s `ib hhvgp#b2`p #h2gj.sb o@i` +2-gsqt `iglq`k hbx...
TRANSCRIPT

NPFL122, Lecture 11
V-trace, PopArt Normalization,
Partially Observable MDPsMilan Straka
January 7, 2019
Charles University in Prague Faculty of Mathematics and Physics Institute of Formal and Applied Linguistics
unless otherwise stated

IMPALA
Impala (Importance Weighted Actor-Learner Architecture) was suggested in Feb 2018 paperand allows massively distributed implementation of an actor-critic-like learning algorithm.
Compared to A3C-based agents, which communicates gradients with respect to the parametersof the policy, IMPALA actors communicates trajectories to the centralized learner.
Actor Actor
Actor
ActorActor
Actor Learner
ObservationsParameters
Actor
Actor
Observations
Observations
Parameters Gradients
Learner
Worker
Master
LearnerActor
ActorActor
Figure 1 of the paper "IMPALA: Scalable Distributed Deep-RL with Importance WeightedActor-Learner Architectures" by Lasse Espeholt et al.
Environment steps Forward pass Backward pass
Actor 2Actor 3
Actor 1Actor 0
4 time steps
(a) Batched A2C (sync step.)
Actor 2Actor 3
Actor 1Actor 0
4 time steps
(b) Batched A2C (sync traj.)
…
…
Actor 2Actor 3
Actor 1Actor 0
Actor 4Actor 5Actor 6Actor 7
...next unroll
(c) IMPALA
Figure 2 of the paper "IMPALA: Scalable Distributed Deep-RL with Importance WeightedActor-Learner Architectures" by Lasse Espeholt et al.
If many actors are used, the policy used to generate a trajectory can lag behind the latestpolicy. Therefore, a new V-trace off-policy actor-critic algorithm is proposed.
2/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA – V-trace
Consider a trajectory generated by a behaviour policy .
The -step V-trace target for is defined as
where is the temporal difference for V
and and are truncated importance sampling ratios with :
Note that if and assuming , reduces to -step Bellman target.
(S ,A ,R ) t t t+1 t=st=s+n b
n S s
v s =defV (S ) +s γ c δ V ,
t=s
∑s+n−1
t−s (∏i=s
t−1i) t
δ Vt
δ Vt =def
ρ (R +t t+1 γV (s ) −t+1 V (s )),t
ρ t c i ≥ρ̄ c̄
ρ t =def min , , c (ρ̄b(A ∣S )t t
π(A ∣S )t t ) i =def min , .(c̄b(A ∣S )i i
π(A ∣S )i i )
b = π ≥c̄ 1 v s n3/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA – V-trace
Note that the truncated IS weights and play different roles:
The appears in the definition of and defines the fixed point of the update rule. For
, the target is the value function , if , the fixed point is somewhere
between and . Notice that we do not compute a product of these coefficients.
The impacts the speed of convergence (the contraction rate of the Bellman operator),
not the sought policy. Because a product of the ratios is computed, it plays an important
role in variance reduction.
The paper utilizes and out of , works empirically the best.
ρ t c i
ρ t δ Vt =ρ̄ ∞ v π <ρ̄ ∞
v π v b ρ t
c i
c i
=c̄ 1 ∈ρ̄ {1, 10, 100} =ρ̄ 1
4/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA – V-trace
Consider a parametrized functions computing and . Assuming the defined -
step V-trace target
we update the critic in the direction of
and the actor in the direction of the policy gradient
Finally, we again add the entropy regularization term to the loss function.
v(s; θ) π(a∣s;ω) n
v s =defV (S ) +s γ c δ V ,
t=s
∑s+n−1
t−s (∏i=s
t−1i) t
(v −s v(S ; θ))∇ v(S ; θ)s θ s
ρ ∇ log π(A ∣S ;ω)(R +s ω s s s+1 γv −s+1 v(S ; θ)).s
H(π(⋅∣S ; θ))s
5/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA
Architecture CPUs GPUs1 FPS2
Single-Machine Task 1 Task 2
A3C 32 workers 64 0 6.5K 9KBatched A2C (sync step) 48 0 9K 5KBatched A2C (sync step) 48 1 13K 5.5KBatched A2C (sync traj.) 48 0 16K 17.5KBatched A2C (dyn. batch) 48 1 16K 13KIMPALA 48 actors 48 0 17K 20.5KIMPALA (dyn. batch) 48 actors3 48 1 21K 24K
Distributed
A3C 200 0 46K 50KIMPALA 150 1 80KIMPALA (optimised) 375 1 200KIMPALA (optimised) batch 128 500 1 250K
