scalable big data stream processing with storm and groovy
TRANSCRIPT

© 2014 SpringOne 2GX. All rights reserved. Do not distribute without permission.
Scalable Big Data Stream Processing
with Storm and Groovy

• 20 years of industry experience
• ORGANIZER OF NYC STORM USER GROUP
• ARCHITECT AT WEBMD
CONTACT ME
[email protected] @edvorkin
Eugene Dvorkin
PRESENTATION FEEDBACK
#spring2gx @edvorkin

• Stream processing
• Storm architecture
• Storm abstractions
• Parallelism
• Message Processing
• Storm cluster
• Fault-tolerance
• Trident
• Storm at WebMD
• QA
PRESENTATION SUMMARY

Stream Processing
[
I
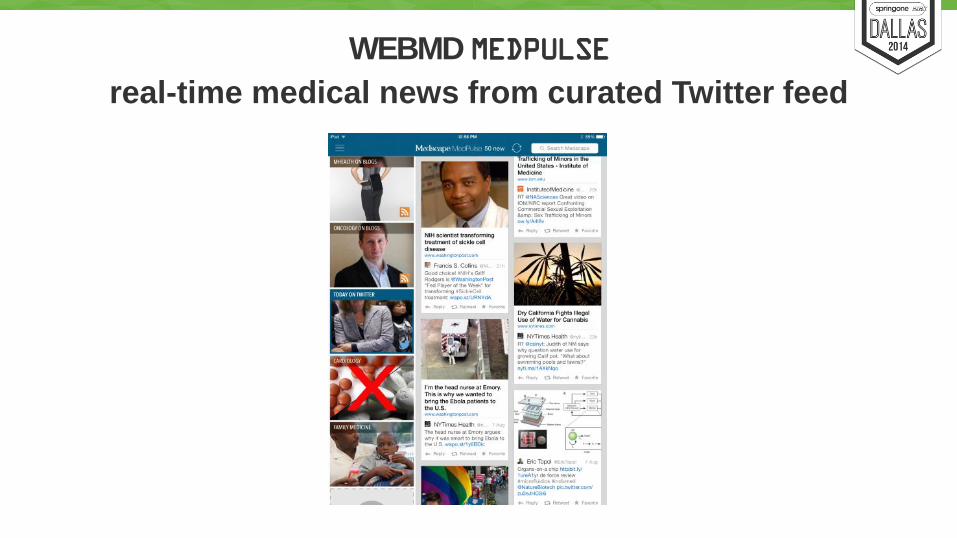
WEBMD MEDPULSE
real-time medical news from curated Twitter feed

Twitter streaming system
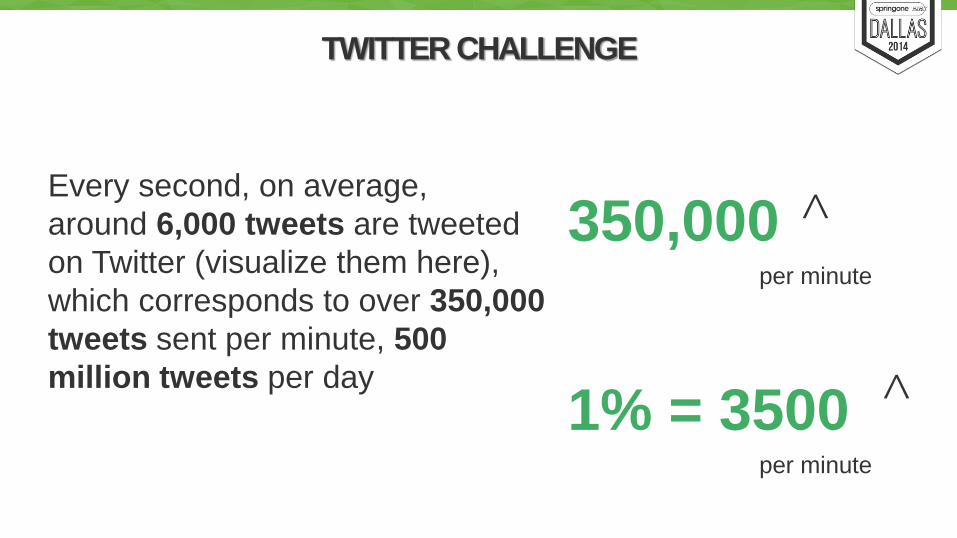
Every second, on average,
around 6,000 tweets are tweeted
on Twitter (visualize them here),
which corresponds to over 350,000
tweets sent per minute, 500
million tweets per day
TWITTER CHALLENGE
350,000 per minute
^
1% = 3500 per minute
^

