scalable applications and real time response ashish motivala cs 614 april 17 th 2001
Post on 21-Dec-2015
216 views
TRANSCRIPT

Scalable Applications and Real Time Response
Ashish MotivalaCS 614
April 17th 2001

Scalable Applications and Real Time Response
Using Group Communication Technology to Implement a Reliable and Scalable Distributed IN Coprocessor; Roy Friedman and Ken Birman; TINA 1996.
Manageability, availability and performance in Porcupine: a highly scalable, cluster-based mail service; Yasushi Saito, Brian N. Bershad and Henry M. Levy; Proceedings of the 17th ACM Symposium on Operating Systems Principles , 1999, Pages 1 – 15.

Real-time
Two categories of real-time– When an action needs to be predictably
fast. i.e. Critical applications.– When an action must be taken before a
time limit passes.
More often than not real-time doesn’t mean “as fast as possible” but means “slow and steady”.

Real problems need real-time
Air Traffic Control, Free Flight– when planes are at various locations.
Medical Monitoring, Remote Tele-surgery– doctors talk about how patients responded after drug
was given, or change therapy after some amount of time.
Process control software, Robot actions– a process controller runs factory floors by
coordinating machine tools activities.

More real-time problems
Video and multi-media systems– synchronous communication protocols that
coordinate video, voice, and other data sources
Telecommunications systems– guarantee real-time response despite
failures, for example when switching telephone calls

Predictability
If this is our goal…– Any well-behaved mechanism may be
adequate– But we should be careful about uncommon
disruptive cases• For example, cost of failure handling is often
overlooked• Risk is that an infrequent scenario will be very
costly when it occurs

Predictability: Examples
Probabilistic multicast protocol– Very predictable if our desired latencies are
larger than the expected convergence – Much less so if we seek latencies that bring
us close to the expected latency of the protocol itself

Back to the paper
Telephone networks need a mixture of properties– Real-time response– High performance– Stable behavior even when failures and
recoveries occur Can we use our tools to solve such a
problem?

Role of coprocessor
A simple database– Switch does a query
• How should I route a call to 1800-327-2777 from 607-266-8141?
• Reply: use output line 6
– Time limit of 100ms on transaction Call ID, call conferencing, automatic
transferring, voice menus, etc Update database

IN coprocessor
SS7switch
SS7switch
SS7switch
SS7switch

IN coprocessor
SS7switch
SS7switch
SS7switch
SS7switch
coprocessor
coprocessor
coprocessor
coprocessor

Present coprocessor
Right now, people use hardware fault-tolerant machines for this– E.g. Stratus “pair and a spare” – Mimics one computer but tolerates
hardware failures– Performance an issue?

Goals for coprocessor
Requirements– Scalability: ability to use a cluster of machines for
the same task, with better performance when we use more nodes
– Fault-tolerance: a crash or recovery shouldn’t disrupt the system
– Real-time response: must satisfy the 100ms limit at all times
Downtime: any period when a series of requests might all be rejected
Desired: 7 to 9 nines availability