1 Nvidia P100 2 In frames/sec (4 times the agent steps due to action repeat). 3 Limited by
amount of rendering possible on a single machine.
Table 1 of the paper "IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures" by Lasse Espeholt et al.
6/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA – Population Based Training
For Atari experiments, population based training with a population of 24 agents is used toadapt entropy regularization, learning rate, RMSProp and the global gradient norm clipping
threshold.
exploit
explore
(a) Sequential Optimisation
(b) Parallel Random/Grid Search (c) Population Based Training
Hyperparameters
Weights
Performance
Training
Hyperparameters
Weights
Performance
Figure 1 of paper "Population Based Training of Neural Networks" by Max Jaderberg et al.
ε
7/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA – Population Based Training
For Atari experiments, population based training with a population of 24 agents is used toadapt entropy regularization, learning rate, RMSProp and the global gradient norm clipping
threshold.
In population based training, several agents are trained in parallel. When an agent is ready(after 5000 episodes), then:
it may be overwritten by parameters and hyperparameters of another agent, if it issufficiently better (5000 episode mean capped human normalized score returns are 5%better);and independently, the hyperparameters may undergo a change (multiplied by either 1.2 or1/1.2 with 33% chance).
ε
8/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA
IMPALA - 1 GPU - 200 actors Batched A2C - Single Machine - 32 workers A3C - Single Machine - 32 workers A3C - Distributed - 200 workers
0.0 0.2 0.4 0.6 0.8 1.0
Environment Frames 1e9
10
15
20
25
30
35
40
45
50
55
Return
rooms_watermaze
0.0 0.2 0.4 0.6 0.8 1.0
Environment Frames 1e9
0
5
10
15
20
25
30
rooms_keys_doors_puzzle
0.0 0.2 0.4 0.6 0.8 1.0
Environment Frames 1e9
−5
0
5
10
15
20
25
30
35
lasertag_three_opponents_small
0.0 0.2 0.4 0.6 0.8 1.0
Environment Frames 1e9
0
50
100
150
200
250
explore_goal_locations_small
0.0 0.2 0.4 0.6 0.8 1.0
Environment Frames 1e9
5
10
15
20
25
30
35
40
45
seekavoid_arena_01
1 5 9 13 17 21 24
Hyperparameter Combination
0
10
20
30
40
50
60
FinalReturn
rooms_watermaze
1 5 9 13 17 21 24
Hyperparameter Combination
0
5
10
15
20
25
30
35
40
rooms_keys_doors_puzzle
1 5 9 13 17 21 24
Hyperparameter Combination
−5
0
5
10
15
20
25
30
35
40
lasertag_three_opponents_small
1 5 9 13 17 21 24
Hyperparameter Combination
0
50
100
150
200
250
300
explore_goal_locations_small
1 5 9 13 17 21 24
Hyperparameter Combination
0
10
20
30
40
50
seekavoid_arena_01
Figure 4 of the paper "IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures" by Lasse Espeholt et al.
9/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA – Learning Curves
Figures 5, 6 of the paper "IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures" by Lasse Espeholt et al.
10/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA – Atari Games
Table 4 of the paper "IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures" by Lasse Espeholt et al.
11/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA – Ablations
Task 1 Task 2 Task 3 Task 4 Task 5
Without Replay
V-trace 46.8 32.9 31.3 229.2 43.81-Step 51.8 35.9 25.4 215.8 43.7ε-correction 44.2 27.3 4.3 107.7 41.5No-correction 40.3 29.1 5.0 94.9 16.1
With Replay
V-trace 47.1 35.8 34.5 250.8 46.91-Step 54.7 34.4 26.4 204.8 41.6ε-correction 30.4 30.2 3.9 101.5 37.6No-correction 35.0 21.1 2.8 85.0 11.2
Tasks: rooms watermaze, rooms keys doors puzzle,
lasertag three opponents small,
explore goal locations small, seekavoid arena 01
Table 2 of the paper "IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures" by Lasse Espeholt et al.
12/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

