRST, FOLLOW and REACHABILITY relations, which
are defined as follows:
FIRST(a) defines the set of terminal symbols a string a cem start
with. For example, FIRST(S) = {det,adj,noun,npr,pron} is the set
of terminals a sentence of grammar G2 (see Figure 2.5) cem begin with.
Definition 3.3 LetR = (N, S,M,5) be a recursive transition network
grammar and et 6 (iVUS)*. FIRST(a) = {w \ w e £ and aAwß for
FOLLOW(A) is the set of terminals that can immediately follow a
nonterminal symbol A. For example, in grammar G2 (see Figure 2.5),FOLLOW(NP) = {verb,prep, $}, where the symbol $ denotes the end
marker of a sentence.
Definition 3.4 Let R = (N,H,M,S) be a recursive transition network

3.3. Chart Parsing 63
and B€N. FOLLOW(B) = {w \ S 4> aBj and w 6 FIRST^)}
The REACHABILITY relation 3. holds between two symbols A and
B if there is a derivation from A to B such that B is the first element
in the string dominated by A. More formally:
Definition 3.5 LetR = (_V, S, M,S) be a recursive transition network,
A £ N and B_ (N U E). B is reachable from A, Ä&B <s> A 4- Sa in
any sentential form.
The FIRST relation is a subset of the REACHABILITY relation.
The REACHABILITY relation can also be defined as the transitive
closure of the left-corner relation, i.e., all tuples consisting of the sym¬
bol of the left-hand side emd the first symbol of the right-hand side of
all grammeir mies in em e-free contex-free grammar. For example, in
grammar G2 (see Figure 2.5), the REACHABILITY relation includes
the following tuples: {(S, NP), (S, det), (NP, noun),...}.
The above relations can be precomputed and stored for a specific
grammeir. At parse time, this information can be used to effieientlyguide the rule invocation strategy. In the next two sections, we describe
four top-down and four bottom-up strategies which make use of these
relations. These eight strategies have been implemented in our chart
parser.
3.3.1 Top-Down Strategies
Top-down parsing can be viewed as finding a derivation for an input
string. Beginning with the start symbol, nonterminal symbols are re¬
placed step by step by the right-hand sides of the corresponding ruies
until the string consists of terminal symbols only. Top-down parsingcan also be regarded as construeting a parse tree for the input stringstarting from the root and creating the tree in preorder.
There are several top-down strategies (see, for example, [AU72],[ASU86]), general but quite inefficient top-down algorithms based on
backtracking or recursive algorithms and nonrecursive algorithms based
on LL(k) tables, where k indicates the number of lookahead symbols.

64 Chapter 3. Algorithms
Between the general (exponential) algorithms based on backtracking,which can be used to parse context-sensitive languages, and the ef¬
ficient (ünear) LL(k)-algorit_ms, which are, however, restricted to a
subset of the context-free languages, there is a class of quite efficient
algorithms which can parse general context-free languages. These algo¬rithms, sometimes also called tabular parsing methods [AU72], belong to
the family of chart parsing algorithms, which are especially well-suited
to parse natural languages.
In the following, we present four top-down rule invocation strategies,starting with the most simple but leeist efficient one, which is a pure top-down strategy. The other three strategies use the FIRST and FOLLOW
relations to pmne search paths which do not lead to a parse.
Strategy Tl (top-down) Strategy Tl is the simplest top-down rule
invocation strategy discussed here. After initializing the chart with an
inactive edge [i,i + l,Cj,Cj,e], for eeich input word a< of category Ci,a new active edge [1,1, S,e, X] is added to the chart for each transition
(qs,X,p). These initial hypotheses predict that the input string will be
parsed as a constituent of type S. The top-down parser proeeeds as
follows: For every pedr of active and inactive edges, the fundamental
rule is apphed. In addition, each time an active edge "seeking" as next
symbol a nonterminal X is eidded to the chart, an empty active edge of
category X is eidded to the chart at the vertex where the active edgeends (unless it is already in the chart). The fundamental mle and the
prediction of new, empty active edges are apphed until no more edgescan be added to the chart. If the chart contains one or more inactive
edges of type 5 (i.e., [l,n,5,a, e]) that span the entire chart, the inputstring has been recognized. Otherwise, the string does not belong to the
language defined by the grammar. Figure 3.7 shows a simplified version
of the recognition algorithm.
In an implementation, an edge can be extended to contain a parse
tree, thereby turning the recognizer into a parser. In addition, an effi¬
cient indexing scheme can be used instead of a simple hst to maintain
the set of active and inactive edges. Furthermore, a second data stmc¬
ture called an agenda can be used to störe the tuples of active and
inactive edges to which the fundamental rule is to be apphed. Depend¬ing on whether the agenda is implemented as a Stack, queue or sorted
list, the algorithm behaves as a depth-first, breadth-first or heuristic

3.3. Chart Parsing 65
Algorithm: 3
Input: A recursive transition network (RTN) R = (N, S, M, S) and an
input string w = -1-203 ...an with a< 6 S
Output: An inactive edge [1, n + 1,5, a, e] or fedlure
Method: Initialize the set of edges I by performing step (1). Repeat
steps (2) and (3) until no new edges can be added to the set I.
1. For every terminal et,- of the input string, add an edge
[i,i + l,Ai,Ai,e] to the set of edges I. For each transition
(qs, X,p) with X € (S U N) and p 6 Qs of Ms, add an edge
[1,1,5, €,__"] toset/.
2. Whenever an active edge ej = [i,j, A,a,B] is eidded to set /,
add, for every transition (qß,X,p) of Mb, a new active edge
[_/,_•',5,e,__] to set I (unless this edge is already in set I).
3. Let et- = [i,j,A,a, e] be an inactive edge. For each ac¬
tive edge efc = [k,i,B,ß, A] of set _" and for each transition
(6*(QB,ßÄ),X,p), add a new edge [k,j,B,ßA,X] to set L
Figure 3.7: Top-down chart parsing algorithm

66 Chapter 3. Algorithms
search algorithm.
Strategy T2 (top-down with selectivity) Grammars for natural
languages tend to have a large branching faetor, as, for a nonterminal A,there are frequently several ruies which expand A. It is often possible to
restrict the number of alternatives if it is known which set of terminals
can derive the first nonterminal of the right-hand side of a rule (ortransition network). This is exactly the information a predictive top-down parser uses to select one of a set of alternative ruies [ASU86].Each time the parser enters a transition network of category A, each
active edge [.,.,__,e,.B] is tested to see whether it cem derive the input
symbol a,- by examining whether a< e FIRST(B). Therefore, step (2)two of the top-down algorithm of Figure 3.7 is modified as follows:
Whenever an active edge e = [i,j, A, a, B] is added to set /,
eidd, for every transition (qi,,X,p) of Mb, a new active edge
[j,j,B,e,X] to set I if aj £ FIRST(B).
Remark: This strategy is similar to predictive LL(k) parsing. How¬
ever, it is more general because it parses all context-free grammars. It
corresponds to Kay's "directed top-down" scheme [Kay82], a directed
top-down strategy that uses the FIRST relation to test whether the
next input symbol is in the FIRST set of the active edge each time an
empty active edge is created.
Strategy T3 (top-down with lookahead) The use of the FIRST
relation significantly reduces the number of useless active edges. The
applieation of the FOLLOW relation can be used in a similar way to
reduee the number of useless inactive edges. This is important, since
inactive edges not only use storage but may also trigger new active
edges. Each time an inactive edge [i,j,A,a,e] is added to the chart,it is tested whether the next input symbol aj (to the right) is in the
FOLLOW set of the nonterminal A. Therefore, step (3) of the top-down
algorithm (see Figure 3.7) is modified as follows:
Let e,- = [i,j,A,a,e] be an inactive edge. For each active
edge ej_ = [k,i,B,ß,A], if S*(qs,ßA) £ Fß (a final State

3.3. Chart Parsing 67
is reached) and aj £ FOLLOW(B), add an inactive edge[k, j,B,ßA,c] to set I; eise, if 6*(qß,ßA) & Fb (non-finalstate reached), add, for each transition (6*(qs,ßA),X,p),an active edge [k, j,B,ßA,X] to set I.
Remark: This strategy corresponds to the algorithm of Earley [Ear72]with a one-symbol lookahead.
Strategy T4 (top-down with lookahead and selectivity) The
most directed strategy is obtained by combining the features of strate¬
gies T2 and T3. This leads to a very efficient algorithm that uses the
FIRST and FOLLOW relations whenever an active or an inactive edgeis added to the chart. Steps (2) and (3) of the top-down algorithm of
Figure 3.7 are replaced by steps (2) and (3) of strategies T2 and T3,
respectively.
Remark: Predictive top-down parsing has been proposed by several
researchers ([Kay82], [Wir87]). Top-down parsing with lookahead is
described by Earley [Ear72]. However, the combination of predictionand lookahead has never been studied. Based on our experiments (seeChapter 4), a most directed strategy, such as strategy T4, seems to
outperform other strategies.
3.3.2 Bottom-Up Strategies
Bottom-up strategies can be considered to construet a parse tree for
an input string beginning at the leaves (bottom) and working up to
the root (top). Shift-reduce algorithms [ASU86] are among the best-
known bottom-up strategies that reduee an input string to the start
symbol by creating a right-most derivation in reverse. A subclass of the
shift-reduce family often used to implement parsers for programming
languages are the LR(k) algorithms, which are basically non-backtrack
shift-reduce parsers whose shift and reduee actions are guided by an FA.
Besides the general backtracking-based bottom-up algorithms capableof handling all context-sensitive languages and the special shift-reduce
algorithms capable of handling only a subset of the context-free lan¬
guages (called LR languages), there are quite efficient algorithms to
recognize general context-free languages. These algorithms belong to

68 Chapter 3. Algorithms
the class of tabular parsing methods [AU72]. In the foUowing, we de¬
scribe four variants of the left-corner algorithm, a type of bottom-uprule invocation strategy. We start with the simplest but least efficient
one and continue with improved versions.
Algorithm: 4
Input: A recursive tremsition network RTN R = (_V,E,M,5) and an
input string w = _ia2a3... an with _,• £ S
Output: An inactive edge [1,»' + l,5,a,e] or failure
Method: Initialize the set of edges / by performing step (1). Repeat
steps (2) and (3) until no new edges cein be added to the set I.
1. For every terminal a,- of the input string, add an edge [*,»' +1, .li, Ai,e] to the set of edges I. For all input items _,- and for
each transition (qB,A,p) of all Mb € Af, add a new active
edge [i, i, B, c, Ai] to set i\
2. Whenever an inactive edge e = [i,j, A, a, e] is ewlded to set I,
add, for every tremsition (qß,A,p) of Mb £ M, a new active
edge [i,i,B,e,A] to set I (unless this edge is edready in set
3. Let e,- = [i,j,A,a,e] be an inactive edge. For each ac¬
tive edge et, = [k,i,B,ß,A] of set / and for each transition
(6*(QB,ßA),X,p), add a new edge [k,j,B,ßA,X] to set I.
Figure 3.8: Bottom-up chart parsing algorithm
Strategy Bl (left-corner) Before describing the left-corner algo¬
rithm, we introduce some terminology. The left corner of a rule is the
leftmost symbol (terminal or nonterminal) on the right side. Similar,the left corner of a transition network is the set of terminals and non-
terminals a network can start with. We often refer to the transitive
closure of the left-corner relation using the term reachability relation
as well. The basic idea of left-corner parsing is to index each transi¬
tion network by its left corners. When a phrase is found, networks that
have that phrase as their left corner eure tried in turn by looking for

3.3. Chart Parsing 69
phrases that span remaining paths through the network. Roughly, in
left-corner peirsing, the left comer of a transition network is recognizedbottom-up and the remainder of the network is recognized top-down.Figure 3.8 shows the algorithm for left-corner parsing. A left-corner
parser traverses the parse tree bottom-up and inorder.
Strategy B2 (bottom-up with top-down filter) Bottom-up
strategies often propose constituents that do not match higher-levelconstituents. This is a severe problem for grammars that have many
common right factors. If, for example, the NP network has two pathswhich derive det noun and noun, this network is triggered twice on
the input string der Mann (the man), once on der and once on Mann.
Bottom-up parsers are overproductive in edges that do not attach to
phrases on the left. Directed bottom-up parsing avoids this problem bya teehnique that is the dual of predictive parsing. Directed bottom-up
parsing is somewhat like running a top-down parser in parallel. Each
time an inactive edge is added to the chart, it is tested whether there
is an active edge at the start-vertex of the inactive edge which can be
extended by the inactive edge. Step (2) of the bottom-up algorithm is
modified as follows:
Whenever an inactive edge [i, j, A, a, e] is added to set I, add,for each transition (g_j, A,p) of Mb £ M, a new active edge
[i,i,B,e,A] to set i" if there is em active edge [k,i,C,a,D]and D$tA.
Strategy B3 (bottom-up with lookahead) Left-corner parsingcan also be optimized in another way by using a kind of lookahead
similar to that of strategy T3. Each time an inactive edge is added to
the chart, it is tested whether the next input symbol to the right of
the inactive edge is in the FOLLOW set of that edge. Step (2) of the
bottom-up algorithm is modified as follows:
Whenever an inactive edge e = [i,j, A, a, e] is added to set I
and aj £ FOLLOW(A), add, for every transition (qs,A,p)of Mb £ M, a new active edge \j, k,B,e, A] to set I.

70 Chapter 3. Algorithms
Strategy B4 (bottom-up with top-down filtering and looka¬
head) The most efficient bottom-up algorithm is obtained by com¬
bining the top-down filter of strategy B2 and the lookahead of strategyB3. Step (2) of the algorithm of Figure 3.8 is modified in the following
way:
Whenever an inactive edge e = [i,j,A,a,e] is added to set I
and _j £ FOLLOW(A), add, for every transition (qu, A,p)of Mb £ M, a new active edge [i,i,B,e,Ä] to set I if there
is an active edge [k, i, C, a, D] and DMA.
Remark: This strategy is similar to Tomita's extended version of the
LR edgorithm [Tom86] which can be used to parse general context-free
languages.
3.3.3 Computational Complexity
In the previous sections, we presented eight rule invocation strategieswithin the framework of chart parsing. In this section, we discuss the
computational complexity of chart parsing, i.e., its worst-case asymp-
totic time and space complexity. Time complexity is a measure for the
number of elementary mechanical Operations executed as a funetion of
the input. Space complexity is a measure of the memory that is requiredto störe intermediate results as a funetion of the size of the input. To
indicate complexity, we use the 0-notation9. In order to analyze the
complexity of chart parsing, we restate the algorithm in a form revealingthe parallelism between context-free parsing emd matrix multiplication.This was originally shown by Martin et al. [MCP87]. Without loss of
generedity, we assume that the grammeir is in Chomsky Normal Form
[AU72]. Edges between vertex -i and vertex Vj consist of all possiblecombinations of edges from vertices u,- to vk and edges from vertices
vk to Vj as created by the applieation of the fundamental rule of chart
parsing.
9The use of the O-notation for upper bound wipes out constants from complexityformulas. For example, an algorithm with complexity 8n3 + 5n is O(n'). More
formally, we say that a funetion / is "of order g" ox 0(g) iff there exists positiveconstants c and fc such that, for all n > fc, |/(n)| < c|_f(n)|.