SS7 experiment
Horus runs the “800 number database” on a cluster of processors next to the switch
Provide replication management tools Provide failure detection and automatic
configuration
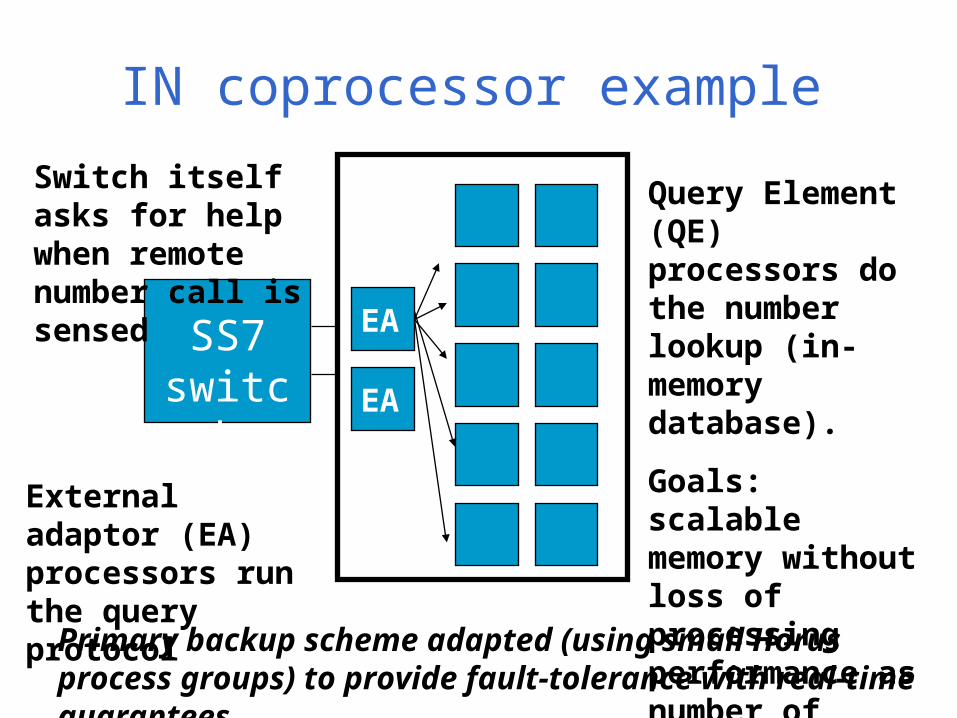
IN coprocessor example
SS7 switch
Query Element (QE) processors do the number lookup (in-memory database).
Goals: scalable memory without loss of processing performance as number of nodes is increased
Switch itself asks for help when remote number call is sensed
External adaptor (EA) processors run the query protocol
EA
EA
Primary backup scheme adapted (using small Horus process groups) to provide fault-tolerance with real-time guarantees

Options?
A simple scheme:– Organize nodes as groups of 2 processes– Use virtual synchrony multicast
• For query• For response• Also for updates and membership tracking

IN coprocessor example
SS7 switch
EA
EA
Step 1: Switch sees incoming request

IN coprocessor example
SS7 switch
EA
EA
Step 2: Switch waits while EA procs. multicast request to group of query elements (“partitioned” database)

IN coprocessor example
SS7 switch
Think
Think
EA
EA
Step 3: The query elements do the query in duplicate

IN coprocessor example
SS7 switch
EA
EA
Step 4: They reply to the group of EA processes

IN coprocessor example
SS7 switch
EA
EA
Step 5: EA processes reply to switch, which routes call

Results!!
Terrible performance!– Solution has 2 Horus multicasts on each
critical path– Experience: about 600 queries per second
but no more Also: slow to handle failures
– Freezes for as long as 6 seconds Performance doesn’t improve much
with scale either

Next try
Consider taking Horus off the critical path Idea is to continue using Horus
– It manages groups– And we use it for updates to the database and for
partitioning the QE set But no multicasts on critical path
– Instead use a hand-coded scheme Use Sender Ordering (or fifo) instead of Total
Ordering

Hand-coded scheme
Queue up a set of requests from an EA to a QE
Periodically (15 ms), sweep the set into a message and send as a batch
Process queries also as a batch Send the batch of replies back to EA

Clever twists
Split into a primary and secondary EA for each request– Secondary steps in if no reply seen in 50ms– Batch size calculated so that 50ms should
be “long enough” Alternate primary and secondary after
each request.

