scalability and availability for marketing campaigns
TRANSCRIPT

Scalability and availability for marketing campaigns
Ryan Shuttleworth – Technical Evangelist @ryanAWS

Scalability and availability for marketing campaigns
Rules for ‘just making things work’

The fundamental rule is
Elasticity

Traditional IT
capacity
Elastic capacity
Capacity
Time Your IT needs
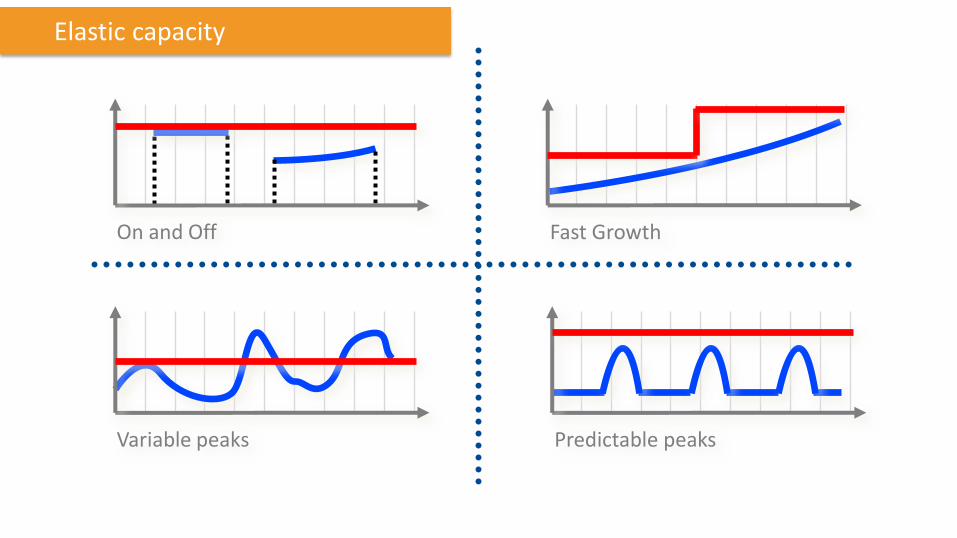
On and Off Fast Growth
Variable peaks Predictable peaks
Elastic capacity
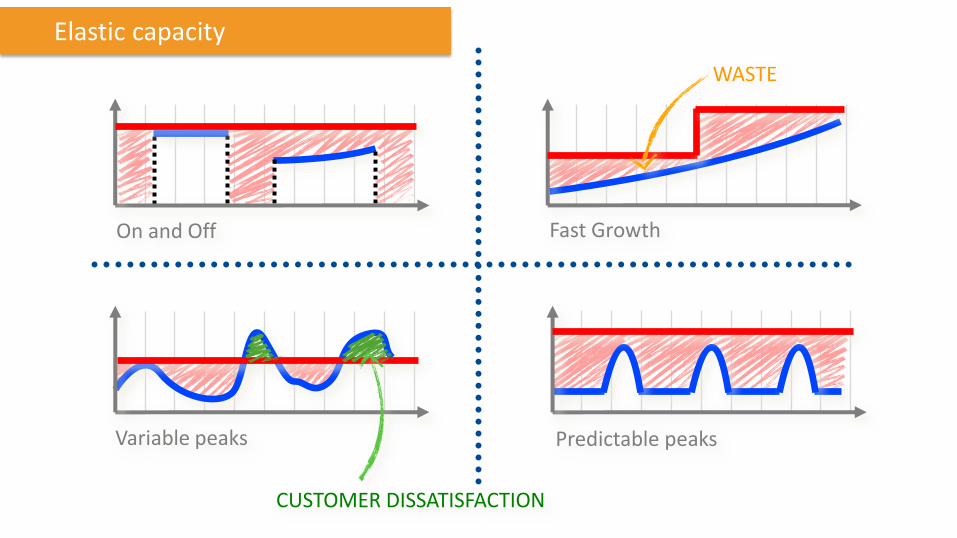
On and Off Fast Growth
Predictable peaks Variable peaks
WASTE
CUSTOMER DISSATISFACTION
Elastic capacity

Elastic cloud capacity
Traditional
IT capacity
Your IT needs
Time
Capacity
Elastic capacity

Fast Growth On and Off
Predictable peaks Variable peaks
Elastic capacity

503 Service Temporarily Unavailable
The server is temporarily unable to service
your request due to maintenance downtime or
capacity problems. Please try again later.