3.3. Chart Parsing 71
chart(i,j) := Ui<j_<j-/»art(., fc) *chart(k,j)
The chart parsing algorithm can be stated as follows:
beginfor j := 1 to n do
chart(j - l,j) := {A \ A -* wordj} (lexicon)for i := j - 2 downto 0 do
chart(i, j) := Ui<fc<j chart(i, fc) * chart(k, j) (fund. rule)end
end
if 5 in chart(0, n) then accept eise reject.end
This algorithm has time complexity 0(n3), considering all combina¬
tions of tJ,fc, eeich of which have n possible values. The combination
of two edges, i.e., the applieation of the fundamental rule, is indepen¬dent of the length of the input sentence and requires constant time. The
space complexity of chart parsing is 0(n2), since each vertex i. contains
around t incoming edges.

Leere Seite\nBlank

Chapter 4
Comparison of
Algorithms
In this chapter, we discuss the practical efficiency of the algorithms
presented in Chapter 3 and report the results of em empirical comparisonof the eight rale invocation strategies described in Chapter 3.
4.1 Introduction
When building practical natural language Systems on small, interac¬
tive Computers such as personal Workstations, it is crueial to have ef¬
ficient algorithms with low computational complexity. The computa¬
tional complexity of parsing and unification algorithms has been stud¬
ied extensively in Computer science, mostly in terms of worst-case time
and space complexity. Although the knowledge of (theoretical) upper
bounds leads to a better understanding of algorithms, it may turn out to
be of less significance when processing natural language. For example,Barton [BBR87] has proved the two-level model presented in Chap¬ter 2 to be NP-hard (by transforming the Boolean satisfiabihty probleminto two-level generation and recognition). However, Koskenniemi and
Church [KC88] have shown that the number of harmony processes (e.g.,vowel harmony or umlaut) in natural languages is relatively small and
73

74 Chapter 4. Comparison of Algorithms
that therefore the average complexity of the two-level model is low. To
infer from the worst-case complexity that the two-level model is ineffi¬
cient for morphological analysis is therefore rather misleading. In fact,
experiments have revealed that the practical efficiency is almost hnear.
This does not mean that we want to argue against complexity theory.
Complexity theory may give useful insights when apphed to linguistictheories. However, it looks at these theories from only one partieular
point of view. Furthermore, complexity theory provides only a coarse-
grained measure, as it ignores constants in complexity formulas. These
constants may very well be significant or even decisive for practical ap¬
plications. An example of this is the truly hnear unification algorithm of
Paterson, which is mainly of theoretical interest because of its large con¬
stant faetor. Another example are chart parsing algorithms, all of which
are of time complexity 0(n3). Nevertheless, algorithms which make use
of relations such as FIRST or FOLLOW are significantly more efficient
than "undirected" algorithms, although they belong to the same com¬
plexity class. Therefore, we believe that, in order to build efficient NLP
Systems, it is not sufficient to take into account only the theoretical
worst-case complexity of the algorithms used. The algorithms must
also be compared and evaluated on "natural" data, and the potential
computational sinks of a system must be carefully investigated before
selecting an appropriate algorithms.
The overall Performance of our parser is determined mainly by the
following two algorithms:
• The chart-parsing algorithm, which creates and manipulates edgesand applies the fundamental rule.
• The unification algorithm, which is part of the fundamental rule.
The unification algorithm is part of the parsing algorithm. Each
time the fundamental mle of chart parsing is applied, the unification
equations associated with the active edge are evaluated. Depending on
the style a grammar is written in, the computational bürden is shifted
from one algorithm to the other. A grammar can be written either
by defining a large number of networks with few (or even no) unifica¬
tion equations or by a small number of networks with many unification
equations. The style a grammar is written in depends largely on the

4.2. Unification Algorithms 75
linguistic theory emd the preferences of the grammar writer. For this
reason, our parser is designed to be configurable.
In the following, we report the results of the experiments we con¬
dueted to investigate the practical efficiency of the parsing and unifi¬
cation algorithms implemented in the Syma system. The parsing and
unification algorithms are integrated in a general chart parser using the
same data structures (e.g., lexicons, grammars and chart). This makes
it possible to compare them on a fair basis. For the algorithms, the
same monitoring tools were used to collect data about time and Space
efficiency. The entire Software was written in a similar programmingstyle, and programming tricks of any kind were avoided to make the
code more transparent and easier to maintain. The experiments were
ran on a DEC Vaxstation 3200 (with 24 MB of main memory) using a
Common Lisp programming environment. The time indicated does not
include garbage-collection time.
4.2 Unification Algorithms
Unification is integrated in the chart parsing algorithm. This makes it
difficult to measure1 the CPU time used for unification alone, irrespec¬tive of the remaining steps of the parsing algorithm. To circumvent this
problem, we implemented an interface to use the unification algorithmswithout the chart parser and measured time consumption on "artificial"
data.
The practical efficiency of the two graph unification algorithms(Wroblewsky's and Gazdar's) is roughly equal. The main difference
lies in space consumption, where the algorithm of Wroblewsky is supe¬
rior to that of Gazdar. However, both algorithms are of exponentialworst-case time complexity.
The efficiency of the two term unification algorithms (Robinson'sand Escalada-Imaz and Ghallab's) is about the same for short and/orsimple terms. For example, in unifying the two following terms (set51), both algorithms demonstrate a nearly linear behavior.
'To measure how much CPU time is spent in a funetion, we used the Common
Lisp macro TIME. Due to the relatively low resolution of this macro, funetions which
consume little CPU time cannot be measured very reliably.

76 Chapter 4. Comparison of Algorithms
*1 = f(X„,Xn-i,...,Xi)
.2= f(Xn-i,Xn-2,...,Xi,a)
Table 4.1 shows the (relative) CPU time used to unify these terms, with
n ranging from 1 to 20. The algorithm of Robinson is denoted by R,
the algorithm of Escalada-Imaz and Ghallab by EG.
n 2 4 6 8
ARITY
10 12 14 16 18 20
R
EG
0.09
0.08
0.09
0.08
0.10
0.09
0.12
0.10
0.13 0.15
0.11 0.12
0.17
0.13
0.19
0.13
0.21
0.14
0.25
0.15
Table 4.1: Test set Sl
For more complex terms, the algorithm of Escalada-Imaz and Ghal¬
lab is superior in almost all cases. For example, when unifying the two
terms below (set 52), the algorithm of Escalada-Imaz and Ghallab is
still almost linear, whereas the algorithm of Robinson is exponential.
h = f(X„,X„-i,.. .,Xi)
tl = /(_;(-^n+l,-^n+l)-X"n+l))---,5(^2,-^2)^2))
Table 4.2 shows the CPU time elapsed for n ranging from 1 to 20.
With Robinson's algorithm, we stopped measuring at n = 14.
n 2 4 6 8
ARITY
10 12 14 16 20
R
EG
0.10
0.09
0.30
0.10
2.62
0.11
28.14
0.13
304.0 3101.5
0.14 0.15
32636.9
0.16 0.17 0.20
Table 4.2: Test set S2

4.3. Rule Invocation Strategy 77
However, when parsing natural languages, terms of the above com¬
plexity rarely occur. In our grammars, term unification is mostly used
to bind constants to variables or to unify terms with an arity of 1 to
5 and without deeply nested subterms. For such grammars, the algo¬rithm of Escaleida-Imeiz and Ghallab is only about 20% faster than that
of Robinson. Nevertheless, the sum of the features of the algorithm of
Escalada-Imaz and Ghallab makes it most suitable:
1. Its worst-case complexity is almost hnear.
2. Its practical efficiency is very high due to simple data stmctures.
3. Cycle testing is pe_rt of the construction of the unifier emd requiresno additional steps.
4. It is relatively easy to implement.
Concludingly, at least for applications such as natural language pro¬
cessing, the algorithm of Escalada-Imaz and Ghallab is superior to the
algorithm of Robinson.
4.3 Rule Invocation Strategy
In this section, we compare the eight rule invocation strategies presentedin Section 3.3. We use several grammars and sample sentence sets to
measure empirically space and time efficiency.
4.3.1 Complexity Measure
Chart parsing is basically centered around the creation and manipu-lation of edges. Therefore, a reasonable measure of efficiency is the
number of edges produced, since producing edges is a time- and space-
consuming Operation. The UTN formedism as well as most other cur¬
rently used greimmeir formalisms make use of complex Operations such
as unification when applying the fundamental mle of chart parsing.Therefore, we also measured the number of applications of the funda¬
mental mle and the CPU time elapsed for it. Depending on the style

78 Chapter 4. Comparison of Algorithms
a grammar is written in, between 10 to 90 percent of the total CPU
time is used for the applieation of the fundamental rule. This was often
neglected in other comparisons ([Sha89], [Wir87), [Tom86]). While ab¬
solute parsing time is of less interest because it highly dependent on the
hardware, operating system and programming language used, relative
parsing time2 is a good overall indicator of Performance and therefore
also indicated.
Besides the efficiency measures mentioned above, we also coUected
data on the effectiveness ofthe "filters" (i.e., the FIRST, FOLLOW and
REACHABILITY relations) we used. We were interested in knowinghow much each relation contributes to improving the efficiency of the
parsing strategy.
4.3.2 Sample Grammars
For our experiments, we used six different grammars, three German and
three English grammars. Grammar GlGer is a simple toy grammar (seeFigure 2.5 of Chapter 2) of 4 networks, 16 transitions and 17 unification
equations. Grammars GLlGer and GHIoer were developed for our text-
to-speech system ([Huo89], [Mun90]). Grammar GIlGer consists of 22
networks, 113 states, 361 transitions and 513 unification equations. This
grammar covers—
among others — the following phenomena:
• declarative sentences (with partial free order among the argumentsof the main verb)
• relative clauses
• separable-prefix verbs
• ordering among main, auxiliary and modal verbs
• simple noun groups (without coordination)
Grammar GIIlGer is an extension of GÜGer and consists of 48
networks, 279 states, 770 transitions and 1246 unification equations.Grammar GHIgst covers a larger part of German than Gllcer, in¬
cluding the following phenomena:
2Peirsing time is always indicated relatively to the fastest algorithm.

4.3. Rule Invocation Strategy 79
• decleirative sentences
• predicative sentences (subject first, inverse subject)
• interrogative sentences (yes/no- emd wh-questions)
• imperative sentences
• several types of coordination (on the word, phrase and sentence
level)
• several types of subordinate clauses.
In addition to the Germern grammars, we have translated three
context-free English grammars from rule notation to transition net¬
works. The grammars were taken from Tomita [Tom86]. We used these
grammeirs mainly to compare our results with those of other researchers
who used the same greimmars. Grammar G__j„ffj ([Tom86, p 171]) con¬
sists of 8 mies emd was converted to a strongly equivalent transition
network grammar with 4 networks with 14 states and 17 transitions.
Grammar GÜEngi ([Tom86, pp 171-172]) consists of 43 mies emd was
converted to a network greunmar with 13 networks, 62 states and 90
transitions. Grammar GIÜEngi ([Tom86, pp 172-176]) consists of 220
ruies and was converted to a grammar with 36 networks, 228 states and
407 transitions.
4.3.3 Sample Sentences
We used one set of sample sentences each for the grammars. The set
SlGer for the German grammar (__Ger consists of sentences formed
according to the following Schema:
Noun Verb Det Adj Noun (Prep Det Noun)"
An example of such a sentence is Peter sieht den alten Mann mit dem
Fernglas auf dem Hügel (Peter sees the old man with the telescope on
the hill). The number of parses grows very quickly for these sentences
due to the various possibilities to attach prepositional phrases. In fact,the number of parses grows as follows:

80 Chapter 4. Comparison of Algorithms
1, 2, 5, 14, 42, 132,... or1_ / 2n - 2 \
n V n-1 )
These are the Catelan numbers, which grow almost exponentially.
For grammars GUcer and GIÜGer, we provided a set of sentences
each. Set SÜGer consists of 40 sentences with 5 to 18 words, and set
SIÜGer consists of 40 sentences with 4 to 19 words (see Appendix D).
For the English grammars, we used the two sentence sets from
Tomita. Set 5_ßngj consists of 10 sentences [Tom86, p 81] with a syntac¬tic strueture similar to that of set Slcer- Set SIIEngl [Tom86, pp 183-
185] consists of 40 sentences, most of which are taken from publications.The length of the sentences varies from 1 to 32 words. The lists of the
sample sentences can be found in Appendix D.
4.3.4 Experiments and Results
We apphed all parsing strategies (four top-down and four bottom-up)to each grammar and test set. Each of the following tables presents the
results of a test series.
Each table lists the number of active edges (AE), the number of inac¬
tive edges (IE), the total number of edges (TOT=AE+IE), the number
of applications of the fundamental rule (FR) and the (relative) parse
time to parse the entire test set. In addition, we also indicate the
rank for each strategy with respeet to CPU-time (denoted by Rcpu) and
memory consumption (denoted by Rmem)- These figures are listed for
all eight rule invocation strategies. The order of the strategies is the
same as in Chapter 3.
Strategy Tx is the undirected top-down strategy, T2 the top-down
strategy using the FIRST relation ("selective top-down"), T3 the top-
down strategy using the FOLLOW relation ("top-down with looka¬
head") and T4 the strategy using the FIRST and FOLLOW relations
("selective top-down with lookahead").
Strategies _.j to B4 are the bottom-up (left-corner) strategies. Strat¬
egy Bi is the undirected bottom-up strategy, B2 the strategy using a