IMPALA – Ablations
Figure E.1 of the paper "IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures" by Lasse Espeholt et al.
13/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

PopArt Normalization
An improvement of IMPALA from Sep 2018, which performs normalization of task rewardsinstead of just reward clipping. PopArt stands for Preserving Outputs Precisely, while AdaptivelyRescaling Targets.
Assume the value estimate is computed using a normalized value predictor
and further assume that is an output of a linear function
We can update the and using exponentially moving average with decay rate (in the
paper, first moment and second moment is tracked, and standard deviation is computed as
; decay rate is employed).
v(s; θ,σ,μ) n(s; θ)
v(s; θ,σ,μ) =defσn(s; θ) + μ
n(s; θ)
n(s; θ) =defω f(s; θ −T {ω, b}) + b.
σ μ β
μ υ
σ = υ − μ2 β = 3 ⋅ 10−4
14/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

PopArt Normalization
Utilizing the parameters and , we can normalize the observed (unnormalized) returns as
and use an actor-critic algorithm with advantage .
However, in order to make sure the value function estimate does not change when thenormalization parameters change, the parameters computing the unnormalized value
estimate are updated under any change and as:
In multi-task settings, we train a task-agnostic policy and task-specific value functions(therefore, , and are vectors).
μ σ
(G − μ)/σ (G − μ)/σ − n(S; θ)
ω, bμ → μ′ σ → σ′
ω′ =def ω, b
σ′
σ ′ =def .
σ′
σb + μ − μ′
μ σ n(s; θ)
15/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

PopArt Results
Atari-57 Atari-57 (unclipped) DmLab-30
Agent Random Human Random Human Train Test
IMPALA 59.7% 28.5% 0.3% 1.0% 60.6% 58.4%
PopArt-IMPALA 110.7% 101.5% 107.0% 93.7% 73.5% 72.8%
Table 1 of paper "Multi-task Deep Reinforcement Learning with PopArt" by Matteo Hessel et al.
0 2 4 6 8 10 12
Environment Frames 1e9
0
20
40
60
80
100
120
MedianHumanNormalisedScore
Atari-57 (clipped)
PopArt-IMPALA
MultiHead-IMPALA
IMPALA
0 2 4 6 8 10 12
Environment Frames 1e9
−20
0
20
40
60
80
100
120
MedianHumanNormalisedScore
Atari-57 (unclipped)
PopArt-IMPALA
MultiHead-IMPALA
IMPALA
Figures 1, 2 of paper "Multi-task Deep Reinforcement Learning with PopArt" by Matteo Hessel et al.
16/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

PopArt Results
breakout crazy_climber qbert seaquest
UndiscountedReturn
[μ-σ,μ+σ]
Environment Frames Environment Frames Environment Frames Environment Frames
Figure 3 of paper "Multi-task Deep Reinforcement Learning with PopArt" by Matteo Hessel et al.
17/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

PopArt Results
0 2 4 6 8 10
Environment Frames 1e9
0
10
20
30
40
50
60
70
80
MeanCappedHumanNormalisedScore
DmLab-30
PopArt-IMPALA
IMPALA
IMPALA-original
0 2 4 6 8 10
Environment Frames 1e9
0
10
20
30
40
50
60
70
80
MeanCappedHumanNormalisedScore
0.1
IMPALA-original@10B
IMPALA@10B
PopArt-IMPALA@10B
DmLab-30
PopArt-IMPALA
Pixel-PopArt-IMPALA
Figures 4, 5 of paper "Multi-task Deep Reinforcement Learning with PopArt" by Matteo Hessel et al.
18/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