503 Service Temporarily Unavailable
The server is temporarily unable to service
your request due to maintenance downtime or
capacity problems. Please try again later.

Social application
/ ad placement
<100ms

Social application
/ ad placement
<100ms

Scalable and available marketing campaigns
Rules for ‘just making things work’

Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Rule 3: Handle requests at any scale
Rule 4: Simplify architecture with services
Rule 5: Automate operational management
Rule 6: Leverage unique cloud properties

Rule 1: Service all web requests
Or
“you ain’t marketing anything if you aren’t answering the door…”

DNS Application Data
Rule 1: Service all web requests
a) Make sure requests get to your ‘front door’
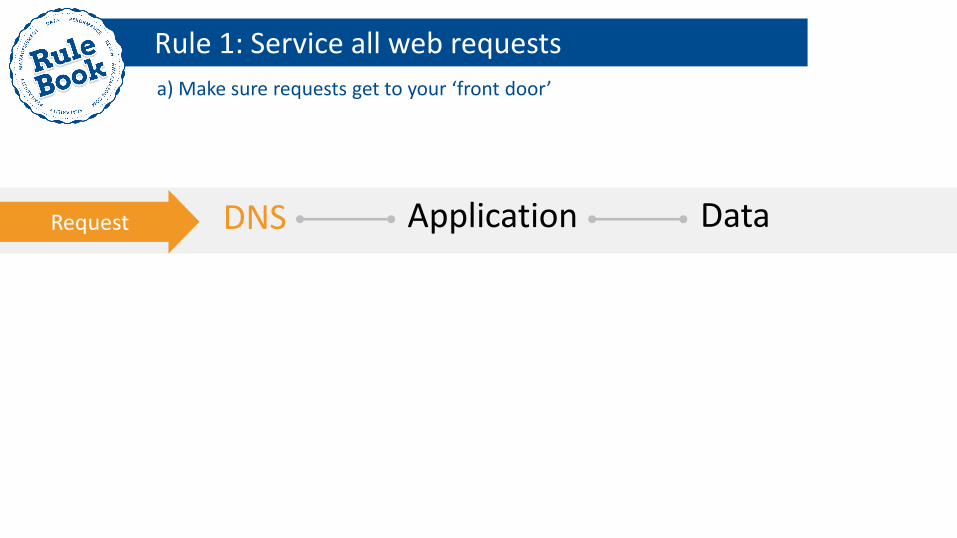
DNS Application Data Request
Rule 1: Service all web requests
a) Make sure requests get to your ‘front door’

DNS Application Data Request
a) Make sure requests get to your ‘front door’
Rule 1: Service all web requests

DNS Application Data Request
…then this is irrelevant
Clients can’t resolve you?
Rule 1: Service all web requests
a) Make sure requests get to your ‘front door’

DNS Application Data Request
“100% Available”
SLA
Rule 1: Service all web requests
Route53
Feature Details
Global Supported from AWS global edge locations for fast and reliable domain name resolution
Scalable Automatically scales based upon query volumes
Latency based routing Supports resolution of endpoints based upon latency, enabling multi-region application delivery
Integrated Integrates with other AWS services allowing Route 53 to front load balancers, S3 and EC2
Secure Integrates with IAM giving fine grained control over DNS record access
http://aws.amazon.com/route53/sla
a) Make sure requests get to your ‘front door’

DNS Application Data Request
Rule 1: Service all web requests
a) Make sure requests get to your ‘front door’ b) Make sure you open the door when they arrive
Route53

Region
DNS Application Data Request
Rule 1: Service all web requests
Elastic Load
Balancer Region
Availability Zone
Availability Zone
Availability Zone
Availability Zone
Route53
a) Make sure requests get to your ‘front door’ b) Make sure you open the door when they arrive
Elastic load balancing Multi-availability zone Multi-region