4.3. Rule Invocation Strategy 81
Str AE IE TOT FR TIME Kcpu "¦mem
Ti 12897 7841 20738 17948 1.08 3 4
T2 12881 7841 20722 17948 1.08 4 3
T3 11978 6003 17981 16110 1.00 1 2
T. 11962 6003 17965 16110 1.01 2 1
Bi 26971 13889 40860 43982 2.82 8 8
B2 25493 13889 39382 36536 2.03 6 7
B3 26052 12051 38103 42144 2.75 7 6
B4 24574 12051 36625 34698 1.98 5 5
Table 4.3: Parsing set 5_c?er with grammar GIgc
Str AE IE TOT FR TIME "¦cpu "¦mem
Ti 207752 19744 227496 116732 1.17 4 4
T2 191572 19744 211316 116140 1.04 2 2
T3 202667 13098 215765 109678 1.12 3 3
T. 186835 13098 199933 109110 1.00 1 1
Bx 506196 63312 569508 289131 2.33 8 8
B2 293866 26235 320101 168834 1.31 6 6
Bz 488257 36584 524841 260705 2.07 7 7
B. 285703 18980 304683 159904 1.26 5 5
Table 4.4: Parsing set SÜGer with grammar Gllce
reachability table, B3 the strategy using the FOLLOW relation and B4the strategy using a reachability table and the FOLLOW relation.
The first three tables (Tables 4.3 to 4.5) present the results of the
experiments with the German grammars (Glcer, GHcer and GIÜGer)-The second three tables (Tables 4.6 to 4.8 show the results of the
experiments with the three Enghsh greimmars (GlEngl, GHEngl and
GIIIEngl)-
For eeich of these six tables, there is a corresponding table in Ap¬pendix E containing additional information. Among others, the tables
contain the number of fails of the fundamental rule (caused by failure
of unification) and some information concerning the effectiveness of the
FIRST, FOLLOW and REACHABILITY relations. It is indicated how
often they are applied and how often they fail. A large number of fails

82 Chapter 4. Comparison of Algorithms
Str AE IE TOT FR TIME /lepu "¦mem
Ti 228795 15742 244537 147930 1.22 6 6
T2 187209 15724 202933 143089 1.07 4 3
T3 221296 13496 234792 139073 1.18 5 5
T4 179898 13478 193376 134258 1.03 2 1
Bi 308341 32190 340531 242535 1.42 8 8
B2 190312 17506 207818 157736 1.05 3 4
B3 294758 27581 322339 223715 1.34 7 7
B4 181728 14855 196583 147122 1.00 1 2
Table 4.5: Parsing set SIÜGer with grammar GIIIgs
Str AE IE TOT FR TIME "cpu "¦mem
Ti 12485 7825 20310 20110 1.00 1 4
T2 12469 7825 20294 20110 1.01 2 3
T3 12485 6906 19391 20110 1.04 3 2
T4 12469 6906 19375 20110 1.06 4 1
Bi 18241 9223 27464 27100 1.41 7 8
B2 15373 9223 24596 24304 1.29 5 6
B3 18241 8304 26545 27100 1.46 8 7
B4 15373 8304 23677 24304 1.34 6 5
Table 4.6: Parsing set SlEngl with grammar Glßngl
increases the overall efficiency of the parser. Each failure prevents the
parser from wasting CPU time and memory by exploring "dead-end"
paths in the search space.
4.3.5 Discussion
This section discusses the results of the parsing experiments.
The tables demonstrate that parsing efficiency is strongly influenced
by the language, the grammar, the grammar formahsm and the sen¬
tence set. Other parsing experiments (e.g., [Sha89], [Wir87], [Tom86])arrive at simileir conclusions. Nevertheless, by carefully tuning a parsing
strategy, efficiency can be significantly increased. Memory consumption

4.3. Rule Invocation Strategy 83
Str AE IE TOT FR TIME "¦cpu "mem
Ti 13902 4858 18760 14917 1.16 5 6
T2 12262 4858 17120 14849 1.00 1 3
T3 13902 4312 18214 14917 1.24 6 5
T4 12262 4312 16574 14849 1.07 3 1
Bi 24703 9368 34071 29855 1.95 7 8
B2 12262 4858 17120 14849 1.05 2 3
Bz 23953 7498 31451 28730 1.97 8 7
B4 12262 4312 16574 14849 1.14 4 1
Table 4.7: Parsing set SlEngi with grammar GÜEngi
can be reduced by up to a faetor of four emd CPU time by up to a fae¬
tor of three. This faetor can even be improved by implementing the
lookup step for the various relations more effieiently, thereby reducingthe overhead caused by testing.
Undirected top-down strategies (T.) perform better than undirected
bottom-up strategies (Bi) in our experiments. The reason for this
is that the grammars we used have a large number of common left
factors3, but a comparatively low branching faetor4. This is, of course,
a grammar-dependent feature.
Directed strategies5 outperform undirected strategies with respeet to
parsing time and memory usage. This holds for top-down and bottom-
up strategies.
The FIRST relation contributes more to the increase of efficiencythan the FOLLOW relation. The lookahead feature (FOLLOW rela¬
tion) is not as effective as might be expected. This is largely due to
3By common left factors, we mean prefixes in the right-hand side of a rule or
network which are common to several ruies. For example, the prefix a is common
to the two ruies A —* aß and B -* ay. The more such ruies a grammar has, the
more ruies must be tried when parsing bottom-up.
4By branching faetor, we mean the average number of right-hand sides of a rule
(or transitions leaving the start Vertex of a network). A large branching faetor causes
a top-down parser to explore a large number of hypotheses, most of which will fail
later on.
5The algorithm of Tomita can be considered a maximally directed chart-parser
that uses the FIRST and FOLLOW relation to construet an LR-table at compiletime.

84 Chapter 4. Comparison of Algorithms
Str AE IE TOT FR TIME "¦cpu "¦mem
Ti 91578 16946 108524 54689 1.54 5 5
T2 69160 16946 86106 54689 1.10 2 2
T3 76288 13880 90168 44226 1.39 3 3
T4 55173 13880 69053 44226 1.00 1 1
Bi 210021 49372 259393 168871 2.85 8 8
B2 99001 22797 121798 75509 1.55 6 6
Bz 169299 40022 209321 138232 2.73 7 7
B4 84984 19415 104399 65016 1.52 4 4
Table 4.8: Parsing set SÜEngl with grammar GIÜEngi
the fact that all our grammers are highly overgenerative. The more
restricted a grammeir is, the more effectively lookahead can be put to
use. The effect of lookahead also varies from languages with free word
order to languages with a more fixed word order.
In general, it is not clear whether the most directed top-down strat¬
egy (T4) or the most-directed bottom-up (B4) strategy is more efficient.
As we have already argued, this depends largely on the style a gram¬
mar is written in. In most of our experiments, T4 was the more efficient
strategy.
The results of our comparison favor directed strategies such as T4
or B4. However, there are situations where undirected strategies are
preferable. When parsing incomplete sentences or sentences not cov¬
ered by a grammar, an undirected bottom-up strategy can be used to
break up a sentence into smaller phrases, which can then be parsed.We have built such a "fall-back" faeility into the Syma system. It is
apphed whenever a sentence cannot be parsed by the default strategy.In such cases, pieces of a sentence are parsed bottom-up, and a dynamic
programming procedure selects the largest constituents which cover the
entire sentence. Although this cannot be considered a linguisticallysound error recovery strategy, it works reasonably well and provides the
parser with a kind of "graceful degradation".

Chapter 5
Implementation
This chapter describes the implementational aspects of the Syma Soft¬
ware. Section 5.1 states the requirements for the implementation and
the underlying design considerations. Section 5.2 gives an overview of
the Syma Software from the point of view of the implementation, and
Section 5.3 describes the essential features of each module.
5.1 Requirements and Design Considera¬
tions
The primary aim of the prototype implementation was to show that
the concept suggested for the morphological and syntactic analyzer can
be implemented and used in a practical applieation such as a text-
to-speech system. Furthermore, the implementation was to meet the
following requirements:
• Language-specific knowledge, e.g., lexical entries or grammatical
ruies, should be strictly separated from programs1. All language-
*This aspect distinguishes our approach from Systems such as GRAPHON [PK86]or MORPHIX [FN86], which were developed especially for German morphology, and
where linguistic knowledge was encoded directly into the program.
85

86 Chapter 5. Implementation
specific knowledge should be kept as data structures, thus en-
abling the system to process syntax and morphology of different
languages2.
• The Software should be portable. Therefore, it should not rely onhardware- or operating-system-dependent features.
• Each module should be self-contained to allow experimenting with
it and extending and modifying parts of it without affecting other
modules. It should be possible to configure the Software to meet
the requirements of a user or an applieation.
These requirements, together with some general principles of Soft¬
ware engineering (e.g., modularization, use of abstraet data structures,code sharing through objeet-oriented programming), led to the followingdesign considerations:
• A knowledge-based architecture was chosen, as it supports a clear
Separation between language-specific knowledge and general "in¬
ference" mechanisms. This architecture is also put forward by the
use of declarative formalisms.
• The general-purpose programming language Common Lisp3 (CL)([Ste84], [Frei88]) was used for the implementation of the entire
system. CL is especially suited for the task at hand because:
- It supports rapid prototyping and provides a sophisticatedSoftware development environment.
- It has a rieh set of predefined data types and high-level fune¬
tions.
- It allows different programming styles (imperative, functional
and objeet-oriented) and is well-suited for symbolic compu¬
tation.
- It is a quasi-standard supported by most Computer manufac¬
turers and operating Systems.
2At the time of this writing, the Syma system has been applied to German and
English morphology and syntax.3Other programming languages such as Prolog or Smalltalk would also meet most
of the requirements stated above. Common Lisp was chosen because it is one of the
most frequently used programming languages in NLP research.

5.2. System Overview 87
• The entire system is designed as a set of relatively independentmodules (or packages, in CL terminology). The user has access
to the funetions exported by each module through a common in¬
terface, which hides the underlying modules. The behavior of the
system is controlled by a set of parameters, e.g., to select a default
parsing strategy and unification algorithm or to control input and
output funetions. These parameters cem be changed interactivelyor initialized during the start-up of the system. The entire Soft¬
ware is designed to be flexible emd easy to extend and adapt to
different applications.
5.2 System Overview
The SYMA Software consists of eight major CL packages4. Each packagecontains a set of related funetions, meicros and data structures which
implement its functionality. Figure 5.1 gives an overview of the hier¬
archical Organization of the packages, and Table 5.1 shows the size of
each package in number of source code lines. The following list brieflysummarizes the functionality of each package:
INTERFACE This package provides a command-hne interpreterwhich connects the user to the funetions imported from the under¬
lying packages. It also provides interactive help and trace facilities
as well as a general setup funetion to change system parameters.
PARSER This package implements a general chart parser. It can be
parameterized to process in a depth-first or breadth-first manner.
One out of four top-down and four bottom-up strategies can be
selected.
GRAMMAR This package consists ofa set of funetions to load transi¬
tion network grammars from text files, compile them and initialize
the internal data structures used to interface the grammar to the
chart parser.
4A package is an entity to lüde data structures and funetions and to make the
modular strueture of large Lisp Systems more explicit. Symbols which should be
known outside of a package are part of the public interface of a package. The
concept of packages is comparable to the concept of modules in Modula-2.
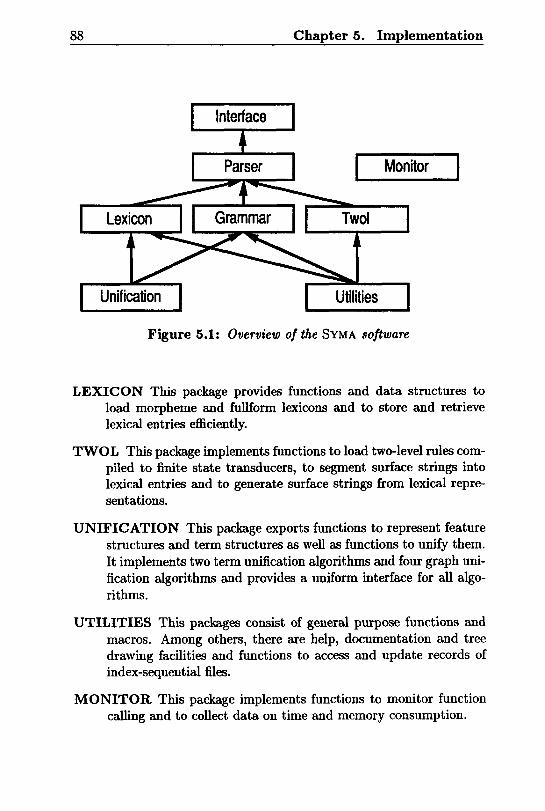
88 Chapter 5. Implementation
Figure 5.1: Overview ofthe Syma Software
LEXICON This package provides funetions and data structures to
load morpheme and fullform lexicons and to störe and retrieve
lexical entries effieiently.
TWOL This package implements funetions to load two-level ruies com¬
piled to finite state transducers, to segment surfeice strings into
lexical entries and to generate surface strings from lexical repre¬
sentations.
UNIFICATION This package exports funetions to represent feature
structures and term structures as weh as funetions to unify them.
It implements two term unification algorithms and four graph uni¬
fication algorithms and provides a uniform interface for all algo¬rithms.
UTILITIES This packages consist of general purpose funetions and
macros. Among others, there are help, documentation and tree
drawing facilities and funetions to access and update records of
index-sequential files.
MONITOR This package implements funetions to monitor funetion
calling and to collect data on time and memory consumption.

