rsensing6_khairul 1 image classification image classification uses the spectral information...
TRANSCRIPT

rsensing6_khairul1
Image Classification
Image Classification uses the spectral information represented by the digital numbers in one or more spectral bands, and attempts to classify each individual pixel based on this spectral information
The objective is to assign all pixels in the image to particular classes or themes (e.g. water, coniferous forest, deciduous forest, corn, wheat, etc.).
The resulting classified image is comprised of a mosaic of pixels, each of which belong to a particular theme, and is essentially a thematic "map" of the original image

rsensing6_khairul2
Image Classification
Image Data Thematic Map

rsensing6_khairul3
Spectral or Information Classes ?
When talking about classes, we need to distinguish between
Information classes (e.g. land use) Spectral classes (e.g. land cover)

rsensing6_khairul4
Information & Spectral Classes
Information classes are those categories of interest that the analyst is actually trying to identify in the imagery, such as: different kinds of crops, different forest types or
tree species,different geologic units or rock types, etc. Spectral classes are groups of pixels that are uniform (or
near-similar) with respect to their brightness values in the different spectral channels of the data.
The objective is to match the spectral classes in the data to the information classes of interest.

rsensing6_khairul5
Information & Spectral Classes
Rarely is there a simple one-to-one match between these two types of classes.
Rather, unique spectral classes may appear which do not necessarily correspond to any information class of particular use or interest to the analyst.
Alternatively, a broad information class (e.g. forest) may contain a number of spectral sub-classes with unique spectral variations.
It is the analyst's job to decide on the utility of the different spectral classes and their correspondence to useful information classes.

rsensing6_khairul6
Classification Types
Common classification procedures can be broken down into two broad subdivisions based on the method used:
supervised classification and unsupervised classification

rsensing6_khairul7
Supervised Classification
This form of classification involves some form of supervision by the operator by specifying, to the particular algorithm, numerical descriptors of various land-cover types present in a particular scene.
There are four main stages involved in Supervised Classification.:1. The Training Stage2. Classification Stage3. Output Stage4. Accuracy Assesment Stage

rsensing6_khairul8
Training Stage
In this stage, the operator identifies representative training areas within a scene, and develops a numerical description of the spectral attributes of each land-cover type e.g. corn field, river, road, deciduous forest etc etc.
The accuracy with which the training stage is undertaken will ultimately determine the success of the classification.
In order to yield acceptable results, therefore, training data must be both representative and complete.

rsensing6_khairul9
Oblique Air Photo of Morrow Bay, California

rsensing6_khairul10Landsat TM, Morrow Bay, California
TM Band 4 = red
TM Band 3 = green
TM Band 2 = blue
TM Band 3 = red
TM Band 2 = green
TM Band 1 = blue

rsensing6_khairul11
Training Stage
In reality, therefore, it can be useful if the operator is familiar with the location from which the remotely sensed data has been acquired. This will make the selection of training sites relatively straightforward.
In addition, any in-situ spectral measurements of the training areas taken at the time of data collection will be taken into account.

rsensing6_khairul12
Training Sites
The location of training areas in an image is normally established by viewing windows, or portions of the full scene.
The operator normally obtains training data by outlining areas with a cursor (mouse) in the form of discrete polygons for each cover-type.
The row and column locations of these polygons are then used as the basis for extracting (from the image file)the digital numbers from the pixels located within each boundary.

rsensing6_khairul13
Training Sites for Land-Cover Units

rsensing6_khairul14
When DNs are plotted as a function of the band sequence (increasing with wavelength), the result is a spectral signature or spectral response curve for that training class. In reality the spectral signature is for all of the materials within the training site that interact with the incoming radiation.

rsensing6_khairul15
Selection of Training Data
Accurate selection of training data is crucial for accurate supervised classification.
There are many approaches to signature collection and analysis, but all rely to a certain degree on the experience of the analyst.
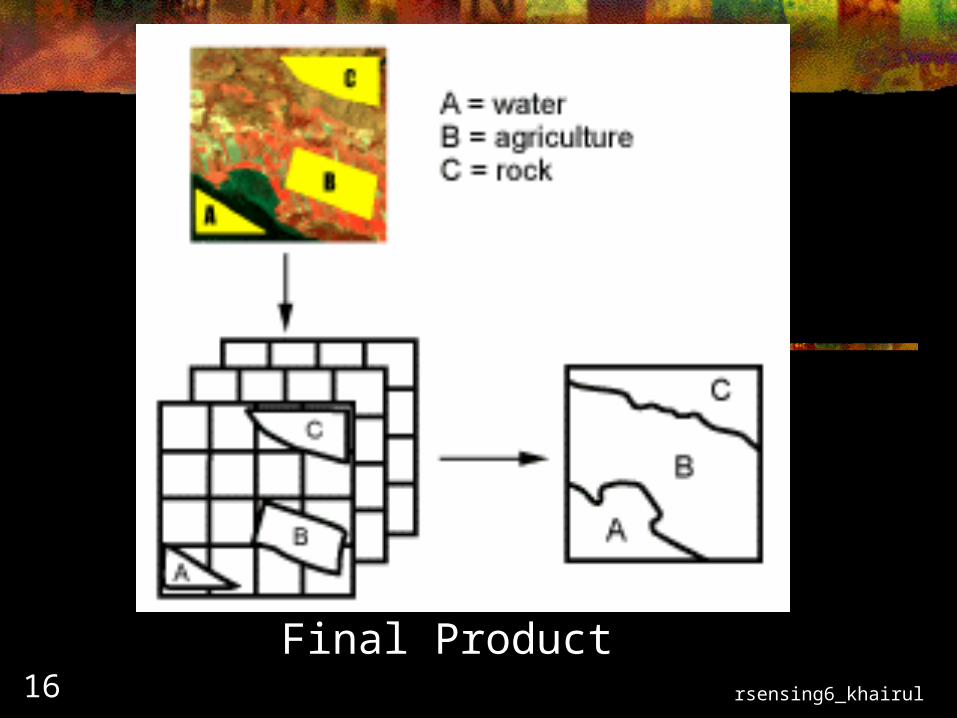
rsensing6_khairul16
Final Product