HADOOP
Inherently BATCH-Oriented System

What is the need?
• Exponential rise in real-time data
• New business opportunity
Why Now?
• Economics of OSS and commodity hardware
WHY STREAM PROCESSING
Stream processing has emerged as a key use case*
*Source: Discover HDP2.1: Apache Storm for Stream Data Processing. Hortonworks. 2014

• Detecting fraud while someone swiping credit card
• Place ad on website while someone is reading a specific
article
• Alerts on application and machine failures
• ETL – move data from one system to another in real-time
Stream Processing Use Cases

Stream Processing Flow
4

Do It Yorself
DB
t
*Image credit:Nathanmarz: slideshare: storm
• How to scale
• Ho to deal with failures
• What to do with failed
messages
• A lot of infrastructure
concerns
• Complexity
• Tedious to build

Apache
STORM
II
%
å å

STORM HISTORY
2011 Created
by Nathan
Martz
2011 Acquired
by Twitter
2013 Apache
Incubator
Project
2011
Open
sourced
2014 Part of
Hortonworks
HDP2
platform
V a

STORM ADOPTION
Most mature, widely adopted framework
Source: http://storm.incubator.apache.org/
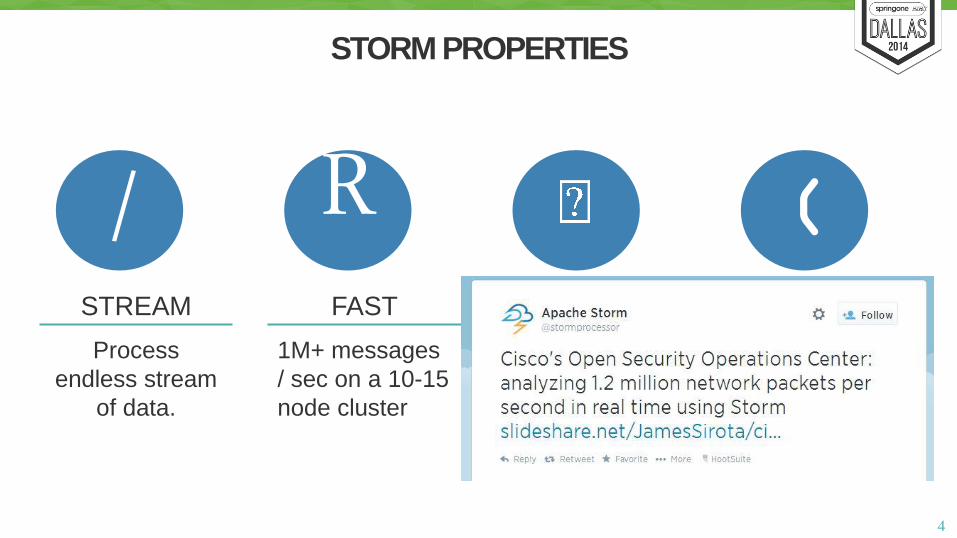
STORM PROPERTIES
STREAM
Process
endless stream
of data.
FAST
1M+ messages
/ sec on a 10-15
node cluster
SCALABLE FAULT
TOLERANT
( / R
4

STORM PROPERTIES
RELIABLE
Guaranteed
message
processing
RUNS ON
JVM
SUPPORT
ANY
LANGUAGE
Java, Python,
C# , etc
EASY
Û $ u 5

STORM
ABSTRACTIONS Tuples, Streams, Spouts, Bolts and
Topologies
Z III
å å å

TUPLE
STORM ABSTRACTIONS
Storm data type: Immutable List of Key/Value pair of any data type
word: “Hello”
Count: 25
Frequency: 0.25

