running siebel on aws - oracle open world 13
TRANSCRIPT

Siebel on AWSBuilding extremely HA and scalable Siebel infrastructure with no Hardware!
Enterprise Beacon, [email protected]

Enterprise Beacon, Inc.
• Founded in 2008• Oracle Gold Partner• AWS Consulting Partner• Launched the first test drive for Siebel using
EC2 and RDS– Deep expertise on both Siebel and AWS
• Object Hive - Exa-Ready Certified– Siebel Version Control Product

Benefits over Salesforce/SAASSiebel on AWS Salesforce/SAAS
Customers already own Siebel licenses! Only pay for AWS based on usage.
Per user/Per month = High TCO
No high cost/high risk reimplementation needed for existing Siebel implementations
High risk/ High cost migration
Ability to completely keep instance behind enterprise firewall
Has to be accessed over public internet
No crippling governor limits in production
Governor and edition limits on every aspect

Benefits over Salesforce/SAAS..Siebel on AWS Salesforce/SAAS
Apply Innovation packs as needed
Quarterly releases are applied directlyThings break:e.g Sidebar bar JS hack. History data storage durations.
No instance migrations Customers can be moved across instances without a choice with little notice
Unlimited number of environments
Limitation on number/size of environments and refresh periods
AWS 99.95 guarantee No SLA guarantee!
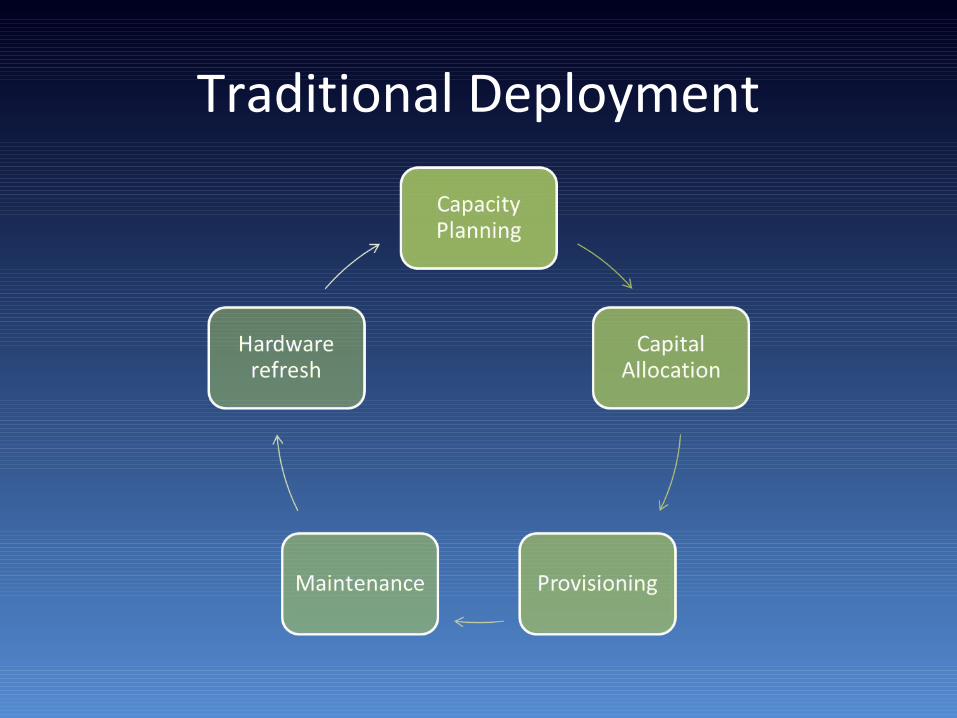
Traditional Deployment

Benefits over On PremiseAWS On Premise
Low operating costs and TCO Capital Expense and Higher TCO for hardware and virtualization licenses.
Moore's law works for you Moore's law works against you
Ability to right size any environment when needed.
Not possible
Auto recovery for failed instances. Not possible. Even with virtualization you still need spare hardware.
HA built into the platform can be taken advantage of by spreading instances across AZs and Regions
HA requires expensive clustering or expensive virtualization software and hardware. Does not protect against datacenter failure (No Azs)

