robust fuzzy extractors and helper data manipulation ... · 1 robust fuzzy extractors and helper...
TRANSCRIPT

1
Robust Fuzzy Extractors and Helper DataManipulation Attacks Revisited: Theory vs Practice
Georg T. Becker
F
Abstract—Fuzzy extractors have been proposed in 2004 by Dodis et al.as a secure way to generate cryptographic keys from noisy sources. Inrecent years, fuzzy extractors have become an important building blockin hardware security due to their use in secure key generation based onPhysical Unclonable Functions (PUFs). Fuzzy extractors are provablysecure against passive attackers. A year later Boyen et al. introducedrobust fuzzy extractors which are also provably secure against activeattackers, i.e., attackers that can manipulate the helper data.
In this paper we show that the original provable secure robust fuzzyextractor construction by Boyen et al. actually does not fulfill theerror-correction requirements for practical PUF applications. The fuzzyextractors proposed for PUF-based key generation on the other handthat fulfill the error-correction requirements cannot be extended to suchrobust fuzzy extractors, due to a strict bound t on the number ofcorrectable errors. While it is therefore tempting to simply ignore thisstrict bound, we present novel helper data manipulation attacks on fuzzyextractors that also work if a “robust fuzzy extractor-like” constructionwithout this strict bound is used.
Hence, this paper can be seen as a call for action to revisit thisseemingly solved problem of building robust fuzzy extractors. The newfocus should be on building more efficient solutions in terms of error-correction capability, even if this might come at the costs of a proof ina weaker security model.
Index Terms—Robust Fuzzy Extractor, Physical Unclonable Functions(PUFs), Helper Data Manipulation Attacks
1 IntroductionFuzzy extractors have been proposed in 2004 by Dodis etal. [10] as a provably secure way to generate cryptographickeys from correlated but possibly noisy sources. The mainmotivation for this work back in 2004 were biometrics:During a generation phase, a biometric reading such asa fingerprint or iris picture is used to generate a crypto-graphic key and helper data. At a later time, a second,possibly noisy, reading of the same biometric source isused in conjunction with the helper data to reproduce thecryptographic key. Fuzzy extractors guarantee that i) thederived key is uniform even after revealing the helper data,i.e., the helper data does not reveal information aboutthe key, and ii) as long as the distance between the two
The author is with the Digital Society Institute at the ESMT Berlin,Germany. Most of the work was done while he was with the HorstGörtz Institute for IT Security, Ruhr-Universität Bochum, Germany.E-mail: {firstname.lastname}@rub.de.The author would like to thank Johannes Tobisch for providing the
GMC decoding implementation and for his helpful comments as wellas the anonymous reviewers for their helpful feedback.
readings is smaller than or equal to a constant t, the samekey is extracted during the recreation step.
While fuzzy extractors are provably secure against pas-sive attackers, this does not say anything about attack-ers who can alter the helper data. Therefore, Boyen etal. proposed a construct called robust fuzzy extractor in2005 [2] which is also secure against helper data manip-ulation attacks. The original robust fuzzy extractor wasonly provably secure in the random oracle model, but aprovably secure construction in the general model wasproposed a year later in [8] and slightly improved in [7],[14]. It is noteworthy that, in theory, any fuzzy extractorcan be turned into a robust fuzzy extractor. Hence, atleast for the Hamming distance metric, the problem ofbuilding provably secure fuzzy extractors and provablysecure robust fuzzy extractors seems to be solved.
From a practical perspective, fuzzy extractors havebecome increasingly important not due to biometrics, butdue to key generation based on Physical Unclonable Func-tions (PUFs). Storing and generating cryptographic keysin embedded devices can be a challenging task, in partic-ular if they need to be able to withstand physical attacks.Standard non-volatile memory has little protection againstan unauthorized read-out, especially if the non-volatilememory is not on the same chip. Only dedicated securenon-volatile memory can offer protection against an ad-vanced attacker. PUFs are a promising alternative to suchsecure non-volatile memory. The idea of PUFs is to usethe process variations within each chip to derive a unique“fingerprint”, which is called the PUF response. A FuzzyExtractor is then used to derive a cryptographic key andhelper data from this PUF response. In the recovery phase,this helper data is used in conjunction with a (possiblynoisy) PUF response to recover the key again. PUF-basedkey generation, and in particular how to construct fuzzyextractors for PUF-based key storage, has been the focusof a lot of research. One important focus of this researchis how to handle the significant level of noise that canbe present in the PUF responses. Several error-correctingcodes and decoding strategies have been proposed to beused in fuzzy extractors for PUF-based key generation,e.g. in [1], [16], [17], [18], [19], [25]. It is noteworthy thatfuzzy extractors and PUF-based key generation are notpurely academic research topics anymore. Several high-security products by companies such as Microsemi, Altera

2
and NXP use fuzzy extractors in conjunction with PUF-based key generation1.The first helper data manipulation attacks against PUF
based key generation were not on fuzzy extractors, but onhelper data algorithm based on pattern matching [5] anddesigns specifically for Ring-Oscillators [6]. Another helperdata manipulation attack was presented on soft-decisionerror-correction [3]. While the attack was described basedon the helper data algorithm by Maes et al. [18], which isstrictly speaking not a fuzzy extractor as no bound on themin-entropy is provided, the attack can also be applied toeven number repetition codes and hence fuzzy extractors.
In practice, most solutions for PUF-based generationneed a robust fuzzy extractor, which has been acknowl-edged in numerous papers. However, papers describingactual implementations only used fuzzy extractors and notrobust fuzzy extractors.
1.1 Main contributionIn this paper we will show that how to build provablysecure as well as practical robust fuzzy extractors is not asolved problem. In particular, we show that:• It is actually not possible to build a provably secure
robust fuzzy extractor based on the Bose-Chaudhuri-Hocquenghem-Codes (BCH) construction proposedby Boyen et al. [2] for noise levels above 3%.
• The concatenated code constructions used in practi-cal fuzzy extractor implementations that can handlenoise levels of 15% or more are actually not well-formed and therefore using them in Boyen et al. ’sconstruction violates the security proof.
• We introduce a new helper data manipulation attackstrategy on linear codes which we demonstrate basedon several decoding strategies for Reed–Muller codesand soft-decision decoding.
• In this new attack strategy the attacker sets a keyas opposed to recovering a key. Therefore, the newattack strategy can be used to attack a robust fuzzyextractor-like construction which uses a hash functionto check the integrity of the helper data, but ignoresthe strict bound t of the proof by Boyen et al. .
Finally, we also propose some promising research direc-tions to solve this problem in the future.
1.2 OutlineThe next Sections provides some necessary background in-formation. In particular, robust fuzzy extractors and theirrelated constructions are formally defined and introduced.In Section 3 the robust fuzzy extractor based on BCHcodes is examined in greater detail, and it is shown thatbuilding a robust fuzzy extractor based on BCH codes isnot possible for realistic parameters. Section 4 introducesthe attack model and strategy of our new helper data
1. NXP announced that the upcoming SmartMX2 security chipswill feature a PUF, Altera uses PUFs in their Stratix 10 FPGAs,Microsemi in their SmartFusion FPGAs. All these products useIntrinsic-ID’s licenses and PUF solutions.
manipulation attack and Section 5 presents some concreteexamples of how the attack works against Reed–Mullercodes and soft-decision decoding. Finally, a discussionoutlook is provided in Section 6 with promising futureresearch directions, before the paper finishes with a shortconclusion.
2 BackgroundThis Section introduces the formal definitions of robustfuzzy extractors and their building blocks. The corre-sponding proofs and a more detailed description can befound in the referenced papers. In the following we willuse the definitions from [2].
2.1 NotationsIn this paper we will use the following notations: A vectoris represented with a bold lowercase character, a matrixwith a bold uppercase character, a scalar with a lowercasecharacter, a random variable with an uppercase character,and a set with calligraphic character. Table 1 is a summaryof the variable names used in this paper to describethe robust fuzzy extractor for PUF based key generationand the helper data manipulation attack. In this context,a variable used in the recovery phase before the error-correction is denoted with a tick mark, a variable after theerror-correction is denoted with a bar, and a value chosenor predicted by the attacker is indicated with an a index.For binary error-correction codes we use to the notion of[n, k, d], with n being the codeword length, k being thedimension and d denoting the minimum distance betweencodewords.
Original Before After Attacker’sError Corr. Error Corr. choice
PUF response w w′ w wa
codeword x x′ x xa
helper data s sa
hash value h h ha
secret key r r ra
error vector eattack vector ea
TABLE 1: Overview of variable definitions
2.2 Definitions of secure sketches and fuzzy extractorsFuzzy extractors and secure sketches were proposed byDodis et al. in 2004 [10]. A secure sketch is defined asfollows: [2]Definition 1: An (m,m′, t)-secure sketch over a metric
space (M, d) comprises a sketching procedure SS : M →{0, 1}∗ and a recovery procedure Rec, where:1) (Security) For all random variablesW overM such
that H∞(W ) ≥ m, we have H∞(W |SS(W )) ≥ m′,with H∞ denoting the min-entropy.
2) (Error tolerance) For all pairs of pointsw,w′ ∈ M with d(w,w′) ≤ t, it holds thatRec(w′,SS(w)) = w.