Handling Failure and Overload
Failure– QE: backup EA reissues request after half the
deadline, without waiting for the failure detector– EA: the other EA takes over and handles all the
requests
Overload– Drop requests if there is no chance of servicing
them, rather than missing all deadlines– High and low watermarks

Results
Able to sustain 22,000 emulated telephone calls per second
Able to guarantee response within 100ms and no more than 3% of calls are dropped (randomly)
Performance is not hurt by a single failure or recovery while switch is running
Can put database in memory: memory size increases with number of nodes in cluster

Other settings with a strong temporal element
Load balancing– Idea is to track load of a set of machines– Can do this at an access point or in the
client– Then want to rebalance by issuing requests
preferentially to less loaded servers

Load balancing in farms
Akamai widely cited– They download the rarely-changing content
from customer web sites– Distribute this to their own web farm– Then use a hacked DNS to redirect web
accesses to a close-by, less-loaded machine Real-time aspects?
– The data on which this is based needs to be fresh or we’ll send to the wrong server

Conclusions
Protocols like pbcast are potentially appealing in a subset of applications that are naturally probabilistic to begin with, and where we may have knowledge of expected load levels, etc.
More traditional virtual synchrony protocols with strong consistency properties make more sense in standard networking settings

Future directions in real-time
Expect GPS time sources to be common within five years
Real-time tools like periodic process groups will also be readily available (members take actions in a temporally coordinated way)
Increasing focus on predictable high performance rather than provable worst-case performance
Increasing use of probabilistic techniques

Dimensions of Scalability
We often say that we want systems that “scale”
But what does scalability mean? As with reliability & security, the term
“scalability” is very much in the eye of the beholder

Scalability
As a reliability question:– Suppose a system experiences some rate of
disruptions r– How does r change as a function of the size
of the system?• If r rises when the system gets larger we would
say that the system scales poorly• Need to ask what “disruption” means, and what
“size” means…

Scalability
As a management question– Suppose it takes some amount of effort to
set up the system– How does this effort rise for a larger
configuration?– Can lead to surprising discoveries
• E.g. the 2-machine demo is easy, but setup for 100 machines is extremely hard to define

Scalability
As a question about throughput– Suppose the system can do t operations
each second– Now I make the system larger
• Does t increase as a function of system size? Decrease?
• Is the behavior of the system stable, or unstable?

Scalability
As a question about dependency on configuration– Many technologies need to know something
about the network setup or properties– The larger the system, the less we know!– This can make a technology fragile, hard to
configure, and hence poorly scalable

Scalability
As a question about costs– Most systems have a basic cost
• E.g. 2pc “costs” 3N messages
– And many have a background overhead• E.g. gossip involves sending one message per
round, receiving (on avg) one per round, and doing some retransmission work (rarely)
Can ask how these costs change as we make our system larger, or make the network noisier, etc

Scalability
As a question about environments– Small systems are well-behaved– But large ones are more like the Internet
• Packet loss rates and congestion can be problems• Performance gets bursty and erratic• More heterogeneity of connections and of
machines on which applications run
– The larger the environment, the nastier it may be!

Scalability
As a pro-active question– How can we design for scalability?– We know a lot about technologies– Are certain styles of system more scalable
than others?

Approaches
Many ways to evaluate systems:– Experiments on the real system– Emulation environments– Simulation– Theoretical (“analytic”)
But we need to know what we want to evaluate

Dangers
“Lies, damn lies, and statistics”– It is much to easy to pick some random
property of a system, graph it as a function of something, and declare success
– We need sophistication in designing our evaluation or we’ll miss the point
Example: message overhead of gossip– Technically, O(n)– Does any process or link see this cost?
• Perhaps not, if protocol is designed carefully

Technologies
TCP/IP and O/S message-passing architectures like U-Net
RPC and client-server architectures Transactions and nested transactions Virtual synchrony and replication Other forms of multicast Object oriented architectures Cluster management facilities

You’ve Got Mail
Cluster research has focused on web services Mail is an example of a write-intensive
application– disk-bound workload– reliability requirements– failure recovery
Mail servers have relied on “brute force” approach to scaling– Big-iron file server, RDBMS

