salon big data paris 2017 - palais des congrès · (netflix metacat) producteur de la donné hive...
TRANSCRIPT

Data Lake : une approche alternativeSalon Big Data Paris 2017Mélanie LANGLOIS - Directeur département Innovation SI

Data Lake : une approche alternative
Notre rêve …
09/03/2017Salon Big Data Paris 2017 - Médiamétrie
Data Scientists
… accès « no limit » à la data !!!
Data Lake : une approche alternative
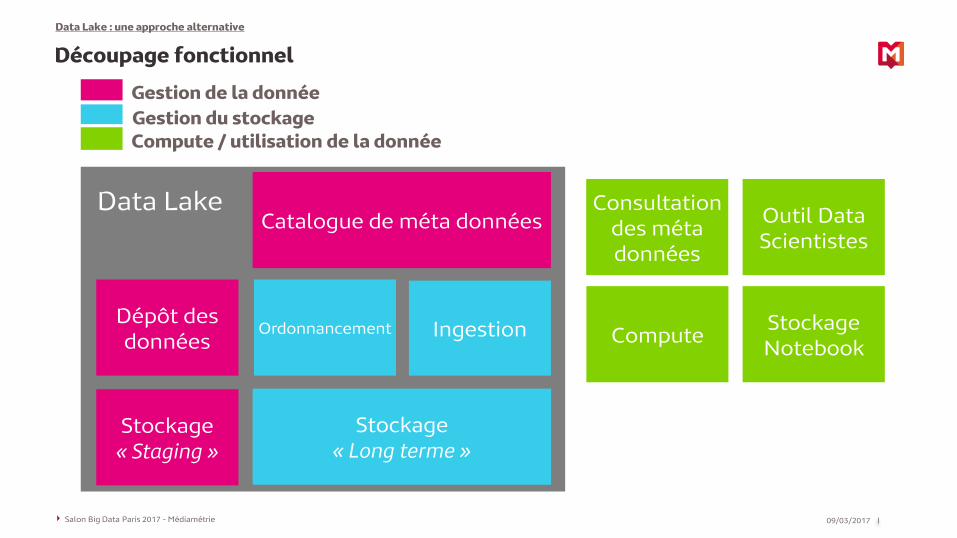
Découpage fonctionnel
09/03/2017Salon Big Data Paris 2017 - Médiamétrie
Compute / utilisation de la donnée
Gestion de la donnée
Gestion du stockage
Dépôt des données
Ingestion
Catalogue de méta données
Stockage« Staging »
Stockage« Long terme »
Consultation des méta données
ComputeStockage Notebook
Outil Data Scientistes
Ordonnancement
Data Lake