STREAM
STORM ABSTRACTIONS
Unbounded Sequence of Tuples between nodes

SPOUT
STORM ABSTRACTIONS
The Source of the Stream

READ Data
Read from stream of data – queues, web logs, API
calls, databases
Emit tuples into storm
STORM ABSTRACTIONS
Spout responsibilities
STREAM

BOLT
STORM ABSTRACTIONS
Processing Unit
⚡
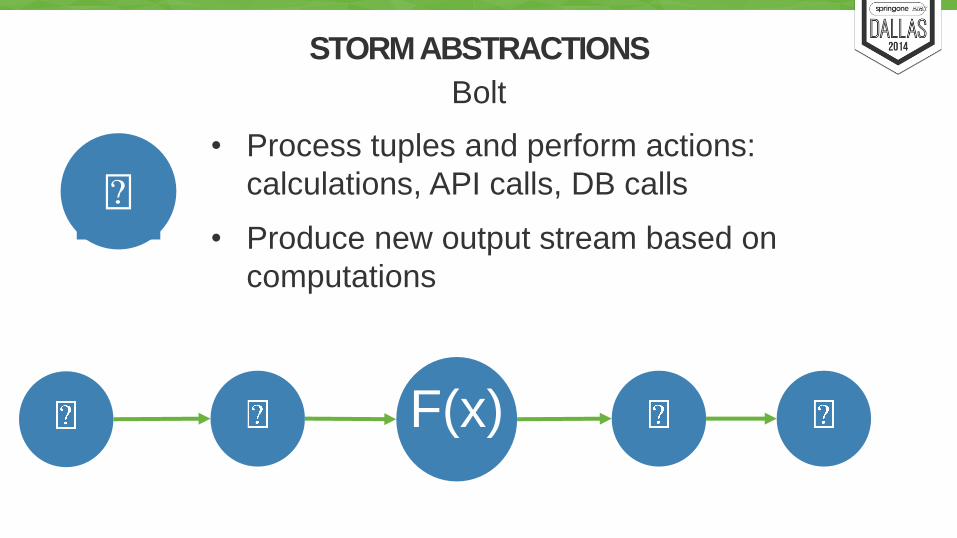
• Process tuples and perform actions:
calculations, API calls, DB calls
• Produce new output stream based on
computations
STORM ABSTRACTIONS
Bolt
⚡
F(x)
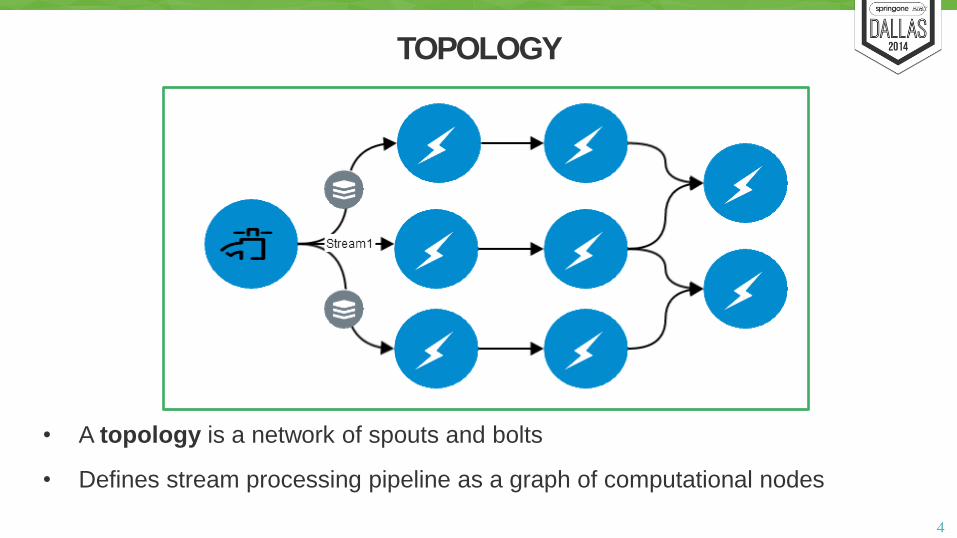
• A topology is a network of spouts and bolts
• Defines stream processing pipeline as a graph of computational nodes
TOPOLOGY
4