Region
Rule 1: Service all web requests
DNS Application Data Request
Region
a) Make sure requests get to your ‘front door’ b) Make sure you open the door when they arrive c) Have the data to form a response
Elastic Load
Balancer Region
Availability Zone
Availability Zone
Availability Zone
Availability Zone
Route53
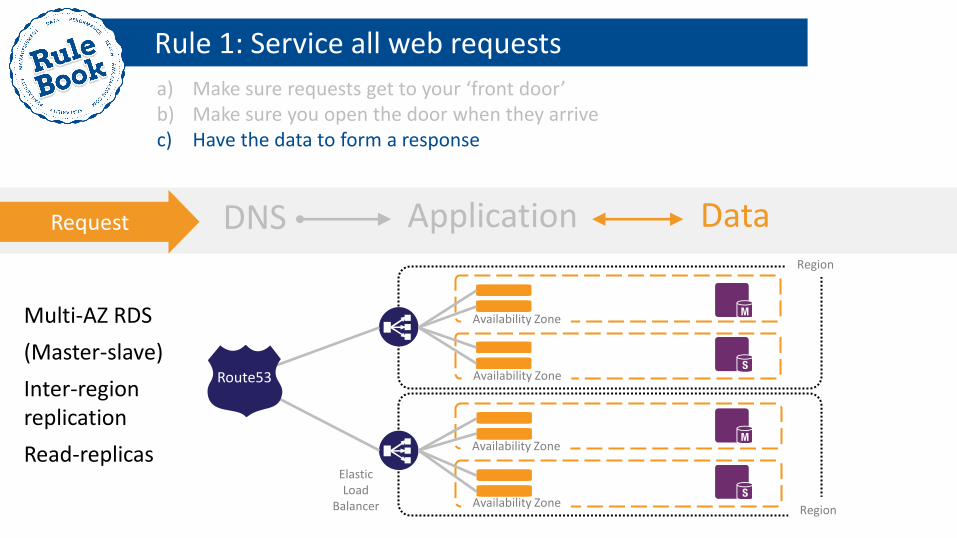
Region
Rule 1: Service all web requests
DNS Application Data Request
Region
Elastic Load
Balancer
Route53
Region
Availability Zone
Availability Zone
Availability Zone
Availability Zone
a) Make sure requests get to your ‘front door’ b) Make sure you open the door when they arrive c) Have the data to form a response
Multi-AZ RDS
(Master-slave)
Inter-region replication
Read-replicas

Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Rule 3: Handle requests at any scale
Rule 4: Simplify architecture with services
Rule 5: Automate operational management
Rule 6: Leverage unique cloud properties

Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Or
“I’m not hanging around, so be quick…”

Rule 2: Service requests as fast as possible

Rule 2: Service requests as fast as possible
a) Choose the fastest route
Region A
Route53
Region B
Request

Rule 2: Service requests as fast as possible
a) Choose the fastest route
Region A
Route53
Region B
16ms 92ms
Request

Rule 2: Service requests as fast as possible
a) Choose the fastest route
Region A
Route53
Region B
16ms 92ms
Request

Rule 2: Service requests as fast as possible
Region A
Route53
Region B
16ms
Request
Region A DNS entry
a) Choose the fastest route

Rule 2: Service requests as fast as possible
a) Choose the fastest route b) Offload your application servers
London
Paris
NY
Served from S3
/images/*
3
Served from EC2
*.php
2
Single CNAME
www.mysite.com
1
CloudFront World-wide content distribution network
Easily distribute content to end users with low
latency, high data transfer speeds, and no
commitments.

Without CloudFront
EC2 webservers/app servers loaded by user
requests
Rule 2: Service requests as fast as possible
a) Choose the fastest route b) Offload your application servers

With CloudFront
Load of user requests pushed into
CloudFront, EC2 cluster can scale
down
Offload Scale Down
Rule 2: Service requests as fast as possible
a) Choose the fastest route b) Offload your application servers

