sc4 workshop 2 : pieter colpaert - maximizing the reuse of open transport data
TRANSCRIPT

Maximizing the reuse ofOpen Transport Data
Pieter ColpaertGhent University - iMinds/imec

How far do you live from work?

km or min?

Imagine a program calculating distance in minutesWhat data would you need?

Transport has become adata sharing problem
How can we fix it?

Sharing data between 2 systems
Your system Third party systemAgree on a protocol
Will determine which questions can be answered in a timely fashion
Can ask questions to your system as previously agreed

Sharing data on the Web
Your system
?
?
?
?
?
?
Maximizing reuse → need to raise the interoperability

↓Querying
syntactic
semantic
technical
legal
When I have got 2 datasets, how easy is it to use them as if they were 1?

OpenDefinition.org
↓Querying
syntacticsemantic
technicallegal

reuse is allowed
Documents on the webreuse in a gray zone unauthorised reuse
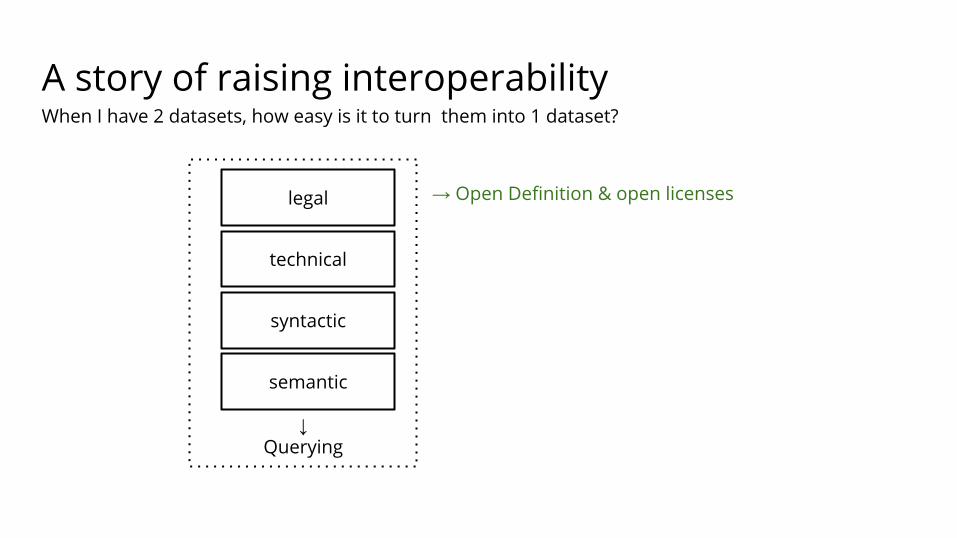
A story of raising interoperability
↓Querying
syntactic
semantic
technical
legal
When I have 2 datasets, how easy is it to turn them into 1 dataset?
→ Open Definition & open licenses
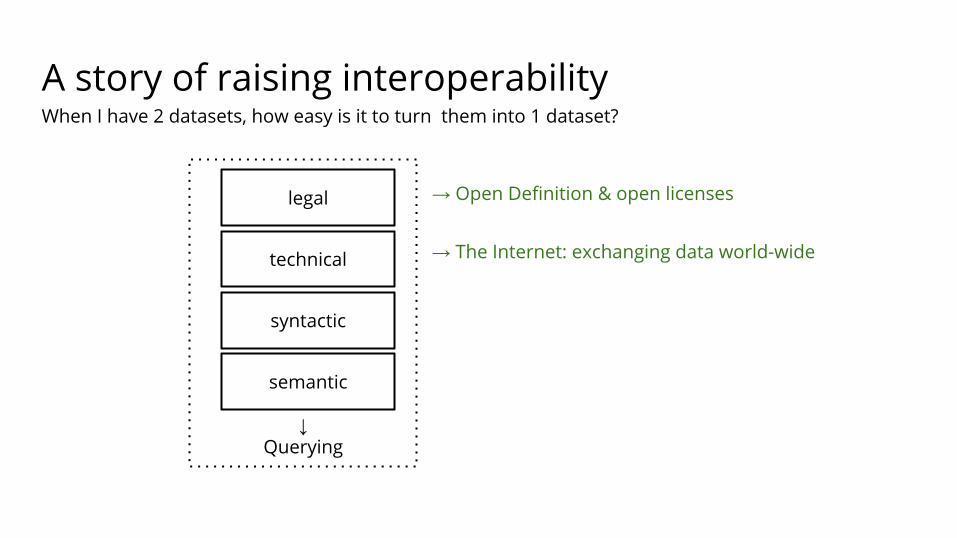
A story of raising interoperability
↓Querying
syntactic
semantic
technical
legal
When I have 2 datasets, how easy is it to turn them into 1 dataset?
→ Open Definition & open licenses
→ The Internet: exchanging data world-wide
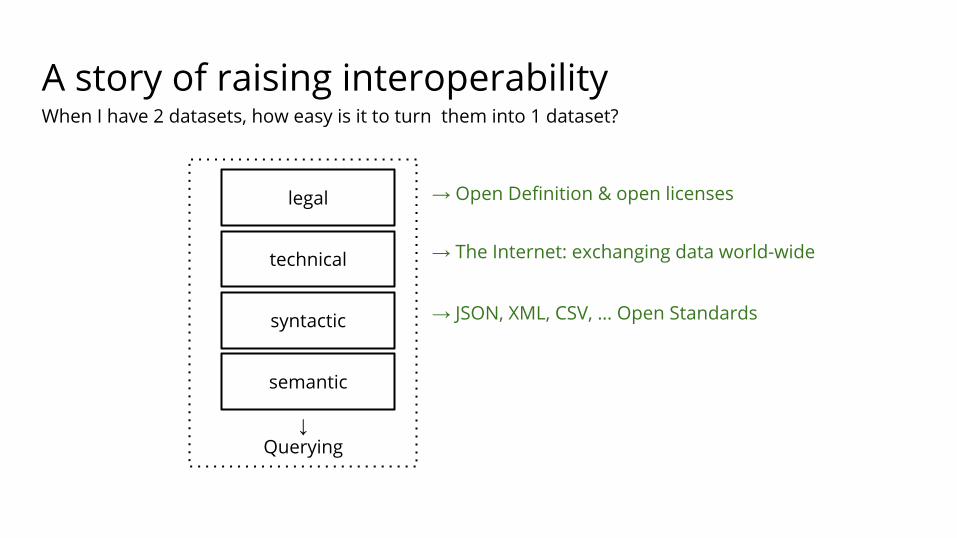
A story of raising interoperability
↓Querying
syntactic
semantic
technical
legal
When I have 2 datasets, how easy is it to turn them into 1 dataset?
→ Open Definition & open licenses
→ The Internet: exchanging data world-wide
→ JSON, XML, CSV, … Open Standards