• May have multiple spouts
TOPOLOGY
4

TASK
TASKS Instance of Spout or Bolt
• Each spout and bolt may
have many instances
(tasks) that perform all the
processing in parallel.
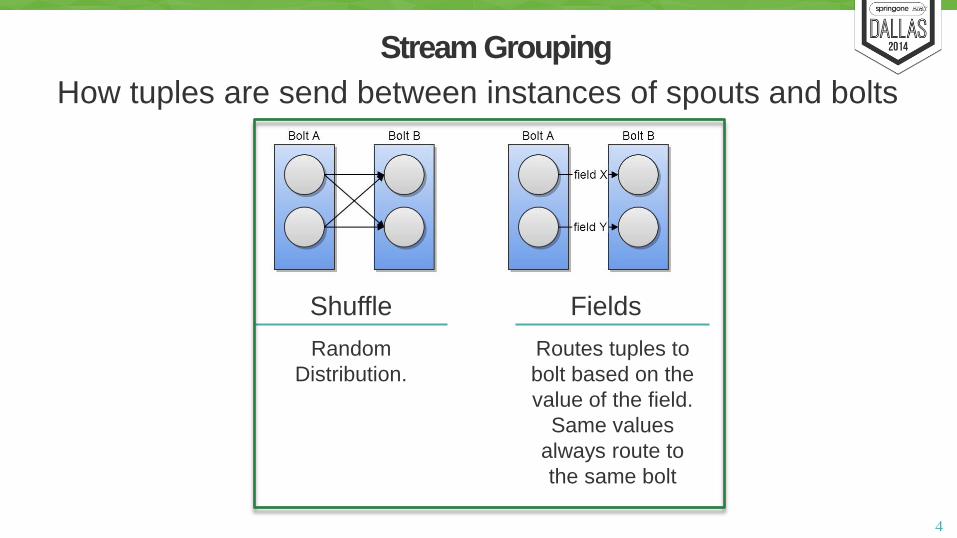
Stream Grouping
How tuples are send between instances of spouts and bolts
Shuffle
Random
Distribution.
Fields
Routes tuples to
bolt based on the
value of the field.
Same values
always route to
the same bolt
4

Abstractions Summary
4
• Tuple
• Stream
• Spout (task)
• Bolt (task)
• Topology

Let’s Code
( IV
å å å å

compile 'org.apache.storm:storm-core:0.9.2-incubating’
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.2-incubating</version>
</dependency>
STORM DEPENDENCIES

DISTRIBUTED WORD COUNT TOPOLOGY
sentence word
Word
count
SPOUT
1
Split
Sentence
⚡ 2
Printer
Bolt
4
Word
Count
⚡ 3 final count:
Two 20
Households 24
Both 22
Alike 1
In 1
Dignity 10
"Two households, both alike in dignity"
“Two”
“households”
“both”
“alike”
“in” “dignity”
“Two”:2
“households”:4
“both”:5
“alike”:5
“in”:4 “dignity”:7