Rule 2: Service requests as fast as possible
Res
po
nse
Tim
e
Serv
er L
oad
Res
po
nse
Tim
e
Serv
er
Load
Res
po
nse
Tim
e
Serv
er
Load
No CDN CDN for
Static
Content
CDN for
Static &
Dynamic
Content
Offload Scale Down
a) Choose the fastest route b) Offload your application servers
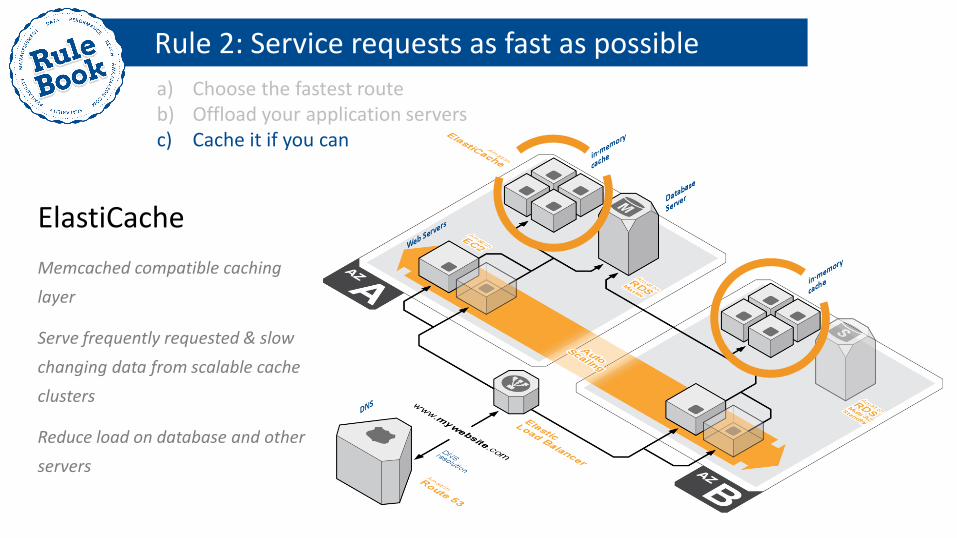
Rule 2: Service requests as fast as possible
a) Choose the fastest route b) Offload your application servers c) Cache it if you can
ElastiCache
Memcached compatible caching
layer
Serve frequently requested & slow
changing data from scalable cache
clusters
Reduce load on database and other
servers

Rule 2: Service requests as fast as possible
a) Choose the fastest route b) Offload your application servers c) Cache it if you can d) Single digit latencies where it matters
Scale Dat
abas
e Q
ue
ry P
erfo
rman
ce
Desired consistency, predictability

Rule 2: Service requests as fast as possible
a) Choose the fastest route b) Offload your application servers c) Cache it if you can d) Single digit latencies where it matters
Scale Dat
abas
e Q
ue
ry P
erfo
rman
ce
Desired consistency, predictability
Actual degraded
performance with scale

Rule 2: Service requests as fast as possible
a) Choose the fastest route b) Offload your application servers c) Cache it if you can d) Single digit latencies where it matters
Scale Dat
abas
e Q
ue
ry P
erfo
rman
ce
Desired consistency, predictability
Actual degraded
performance with scale
Management problems
Data sharding Data caching Provisioning
Cluster management Fault management

Rule 2: Service requests as fast as possible
a) Choose the fastest route b) Offload your application servers c) Cache it if you can d) Single digit latencies where it matters
Scale Dat
abas
e Q
ue
ry P
erfo
rman
ce
Dynamo DB Query Performance
Relational Database
Query Performance
DynamoDB
Low latency Large scale Zero admin
Predictable performance

Rule 2: Service requests as fast as possible
a) Choose the fastest route b) Offload your application servers c) Cache it if you can d) Single digit latencies where it matters
Scale Dat
abas
e Q
ue
ry P
erfo
rman
ce
Dynamo DB Query Performance DynamoDB
Low latency Large scale Zero admin
Predictable performance
Average single-digit milliseconds server side latencies
Runs on solid state drives, and is built to
maintain consistent, fast latencies at any scale

Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Rule 3: Handle requests at any scale
Rule 4: Simplify architecture with services
Rule 5: Automate operational management
Rule 6: Leverage unique cloud properties

Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Rule 3: Handle requests at any scale
Or
“When they come, they REALLY come…”