3
In the context of PUFs, a secure sketch can be used togenerate helper data s for a PUF response w during thefirst key generation (sketching procedure). This helperdata can then be used to correct up to t errors in anoisy PUF response w′ during the “recovery” phase. Thesecurity guarantees state that the remaining min-entropyin the PUF response w after revealing the helper datas is at least m′ ≤ m. Hence, w is not guaranteed tobe uniformly distributed and revealing the helper datareduces the guaranteed min-entropy. Therefore, w cannotbe used directly as a cryptographic key. The main purposeof a Fuzzy Extractor is to extend the secure sketch togenerate a string r that is uniformly distributed so thatit can be be used as a cryptographic key. The formaldefinition is as follows: [2]Definition 2: An (m, l, t, δ)-fuzzy extractor over a met-
ric space (M, d) comprises a (randomized) extraction algo-rithm Ext :M→ {0, 1}l×{0, 1}∗ and a recovery procedureRec such that:1) (Security) For all random variables W over M
that satisfy H∞(W ) ≥ m, if 〈r,pub〉 ← Ext(W )then SD(〈r,pub〉 , 〈Ul,pub〉) ≤ δ, where SD() isthe statistical difference as defined in [2] and Ul isa random variable that is uniformly distributed over{0, 1}l.
2) (Error tolerance) Let d() be a distance metric forM. Then for all pairs of points w,w′ ∈ M withd(w,w′) ≤ t, if 〈r,pub〉 ← Ext(w) then it is thecase that Rec(w′,pub) = r.
The aforementioned fuzzy extractor is only secureagainst a passive attacker. I.e., it does not make anyguarantees about the security if the attacker can manipu-late the helper data pub2. For this purpose, robust fuzzyextractors were proposed by Boyen et al. [2] that arealso secure against active attackers. These robust fuzzyextractors are based on well-formed secure sketches whichare defined as follows: [2]Definition 3: An (m,m′, t)-secure sketch (SS,Rec) is
said to be well-formed if it satisfies the condition ofDefinition 1, except for the following modifications:1) Rec may now return either an element in M or the
distinguished symbol ⊥.2) For all w′ ∈ M and arbitrary pub′, if
Rec(w′,pub′) 6= ⊥ then d(w′,Rec(w′,pub′)) ≤ t.In other words, a secure sketch only guarantees that ifthere are t or less errors, the errors will be corrected. Itdoes not say anything about what happens if there aremore than t errors. Correcting more than t errors does nothave any impact on security. In addition, t does not evenneed to be a strict lower bound but can be relaxed, whichwas formalized in [9] as relaxed notions of correctness.A well-formed secure sketch on the other hand correctsexactly up to t errors and responds with ⊥ if there are
2. With pub we denote the helper data to be in line with thedefinition in with [2]. The helper data is typically a vector s. However,the exact format of the helper data is not defined and can be of anydata type.
more than t errors. One cannot simply relax this notionand allow more than t errors to be corrected withoutviolating the assumptions in the proof. It is actually simpleto construct a well-formed secure sketch from any securesketch: For this, one only needs to compute t′ = d(w,w′).If t′ > t return ⊥ else return w.
A robust sketch is resistant to helper data manipulationattacks and is defined as follows: [2]Definition 4: Given algorithms (SS,Rec) and random
variables W = {W0,W1, ...,Wn} over the metric space(M, d), consider the following game between an adver-sary A and a challenger: Let w (resp., wi) be the valueassumed by W0 (resp., Wi). The challenger computespub← SS(w0) and gives pub to A. Next, for i = 1, ..., n,the adversary A outputs a “challenge” pubi 6= pub and isgiven Rec(wi,pubi) in return. If there exists an i such thatRec(wi,pubi) 6= ⊥ we say that the adversary succeeds andthis event is denoted by Succ.
We say that (SS,Rec) is an (m,m′′, n, ε, t)-robust sketchover (M, d) if it is a well-formed (m,m′′, t)-secure sketchand:
1) For all t-bounded distortion ensembles W withH∞(W0) ≥ m and all adversaries A we havePr[Succ] ≤ ε.
2) The average min-entropy of W0, conditioned on theentire view of A throughout the above game, isat least m′′. Which implies that (SS,Rec) is an(m,m′′, t)-secure sketch.
Similar to secure sketches, a robust sketch does notnecessarily produce a uniformly distributed string that canbe used as a cryptographic key. For this purpose robustfuzzy extractors were defined as follows: [2]Definition 5: Given algorithms (Ext,Rec) and random
variables W = {W0,W1, ...,Wn} over a metric space(M, d), consider the following game between an adversaryA and a challenger: Let w0 (resp., wi) be the valueassumed by W0 (resp., Wi). The challenger computes(r,pub) ← Ext(w0) and gives pub to A. Next, fori = 1, .., n, the adversary A outputs pubi 6= pub andis given Rec(wi,pubi) in return. If there exists an i suchthat Rec(wi,pubi) 6= ⊥ we say the adversary succeedsand this event is denoted by Succ. We say (Ext,Rec) isan (m, l, n, ε, t, δ)-robust fuzzy extractor over (M, d) if thefollowing hold for all t-bounded distortion ensembles Wwith H∞(W0) ≥ m:• (Robustness) For all adversaries A, it holds thatPr[Succ] ≤ ε.
• (Security) Let V iew denote the entire view ofA at the conclusion of the above game. Then,SD(〈r, V iew〉 , 〈Ul, V iew〉) ≤ δ. SD() is again thestatistical difference as defined in [2] and Ul theuniform distribution over l-bit strings.
• (Error-tolerance) For all w′ with d(w0,w′) ≤ t, wehave Rec(w′,pub) = r.
2.3 Robust fuzzy extractor constructionsAfter we have defined the various constructions we willnow take a look at how they can be realized. In this paper

4
we only look at constructions for the Hamming distancemetric, since this is used in PUF-based key generation.The main building block of all constructions is the securesketch. Two secure sketch constructions for the Hammingdistance metric were proposed by Dodis et al. [10], thecode-offset and the syndrome construction.
2.3.1 Secure sketches for the Hamming distance metricThe code-offset construction [10] is based on the fuzzycommitment proposed by Juels and Wattenberg [13] andis defined as follows:Definition 6: Code-offset construction: During sketch-
ing, choose a random codeword x ∈ C and compute thehelper data s = SS(w,x) = w⊕ x. For recovery, computex = decode(w′ ⊕ s), where decode() denotes the decodingprocedure of the error-correction code C and w′ the po-tentially noisy PUF response. Then w = Rec(w′, s) = s⊕xwith w == w if d(w′,w) ≤ t.The syndrome construction requires the code C to be alinear binary error-correction code and works as follows:Definition 7: Syndrome construction: During sketching,
compute s = SS(w,x) = w · HT, where HT is thetransposed parity-check-matrix of the used linear error-correction code C. For recovery, compute s′ = w′ · HT.Determine e = locate(s′ ⊕ s) by using the error-locationalgorithm locate() of the code C. Then w = Rec(w′, s) =w′ ⊕ e with w = w if d(w′,w) ≤ t.Both the code-offset and the syndrome construction are
popular for PUF-based key generation.
2.3.2 Hash-based robust fuzzy extractorBoyen et al. showed how robust fuzzy extractors can bebuilt using any well-formed secure sketch in conjunctionwith a hash function. This construction, which we willdenote as hash-based construction in the remainder of thepaper is provably secure in the random oracle model [2].This hash-based construction works as follows:Definition 8: Assume we are given two hash functions
H1, H2 : {0, 1}∗ → {0, 1}l (in practice a single hashfunction can be used by prepending a padding) and a well-formed secure sketch (SS,Rec). The hash-based robustfuzzy extractor (Ext,Rec) with (r,pub) = Ext(w) andr = Rec(w′,pub) works as follows:3
• (r,pub) = Ext(w): Let s = SS(w). Outputpub = (s,H1(w, s)) and r = H2(w, s).
• r = Rec(w′,pub): Parse pub as (s,h) and setw = Rec(w′, s). If d(w,w′) ≤ t and h == H1(w, s)then output r = H2(w) else output r = ⊥.
How the hash-based robust fuzzy extractor works inconjunction with the code-offset construction is illustratedin Figure 1. One great advantage of this construction isthat in this way any fuzzy extractor can be extended toa robust fuzzy extractor. Hence, when discussing fuzzyextractor constructions for PUF-based key generation, it isoften noted that in case resistance against active attackers
3. It is also possible to compute r with r = H2(w, s) as it was donein [11]. Yet the original proposal in [2] uses r = H2(w).
Fig. 1: Illustration of the robust fuzzy extractor when itis used in conjunction with the code-offset construct. Onthe left the extraction phase and on the right the recov-ery phase is depicted. The distance check d(w′,w) ≤ thighlighted in the red square is often overlooked in PUFpapers. A fuzzy extractor without this distance check iscalled RFE-like construct in this paper and attacks againstsuch a construct will be presented in Section 4.
is needed, the fuzzy extractor can easily be turned intoa robust fuzzy extractor. However, we want to point toa detail that is often overlooked: In a fuzzy extractord(w,w′) ≤ t is only a correctness requirement, i.e., onlyguarantees that the errors are corrected. It has nothing todo with security and hence an engineer can simply ignorethis part without jeopardizing security. Indeed, Dodis etal. [9] formalized this as relaxed notion of correctness,since better error correction rates can be achieved withsuch relaxed notations.