Partially Observable MDPs
Recall that a Markov decision process (MDP) is a quadruple , where:
is a set of states,
is a set of actions,
is a probability that action will lead from
state to , producing a reward ,
is a discount factor.
Partially observable Markov decision process extends the Markov decision process to a sextuple
, where in addition to an MDP
is a set of observations,
is an observation model.
In robotics (out of the domain of this course), several approaches are used to handle POMDPs,to model uncertainty, imprecise mechanisms and inaccurate sensors.
(S,A, p, γ)
SAp(S =t+1 s ,R =′
t+1 r∣S =t s,A =t a) a ∈ A
s ∈ S s ∈′ S r ∈ Rγ ∈ [0, 1]
(S,A, p, γ,O, o)
Oo(O ∣S ,A )t t t−1
19/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

Partially Observable MDPs
In Deep RL, partially observable MDPs are usually handled using recurrent networks. Aftersuitable encoding of input observation and previous action , a RNN (usually LSTM)
unit is used to model the current (or its suitable latent representation), which is in turn
utilized to produce .
Figure 1a of paper "Unsupervised Predictive Memory in a Goal-Directed Agent" by Greg Wayne et al.
O t A t−1
S t
A t
20/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

MERLIN
However, keeping all information in the RNN state is substantially limiting. Therefore, memory-augmented networks can be used to store suitable information in external memory (in the linesof NTM, DNC or MANN models).
We now describe an approach used by Merlin architecture (Unsupervised Predictive Memory ina Goal-Directed Agent DeepMind Mar 2018 paper).
Figure 1b of paper "Unsupervised Predictive Memory in a Goal-Directed Agent" by Greg Wayne et al.
21/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

MERLIN – Memory Module
Figure 1b of paper "Unsupervised Predictive Memory in aGoal-Directed Agent" by Greg Wayne et al.
Let be a memory matrix of size .
Assume we have already encoded observations as and previous
action . We concatenate them with previously read vectors
and process by a deep LSTM (two layers are used in the paper) tocompute .
Then, we apply a linear layer to , computing key vectors
of length and positive scalars .
Reading: For each , we compute cosine similarity of and all memory rows , multiply the
similarities by and pass them through a to obtain weights . The read vector is
then computed as .
Writing: We find one-hot write index to be the least used memory row (we keep usage
indicators and add read weights to them). We then compute , and
update the memory matrix using .
M N ×mem 2∣z∣
e t
a t−1 K
h t
h t K
k , …k 1 K 2∣z∣ K β , … , β 1 K
i k i M j
β i softmax ω i
Mw i
v wr
v ←ret γv +ret (1 − γ)v wr
M ← M + v [e , 0] +wr t v [0, e ]ret t
22/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

MERLIN — Prior and Posterior
However, updating the encoder and memory content purely using RL is inefficient. Therfore,MERLIN includes a memory-based predictor (MBP) in addition to policy. The goal of MBP isto compress observations into low-dimensional state representations and storing them in
memory.
According to the paper, the idea of unsupervised and predictive modeling has been entertainedfor decades, and recent discussions have proposed such modeling to be connected tohippocampal memory.
We want the state variables not only to faithfully represent the data, but also emphasiserewarding elements of the environment above irrelevant ones. To accomplish this, the authorsfollow the hippocampal representation theory of Gluck and Myers, who proposed thathippocampal representations pass through a compressive bottleneck and then reconstruct inputstimuli together with task reward.
In MERLIN, a prior distribution over predicts next state variable conditioned on history of
state variables and actions , and posterior corrects the prior using
the new observation , forming a better estimate .
z
z t
p(z ∣z , a , … , z , a )t t−1 t−1 1 1
o t q(z ∣o , z , a , … , z , a )t t t−1 t−1 1 1
23/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