name type same as location
iMinds company IBBT Gaston Crommenlaan 8
{ “iMinds” : { “type” : “company”, “same as” : “IBBT, “location” : “Gaston Crommenlaan 8” }}
<iMinds> <type>company</type> <sameas>IBBT</sameas> <location> Gaston Crommenlaan 8 </location></iMinds>
Table / CSV / Spreadsheet
JSON XML
Serialisations

name type same as location
iMinds company IBBT Gaston Crommenlaan 8
<iMinds> <type> <company> .<iMinds> <sameas> <IBBT> .<iMinds> <vestiging> “Gaston Crommenlaan 8” .
Table / CSV / Spreadsheet
triples
Triple structure
{ “iMinds” : { “type” : “company”, “same as” : “IBBT, “location” : “Gaston Crommenlaan 8” }}
<iMinds> <type>company</type> <sameas>IBBT</sameas> <location> Gaston Crommenlaan 8 </location></iMinds>
JSON XML

World Wide Web
iMindssame as
IBBT
iMinds is a
company
IBBTlocated at
Gaston Crommenlaan 8
Machine 1 Machine 2 Machine 3
Linked data

Problem
The word company is ambiguous. How can we make sure that machines understand each other?
semantic interoperability
What about “is a”?
and what about “iMinds”?