WORD COUNT
Data Source
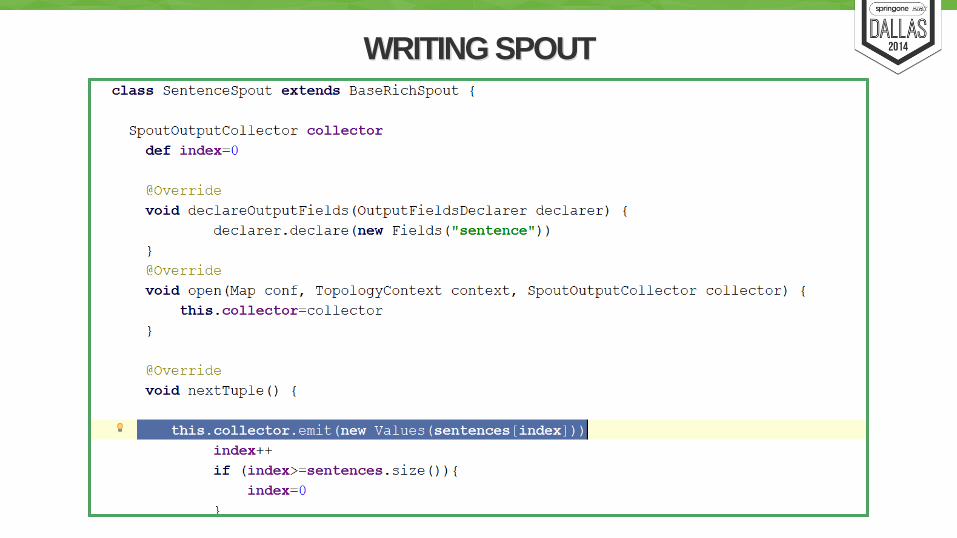
WRITING SPOUT

WRITING BOLT
SplitSentenceBolt
Resource initialization

WRITING BOLT
WordCountBolt

WRITING BOLT
PrinterBolt

TOPOLOGY
Linking it all together

Demo

STORM
PARALLELISM
How to scale
stream processing
q V
å å å å å

STORM PARALLELISM
storm main components
Machines in a
storm cluster
JVM processes
running on a node.
One or more per
node.
Java thread
running within
worker JVM
process.
Instances of
spouts and
bolts.
NODES (SERVERS) WORKERS (JVM) EXECUTORS (THREADS) TASKS
(BOLT/SPOUT)

Parallelism configuration
q

Parallelism configuration
q

Stream Grouping
How tuples are send between instances of spouts and bolts

Guaranteed
message
Processing
VII
a
å å å å å å

Reliability API
Tuple tree
Storm retries always happen from the source

Reliability API (Spout)
Methods from ISpout interface

Reliability API (Bolt)
Reliability in Bolts
Anchoring Ack Fail

TESTING Unit testing Storm
components
VII
a

TEST EACH COMPONENT
SEPARATELY
USE STORM TESTING API
CHECK TestingApiDemo.java
on GITHUB
TESTING STORM

TESTING with SPOCK
BDD style of testing

COMPONENTS
OF A STORM
CLUSTER Z
VIII
å å å å å å å
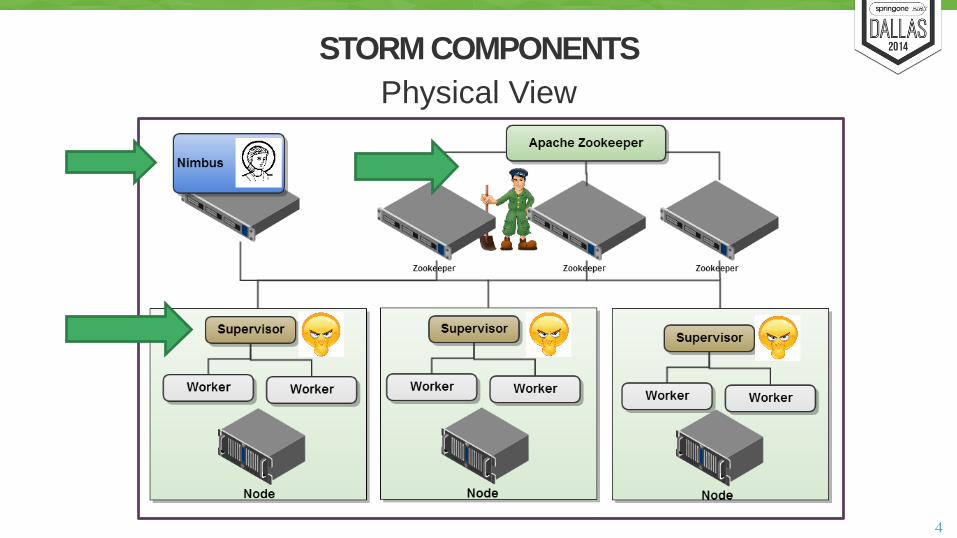
STORM COMPONENTS
Physical View
4

PACKAGE and DEPLOYMENT
deploying topology to a cluster
storm jar Spring2GX-1.0.jar com.spring2gx.storm.WordCountTopology word-count-
topology