5.3. Description of Packages 89
Module Name Code Size Description
INTERFACE 1'600 command interpreter, setup, helpPARSER 2'500 chart parser
GRAMMAR 900 grammar loader emd CompilerLEXICON 1'200 lexicon system
TWOL 700 finite automata interpreterUNIFICATION 6'200 unification algorithmsMONITOR 6'000 monitor Utilities
UTILITIES 3'300 general purpose Utilities
Table 5.1: Overview and size of source code ofthe Syma Software
5.3 Description of Packages
This section describes the essential features of the six major packagesand discusses some implementational aspects relevant to the under¬
standing of the Syma system.
5.3.1 Interface Package
The peickage INTERFACE provides a command-line interpreter to in¬
teract with the user. To ensure portability, the interface is based on
the Standard (TTY-based) CL input and output funetions and does not
use window, mouse or menu intereictions. The Syma system can be
configured intereictively by changing the system parameters. The user
can set parameters:
• to select the knowledge bases (e.g., lexicons, spelling ruies or gram¬
mars);
• to control the input and output format and to redirect the input
and output streams;
• to select the default parsing and unification algorithms;
• to activate the tracing facilities;

90 Chapter 5. Implementation
• to collect and display data on the running system, e.g., number
of words and sentences processed, statistics on the applieation of
the fundamental rule or on the unification Operation.
The eore funetions provided by the user interface can be roughlydivided into three categories:
(a) Loading several types of knowledge bases such as morpheme and
fullform lexicons, spelling and pronunciation ruies, and word and
sentence grammars.
(b) Looking up lexical entries such as morphemes or fullforms.
(c) Applying "ruies" (two-level ruies or UTN greimmars) to segmentword forms or parse single words, sentences and entire texts.
5.3.2 Parser Package
The package PARSER is the eore module of the Syma system. It pro¬
vides funetions, macros and data structures to parse sequences of tokens
(words or sentences) using transition network grammars. The packagehas an interface to the packages LEXICON, GRAMMAR and TWOL.
The package does not implement a single parser, but an entire hierar-
chy of chart parsers in an objeet-oriented programming style5. The word
and sentence parsers are instances of a general parser which supports
eight different rule-invocation strategies. Each instance of a parser uses
a chart, which stores active and inactive edges, and an agenda, which
manages "executable tasks". An "executable task" consists of a pairof active and inactive edges to which the fundamental rule can be ap¬
phed. Depending on whether the agenda is organized as a Stack or as
a queue, the parser proeeeds in a depth-first or breadth-first manner.
The kernel loop of a parser removes a task from the agenda, appliesthe fundamental rule and stores the resulting new tasks on the agenda
5Common Lisp only partially supports the concept of objeet-oriented program¬
ming. However, the parsers have been designed according to the suggestions of the
recently standardized extension of CL called Common Lisp Object System (CLOS)[Kee89]. It is planned to reimplement the parser using CLOS for the next version of
the Syma Software.

5.3. Description of Packages 91
until the agenda is empty. The fundamental rule tries to eombine an
active and an inactive edge by evaluating the unification equations of
the active edge and inserts the result into the chart.
5.3.3 Grammar Package
The package GRAMMAR implements funetions to load and compiletransition network grammars. When loading a grammar from a file,the grammar is transformed from a textual representation into data
structures consisting of states connected by transitions. This represen¬
tation is elosely related to the Standard graphical notation6 used, for
example, in Section 2.3, where vertices eire connected by correspond¬
ing transitions. The Compiler traverses each network and transition,
thereby compiling the unification equations and Computing the FIRST,FOLLOW and REACHABILITY relations for the grammar. In a run¬
ning system, one word and one sentence grammar can be used at the
same time.
5.3.4 Lexicon Package
The package LEXICON provides funetions and data structures to load
morpheme and fullform lexicons and to störe and retrieve lexical entries
effieiently. When a lexicon is being loaded, the set of features of each
entry is checked for validity using a feature speeification to guarantee
consisteney of the lexicon. Lexicons can be loaded from text files or
index-sequential files. Functions to convert file formats are also pro¬
vided.
Fullforms eure stored in hash tables and can be retrieved without
further morphological processing. Morpheme entries are stored in a
letter tree (also called tries [Sed84, p 216 ff]), a data strueture well-
suited for efficient morphological processing. In addition, the packagemaintains a hash table, which is used as a "cache memory" to störe
words which have already been analyzed.
6A representation elosely related to its graphical counterpart simplifies the im¬
plementation of a graphic editor which operates directly on the same data structures
the parser uses. This allows coupling the editor and the parser together, which is
indispensable for a highly interactive system.

92 Chapter 5. Implementation
5.3.5 Twol Package
The package TWOL implements funetions to load two-level descrip¬tions consisting of aiphabet definitions and ruies (compiled to finite
automata) and to analyze and generate strings of characters.
For efficiency reasons, the transition table of each automaton (asdescribed in Section 2.1) is split into transition vectors, where each
vector describes the possible next states for a given pair of characters.
For example, the vector:
e:0 104568
defines the next states given the current state and the input paire : 0. Transition vectors from different DFAs with the same label (pairof lexical and surface characters) are stored together. For example, for
each of the n finite automata, a transition vector is stored under each
pair of characters allowed by the aiphabet definition and the two-level
ruies:
e : e < vectori >
< vector2 >
< vectorn >
e:0 < vectori >
< vector2 >
< Vectorn >
This indexing scheme makes it possible to process all DFAs effieientlyand in "parallel", as required by the two-level model.
5.3.6 Unification Package
The package UNIFICATION provides funetions emd data structures
to represent linguistic objects either as sets of name-term pairs or as

5.3. Description of Packages 93
feature structures (as defined in Section 2.2) emd to unify those objects.
In the current implementation, two algorithms to unify terms and
four algorithms to unify feature structures eure supported. A common
interface hides the underlying algorithm and facilitates adding new al¬
gorithms without changing the package interface. The interface consists
of a small number of funetions which are mainly used by the parser as
part of the fundamental rule emd by the package LEXICON to represent
morpheme and fullform entries.
In addition, a setup funetion is provided to change the unification
algorithm. There are also funetions to collect data about the number
of successful unifications and failed unifications due to name clashes,
cyeles or arity errors.

Leere Seite\nBlank

Chapter 6
Evaluation and
Extensions
This chapter evaluates the morphological and syntactic analyzer pre¬
sented in the previous chapters. Furthermore, it suggests extensions to
the formalisms and the Software.
6.1 Evaluation
The evaluation in this section is based on our experience with the for¬
malisms and the softweure1 during the past three years. The Syma
system has been used extensively by several people to develop gram¬
mars for synteix and morphology and to implement lexicons and mor-
phographemic and morphophonetic rule sets. The Software has also
been used as a component in a high-quabty text-to-speech system for
German.
We evaluate our approach from the following two points of view:
'Both the formalisms and the Software have undergone major extensions and
improvements in the course of time. Many improvements and new ideas are due to
suggestions by the people who used the system.
95

96 Chapter 6. Evaluation and Extensions
a) From the point of view of linguistic formalisms. In partieular, we
discuss to what extent our formalisms meet the general eriteria of
linguistic felicity, expressiveness and computational effectiveness.
b) From the point of view of a module in a text-to-speech system.
We show the advantages and limitations of the Syma system as a
module in a high-quality text-to-speech system.
6.1.1 From the Perspective of Formalisms
To evaluate the hnguistic formalisms of the Syma system, we use the
three general eriteria linguistic felicity, expressiveness and computa¬
tional effectiveness as introduced by Shieber [Shi85] emd already men¬
tioned in Chapter 2:
Linguistic Felicity
The eriterion linguistic felicity judges to what extent a formahsm allows
describing hnguistic phenomena the way hnguists tend to describe them.
Since the way linguists describe natural language depends strongly on
the underlying linguistic theory, there is not just one best way and one
best formahsm for such descriptions. Therefore, an evaluation2 can
never be unbiased.
Our experience with the two-level rule notation described in Chap¬ter 2 has shown that the formahsm is easy to use and adequate for
most phenomena encountered. That the ruies are declarative and order-
independent facilitates developing and testing rule sets. However, one
flaw is that some morphological features have to be speeified twice, once
as features in the lexical description and once as part of the lexical string
(to "trigger" a rule). This redundancy could be eliminated by either au-
2The same problem arises when comparing and evaluating programming lan¬
guages. Although there are some objeetive eriteria to characterize programming
languages, one and the same problem can often be solved using entirely different
programming languages. E.g., a simple Prolog program can declaratively State mem-
bership in a set. The same problem can be also be solved easily in a procedural
language like C. To some extent, therefore, it is a matter of subjective judgementwhich language is considered better suited for this problem.

6.1. Evaluation 97
tomatically inserting the morphological features into the lexical stringor by modifying the formahsm as suggested in [Tro90].
Our decision to separate the lexicon and the word greunmar, which
were intermingled in the original two-level model, has proven to be ex¬
tremely helpful. It greatly simphfies the task of writing morphotacticruies and recording new lexical entries and meets the linguistic concep-
tion that separates these two types of knowledge.
The UTN formahsm does not correspond to the notation of rewrite
ruies, which is widely used in hnguistics. However, transition networks
can easily be translated to ruies (emd vice versa), and both notations
are fully equivalent. In our opinion, networks eure a natural and indis¬
pensable way to modularize grammeirs, a feature lacking in Standard
rule notation. Our experience has revealed that it is easier to write and
modify a grammar of several dozen networks (that can be displayedand edited graphically) than one of several hundred ruies. The crit-
icism against other network formalisms [PW80], in particuleur againstthe ATN formahsm ([Woo70], [Bat78]), does not apply to the UTN
formahsm. The criticism is directed against the procedural Operationsrelated to transitions and the "uncontrolled" interaction between net¬
works. These Operations are replaced by unification equations in the
UTN formahsm, which make it fully declarative.
Expressiveness
The two-level model has finite-state power, as every regulär expressioncan be recognized by a finite state automaton. (However, it is not
entirely clear what the generative power of two-level ruies is. Ritchie
[Rit89] has proved that there are regulär expressions which cannot be
generated by two-level ruies.) The expressiveness of the two-level for¬
malism is fully adequate to formulate morphographemic and morpho¬
phonetic alternations. We did not encounter any examples beyond the
expressive power of the two-level formalism.
The expressive power of recursive transition networks correspondsto that of context-free grammars and vice versa. By adding unification
to RTNs, their expressive power is increased significantly and includes
that of indexed and context-sensitive grammars. It is assumed that
the generative capacity of the UTN formahsm is that of recursively

98 Chapter 6. Evaluation and Extensions
enumerable sets. Although there are very few examples of syntacticconstructions that cannot be expressed by context-free grammars, the
additional power added by unification and feature structures is well-
motivated. It assists in writing compact grammars and allows using
complex categories (feature-value pairs), a concept found in most con-
temporary syntactic theories.
Computational Effectiveness
The two-level model has been proven to be AfV-haxd [BBR87], but this
finding is more of theoretical interest. It reveals that the formahsm
could be strengthened with additional principles to decrease its com¬
plexity. The two-level model has been applied to several languages and
its practical efficiency has always been reported to be very good. This
matches our own experience. The processing of the compiled two-level
ruies is by far the most efficient step in our analyzer.
Parsing sentences using grammars written in the UTN formahsm is
computationally much more expensive than processing two-level ruies.
But it is also generally acknowledged that syntactic analysis is a much
more complex task than (morpho-)phonological analysis. By using pars¬
ing strategies adapted to the strueture of natural language, reasonablyefficient Systems can be built that cover a fairly large part of the syntax
of a language. If the progress in hardware technology continues, which
is likely, it will be feasible in the near future to have Workstations per¬
forming syntactic and morphological analysis covering a large range of
hnguistic phenomena in real-time.
6.1.2 As Applied in a TTS-System
In this section, we discuss the strengths and weaknesses of our approachto syntactic and morphological analysis with respeet to its applieation in
a text-to-speech system. We discuss in more detail the three major tasks
the analyzer performs, namely lexical analysis, morphotactic analysisand syntactic analysis, and compare them with other approaches.
The lexical analyzer, based on the two-level model, allows stating
spelling and phonological ruies in the same formalism. This makes ex-

6.1. Evaluation 99
phcit the symmetry of the underlying processes and simphfies the imple¬mentation. The declarativeness of the formahsm enables using the same
set of ruies in analysis and generation mode. This makes the grapheme-to-phoneme conversion bidirectional, em attractive feature for speechrecognition applications. Our experience shows that the two-level ap¬
proach is especially well-suited for grapheme-to-phoneme conversion.
To our knowledge, this is the first time that the two-level model is used
in a TTS system.
The morpheme-based approach of the Syma system can be con-
trasted with TTS Systems based on letter-to-phoneme ruies3. Because
these Systems do not use a lexicon, they can convert unrestricted text
to synthetic speech (ranging from weather reports to news to Fortran
hstings to fairy tales). In a lexicon-based approach, the size of the
lexicon limits the coverage that can be achieved. (Of course, a lexicon-
based approach can always make use of additional letter-to-phonemeruies for the words not covered by the lexicon.) It is obvious that a
lexicon-based approach is more expensive than an approach based on
letter-to-phoneme ruies. The recording of leirge numbers of morphemesis a time-consuming task. A system which ineorporates a lexicon also
uses more memory resources them a rule-based approach. Nevertheless,we consider a morpheme-based approach to be superior for the followingreasons:
• Letter-to-phoneme ruies can fail to produee the correct transcrip¬tion. For German as well as for other languages, morphemeboundaries have a strong influence on phonemization. Using a
morpheme lexicon is the only reliable way to determine morphemeboundaries.
• In order to achieve high-quality synthetic speech, it is necessary
to have, besides the phonemic transcription, additional informa¬
tion such as phrase boundaries and accents, which can be derived
at least partially from the synteictic strueture of a sentence. By
using a morpheme lexicon and a word grammeir, the morpholog¬ical analyzer can determine peurt-of-speech information, which is
indispensable for further synteictic processing.
3Yet another approach was put forward by Sejnowsky and Rosenberg [SR86].They used a neural network architecture to perform the task. Although the approachis very interesting from several points of view, its Performance is not nearly as
accurate as that of good letter-to-phoneme ruies or morpheme-based approaches.