MERLIN — Prior and Posterior
To achieve the mentioned goals, we add two terms to the loss.
We try reconstructing input stimuli, action, reward and return using a sample from the statevariable posterior, and add the difference of the reconstruction and ground truth to the loss.
We also add KL divergence of the prior and posterior to the loss, to ensure consistencybetween the prior and posterior.
Figure 1c of paper "Unsupervised Predictive Memory in a Goal-Directed Agent" by Greg Wayne et al.
24/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

MERLIN — AlgorithmAlgorithm 1 MERLIN Worker Pseudocode
// Assume global shared parameter vectors θ for the policy network and χ for the memory-
based predictor; global shared counter T := 0// Assume thread-specific parameter vectors θ′, χ′
// Assume discount factor γ ∈ (0, 1] and bootstrapping parameter λ ∈ [0, 1]Initialize thread step counter t := 1repeat
Synchronize thread-specific parameters θ′ := θ;χ′ := χ
Zero model’s memory & recurrent state if new episode begins
tstart := t
repeat
Prior N (µpt , log Σ
pt ) = p(ht−1,mt−1)
et = enc(ot)Posterior N (µq
t , log Σqt ) = q(et, ht−1,mt−1, µ
pt , log Σ
pt )
Sample zt ∼ N (µqt , log Σ
qt )
Policy network update h̃t = rec(h̃t−1, m̃t, StopGradient(zt))Policy distribution πt = π(h̃t, StopGradient(zt))Sample at ∼ πt
ht = rec(ht−1,mt, zt)Update memory with zt by Methods Eq. 2
Rt, ort = dec(zt, πt, at)
Apply at to environment and receive reward rt and observation ot+1t := t+ 1;T := T + 1
until environment termination or t− tstart == τwindow
If not terminated, run additional step to compute V πν (zt+1, log πt+1)
and set Rt+1 := V π(zt+1, log πt+1) // (but don’t increment counters)
Reset performance accumulators A := 0;L := 0;H := 0for k from t down to tstart do
γt :=
{
0, if k is environment termination
γ, otherwise
Rk := rk + γtRk+1
δk := rk + γtVπ(zk+1, log πk+1)− V π(zk, log πk)
Ak := δk + (γλ)Ak+1
L := L+ Lk (Eq. 7)
A := A+ Ak log πk[ak]H := H− αentropy
∑
i πk[i] log πk[i] (Entropy loss)
end for
dχ′ := ∇χ′L
dθ′ := ∇θ′(A+H)Asynchronously update via gradient ascent θ using dθ′ and χ using dχ′
until T > Tmax
Algorithm 1 of paper "Unsupervised Predictive Memory in a Goal-Directed Agent" by Greg Wayne et al.
25/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