In a robust fuzzy extractor on the other handd(w,w′) ≤ t is a security requirement. If this inequality isnot satisfied, the robust fuzzy extractor needs to return ⊥.In other words, the robust fuzzy extractor requires a well-formed secure sketch not because of a correctness require-ment, but because of a security requirement. Hence, thisaspect cannot be ignored without security implications.
2.3.3 Fuzzy extractors for PUF-based key generationIn this Subsection we will briefly discuss some of thedifferent fuzzy extractors that have been proposed inconjunction with PUF-based key generation. In earlierworks BCH codes have been used [12], [24]. However,the superior error correction capability of concatenatedcodes was pointed out by Bösch et al. in 2008 [1]. Inparticular, they proposed a simple inner repetition codewith an outer Reed–Muller or Golay code. Concatenatedcodes with BCH codes in conjunction with repetitioncodes have been used in the literature as well [20]. In2009 the idea to use soft-decision error correction wasfirst introduced by Maes et al. in conjunction with PUF-based error correction [18], [19]. The idea is to collectadditional information about the reliability of each PUFresponse bit and add this as additional helper data duringthe generation phase. During reconstruction, soft-decision

5
error correction codes can use this information to consid-erably decrease the probability of a decoding error. Forthis, concatenated codes with soft-decision repetition andReed–Muller codes were proposed. One disadvantage ofthis approach is that the soft-decision information needsto be collected first, which might not always be trivial.How to overcome this problem was presented in 2012by van der Leest et al. [16], by using a hard-in soft-out inner code (repetition decoder) in conjunction witha soft-decision outer code (Reed–Muller or Golay code).Compared to hard-decision decoding, considerably bettererror correction rates are achieved without the need tocollect additional information during the generation phase.The same hard-in soft-out decoding was also used in [17].Similarly, the generalized concatenated code constructionsby Puchinger et al. [21] also use hard-in soft-out decodingof Reed–Muller codes.
3 Impossibility results for BCH codesIn order to show the feasibility of fuzzy extractors,Dodis et al. showed that BCH codes can be used toconstruct fuzzy extractors based on the code-offset andsyndrome construction [10]. Later work showed how everyfuzzy extractor can be turned into a robust fuzzy extrac-tor [2] and, hence, at least in theory BCH codes can alsobe used to build robust fuzzy extractors. In this sectionwe look at the problem from a more practical perspective,by investigating if the parameters of the security proofcan also be met for realistic error-correction rates, as theyare needed for PUF-based key generation. A typical goalin PUF-based key generation is to achieve a failure rateof less than 10−6 or 10−9 during key generation, with anassumed worst-case PUF reliability of around 85%4. Thisis assumed in, e.g., [1], [17], [18], [20], [21]. Note that in allof these papers concatenated code constructions are usedthat yield much better average error correction rates thannon-concatenated code. However, concatenated codes havea significantly worse minimum error-correction capacityt (see Section 3.3), making them unsuitable for robustfuzzy extractors that follow the security proof from [2]. Wetherefore want to evaluate in this Section, if these resultscan also be achieved with a single BCH code, as it wasproposed for robust fuzzy extractors by Boyen et al. [2].
3.1 Security bound for Boyen et al.’s hash-based ro-bust fuzzy extractor constructionThe robust fuzzy extractor proof from [2] provides aformula to compute the success probability ε of an activeattacker. This equation allows the derivation of a securitybound that the binary [n, k, 2t + 1] BCH codes need tofulfill in order to be provably secure when used in robustfuzzy extractors.
4. Worst case reliability of 85% in this case means that the chancethat a response bit flips is 15% in average for the worst environmentalconditions that is still within specification (e.g. highest specifiedtemperature).
Theorem 1: Security Bound:A binary linear [n, k, 2t+ 1] code used in a robust sketchas defined in [2] that does not fulfill the following bounddoes not fulfill the corresponding security proof of Boyenet al.:
k > 1 + log2(n) + log2
( t∑i=0
(n
i
))(1)
Proof: From [2] Theorem 1 the success probability ε ofan attacker is defined with:5
ε = (4qH + 2n · v) · 2−m′
(2)
where qH denotes the number of times an attacker isallowed to query the robust fuzzy extractor, v denotes thevolume of the error correction code, and m′ the remainingmin-entropy after revealing the helper data. For binarylinear [n, k, 2t+1] codes v can be expressed as (see, e.g., [7],Sec. III.e.):
v =t∑i=0
(n
i
)(3)
For a secure sketch based on a [n, k, 2t+1] code, the upperbound of the min-entropy m′ can be written as m′ ≤ n−(n− k) = k. Note that we are looking for an impossibilityresult, i.e., we want to show that if the inequality does nothold the construction does not fulfill the security prooffrom [2]. We do not want to show that if the inequalityholds that the constriction is secure. Therefore, we derivea lower bound of the attacker’s success probability ε asfollows:
ε = (4qH + 2n · v) · 2−m′
ε ≥ 2n ·t∑i=0
(n
i
)· 2−k
log2(ε) ≥ log2
(2n ·
t∑i=0
(n
i
)· 2−k
)
log2(ε) ≥ 1 + log2(n) + log2
( t∑i=0
(n
i
))−k
(4)
Since the success probability ε needs to be smaller than 1,i.e., ε < 1, one can simply define a lower bound as:
log2(1) > log2(ε) ≥ 1 + log2(n) + log2
( t∑i=0
(n
i
))−k
0 > 1 + log2(n) + log2
( t∑i=0
(n
i
))−k
k > 1 + log2(n) + log2
( t∑i=0
(n
i
))�
(5)
There are parameter choices for BCH codes that fulfill thebound. However, in practice, not only the security boundhas to hold, but the resulting BCH code also needs to
5. We use the simplified lower bound of Theorem 1 [2] for the casethat the hash output length was chosen appropriately.
6
n 63 127 255 511 1023 2047 4095 8191 16383 32767 65535p =0.92 - 27 45 85 126 231 413 819 1483 2861 5579p =0.93 - 27 42 85 115 205 367 686 1321 2517 4902p =0.94 15 23 42 59 102 179 330 597 1170 2340 4681p =0.95 15 21 42 53 87 153 292 506 955 1829 3545p =0.96 13 21 29 45 74 127 227 415 793 1483 2863p =0.97 11 21 25 37 60 101 178 325 599 1133 2184
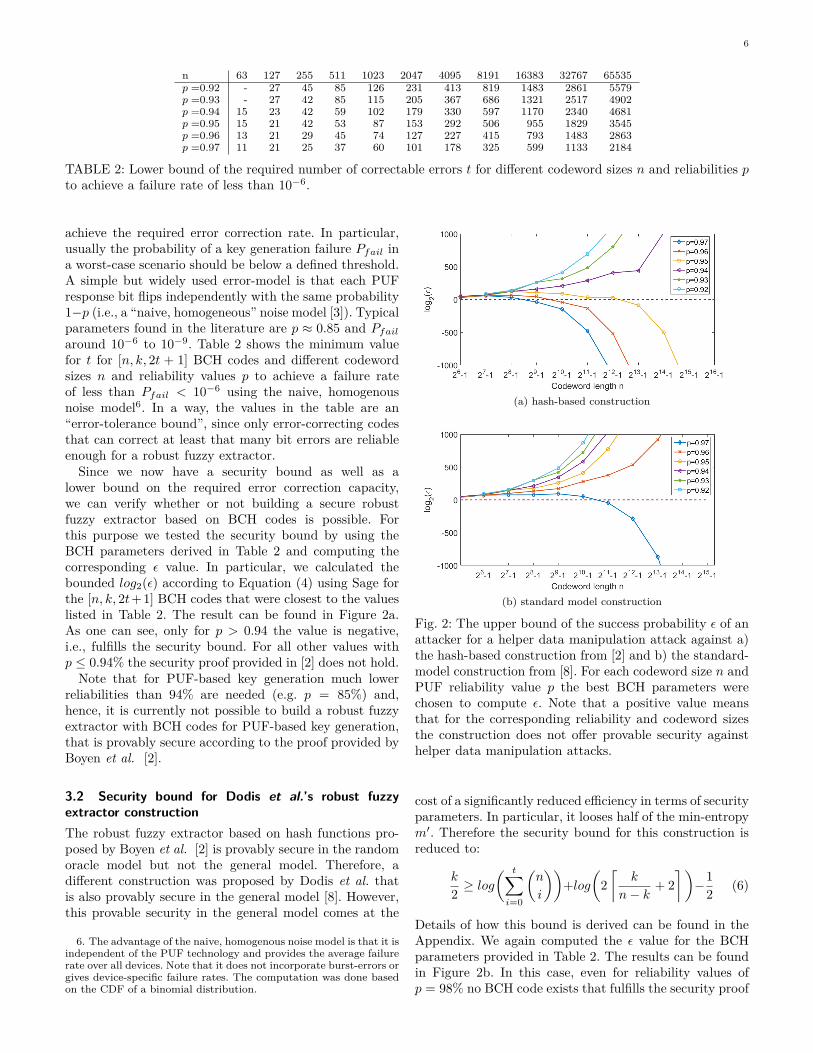
TABLE 2: Lower bound of the required number of correctable errors t for different codeword sizes n and reliabilities pto achieve a failure rate of less than 10−6.
achieve the required error correction rate. In particular,usually the probability of a key generation failure Pfail ina worst-case scenario should be below a defined threshold.A simple but widely used error-model is that each PUFresponse bit flips independently with the same probability1−p (i.e., a “naive, homogeneous” noise model [3]). Typicalparameters found in the literature are p ≈ 0.85 and Pfailaround 10−6 to 10−9. Table 2 shows the minimum valuefor t for [n, k, 2t + 1] BCH codes and different codewordsizes n and reliability values p to achieve a failure rateof less than Pfail < 10−6 using the naive, homogenousnoise model6. In a way, the values in the table are an“error-tolerance bound”, since only error-correcting codesthat can correct at least that many bit errors are reliableenough for a robust fuzzy extractor.