100 Chapter 6. Evaluation and Extensions
At a recently organized international Workshop on speech synthesis
(ESCA Workshop on Speech Synthesis, Autrans France, 1990) a strongtrend toward lexicon-based approaches for TTS Systems could be ob¬
served, which supports our view.
It is generally acknowledged that syntactic strueture has a stronginfluence on prosody contour. But it is less clear how much syntacticinformation is needed and what the interconnections between syntaxand prosody are. Among the Systems conducting syntactic analysis,the MITalk system ([AHK87], [Kla87]) is the best-known one. The
MITalk system is based on a phrase-level parser which uses few re-
sources and runs very effieiently. The main reasons to implement a
phrase-level parser instead of a sentence parser were resource considera¬
tions and the coverage the system was to achieve [AHK87, p 40 ff]. Theresource considerations have already become obsolete due to technolog-ical advanees since the design of the MITalk system. As concerns the
coverage, we argue that a sentence parser can achieve the same coverage
as a phrase-level parser if an appropriate parsing algorithm is used. By
using a chart-parsing algorithm, information is monotonicaUy added to
the chart in the course of peirsing. If a grammar with a fairly large
coverage is used, a sentence can be parsed fully in the majority of the
cases, thus providing the syntactic strueture of the entire sentence. If
the parser fails, an undirected left-corner strategy can be used to parse
single phrases bottom-up. Each phrase found is stored in the chart, and
the phrases with the largest non-overlapping coverage can be combined
to form a "flat" syntax tree. We claim that a sentence-level peirser pro¬
vided with such a "fall-back procedure" is more general and superior to
a phrase-level parser.
One serious problem in füll syntactic analysis is that of ambiguities.Syntactic structures are often ambiguous both at the phrase and the
sentence level. We have condueted experiments using heuristic eriteria
(such as minimizing the complexity of constituents or scoring word hy¬
potheses) to disambiguate syntactic structures. However, the results
were unsatisfactory. A linguistically sound Solution to the problemwould include semantic analysis. A füll syntactic analysis as performedin our system provides the foundation for that step.
In condusion, our approach to syntactic and morphological analysisfor a TTS appheation is linguistically well-motivated and technicallyfeasible, as has been proven by our prototype implementation. Further

6.2. Extensions 101
developing the Syma system to allow it to process unrestricted text,as required for commercial applications, will still involve a large effort.
However, the overall architecture is general enough to allow for such
improvements.
6.2 Extensions
In this section, we suggest extensions both for the formalisms and the
Software environment of the Syma system.
6.2.1 Extensions to the Formalism
Lexicon: In its current version, the lexicon ineorporates consisteneychecking ruies to detect entries with inconsistent features. Additional
types of ruies such as "completion ruies", which infer the values of some
features from other features, and "multiplication ruies", which construet
new lexical entries that can be predicted from existing ones, could be
implemented to simplify the construction of large lexicons.
Two-level Ruies: As has been mentioned before, the encoding of
lexical features into the lexical string (using diacritics) should be elim¬
inated or at least hidden. However, it is still unclear how this could be
achieved without adding additional complexity to the two-level model
or losing its bidirectionality.
UTN Formalism: The version of the UTN formahsm presented in
Chapter 2 can be eoneeived as a kernel formahsm which cem be enhanced
in several respects. The notation of unification equations could be ex¬
tended to allow other Operations beside unification. Such Operationsinclude generalization, negation and disjunetion as weh as implication,functional uncertainty or nonmonotonic coneepts such as default values
[Usz90]. Adding these Operations to the UTN formalism is not a trivial
task. It has impücations on how greimmars are written as well as on
the parsing algorithms and the complexity of the system. There is a
large amount of ongoing research to set up a logical framework [Smo90]

102 Chapter 6. Evaluation and Extensions
to express these Operations and investigate their applieation to linguis¬tic descriptions. There is also a strong tendency to eombine coneeptsfrom objeet-oriented programming, logic programming and constraint
programming (a more general term for unification-based grammar for¬
malisms) into a unifying framework [Car90] emd to develop new lan¬
guages which are suited to knowledge representation as well as hnguisticappheations.
6.2.2 Extensions to the Software
The major effort for the prototype implementation of the Syma systemwas put into the kernel algorithms, such as the parsing and unification
algorithms, rather than into the implementation of a sophisticated user
interface. This was partially due to limited time, but also to the fact
that Common Lisp, as it currently Stands, does not speeify a Standard
for window, mouse and menu interactions. Therefore, most future ex¬
tensions to the Software will be aimed at improving user interaction with
the system. Among others, the following extensions are suggested:
• A sophisticated graphical editor which allows designing emd edit-
ing transition network grammars graphically. Such an editor
should also have an interface to the parser to support designing,testing and modifying grammars interactively.
• An interface based on window, mouse and menu interactions to
replace the tty-based command interpreter.
• A module that supports the recording of new lexical entries
through an interactive dialogue. Such an interface should allow
people with little background in hnguistics to record new entries.
• An extended lexicon module which uses a Standard database Sys¬
tem to maintain consisteney and to manage multi-user access.
This is necessary to build up large lexicons.
The implementation of these extensions is a major project. The pri-
ority assigned to each of these extensions strongly depends on whether
the Syma system will be used as a research tool or within an applieationenvironment.

6.3. Condusion 103
6.3 Condusion
In this dissertation, an approach for morphological and syntactic anal¬
ysis has been proposed. The formalisms as weh as the algorithms used
have been described and an overview of the implementation of the Syma
system has been given. We have compared severed peirsing strategies andunification algorithms. Furthermore, we have evaluated our approachbased on the experience we gained when using the Syma system as a
module in a text-to-speech program.
The results of the project presented in this thesis eure encouraging.With our approach, it appears to be possible to formalize and process
morphological and syntactic knowledge in a hnguistically well-motivatedand computationally effective manner.
The use of morphological and syntactic information in a text-to-
speech system considerably improves the intelhgibility and naturalness
of synthetic speech. In addition, it provides a sound basis to include
additional linguistic knowledge such as semantics and pragmatics.
Future research in speech synthesis as well as in speech recognitionwill be much stimulated by the results in fields such as computationalhnguistics and psycholinguistics. By adopting theories and modeis de¬
veloped for higher linguistic levels such as syntax, semantics or prag¬
matics developed for written language processing, the quality, coverage
and robustness of today's speech processing Systems will improve sub-
stantially.

Leere Seite\nBlank

Appendix A
Syntax of Two-Level
Ruies
<spelling rules>::= "SurfaceAlphabet" <character set>
"SurfaceSet" { <set deciaration> }
"LexicalAlphabet" <character set>
"LexicalSet" { <set declaration> }
"NullCharacter" <alphabet char>
"AnyCharacter" <alphabet char>
"Ruies" { <rule> >
<character set> ::= "." . <alphabet char> > "}"
<alphabet char> ::= <surface character>
I <lexical character>
I <null symbol>
<surface char> ::= <single char>
<lexical char> ::= <single char>
<set declaration> ::= <name> "in" <character set>
105

106 Appendix A. Syntax of Two-Level Ruies
<rule> ::= <name> <pair> <operator> <contexts>
<operator> ::= "==>" | "<==" | "<==>"
<context> ::= <simple context>
I "{" <simple context> { <simple context> } "}"
<simple context>::= <context expr>" "
<context expr>
<context expr> ::= <pair>I "<" <item list> ">"
I "{" <item list> "}"
I "(" <context expr>* ")"
<item list> ::= <context expr>I <context expr> <item list>
<pair> ::= <lexical symbol> ":" <surface symbol>
<lexical symbol>::= <lexical char>
I <lexical set name>
I <null char>
<lexical symbol>::= <lexical char>
I <lexical set name>
I <null char>

Appendix B
Syntax of UTN
Formalism
<ÜTN gra__mar> ::= <gr_mm_r-declaration> _<network>}
<grammar-declaration> :: =
"(" <gra__mar-name> <iu_ification-type> -[<network-name>} ")"
<unifcation-type> ::= ":term" | ":graph"
<network> ::= <network-declaration> -(<state>}
<network-declaration> ::=
"(" <network-n_me> <const-decl> {<state-name>} ")"
<const-decl> ::= "(" <nonterminal> <state-id> ")"
<state> ::= "(" <state-id> <transition> {<transition>} ")"
107

108 Appendix B. Syntax of UTN Formalism
<transition> ::= <terminal-trans>
I <nonter_i_al-trans>
I <epsilon-trans>| <dummy-trans>
<terminal-trans> ::=
"(" "cat" <preterminal> <equation-setl> <state-id> ")"
<nonterminal-trans> ::=
"(" "call" <nonterminal> <equation-setl> <state-id> ")"
<epsilon-trans> ::=
"(" "jump" <equation-set2> <state-id> ")"
<dummy-treins> ::=
"(" "reply" <pretermine_l> (<name-ten_ pairs>I <complex-feature>) <state-id> ")"
<name-term pairs> ::= "(" { "(" <n_une> <term> ")" } ")"
<complex feature> ::= <constant> I <variable>
| "(" { "(" <name> <complex feature> ")" } ")"
<equation-setl> ::=
"(" _<term-equation> I <dag-equation>} ")"
<term-equation> ::= "(" <term-exp> "=" <term-exp> ")"
<term-exp> ::= <term> I <feature-exp>
<term> ::= <const> I <variable>
I "(" <term> {<term>} ")"
<feature-exp> ::= "(" "feature" <feature-name> ")"

109
<dag-equation> ::= "(" <path-expr> "=" <path-expr> ")"
<path-expr> ::= "(" <path> I <const> ")"
<path> ::¦ <category> [""" <index>] feature {<feature>}
<category> ::¦ <nonterminal> I <preterminal>

Leere Seite\nBlank

Appendix C
Sample Grammars
The foUowing two sections contain two simple UTN grammars for Ger¬
man. The first example is based on the notation of name-term pairs.The second example is based on feature structures.
111

112 Appendix C. Sample Grammars
HC*******!):*«««**««»«««««!!!***********!)!*««««««««*******
Sample German Grammar "S1GERM"
Description: subject-verb agreement
subcatogorization
SYMA Version 3.3
Unification: term unification
fllfl,ffflllf»>fff»lf»lll,,!ltl»llllt»tt!tlllltllttftttll»
;;; constituents S, NP, VP, PP ;;;
ll!>»»!ff>»»t>!l!»»>>tl»tf«lltl>fttttltlt*l>fll>llt»ltl*tl
(slgerm :term s/ np/ vp/ pp/)
Mltinf llf llllltlMMMMItlHHMIIIIMIIIIIIIIMMHIM
;;; S net ;;;
ttttitttittttttttttttttiittttttiiiiiitittiiiiiiiiiiiiiittt
(s/ (sl s) s2 s3)
(sl (call np ((?case ?number ?gender) = (feature agr))(?case = nom)
s2))
(s2 (call vp (?number = (feature num)) s3))
(s3 (reply s ((head (?case ?number ?gender)))))

113
>>»»»•»,»»»•>»»i»*»»»»»»iifi»»»»»»i»i»i>f»i>f»ii|t)|iii»>>i»»
;;; NP net ;;;
II III MM lllltlll MMMIMmiMIIIHIIHIHIII IIIIII lll II
(np/ (npl np) np2 np3 np4)
(npl (cat *det* (?agreement = ((feature cas)
(feature num)
(feature gen))) np2)
(jump np2)
(call np (?agreement = (feature agr)) np3)
(cat *npr* (?agreement = ((feature cas)
(feature num)
(feature gen))) np4)
(cat *pron* (?agreement = ((feature cas)
(feature num)
(feature gen))) np4))
(np2 (cat *adj* (?agreement ¦ ((feature cas)
(feature num)
(feature gen))) np2)
(cat *noun* (?agreement = ((feature cas)
(feature num)
(feature gen))) np4))
(np3 (call pp np4))
(np4 (reply np ((agr ?agreement))))

114 Appendix C. Sample Grammars
»»»»ll
* » »
l l » > » l
1 » » 1 l 1 1 » » » I
» 1 » l » » 1 1 l l 1
ii»»i*»»»»»»»iii»»»»»»i»»»»i»iii»ii»»iii»
VP net ;;;
i»»»»iiiiiii»i»»»»iiii»»iii»ii»»iiiiiii»i
(vp/ (vpl vp) vp2 vp3)
(vpl (cat *verb* (?subcat = (feature subcat))
(?number = (feature num)) vp2)
(cat *verb* (?subcat = (feature subcat))
(?subcat = non)
(?number = (feature num))vp3))
(vp2 (call np ((?subcat ?gender ?numberl) ¦
(feature agr)) vp3))
(vp3 (call pp vp3)
(reply vp ((num ?number) (subcat ?subcat))))
»ff*i>ifi>iiftii»ffiff>ii,f»i,fiiii»>>>>>iir>i*i*»>****if>
;;; PP net ;;;
llltlllli MUH i iMIIMIIIIIIIMIIIIIMIIIIIIIIIIIIIItlll)
(pp/ (ppl pp) pp2 pp3)
(ppl (cat *prep* (?rection = (feature rec)) pp2))
(pp2 (call np ((?rection ?number ?gender) =
(feature agr)) pp3))
(pp3 (reply pp ((cas ?rection)(num ?number)
(gen ?gender))))

115
l)!***************************************************
Sample German Grammar "S1GERM"
Description: subject-verb agreement
subcatogorization
SYMA Version 3.3
Unification: graph unification
IMIMIMIIIIIIIMIMIIMIMIMltlll llllllllllllll Ifl
;;; constituents S, NP, VP, PP ;;;
IMIIIIIIMIIIMIIIMIIIIIIIIIIMIMIMIMIMIIIMIIMIIII
(slgerm :graph s/ np/ vp/ pp/)
»»»»»»lll»llllllll»»»»»lll»»»»ll»l»»»»»»»ll»»lllllll»»f»ll
;;; S net ;;;
»iiiiifii»»»»»i»»iii»iii»»»iii»»i»iiiiiiiiiii»»»»»»»»iiiii
(s/ (sl s) s2 s3)
(sl (call np ((np agr cas) ¦ nom) s2))
(s2 (call vp ((vp subj) = (np agr))((vp head number) = (np agr num))
((s head) = (vp head))
((s subj) = (vp subj)) s3))
(s3 (reply s ))

116 Appendix C. Sample Grammars
» » » » 1 1 1 1 1
lll
illillill
lllllll Miinnmi in imnm imiiiii mm in
NP net ;;;
(np/ (npl np) np2 np3 np4)
(npl (cat *det* ((np agr cas) = (*det* cas))
((np agr num) = (*det* num))
((np agr gen) = (*det* gen)) np2)
(jump np2)
(call "npl (("npl agr) = (np agr)) np3)
(cat *npr* ((np agr cas) = (*npr* cas))
((np agr num) = (*npr* num))
((np agr gen) = (*npr* gen)) np4)
(cat *pron* ((np agr cas) = (*pron* cas))
((np agr num) « (*pron* num))
((np agr gen) ¦ (*pron* gen)) np4))
(np2 (cat *adj* ((np agr cas) = (*adj* cas))
((np agr num) = (*adj* num))
((np agr gen) = (*adj* gen)) np2)
(cat *noun* ((np agr cas) = (*noun* cas))
((np agr num) = (*noun* num))
((np agr gen) = (*noun* gen)) np4))
(np3 (call pp ((np pp) = (pp head)) np4))
(np4 (reply np ))