Conventional Mail Servers
User DBServer
popd sendmail
NFSServer
NFSServer
Static partitioning
Performance problems:No dynamic load balancing
Manageability problems:Manual data partition decision
Availability problems:Limited fault tolerance

Porcupine’s Goals
Use commodity hardware to build a large, scalable mail service
Performance: Linear increase with cluster size
Manageability: React to changes automatically
Availability: Survive failures gracefully
1 billion messages/day (100x existing systems)
100 million users (10x existing systems)
1000 nodes (50x existing systems)

Key Techniques and Relationships
Functional Homogeneity“any node can perform any task”
AutomaticReconfiguration
Load BalancingReplication
Manageability PerformanceAvailability
Framework
Techniques
Goals
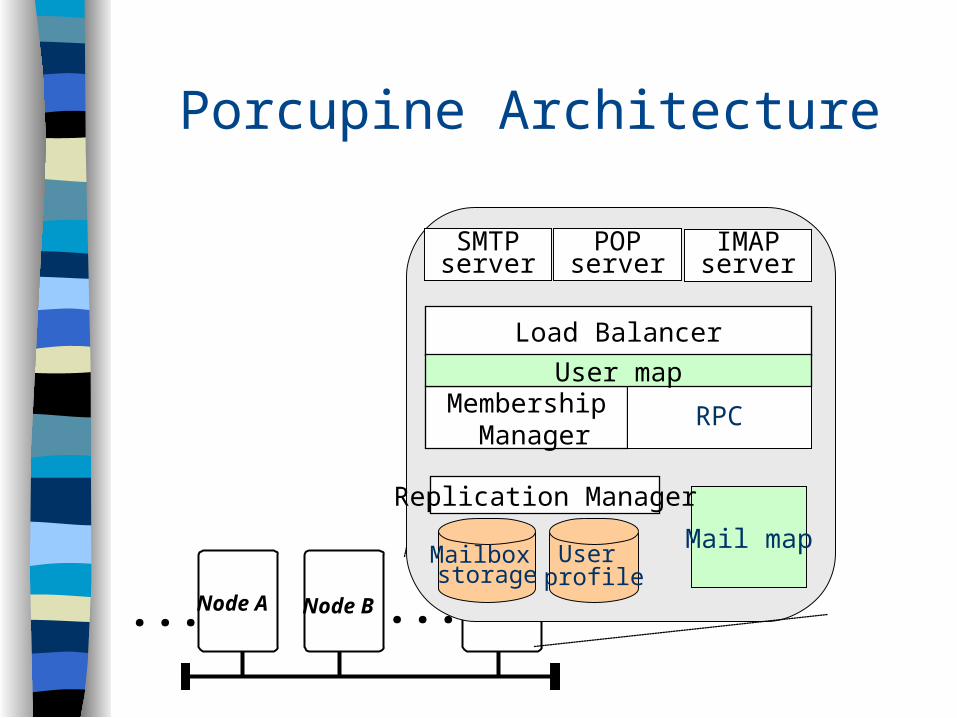
Porcupine Architecture
Node A ...Node B Node Z...
SMTPserver
POPserver
IMAPserver
Mail mapMailbox storage
User profile
Replication Manager
Membership Manager
RPC
Load Balancer
User map

Basic Data Structures
“bob”
BCACABAC
bob: {A,C}ann: {B}
BCACABAC
suzy: {A,C} joe: {B}
BCACABAC
Apply hash function
User map
Mail map/user info
Mailbox storage
A B C
Bob’s MSGs
Suzy’s MSGs
Bob’s MSGs
Joe’s MSGs
Ann’s MSGs
Suzy’s MSGs

Porcupine Operations
Internet
A B...
A
1. “send mail to bob”
2. Who manages bob? A
3. “Verify bob”
5. Pick the best nodes to store new msg C
DNS-RR selection
4. “OK, bob has msgs on C and D 6. “Store
msg”B
C
Protocol handling
User lookup
Load Balancing
Message store
...C