Since we now have a security bound as well as alower bound on the required error correction capacity,we can verify whether or not building a secure robustfuzzy extractor based on BCH codes is possible. Forthis purpose we tested the security bound by using theBCH parameters derived in Table 2 and computing thecorresponding ε value. In particular, we calculated thebounded log2(ε) according to Equation (4) using Sage forthe [n, k, 2t+1] BCH codes that were closest to the valueslisted in Table 2. The result can be found in Figure 2a.As one can see, only for p > 0.94 the value is negative,i.e., fulfills the security bound. For all other values withp ≤ 0.94% the security proof provided in [2] does not hold.Note that for PUF-based key generation much lower
reliabilities than 94% are needed (e.g. p = 85%) and,hence, it is currently not possible to build a robust fuzzyextractor with BCH codes for PUF-based key generation,that is provably secure according to the proof provided byBoyen et al. [2].
3.2 Security bound for Dodis et al.’s robust fuzzyextractor constructionThe robust fuzzy extractor based on hash functions pro-posed by Boyen et al. [2] is provably secure in the randomoracle model but not the general model. Therefore, adifferent construction was proposed by Dodis et al. thatis also provably secure in the general model [8]. However,this provable security in the general model comes at the
6. The advantage of the naive, homogenous noise model is that it isindependent of the PUF technology and provides the average failurerate over all devices. Note that it does not incorporate burst-errors orgives device-specific failure rates. The computation was done basedon the CDF of a binomial distribution.
(a) hash-based construction
(b) standard model construction
Fig. 2: The upper bound of the success probability ε of anattacker for a helper data manipulation attack against a)the hash-based construction from [2] and b) the standard-model construction from [8]. For each codeword size n andPUF reliability value p the best BCH parameters werechosen to compute ε. Note that a positive value meansthat for the corresponding reliability and codeword sizesthe construction does not offer provable security againsthelper data manipulation attacks.
cost of a significantly reduced efficiency in terms of securityparameters. In particular, it looses half of the min-entropym′. Therefore the security bound for this construction isreduced to:
k
2 ≥ log( t∑i=0
(n
i
))+log
(2⌈
k
n− k+ 2⌉)−1
2 (6)
Details of how this bound is derived can be found in theAppendix. We again computed the ε value for the BCHparameters provided in Table 2. The results can be foundin Figure 2b. In this case, even for reliability values ofp = 98% no BCH code exists that fulfills the security proof

7
of Dodis et al. [8].
3.3 Impact of concatenated codes on the securityboundBefore looking into concatenated codes, let us first con-sider the case that a message m is split into l blocks ofsize n and each block is decoded by a BCH code (or otherlinear code). Assume that a BCH code is used of which themaximum as well as the minimum number of correctableerrors within any given code word is t. If we concatenatel codeword blocks, the maximum number of correctableerrors is t · l, while the minimum number of correctableerrors is still only t, since t+ 1 errors in a single block willresult in a decoding failure. Hence, for more than t errorsthe robust fuzzy extractor needs to output ⊥, which makesit completely impractical. Otherwise, such a constructionwould not be in line with the security proofs of Boyen etal. [2] and Dodis et al. [8].
A crucial error correction concept in practice is the useof concatenated codes. Nearly all PUF-based key genera-tion proposals use concatenated codes, which first encodethe message with an inner code and then again with anouter code. In many cases the inner codes is a simplerepetition code, while the outer code is more complex. Themain idea is that the average error correction capability isconsiderably higher, even though the minimum number ofcorrectable errors is much smaller than using a single largecode. In practice, this average number of correctable errorsis what really matters to determine the failure probabilityPfail for PUF-based key generation. But since t is definedby the minimum number and not the average numberof correctable errors, using concatenated codes in a well-formed secure sketch is impossible. For example, in [20]a [7,1,7] repetition code, concatenated with a [318,174,35]BCH code was used. The repetition code can correct 3errors in a 7-bit codeword, and the BCH code can correctup to 17 errors in a 318-bit codeword. The concatenatedcode has a codeword length of n = 318 · 7 = 2, 226. Theminimum number of bit errors for a decoding error tooccur is 18 · 4 = 72. On the other hand, the maximumnumber of errors such that a codeword can still be decodedcorrectly is 17 · 7 + 301 · 3 = 1, 022. When used in awell-formed secure sketch as required for the robust fuzzyextractor constructions from [2] and [8], the number ofcorrectable errors would have to be set to t=72. Hence,such a construction would be impractical and considerablyworse than a non-concatenated code.
From an engineering perspective, it is tempting to ignorethe requirement of the proof that a well-formed securesketch is needed, and e.g. set t to the average or highestnumber of correctable errors. While this violates the proof,such a construction might still be secure considering thatno attack on such a construction is known. This scenariois discussed in greater detail in the next section.
4 Helper data manipulation attackIn this section the general attack strategy for the newhelper data manipulation attacks is described, before some
specific attacks against specific error correction strategiesand implementations are introduced in the next Section.
4.1 Attack modelRecently, Delvaux et al. [3] introduced a helper datamanipulation attack on a soft-decision error-correctionstrategy, in which modified helper data is sent to thePUF-enabled device and the attacker observed whetheror not a decoding failure occurred. With each query theattacker learns information about the PUF response andcan eventually reconstruct the entire response in a divide-and-conquer-like fashion.
In this paper we consider that instead of a fuzzyextractor an RFE-like construct is used. An RFE-likeconstruction is similar to the hash-based construction byBoyen et al. [2], but neglects the distance check t (seeFigure 1). The RFE-like construction is tempting to use,since it allows the use of concatenated codes. The RFE-like construct prevents helper data manipulation attacksas described above, since the key recovery always failsif the attacker does not transmit a valid hash value h.And without knowing the reconstructed PUF response w,the attacker cannot compute a valid hash value ha for amodified helper data sa.
The new attack strategy is therefore not to try to learnthe original PUF response w, but instead to try to set thereconstructed PUF response w to a value known by theattacker. This, in turn, enables the attacker to computea valid hash value ha. Note that this also means thatthe reconstructed key r is known by the attacker, butis not the same as the original key. Hence, the attackerdoes not learn the original key r with such an attack.Whether or not this is a reasonable attack goal depends onthe application the key is used for. For example, imagingthat the PUF-derived key is used to encrypt an externallystored bitstream. In the helper data manipulation attackfrom [3], the attacker would have learned the encryptionkey of the bitstream. This would allow the attacker to bothdecrypt the original bitstream as well as supply the devicewith its own bitstream. In our helper data manipulationattack scenario on the other hand the attacker would beable to supply a different bitstream to the device but wouldnot be able to decrypt the original bitstream.
Other scenarios in which setting the key is a legitimateattack goal is if the key is used for access control to thedevice. In this case it is sufficient for the attacker to set anew key without learning the old key as the main goal isto get access to the device. If on the other hand the goalis to create a software clone of a PUF device, e.g. becauseit is used as an anti-counterfeiting mechanisms, setting akey is not enough. In this case the original key is needed.
However, the presented helper data manipulation at-tacks can also be extended from only setting a key toadditionally recovering the original key. When and howthis can be achieved is briefly discussed in Section 4.3. Butthe focus of this paper is only to set the key to defeat thesecurity goal of a robust fuzzy extractor. The attacker’scapability can be summarized as follows:

8
Attacker PUF device
Given: helper data s, with s = x⊕w Given: noisy PUF function, PUF() = w⊕ e
Choose attack vector ea such thatxa = decode(ci ⊕ ea), ∀ci ∈ Cawith Ca ⊆ C and |Ca| maximizedsa = s⊕ ea
wa = sa ⊕ xa
ha = H1(sa, wa)ra = H2(wa)
sa,ha−−−−−−−→w′ = PUF() = w⊕ ex′ = w′ ⊕ sa
= (w⊕ e)⊕ (w⊕ x⊕ ea) = x⊕ e⊕ ea
x = decode(x′) = decode(x⊕ e⊕ ea)w = sa ⊕ xh = H1(sa, w)IF h==ha set r = H2(w) and status=‘ok’ELSE set r = ⊥ and status=‘error’
status←−−−−−−−
IF status==‘error’ repeat attackELSE success and ra == r and wa == w
TABLE 3: General description of the new helper data manipulation attack on an RFE-like construct.