STORM UI
Monitoring and performance tuning

STORM
FAULT-
TOLERANCE
x IX
å å å å å å å å

Normal operations

NIMBUS DOWN
Run under supervision: Monit, supervisord

WORKER NODE DOWN
Nimbus move work to another node

SUPERVISOR DOWN

WORKER PROCESS DOWN
Supervisor will restart worker

TRIDENT Micro-Batch
Stream Processing
K X
å å å å å å å å å

TRIDENT
Trident
FUNCTIONS
Functions,
Filters,
aggregations,
joins, grouping
MICRO-BATCH
Ordered batches of
tuples. Batches can
be partitioned.
HIGH LEVEL API
Similar to Pig
or Cascading
EXACTLY ONE SEMANTICS
Transactional
spouts
SUPPORT STATE
Trident has first class
abstraction for
reading and writing to
stateful sources
Ü
1
4

TRIDENT IS MICRO-BATCH
Stream processed in small batches
• Each batch has a unique ID which is always the same on each replay
• If one tuple failed, the whole batch is reprocessed
• Batches are ordered

How trident provides exactly –one semantics?

EXACTLY-ONCE SEMANTICS
Store the count along with BatchID
COUNT 100
BATCHID 1
COUNT 110
BATCHID 2
10 more tuples with batchId 2
Failure: Batch 2 replayed
The same batchId (2)
• Spout should replay a batch exactly as it was played before
• Trident API hide dealing with batchID complexity

TRIDENT EXAMPLE
Word count with Trident

TRIDENT EXAMPLE
Word count with Trident
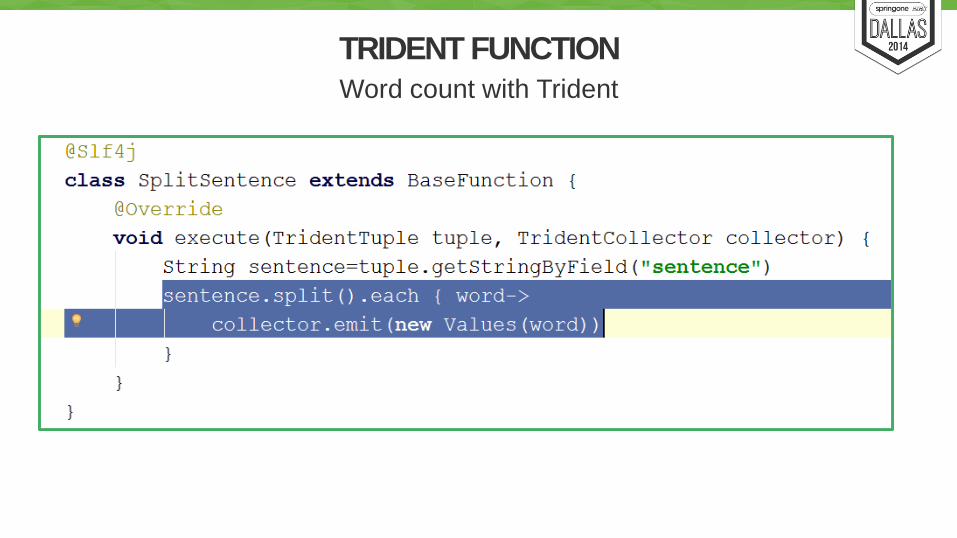
TRIDENT FUNCTION
Word count with Trident

Demo

Style of computation One at a time Micro Batch
Lower Latency
Higher throutput
At least once semantics
Exactly-once semantics
Simpler programming model
STORM vs TRIDENT
4