Rule 3: Handle requests at any scale
a) Scale up
Vertical Scaling
From $0.02/hr
Basic unit of compute capacity
Range of CPU, memory & local disk options
14 Instance types available, from micro through cluster
compute to SSD backed
Scale up with Elastic Compute Cloud (EC2)
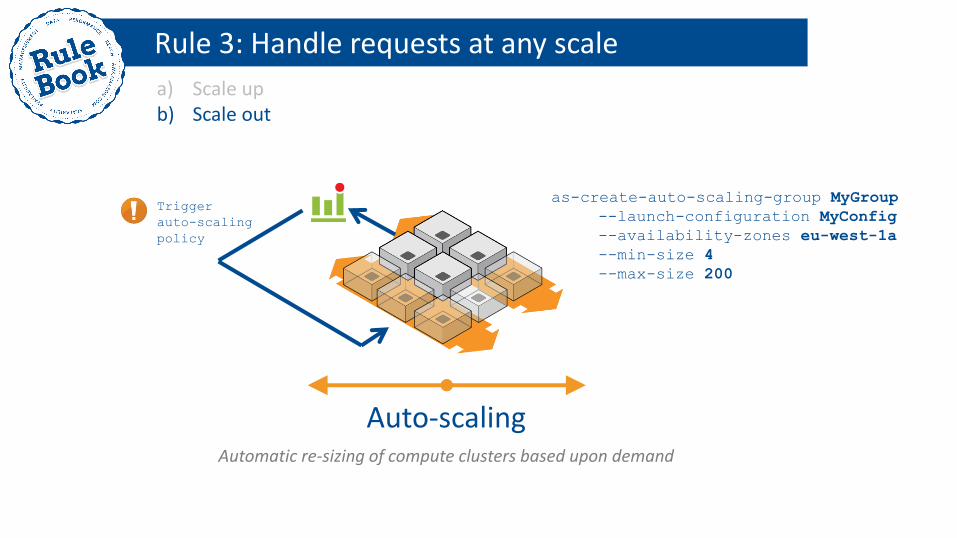
Rule 3: Handle requests at any scale
a) Scale up b) Scale out
Trigger
auto-scaling
policy
as-create-auto-scaling-group MyGroup
--launch-configuration MyConfig
--availability-zones eu-west-1a
--min-size 4
--max-size 200
Auto-scaling Automatic re-sizing of compute clusters based upon demand
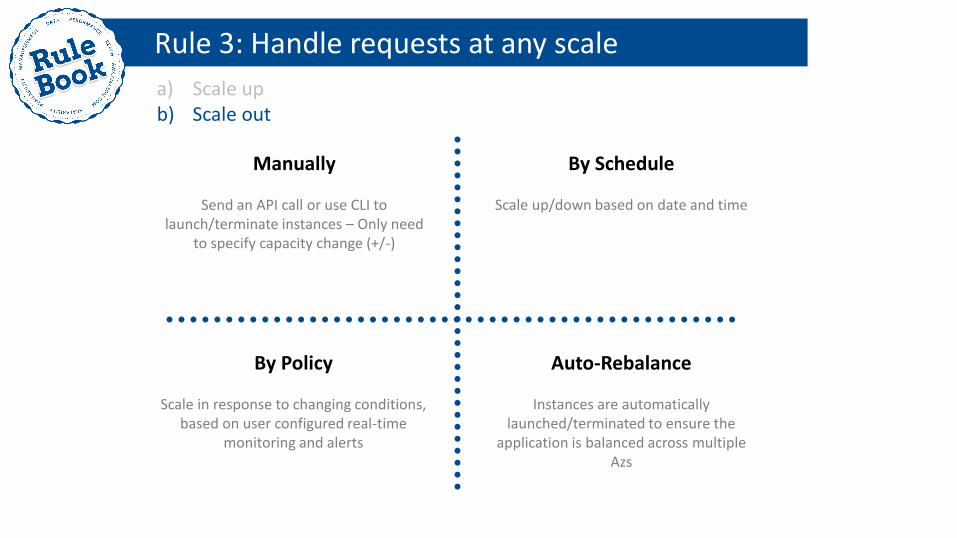
Manually
Send an API call or use CLI to launch/terminate instances – Only need
to specify capacity change (+/-)
By Schedule
Scale up/down based on date and time
a) Scale up b) Scale out
By Policy
Scale in response to changing conditions, based on user configured real-time
monitoring and alerts
Auto-Rebalance
Instances are automatically launched/terminated to ensure the
application is balanced across multiple Azs
Rule 3: Handle requests at any scale

Manually
Send an API call or use CLI to launch/terminate instances – Only need
to specify capacity change (+/-)
By Schedule
Scale up/down based on date and time Preemptive manual scaling of capacity
e.g. before a marketing event add 10 more instances
Regular scaling up and down of instances
e.g. scale from 2 to 10 every Friday to handle load generated by party goers
a) Scale up b) Scale out
By Policy
Scale in response to changing conditions, based on user configured real-time
monitoring and alerts
Auto-Rebalance
Instances are automatically launched/terminated to ensure the
application is balanced across multiple Azs
Rule 3: Handle requests at any scale
Dynamic scale based upon custom metrics
e.g. SQS queue depth, Average CPU load, ELB latency
Maintain capacity across availability zones
e.g. Instance availability maintained in event of AZ becoming unavailable