Data Lake : une approche alternative
Dépôt de données dans le Data Lake
09/03/2017Salon Big Data Paris 2017 - Médiamétrie
1. Avoir un schéma technique dès le début réduit la charge cognitive
2. Enrichir le schéma de métadonnées aide à comprendre la donnée et son contexte plus rapidement
3. Le producteur de la donnée est le plus à même de savoir ce qu'il y a dedans
4. Une donnée propre dès le début est obligatoire car la qualité ne doit pas être polluée par une représentation technique non conforme
Dépôt des données
Ingestion
Catalogue de méta données
Stockage« Staging »
Stockage« Long terme »
Consultation des méta données
ComputeStockage Notebook
Outil Data Scientistes
Ordonnancement
Data Lake
Schema on-write+Service de méta-data
Data Lake : une approche alternative
09/03/2017Salon Big Data Paris 2017 - Médiamétrie
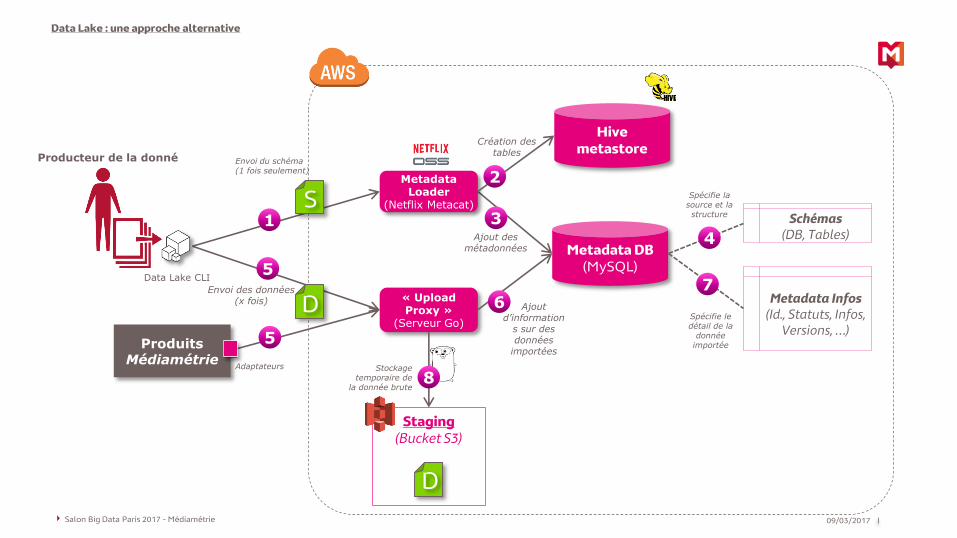
Staging(Bucket S3)
« UploadProxy »
(Serveur Go)
Metadata DB(MySQL)
Schémas(DB, Tables)
Metadata Infos(Id., Statuts, Infos,
Versions, …)Produits
Médiamétrie
S
D
D
1 3
4
67
Data Lake CLI
Envoi du schéma(1 fois seulement)
Envoi des données(x fois)
5
Spécifie la source et la structure
Ajout d’information
s sur des données
importées
Spécifie le détail de la
donnée importée
Stockage temporaire de
la donnée brute
Adaptateurs
MetadataLoader
(Netflix Metacat)
Producteur de la donné
Hivemetastore
8
5
Création des tables
2
Ajout des métadonnées
Data Lake : une approche alternative
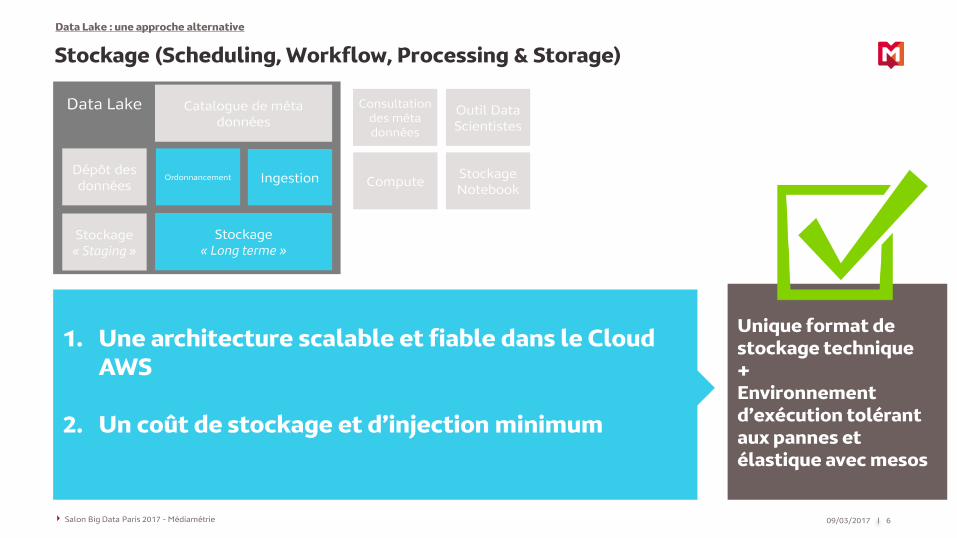
Stockage (Scheduling, Workflow, Processing & Storage)
09/03/2017 6Salon Big Data Paris 2017 - Médiamétrie
Dépôt des données
Ingestion
Catalogue de méta données
Stockage« Staging »
Stockage« Long terme »
Consultation des méta données
ComputeStockage Notebook
Outil Data Scientistes
Ordonnancement
Data Lake
Unique format de stockage technique+Environnement d’exécution tolérant aux pannes et élastique avec mesos
1. Une architecture scalable et fiable dans le Cloud AWS
2. Un coût de stockage et d’injection minimum