CHALLENGE
XII
å å å å å å å å å å

Twitter streaming system

WEBMD MEDPULSE
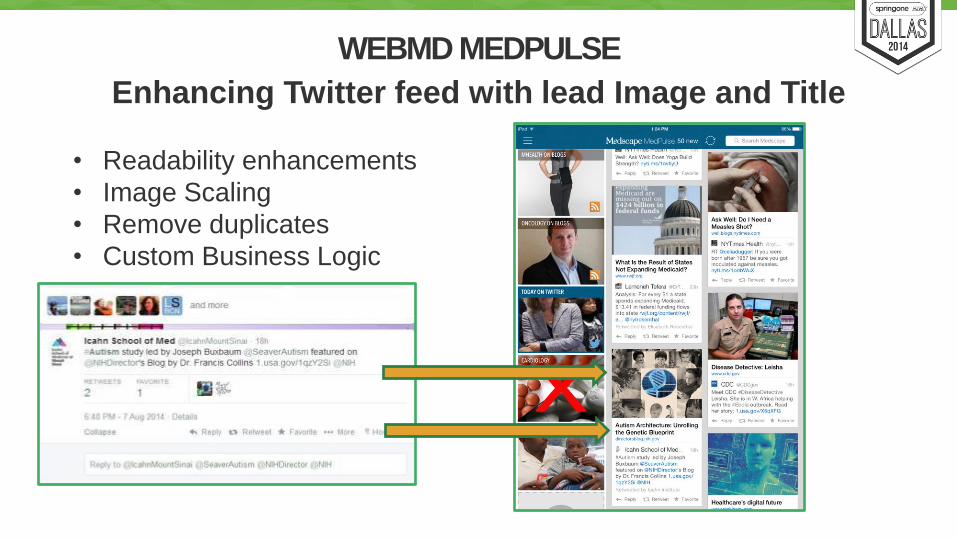
WEBMD MEDPULSE
Enhancing Twitter feed with lead Image and Title
• Readability enhancements
• Image Scaling
• Remove duplicates
• Custom Business Logic

Twitter streaming system

TWITTER STREAMING API

TWITTER STREAMING API
Status

use Twitter4J java library
CREATE SPOUT

use existing Spout from Storm contrib
project on GitHub
CREATE TWITTER SPOUT
Spouts exists for: Twitter, Kafka, JMS,
RabbitMQ, Amazon SQS, Kinesis,
MongoDB….
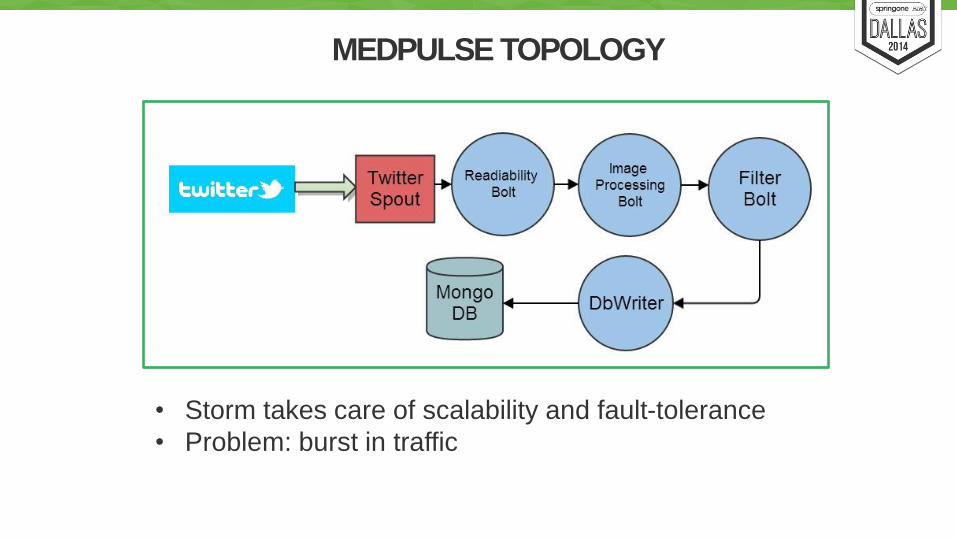
MEDPULSE TOPOLOGY
• Storm takes care of scalability and fault-tolerance
• Problem: burst in traffic