Rule 3: Handle requests at any scale
a) Scale up b) Scale out c) Dial it up
Elastic Block Store Provisioned IOPS up to 1000 per EBS
volume
Predictable performance for
demanding workloads such as
databases
DynamoDB Provisioned read/write performance per
table
Predictable high performance scaled via
console or API


“AWS gave us the flexibility to bring a massive amount of capacity online in a short period of
time and allowed us to do so in an operationally straightforward way.
AWS is now Shazam’s cloud provider of choice,”
Jason Titus,
CTO
DynamoDB: over 500,000 writes per
second
Amazon EMR: more than 1 million writes
per second

Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Rule 3: Handle requests at any scale
Rule 4: Simplify architecture with services
Rule 5: Automate operational management
Rule 6: Leverage unique cloud properties

Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Rule 3: Handle requests at any scale
Rule 4: Simplify architecture with services
Or
“Marketing is fun. Software is a drag…”

Your Business
70%
On-Premise Infrastructure
30%
Managing All of the “Undifferentiated Heavy Lifting”
Rule 4: Simplify architecture with services

AWS Cloud-Based
Infrastructure
Your Business
More Time to Focus on Your Business
Configuring Your Cloud Assets
70%
30% 70%
On-Premise Infrastructure
30%
Managing All of the “Undifferentiated Heavy Lifting”
Rule 4: Simplify architecture with services

Relational Database Service Database-as-a-Service
No need to install or manage database instances
Scalable and fault tolerant configurations
DynamoDB Provisioned throughput NoSQL database
Fast, predictable performance
Fully distributed, fault tolerant architecture
Use RDS for databases
Use DynamoDB for high performance key-
value DB
Rule 4: Simplify architecture with services

Amazon SQS
Processing
task/processing
trigger
Processing results
Amazon SQS Reliable, highly scalable, queue service
for storing messages as they travel
between instances
Task A
Task B
(Auto-scaling)
Task C
2
3
1
Simple Workflow Reliably coordinate processing steps
across applications
Integrate AWS and non-AWS resources
Manage distributed state in complex
systems
Push inter-process workflows into the cloud with SWF
Reliable message queuing without
additional software
Rule 4: Simplify architecture with services
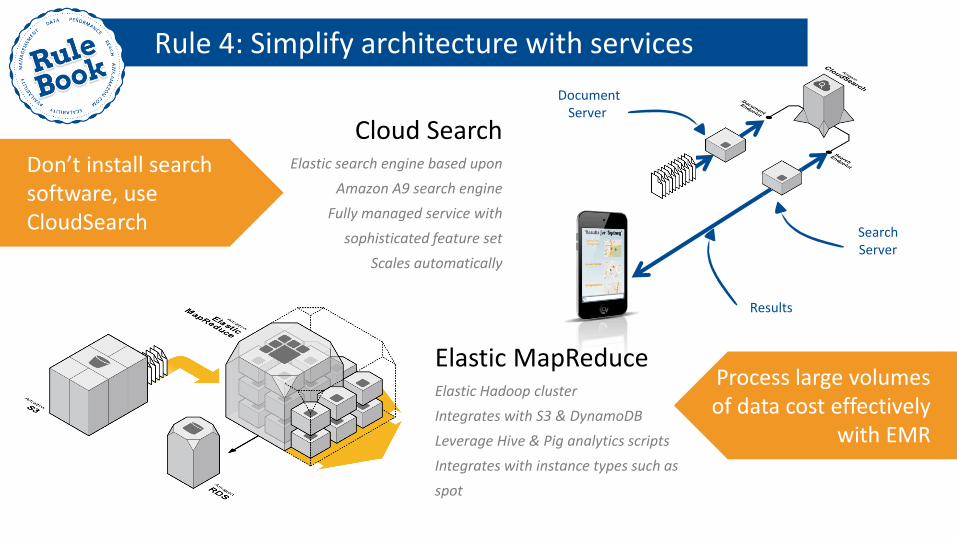
Cloud Search Elastic search engine based upon
Amazon A9 search engine
Fully managed service with
sophisticated feature set
Scales automatically
Document Server
Results
Search Server
Don’t install search software, use CloudSearch
Process large volumes of data cost effectively
with EMR
Elastic MapReduce Elastic Hadoop cluster
Integrates with S3 & DynamoDB
Leverage Hive & Pig analytics scripts
Integrates with instance types such as
spot
Rule 4: Simplify architecture with services