MERLIN
Figure 2 of paper "Unsupervised Predictive Memory in a Goal-Directed Agent" by Greg Wayne et al.
26/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW
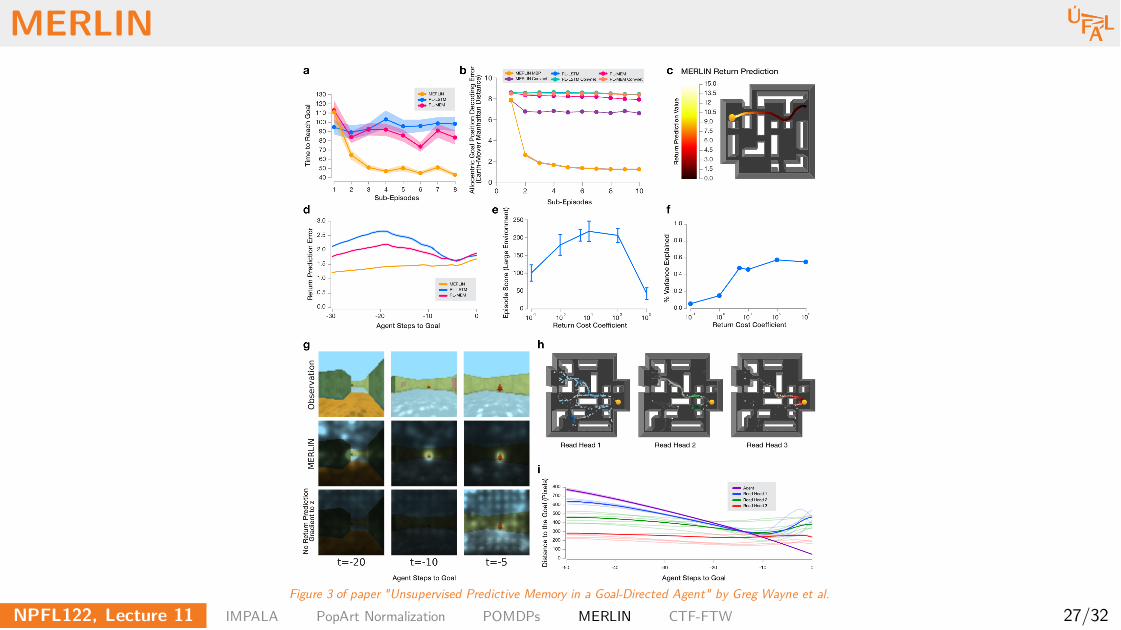
MERLIN
Figure 3 of paper "Unsupervised Predictive Memory in a Goal-Directed Agent" by Greg Wayne et al.
27/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

MERLIN
Extended Figure 3 of paper "Unsupervised Predictive Memory in a Goal-Directed Agent" by Greg Wayne et al.
28/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

For the Win agent for Capture The Flag
Agent Elo
Internal Timescale
KL Weighting
Learning Rate
FTW
Strong Human
Average Human
Self-play + RS
(a) FTW Agent Architecture (b) Progression During Training
Self-play
Random agent
…
? t
at
Sampled
latent
variable
rtw
Game points ?t
Internal
reward
Act ion
Slow RNN
Fast RNN
Winning
signal
Pt
Qt Qt+1
Policy
Observation xt
Figure 2 of paper "Human-level performance in first-person multiplayer games with population-based deep reinforcement learning" by Max Jaderber et al.
29/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

For the Win agent for Capture The Flag
Extension of the MERLIN architecture.
Hierarchical RNN with two timescales.
Population based training controlling KL divergence penalty weights, slow ticking RNNspeed and gradient flow factor from fast to slow RNN.
30/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

For the Win agent for Capture The Flag
Figure S10 of paper "Human-level performance in first-person multiplayer games with population-based deep reinforcement learning" by Max Jaderber et al.
31/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW

For the Win agent for Capture The Flag
0K 10K 30K 350K 350K 450K
Behaviour
Probability
Teammate Following
Opponent Base Camping
Home Base Defence
Agent
Strength
Opponent Captured Flag
Agent Picked up Flag
Agent Tagged Opponent
Beating
Average
Human
Beating
Weak
Bots
Relative
Internal Reward
Magnitude
Knowledge
0%
25%
50%
75%
100%
450K300K200K45K7K4K2K
450K300K200K45K7K4K2K
Phase 1 Learning the basics of the game Phase 2 Increasing navigation, tagging, and coordination skills Phase 3 Perfecting strategy and memory
“I have the flag”
“I am respawning”“My flag is taken”
“Teammate has the flag”Single Neuron
Response
Visitation Map Top Memory Read Locations Visitation Map Top Memory Read Locations Visitation Map Top Memory Read Locations
Games Played
Memory
Usage
Beating Strong Humans
Figure 4 of paper "Human-level performance in first-person multiplayer games with population-based deep reinforcement learning" by Max Jaderber et al.
32/32NPFL122, Lecture 11 IMPALA PopArt Normalization POMDPs MERLIN CTF-FTW