Solution
iMinds → http://data.kbodata.be/organisation/0866_386_380#id is a → http://www.w3.org/1999/02/22-rdf-syntax-ns#type
Company → http://www.w3.org/ns/regorg#RegisteredOrganization
Uniform Resource Identifiers (URIs)

E.g., Linked Datex and Linked GTFS
Vocabularies athttp://vocab.datex.org/terms http://vocab.gtfs.org/terms
E.g.,Searching for Parking Facilities
with Linked Data thanks to “rich snippets”
But is that it?

A story of raising interoperability
↓Querying
syntactic
semantic
technical
legal
When I have 2 datasets, how easy is it to turn them into 1 dataset?
→ Open Definition & open licenses
→ The Internet: exchanging data world-wide
→ JSON, XML, CSV, … Open Standards
→ using URIs instead of local identifiers

Where can you get in what amount of time?
under specific conditions:taking into account: multimodality, criminality, your subscriptions,
what you’re carrying, disabilities, etc

data dumpRoute planning
algorithms as a service

A long tail for transport data services
...
Hard to guess which kind of queries will be needed

Can we find a way to publishfor example public transport data
while minimizing federated reuse cost?

Data needed for algorithm
a connectiondepartureTime
+departureStop
arrivalTime+
arrivalStop
another connectiondepartureTime
+departureStop
arrivalTime+
arrivalStop
time
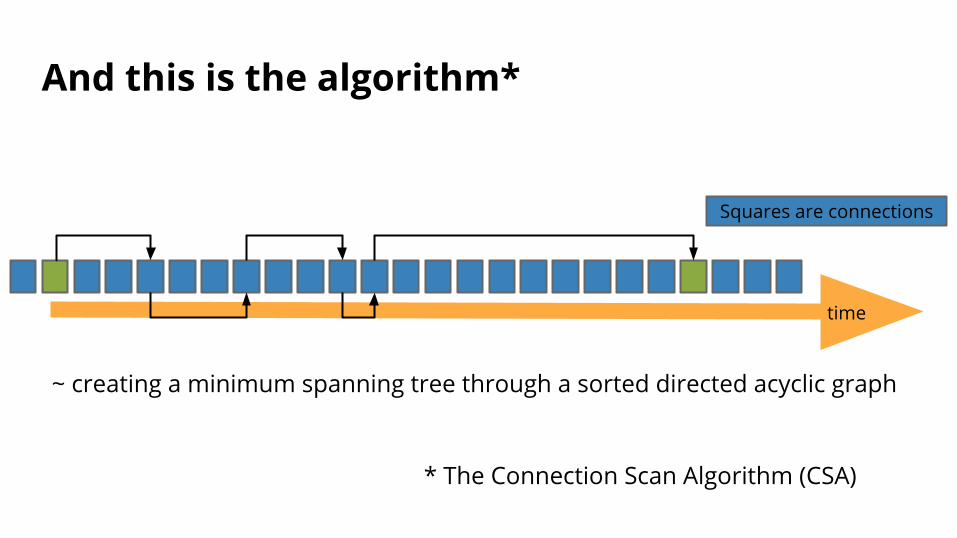
* The Connection Scan Algorithm (CSA)
And this is the algorithm*
~ creating a minimum spanning tree through a sorted directed acyclic graph
Squares are connections

Resource XResource ...Resource 2Resource 1
time
nextPage
nextPage
When published in pages on the Web, route planning will need X requests instead of 1

Try it yourself at
http://LinkedConnections.org

Striking the golden mean?
Data dumps
Smart servers
Data publishing (cheap/reliable)
Data services(rather expensive/unreliable)
Entire query languages over
HTTP
Dataset split in fragments
Smart agents
algorithmsas a service

Global interoperability for Route Planners?
↓Querying
syntactic
semantic
technical
legal → Open Definition & open licenses
→ The Internet: exchanging data world-wide
→ JSON, XML, CSV, … Open Standards
→ Work in progress linkedconnections.org
→ using URIs instead of local identifiers

Checklist Open (Transport) Data
Do you have an open license on your data?
Is it shared publicly on the Web in an open format (html/css/xml/json…)?
Do you identify things in a globally interoperable way?
How easy is it to include your dataset in a federated query?
Are you exposing basic reusable building blocks for your dataset?

A world where knowledge creates powerfor the many, not the few
Questions?
@pietercolpaerthttp://pieter.pm