“Amazon CloudSearch is a game-changing product that has allowed us to deliver powerful
new search capabilities. Our customers can now find what they are looking for faster and more
easily than ever before…
….We saved many months of re-architecture and development time by going with Amazon
CloudSearch”
Don MacAskill CEO & Chief Geek
SmugMug



Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Rule 3: Handle requests at any scale
Rule 4: Simplify architecture with services
Rule 5: Automate operational management
Rule 6: Leverage unique cloud properties

Rule 5: Automate operational management
Rule 6: Leverage unique cloud properties
Or
“Run it from the iPhone…”

Compute
Storage
Security Scaling
Database
Networking Monitoring
Messaging
Workflow
DNS
Load Balancing
Backup CDN
Rule 5: Automate operational management
a) Everything is programmable
Access everything via CLI, API or
Console
Achieve the highest levels of automation
sophistication with ease

Rule 5: Automate operational management
a) Everything is programmable b) Think disposable, one click deployments
Cloud Formation Automate creation of ‘stacks’ in a repeatable way
Scripting framework for AWS resource creation
Feature Details
Platform support Support for AWS resources from EC2 to IAM
Resource creation Creates AWS resources behind the scenes and reports on progress
Declarative Specify stacks in JSON format and source control your environments
Customizable Drive stack creation with paramaters

Rule 5: Automate operational management
a) Everything is programmable b) Think disposable, one click deployments c) Design for failure, implement self healing
Customize instance startup
Get instances to ask ‘who am I?’ question on startup and be configured dynamically upon
being asnwered
Maintain capacity of instances
Using a minimum pool size will maintain
capacity in the event of instance failures
Know what’s going on, take automated actions
Use CloudWatch standard and custom metrics to create
alarms.
Respond with automated administration actions
Bootstrapping Auto-scaling Cloud Watch

Rule 5: Automate operational management
a) Everything is programmable b) Think disposable, one click deployments c) Design for failure, implement self healing

Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Rule 3: Handle requests at any scale
Rule 4: Simplify architecture with services
Rule 5: Automate operational management
Rule 6: Leverage unique cloud properties

Rule 6: Leverage unique cloud properties
Or
“Do awesome things, fast…”
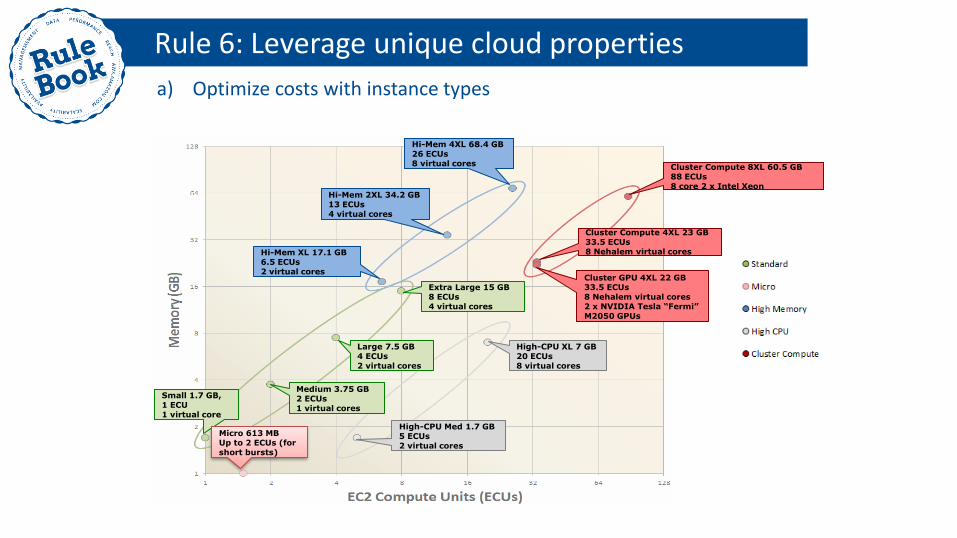
Small 1.7 GB, 1 ECU 1 virtual core
Large 7.5 GB 4 ECUs 2 virtual cores
Extra Large 15 GB 8 ECUs 4 virtual cores
Hi-Mem XL 17.1 GB 6.5 ECUs 2 virtual cores
Hi-Mem 2XL 34.2 GB 13 ECUs 4 virtual cores
Hi-Mem 4XL 68.4 GB 26 ECUs 8 virtual cores
High-CPU Med 1.7 GB 5 ECUs 2 virtual cores
High-CPU XL 7 GB 20 ECUs 8 virtual cores
Micro 613 MB Up to 2 ECUs (for short bursts)
Cluster GPU 4XL 22 GB 33.5 ECUs 8 Nehalem virtual cores 2 x NVIDIA Tesla “Fermi” M2050 GPUs
Cluster Compute 4XL 23 GB 33.5 ECUs 8 Nehalem virtual cores
Cluster Compute 8XL 60.5 GB 88 ECUs 8 core 2 x Intel Xeon
Medium 3.75 GB 2 ECUs 1 virtual cores
Rule 6: Leverage unique cloud properties
a) Optimize costs with instance types