Data Lake : une approche alternative
Stockage (Scheduling, Workflow, Processing & Storage)
MetadataDB
(MySQL)
Metadata Infos(Id., Statuts, Infos,
Versions,…)
Chronos(Job Scheduler for
Mesos)
Workflow Luigi(Python Workflow
Manager)
Eremetic(Task Queue
Mesos)
Staging(Bucket S3)
D
Container Docker(Mesos)
Luigi Agent« ETL Exec »
ETL MinionsScala/Spark
9
11
12
13
14
15
Data Lake(Bucket S3)
16
19
16
Toutes les 1 minutes, Chronos vérifie si de nouvelles données
sont en attentes d’import (statut: « uploaded »)
Si des fichiers sont dans un état « uploaded », alors Chronos déclenche le lancement du
traitement d’intégration (Luigi)
Récupère des informations sur les nouveaux fichiers Pour chaque nouveau fichier,
Luigid crée une tâche dans Eremetic
Création d’une tâche « Mesos » sous la forme d’un container
Docker
Récupère les métadonnées nécessaire au traitement
Récupère les données brutes
18
Transforme les données pour les mettre dans un format de
stockage long terme
Entrepose les données dans le Bucket S3 « Stockage long
terme » du Data Lake
Mise à jour des infos et statut de la donnée importée
D
Autoscaller(Gestionnaire de
ressources en Python)
Monitore la queue Eremetic et gère les instances de ressources
en fonction des besoins
10

Data Lake : une approche alternative
Stockage (Scheduling, Workflow, Processing & Storage)
09/03/2017 8Salon Big Data Paris 2017 - Médiamétrie
Dépôt des données
Ingestion
Catalogue de méta données
Stockage« Staging »
Stockage« Long terme »
Consultation des méta données
ComputeStockage Notebook
Outil Data Scientistes
Ordonnancement
Data Lake
Hive/Metacat pour accéder aux méta-données de localisation de la data dans S3
Le/la Data Scientiste doit pouvoir utiliser les bons outils, c.-à-d. les siens !

Data Lake : une approche alternative
Cas d’usage du Data Lake
09/03/2017Salon Big Data Paris 2017 - Médiamétrie
HiveMetastore
Data Lake(Bucket S3)
D
Serveur de calculs
(EMR)
Serveur de calculs(EMR)
Demande de la localisation des données choisies
Retour des métadatade localisation
Accès segment Data Lake
Récupération des données
1
Instancie un environnement de calculs dans AWS
3
4
Base SQL Analytique
(Redshift)
«Client SQL »
5
Metadata DB(MySQL)
Schémas(DB, Tables)
MetadataLoader(NetflixMetacat)
Consultation metadataAPI REST
2
Data Scientists
Data Scientists
Data Scientists
Data Scientists

Data Lake : une approche alternative
Stack pour la gestion des ressources
09/03/2017Salon Big Data Paris 2017 - Médiamétrie
HA Proxy
Host x (CentOS 7)
Docker
Mesos Agent
Host 3 (CentOS 7)
Mesos Agent
Host 2 (CentOS 7)
Mesos Agent
Host 1 (CentOS 7)
Netflix exhibitor
Zookeeper
Mesos Master
Mesos Agent
Marathon framework
Chronos framework
Docker
marathon-lb
mesos-dns
getFiles
hive-metastore
metacat
autoscaller
luigid
eremetic
Host x (CentOS 7)
Mesos Agent
Docker
upload-proxy
1
2
3
5
6
7
8
10
11
Pousse des offres 1
3
4
5
6
27
7
1
2
3
4
5
1
1

Data Lake : une approche alternative
Conclusion

Mélanie LANGLOIS - Directeur département Innovation SI
www.mediametrie.frtwitter.com/Mediametrie