Benefits over On Premise ..AWS On Premise
DR can be built at extremely low cost across data centers
DR requires buying expensive hardware
Low Support cost High Hardware support costsVMware licensing and support costs
Ability to know the performance before launching
Performance is known until hardware is procured and deployed
No End Of Life for hardware. Simply upgrade to newer instances with a few clicks
Hardware EOL customers are forced to buy hardware again
Ease of use. Create replica environments in few clicks
Hard to maintain and replicate

Cost to Business
• All this leads to– Wasted capacity– Inadequate capacity– High Costs– Inadequate testing coverage– Poor testing – Poor build and release quality

AWS Concepts
• EC2 (Elastic Compute 2)– Amazon Elastic Compute Cloud (EC2) is a central part of Amazon Web Services (AWS).
EC2 allows users to rent virtual computers on which to run their own computer applications.
– Many different instance types
• RDS (Relational Database Service)– IAAS more specifically Database As A Service – Available database options for Siebel
• Oracle• SQL server
• Elastic Compute Unit (ECU)– The elastic compute unit (ECU) was introduced by Amazon EC2 as an abstraction of
computer resources and as a unit to measure computing capacity

• Elastic Block Store (EBS)– All virtualized instances run of a stored image– EBS volumes are built on replicated storage, so that the failure of a single component
will not cause data loss.
• Simple Storage Service (S3)– Amazon S3 provides a simple interface that can be used to store and retrieve any
amount of data, at any time, from anywhere. It gives customers access to the same highly scalable, reliable, secure, fast, inexpensive infrastructure.
• Elastic Load Balancer (ELB)– In addition to balancing load based on incoming traffic ELB can detect unhealthy
instances and re-route traffic to healthy instances
• Route 53 – A highly available and scalable Domain Name System (DNS) web service, it can help
detect an outage of a instance and redirect traffic to alternate locations where your application is operating properly.
– 100% SLA for Route 53 since it used build DNS Fail Overs

North America

Gov CloudFor US Gov Only
• AWS Region designed to allow US government agencies and customers to move sensitive workloads into the cloud by addressing their specific regulatory and compliance requirements
• FEDRAMP and ITAR certified
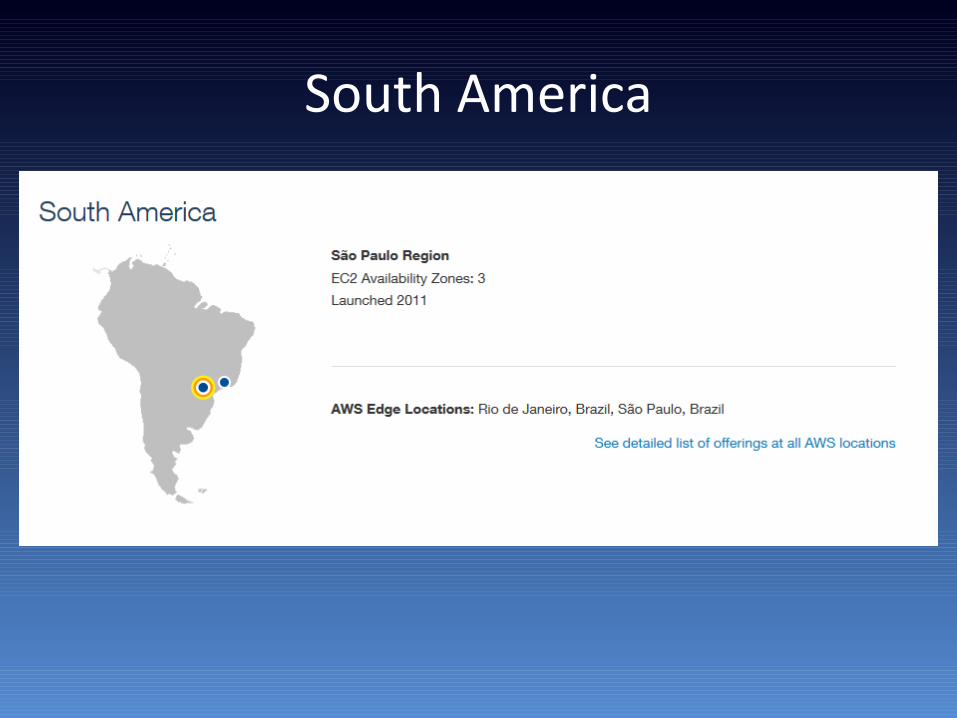
South America