rsensing6_khairul17
The Classification StageThe Classification Stage
Numerous mathematical approaches to spectral pattern recognition have been developed.
1. Minimum distance to mean2. Parallelepiped classifier3. Maximum likelyhood classifier
In order to demonstrate some of these methods, it is important to look at the relationship between the spectral response of selected cover-types in relation to the spectral band-widths of the sensor..

rsensing6_khairul18
Clusters of data in feature-space corresponding to different surfacesClusters of data in feature-space corresponding to different surfaces

rsensing6_khairul19
Paralellpiped ClassifierParalellpiped Classifier
In this classifier, the range of spectral measurements are taken into account. The range is defined as the highest and lowest digital numbers assigned to each band from the training data
An unknown pixel is therefore classified according to its location within the class range. However, difficulties occur when class ranges overlap. This can occur when classes exhibit a high degree of correlation or covariance.
This can be partially overcome by introducing stepped borders to the class ranges.

rsensing6_khairul20
Simple parallelpiped classificationSimple parallelpiped classification

rsensing6_khairul21
Parallelpiped classification with more precise boundariesParallelpiped classification with more precise boundaries

rsensing6_khairul22
Minimum distance to means classifierMinimum distance to means classifier
1. Calculate of the mean spectral value in each band and for each category.
2. Relate each mean value by a vector function3. A pixel of unknown identity is calculated by computing
the distance between the value of the unknown pixel and each of the category means.
4. After computing the distances, the unknown pixel is then assigned to the closest class.
Limitations of this process include the fact that it is insensitive to different degrees of variance within spectral measurements.

rsensing6_khairul23

rsensing6_khairul24
Minimum distance to means classification methodMinimum distance to means classification method

rsensing6_khairul25
Maximum Likelihood Classifier
This classifier quantitatively evaluates both the variance and covariance of the trained spectral response patterns when deciding the fate of an unknown pixel.
To do this the classifier assumes that the distribution of points for each cover-type are normally distributed
Under this assumption, the distribution of a category response can be completely described by the mean vector and the covariance matrix.
Given these values, the classifier computes the probability that unknown pixels will belong to a particular category.

rsensing6_khairul26Maximum likelihood classification methodMaximum likelihood classification method
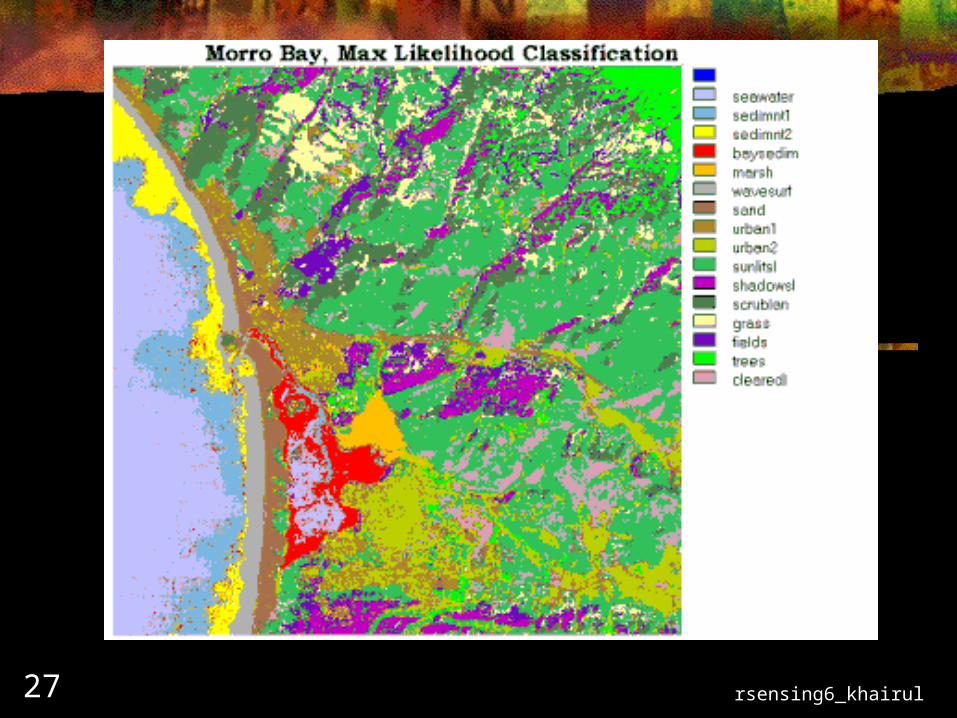
rsensing6_khairul27