117
>»»»»»»»»l»»»ll»*»ll»l»llllll*lfl»»l»lll»»»»»lll»ll»»f»lll
;;5 VP net ;;;
IIIIIIIIMIIIMIMIIIIMIMMMIIIMIIIMIIIItMlMIMIIII
(vp/ (vpl vp) vp2 vp3)
(vpl (cat *verb* ((vp obj cas) ¦ (*verb* subcat))
;; transitive verb
((vp head number) = (*verb* num))
((vp head pers) = (*verb* pers)) vp2)
(cat *verb* ((vp head num) = (»verb* num))
;; intransitive verb
((vp head pers) = (*verb* pers))
((vp obj cat) = («verb* subcat))
((vp obj cat) = non) vp3))
(vp2 (call np ((vp obj) = (np agr)) vp3))
(vp3 (call pp ((vp pp) = (pp head)) vp3)(reply vp))
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii
...
PP net ;;;
MIMMMMI MM MMIMMII IMIMI II UM II I IMMIIMMIMI
(pp/ (ppl pp) pp2 pp3)
(ppl (cat *prep* ((pp head rec) = (*prep* rec)) pp2))
(pp2 (call np ((pp head obj) = (np agr)) pp3))
(pp3 (reply pp ))

Leere Seite\nBlank

Appendix D
Sample Sentences
This appendix hsts the sample sentences used for the peirsing experi¬ments.
Sentences Used in Experiment 2:
Sie hören den Lawinenbericht von zehn Uhr.
Die niederschlagsfreie Witterung mit hohen Temperaturen führte zu
einer starken Umwandlung der Schneedecke.
Die Durchfeuchtung ist bis auf zweitausend Meter angestiegen.
Die Lawinengefahr in nordwestlichen Kammlagen hat leicht abgenom¬men.
Am Alpennordhang ist immer noch mit einer lokalen Schneebrettgefahrzu rechnen.
Gefahrenstellen sind vorwiegend Steilhänge mit starker Sonnenein¬
strahlung.
Am Alpensüdhang ist die Schneebrettgefahr zur Zeit gering.
Ein etwas flacher gewordenes Hoch überquert unser Land.
In der Westschweiz ist der Himmel vorwiegend bewölkt.
119

120 Appendix D. Sample Sentences
Am Montag Vormittag ist mit ausgiebigen Niederschlägen zu rechnen.
Seit drei Tagen existiert wieder eine Drahtseilbahn auf die Heimwehfluh.
Bei allen Seniorenangeboten dürfen die Enkelkinder gratis mitfahren.
Im August steht Interlaken ganz im Zeichen der grossen Eisenbahn-
schau.
Die Motorenausstellung steht gleichzeitig mit einem Modelleisenbahn¬
treff auf dem Programm.
Die Automobilrennsportverbände stehen auf vier Quadratkilometer ihre
neusten Formeleinswagen aus.
Im Expresszug durchs winterliche Puschlav erlebt man einen einzigar¬
tigen Eindruck.
Die Gletscherbahn Fiesch Eggishorn lädt am Donnerstag alle Kinder zu
einer heiteren Fahrt mit der neuen Luftseilbahnkabine ein.
Die fünfstündige Radiowanderung vom Samstag führt uns diesmal ins
Obwaldnerland voraussichtlich ins kleine Schlierental.
Die zweite Appenzeller Holzbildhauerwoche findet am Dienstag dem
sechzehnten August in der Zunft ADEGASS statt.
Zudem steht am Montag wieder einmal der Zibelemärit das grosse
Berner Volksfest auf dem Programm.
In Burma hat sich die Lage nach dem Rücktritt von Sin Lewin offenbar
entspannt.
Am kommenden Freitag will das Parlament einen Nachfolger für Lewin
bestimmen.
Im benachbarten Bangkok berichteten Touristen über vereinzelte Un¬
ruhen.
In der Schweiz führen die Hilfswerke eine Sammelaktion durch.
In der Hauptstadt Rangun kam es am Dienstag zu neuen, heftigen Aus¬
schreitungen.

121
Die Kommission will die sozialistische Initiative zur Unterstützung der
schwachen Bergregionen zur Ablehnung empfehlen.
Die Mitgheder können über eine topaktueUe Alternative zur Vorlageentscheiden.
Der Bundespräsident Doktor Kreisky reichte vor dem Parlament seinen
Rücktritt ein.
Gemäss Aussage des Präsidenten war die Herkunft der Drogengelderden meisten Mitgliedern der Kommission bekannt.
Wir sind von Klosters nach Fiesch mit dem Zug gefahren.
Heute fährt Susi mit ihren Kindern nach Interlaken.
Örtlich sind die Fahrbahnen, besonders die Überholspuren mit
Schneematsch bedeckt.
Niemand fährt bei den Verhältnissen im Winter mit dem Auto über den
Berninapass.
Schön ist es in Lugano.
Schöner ist es in Fiesch.
Am schönsten ist es zu Hause im Appenzell.
Eine rosa Sau läuft über die gelben Butterblümlein.
Die kecke Greta fährt am Samstag nach Alaska.
In den Bergen kann man gut Ski laufen.
Den letzten Versuch machen die Leute in diesen Wochen.

122 Appendix D. Sample Sentences
Sentences Used in Experiment 3:
Seid ihr gestern in Bern am Zibelemärit gewesen?
Wurden wir um eine Auskunft gefragt?
Wer war Mitghed in der Kommission zur Unterstützung des Skisports?
Woher kommt ihr so früh am morgen?
Geht nach der Schule auf dem schnellsten Weg nach Hause!
Mein Freund, den ich gestern getroffen habe, lebte lange Zeit in Burma.
Man brach auf, um nicht in den Regen zu kommen.
Anstatt, wie es sich gehören würde nach Hause zu gehen, bleiben wir.
Er habe, falls man das einmal glauben will, über seinen Rücktritt dem
Parlament keine Auskünfte gegeben.
Anstatt seinen Nachfolger zu berücksichtigen, wählte das Parlament
einen anderen zum neuen Präsidenten.
Ich fand ein Stück Zeitung.
Das zu sagen ist nicht sehr freundlich.
Sie meinte der Schnee würde rasch schmelzen und der Frühling käme
früher in diesem Jahr.
Zürich, Lugano und Bern sind einzigartige Städte.
Entweder er oder sie und sowohl wir als auch ihr fahren zu diesem
Treffen nach Bern.
Wir beendeten unsere Ferienwoche gestern mit einer langen und be¬
schwerlichen Wanderung.
Er ist ernst freundlich friedlich und einsatzfreudig.
Im Appenzell, im Puschlav und im Wallis finden in diesem Jahr zahl¬
reiche offizielle Ausstellungen statt.
In und um Bern finden in diesem Jahr zahlreiche Ausstellungen über

123
Sprachsynthese statt.
Sowohl von Osten und Westen wie auch von Norden und Süden kamen
die Leute herbei.
Drei oder vier Kinder spielten im Garten.
Die Frau, welcher Susi das Auto gegeben hatte, ist jung.
Wer wird uns morgen ins Puschlav fahren.
Entweder er oder sie fahren mit der Luftseilbahnkabine aufs Eggishorn.
Es sind sowohl der Präsident als auch das Parlament über die Vorlageinformiert worden.
Während es in Zürich und in Bern regnet, scheint die Sonne in Lugano.
Weisst du woher dieser Zug kommt und wohin er fährt.
Sie berichtete, ihr Mann sei aus Klosters gekommen und er habe dort
während zehn Jahren gelebt.
Die meisten Touristen am Zibelemärit kosten die Leckerbissen aus dem
Puschlav und dem Tessin.
Oberhalb der Lorelei ist eine Ruine in den Rhein gesunken.
Wo hegt die Lorelei?
Wer hat am Wochenende das Gewitter in den Bergen erlebt?
Gibt es in InterlaJcen eine Bergsteigerschule?
Ist das Motto der Tat lächerlich?
Der gesuchte Weg erscheint auf dem Stadtplan in roten Leuchtpunkten.
Der Eilzug aus Nizza fährt in den Bahnhof ein.
Bitte wiederholen sie die Telefonnummer die sie erfragt haben.
Beachten sie die folgende Anweisung:
Nehmen sie den Telephonhörer ab, werfen sie das Geld in den
Münzspeicher und wählen sie die Nummer des Teilnehmers.

124 Appendix D. Sample Sentences
Wir danken Ihnen für die freundliche Unterstützung und hoffen weiter¬
hin auf gute Zusammenarbeit.

125
Sentences Used in Experiment 6:
The assembly language provides a means for writing a program without
having to be concemed with actual memory addresses.
It allows the use of symbolic codes to represent the instruetions.
Labels can be assigned to a partieular instruction step in a source pro¬
gram to identify that step as an entry point for use in subsequent in¬
struetions.
Operands which follows each instruction represent storage locations.
The assembly language also includes assembler directives that Supple¬ment the machine instruction.
A pseudo-op is a statement which is not translated into machine in¬
struction.
A program written in assembly language is called a source program.
It consists of symbolic commands called statements.
Each statement is written on a single hne, and it may consist of four
entries.
The source program is processed by the assembler to obtain a machine
language program that can be executed directly by the cpu.
Ethernet is a broadcast communication system for carrying digital data
packets among Computing stations which are locally distributed.
The packet transport mechanism provided by ethernet has been used
to build Systems which can be local Computer networks.
Switching of packets to their destinations on the ethernet is distributed
among the receiving stations using packet address recognition.
A model for estimating Performance under heavy loads is included for
completeness.
In writing this book, I had several purposes in mind.
It is a text book for students who are beginning graduate work in Com¬
puter science.

126 Appendix D. Sample Sentences
It includes exercises designed to help the Student master a body of
techniques.
It is a practical guide for people who are building Computer Systemsthat deal with natural language.
It is not structured as a how-to book, but it describes the relevemt tech¬
niques in detail, and it includes an extensive outhne of english grammar.
It is a reference source with many pointers into the literature of linguis¬tics.
I have attempted to introduce a wide variety of material to providenewcomers with broad access to the field.
Each chapter includes suggestions for further reeiding, and there is an
extensive bibliography.
However, I have tried to limit the references to easily available material.
This is a book about human language.
Its approach is motivated by two questions.
What knowledge must a person have to speak language.
How is the mind organized to make use of this knowledge in communi-
cating.
In looking at language as a cognitive process, we deal with issues that
have been the focus of hnguistic study for many years, and this book
includes insights gained from these studies.
We look at language from a different perspective.
In forty years, since digital Computers were developed, people have pro¬
grammed them to perform many aetivities that we think of as requiringsome form of intelhgence.
Our study of the mental processes involved in language draws heav¬
ily on coneepts that have been developed in the area called artificial
intelhgence.
It is seife to say that much of the work in Computer science has been

127
pragmatic, based on a desire to produee Computer programs that can
perform useful tasks.
The same concept of program can be apphed to the understanding of
any system which is executing processes that can be understood as the
rule-governed manipulation of symbols.
The next chapter sets the computational approach into the contex of
other approaches to language by giving a brief history of the majordirections in hnguistics.
In performing a mental task hke deeiding on a chess move, we are aware
of going through a sequence of thought processes, as we shall see in later
chapters.
Run.
Doit.
I have a pen.
I must not do that.
Time flies hke an arrow.

Leere Seite\nBlank

Appendix E
Empirical Raw Data
This appendix presents the raw empirical data obtained by the parsing
experiments.
129

Parsing
Zxpariaant
1
Craasaar:
GI-GER
(simplaGarman
graansar,
4natworks,
13
statas,
16
transitions,
17
unification
aquations)
Tastsat:
SI-GER
(8
santancas,
124
words)
Data:
05-09-1990
Hardwara:
VS3200/24MS
Software:
SYMA
Softwara
V3.3
(andVAX
Lisp
V2.2)
No
of
KDGBS
NO
OfFUND
RUI_S
tOt
ISUCC
FIRST
count
|fail
FOLLOW
coun
|fail
|REACHABILITY
count
|fail
RANK
Z|R
|T
ParsingZxpariaant
2
Graaaaar:
GII-GKR
(Garauuigr«__¦___,
22
natworks,
113
stataa,
361
transitions,
513unification
aquations)
Tastsat:
SIX-GKR
(40
aantancaa,
403
worda)
Data:
10-09-1990
Hardwara:
VS3200/24MB
Softwara:
SYMA
SoftwaraV3.3
(andVAX
Lisp
V3.1)
1S
||
No
of
EDGES
||Ho
of
«TOD
HOLE
11
_IKST
|FOLLOW
|R_KC___II.IT.
||
CPU
1j
BAUE
1|
jtot
|aa
|ia*
1j
tot
|aucc
j|count
|fail
1coun
1fail
jcount
|fail
jj
||E
1R
|T
1Tl
||227496
|207752
|19744
II
116732
|69782
II
-
1-
1-
1-
1-1
-II
419.4
II
4|
4|
4
112
II
211316
1191572
|19744
II116140
|69190
II
45975
144107
1-
1-
1-
1-
II
373.5
II
2|
3|2
113
||215765
|202667
|13098
II
109678
162728
II-
1-
116444
13346
1-
1-
II
404.5
II
3|
2|
3
1T4
||199933
|186835
113098
II109110
|62160
II
45583
143715
116444
13346
1-
1II
359.8lllllll
1Bl
||569508
1506196
|63312
II
289131
|178559
II
-1
-
1-
1-
1-1
-II
839.8
II
8|
81
8
1B2
||320101
1293866
|26235
II168834
194236
II
-
1-
1-
1-
115284
114326
II
472.6
II
6|
6|
6
1B3
II
524841
|488257
|36584
||260705
1150497
||
-
1-
149664
113080
1-
1II
746.4
II
7|
7|
7
IB4
||304683
|285703
118980
II159904
|85670
II
1-
122335
13355
115245
114326
II
452.0
II
51
51
5
Parsing—spari_ant
3
Gra_aar:
GIXI-GER
(Gaznan
axaamar,
48
natvorks,
279
stataa,
770
transitions,
1246unification
aquations)
Tastsat:
SXXX-GER
(40
santancas,
422
words)
Data:
05-09-1990
Bardwara:
VS3200/24MB
Softwara:
SXM»Softwara
V3.3
(andVAXLisp
V3.2)
Mo
of
EDGES
tot
1aa
|iaa
Mo
of
irms
Rtn_
tot
Isuec
147930
I72198
I
FIRST
count
|fail
FOI—OH
coun
|fail
REACHABILITY
count
Ifail
143089
I67646
139073
|68367
1342S8
I63841
242535
I118824
157736
I72373
223715
I111289
147122
|67920