EMEA

Asia Pacific

Availability ZoneA data center build for the cloud
• Each region is further divided into Zones called Availability Zones (AZs)
• To make AWS more fault-tolerant, Amazon engineered Availability Zones that are designed to be insulated from failures in other availability zones.– Separate Power Sources– Separate Switches– Separate storage – Separate physical infrastructure
• AWS SLA gurantee of 99.95 for cross AZ

EC2
• Various instance sizes and types– From 1 core/1gb to 40Core/244gb
• Easily change instance size (ECU/Memory) with web console or AWS APIs• Easily backup and restore images (called
AMIs)
– `

EC2..
• Provisioned IOPS – tailor storage performance to your need
• Only storage charges apply for shutdown instances– $0.05 per GB per month– So 120gb stand by instance will cost only $6 a month.
• All web console task have equivalent APIs• Auto Recovery

AWS pricing model
• On-Demand– pay for compute capacity by the hour with no long-term
commitments.
• Reserved instance– option to make a low, one-time payment for each instance
you want to reserve and in turn receive a significant discount on the hourly charge for that instance.

RDS• Amazons database as a service for Oracle
and SQL Server.• Automatic Backups for user define
period• Point in time recovery• Provisioned IOPS currently up to 30000
IOPS for extreme IO performance• Multi – AZ option• BYOL/Pay as you go for Oracle and MS
SQL

VPCVirtual Private Cloud
• A virtual private cloud (VPC) is a virtual network dedicated to your AWS account. It is logically isolated from other virtual networks in the AWS cloud.
• Three connectivity options between customers data center and AWS’s data center– Software Encryption– Hardware Encryption– Direct connect establishes private connectivity between
AWS and your datacenter, office, or collocation environment.

SubnetsBorder Gateway Protocol
• A subnet is a range of IP addresses in your VPC• These address are unique private IP addresses
across customers data center• Users need not know the addresses are AWS
or no• Instances on AWS can be attached to
customers domain

Siebel Architecture on AWSEnabling Siebel on the cloud
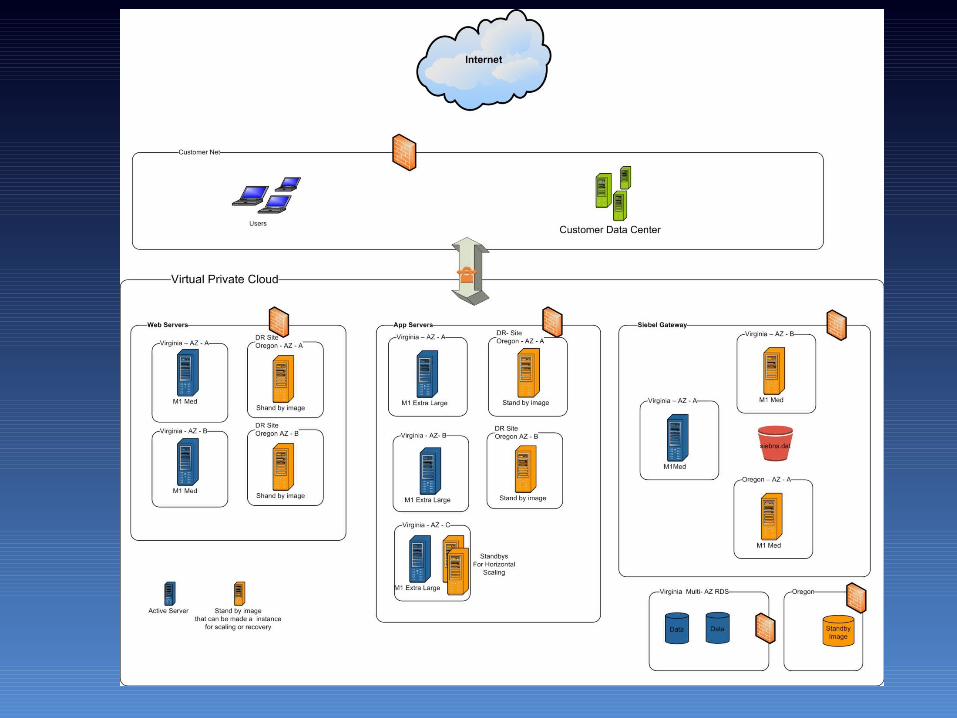