MEDPULSE TOPOLOGY
Introducing Queuing Layer with Kafka
Fast
( V Ñ Scalable Durable Distributed
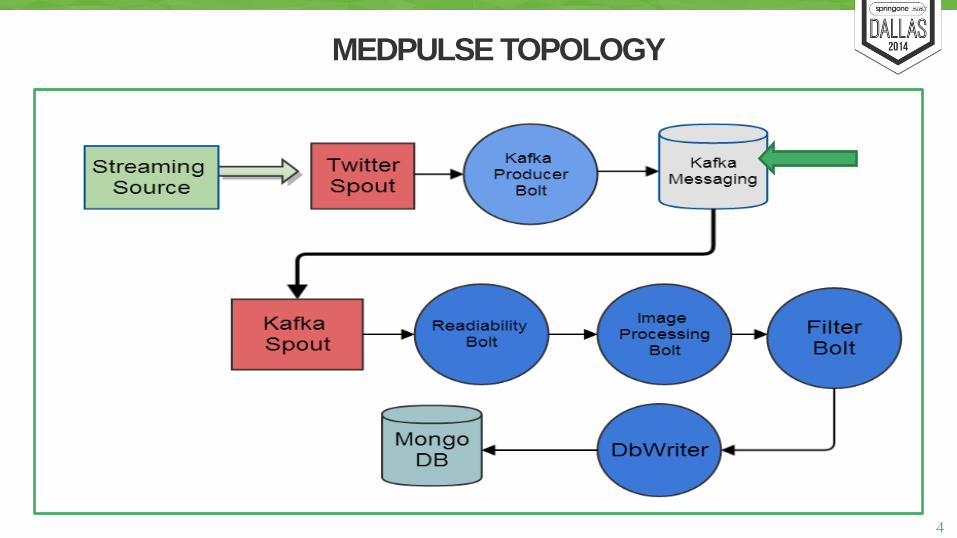
MEDPULSE TOPOLOGY
4

STORM ARCHITECTURAL BLUEPRINT
Queue
(Kafka)

OTHER WEBMD USE CASES
Solr Indexing

RULE ENGINE TOPOLOGY
Processing Groovy Rules (DSL) on a scale in real-time

Tuning and
Monitoring
XII
å å å å å å å å å å å

Synthetic Monitoring
Use Graphite
Statsd and Storm Metrics API
http://www.michael-noll.com/blog/2013/11/06/sending-metrics-from-storm-to-graphite/
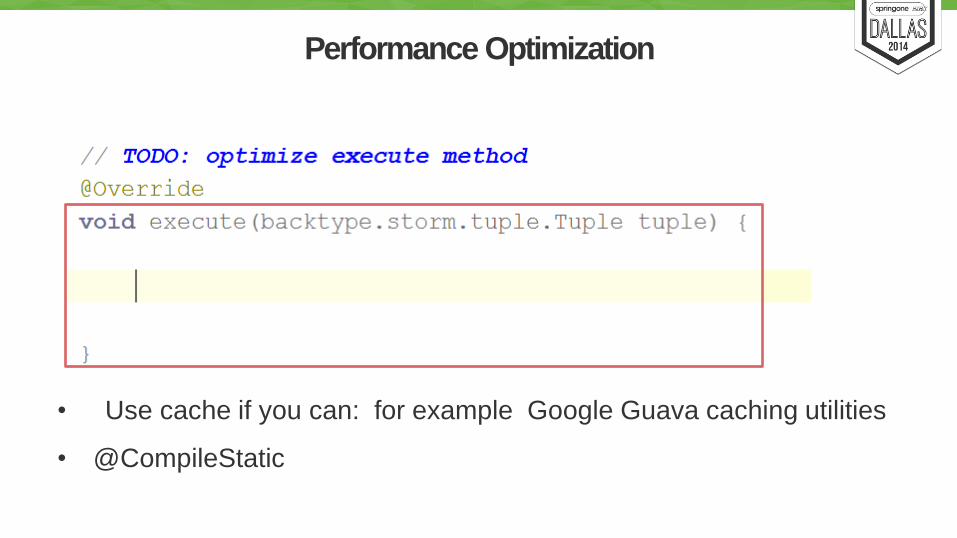
• Use cache if you can: for example Google Guava caching utilities
• @CompileStatic
Performance Optimization

RESOURCES
• http://www.michael-noll.com
• http://www.bigdata-cookbook.com/post/72320512609/storm-metrics-how-to
• http://svendvanderveken.wordpress.com/

RESOURCES
edvorkin/Storm_Demo_Spring2GX

YOU FOR LISTENING
THANK

Go ahead. Ask away.
QUESTIONS
AND
ANSWERS

WRITING SPOUT

å
å å