Unix/Linux instances start at $0.02/hour
Pay as you go for compute power
Low cost and flexibility
Pay only for what you use, no up-front commitments or long-term contracts
Use Cases:
Applications with short term, spiky, or
unpredictable workloads;
Application development or testing
On-demand instances
1- or 3-year terms
Pay low up-front fee, receive significant hourly discount
Low Cost / Predictability
Helps ensure compute capacity is available
when needed
Use Cases:
Applications with steady state or predictable usage
Applications that require reserved capacity,
including disaster recovery
Reserved instances
Bid on unused EC2 capacity
Spot Price based on supply/demand, determined automatically
Cost / Large Scale, dynamic workload handling
Use Cases:
Applications with flexible start and end times
Applications only feasible at very low compute prices
Spot instances
Rule 6: Leverage unique cloud properties
a) Optimize costs with instance types

0
1000
2000
3000
4000
5000
6000
7000
Reserved Instances
On Demand
Spot
Rule 6: Leverage unique cloud properties
a) Optimize costs with instance types

a) Optimize costs with instance types b) Get insight fast with Elastic MapReduce
Rule 6: Leverage unique cloud properties
Elastic MapReduce Managed, elastic Hadoop cluster
Integrates with S3 & DynamoDB
Leverage Hive & Pig analytics scripts
Integrates with instance types such as spot
Feature Details
Scalable Use as many or as few compute instances running Hadoop as you want. Modify the number of instances while your job flow is running
Integrated with other services
Works seamlessly with S3 as origin and output. Integrates with DynamoDB
Comprehensive Supports languages such as Hive and Pig for defining analytics, and allows complex definitions in Cascading, Java, Ruby, Perl, Python, PHP, R, or C++
Cost effective Works with Spot instance types
Monitoring Monitor job flows from with the management console

Cluster compute instances
Implement HVM process execution
Intel® Xeon® E5-2670 processors
10 Gigabit Ethernet & GPUs
Cluster
Compute
80 EC2
Compute Units
60GB RAM
3TB Local
Disk
Network placement groups
Cluster instances deployed in a ‘Placement Group’ enjoy low
latency, full bisection 10 Gbps bandwidth
10Gbps
Rule 6: Leverage unique cloud properties
a) Optimize costs with instance types b) Get insight fast with Elastic MapReduce c) Create a supercomputer backend when you need it

Rule 2: Service requests as fast as possible
Rule 1: Service all web requests
Rule 3: Handle requests at any scale
Rule 4: Simplify architecture with services
Rule 5: Automate operational management
Rule 6: Leverage unique cloud properties

But don’t take it from me…

AWS for digital advertising Scalability & availability for marketing campaigns Delivering a Social Application that can Handle 130 Billion Requests per Month on a Credit Card Budget Matt Millar, CEO, Tellybug
Improving Time to Market with a Low TCO The Changing Media and Technology Landscape Requires a New Kind of Agency with Innovation at its Core Regardt Meyer, Group Technical Director, AKQA
Find out more from your advertising campaign using analytics Digital Media & AWS - VIP Program for Digital Media Tom Ray, CloudReach
Agenda