Solution Overview
• Customers network can be connected by• IPSec/VPN or Hardware/VPN or Direct Connect
• All instances will only be accessible from customers network only and part of customers domain
• Each application tier will be placed across multiple AZs• Standby images will be created for Disaster recovery in a
Alternate Zones/ Regions• A Elastic Load balancer, Elastic IP and Route 53 will be used to
make failure over transparent to end users.
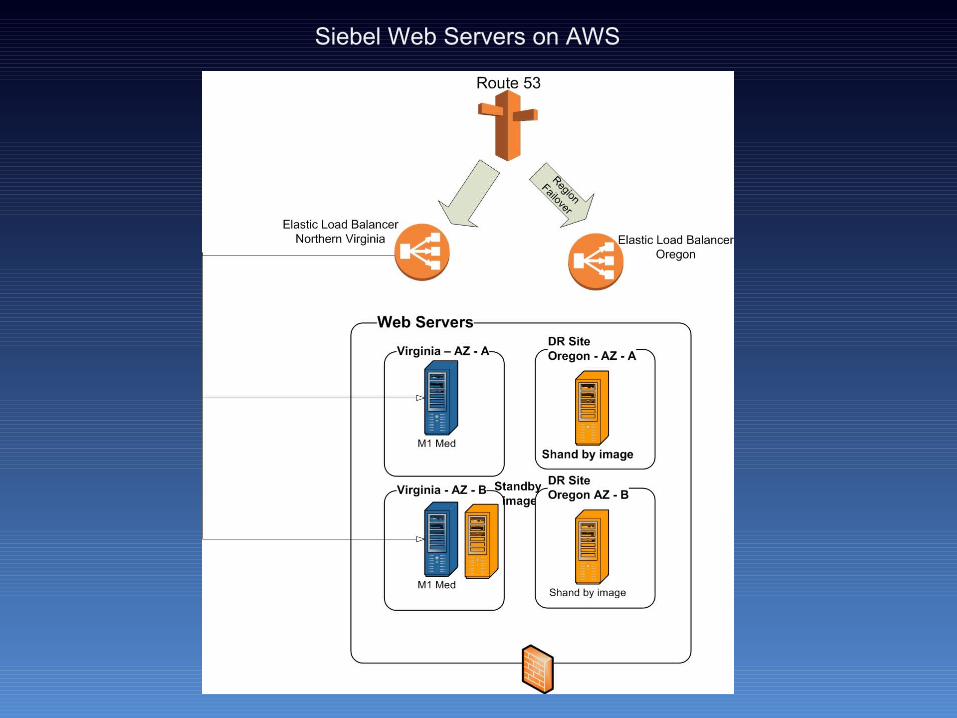
Siebel Web Servers on AWS
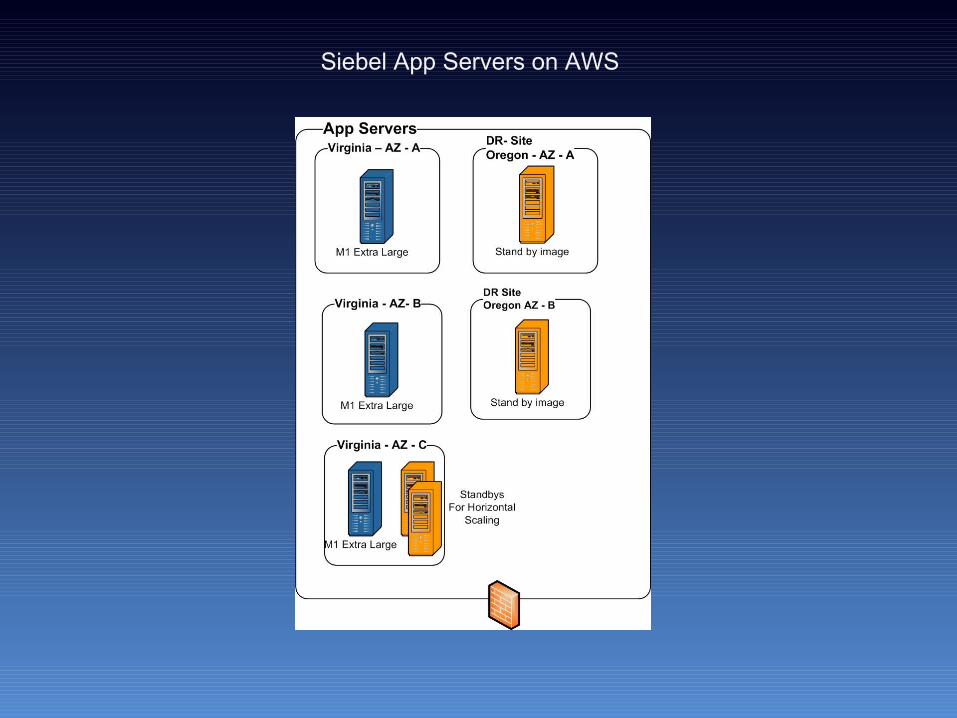
Siebel App Servers on AWS
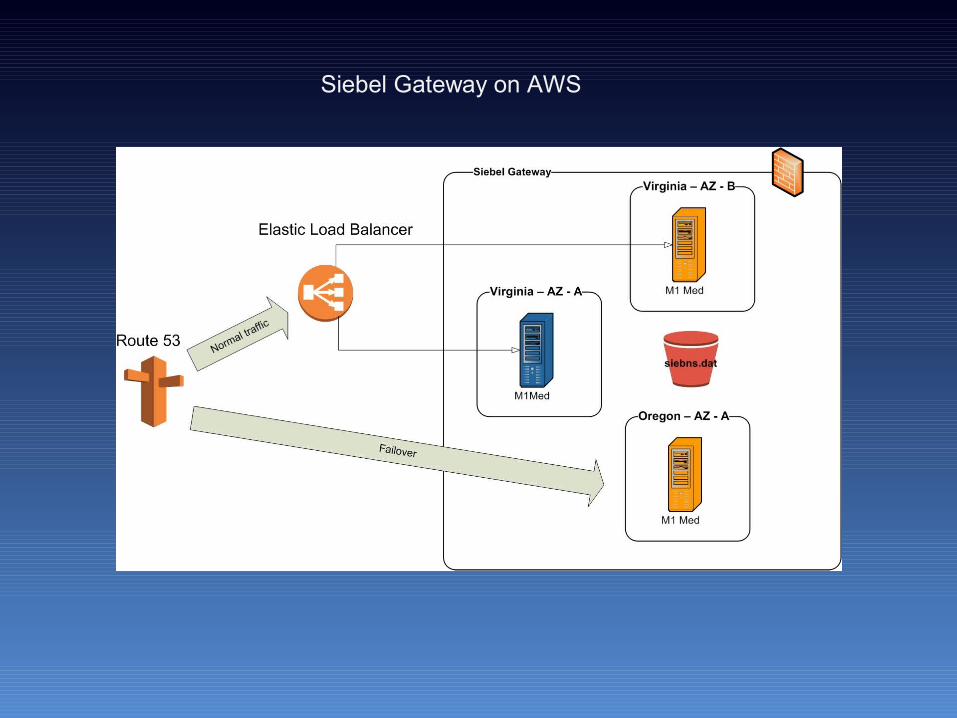
Siebel Gateway on AWS