• Attacker’s goal:– Make the PUF-enabled device reconstruct a key
ra that is known to the attacker (but whichdiffers from the original key r).
• Attacker’s capabilities:– The attacker has read and write access to the
helper data (s and h)– The attacker can verify if the predicted ra has
been reconstructed by the PUF device
4.2 New attack strategy
The main idea behind the new helper data manipulationattack is to send modified helper data sa to the PUF-enabled device such that during the recovery phase it de-codes to a specific known codeword xa = decode(w′ ⊕ sa)with a very high probability, independent of the PUFresponse w′. This, in turn, implies that the PUF devicewill recover a PUF response wa = sa ⊕ xa which theattacker can predict with a high probability. The attackercan then compute a valid hash value ha = H1(sa, wa). Ifthe attack succeeded, the PUF device and the attackerthen share a common key ra = H2(wa).
The entire attack is depicted in Table 3. The crucialpoint is, whether or not the attacker is able to modify thehelper data s in a way that during the error-correctionphase the PUF device will decode towards the attacker’sprediction xa with a high probability. Whether or not thisis possible strongly depends on i) the used error-correctioncode and ii) the implementation of the error-correctiondecoding. In the next section we will show some concreteattacks on implementations of different error-correctioncodes that have been proposed in the context of PUF-based key storage.
4.3 Extending attack to extract original keyDepending on the applications and used error-correctioncodes, it might be possible to not only set the key butto also recover the key. In practice, often not a singlelong code is used for the codeword x, but instead thethe codeword x actually consists of l smaller codewordsthat are concatenated together. This is actually true forall the codes we consider in our attack section. In thiscase, an attacker can perform a helper data manipulationattack that tries to set the codeword x for l− 1 codewordblocks but leaves one untouched. For the helper datamanipulation attack to succeed, the attacker then guessesthe unmodified codeword and tests the guess using theappropriate wa to compute the hash ha. If the unmodifiedcode word has k bit of entropy, the attacker has in averageto guess 2k−1 times till he succeeds and can proceed to thenext codeword block. This way the attacker could learn theentire original codeword x, and, hence, also the originalPUF response w = x ⊕ s and key r at the costs of anincreased attack complexity of l · 2k−1.
Note that this strategy also works, if only a fuzzyextractor (as opposed to an RFE-like fuzzy extractor) isused, as long as the attacker can verify if the recoveredkey is the one he assumed it is. This greatly increases thepractical relevance of the attacks discussed in the nextsection.
5 Example attacksIn this Section several attacks on popular error-correctioncodes for PUF-based key generation are shown. In par-ticular, several decoding strategies for Reed–Muller codesare attacked, as well as soft-decision decoding and even-numbered repetition decoding.
One of the most popular error-correction codes for PUF-based key generation are Reed–Muller codes, which are for

9
example used in [1], [16], [18], [19], [21]. In the following,we will show that different implementation strategies forReed–Muller codes exists that can be attacked using thenew helper data manipulation attack. For a successfulattack, we need to find an error pattern ea, such thatthe decoding algorithm decodes the codeword x′ ⊕ ea tothe same codeword xa for most codewords x′. There areseveral possible decoding strategies for Reed–Muller codes.We consider three popular decoding strategies: soft- andhard-decision maximum-likelihood decoding (SDML, ML),soft-decision Generalized Multiple Concatenated codes(GMC) decoding, and classic Reed decoding based on amajority logic vote.
5.1 Attacking SDML decodingThe SDML decoding procedure simply consists of gener-ating all possible codewords and returning the one withthe smallest Hamming distance to the received vector.The key observation for our attack on SDML decodingis that for some error vectors ea several codewords havethe same minimal Hamming distance. In this case alwaysthe first or last tested codeword will be chosen in mostimplementations7.
5.1.1 The noise free caseTo provide a concrete example, let us look at a [16,5,8]Reed–Muller code which contains 2k = 25 = 32 different16-bit codewords xi. Let us denote the codeword x0 as thecodeword consisting of all-zeros x0 = [0, .., 0], and x1 =[1, .., 1] the codeword consisting of all-ones. If we add thefollowing error vector ea = [0110101011000000] to xi then:
HD(x0,xi ⊕ ea) = 6 or HD(x1,xi ⊕ ea) = 6and HD(xj ,xi ⊕ ea) = {6, 10} ∀ i, j ≥ 2
(7)
In this case, depending on the codeword xi, themaximum-likelihood decoding always decodes to either x0or x1 for attack vector ea. In particular, there are 16codewords xi such x0 = decode(xi⊕ea) and 16 codewordsxi such that x1 = decode(xi⊕ea). Hence, by manipulatingthe helper data with error vector ea, only one bit ofentropy remains from the original 5 bits of entropy in thenoise-free case.
For their PUF design, van der Leest et al. [16] proposedto use 35 blocks of a concatenated code constructionconsisting of a hard-in soft-out [7,1,7] repetition code asan inner code and a [16,5,8] Reed–Muller code with SDMLdecoding as an outer code to derive a 175-bit secret. Letus first consider the noise free case. In order to defeatthe RFE-like construction, the attacker has to correctlyguess 35 blocks, i.e. predict 35 times the decoded codewordxa correctly to be able to compute the correct hash haand key ra. After the helper data manipulation one bitof entropy is left per block and a resulting entropy andmin-entropy of 35 bits all codeword blocks. One way to
7. It is also possible to choose a random codeword instead, inwhich case the attack would not work. However, this is typically moredifficult to implement especially for hardware implementation.
reliability min-entropy entropy min-entropy(per codeword) (per codeword) (per 175 bits)
soft-decision100% 1.0 1.0 35.099% 2.0 3.6 69.698% 2.8 4.5 98.297% 3.4 4.8 118.596% 3.8 4.9 130.895% 4.0 4.9 138.8
hard-decision100% 1.0 1.0 35.095% 1.0 1.0 35.090% 1.0 1.2 36.485% 1.2 1.8 41.180% 1.5 2.7 51.8
Without attack– 5 5 175
TABLE 4: Top: Overview of helper data manipulationattacks on a hard-in soft-out [7,1,7] repetition code inconjunction with a [16,5,8] Reed–Muller code using soft-decision SDML decoding. Bottom: hard-decision ML de-coding of a concatenated [7,1,7] repetition code with a[16,5,8] Reed–Muller code
interpret the min-entropy is that the success probabilityfor the most likely decoded codeword xa is 2−35. But itshould be noted, that testing a key requires the attacker tosend a manipulated helper data to the PUF device. Evenfor an entropy of 35 bits the attack would be quite hardto execute in practice, since the PUF would have to bechallenge around 235 times. But please also note that afull bit-entropy of the PUF is assumed which in practicemight be reduced, e.g., due to a bias of response bits.
5.1.2 Impact of noise on the attackIn practice the PUF response w′ will be noisy and hencea legitimate question is how well the attack works in thepresence of noise. To evaluate this question, we performedfollowing analysis. In a first step, 100,000 random binaryresponse strings are generated in MATLAB and the cor-responding helper data for the code-offset constructionand the error correction code are computed. Then eachresponse is flipped with probability 1 − p to simulatenoise (i.e. we use the naive homogeneous noise model inwhich each response bit has the same failure probability).The helper data is manipulated according to the attackstrategy. The noisy responses and the modified helper dataare passed to the Rec algorithm and the decoded responsesare stored. Based on this analysis, the probability thata decoding to a certain response wi occurs is computed,which in turn allows us to compute the min-entropy andentropy of the recovered response w in the presence ofthe attack. One thing to consider is that to estimate therequired error-correction capacity of a code the worst-casePUF reliability under environmental conditions is used.But during an attack the environmental conditions can bekept constant to reduce the noise to a minimum. There-fore, the reliability during an attack is considerably higherthan the worst-case reliability used to select the code. ForSRAM PUFs for example, reliability values around 96-98%are not uncommon when the environmental conditions are

10
kept constant while their worst case reliably can be easily10% worse [23].
The top of Table 4 shows the results for the attack onthe SDML construction from [16] while the bottom showsthe same attack for hard-decision maximum likelihooddecoding as proposed in [1]. The attack on soft-decisiondecoding quickly becomes very difficult to perform in thepresence of noise. Even with a reliability of 99%, themin-entropy within a 175-bit block is only reduced to69.6. However, when hard-decision maximum likelihooddecoding is used, the attack is very resistant to noise. Thisis due to the fact that the inner repetition code correctsmost of the noise. In this case the min-entropy of a 175-bit block is only slightly increased from 35 to 36.4 for areduction of the PUF reliability to 90%. This shows thathelper data manipulation attacks are not restricted to soft-decision decoding. Hard-decision decoding can actually beeasier to attack in some cases.