Measurement Environment
30 node cluster of not-quite-all-identical PCs100Mb/s Ethernet + 1Gb/s hubsLinux 2.2.742,000 lines of C++ code
Synthetic load Compare to sendmail+popd

Performance
GoalsScale performance linearly with cluster size
Strategy: Avoid creating hot spotsPartition data uniformly among nodesFine-grain data partition

How does Performance Scale?
0
100
200
300
400
500
600
700
800
0 5 10 15 20 25 30Cluster size
Messages/second
Porcupine
sendmail+popd
68m/day
25m/day

Availability
Goals:Maintain function after failures
React quickly to changes regardless of cluster size
Graceful performance degradation / improvement
Strategy:
Hard state: email messages, user profile Optimistic fine-grain replication
Soft state: user map, mail map Reconstruction after membership change

Soft-state Reconstruction
B C A B A B A C
bob: {A,C}
joe: {C}
B C A B A B A C
B A A B A B A B
bob: {A,C}
joe: {C}
B A A B A B A B
A C A C A C A C
bob: {A,C}
joe: {C}
A C A C A C A C
suzy: {A,B}
ann: {B}
1. Membership protocolUsermap recomputation
2. Distributed disk scan
suzy:
ann:
Timeline
A
B
ann: {B}
B C A B A B A C
suzy: {A,B}C ann: {B}
B C A B A B A C
suzy: {A,B}ann: {B}
B C A B A B A C
suzy: {A,B}

How does Porcupine React to Configuration Changes?
300
400
500
600
700
0 100 200 300 400 500 600 700 800Time(seconds)
Messages/second
No failure
One nodefailureThree nodefailuresSix nodefailures
Nodes fail
New membership determined
Nodes recover
New membership determined

Hard-state Replication
Goals:Keep serving hard state after failuresHandle unusual failure modes
Strategy: Exploit Internet semanticsOptimistic, eventually consistent replicationPer-message, per-user-profile replicationEfficient during normal operationSmall window of inconsistency

How Efficient is Replication?
0
100
200
300
400
500
600
700
800
0 5 10 15 20 25 30Cluster size
Me
ss
ag
es
/se
co
nd
Porcupine no replication
Porcupine with replication=2
68m/day
24m/day

How Efficient is Replication?
0
100
200
300
400
500
600
700
800
0 5 10 15 20 25 30Cluster size
Me
ss
ag
es
/se
co
nd
Porcupine no replication
Porcupine with replication=2
Porcupine with replication=2, NVRAM
68m/day
24m/day33m/day

Load balancing: Deciding where to store messages
Goals:Handle skewed workload wellSupport hardware heterogeneity
Strategy: Spread-based load balancingSpread: soft limit on # of nodes per mailbox
Large spread better load balanceSmall spread better affinity
Load balanced within spreadUse # of pending I/O requests as the load
measure

How Well does Porcupine Support Heterogeneous
Clusters?
0%
10%
20%
30%
0% 3% 7% 10%Number of fast nodes (% of total)
Th
rou
gh
pu
t in
crea
se(%
)
Spread=4
Static
+16.8m/day (+25%)
+0.5m/day (+0.8%)

Claims
Symmetric function distribution Distribute user database and user
mailbox– Lazy data management
Self-management– Automatic load balancing, membership
management Graceful Degradation
– Cluster remains functional despite any number of failures

Retrospect Questions:
– How does the system scale?– How costly is the failure recovery procedure?
Two scenarios tested– Steady state– Node failure
Does Porcupine scale?– Papers says “yes”– But in their work we can see a reconfiguration
disruption when nodes fail or recover• With larger scale, frequency of such events will rise• And the cost is linear in system size
– Very likely that on large clusters this overhead would become dominant!

Some Other Interesting Papers
The Next Generation Internet: Unsafe at any Speed? Ken Birman
Lessons from Giant-Scale ServicesEric Brewer, UCB