Database on AWS
• In the region closet to the customer site deploy a Multi-AZ RDS instance
• In a secondary region have a stand by– Will require Golden gate or other means
• Failover to the stand by using Route 53

Unbeatable combination.Win! Win!
• Open UI (Mobile First)– Mobility
• Innovation Packs (No Major Upgrades)– Pick and Pace your upgrades
• AWS (Cloud First)– On Demand, HA, unlimited scalability , Low Op Ex
and TCO
• Enterprise Beacon – Outcome Management

Demos

Paradigm ShiftNo more hardware!
• Customers need to get out of the old paradigm– Cloud is not just Physical to Virtual– Take advantage of underlying HA – Replicate full stack when needed– Fine tune instance types – Auto scale – Automatic Backups

AWS Support
• Subject to AWS approval– 50% discount for POC for customers– $25,000 credit for 1st year of operation for 1st
reference able customer

Enterprise Beacon Roadmap
• Migrate non prod environments < 1 week• Migrate prod environments – Define architecture based on expected SLA – Build Infrastructure – Performance test and tune infrastructure– Help redefine ops process– Cut Over– Operations support

Next Steps?

Appendix
• Web Server failure scenarios• App Server failure scenarios• Gateway failure scenarios• Database failure scenarios

Scenario Solution Impact
Web Server Fails Auto recovery Slow Performance while stand by instances are added
AZ failure ELB Managed. Launch Additional Instances on available AZ
Slow Performance while stand by instances are added
Region Failure* i.e failure of all AZs in a region which is extremely low possibility
DNS Failover. Startup web servers on the secondary region.Switch Route 53 entry for Web Server to point to ELB in Secondary Region.
System will be unavailable while instances in stand by region come online•Impact can reduced if instances in secondary region are kept online