5.2 Attacking GMC decodingAnother popular decoding algorithm for Reed–Mullercodes is the Generalized Multiple Concatenated code(GMC) decoding [22]. It is, e.g., used in [19] and [21]in conjunction with PUF-based key generation. The mainidea of this soft-decision decoding algorithm is to treat theReed–Muller code as a concatenation of multiple smallercodes, and recursively decode these codes. The smallestcode that is decoded is simply a repetition code, whichhas a very low decoding complexity. The algorithm canbe used as a soft-decision decoder, and with some slightmodifications also supports erasures. We implemented theGMC decoding in MATLAB as a target implementation.Again, the [16,5,8] Reed–Muller code was used and anerror pattern for a helper data manipulation attack wasfound by simply testing all 216 possible error pattern.It turned out that the helper data manipulation attackon our GMC decoding implementation is actually morepowerful than the one on SDML decoding.
For the noise-free case, our GMC implementation al-ways decodes to the same codeword when supplied withfollowing error vector ea = [0000001011001010], i.e.:
x0 = decode(xi ⊕ ea) ∀xi ∈ C (8)
Hence, the resulting entropy is zero, since always x0is decoded. The attack complexity for a [7,1,7] hard-insoft-out repetition code as an inner code in conjunctionwith the tested soft-decision GMC [16, 5, 8] Reed–Mullerimplementation for different error rates is summarized inTable 5. For a noise level of 98% the attack complexityis quite reasonable and, hence, the attack can be consid-ered practical. However, for larger noise levels the attackcomplexity increases significantly.
5.3 Attacking Reed decodingAnother decoding algorithm considered in this paper isthe classic hard-decision Reed decoding based on major-ity logic. For this purpose we took a publicly available
reliability min-entropy entropy min-entropy(per codeword) (per codeword) (per 175 bits)
100% 0 0 099% 0.4 2.2 14.498% 0.9 3.7 31.397% 1.4 4.5 49.296% 1.9 5.0 66.695% 2.4 5.2 82.7
Without attack– 5 5 175
TABLE 5: Overview of helper data manipulation attackson a hard-in soft-out [7,1,7] repetition code in conjunctionwith a [16,5,8] Reed–Muller code using soft-decision GMCdecoding.
reliability min-entropy entropy min-entropy(per codeword) (per codeword) (per 175 bits)
100% 0.2 0.5 6.895% 0.2 0.6 6.890% 0.2 0.7 7.485% 0.3 1.3 11.0
Without attack– 5 5 175
TABLE 6: Results of helper data manipulation attackson a hard-decision [7, 1, 7] repetition code in conjunctionwith a [16, 5, 8] Reed–Muller code using classic majoritydecoding.
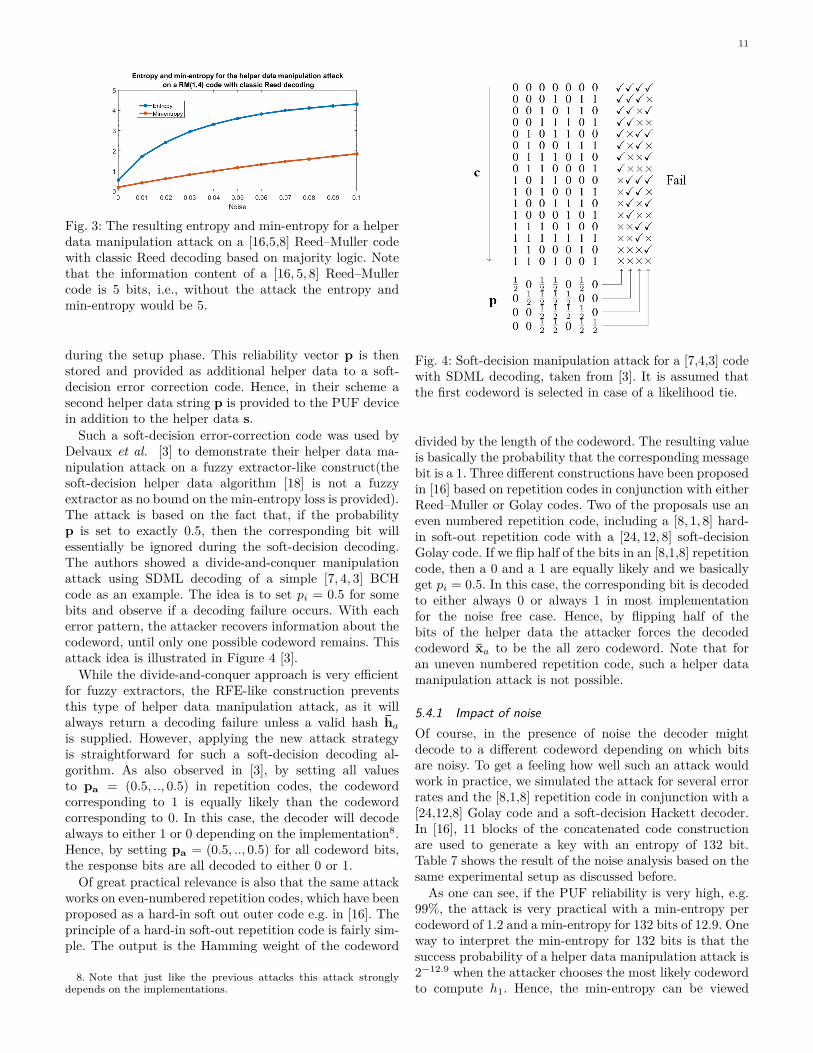
MATLAB implementation of a Reed–Muller majority logicdecoding and again searched for an error vector suitablefor a helper data manipulation attack. The attack vectorwe found was actually better than for the SDML decodingbut slightly worse than GMC decoding. For error vectorea = [1001011000000000] the implementation we useddecoded to the all-zero codeword x0 for 28 of the 32codewords xi. The four codewords that did not decodeto x0 decoded to the bit vector consisting of all zerosbesides the least significant bit which was a one. Hence,in the noise-free case, a min-entropy of 28/32 = 0.2 isachieved per block. However, when considering noise thehelper data manipulation attack on classic hard-decisionReed decoding actually exhibits the best performanceamongst all considered concatenated codes. This is onceagain due to the fact that the inner repetition code correctsmost of the noise. If we use a [7,1,7] repetition code inconjunction with a [16, 5, 8] Reed–Muller code even with aPUF reliability of only 85% the attack complexity is in theorder of 211. The results of our attack on the concatenatedconstruction can be found in Table 6.
For comparison, Figure 3 shows the development of themin-entropy of this attack when only a single Reed–Mullercode is being used. Without the inner repetition coding,the attack would be considerably more difficult in a noisyenvironment.
5.4 Attacks on soft-decision and even-numbered rep-etition codesMaes et al. were the first to propose soft-decision decodingfor PUFs in 2009 [18]. They proposed to derive a reliabilityvalue for each PUF bit by querying the PUF multiple times
11
Fig. 3: The resulting entropy and min-entropy for a helperdata manipulation attack on a [16,5,8] Reed–Muller codewith classic Reed decoding based on majority logic. Notethat the information content of a [16, 5, 8] Reed–Mullercode is 5 bits, i.e., without the attack the entropy andmin-entropy would be 5.
during the setup phase. This reliability vector p is thenstored and provided as additional helper data to a soft-decision error correction code. Hence, in their scheme asecond helper data string p is provided to the PUF devicein addition to the helper data s.Such a soft-decision error-correction code was used by
Delvaux et al. [3] to demonstrate their helper data ma-nipulation attack on a fuzzy extractor-like construct(thesoft-decision helper data algorithm [18] is not a fuzzyextractor as no bound on the min-entropy loss is provided).The attack is based on the fact that, if the probabilityp is set to exactly 0.5, then the corresponding bit willessentially be ignored during the soft-decision decoding.The authors showed a divide-and-conquer manipulationattack using SDML decoding of a simple [7, 4, 3] BCHcode as an example. The idea is to set pi = 0.5 for somebits and observe if a decoding failure occurs. With eacherror pattern, the attacker recovers information about thecodeword, until only one possible codeword remains. Thisattack idea is illustrated in Figure 4 [3].While the divide-and-conquer approach is very efficient
for fuzzy extractors, the RFE-like construction preventsthis type of helper data manipulation attack, as it willalways return a decoding failure unless a valid hash hais supplied. However, applying the new attack strategyis straightforward for such a soft-decision decoding al-gorithm. As also observed in [3], by setting all valuesto pa = (0.5, .., 0.5) in repetition codes, the codewordcorresponding to 1 is equally likely than the codewordcorresponding to 0. In this case, the decoder will decodealways to either 1 or 0 depending on the implementation8.Hence, by setting pa = (0.5, .., 0.5) for all codeword bits,the response bits are all decoded to either 0 or 1.Of great practical relevance is also that the same attack
works on even-numbered repetition codes, which have beenproposed as a hard-in soft out outer code e.g. in [16]. Theprinciple of a hard-in soft-out repetition code is fairly sim-ple. The output is the Hamming weight of the codeword
8. Note that just like the previous attacks this attack stronglydepends on the implementations.
Fig. 4: Soft-decision manipulation attack for a [7,4,3] codewith SDML decoding, taken from [3]. It is assumed thatthe first codeword is selected in case of a likelihood tie.
divided by the length of the codeword. The resulting valueis basically the probability that the corresponding messagebit is a 1. Three different constructions have been proposedin [16] based on repetition codes in conjunction with eitherReed–Muller or Golay codes. Two of the proposals use aneven numbered repetition code, including a [8, 1, 8] hard-in soft-out repetition code with a [24, 12, 8] soft-decisionGolay code. If we flip half of the bits in an [8,1,8] repetitioncode, then a 0 and a 1 are equally likely and we basicallyget pi = 0.5. In this case, the corresponding bit is decodedto either always 0 or always 1 in most implementationfor the noise free case. Hence, by flipping half of thebits of the helper data the attacker forces the decodedcodeword xa to be the all zero codeword. Note that foran uneven numbered repetition code, such a helper datamanipulation attack is not possible.