ParsingKxparimant
4
Granaar:
Gl-ENGL
(Tonita'sEnglish
graamar,
4natworka,
14
statas,
17
transitions,
no
unification
aquations)
Taataat:
SI-ZNGL
(8
aantancas,
124
words)
Data:
05-09-1990
Bardwara:
VS3200/24MB
Softwara:
SXHA
SoftwaraV3.3
(andVAX
Lisp
V3.1)
SM
Mo
of
EDGES
||
Mo
of
FDMDROLE
||
FIRST
|FOI—OH
|REACHABILIT-
||
CFD
||
RA—K
11tot
|aa
|ia«
1j
tot
1aucc
||count
1fail
jcoun
|fail
1count
1fail
II
1|E
1R
1T
Tl
||
20310
|12485
17825
II
20110
120110
II-1
-|-|
-
1-|
-II
16.2
II
4|
1|
1
T2
||20294
|12469
17825
M20110
120110
II
3078
12990
1-
1-
1-
1-
II
16.3
||
31
11
2
T3
||
19391
|12485
16906
II
20110
|20110
II
-
1-
17825
1919
|-
1-
II16.8
II2
|1
13
14
||19375
112469
16906
II
20110
120110
II
3078
12990
17825
1919
|-
1-
II
17.1
II
1|
1|
4
Bl
||
27464
|18241
19223
II
27100
127100
II
-
1-l-l
-
1-|
-II
22.9
II
8|
7|
7
B2
||
24596
|15373
19223
II
24304
124304
II-
1-
1-
1-
12796
12796
II20.9
II
61
5|
5
B3
II26545
|18241
18304
II
27100
127100
II-
1-
19223
1919
|-
1-
II
23.7
II
7|
7|
8
B4
||
23677
|15373
18304
II
24304
|24304
II
-
|-
19223
1919
12796
12796
II
21.7
||5
|5
|6
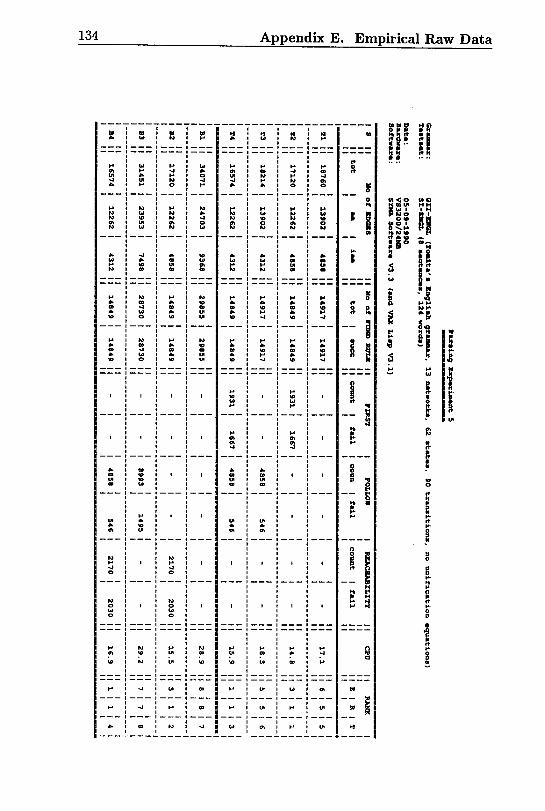
ParsingExparivant
5
Graaaar:
GZZ-ZN6L
(Toaita'a
English
graanar,
13
natworks,
62
statas,
90
transitions,
no
unification
aquations)
Tast-sat:
SX-ZHGL
(8
saatancas,
124
words)
Data:
05-09-1990
Bardwara:
VS3200/24MB
Softwara:
SYMA
SoftwaraV3.3
(andVAX
Lisp
V3.1)
S1
1Ho
1tot
Of
EDGES
a*
ia.
|MO
Of
FI
1tot
WD
ROLE
|
SUCC
|
IFIRST
Icount
|fail
FOI—OR
coun
|fail
REACHABILITY
|
count
1fail
1
ICPD
|I
RAHE
IE
IR
I6|5
T
Tl
11
18760
13902
4858
|1
14917
14917
| !-
!-
-
!-
!-
i1
17.1
15
T2
|I
17120
12262
4858
11
14849
14849
|I
1931
|1667
-!
-
i-
!1
14.8
|1
31
1
T3
|I
18214
13902
4312
|I
14917
14917
| !-
i-
4858
1546
-
!-
!1
18.3
|I
55
6
14
|1
16574
12262
4312
|I
14849
14849
11
1931
|1667
4858
|546
-
!-
!1
15.9
|I
1
18
18
3
Bl
11
34071
24703
9368
|I
29855
29855
1 i-
!-
-!
-
!I
28.9
|7
B2
|I
17120
12262
4858
|1
14849
14849
| !-
!-
-!
2170
|2030
|1
15.5
|I
31
2
B3
|1
31451
23953
7498
|I
28730
28730
|1
-
!-
8993
|1495
-i
-!
129.2
|I
77
8
B4
|I
16574
12262
4312
|I
14849
14849
| i-
!-
4858
|546
2170
|2030
|1
16.9
|I
11
4

ParaingExparimant
6
Graamar:
GXXX-EHGL
(Tomita's
English
graanar,
36
natworks,
228
statas,
407
transitions,
nounification
aquations,
)
Tastsat:
SXX-EHGL
(39
santancas,
596
words)
Data:
05-10-1990
Bardwara:
VS3200/24MB
Softwara:
SXHA
SoftwaraV3.3
(andVAX
Lisp
V3.1)
S||
HO
OfEDGES
l|Mo
Of
FONDROLE
||
FIRST
|FOLLOH
|REACHABILITY
||
CPO
1|
RAMK
|
1|tot
|aa
|iaa
1j
tot
1aucc
jjcount
|fail
jcoun
|fail
|count
1fail
|j
||E
|R
|T
j
11
II108524
|91578
116946
II
54689
154689
||
-
1-l-l
-
1-|
"II
130.3
II
5|
3|
5|
T2
||
86106
169160
116946
II
54689
154699
II
20301
118422
1-
1-
1-
1II
93.3
II
21
3|2
|
T3
||
90168
|76288
113880
II44226
144226
||-
|-
114638
1758
|-
1-
II117.6
II
31
11
31
T4
||
69053
155173
113880
II44226
144226
||
17385
115506
114638
1758
|-
1-
II
84.6
II
11
11
11
Bl
||
259393
1210021
149372
II
168871
1168871
||
-|
-
1-
1-
1-|
-II
240.9
II8
|8
|8
|
B2
II
121796
199001
122797
II75509
175509
II
-
1-
1-
1-
19633
18599
II
130.8
II
61
61
61
B3
||209321
|169299
140022
II138232
1138232
II
-
1-
142577
12555
1-
1II
230.8
II
71
71
7|
B4
||
104399
184984
119415
II
65016
165016
II
-
|-
120489
11074
19395
18361
II
129.0
II
4|
51
4|

Leere Seite\nBlank

List of Figures
1.1 Morphological analyzer 4
1.2 Syntactic analyzer 5
1.3 Architecture of the text-to-speech system 7
2.1 Part of the transition graph of the DFA "s-deletion" . . 20
2.2 A segment of the lattiee of first-order terms 29
2.3 Transition network grammar Gl 33
2.4 Constituent strueture tree for the string aaabbbcc .... 34
2.5 Transition network grammar G2 37
3.1 Nondeterministic unification algorithm 46
3.2 Version of Robinson's unification algorithm 49
3.3 Example 1 of syntax trees 57
3.4 Example 2 of syntax trees 58
3.5 Example 1 of a chart 60
3.6 Example 2 of a chart 61
3.7 Top-down chart parsing algorithm 65
3.8 Bottom-up chart parsing algorithm 68
5.1 Overview of the Syma Software 88
137

Leere Seite\nBlank

List of Tables
2.1 Transition table for the DFA "s-deletion" 20
4.1 Test set Sl 76
4.2 Test set S2 76
4.3 Parsing experiment 1 81
4.4 Parsing experiment 2 81
4.5 Parsing experiment 3 82
4.6 Parsing experiment 4 82
4.7 Parsing experiment 5 83
4.8 Parsing experiment 6 84
5.1 Overview and size of source code of the Syma Software . 89
139

Leere Seite\nBlank

Bibliography
[AHK87] J. Allen, M. S. Hunnicutt, and D. Klatt. From text to
speech: The MITalk system. Cambridge Studies in SpeechScience and Communication, Cambridge University Press,1987.
[ASU86] A. V. Aho, R. Sethi, and J. D. Ullman. COMPILERS Prin¬
ciples, Techniques and Tools. Addison-Wesley PublishingCo., 1986.
[ATJ72] A. V. Aho and J. D. Ullman. The Theory of Parsing, Trans¬
lation, and Compiling. Automatic Computation, Prentice-
Hall Inc., Englewood Cliffs, N.Y., 1972.
[Bat78] M. Bates. The Theory and Practice of Augmented Tran¬
sition Network Grammars. In L. Bolc, editor, Natural
Language Communication with Computers, pages 191-259,
Springer Verlag, 1978.
[BBR87] G. E. Barton, R. C. Berwick, and E. S. Ristad. Computa¬tional Complexity and Natural Language. The MIT Press,
Cambridge, Massachusetts, 1987.
[Bea86] J. Bear. A Morphological Recognizer with Syntactic and
Phonological Ruies. In Proc. of the llth International Con¬
ference on Computational Linguistics, pages 272-276, 1986.
[Bea88a] J. Bear. Generation and recognition of inflectional mor¬
phology. In H. Trost, editor, 4- Osterreichische Artificial-
Intelligence- Tagung, pages 3-7, Springer Verlag, 1988.
141

142 Bibliography
[Bea88b] J. Bear. Two-level Ruies and Negative Rule Features. In
Proc. of the 12th International Conference on Computa¬tional Linguistics, pages 28-31, 1988.
[Ber82] H. Bergmann. Lemmatisierung in HAM-ANS. Memo
ANS 10, Forschungsstelle für Informationswissenschaften
und Künstliche Intelligenz, Universität Hamburg, Juni
1982.
[BFW86] J. Bachenko, E. Fitzpatrick, and C. Wright. The contri¬
bution of parsing to prosodic phrasing in an experimental
text-to-speech system. In Proceedings of the 24th Annual
Meeting of the Association for Computational Linguistic,
pages 145-155, 1986.
[Bla90] P. Blackburn. Introduction to lattices and their applica¬tions in formal semantics. Lecture notes for the 2nd Euro¬
pean Summer School in Language, Logic and Information,Leuven Belgium, August 1990.
[BM72] R. S. Boyer and J. S. Moore. The sharing of strueture in
theorem-proving programs. Machine Intelligence, 7, 1972.
[Car90] B. Carpenter. The logic of typed feature structures: inher-
itance, (in)equations and extensionality. Lecture notes for
the 2nd European Summer School in Language, Logic and
Information, Leuven Belgium, August 1990.
[CCL90] C. H. Coker, K. W. Church, and M. Y. Liberman. Mor¬
phology and rhyming: two powerful alternatives to letter-
to-sound ruies for speech synthesis. In Proceedings of the
ESCA Workshop on Speech Synthesis, European SpeechCommunication Association, September 1990. Autrans,France.
[Cho65] N. Chomsky. Aspects of the Theory of Syntax. The MIT
Press, 1965.
[Coz90] R. Cozzio. Vergleich und Implementation von Unifikation¬
salgorithmen. Institut für Elektronik, ETH Zürich, 1990.
Diplomarbeit in Informatik.

Bibliograph;/ 143
[Dae88] W. Daelemans. Grafon: A Grapheme-to-Phoneme Conver¬
sion System for Dutch. In Proc. of the 12th International
Conference on Computational Linguistics, 1988.
[Dom90] M. Doming. Lexeme-based morphology: a computation¬
ally expensive approach intended for a server-architecure.
In Proc. of the 13th International Conference on Computa¬tional Linguistics, 1990.
[Ear72] J. Earley. An Efficient Context-Free Parsing Algorithm.Commun. ACM, 13(2):94-102, February 1972.
[EG88] G. Escalada-Imaz and M. Ghallab. A practically efficient
and almost hnear unification algorithm. Artificial Intelli¬
gence, 36:249-263, 1988.
[Eme88] M. Emele. Überlegungen zu einer Two-level Morphologiefür das Deutsche. In H. Trost, editor, 4- Österreichische
Artificial-Intelligence-Tagung, pages 156-163, Springer Ver¬
lag, 1988.
[FN86] W. Finkler and G. Neumann. MORPHIX: Ein hoch-
portabler Lemmatisierungsmodulfür das Deutsche. Memo 8,KI-Labor am Lehrstuhl für Informatik IV, Universität des
Saarlandes, Saarbrücken, 1986.
[FN88] W. Finkler and G. Neumann. MORPHIX a fast realiza¬
tion of a classification-based approach to morphology. In
H. Trost, editor, 4- Österreichische Artificial-Intelligence-
Tagung, pages 11-19, Springer Verlag, 1988.
[Fra88] Franz Inc. COMMON LISP: THE REFERENCE.
Addison-Wesley Pubhshing Co., 1988.
[GM89] G. Gazdar and C. MeUish. Natural Language Processing in
LISP. Addison-Wesley Pubhshing Co., 1989.
[HG88] H. Haugeneder and M. Gehrke. Improving Search Strate¬
gies: An Experiment in Best-First Parsing. In Proc. of the
12th International Conference on Computational Linguis¬
tics, pages 237-241, 1988.
[HGL88] K. Huber, D. Gilg, and R. Leber. Automatische Messungder Dauer von Lauten in lautsprachlichen Äusserungen. In

144 Bibliography
H. Trost, editor, 4- Österreichische Artificial-Intelligence-
Tagung, pages 54-61, Springer Verlag, 1988.
[HHP*87] K. Huber, H. Huonker, B. Pfister, T. Russi, and C. Traber.
Sprachsynthese ab Text. In H. Tillmann and G. Will_e, edi¬
tors, Analyse und Synthese gesprochener Sprache, pages 26-
33, Gesellschaft für Linguistische Datenverarbeitung, Georg01ms Verlag Hildesheim, 1987.
[Hir90] J. Hirschberg. Using discourse context to guide pitch accent
decision in synthetic speech. In Proceedings of the ESCA
Workshop on Speech Synthesis, European Speech Commu¬
nication Association, September 1990. Autrans, France.
[HLPW87] J. Hirschberg, D. Litman, J. Pierrehumbert, and G. Ward.
Intonation and the intentional strueture of discourse. In
Proceedings of the lOth International Joint Conference on
Artificial Intelligence, pages 636-639, IJCAI Inc., MorganKaufmann Pubhsher, Inc., Los Altos, California 94022,1987.
[HU79] J. E. Hopcroft and J. D. Ullman. Introduction to Au¬
tomata Theory, Languages, and Computation. Addison-
Wesley Pubhshing Co., 1979.
[Hub90a] K. Huber. Messung und Modellierung der Segementdauer
für die Synthese deutscher Lautsprache. PhD thesis, ETH
Zürich, Institut für Elektronik, 1990. (fortheoming).
[Hub90b] K. Huber. A Statistical model of duration control for speech
synthesis. In Proc. of 5th. European Signal Processing Con¬
ference, 1990.
[Hue75] G. P. Huet. A unification algorithm for typed A-calculus.
Theoretical Computer Science, 1:27-57, 1975.
[Huo89] H. Huonker. Syntaktische Analyse: Grammatik und Voll¬
formenlexikon. Zwischenbericht zum SNF-Projekt 2000-
5.294 2, Institut für Elektronik, ETHZ, Januar 1989.
[Kae85] H. Kaeshn. Systematische Gewinnung und Verkettungvon Diphonelementen für die Synthese deutscher Standard¬
sprache. PhD thesis, ETH Zürich, Institut für Elektronik,1985. Diss. ETH Nr. 7732.