High Load/Low Load Based on concurrent users, CPU and Memory additional standby instances can be turned on or existing
Improved performance and TCO as infrastructure scales to according to demand
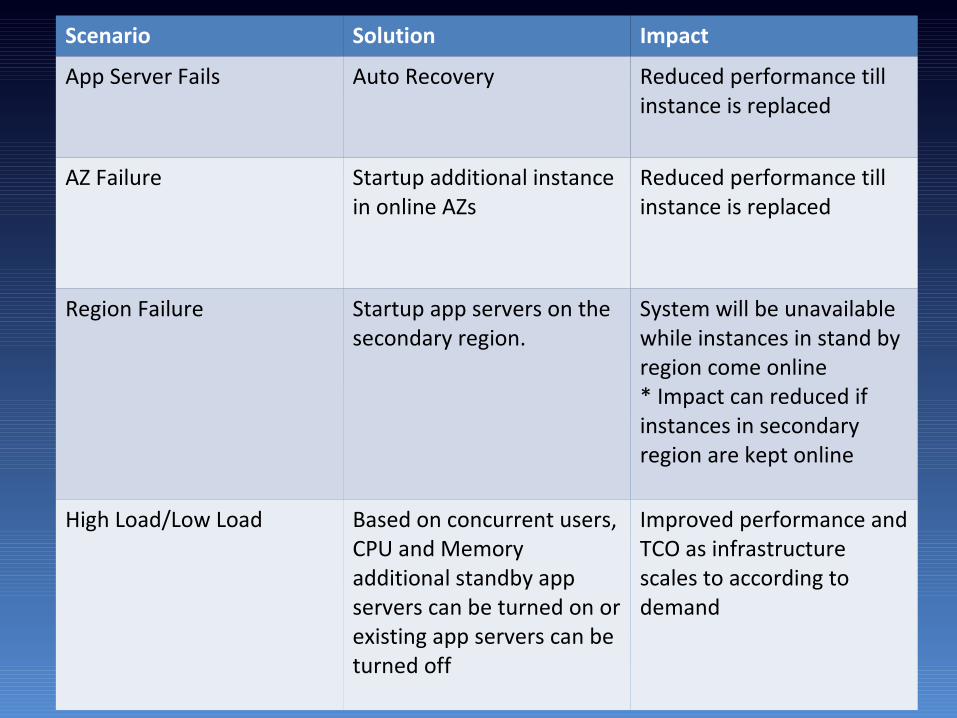
Scenario Solution Impact
App Server Fails Auto Recovery Reduced performance till instance is replaced
AZ Failure Startup additional instance in online AZs
Reduced performance till instance is replaced
Region Failure Startup app servers on the secondary region.
System will be unavailable while instances in stand by region come online* Impact can reduced if instances in secondary region are kept online
High Load/Low Load Based on concurrent users, CPU and Memory additional standby app servers can be turned on or existing app servers can be turned off
Improved performance and TCO as infrastructure scales to according to demand
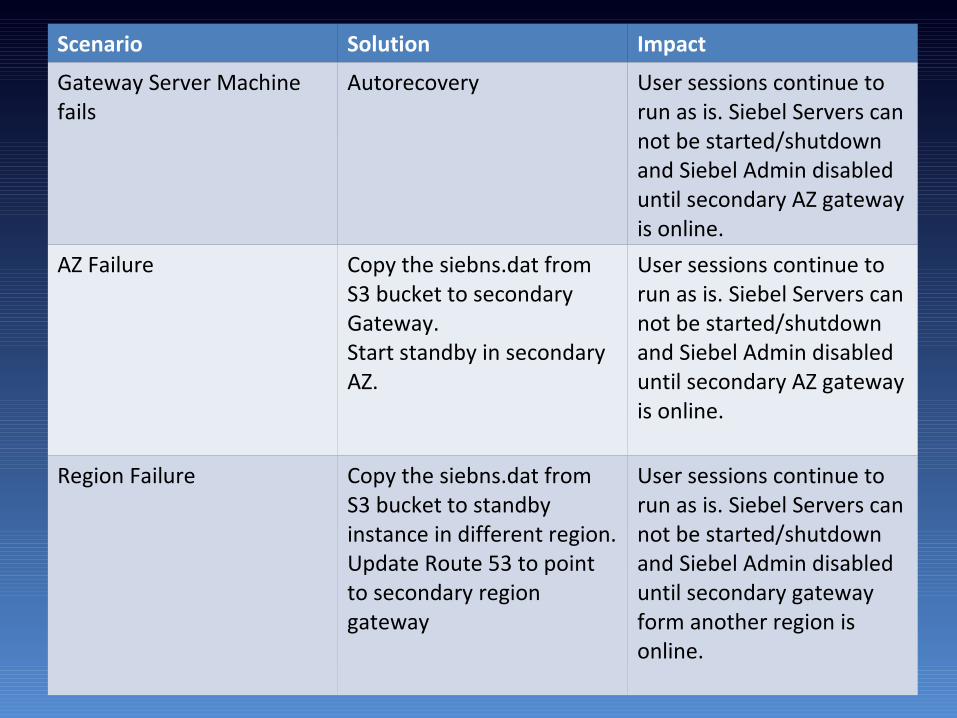
Scenario Solution Impact
Gateway Server Machine fails
Autorecovery User sessions continue to run as is. Siebel Servers can not be started/shutdown and Siebel Admin disabled until secondary AZ gateway is online.
AZ Failure Copy the siebns.dat from S3 bucket to secondary Gateway.Start standby in secondary AZ.
User sessions continue to run as is. Siebel Servers can not be started/shutdown and Siebel Admin disabled until secondary AZ gateway is online.
Region Failure Copy the siebns.dat from S3 bucket to standby instance in different region.Update Route 53 to point to secondary region gateway
User sessions continue to run as is. Siebel Servers can not be started/shutdown and Siebel Admin disabled until secondary gateway form another region is online.

Scenario Solution Impact
Active RDS instance fails
RDS fails over to secondary node and that becomes primary
System is down till the secondary node comes online
Region Failure Golden Gate Replication

Thank You