5.4.1 Impact of noiseOf course, in the presence of noise the decoder mightdecode to a different codeword depending on which bitsare noisy. To get a feeling how well such an attack wouldwork in practice, we simulated the attack for several errorrates and the [8,1,8] repetition code in conjunction with a[24,12,8] Golay code and a soft-decision Hackett decoder.In [16], 11 blocks of the concatenated code constructionare used to generate a key with an entropy of 132 bit.Table 7 shows the result of the noise analysis based on thesame experimental setup as discussed before.
As one can see, if the PUF reliability is very high, e.g.99%, the attack is very practical with a min-entropy percodeword of 1.2 and a min-entropy for 132 bits of 12.9. Oneway to interpret the min-entropy for 132 bits is that thesuccess probability of a helper data manipulation attack is2−12.9 when the attacker chooses the most likely codewordto compute h1. Hence, the min-entropy can be viewed

12
reliability min-entropy entropy min-entropy(per codeword) (per codeword) (per 132 bits)
100% 0 0 099% 1.2 3.8 12.998% 2.0 6.1 22.497% 2.8 7.6 30.596% 3.4 8.7 37.995% 4.1 9.4 44.9
Without attack– 12 12 132
TABLE 7: Result of a helper data manipulation attack ona [8,1,8] hard-in soft-out repetition code as an outer codeand a [24,12,8] Golay code with a soft-decision Hackettdecoder for different noise levels.
as the attack complexity at least in case that the noiseis identically and independently distributed (which is notnecessarily true in practice, see [3]). For smaller reliabilityvalues such as 95% the attacks become quite difficult toperform in practice with a min-entropy of roughly 44.9.
6 DiscussionSo far we have mainly presented negative results, i.e.,showed that it is currently not possible to build a robustfuzzy extractor that fulfills the security proof, and thatseveral practical error correction constructions are attack-able. However, by no means does that mean that buildinga provably secure fuzzy extractor is in general impossible.What we need are new proofs and constructs.
6.1 Outlook: Secure decoding strategiesLooking forward, what is needed is a provably secure ro-bust fuzzy extractor that works with efficient concatenatedcode constructions to achieve the required error correctionrates. As a starting point, the hash-based constructionseems to be very promising, since it has considerablybetter performance than the construction for the generalmodel proposed in [8]. The helper data manipulationattacks discussed in Section 4 show that these attacksstrongly depend on the used error correction code, thedecoding strategy, as well as its implementation. But by nomeans do our results show that any error correction codeor any implementation could be attacked using helper datamanipulation attacks! In particular, some error correctioncodes have a very interesting property that makes themsecure against the helper data manipulation attacks fromSection 4.
Recall the syndrome decoding strategy from Definition 7,where during decoding in the first step an error polynomiale is computed using the locate function, and in the secondstep this error polynomial is XORed with the receivedcodeword x′. What is important for us is that there aredecoding strategies for BCH codes based on syndromedecoding for which the following equation holds for allcodewords xi of the [n, k, 2t+ 1] code C:
ej = locate((xi ⊕ ej) ·HT
)∀ xi ∈ C, ∀ ej ∈ {0, 1}n and ej ∈ {0, 1}n
(9)
In other words, the error polynomial ej is independent ofthe codeword xi and only depends on the error polynomialej . While it is possible to flip specific bits of the decodedcodeword x with a helper data manipulation attack, it isnot possible to set specific bits. The attacker can no longerpredict x with an increased probability and can thereforealso not compute a hash value ha which the PUF devicewill accept as valid. Hence, the helper data manipulationattacks presented in this paper do not work any longer, ifa concatenated code construction is used in the RFE-likeconstruction for which Equation (9) holds.
It therefore seems, that it should be possible to buildsecure robust fuzzy extractors, if the used error correctioncodes fulfills Equation (9). However, note that we onlypresented a security argument. Proving this in a moreformal setting would be very interesting, since this wouldenable us to use a relaxed notion of correctness for robustfuzzy extractors, similar as it has been proposed for fuzzyextractors in [9]. This would allow the use of efficientconcatenated code constructions and possibly even soft-decision decoding. But it is important to note that thisway not a specific error-correction code construct can beshown to be provably secure. Instead, only specific errorcorrection strategies could be proven to be secure. Inother words, using a BCH code does not guarantee thatthe implemented decoding strategy indeed fulfills Equa-tion (9). To give an example, consider an [n, k, 2t+1] BCHcode with a small k. The typical decoding strategy for aBCH code is syndrome decoding. But for codes with asmall k, maximum-likelihood decoding can be used as welland might be very efficient, especially in hardware imple-mentations. However, for maximum-likelihood decodingEquation (9) does not hold and helper data manipulationattacks are possible (see the attack in Section 5.1).
Another important, but difficult, aspect is the remainingmin-entropy for concatenated codes if the PUF responsew does not have full bit entropy. While there is a clearupper bound on the entropy loss in fuzzy extractors [10],using this bound makes building fuzzy extractors verychallenging [15]. In [17], [4] a more in-depth discussionregarding this aspect is presented, including a considerablytighter bound than the one assumed in [15]. In how far thepresented attacks can be improved by incorporating suchreductions in the PUF response entropy is an interestingresearch question.
6.2 Random oracle model vs general modelFrom a practical perspective, the first robust fuzzy extrac-tor proposal by Boyen et al. [2] based on hash functionsis very compelling, since it only requires a hash functionwhich needs to be implemented for the fuzzy extractoranyway. Furthermore, it is very straightforward and easyto implement and to understand. The fact that it is “only”secure in the random oracle model is not seen as a bigproblem from a practical perspective. To put it bluntly,hardware security engineers have much bigger problemsthan the assumptions in the random oracle model. For

13
example, in practice it is typically impossible to determinethe exact entropy within a PUF or a biometric reading.The best we can usually do is perform measurementsand simulations and approximate the entropy based onsome assumptions. However, this will never be hundredpercent accurate and proving that the made assumptionsare correct extremely challenging, if not impossible, unlessvery loose bounds are used. Therefore sacrificing nearlyhalf of the entropy so that the system is also provablysecure in the standard model does not really make sensefrom a practical perspective. As a result, the constructionby Dodis et al. [8] that is provably secure in the generalmodel has basically been ignored by the PUF community.It should also be noted that the problem of robust fuzzyextractors in general has been largely neglected by thePUF community. Usually, the need of security against anactive attacker is acknowledged, but this is typically onlyfollowed by the remark that in this case hash-based robustfuzzy extractor construction should be used. However, itappears that the details of the proofs and definitions ofthe robust fuzzy extractor have not been really considered.Therefore, the fact that it is actually not possible to extendthe popular fuzzy extractor constructions to robust fuzzyextractors has not been discussed.
From a theoretical perspective, the construction that issecure in the general model is more compelling since ithas less assumptions. The construction for the standardmodel therefore has gained much more attention in theoryoriented papers [14], [7]. However, the fact that the smallerror correction rate of robust fuzzy extractors is actuallythe most limiting factor for a provable, as well as practical,robust fuzzy extractor has not been identified. Comingup with a provably secure robust fuzzy extractor with arelaxed notion of correctness (i.e., based on a non well-formed secure sketch) would have a big practical impact,even if it is proven in a weaker security model than therandom oracle model or general model.
7 ConclusionThis work shows that i) currently no robust fuzzy extrac-tor construction exists that fulfills the security proof ofBoyen et al. [2] while also achieving the required error cor-rection rates for PUF based key generation, and ii) manyimplementations of decoding algorithms for error correc-tion codes used in PUF-based key generation schemesare susceptible to helper data manipulation attacks, evenwhen they are used in a fuzzy extractor setting with anadditional hash value check against modifications. Pleasenote that these attacks only work when the distance checkt that is required in the construction of Boyen et al. isignored. Hence, these attacks do not invalidate the resultsof Boyen et al. , but instead highlight that simply ignoringthe check, as it seems to be the suggested in many practiceoriented papers, is not a valid solution.
Hence, our results show that the problem of buildingrobust fuzzy extractors is actually not solved yet. Ourattack on the widely used Reed–Muller decoding shows
that there is a great need to build robust fuzzy extractors,that are secure against helper data manipulation attacks.While this paper mainly presented negative results andattacks, this does not mean that building secure robustfuzzy extractors is a lost cause: By considering specificdecoding strategies it seems that it should be possible tobuild both (provably) secure and practical robust fuzzyextractor. However, for this a combined effort of bothpractitioners, as well as theorist, is needed.