Bibliography 145
[Kae86] H. Kaeshn. A systematie approach to the extraction of di¬
phone elements from natural speech. IEEE Trans. Acoust,Speech, Signal Processing, ASSP 34(2):264-271, April 1986.
[Kap73] R. M. Kaplan. A General Synteictic Processor. In R. Rustin,editor, Natural Language Processing, pages 193-240, Algo-rithmics Press, New York, 1973.
[Kas87] R. T. Kasper. Feature Structures: A Logical Theory with
Application to Language Analysis. PhD thesis, Universityof Michigan, 1987.
[Kay73] M. Kay. The MIND System. In R. Rustin, editor, Natu¬
ral Language Processing, pages 193-240, Algorithmics Press,New York, 1973.
[Kay77] M. Kay. Morphological and Syntactic Analyis. In A. Zam-
polli, editor, Linguistic Structures Processing, pages 131-
234, North-Holland, Xerox Palo Alto Research Center, 1977.
[Kay82] M. Kay. Algorithm Schemata and data strucures in syntac¬tic processing. In S. Alten, editor, Text Processing: Text
Analysis and Generation, Text Typology and Attribution,pages 327-358, Almqvist and Wiksell International, Stock¬
hohn, Sweden, 1982.
[Kay84] M. Kay. Functional Unification Grammar: A Formahsm
for Machine Translation. In Proc. of the 9th International
Conference on Computational Linguistics, 1984.
[Kay87] M.Kay. Nonconcatenative finite-state morphology. In ACL
Proceedings, Third European Conference, pages 2-10, 1987.
[KC88] K. Koskenniemi and K. Church. Complexity, two-level mor¬
phology and finnish. In Proc. of the 12th International Con¬
ference on Computational Linguistics, pages 335-340, 1988.
[Kee89] S. E. Keene. Object-Oriented Programming in COMMON
LISP. Addison-Wesley Pubhshing Co., 1989.
[KK85] L. Karttunen and M. Kay. Strueture sharing with binarytrees. In Proceedings of the 23th Annual Meeting of the
Association for Computational Linguistic, 1985.

146 Bibliography
[KKK87] L. Karttunen, K. Koskenniemi, and R. Kaplan. TWOL: a
Compiler for two-level phonological ruies. In M. Dalrymple,
editor, Tools for Morphological Analysis, CSLI Report 108,
Center for the Study of Language and Information, Stanford
University, Stanford CA, 1987.
[Kla87] D. H. Klatt. Review of text-to-speech conversion for
Enghsh. Journal of the Acoustical Society of America,
82(3):737-793, September 1987.
[Kni89] K. Knight. Unification: a multidisciplinary survey. ACM
Comput. Surv., 21(No. 1):93-124, March 1989.
[Kos83a] K. Koskenniemi. Two-level model for morphological analy¬sis. In Proceedings of the 8th International Joint Conferenceon Artificial Intelligence, pages 683-685, 1983.
[Kos83b] K. Koskenniemi. Two-level Morphology: A General Compu¬tational Model for Word-Form Recognition and Production.
PhD thesis, University of Helsinki, 1983.
[Kos84] K. Koskenniemi. A General Computational Model for
Word-Form Recognition and Production. In Pro. of the
lOth International Conference on Computational Linguis¬
tics, 1984.
[KZ85] L. Karttunen and A. Zwicky. Introduction. In D. R. Dowty,L. Karttunen, and A. Zwicky, editors, Natural Language
Parsing, pages 1-25, Cambridge University Press, 1985.
[Man74] M. Mangold. DUDEN Aussprachewörterbuch. Volume 6,
Bibliographisches Institut Mannheim, Wien Zürich, 1974.
[MCP87] W. A. Martin, K. Church, and R. Patil. Preliminary anal¬
ysis of a breadth-first parsing algorithm: theoretical and
experimental results. In L. Bolc, editor, Natural Language
Parsing Systems, pages 267-328, Springer Verlag, 1987.
[MM82] A. Martelli and U. Montanari. An efficient unification algo¬rithm. ACM Transactions on Programming Languages and
Systems, 4(2):258-282, April 1982.
[Mon90] A. I. C. Monaghan. A multi-phrase parsing strategy for un¬
restricted text. In Proceedings of the ESCA Workshop on

Bibliography 147
Speech Synthesis, European Speech Communication Associ¬
ation, September 1990. Autrans, France.
[Mun90] W. Müntener. Realisierung einer unifikationsbasierten Net¬
zwerkgrammatik für das Deutsche. Institut für Elektronik,ETH Zürich, 1990. Diplomarbeit in Informatik.
[OSh90] D. O'Shaughnessy. Relationship between syntax and
prosody for speech synyhesis. In Proceedings of the ESCA
Workshop on Speech Synthesis, European Speech Commu¬
nication Association, September 1990. Autrans, France.
[Per85] F. C. N. Pereira. A structure-sharing representation for
unification-based grammar formalisms. In Proceedings ofthe 23th Annual Meeting of the Association for Computa¬tional Linguistic, 1985.
[Per87] F. C. N. Pereira. Grammars and Logics for Partial Infor¬mation. Technical Note 420, Center for the Study of Lan¬
guage and Information, SRI International, Stanford Univer¬
sity, May 1987.
[PK86] A. Pounder and M. Kommenda. Morphological Analysis for
a German Text-to-Speech System. In Proc. of the llth In¬
ternational Conference on Computational Linguistics, 1986.
[PMW90] B. H. Partee, A. T. Meulen, and R. E. Wall. Mathematical
Methods in Linguistics. Volume 30 of Studies in Linguisticsand Philosophy, Kluwer Academic Publishers, 1990.
[PS87] F. C. N. Pereira and S. M. Shieber. Prolog and Natural
Language Analysis. CSLI Lecture Notes 10, Center for the
Study of Language and Information, 1987.
[PW78] M. S. Paterson and M. N. Wegman. Linear unification.
Journal of Computer and System Sciences, 16:158-167,1978.
[PW80] F. C. N. Pereira and D. H. D. Warren. Definite Clause
Grammars for Language Analysis - A Survey of the For¬
malism and a Comparison with Augmented Transition Net¬
works. Artificial Intelligence, 13:231-278, 1980.

148 Bibliography
[Rit89] G. Ritchie. On the generative power of two-level morpholog¬ical ruies. In ACL Proceedings, Fifth European Conference,
pages 51-57, 1989.
[Rob65] J. A. Robinson. A Machine-Oriented Logic Based on the
Resolution Principle. Journal of the Association for Com¬
puting Machinery, 12(1):23-41, January 1965.
[Rot91] R. Rothenberger. Two-level Regeln für deutsche Verben.
Manuskript (unpublished), 1991.
[RPBR87] G. D. Ritchie, S. G. Pulman, A. W. Black, and G. J. Russell.
A computational framework for lexical description. Compu¬tational Linguistics, 13(3-4):290-305, 1987.
[RPRB86] G. J. Russell, S. G. Pulman, G. D. Ritchie, and A. W. Black.
A dictionary and morphologicals analyzer for enghsh. In
Proc. of the llth International Conference on Computa¬tional Linguistics, 1986.
[Rus89] T. Russi. Syntaktische Analyse: Konzept, Algorithmen und
Implementation eines Parsers für die syntaktische Analysenatürlicher Sprache. Technical Report, Institut für Elek¬
tronik, ETH Zürich, 1989.
[Rus90a] T. Russi. A framework for morphological and syntactic
analysis and its applieation in a text-to-speech system for
german. In Proceedings of the ESCA Workshop on Speech
Synthesis, European Speech Communication Association,
September 1990. Autrans, France.
[Rus90b] T. Russi. A syntactic and morphological analyzer for a text-
to-speech system. In Proc. of the 13th International Con¬
ference on Computational Linguistics, 1990.
[Sch89] A. Schneider. Heuristische Parsingstrategien für die syntak¬tische Analyse natürlicher Sprache. Institut für Elektronik,ETH Zürich, 1989. Diplomarbeit in Informatik.
[Sed84] R. Sedgewick. Algorithms. Addison-Wesley Pubhshing Co.,1984.
[Sel85] P. Seils. Lectures on Contemporary Syntactic Theories.
CSLI Lecture Notes 3, Center for the Study of Languageand Information, 1985.

Bibliography 149
[Sha89] P. Shann. The selection of a parsing strategy for an on-hne
machine translation system in a sublanguage domain. A new
practical comparison. In Proc. of ihe International Work¬
shop on Parsing Technologies, pages 264-276, Carnegie Mel¬
lon University, 1989.
[Shi85] S. M. Shieber. Criteria for designing Computer facilities for
hnguistic analysis. Linguistics, 23:189-211, 1985.
[Shi86] S. M. Shieber. An Introduction to Unification-Based Ap¬
proaches to Grammar. CSLI Lecture Notes 4, Center for
the Study of Language and Information, 1986.
[Shi87] S. M. Shieber. Evidence against the context-freeness of nat¬
ural language. In W. S. et.al., editor, The Formal Complex-
tity of Natural Language, pages 320-334, D.Reidel Pubhsh¬
ing Company, 1987.
[Shi88] S. M. Shieber. CL-PATR User's Manual. Artificial Intel¬
hgence Center and Center for the Study of Language and
Information, SRI International, July 13 1988.
[Sie87] J. Siekmann. Unification theory. In D. B., H. D., and S. L.,
editors, Advanees in Artificial Intellicence-II, pages 365-
400, Seventh European Conference on Artificial Intelhgence,
ECAI-86, North-Holland, July 20-25 1987. Brighton, U.K.
[SKP84] S. M. Shieber, L. Karttunen, and F. C. N. Pereira. Notes
from the Unification Underground: A Compilation of Paperson Unification-Based Grammar Formalisms. Technical Re¬
port 327, Artificial Intelligence Center, SRI International,
1984.
[Smo90] G. Smolka. Logical foundations of unification grammars.
Lecture notes for the 2nd European Summer School in Lan¬
guage, Logic and Information, Leuven Belgium, August1990.
[SR86] T. J. Sejnowski and C. Rosenberg. NETtalk: A Parallel
Network that Learns to Read Aloud. Reports of the Cog¬nitive Neuropsychology Laboratory 13, The Johns Hopkins
University, 1986.

150 Bibliography
[SR90] B. Schnabel and H. Roth. Automatic linguistic processingin a german text-to-speech synthesis system. In Proceed¬
ings of the ESCA Workshop on Speech Synthesis, European
Speech Communication Association, September 1990. Au¬
trans, France.
[Ste84] G. L. Steele Jr. COMMON LISP: The Language. DigitalPress, 1984.
[Tan87] S. L. Tanimoto. The Elements of Artificial Intelligence.
Principles of Computer Science Series, Computer Science
Press, 1803 Research Boulevard Rockville, Maryland 20850,1987.
[Tar75] R. Tarjan. Efficiency of a good but not hnear set unifica¬
tion algorithm. Journal of the Association for Computing
Machinery, 22(2):215-225, April 1975.
[Tom86] M. Tomita. Efficient Parsing for Natural Language. Kluwer
Academic Publishers, 1986.
[TR88] C. Traber and R. Rothenberger. Akzentuierung,
Phrasierung, Grundfrequenzsteuerung und Prototyp eines
Sprachsynthesesystems. Technical Report, Institut für Elek¬
tronik, ETH Zürich, 1988.
[Tra90] C. Traber. Fo generation with a data base of natural Fq
patterns and with a neural network. In Proc. of the ESCA
Tutorial and Research Workshop on Speech Synthesis, Eu¬
ropean Speech Communication Association, 1990.
[Tro90] H. Trost. The apphcation of two-level morphology to non-
concatenative german morphology. In Proc. of the 13th In¬
ternational Conference on Computational Linguistics, 1990.
[Usz90] H. Uszkoreit. Unification in linguistics. Lecture notes for
the 2nd European Summer School in Language, Logic and
Information, Leuven Belgium, August 1990.
[Wir87] M. Wiren. A comparison of rule-invocation strategies in
context-free chart parsing. In ACL Proceedings, Third Eu¬
ropean Conference, 1987.

Bibliography 151
[Woo70] W. A. Woods. Transition Network Grammar for Natural
Language Analysis. Commun. ACM, 13(10):591-606, Oe¬
tober 1970.
[Wro87] D. Wroblewsky. Nondestructive graph unification. In Pro¬
ceedings of the Conference on the AAAI, pages 582-587,1987.

Curriculum Vitae
i960 Geboren am 13. Dezember 1960 in Andermatt (Uri).
1967-1973 Primarschule in Andermatt.
1973-1980 Mittelschule und Matura (Typus B) in Altdorf.
1980-1984 Studium der Elektrotechnik an der ETH Zürich.
1985 Diplom als Elektroingenieur (Dipl. El. Ing. ETH).
1985-1990 Assistent und wissenschaftlicher Mitarbeiter in der Gruppe für
Sprachverarbeitung am Institut für Elektronik der ETHZ. Disser¬
tation in Rahmen des Projekts Sprachsynthese.