rsensing6_khairul28

rsensing6_khairul29
Accuracy Assessment
This is effectively the detailed assessment of agreement between two maps at specific locations.
This is commonly referred to as a sort of Classification Error.
In this case, the units of assessment are simply pixels derived from remote sensing data, and errors are defined as misidentification of the identities of these individual pixels
The standard form of reporting site specific errors is an error matrix,

rsensing6_khairul30
Advantages of Supervised Classification
Analyst has control
Processing is tied to specific areas of known identity
Analyst not faced with the problem of matching categories on the final map with field information
Operator can detect errors, and often remedy them

rsensing6_khairul31
Disadvantages of Supervised Classification
The analyst imposes a structure on the data, which may not match reality. (may be over-simple)
Training classes are generally based on field identification, and not on spectral properties (signatures are forced).
Training data selected by the analyst, may not be representative of conditions encountered throughout the image (heterogenaety in classes is common).
Training data can be time-consuming and costly (iterative process)
Unable to recognise and represent special or unique categories not represented in the training data.

rsensing6_khairul32
Unsupervised Classification
This can be defined as the identification of natural groups, or structures within multispectral data
Assumption:
It can be demonstrated that remotely sensed images are usually composed of spectral classes that internally are reasonably uniform in respect to brightness in several spectral channels
Unsupervised classification is therefore the process of identifying, labelling, and mapping these classes.

rsensing6_khairul33

rsensing6_khairul34
Processing Theory
The basis of unsupervised classification is a pixel-by-pixel identification of groupings (clusters) of data within feature-space.
So, assuming clusters are apparent in the image data, this is largely done by calculating the distances between specific pixels within feature space, and assigning them to cluster-centeres (using a distance function - e.g. Euclidian Distance)

rsensing6_khairul35
Assignment of Spectral Categories to Information Categories
The output from this process is a map of the uniform groupings of pixels. As such they only become useful if they can be matched to one or more ground/information classes in order to produce a final product (e.g. land-use map).
Sometimes the assignment of identifiers to classes can be made on a purely spectral basis (e.g. water). However, we can only rarely use spectral properties in isolation - other field information is necessary.

rsensing6_khairul36Natural Clusters in 2-band data

rsensing6_khairul37
We can visualise natural clusters within 3-band RS data with the aid of this diagram, taken from Sabins, "Remote Sensing: Principles and Interpretation." 2nd Edition, for four classes:
A = Agriculture; D= Desert; M = Mountains; W = Water.

rsensing6_khairul38
Typical Processing Sequence
Specify minimum and maximum numbers of categories
Identify cluster centres (class centroid) Calculate distances (euclidian) between clusters
in feature space, based on a class centroid. Recalculation of class centroid as more pixels
are analysed, until no appreciable change is detected.

rsensing6_khairul39
Assignment of Spectral Categories to Assignment of Spectral Categories to Information CategoriesInformation Categories
The output from this process is a map of the uniform groupings of pixels.
As such they only become useful if they can be matched to one or more ground/information classes in order to produce a final product (e.g. land-use map).
Sometimes the assignment of identifiers to classes can be made on a purely spectral basis (e.g. water).
However, we can only rarely use spectral properties in isolation - other field information is necessary.

rsensing6_khairul40
Advantages of Unsupervised Classification
No extensive prior knowledge of the region is required.
The opportunity for human error is minimised.
Unique classes are recognised as distinct units.

rsensing6_khairul41
Disadvantages of Unsupervised Classification
These are primarily from a reliance on “natural” groupings, and matching these with field data:
Spectral classes are not necessarily information classes. Analyst has little control over image classes - making
inter-comparison of data difficult Spectral properties change over time. Therefore the
relationship between spectral response and information class are not constant, and detailed spectral knowledge of surfaces may be necessary

rsensing6_khairul42
Selection of Correct Classification Algorithm
There are many classification algorithms available for land-cover mapping. Selection of the appropriate classifier should be made on the basis of local experience.
Unsupervised and supervised methods are appropriate for sites where either very little or very complete field records are available.
However, even when the accuracy of a classification is determined, it is difficult to anticipate the balance between the effects of the choice of classifier, selection of data, characteristics of landscape, and other factors.