References[1] Bösch, C., Guajardo, J., Sadeghi, A.R., Shokrollahi, J., Tuyls,
P.: Efficient helper data key extractor on FPGAs. In: CHES2008, LNCS, vol. 5154, pp. 181–197. Springer (2008)
[2] Boyen, X., Dodis, Y., Katz, J., Ostrovsky, R., Smith, A.: Secureremote authentication using biometric data. In: Advances incryptology–EUROCRYPT 2005, pp. 147–163. Springer (2005)
[3] Delvaux, J., Gu, D., Schellekens, D., Verbauwhede, I.: Helperdata algorithms for PUF-based key generation: overview andanalysis. IEEE Transactions on Computer-Aided Design of In-tegrated Circuits and Systems 34(6), 889–902 (2015)
[4] Delvaux, J., Gu, D., Verbauwhede, I., Hiller, M., Yu, M.D.M.:Efficient fuzzy extraction of PUF-induced secrets: Theory andapplications. In: CHES 2016. LNCS, Springer (2016)
[5] Delvaux, J., Verbauwhede, I.: Attacking PUF-based patternmatching key generators via helper data manipulation. In: Cryp-tographers Track at the RSA Conference (CT-RSA). pp. 106–131. Springer (2014)
[6] Delvaux, J., Verbauwhede, I.: Key-recovery attacks on variousRO PUF constructions via helper data manipulation. In: Pro-ceedings of the conference on Design, Automation & Test inEurope - DATE 2014. p. 72. European Design and AutomationAssociation (2014)
[7] Dodis, Y., Kanukurthi, B., Katz, J., Reyzin, L., Smith, A.:Robust fuzzy extractors and authenticated key agreement fromclose secrets. IEEE Transactions on Information Theory 58(9),6207–6222 (2012)
[8] Dodis, Y., Katz, J., Reyzin, L., Smith, A.: Robust fuzzy ex-tractors and authenticated key agreement from close secrets.In: Annual International Cryptology Conference. pp. 232–250.Springer (2006)
[9] Dodis, Y., Ostrovsky, R., Reyzin, L., Smith, A.: Fuzzy extrac-tors: How to generate strong keys from biometrics and othernoisy data. SIAM journal on computing 38(1), 97–139 (2008)
[10] Dodis, Y., Reyzin, L., Smith, A.: Fuzzy extractors: How togenerate strong keys from biometrics and other noisy data. In:Eurocrypt 2004. LNCS, vol. 3027, pp. 523–540. Springer (2004)
[11] Dodis, Y.e.H.t.g.s.k.f.b., other noisy data, Reyzin, L., Smith, A.:Fuzzy Extractors, pp. 79–99. Springer London, London (2007),https://doi.org/10.1007/978-1-84628-984-2_5
[12] Guajardo, J., Kumar, S.S., Schrijen, G.J., Tuyls, P.: Physicalunclonable functions and public-key crypto for FPGA IP protec-tion. In: Field Programmable Logic and Applications, 2007. FPL2007. International Conference on. pp. 189–195. IEEE (2007)
[13] Juels, A., Wattenberg, M.: A fuzzy commitment scheme. In:Proceedings of the 6th ACM conference on Computer andcommunications security. pp. 28–36. ACM (1999)
[14] Kanukurthi, B., Reyzin, L.: An improved robust fuzzy extractor.In: International Conference on Security and Cryptography forNetworks. pp. 156–171. Springer (2008)
[15] Koeberl, P., Li, J., Rajan, A., Wu, W.: Entropy loss in PUF-based key generation schemes: The repetition code pitfall. In:HOST 2014. pp. 44–49. IEEE (2014)
[16] van der Leest, V., Preneel, B., van der Sluis, E.: Soft decisionerror correction for compact memory-based PUFs using a singleenrollment. In: CHES 2012, LNCS, vol. 7428, pp. 268–282.Springer (2012)
[17] Maes, R., van der Leest, V., van der Sluis, E., Willems, F.:Secure key generation from biased PUFs. In: CHES 2015, pp.517–534. LNCS, Springer (2015)
[18] Maes, R., Tuyls, P., Verbauwhede, I.: Low-overhead implemen-tation of a soft decision helper data algorithm for SRAM PUFs.In: CHES 2009, LNCS, vol. 5747, pp. 332–347. Springer (2009)

14
[19] Maes, R., Tuyls, P., Verbauwhede, I.: A soft decision helper dataalgorithm for SRAM PUFs. In: IEEE International Symposiumon Information Theory – ISIT 2009. pp. 2101–2105. IEEE (2009)
[20] Maes, R., Van Herrewege, A., Verbauwhede, I.: PUFKY: A fullyfunctional PUF-based cryptographic key generator. In: CHES2012, LNCS, vol. 7428, pp. 302–319. Springer (2012)
[21] Puchinger, S., Müelich, S., Bossert, M., Hiller, M., Sigl, G.: Onerror correction for physical unclonable functions. In: SCC 2015;10th International ITG Conference on Systems, Communica-tions and Coding; Proceedings of. pp. 1–6. VDE (2015)
[22] Schnabl, G., Bossert, M.: Soft-decision decoding of Reed-Mullercodes as generalized multiple concatenated codes. IEEE Trans-actions on Information Theory 41(1), 304–308 (1995)
[23] Schrijen, G.J., van der Leest, V.: Comparative analysis of SRAMmemories used as PUF primitives. In: Proceedings of the Confer-ence on Design, Automation and Test in Europe. pp. 1319–1324.EDA Consortium (2012)
[24] Suh, G.E., O’Donnell, C.W., Sachdev, I., Devadas, S.: Designand implementation of the AEGIS single-chip secure processorusing physical random functions. In: 32nd International Sym-posium on Computer Architecture (ISCA’05). pp. 25–36 (June2005)
[25] Yu, M.M., Sowell, R., Singh, A., M’Raïhi, D., Devadas, S.: Per-formance metrics and empirical results of a PUF cryptographickey generation ASIC. In: HOST 2012. pp. 108–115. IEEE (2012)
AppendixSecurity bound for the general construction from Dodis etal.
Theorem 2: Security Bound for the general constructfrom Dodis et al. [7] :A binary linear [n, k, 2t+ 1] code used in a robust sketchas defined in [7] that does not fulfill the following bound isnot provably secure according to the proof provided in [7]:
k
2 ≥ log( t∑i=1
(n
i
))+log
(2⌈
k
n− k+ 2⌉)−1 (10)
Proof: Our Theorem is based on Theorem 3 from [7]. In [7]slightly different notions are used than in this paper andthe paper from Boyen [2]. In particular the new notionof pre- and post-application robustness is introduced. Wewill not discuss these definitions and refer the interestedreader to [7]. A few variables used in Theorem 3 [7] canbe confusing since we use them differently in this paperand therefore we marked variables from Theorem 3 [7]that have a different meaning in this paper with a tilde.Furthermore, v is denoted in [7] with B. In Theorem 3from [7] it is stated that for any ε, δ satisfying
l ≤ 2m− n− k − 2 ·max{log(v) + log
(2⌈n−kk
+ 2⌉)
+log(
1δ
), 2log
(1ε
)}(11)
(Gen,Rec) is an (m, l, t, ε)- fuzzy extractor for M withpre-application robustness δ. The pre-application robust-ness is basically the chance that an active attacker canperform a helper data manipulation attack while ε is thesuccess probability of a passive attacker. Hence, ε = δas we denoted the attack probability of an active attackerwith ε in this paper. For a linear [n, k, 2t−1] code k = n−kand the maximum possible entropy m is m = n. Thevariable l is the length of the resulting key in bits. We areagain interested in an impossibility result that shows that
codes not fulfilling the bound cannot be secure (but againfulfilling the bound does not necessarily mean the robustfuzzy extractor is secure). One can bound the attackerssuccess probability ε with:
l ≤ 2m− n− k − 2(log(v) + log
(2⌈n−kk
+ 2⌉)
+log(
1ε
)l2 ≤
k2 − log
(∑ti=1(ni
))−log
(2⌈
kn−k + 2
⌉)+log(ε)
log(ε) ≥ log(∑t
i=1(ni
))+log
(2⌈
kn−k + 2
⌉)−k2 −
l2
(12)
Since l ≥ 1 and ε ≤ 1 we can define the following boundthat needs to be fulfilled:
log(1) ≥ log(ε) ≥ log(∑t
i=1(ni
))+log
(2⌈
kn−k + 2
⌉)−k2 −
l2
k2 ≥ log
(∑ti=1(ni
))+log
(2⌈
kn−k + 2
⌉)− 1
2
�
(13)
Dr. Georg T. Becker is a senior researcherat the Digital Society Institute (DSI) at theESMT Berlin. Before joining the DSI in Decem-ber 2016 he was a Post-Doc in the EmbeddedSecurity Group at the Horst Görtz Institute forIT-Security at the Ruhr Universität Bochum.His primary research interest is IT-security withspecial focus on hardware security with topicssuch as hardware Trojans, Physical UnclonableFunctions (PUFs) and side-channel analysis. Hereceived his Ph.D. in Electrical and Computer
Engineering at the University of Massachusetts Amherst in 2014 andholds a M.Sc. degree in IT-Security (2009) and a B.Sc. degree in AppliedComputer Science (2007) from the Ruhr Universität Bochum.